Con il lancio della funzionalità di ricerca neurale per Servizio Amazon OpenSearch in OpenSearch 2.9, ora è semplice integrarsi con modelli AI/ML per potenziare la ricerca semantica e altri casi d'uso. Il servizio OpenSearch supporta sia la ricerca lessicale che quella vettoriale dall'introduzione della funzionalità k-nearest neighbor (k-NN) nel 2020; tuttavia, la configurazione della ricerca semantica richiedeva la creazione di un framework per integrare modelli di machine learning (ML) per l'acquisizione e la ricerca. La funzionalità di ricerca neurale facilita la trasformazione da testo a vettore durante l'acquisizione e la ricerca. Quando si utilizza una query neurale durante la ricerca, la query viene tradotta in un incorporamento di vettore e k-NN viene utilizzato per restituire gli incorporamenti di vettore più vicini dal corpus.
Per utilizzare la ricerca neurale, è necessario impostare un modello ML. Consigliamo di configurare connettori AI/ML per i servizi AWS AI e ML (come Amazon Sage Maker or Roccia Amazzonica) o alternative di terze parti. A partire dalla versione 2.9 del servizio OpenSearch, i connettori AI/ML si integrano con la ricerca neurale per semplificare e rendere operativa la traduzione del corpus di dati e delle query in incorporamenti di vettori, rimuovendo così gran parte della complessità dell'idratazione e della ricerca dei vettori.
In questo post dimostriamo come configurare i connettori AI/ML su modelli esterni tramite la console del servizio OpenSearch.
Panoramica della soluzione
Nello specifico, questo post ti guida attraverso la connessione a un modello in SageMaker. Quindi ti guideremo attraverso l'utilizzo del connettore per configurare la ricerca semantica sul servizio OpenSearch come esempio di un caso d'uso supportato tramite la connessione a un modello ML. Le integrazioni Amazon Bedrock e SageMaker sono attualmente supportate nell'interfaccia utente della console OpenSearch Service e l'elenco delle integrazioni di prime e terze parti supportate dall'interfaccia utente continuerà a crescere.
Per tutti i modelli non supportati tramite l'interfaccia utente, puoi invece configurarli utilizzando le API disponibili e il Progetti di machine learning. Per ulteriori informazioni, fare riferimento a Introduzione ai modelli OpenSearch. Puoi trovare i progetti per ciascun connettore nel file Repository GitHub di ML Commons.
Prerequisiti
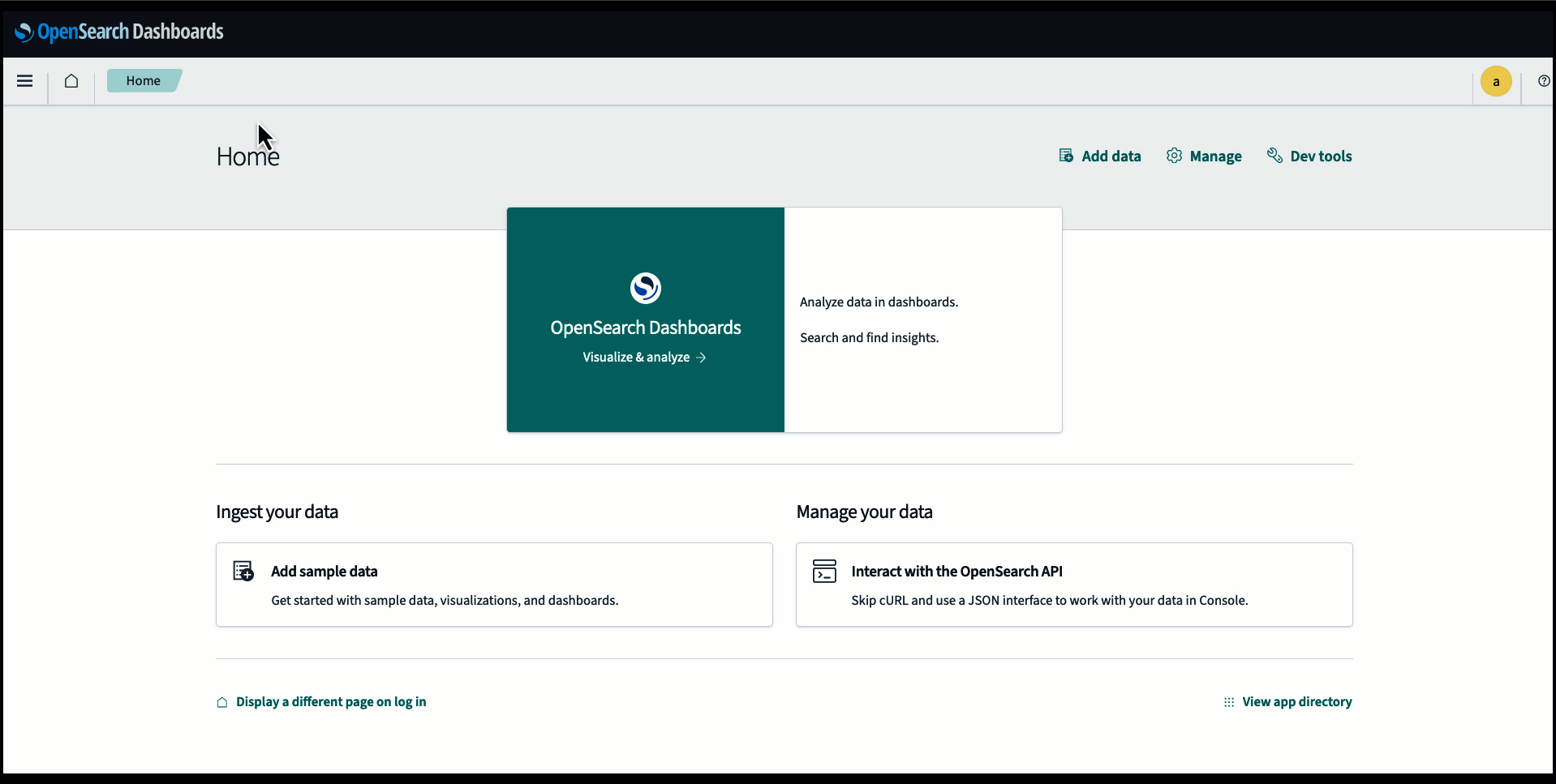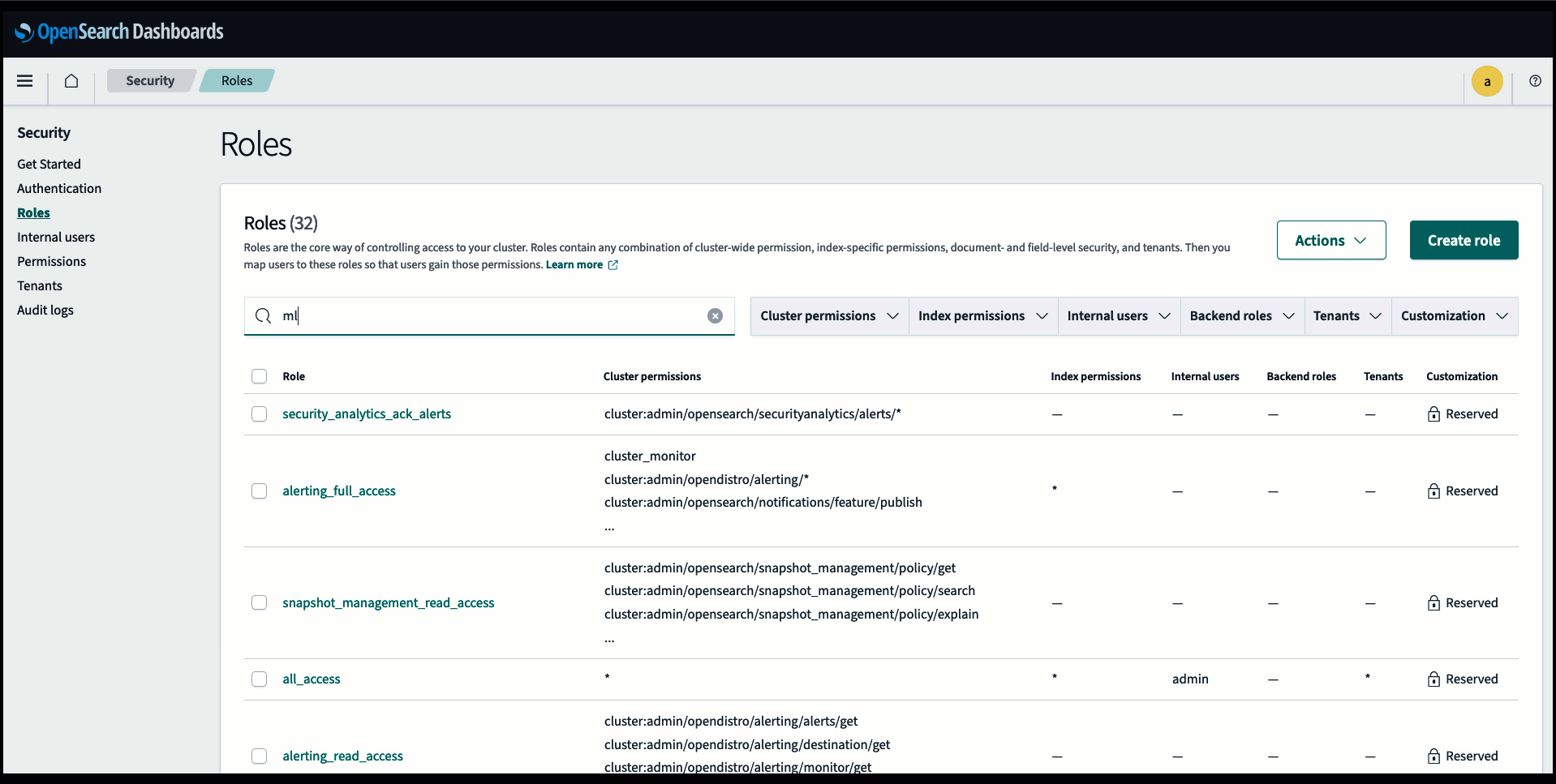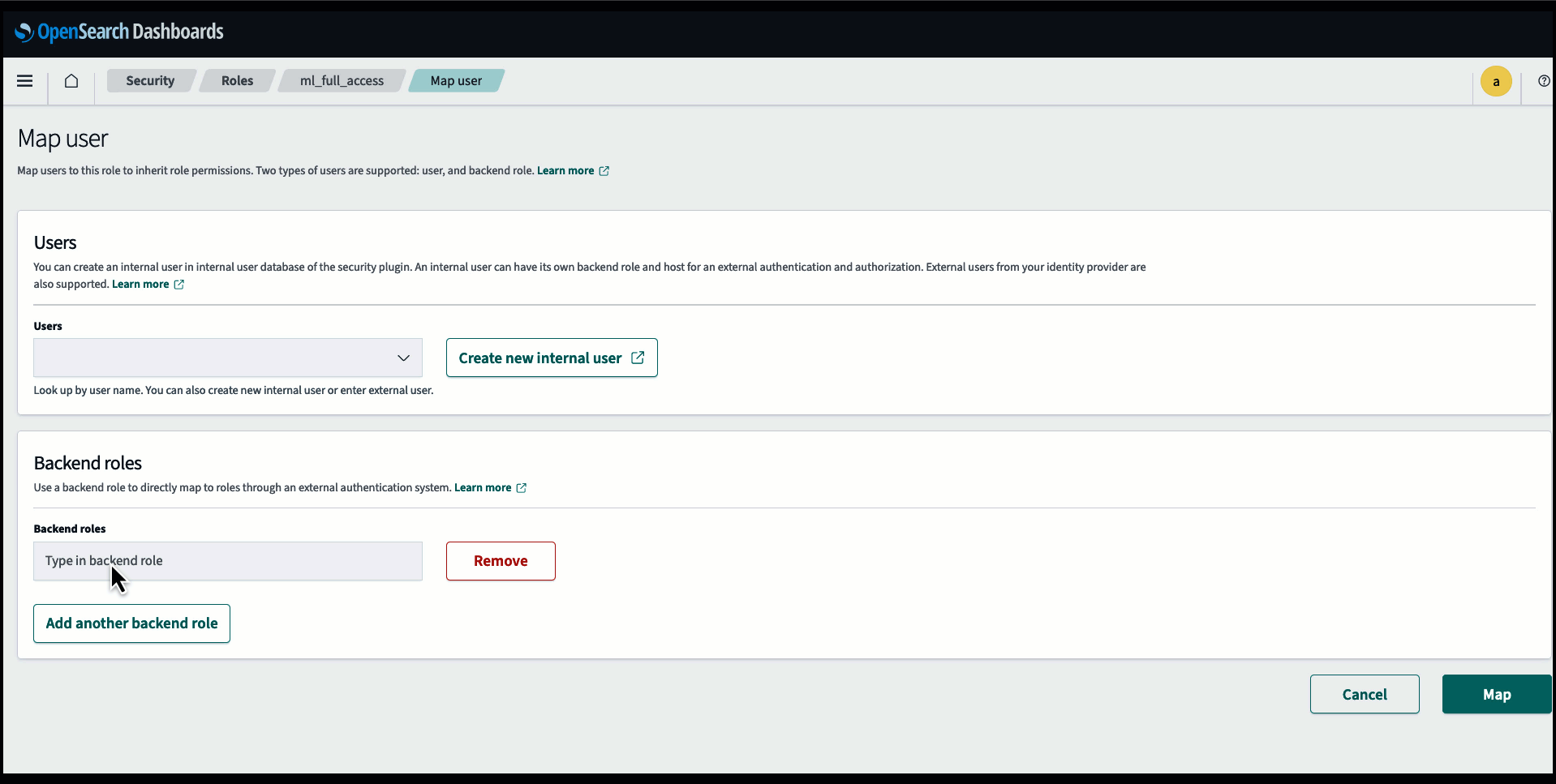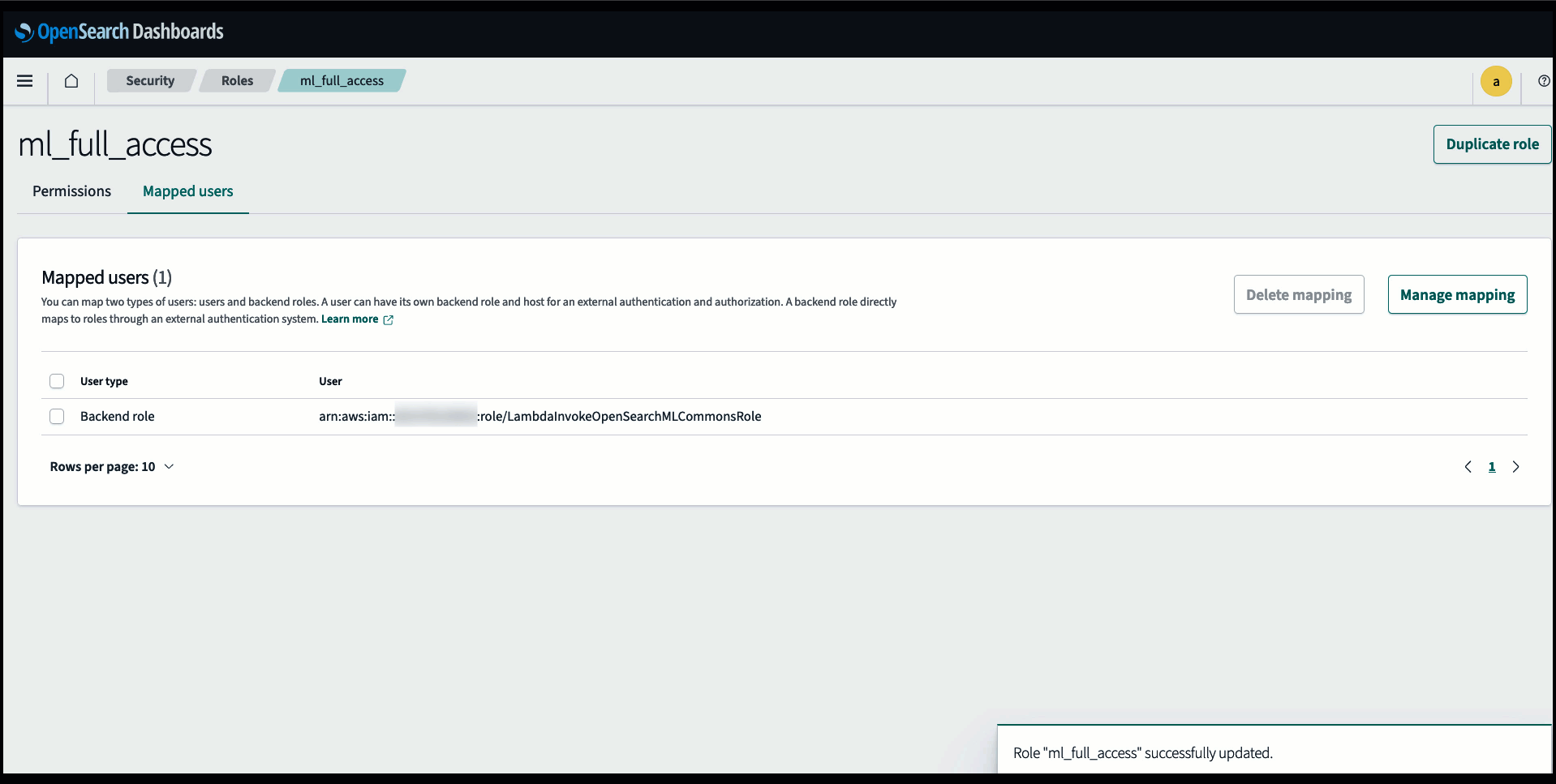
Prima di connettere il modello tramite la console di OpenSearch Service, crea un dominio di OpenSearch Service. Mappa e Gestione dell'identità e dell'accesso di AWS (IAM) ruolo in base al nome LambdaInvokeOpenSearchMLCommonsRole come ruolo di backend su ml_full_access ruolo utilizzando il plug-in Sicurezza su OpenSearch Dashboards, come mostrato nel video seguente. Il flusso di lavoro delle integrazioni di OpenSearch Service è precompilato per utilizzare il file LambdaInvokeOpenSearchMLCommonsRole Ruolo IAM per impostazione predefinita per creare il connettore tra il dominio del servizio OpenSearch e il modello distribuito su SageMaker. Se utilizzi un ruolo IAM personalizzato sulle integrazioni della console di servizio OpenSearch, assicurati che il ruolo personalizzato sia mappato come ruolo backend con ml_full_access autorizzazioni prima di distribuire il modello.
Distribuisci il modello utilizzando AWS CloudFormation
Il video seguente illustra i passaggi per utilizzare la console del servizio OpenSearch per distribuire un modello in pochi minuti su Amazon SageMaker e generare l'ID del modello tramite i connettori AI. Il primo passo è scegliere Integrazioni nel riquadro di navigazione sulla console AWS di OpenSearch Service, che indirizza a un elenco di integrazioni disponibili. L'integrazione viene impostata tramite un'interfaccia utente, che richiederà gli input necessari.
Per configurare l'integrazione, devi solo fornire l'endpoint del dominio del servizio OpenSearch e fornire un nome modello per identificare in modo univoco la connessione del modello. Per impostazione predefinita, il modello distribuisce il modello di trasformazione delle frasi Hugging Face, djl://ai.djl.huggingface.pytorch/sentence-transformers/all-MiniLM-L6-v2.
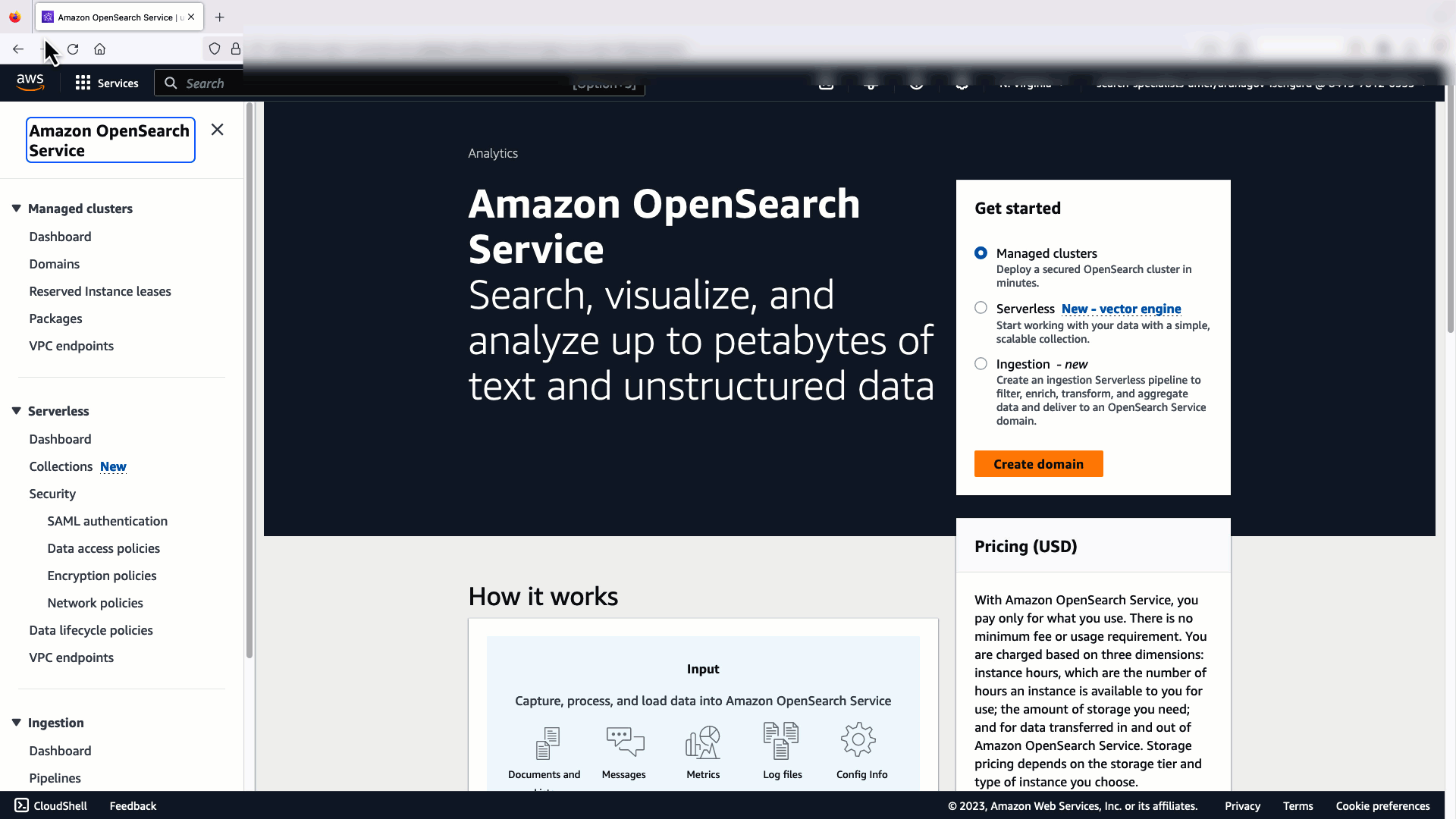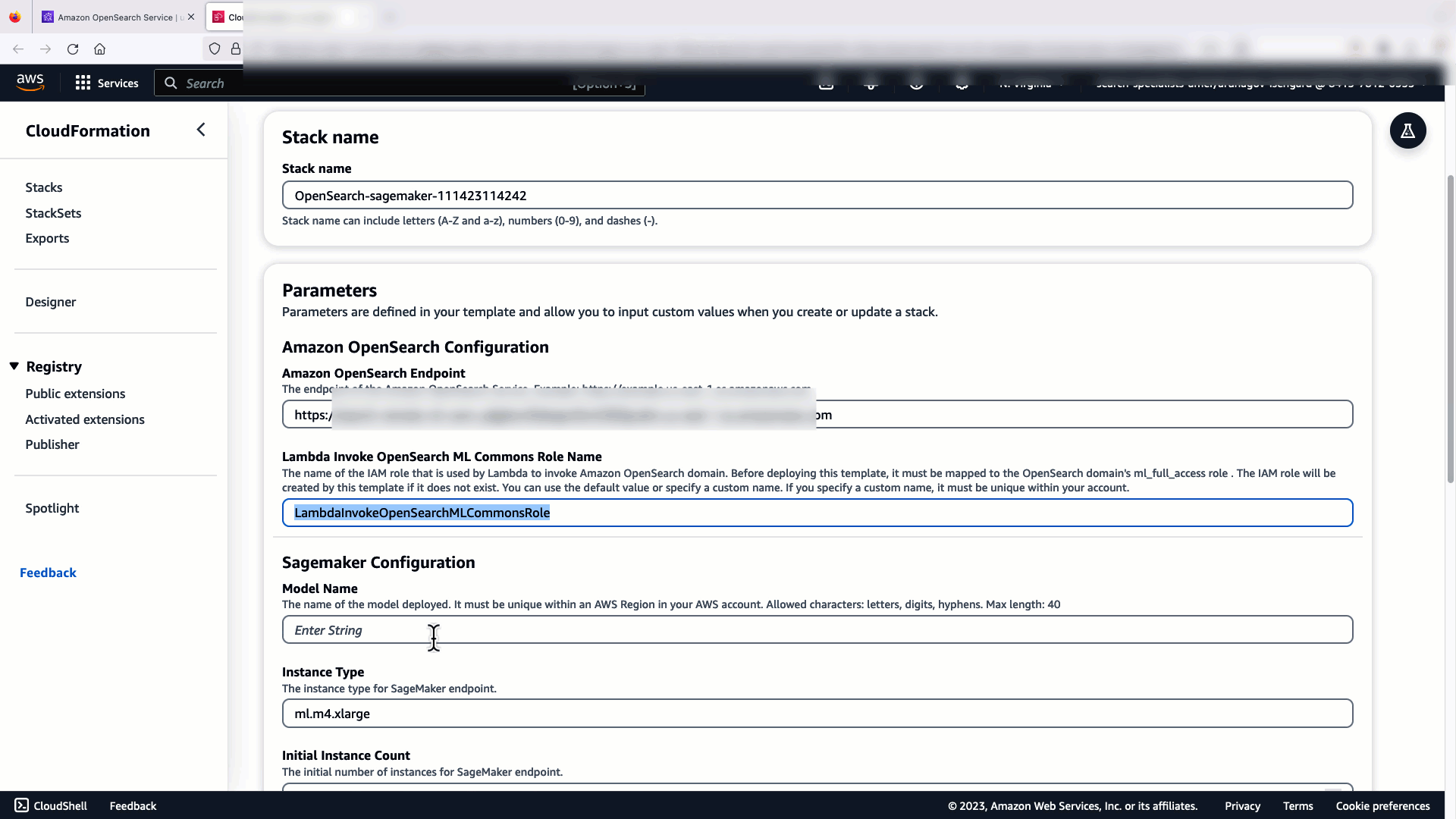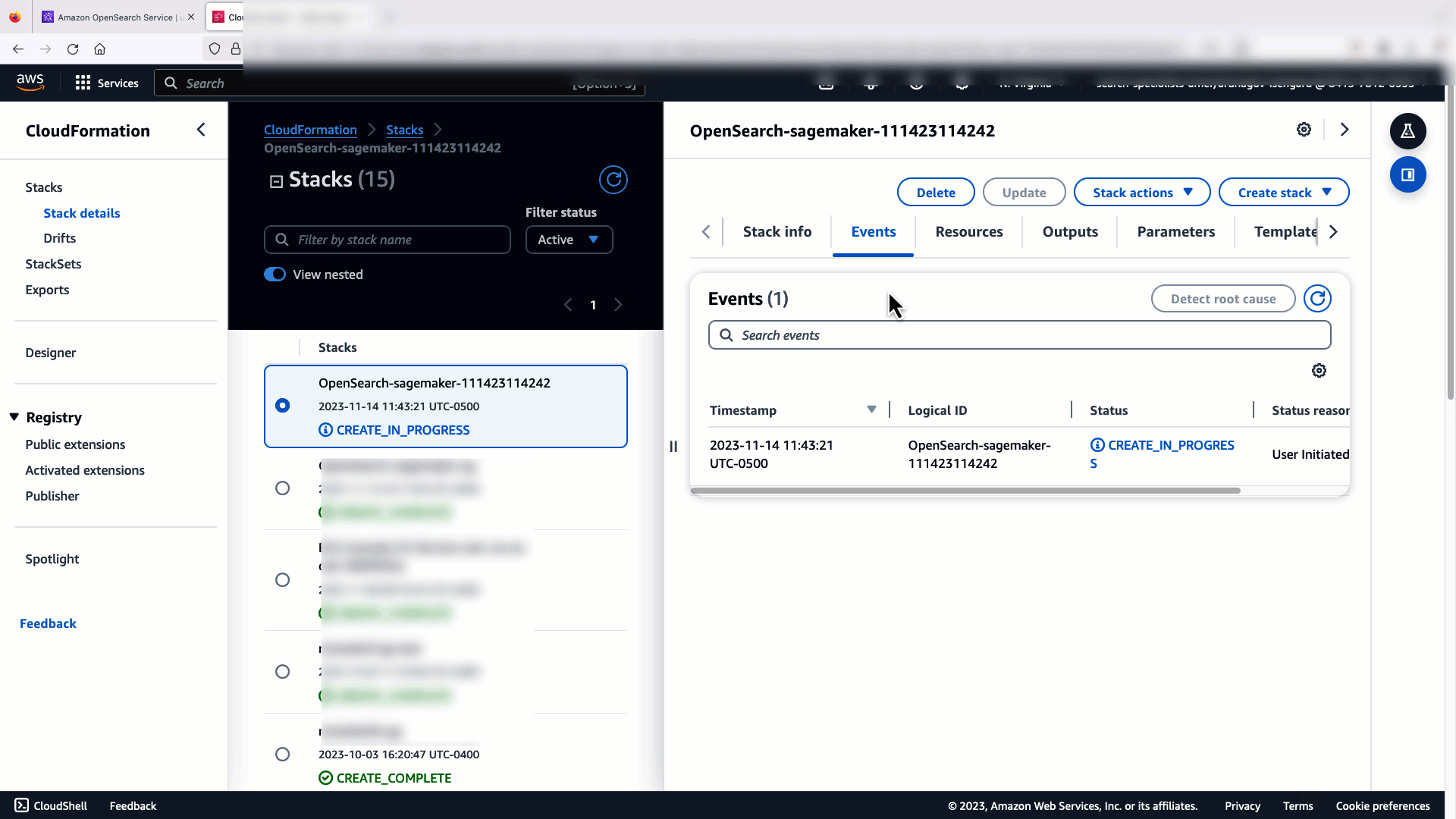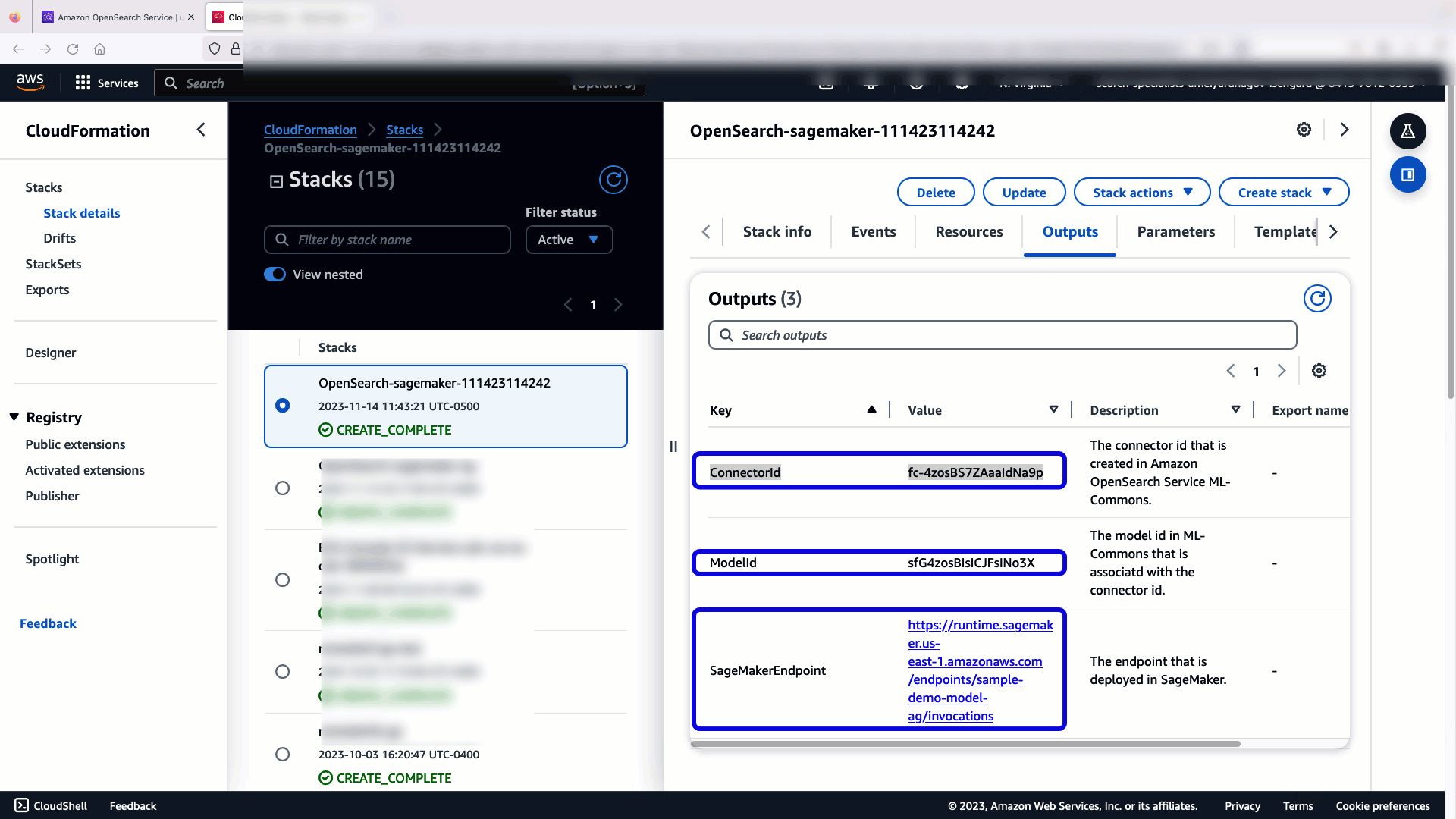
Quando si sceglie Crea Stack, verrai indirizzato al AWS CloudFormazione consolle. Il modello CloudFormation distribuisce l'architettura dettagliata nel diagramma seguente.

Lo stack CloudFormation crea un file AWS Lambda applicazione da cui distribuisce un modello Servizio di archiviazione semplice Amazon (Amazon S3), crea il connettore e genera l'ID modello nell'output. È quindi possibile utilizzare questo ID modello per creare un indice semantico.
Se il modello predefinito all-MiniLM-L6-v2 non soddisfa il tuo scopo, puoi distribuire qualsiasi modello di incorporamento del testo di tua scelta sull'host del modello scelto (SageMaker o Amazon Bedrock) fornendo gli artefatti del modello come oggetto S3 accessibile. In alternativa è possibile selezionare una delle seguenti opzioni modelli linguistici pre-addestrati e distribuirlo su SageMaker. Per istruzioni su come configurare l'endpoint e i modelli, fare riferimento a Immagini Amazon SageMaker disponibili.
SageMaker è un servizio completamente gestito che riunisce un'ampia gamma di strumenti per abilitare il machine learning ad alte prestazioni e a basso costo per qualsiasi caso d'uso, offrendo vantaggi chiave come il monitoraggio dei modelli, l'hosting serverless e l'automazione del flusso di lavoro per la formazione e la distribuzione continue. SageMaker ti consente di ospitare e gestire il ciclo di vita dei modelli di incorporamento del testo e di utilizzarli per alimentare query di ricerca semantica nel servizio OpenSearch. Una volta connesso, SageMaker ospita i tuoi modelli e OpenSearch Service viene utilizzato per eseguire query in base ai risultati di inferenza di SageMaker.
Visualizza il modello distribuito tramite OpenSearch Dashboards
Per verificare che il modello CloudFormation abbia distribuito correttamente il modello sul dominio del servizio OpenSearch e ottenere l'ID del modello, puoi utilizzare l'API REST GET di ML Commons tramite OpenSearch Dashboards Dev Tools.
L'API REST GET _plugins ora fornisce API aggiuntive per visualizzare anche lo stato del modello. Il seguente comando consente di visualizzare lo stato di un modello remoto:
Come mostrato nello screenshot seguente, a DEPLOYED lo stato nella risposta indica che il modello è stato distribuito correttamente nel cluster del servizio OpenSearch.

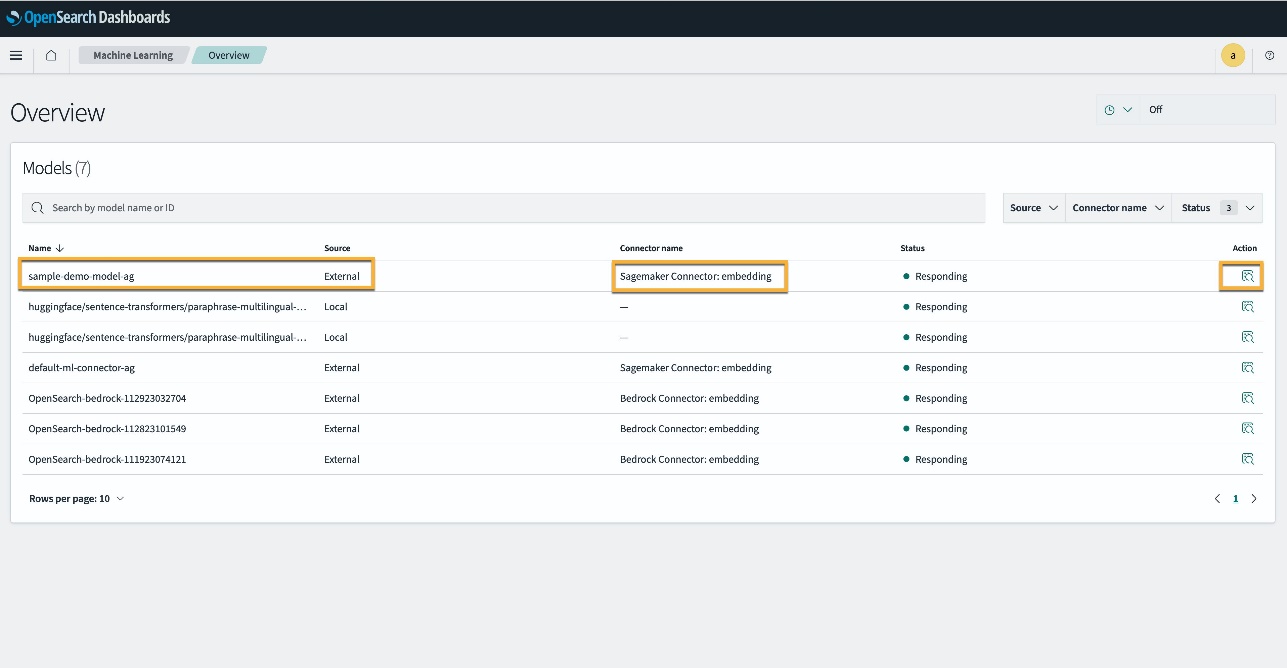
In alternativa, puoi visualizzare il modello distribuito sul tuo dominio del servizio OpenSearch utilizzando il file machine Learning pagina dei dashboard di OpenSearch.

Questa pagina elenca le informazioni sul modello e gli stati di tutti i modelli distribuiti.

Crea la pipeline neurale utilizzando l'ID modello
Quando lo stato del modello viene visualizzato come DEPLOYED in Dev Tools o verde e Rispondendo in OpenSearch Dashboards, puoi utilizzare l'ID modello per creare la pipeline di acquisizione neurale. La seguente pipeline di acquisizione viene eseguita negli strumenti di sviluppo di OpenSearch Dashboards del tuo dominio. Assicurati di sostituire l'ID modello con l'ID univoco generato per il modello distribuito sul tuo dominio.

Crea l'indice di ricerca semantica utilizzando la pipeline neurale come pipeline predefinita
Ora puoi definire la mappatura dell'indice con la pipeline predefinita configurata per utilizzare la nuova pipeline neurale creata nel passaggio precedente. Assicurati che i campi vettoriali siano dichiarati come knn_vector e le dimensioni sono appropriate al modello distribuito su SageMaker. Se hai mantenuto la configurazione predefinita per distribuire il modello all-MiniLM-L6-v2 su SageMaker, mantieni le seguenti impostazioni così come sono ed esegui il comando in Dev Tools.

Acquisisci documenti di esempio per generare vettori
Per questa demo, puoi importare il file campione di catalogo prodotti demostore al dettaglio al nuovo semantic_demostore indice. Sostituisci il nome utente, la password e l'endpoint del dominio con le informazioni del tuo dominio e inserisci i dati grezzi nel servizio OpenSearch:

Convalidare il nuovo indice semantic_demostore
Ora che hai inserito il tuo set di dati nel dominio del servizio OpenSearch, verifica se i vettori richiesti vengono generati utilizzando una semplice ricerca per recuperare tutti i campi. Convalidare se i campi definiti come knn_vectors avere i vettori richiesti.

Confronta la ricerca lessicale e la ricerca semantica alimentate dalla ricerca neurale utilizzando lo strumento Confronta risultati di ricerca
Il Strumento Confronta i risultati della ricerca su OpenSearch Dashboards è disponibile per i carichi di lavoro di produzione. Puoi navigare verso Confronta i risultati della ricerca pagina e confrontare i risultati della query tra la ricerca lessicale e la ricerca neurale configurata per utilizzare l'ID modello generato in precedenza.

ripulire
Puoi eliminare le risorse che hai creato seguendo le istruzioni in questo post eliminando lo stack CloudFormation. Ciò eliminerà le risorse Lambda e il bucket S3 che contengono il modello distribuito a SageMaker. Completa i seguenti passaggi:
- Nella console AWS CloudFormation, vai alla pagina dei dettagli dello stack.
- Scegli Elimina.

- Scegli Elimina per confermare.

Puoi monitorare l'avanzamento dell'eliminazione dello stack sulla console AWS CloudFormation.
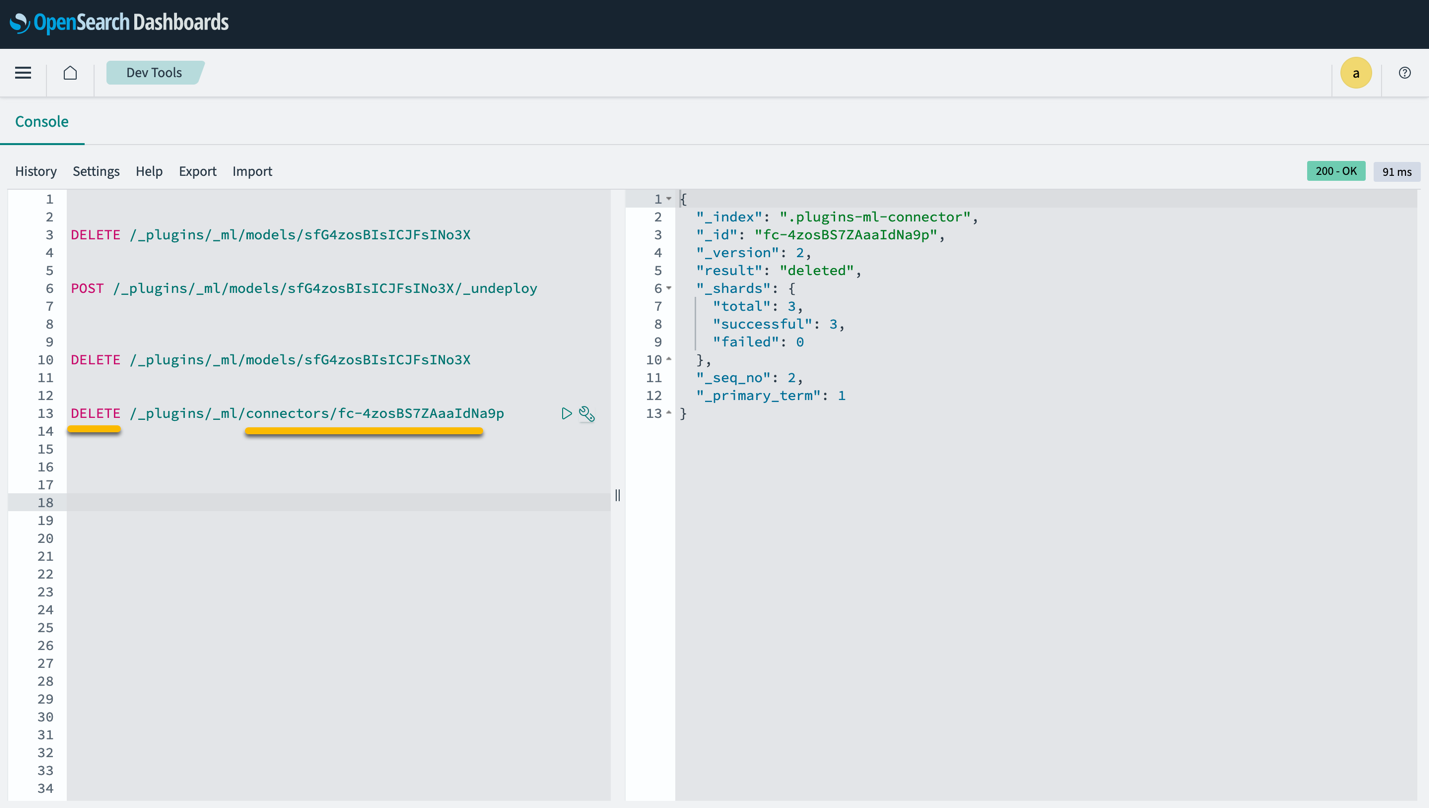
Tieni presente che l'eliminazione dello stack CloudFormation non elimina il modello distribuito sul dominio SageMaker e il connettore AI/ML creato. Questo perché questi modelli e il connettore possono essere associati a più indici all'interno del dominio. Per eliminare in modo specifico un modello e il relativo connettore associato, utilizza le API del modello come mostrato negli screenshot seguenti.
In primo luogo, undeploy il modello dalla memoria del dominio OpenSearch Service:

Quindi puoi eliminare il modello dall'indice del modello:

Infine, elimina il connettore dall'indice del connettore:
Conclusione
In questo post hai imparato come distribuire un modello in SageMaker, creare il connettore AI/ML utilizzando la console del servizio OpenSearch e creare l'indice di ricerca neurale. La possibilità di configurare connettori AI/ML nel servizio OpenSearch semplifica il processo di idratazione dei vettori rendendo native le integrazioni con modelli esterni. Puoi creare un indice di ricerca neurale in pochi minuti utilizzando la pipeline di acquisizione neurale e la ricerca neurale che utilizzano l'ID modello per generare al volo l'incorporamento del vettore durante l'acquisizione e la ricerca.
Per ulteriori informazioni su questi connettori AI/ML, fare riferimento a Connettori AI di Amazon OpenSearch Service per i servizi AWS, Integrazioni di modelli AWS CloudFormation per la ricerca semanticae Creazione di connettori per piattaforme ML di terze parti.
Informazioni sugli autori
 Aruna Govindaraju è un Amazon OpenSearch Specialist Solutions Architect e ha lavorato con molti motori di ricerca commerciali e open source. È appassionata di ricerca, pertinenza ed esperienza utente. La sua esperienza nella correlazione dei segnali degli utenti finali con il comportamento dei motori di ricerca ha aiutato molti clienti a migliorare la propria esperienza di ricerca.
Aruna Govindaraju è un Amazon OpenSearch Specialist Solutions Architect e ha lavorato con molti motori di ricerca commerciali e open source. È appassionata di ricerca, pertinenza ed esperienza utente. La sua esperienza nella correlazione dei segnali degli utenti finali con il comportamento dei motori di ricerca ha aiutato molti clienti a migliorare la propria esperienza di ricerca.
 Dagney Braun è Principal Product Manager presso AWS focalizzato su OpenSearch.
Dagney Braun è Principal Product Manager presso AWS focalizzato su OpenSearch.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/power-neural-search-with-ai-ml-connectors-in-amazon-opensearch-service/
- :ha
- :È
- :non
- $ SU
- 1
- 100
- 12
- 15%
- 2020
- 25
- 7
- 8
- 9
- a
- capacità
- WRI
- accesso
- accessibile
- aggiuntivo
- AI
- AI / ML
- Tutti
- consente
- anche
- alternative
- Amazon
- Amazon Sage Maker
- Amazon Web Services
- an
- ed
- in qualsiasi
- api
- API
- Applicazioni
- opportuno
- architettura
- SONO
- AS
- associato
- At
- Automazione
- disponibile
- AWS
- AWS CloudFormazione
- BACKEND
- basato
- BE
- perché
- comportamento
- vantaggi
- fra
- entrambi
- Porta
- ampio
- costruire
- Costruzione
- by
- Materiale
- Custodie
- casi
- catalogo
- scegliere
- Scegli
- scelto
- Cluster
- Popolo
- confrontare
- completamento di una
- complessità
- Configurazione
- configurato
- configurazione
- Confermare
- collegato
- Collegamento
- veloce
- consolle
- contenere
- continua
- continuo
- correlando
- creare
- creato
- crea
- Attualmente
- costume
- Clienti
- cruscotti
- dati
- Predefinito
- definire
- definito
- consegna
- Dimo
- dimostrare
- dimostra
- schierare
- schierato
- distribuzione
- deployment
- Distribuisce
- descrizione
- dettagliati
- dettagli
- Dev
- Dimensioni
- dimensioni
- documenti
- non
- dominio
- durante
- ogni
- In precedenza
- senza sforzo
- o
- incorporamento
- enable
- endpoint
- motore
- Motori
- garantire
- Etere (ETH)
- esempio
- esperienza
- competenza
- esterno
- Faccia
- facilita
- caratteristica
- campi
- Trovate
- Nome
- concentrato
- i seguenti
- Nel
- Contesto
- da
- completamente
- generare
- generato
- genera
- ottenere
- gif
- GitHub
- Green
- Crescere
- guida
- Avere
- aiutato
- suo
- Alte prestazioni
- host
- di hosting
- padroni di casa
- Come
- Tutorial
- Tuttavia
- HTML
- http
- HTTPS
- abbracciare il viso
- idratazione
- IAM
- ID
- identificare
- Identità
- if
- competenze
- in
- Index
- indici
- indica
- informazioni
- Ingressi
- invece
- istruzioni
- integrare
- integrazione
- integrazioni
- ai miglioramenti
- Introduzione
- IT
- SUO
- jpg
- json
- mantenere
- Le
- Lingua
- lanciare
- IMPARARE
- imparato
- apprendimento
- ciclo di vita
- Lista
- elenchi
- a basso costo
- macchina
- machine learning
- make
- Fare
- gestire
- gestito
- direttore
- molti
- carta geografica
- mappatura
- Memorie
- metodo
- verbale
- ML
- modello
- modelli
- Monitorare
- monitoraggio
- Scopri di più
- molti
- multiplo
- devono obbligatoriamente:
- Nome
- nativo
- Navigare
- Navigazione
- necessaria
- Bisogno
- Neurale
- New
- adesso
- oggetto
- of
- on
- ONE
- esclusivamente
- aprire
- open source
- or
- Altro
- produzione
- pagina
- vetro
- appassionato
- Password
- permessi
- conduttura
- Platone
- Platone Data Intelligence
- PlatoneDati
- plug-in
- Post
- energia
- alimentato
- precedente
- Direttore
- Precedente
- processi
- processori
- Prodotto
- product manager
- Produzione
- Progressi
- proprietà
- fornire
- fornisce
- fornitura
- scopo
- query
- Crudo
- dati grezzi
- raccomandare
- riferimento
- a distanza
- rimozione
- sostituire
- necessario
- Risorse
- risposta
- REST
- Risultati
- nello specifico retail
- mantenuto
- ritorno
- Ruolo
- percorsi
- Correre
- sagemaker
- screenshot
- Cerca
- motore di ricerca
- Motori di ricerca
- problemi di
- vedere
- select
- servire
- serverless
- servizio
- Servizi
- set
- impostazioni
- lei
- mostrato
- Spettacoli
- Segnali
- Un'espansione
- semplifica
- semplificare
- da
- Soluzioni
- Fonte
- specialista
- in particolare
- pila
- Di partenza
- Stato dei servizi
- step
- Passi
- conservazione
- Con successo
- tale
- supportato
- sicuro
- modello
- testo
- che
- Il
- loro
- Li
- poi
- in tal modo
- Strumenti Bowman per analizzare le seguenti finiture:
- di parti terze standard
- questo
- Attraverso
- a
- insieme
- strumenti
- Training
- Trasformazione
- Traduzione
- vero
- Digitare
- ui
- unico
- univocamente
- uso
- caso d'uso
- utilizzato
- Utente
- Esperienza da Utente
- utilizzando
- CONVALIDARE
- verificare
- versione
- via
- Video
- Visualizza
- passeggiate
- Prima
- we
- sito web
- servizi web
- quando
- quale
- volere
- con
- entro
- lavorato
- flusso di lavoro
- l'automazione del flusso di lavoro
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro