SmugMug gestisce due piattaforme fotografiche online molto grandi, SmugMug ed Flickr, consentendo a oltre 100 milioni di clienti di archiviare, cercare, condividere e vendere in modo sicuro decine di miliardi di foto. I clienti che caricano ed effettuano ricerche attraverso decenni di foto hanno contribuito a trasformare la ricerca in un'infrastruttura critica, in costante crescita da quando SmugMug ha utilizzato per la prima volta Amazon CloudSearch in 2012, seguito da Servizio Amazon OpenSearch dal 2018, dopo aver raggiunto miliardi di documenti e terabyte di spazio di archiviazione per le ricerche.
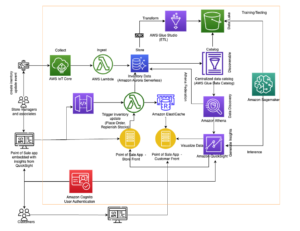
Qui, Lee Shepherd, ingegnere dello staff di SmugMug, condivide l'architettura di ricerca di SmugMug utilizzata per pubblicare, eseguire il backfill e rispecchiare il traffico in tempo reale su più cluster. SmugMug utilizza queste pipeline per confrontare, convalidare e migrare a nuove configurazioni, comprese le istanze r6gd.2xlarge basate su Graviton da i3.2xlarge, insieme ai test Amazon OpenSearch senza server. Copriremo tre pipeline utilizzate per la pubblicazione, il backfill e l'esecuzione di query senza introdurre modelli di traffico irrealistici e spinosi e senza alcun impatto sui servizi di produzione.
Ci sono due principali elementi architettonici critici per il processo:
- Una fonte di verità duratura per i dati dell'indice. È la migliore pratica e parte della nostra strategia di backup per avere un archivio durevole oltre l'indice OpenSearch e Amazon DynamoDB fornisce scalabilità e integrazione con AWS Lambda questo semplifica molto il processo. Utilizziamo DynamoDB per altri servizi non di ricerca, quindi è stata una scelta naturale.
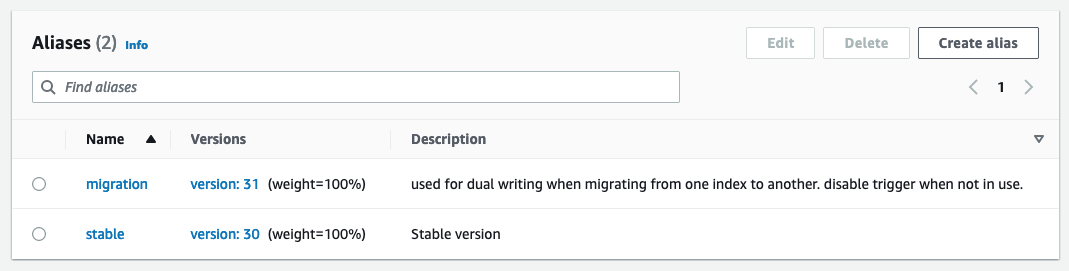
- Una funzione Lambda per pubblicare dati dalla fonte della verità in OpenSearch. Utilizzando alias di funzione aiuta a eseguire più configurazioni della stessa funzione Lambda contemporaneamente ed è fondamentale per mantenere i dati sincronizzati.
editoriale
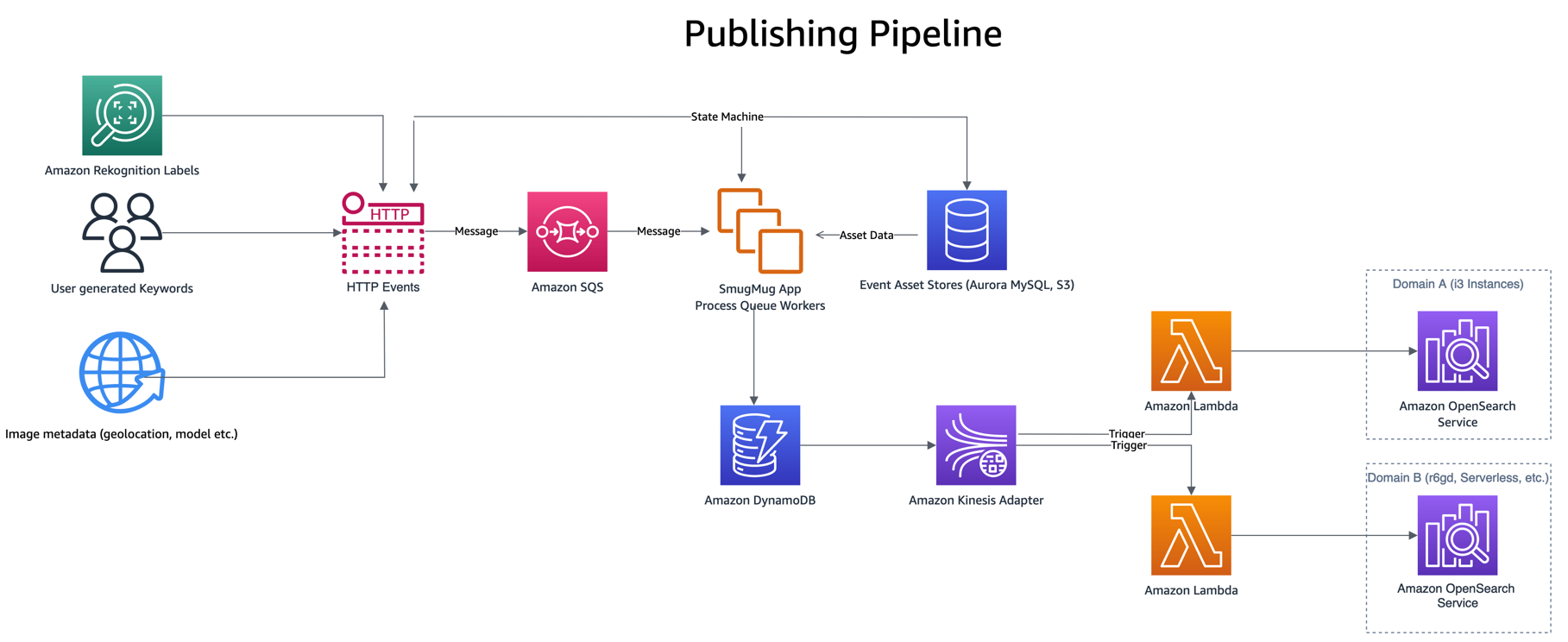
La pipeline di pubblicazione è guidata da eventi come l'inserimento di parole chiave o didascalie da parte di un utente, nuovi caricamenti o rilevamento di etichette Rekognition di Amazon. Questi eventi vengono elaborati, combinando i dati di alcuni altri archivi di risorse come Edizione compatibile con Amazon Aurora MySQL ed Servizio di archiviazione semplice Amazon (Amazon S3), prima di scrivere un singolo elemento in DynamoDB.
La scrittura su DynamoDB richiama una funzione di pubblicazione Lambda, tramite il file Adattatore Kinesis per flussi DynamoDB, che prende un batch di elementi aggiornati da DynamoDB e li indicizza in OpenSearch. L'utilizzo dell'adattatore Kinesis DynamoDB Streams presenta altri vantaggi, ad esempio la riduzione del numero di Lambda simultanei richiesti.
La funzione Lambda di pubblicazione utilizza variabili di ambiente per determinare in quale dominio e indice OpenSearch pubblicare. Un alias di produzione è configurato per scrivere nel dominio OpenSearch di produzione, al di fuori della tabella DynamoDB o Kinesis Stream
Durante il test di nuove configurazioni o la migrazione, un alias di migrazione viene configurato per scrivere nel nuovo dominio OpenSearch ma utilizza lo stesso trigger dell'alias di produzione. Ciò consente la doppia indicizzazione dei dati su entrambi i domini del servizio OpenSearch contemporaneamente.
Ecco un esempio dello schema della tabella DynamoDB:
Il valore "LastUpdated" viene utilizzato come versione del documento durante l'indicizzazione, consentendo a OpenSearch di rifiutare eventuali aggiornamenti non ordinati.
riempimento
Ora che le modifiche vengono pubblicate su entrambi i domini, il nuovo dominio (indice) deve essere riempito con dati storici. Per riempire un indice appena creato, una combinazione di Servizio Amazon Simple Queue (Amazon SQS) e viene utilizzato DynamoDB. Uno script popola una coda SQS con messaggi che contengono istruzioni per scansione parallela un segmento della tabella DynamoDB.
La coda SQS avvia una funzione Lambda che legge le istruzioni del messaggio, recupera un batch di elementi dal segmento corrispondente della tabella DynamoDB e li scrive in un indice OpenSearch. I nuovi messaggi vengono scritti nella coda SQS per tenere traccia dell'avanzamento nel segmento. Una volta completato il segmento, non vengono più scritti messaggi nella coda SQS e il processo si interrompe automaticamente.
La concorrenza è determinata dal numero di segmenti, con controlli aggiuntivi forniti dal dimensionamento della concorrenza Lambda. SmugMug è in grado di indicizzare più di 1 miliardo di documenti all'ora sulla propria configurazione OpenSearch senza alcun impatto sul dominio di produzione.
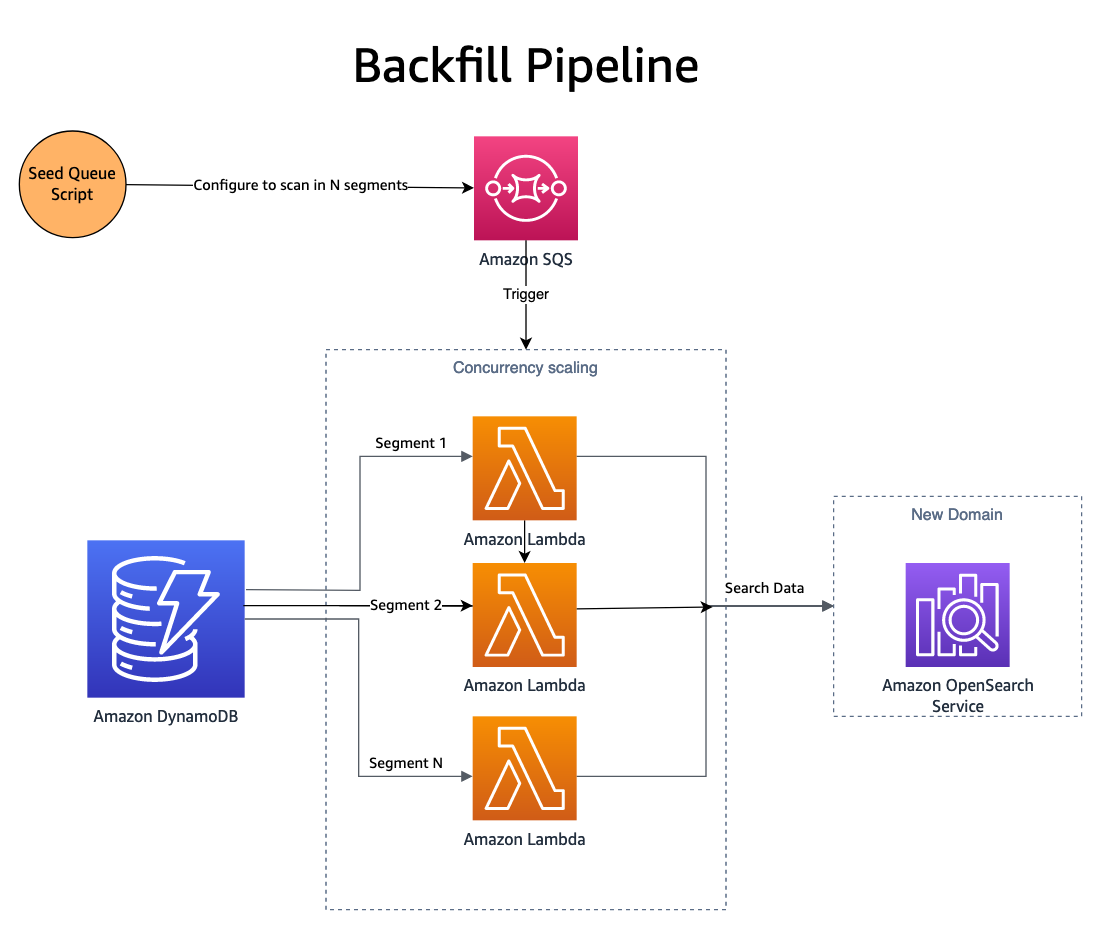
Per seminare la coda SQS viene utilizzato uno script basato su AWS-SDK di NodeJS. Ecco uno snippet delle opzioni dello script di configurazione SQS:
Insieme al formato del messaggio SQS risultante:
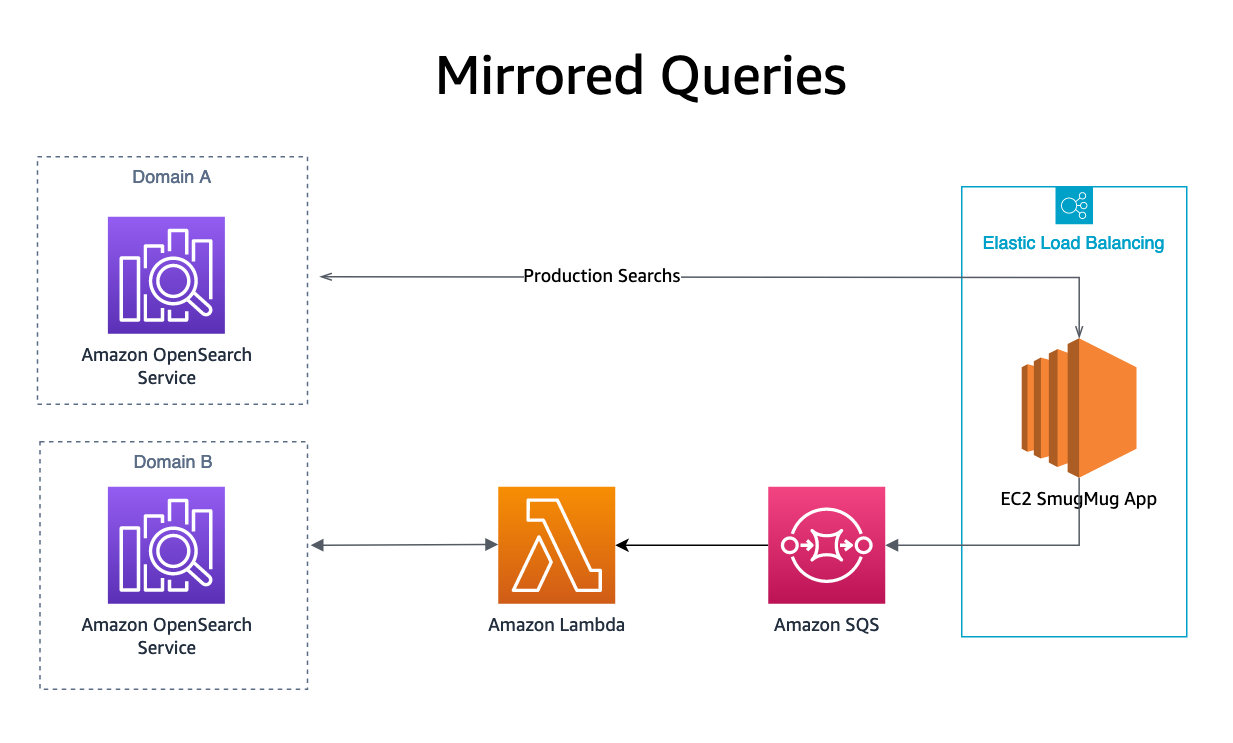
Mirroring
Ultimo, il nostro query di ricerca con mirroring i risultati vengono eseguiti inviando una query OpenSearch a una coda SQS, oltre al nostro dominio di produzione. La coda SQS avvia una funzione Lambda che riproduce la query sul dominio di replica. I risultati della ricerca di queste richieste non vengono inviati a nessun utente ma consentono di replicare il carico di produzione sul servizio OpenSearch in prova senza impatto sui sistemi di produzione o sui clienti.
Conclusione
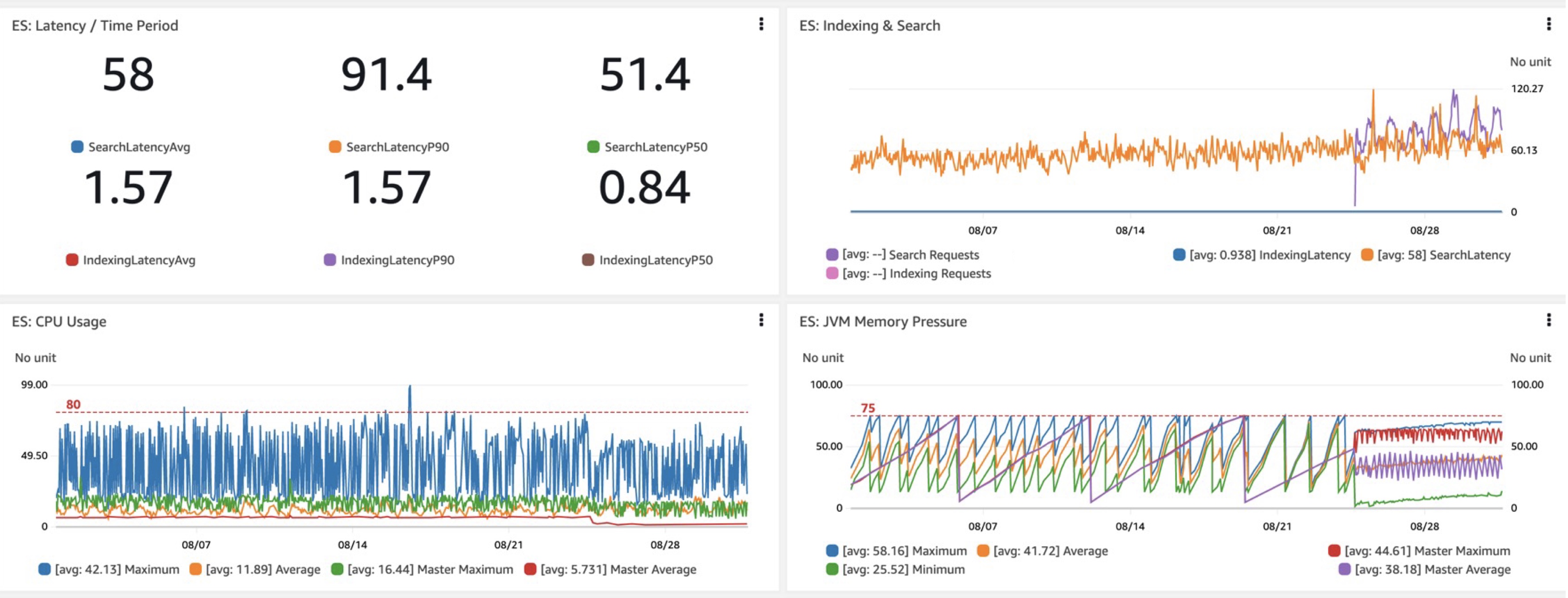
Quando valutiamo un nuovo dominio o configurazione OpenSearch, i parametri principali che ci interessano sono le prestazioni di latenza delle query, vale a dire le latenze impiegate (latenze per tempo) e, soprattutto, le latenze per la ricerca. Nel nostro passaggio a Graviton R6gd, abbiamo riscontrato latenze P40-P50 inferiori di circa il 99%, insieme a guadagni simili nell'utilizzo della CPU rispetto a i3 (ignorando i costi inferiori di Graviton). Un altro vantaggio positivo è stata la pressione della memoria JVM più prevedibile e monitorabile con le modifiche alla garbage collection derivanti dall'aggiunta di G1GC su R6gd e altre nuove istanze.
Utilizzando questa pipeline, stiamo anche testando OpenSearch Serverless e individuando i suoi migliori casi d'uso. Siamo entusiasti di questo servizio e intendiamo pienamente avere in tempo un'architettura interamente serverless. Resta sintonizzato per i risultati.
Informazioni sugli autori
Lee Pastore è un ingegnere software del personale SmugMug
Aydn Bekirov è un responsabile dell'account tecnico principale di Amazon Web Services
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/smugmugs-durable-search-pipelines-for-amazon-opensearch-service/
- :È
- :non
- 1
- 100
- 12
- 14
- 20
- 2012
- 2018
- 40
- 7
- 9
- a
- capace
- WRI
- Il mio account
- aggiunto
- aggiunta
- aggiuntivo
- Dopo shavasana, sedersi in silenzio; saluti;
- consentire
- Consentire
- lungo
- anche
- Amazon
- Amazon Web Services
- an
- ed
- Un altro
- in qualsiasi
- architettonico
- architettura
- SONO
- AS
- attività
- At
- Aurora
- AWS
- di riserva
- basato
- BE
- prima
- essendo
- Segno di riferimento
- beneficio
- vantaggi
- MIGLIORE
- Al di là di
- Miliardo
- miliardi
- entrambi
- ma
- by
- didascalie
- Modifiche
- collezione
- combinazione
- combinando
- rispetto
- compatibile
- Completa
- concorrente
- Configurazione
- configurato
- contenere
- controlli
- Corrispondente
- Costi
- coprire
- CPU
- creato
- critico
- Infrastruttura critica
- Clienti
- dati
- decenni
- rivelazione
- Determinare
- determinato
- documento
- documenti
- dominio
- domini
- spinto
- ogni
- Abilita
- consentendo
- endpoint
- ingegnere
- entrare
- interamente
- Ambiente
- Etere (ETH)
- la valutazione
- eventi
- esempio
- eccitato
- pochi
- campi
- ricerca
- Nome
- in forma
- seguito
- Nel
- formato
- da
- completamente
- function
- Guadagni
- Crescita
- Avere
- altezza
- aiutato
- aiuta
- storico
- ora
- HTML
- http
- HTTPS
- i
- i3
- ID
- Impact
- importante
- in
- Compreso
- Index
- indici
- Infrastruttura
- istanze
- istruzioni
- integrazione
- intendono
- interessato
- ai miglioramenti
- l'introduzione di
- invoca
- elementi
- iterazione
- SUO
- stessa
- jpg
- mantenere
- conservazione
- Le
- parole chiave
- Discografica
- grandi
- Latenza
- lancia
- sottovento
- piace
- vivere
- caricare
- lotto
- inferiore
- Principale
- Memorie
- messaggio
- messaggi
- Metrica
- migrare
- la migrazione
- migrazione
- milione
- milioni di clienti
- specchio
- Scopri di più
- maggior parte
- cambiano
- multiplo
- MySQL
- Nome
- cioè
- Naturale
- esigenze
- New
- recentemente
- GENERAZIONE
- no
- numero
- of
- MENO
- on
- online
- opera
- Opzioni
- Opz
- or
- Altro
- nostro
- Parallel
- parte
- modelli
- per
- per cento
- performance
- foto
- Foto
- pezzi
- conduttura
- Piattaforme
- Platone
- Platone Data Intelligence
- PlatoneDati
- Prevedibile
- pressione
- precedente
- Direttore
- processi
- elaborati
- Produzione
- Progressi
- purché
- fornisce
- pubblicare
- pubblicato
- editoriale
- raggiungendo
- riducendo
- replica
- richieste
- necessario
- risultante
- Risultati
- Correre
- tranquillamente
- stesso
- sega
- Scalabilità
- scala
- copione
- Cerca
- ricerca
- seme
- segmento
- segmenti
- venda
- invio
- inviato
- serverless
- servizio
- Servizi
- Condividi
- azioni
- simile
- Un'espansione
- contemporaneamente
- da
- singolo
- frammento
- So
- Software
- Fonte
- STAFF
- soggiorno
- costantemente
- Interrompe
- conservazione
- Tornare al suo account
- negozi
- Strategia
- flussi
- tale
- SISTEMI DI TRATTAMENTO
- tavolo
- prende
- Consulenza
- decine
- test
- Testing
- di
- che
- Il
- L’ORIGINE
- loro
- Li
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- questo
- tre
- Attraverso
- tempo
- a
- ha preso
- pista
- traffico
- innescare
- Verità
- TURNO
- seconda
- per
- aggiornato
- Aggiornamenti
- Caricamento
- URL
- Impiego
- uso
- casi d'uso
- utilizzato
- Utente
- usa
- utilizzando
- CONVALIDARE
- APPREZZIAMO
- versione
- molto
- Prima
- we
- sito web
- servizi web
- il benvenuto
- Che
- quando
- while
- con
- senza
- scrivere
- scrittura
- scritto
- zefiro
- zero