Mentre OpenAI ChatGPT sta risucchiando tutto l'ossigeno dal ciclo di notizie di 24 ore, Google ha svelato silenziosamente un nuovo modello di intelligenza artificiale in grado di generare video quando vengono forniti input di video, immagini e testo. Il nuovo editor video AI di Google Dreamix ora avvicina i video generati alla realtà.
Secondo la ricerca pubblicata su GitHub, Dreamix modifica il video sulla base di un video e di un prompt di testo. Il video risultante mantiene la sua fedeltà al colore, alla postura, alle dimensioni dell'oggetto e alla posa della telecamera, risultando in un video coerente dal punto di vista temporale. Al momento, Dreamix non può generare video da un semplice prompt, tuttavia, può prendere materiale esistente e modificare il video utilizzando prompt di testo.
Google utilizza modelli di diffusione video per Dreamix, un approccio che è stato applicato con successo per la maggior parte dell'editing di immagini video che vediamo in AI di immagini come DALL-E2 o Stable Diffusion open source.
L'approccio prevede la riduzione pesante del video di input, l'aggiunta di rumore artificiale e quindi l'elaborazione in un modello di diffusione video, che quindi utilizza un prompt di testo per generare un nuovo video da esso che conserva alcune proprietà del video originale e ne riproduce altre in base all'inserimento del testo.
Il modello di diffusione video offre un futuro promettente che potrebbe inaugurare una nuova era per lavorare con i video.

Ad esempio, nel video qui sotto, Dreamix trasforma la scimmia mangiatrice (a sinistra) in un orso danzante (a destra) dato il suggerimento "Un orso che balla e salta al ritmo di musica allegra, muovendo tutto il suo corpo".
In un altro esempio di seguito, Dreamix utilizza una singola foto come modello (come in image-to-video) e un oggetto viene quindi animato da essa in un video tramite un prompt. I movimenti della telecamera sono possibili anche nella nuova scena o in una successiva registrazione time-lapse.
In un altro esempio, Dreamix trasforma l'orango in una pozza d'acqua (a sinistra) in un orango con i capelli arancioni che fa il bagno in un bellissimo bagno.
“Mentre i modelli di diffusione sono stati applicati con successo per l'editing delle immagini, pochissimi lavori lo hanno fatto per l'editing video. Presentiamo il primo metodo basato sulla diffusione in grado di eseguire il movimento basato sul testo e l'editing dell'aspetto di video generici".
Secondo il documento di ricerca di Google, Dreamix utilizza un modello di diffusione video per combinare, al momento dell'inferenza, le informazioni spaziotemporali a bassa risoluzione del video originale con nuove informazioni ad alta risoluzione che ha sintetizzato per allinearsi con il prompt del testo guida.
Google ha affermato di aver adottato questo approccio perché "per ottenere un'alta fedeltà al video originale è necessario conservare alcune delle sue informazioni ad alta risoluzione, aggiungiamo una fase preliminare di messa a punto del modello sul video originale, aumentando notevolmente la fedeltà".
Di seguito è riportata una panoramica video di come funziona Dreamix.
[Contenuto incorporato]
Come funzionano i modelli di diffusione video di Dreamix
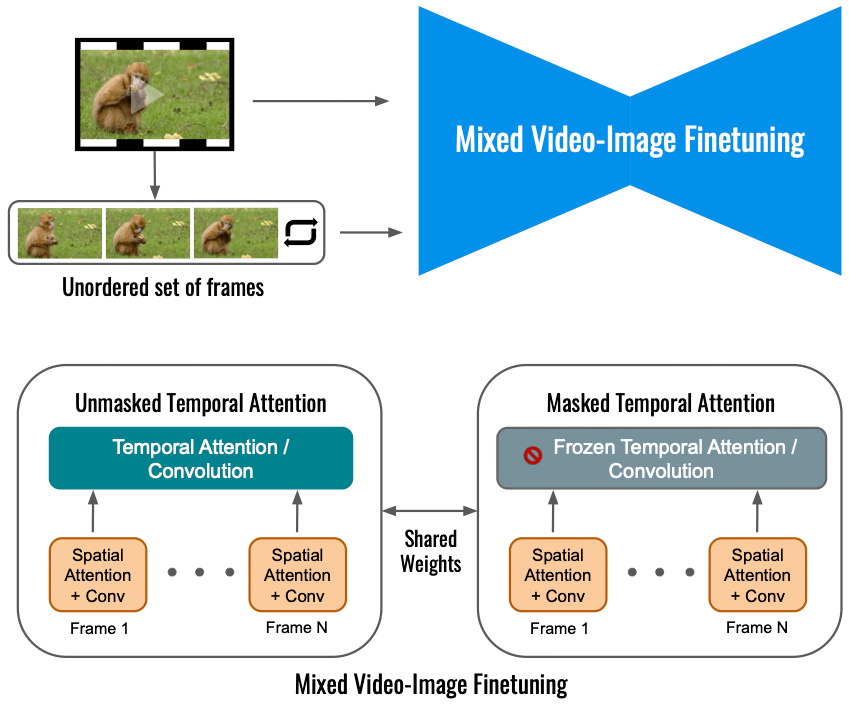
Secondo Google, la messa a punto del modello di diffusione video per Dreamix sul solo video in ingresso limita l'entità del cambiamento di movimento. Usiamo invece un obiettivo misto che oltre all'obiettivo originale (in basso a sinistra) si adatta anche all'insieme non ordinato di fotogrammi. Questo viene fatto usando "l'attenzione temporale mascherata", impedendo la messa a punto dell'attenzione temporale e della convoluzione (in basso a destra). Ciò consente di aggiungere movimento a un video statico.
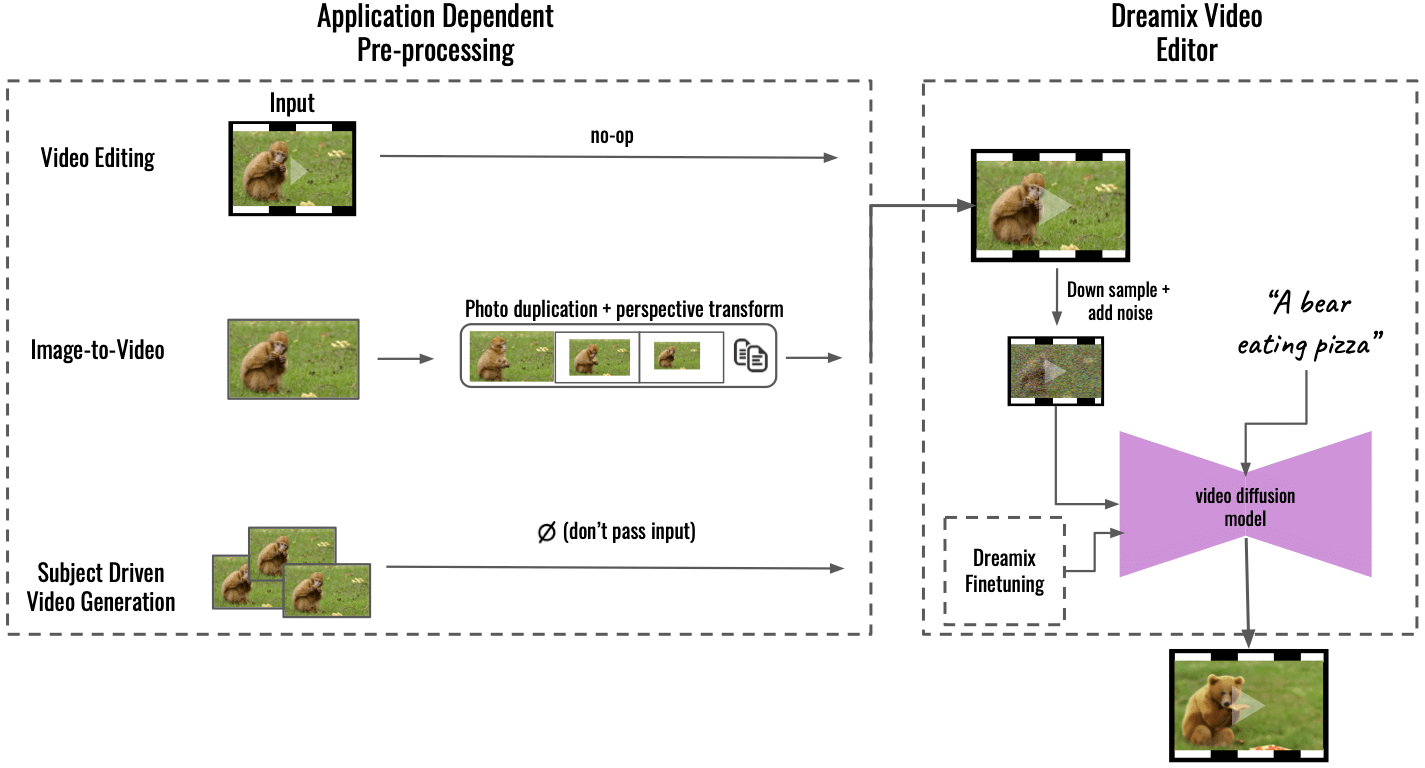
“Il nostro metodo supporta più applicazioni mediante pre-elaborazione dipendente dall'applicazione (a sinistra), convertendo il contenuto di input in un formato video uniforme. Per l'immagine in video, l'immagine di input viene duplicata e trasformata utilizzando trasformazioni prospettiche, sintetizzando un video grossolano con un movimento della telecamera. Per la generazione di video basata sul soggetto, l'input viene omesso: la sola messa a punto si occupa della fedeltà. Questo video grossolano viene quindi modificato utilizzando il nostro "Dreamix Video Editor" generale (a destra): prima corrompiamo il video mediante il downsampling seguito dall'aggiunta di rumore. Quindi applichiamo il modello di diffusione video guidato da testo ottimizzato, che ingrandisce il video fino alla risoluzione spaziotemporale finale ", ha scritto Dream su GitHub.
Puoi leggere il documento di ricerca qui sotto.
Google Dreamix- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://techstartups.com/2023/02/10/google-launches-ai-powered-video-editor-dreamix-to-create-edit-videos-and-animate-images/
- a
- capace
- Secondo
- AI
- ah video
- AI-alimentato
- Tutti
- consente
- da solo
- ed
- Un altro
- applicazioni
- applicato
- APPLICA
- approccio
- artificiale
- attenzione
- basato
- Orso
- bellissimo
- perché
- essendo
- sotto
- stile di vita
- potenziamento
- Parte inferiore
- Porta
- stanza
- non può
- che
- il cambiamento
- ChatGPT
- più vicino
- colore
- combinare
- coerente
- contenuto
- Creazione
- ciclo
- Danza
- Emittente
- hotel
- editore
- incorporato
- epoca
- esempio
- esistente
- pochi
- fedeltà
- finale
- Nome
- seguito
- formato
- da
- futuro
- Generale
- generare
- generato
- ELETTRICA
- gif
- GitHub
- dato
- Capelli
- pesantemente
- ad alta risoluzione
- Come
- Tuttavia
- HTTPS
- Immagine
- immagini
- in
- informazioni
- ingresso
- invece
- IT
- lancia
- limiti
- mantiene
- materiale
- max
- metodo
- misto
- modello
- modelli
- modificare
- momento
- maggior parte
- movimento
- movimenti
- in movimento
- multiplo
- Musica
- New
- notizie
- Rumore
- oggetto
- obiettivo
- Offerte
- open source
- OpenAI
- Arancio
- i
- Altri
- panoramica
- Oxygen
- Carta
- eseguire
- prospettiva
- Platone
- Platone Data Intelligence
- PlatoneDati
- pool
- possibile
- presenti
- prevenzione
- lavorazione
- promettente
- proprietà
- pubblicato
- tranquillamente
- Leggi
- Realtà
- registrazione
- riducendo
- richiede
- riparazioni
- Risoluzione
- risultante
- di ritegno
- Suddetto
- scena
- set
- significativamente
- singolo
- Taglia
- So
- alcuni
- stabile
- Stage
- successivo
- Con successo
- tale
- supporti
- Fai
- modello
- I
- tempo
- a
- trasformazioni
- trasformato
- svelato
- uso
- via
- Video
- Video
- Water
- quale
- lavoro
- lavori
- youtube
- zefiro











