Amazon RedShift è un servizio di data warehousing nel cloud che fornisce elaborazione analitica ad alte prestazioni basata su un'architettura MPP (Massive Parallel Processing). La creazione e la manutenzione di pipeline di dati rappresentano una sfida comune per tutte le aziende. Gestire i file SQL, integrare il lavoro tra team, incorporare tutti i principi di ingegneria del software e importare utilità esterne può essere un'attività dispendiosa in termini di tempo che richiede una progettazione complessa e molta preparazione.
DBT (DataBuildTool) offre questo meccanismo introducendo un framework ben strutturato per l'analisi, la trasformazione e l'orchestrazione dei dati. Applica anche principi generali di ingegneria del software come l'integrazione con i repository git, la configurazione ASCIUGATORE codice, aggiungendo casi di test funzionali e includendo librerie esterne. Questo meccanismo consente agli sviluppatori di concentrarsi sulla preparazione dei file SQL in base alla logica aziendale, mentre dbt si occupa del resto.
In questo post esamineremo un modo ottimale ed economico per incorporare dbt in Amazon Redshift. Noi usiamo Amazon Elastico Registro dei container (Amazon ECR) per archiviare le nostre immagini Docker dbt e AWS Fargate come Servizio di container elastici Amazon (Amazon ECS) per eseguire il lavoro.
Come funziona il framework dbt con Amazon Redshift?
dbt ha un modulo adattatore Amazon Redshift denominato dbt-redshift che gli consente di connettersi e funzionare con Amazon Redshift. Tutti i profili di connessione sono configurati all'interno del dbt profiles.yml file. In un ambiente ottimale, memorizziamo le credenziali AWS Secrets Manager e recuperarli.
Il codice seguente mostra il contenuto di profile.yml:
Il seguente diagramma illustra i componenti chiave del framework dbt:
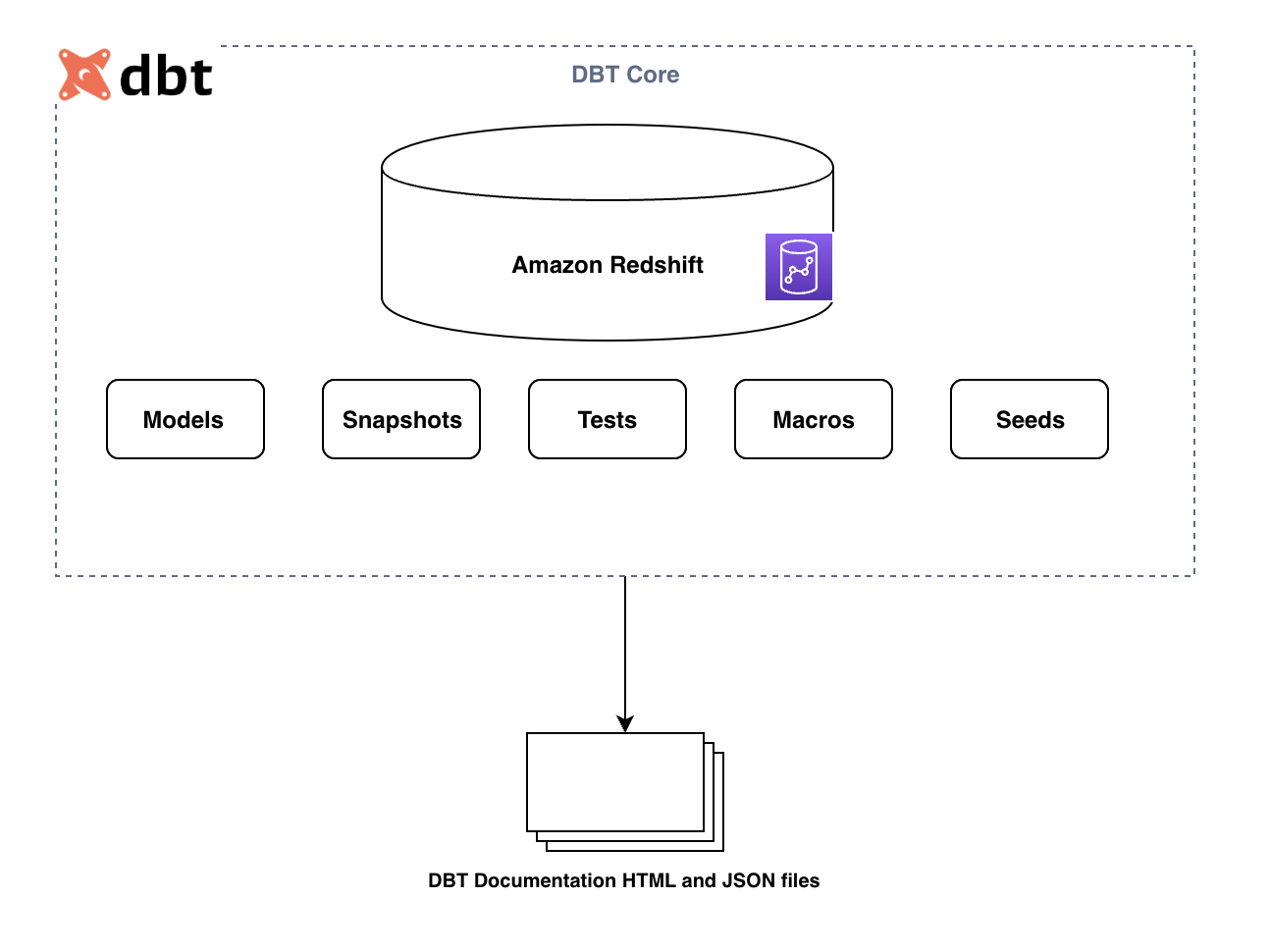
I componenti principali sono i seguenti:
- Modelli – Questi vengono scritti come istruzione SELECT e salvati come file .sql. Tutte le query di trasformazione possono essere scritte qui e possono essere materializzate come tabella o vista. L'aggiornamento della tabella può essere completo o incrementale in base alla configurazione. Per ulteriori informazioni, fare riferimento ai modelli SQL.
- Istantanee – Questi attrezzi tipo-2 dimensioni che cambiano lentamente (SCD) su tabelle di origine modificabili. Questi SCD identificano come una riga in una tabella cambia nel tempo.
- Semi – Questi sono file CSV nel tuo progetto dbt (tipicamente nella directory seed), che dbt può caricare nel tuo data warehouse usando il
dbt seedcomando. - Test – Queste sono le asserzioni che fai sui tuoi modelli e altre risorse nel tuo progetto dbt (come fonti, semi e istantanee). Quando corri
dbt test, dbt ti dirà se ogni test nel tuo progetto supera o fallisce. - Macro – Si tratta di pezzi di codice che possono essere riutilizzati più volte. Sono analoghi alle "funzioni" di altri linguaggi di programmazione e sono estremamente utili se ti ritrovi a ripetere il codice su più modelli.
Questi componenti vengono archiviati come file .sql e vengono eseguiti da comandi CLI dbt. Durante l'esecuzione, dbt crea un file Grafico aciclico diretto (DAG) sulla base del riferimento interno tra le componenti del dbt. Utilizza il DAG per orchestrare di conseguenza la sequenza di esecuzione.
È possibile creare più profili all'interno del file profiles.yml, che dbt può utilizzare per indirizzare diversi ambienti Redshift durante l'esecuzione. Per ulteriori informazioni, fare riferimento alla configurazione di Redshift.
Panoramica della soluzione
Il diagramma seguente illustra l'architettura della nostra soluzione.
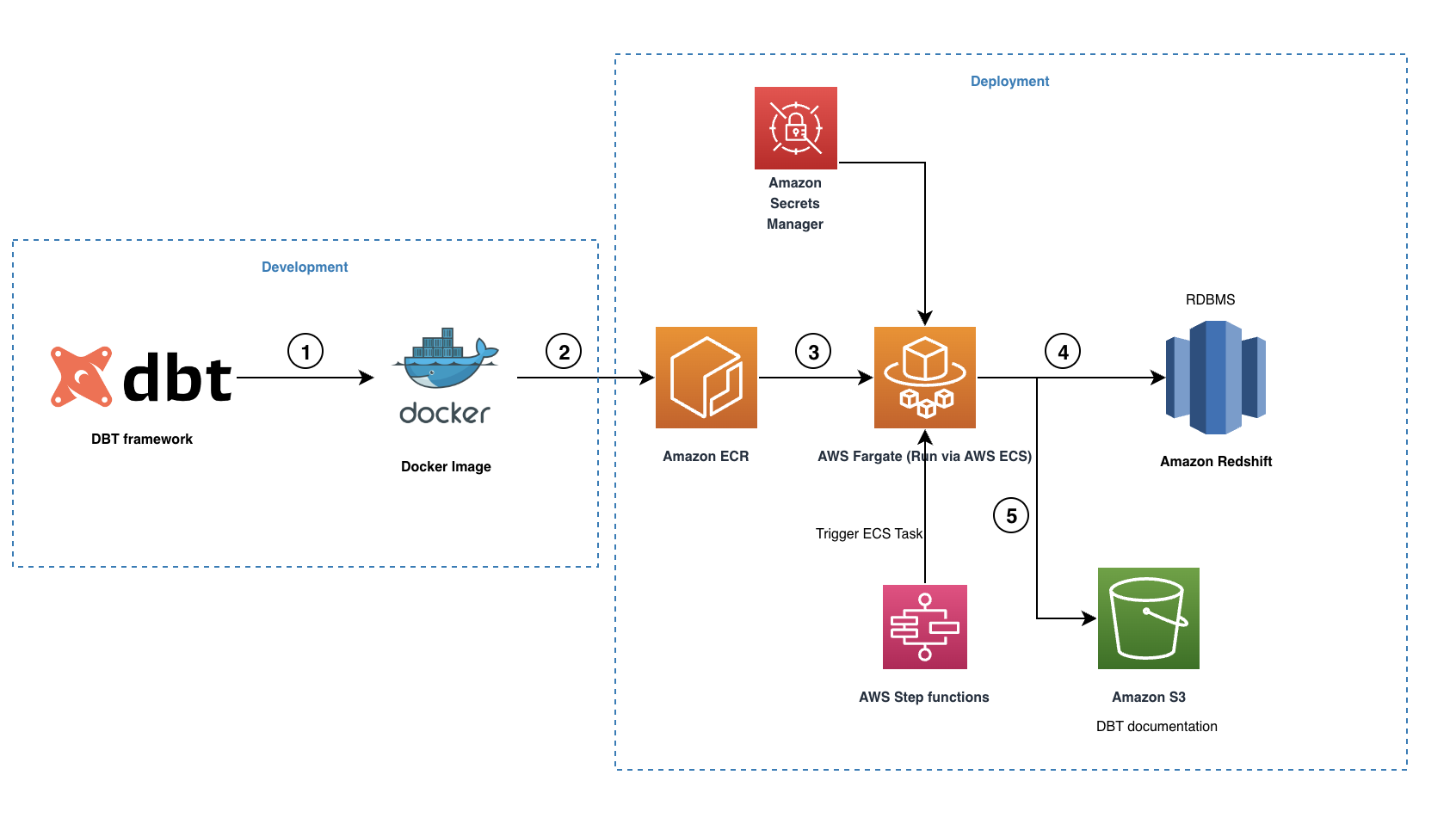
Il flusso di lavoro contiene i seguenti passaggi:
- Il connettore open source dbt-redshift viene utilizzato per creare il nostro progetto dbt inclusi tutti i modelli, le istantanee, i test, le macro e i profili necessari.
- Un'immagine Docker viene creata e inviata al repository ECR.
- L'immagine Docker viene eseguita da Fargate come attività ECS attivata tramite Funzioni AWS Step. Tutte le credenziali di Amazon Redshift vengono archiviate in Secrets Manager, che viene quindi utilizzato dall'attività ECS per connettersi con Amazon Redshift.
- Durante l'esecuzione, dbt converte tutti i modelli, gli snapshot, i test e le macro in istruzioni SQL conformi ad Amazon Redshift e orchestra l'esecuzione in base al processo interno grafico della derivazione dei dati mantenuto. Questi comandi SQL vengono eseguiti direttamente sul cluster Redshift e pertanto il carico di lavoro viene inviato direttamente a Amazon Redshift.
- Una volta completata l'esecuzione, dbt creerà un set di file HTML e JSON per ospitare il file documentazione dbt, che descrive il catalogo dei dati, le istruzioni SQL compilate, il grafico della derivazione dei dati e altro ancora.
Prerequisiti
Dovresti avere i seguenti prerequisiti:
- Una buona comprensione dei principi del dbt e delle fasi di implementazione.
- Un account AWS con autorizzazione del ruolo utente per accedere ai servizi AWS utilizzati in questa soluzione.
- Gruppi di sicurezza per Fargate per accedere al cluster Redshift e Secrets Manager da Amazon ECS.
- Un ammasso Redshift. Per le istruzioni sulla creazione, fare riferimento a Crea un cluster.
- Un archivio ECR: Per istruzioni, fare riferimento a Creazione di un repository privato
- Un manager dei segreti segreto contenente tutte le credenziali per la connessione ad Amazon Redshift. Ciò include l'host, la porta, il nome del database, il nome utente e la password. Per ulteriori informazioni, fare riferimento a Crea un segreto del database AWS Secrets Manager.
- An Archiviazione semplice di Amazon (Amazon S3) per ospitare i file di documentazione.
Crea un progetto dbt
Stiamo utilizzando la CLI dbt in modo che tutti i comandi vengano eseguiti nella riga di comando. Pertanto, installa pip se non è già installato. Fare riferimento a installazione per maggiori informazioni.
Per creare un progetto dbt, completare i seguenti passaggi:
- Installa i pacchetti dbt dipendenti:
pip install dbt-redshift - Inizializza un progetto dbt utilizzando il file
dbt init <project_name>comando, che crea automaticamente tutte le cartelle dei modelli. - Aggiungi tutti gli artefatti DBT richiesti.
Fare riferimento a dbt-redshift-etlpattern repository che include un progetto dbt di riferimento. Per ulteriori informazioni sui progetti di costruzione, fare riferimento a Informazioni sui progetti dbt.
Nel progetto di riferimento abbiamo implementato le seguenti funzionalità:
- SCD di tipo 1 utilizzando modelli incrementali
- SCD di tipo 2 utilizzando le istantanee
- File di ricerca seed
- Macro per aggiungere codice riutilizzabile nel progetto
- Test per l'analisi dei dati in entrata
Lo script Python è preparato per recuperare le credenziali richieste da Secrets Manager per accedere ad Amazon Redshift. Fare riferimento al export_redshift_connection.py file.
- Prepara il file
run_dbt.shscript per eseguire la pipeline dbt in sequenza. Questo script viene inserito nella cartella principale del progetto dbt come mostrato nel repository di esempio.
- Crea un file Docker nella directory principale della cartella del progetto dbt. Questo passaggio crea l'immagine del progetto dbt da inviare al repository ECR.
Carica l'immagine su Amazon ECR ed eseguila come attività ECS
Per inviare l'immagine al repository ECR, completare i seguenti passaggi:
- Recupera un token di autenticazione e autentica il tuo client Docker nel tuo registro:
- Crea la tua immagine Docker utilizzando il seguente comando:
- Una volta completata la compilazione, tagga la tua immagine in modo da poterla inviare al repository:
- Esegui il comando seguente per inviare l'immagine al repository AWS appena creato:
- Nella console Amazon ECS, crea un cluster con Fargate come opzione di infrastruttura.
- Fornisci il tuo VPC e le sottoreti come richiesto.
- Dopo aver creato il cluster, crea un'attività ECS e assegna l'immagine dbt creata come famiglia di definizioni di attività.
- Nella sezione di rete, scegli il tuo VPC, le sottoreti e il gruppo di sicurezza per connetterti con Amazon Redshift, Amazon S3 e Secrets Manager.
Questa attività attiverà il run_dbt.sh script della pipeline ed eseguire tutti i comandi dbt in sequenza. Una volta completato lo script, possiamo vedere i risultati in Amazon Redshift e i file di documentazione inviati ad Amazon S3.
- Puoi ospitare la documentazione tramite l'hosting di siti Web statici Amazon S3. Per ulteriori informazioni, fare riferimento a Hosting di un sito Web statico utilizzando Amazon S3.
- Infine, puoi eseguire questa attività in Step Functions come attività ECS per pianificare i lavori come richiesto. Per ulteriori informazioni, fare riferimento a Gestisci le attività Amazon ECS o Fargate con le funzioni Step.
Il dbt-redshift-etlpattern il repository ora dispone di tutti gli esempi di codice richiesti.
Il costo per l'esecuzione di processi dbt in AWS Fargate come attività Amazon ECS con requisiti operativi minimi richiederebbe circa $ 1.5 (costo_link) al mese.
ripulire
Completa i seguenti passaggi per ripulire le tue risorse:
- Elimina il cluster ECS hai creato.
- Elimina l'archivio ECR creato per archiviare i file di immagine.
- Elimina il cluster Redshift hai creato.
- Elimina i segreti di Redshift archiviato in Secrets Manager.
Conclusione
Questo post ha trattato l'implementazione di base dell'utilizzo di dbt con Amazon Redshift in modo economicamente vantaggioso utilizzando Fargate in Amazon ECS. Abbiamo descritto l'infrastruttura chiave e la configurazione con un progetto di esempio. Questa architettura può aiutarti a sfruttare i vantaggi di avere un framework dbt per gestire la tua piattaforma di data warehouse in Amazon Redshift.
Per ulteriori informazioni sulle macro e sui modelli dbt per il funzionamento interno e la manutenzione di Amazon Redshift, consulta quanto segue Repository GitHub. Nel post successivo, esploreremo i tradizionali modelli di estrazione, trasformazione e caricamento (ETL) che puoi implementare utilizzando il framework dbt in Amazon Redshift. Prova questa soluzione nel tuo account e fornisci feedback o suggerimenti nei commenti.
Informazioni sugli autori
 Seshadri Senthamaraikannan è un architetto dei dati con il team dei servizi professionali AWS con sede a Londra, Regno Unito. Ha una grande esperienza e è specializzato nell'analisi dei dati e lavora con i clienti concentrandosi sulla creazione di soluzioni innovative e scalabili in AWS Cloud per raggiungere i loro obiettivi aziendali. Nel tempo libero ama stare con la famiglia e praticare sport.
Seshadri Senthamaraikannan è un architetto dei dati con il team dei servizi professionali AWS con sede a Londra, Regno Unito. Ha una grande esperienza e è specializzato nell'analisi dei dati e lavora con i clienti concentrandosi sulla creazione di soluzioni innovative e scalabili in AWS Cloud per raggiungere i loro obiettivi aziendali. Nel tempo libero ama stare con la famiglia e praticare sport.
 Maometto Hamdi è un Senior Big Data Architect presso AWS Professional Services con sede a Londra, Regno Unito. Ha oltre 15 anni di esperienza nell'architettura, nella guida e nella creazione di data warehouse e piattaforme Big Data. Aiuta i clienti a sviluppare soluzioni di big data e analisi per accelerare i risultati aziendali attraverso il percorso di adozione del cloud. Fuori dal lavoro, a Mohamed piace viaggiare, correre, nuotare e giocare a squash.
Maometto Hamdi è un Senior Big Data Architect presso AWS Professional Services con sede a Londra, Regno Unito. Ha oltre 15 anni di esperienza nell'architettura, nella guida e nella creazione di data warehouse e piattaforme Big Data. Aiuta i clienti a sviluppare soluzioni di big data e analisi per accelerare i risultati aziendali attraverso il percorso di adozione del cloud. Fuori dal lavoro, a Mohamed piace viaggiare, correre, nuotare e giocare a squash.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/implement-data-warehousing-solution-using-dbt-on-amazon-redshift/
- :ha
- :È
- :non
- $ SU
- 1
- 10
- 11
- 15 anni
- 15%
- 7
- 8
- 90
- 970
- a
- WRI
- accelerare
- accesso
- Accedendo
- Il mio account
- operanti in
- aggiungere
- l'aggiunta di
- Adozione
- Vantaggio
- Tutti
- consente
- già
- anche
- Amazon
- Amazon Web Services
- an
- .
- Analitico
- analitica
- l'analisi
- ed
- si applica
- architettura
- SONO
- in giro
- AS
- autenticare
- Autenticazione
- automaticamente
- AWS
- Servizi professionali AWS
- basato
- basic
- BE
- vantaggi
- fra
- Big
- Big Data
- costruire
- Costruzione
- costruisce
- affari
- by
- Materiale
- che
- casi
- catalogo
- Challenge
- Modifiche
- cambiando
- Scegli
- cavedano
- cliente
- Cloud
- adozione del cloud
- Cluster
- codice
- Commenti
- Uncommon
- compilato
- completamento di una
- complesso
- compiacente
- componenti
- Configurazione
- configurato
- Connettiti
- Collegamento
- veloce
- consolle
- Contenitore
- contiene
- testuali
- costo effettivo
- coperto
- creare
- creato
- crea
- creazione
- Credenziali
- costume
- Clienti
- GIORNO
- dati
- analisi dei dati
- Dati Analytics
- data warehouse
- data warehouse
- Banca Dati
- Predefinito
- definizione
- dipendente
- descritta
- Design
- Dev
- sviluppare
- sviluppatori
- diverso
- direttamente
- docker
- documentazione
- effettua
- durante
- ogni
- Abilita
- Ingegneria
- aziende
- Ambiente
- ambienti
- Etere (ETH)
- esecuzione
- esperienza
- esperto
- esplora
- esterno
- estratto
- estremamente
- fallisce
- famiglia
- Caratteristiche
- feedback
- Compila il
- File
- Trovate
- Focus
- messa a fuoco
- i seguenti
- segue
- Nel
- Contesto
- da
- pieno
- funzionale
- funzioni
- Generale
- generare
- Idiota
- Obiettivi
- buono
- grafico
- Gruppo
- Gruppo
- Avere
- avendo
- he
- Aiuto
- aiuta
- qui
- Alte prestazioni
- il suo
- host
- di hosting
- Come
- HTML
- HTTPS
- identificare
- if
- illustra
- Immagine
- immagini
- realizzare
- implementazione
- implementato
- importare
- importazione
- in
- In altre
- inclusi
- Compreso
- incorporando
- incrementale
- informazioni
- Infrastruttura
- creativi e originali
- install
- istruzioni
- Integrazione
- interno
- ai miglioramenti
- l'introduzione di
- IT
- Lavoro
- Offerte di lavoro
- viaggio
- json
- Le
- Le Lingue
- con i più recenti
- principale
- biblioteche
- piace
- piace
- linea
- caricare
- logica
- accesso
- Londra
- Guarda
- lotti
- macro
- mantenimento
- manutenzione
- make
- gestire
- direttore
- gestione
- massicciamente
- meccanismo
- Soddisfare
- minimo
- modello
- modelli
- modulo
- Mohamed
- Mese
- Scopri di più
- multiplo
- Nome
- Detto
- necessaria
- internazionale
- recentemente
- adesso
- of
- Offerte
- on
- aprire
- open source
- operazione
- operativa
- ottimale
- Opzione
- or
- orchestrazione
- Altro
- nostro
- risultati
- uscite
- al di fuori
- ancora
- panoramica
- Packages
- Parallel
- Passi
- Password
- modelli
- per
- autorizzazione
- pezzi
- conduttura
- posto
- piattaforma
- Piattaforme
- Platone
- Platone Data Intelligence
- PlatoneDati
- Giocare
- gioco
- Post
- preparazione
- preparato
- preparazione
- prerequisiti
- primario
- principi
- un bagno
- lavorazione
- professionale
- Profilo
- Profili
- Programmazione
- linguaggi di programmazione
- progetto
- progetti
- fornire
- fornisce
- Spingi
- spinto
- Python
- query
- riferimento
- riferimento
- registro
- deposito
- richiedere
- necessario
- Requisiti
- richiede
- Risorse
- REST
- Risultati
- riutilizzabile
- Ruolo
- radice
- RIGA
- Correre
- running
- salvato
- scalabile
- programma
- copione
- secondo
- segreti
- Sezione
- problemi di
- vedere
- seme
- semi
- anziano
- Sequenza
- servizio
- Servizi
- set
- regolazione
- dovrebbero
- mostrato
- Spettacoli
- Un'espansione
- Lentamente
- Istantanea
- So
- Software
- Ingegneria del software
- soluzione
- Soluzioni
- Fonte
- fonti
- specializzato
- Spendere
- Sports
- SQL
- dichiarazione
- dichiarazioni
- step
- Passi
- Tornare al suo account
- memorizzati
- sottoreti
- successivo
- tale
- nuoto
- tavolo
- TAG
- Fai
- preso
- Target
- Task
- task
- team
- dire
- modello
- test
- test
- che
- Il
- loro
- Li
- poi
- perciò
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- Attraverso
- tempo
- richiede tempo
- volte
- a
- token
- tradizionale
- Trasformare
- Trasformazione
- innescare
- innescato
- Digitare
- tipicamente
- Uk
- e una comprensione reciproca
- uso
- utilizzato
- Utente
- usa
- utilizzando
- utilità
- via
- Visualizza
- Magazzino
- Magazzinaggio
- Modo..
- we
- sito web
- servizi web
- Sito web
- WELL
- quando
- quale
- while
- wikipedia
- volere
- con
- entro
- Lavora
- flusso di lavoro
- lavori
- sarebbe
- scritto
- anni
- Tu
- Trasferimento da aeroporto a Sharm
- te stesso
- zefiro