Amazon EMR è lieta di annunciare l'integrazione con Amazon Simple Storage Service (Amazon S3) Access Grants che semplifica la gestione delle autorizzazioni di Amazon S3 e consente di imporre un accesso granulare su larga scala. Con questa integrazione, puoi scalare l'accesso Amazon S3 basato sui lavori per i lavori Apache Spark in tutte le opzioni di distribuzione Amazon EMR e applicare l'accesso granulare ad Amazon S3 per una migliore strategia di sicurezza.
In questo post, esamineremo alcuni scenari diversi su come utilizzare le concessioni di accesso di Amazon S3. Prima di iniziare a esaminare l'integrazione di Amazon EMR e Amazon S3 Access Grants, imposteremo e configureremo S3 Access Grants. Quindi utilizzeremo il file AWS CloudFormazione modello seguente per creare un Amazon EMR su Amazon Elastic Compute Cloud (Amazon EC2) Cluster, un'applicazione EMR Serverless e due diversi ruoli lavorativi.
Dopo la configurazione, eseguiremo alcuni scenari su come utilizzare Amazon EMR con S3 Access Grants. Innanzitutto, eseguiremo un lavoro batch su EMR su Amazon EC2 per importare dati CSV e convertirli in Parquet. In secondo luogo, utilizzeremo Amazon EMR Studio con un'applicazione interattiva EMR Serverless per analizzare i dati. Infine, mostreremo come configurare l'accesso tra più account per le concessioni di accesso Amazon S3. Molti clienti utilizzano account diversi all'interno dell'organizzazione e anche all'esterno dell'organizzazione per condividere i dati. Le concessioni di accesso di Amazon S3 semplificano la concessione dell'accesso multiaccount ai dati anche quando si filtra in base a prefissi diversi.
Oltre a questo post, puoi trovare ulteriori informazioni sulle concessioni di accesso Amazon S3 da Scalabilità dell'accesso ai dati con le concessioni di accesso di Amazon S3.
Prerequisiti
Prima di avviare lo stack AWS CloudFormation, assicurati di disporre di quanto segue:
- Un account AWS che fornisce l'accesso ai servizi AWS
- La versione più recente dell'interfaccia a riga di comando di AWS (CLI AWS)
- Un AWS Identity and Access Management (AWS IAM) utente con una chiave di accesso e una chiave segreta per configurare AWS CLI e autorizzazioni per creare un ruolo IAM, policy IAM e stack in AWS CloudFormation
- Un secondo account AWS se desideri testare la funzionalità su più account
Soluzione
Crea risorse con AWS CloudFormation
Per utilizzare Amazon S3 Access Grants, avrai bisogno di un cluster con Amazon EMR 6.15.0 o versione successiva. Per ulteriori informazioni, consulta la documentazione per l'utilizzo delle concessioni di accesso Amazon S3 con un file Cluster Amazon EMR, una Amazon EMR sul cluster EKS, E un Applicazione serverless Amazon EMR. Ai fini di questo post, presupporremo che nella tua organizzazione siano presenti due diversi tipi di utenti con accesso ai dati: ingegneri analitici con accesso in lettura e scrittura ai dati nel bucket e analisti aziendali con accesso in sola lettura. Utilizzeremo due diversi ruoli AWS IAM, ma puoi anche connettere il tuo provider di identità direttamente a IAM Identity Center, se lo desideri.
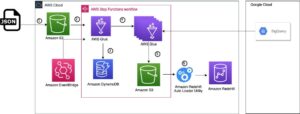
Ecco l’architettura per questa prima parte. Lo stack AWS CloudFormation crea le seguenti risorse AWS:
- Uno stack VPC (Virtual Private Cloud) con sottoreti private e pubbliche da utilizzare con EMR Studio, tabelle di routing e gateway NAT (Network Address Translation).
- Un bucket Amazon S3 per artefatti EMR come file di log, codice Spark e notebook Jupyter.
- Un bucket Amazon S3 con dati di esempio da utilizzare con S3 Access Grants.
- Un cluster Amazon EMR configurato per l'uso ruoli di esecuzione e concessioni di accesso S3.
- Un'applicazione serverless Amazon EMR configurata per utilizzare le concessioni di accesso S3.
- Un Amazon EMR Studio in cui gli utenti possono accedere e creare notebook dell'area di lavoro con l'applicazione EMR Serverless.
- Utilizzeremo due ruoli AWS IAM per le nostre esecuzioni di processi EMR: uno per Amazon EC2 con accesso in scrittura e un altro per Serverless con accesso in lettura.
- Un ruolo AWS IAM che verrà utilizzato da S3 Access Grants per accedere ai dati del bucket (ovvero, il ruolo da utilizzare quando si registra una posizione con S3 Access Grants. S3 Access Grants utilizza questo ruolo per creare credenziali temporanee).
Per iniziare, completare i seguenti passi:
- Scegli Avvia pila:

- Accettare le impostazioni predefinite e selezionare Riconosco che questo modello può creare risorse IAM.
Il completamento dello stack AWS CloudFormation richiede circa 10-15 minuti. Una volta terminato lo stack, vai alla scheda uscite dove troverai le informazioni necessarie per i passaggi successivi.
Creare risorse di concessione di accesso Amazon S3
Innanzitutto, creeremo una risorsa Amazon S3 Access Grants nel nostro account. Creiamo un'istanza S3 Access Grants, una posizione S3 Access Grants che fa riferimento al nostro bucket di dati creato dallo stack AWS CloudFormation accessibile solo dal nostro ruolo AWS IAM del bucket di dati e garantiamo diversi livelli di accesso ai nostri ruoli di lettore e scrittore.

Per creare le risorse S3 Access Grants necessarie, utilizza i seguenti comandi AWS CLI come utente amministrativo e sostituisci qualsiasi campo tra le frecce con l'output dello stack CloudFormation.
Successivamente, creiamo una nuova posizione per le autorizzazioni di accesso S3. Cos'è una posizione? Amazon S3 Access Grants funziona vendendo credenziali AWS IAM con accesso limitato a un particolare prefisso S3. Una posizione S3 Access Grants verrà associata a un ruolo AWS IAM da cui verranno create queste sessioni temporanee.
Nel nostro caso, estenderemo il ruolo AWS IAM al bucket creato con il nostro stack AWS CloudFormation e daremo accesso al ruolo del bucket dati creato dallo stack. Vai alla scheda output per trovare i valori da sostituire con il seguente snippet di codice:
Notare la AccessGrantsLocationId valore nella risposta. Ne avremo bisogno per i passaggi successivi in cui analizzeremo la creazione delle autorizzazioni di accesso S3 necessarie per limitare l'accesso in lettura e scrittura al tuo bucket.
- Per l'utente di lettura/scrittura, utilizzare
s3-control create-access-grantper consentire l'accesso READWRITE al prefisso "output/*": - Per l'utente di lettura, utilizzare
s3control create-access-grantdi nuovo per consentire solo l'accesso in lettura allo stesso prefisso:
Scenario demo 1: Amazon EMR su EC2 Spark Job per generare dati Parquet
Ora che abbiamo configurato i nostri ambienti Amazon EMR e concesso l'accesso ai nostri ruoli tramite S3 Access Grants, è importante notare che i due ruoli AWS IAM per il nostro cluster EMR e l'applicazione EMR Serverless hanno una policy IAM che consente solo l'accesso a il nostro secchio di artefatti EMR. Non hanno accesso IAM al nostro bucket di dati S3 e utilizzano invece le autorizzazioni di accesso S3 per recuperare credenziali di breve durata nell'ambito del bucket e del prefisso. Nello specifico vengono concessi i ruoli s3:GetDataAccess e s3:GetDataAccessGrantsInstanceForPrefix autorizzazioni per richiedere l'accesso tramite la specifica istanza S3 Access Grants creata nella nostra regione. Ciò ti consente di gestire facilmente l'accesso a S3 in un unico posto in modo altamente mirato e granulare che migliora la tua strategia di sicurezza. Combinando S3 Access Grants con ruoli lavorativi su EMR su Amazon Elastic Kubernetes Service (Amazon EX) ed EMR Serverless nonché ruoli runtime per le fasi di Amazon EMR a partire da EMR 6.7.0, puoi gestire facilmente il controllo degli accessi per singoli lavori o query. Le concessioni di accesso S3 sono disponibili su EMR 6.15.0 e versioni successive. Eseguiamo innanzitutto un lavoro Spark su EMR su EC2 come nostro ingegnere di analisi per convertire alcuni dati di esempio in Parquet.
A tale scopo, utilizzare il codice di esempio fornito in convertitore.py. Scarica il file e copialo nel file EMR_ARTIFACTS_BUCKET creato dallo stack AWS CloudFormation. Invieremo il nostro lavoro con il ruolo ReadWrite AWS IAM. Tieni presente che per il cluster EMR abbiamo configurato le autorizzazioni di accesso S3 per ricorrere al ruolo IAM se l'accesso non viene fornito dalle autorizzazioni di accesso S3. IL DATA_WRITER_ROLE ha accesso in lettura al bucket degli artefatti EMR tramite una policy IAM in modo da poter leggere il nostro script. Come prima, sostituisci tutti i valori con il <> simboli da Uscite scheda dello stack CloudFormation.
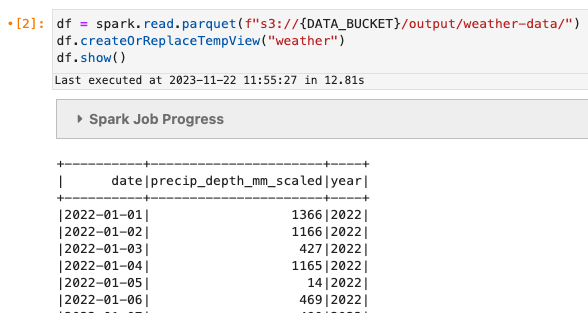
Una volta terminato il lavoro, dovremmo vedere alcuni dati del parquet s3://<DATA_BUCKET>/output/weather-data/. Puoi vedere lo stato del lavoro nel file Passi scheda del Consolle EMR.
Scenario demo 2: EMR Studio con un'applicazione interattiva EMR Serverless per analizzare i dati
Ora andiamo avanti e accediamo a EMR Studio e connettiamoci alla tua applicazione EMR Serverless con il ruolo runtime ReadOnly per analizzare i dati dello scenario 1. Per prima cosa dobbiamo abilitare l'endpoint interattivo sulla tua applicazione Serverless.
- Seleziona il EMRStudioURL nel Scheda Uscite del tuo stack AWS CloudFormation.
- Seleziona Applicazioni sotto il serverless sezione sul lato sinistro.

- Seleziona il EMRBlog applicazione, quindi il Action menu a discesa e Configurae.
- espandere la Endpoint interattivo sezione e assicurati che Abilita endpoint interattivo è controllato

- Scorri verso il basso e fai clic Configura applicazione per salvare le modifiche.
- Torna alla pagina Applicazioni, seleziona EMRBlog applicazione, quindi il Avvia l'applicazione pulsante.
Successivamente, crea un nuovo spazio di lavoro nel nostro Studio.
- Scegli Aree di lavoro sul lato sinistro, poi il Crea spazio di lavoro pulsante.
- Inserisci un nome per l'area di lavoro, lascia le restanti impostazioni predefinite e scegli Crea spazio di lavoro.
- Dopo aver creato l'area di lavoro, dovrebbe avviarsi in una nuova scheda in pochi secondi.
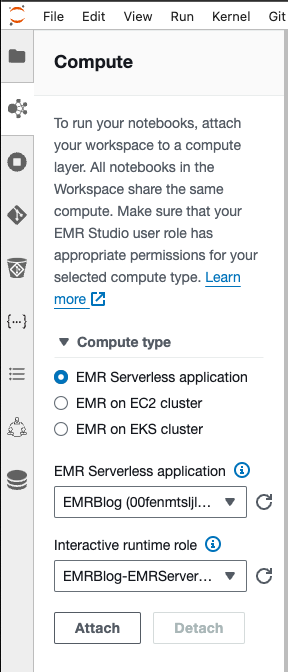
Ora collega il tuo Workspace alla tua applicazione EMR Serverless.
- Seleziona il Calcolo EMR pulsante sul lato sinistro come mostrato nel codice seguente.
- Scegli EMR senza server come tipo di calcolo.
- Scegliere il EMRBlog applicazione e il ruolo runtime che inizia con EMRBlog.
- Scegli allegare. La finestra si aggiornerà e potrai aprirne una nuova PySpark taccuino e segui di seguito. Per eseguire tu stesso il codice, scarica il file Taccuino AccessGrantsReadOnly.ipynb e caricalo nel tuo spazio di lavoro utilizzando il file Carica file pulsante nel browser dei file.
Facciamo una rapida lettura dei dati.
Faremo un semplice conteggio(*):

Puoi anche vedere che se proviamo a scrivere i dati nella posizione di output, otteniamo un errore Amazon S3.

Anche se puoi anche concedere un accesso simile tramite policy AWS IAM, Amazon S3 Access Grants può essere utile per situazioni in cui la tua organizzazione ha superato la gestione dell'accesso tramite IAM, desidera mappare S3 Access Grants a entità o ruoli IAM Identity Center o ha precedentemente utilizzato EMR Mapping dei ruoli del file system (EMRFS). Anche le credenziali S3 Access Grants sono temporanee e forniscono un accesso più sicuro ai tuoi dati. Inoltre, come mostrato di seguito, anche l'accesso tra account trae vantaggio dalla semplicità delle sovvenzioni di accesso S3.
Scenario demo 3 – Accesso tra più account
Uno degli altri modelli di accesso più comuni è l'accesso ai dati tra account. Questo modello è diventato sempre più comune con l’emergere del data mesh, in cui i produttori e i consumatori di dati sono decentralizzati su diversi account AWS.
In precedenza, l'accesso tra più account richiedeva la configurazione di più account complessi che assumevano azioni di ruolo e provider di credenziali personalizzate durante la configurazione del processo Spark. Con S3 Access Grants, dobbiamo solo fare quanto segue:
- Crea un ruolo lavorativo e un cluster Amazon EMR in un secondo account consumatore di dati
- L'account del produttore di dati concede l'accesso all'account del consumatore di dati con una nuova policy delle risorse dell'istanza
- L'account del produttore di dati crea una concessione di accesso per il ruolo lavorativo di consumatore di dati
E questo è tutto! Se hai un secondo account a portata di mano, vai avanti e distribuiscilo questo stack AWS CloudFormation nell'account del consumatore dati, per creare una nuova applicazione EMR Serverless e un nuovo ruolo lavorativo. In caso contrario, segui semplicemente di seguito. La creazione dello stack AWS CloudFormation dovrebbe terminare in meno di un minuto. Successivamente, andiamo avanti e concediamo al nostro consumatore di dati l'accesso all'istanza S3 Access Grants nel nostro account produttore di dati.
- sostituire
<DATA_PRODUCER_ACCOUNT_ID>ed<DATA_CONSUMER_ACCOUNT_ID>con i relativi ID account AWS a 12 cifre. - Potrebbe anche essere necessario modificare la regione nel comando e nella policy.
- Quindi concedi l'accesso in lettura alla cartella di output al nostro ruolo lavorativo EMR Serverless nell'account del consumatore di dati.
Ora che lo abbiamo fatto, possiamo leggere i dati nell'account del consumatore di dati dal bucket nell'account del produttore di dati. Eseguiremo semplicemente un semplice COUNT(*) Ancora. Sostituisci il <APPLICATION_ID>, <DATA_CONSUMER_JOB_ROLE>e <DATA_CONSUMER_LOG_BUCKET> con i valori della scheda Output sullo stack AWS CloudFormation creato nel tuo secondo account.
e sostituisci <DATA_PRODUCER_BUCKET> con il bucket del tuo primo account.
Attendi che il lavoro raggiunga uno stato completato, quindi recupera il log stdout dal tuo bucket, sostituendo il file <APPLICATION_ID>, <JOB_RUN_ID> dal lavoro di cui sopra, e <DATA_CONSUMER_LOG_BUCKET>.
Se utilizzi un computer basato su Unix e hai gunzip installato, puoi utilizzare il seguente comando come utente amministrativo.
Tieni presente che questo comando utilizza solo le policy dei ruoli AWS IAM, non le concessioni di accesso Amazon S3.
Altrimenti puoi usare il use get-dashboard-for-job-run comando e apri l'URL risultante nel browser per visualizzare i log stdout del driver nella scheda Esecutori dell'interfaccia utente Spark.
Pulire
Per evitare di incorrere in costi futuri per le risorse di esempio nei tuoi account AWS, assicurati di procedere come segue:
- È necessario eliminare manualmente lo spazio di lavoro Amazon EMR Studio creato nella prima parte del post
- Svuota i bucket Amazon S3 creati dagli stack AWS CloudFormation
- Assicurati di eliminare le autorizzazioni di accesso Amazon S3, le policy delle risorse e la posizione delle autorizzazioni di accesso S3 create nei passaggi precedenti utilizzando il comando
delete-access-grant,delete-access-grants-instance-resource-policy,delete-access-grants-locationedelete-access-grants-instancecomandi. - Elimina gli stack AWS CloudFormation creati in ciascun account
Confronto con la mappatura dei ruoli di AWS IAM
Nel 2018, EMR ha introdotto la mappatura dei ruoli EMRFS come un modo per fornire l'autorizzazione a livello di storage configurando EMRFS con più ruoli IAM. Sebbene efficace, la mappatura dei ruoli richiedeva la gestione di utenti o gruppi localmente sul cluster EMR oltre a mantenere le mappature tra tali identità e i rispettivi ruoli IAM corrispondenti. In combinazione con ruoli runtime su EMR su EC2 e ruoli lavorativi per EMR su EKS ed EMR senza server, ora è più semplice concedere l'accesso ai dati su S3 direttamente al principale interessato in base al lavoro.
Conclusione
In questo post ti abbiamo mostrato come configurare e utilizzare le concessioni di accesso Amazon S3 con Amazon EMR per gestire facilmente l'accesso ai dati per i tuoi carichi di lavoro Amazon EMR. Con S3 Access Grants ed EMR, puoi configurare facilmente l'accesso ai dati su S3 per le identità IAM o utilizzare la directory aziendale in IAM Identity Center come origine identità. Le concessioni di accesso S3 sono supportate in EMR su EC2, EMR su EKS ed EMR Serverless a partire dalla versione EMR 6.15.0.
Per saperne di più, vedere le Concessioni di accesso S3 ed Documentazione EMR e sentiti libero di porre qualsiasi domanda nei commenti!
Circa l'autore
 Damone Cortesi è un principale sostenitore degli sviluppatori presso Amazon Web Services. Crea strumenti e contenuti per semplificare la vita degli ingegneri dei dati. Quando non è impegnato nel lavoro, continua a creare pipeline di dati e a dividere i log nel tempo libero.
Damone Cortesi è un principale sostenitore degli sviluppatori presso Amazon Web Services. Crea strumenti e contenuti per semplificare la vita degli ingegneri dei dati. Quando non è impegnato nel lavoro, continua a creare pipeline di dati e a dividere i log nel tempo libero.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/use-amazon-emr-with-s3-access-grants-to-scale-spark-access-to-amazon-s3/
- :ha
- :È
- :non
- :Dove
- $ SU
- 1
- 10
- 100
- 107
- 11
- 1232
- 15%
- 20
- 2018
- 500
- 7
- 8
- a
- WRI
- sopra
- accesso
- gestione degli accessi
- Accesso ai dati
- accessibile
- Accedendo
- Il mio account
- conti
- riconoscere
- operanti in
- Action
- azioni
- aggiunta
- indirizzo
- amministrativo
- avvocato
- ancora
- avanti
- Tutti
- consentire
- consente
- lungo
- anche
- Amazon
- Amazon EC2
- Servizio Amazon Elastic Kubernetes
- Amazon EMR
- Amazon Web Services
- an
- Gli analisti
- analitica
- analizzare
- ed
- Annunciare
- Un altro
- in qualsiasi
- Apache
- Apache Spark
- Applicazioni
- applicazioni
- circa
- architettura
- SONO
- AS
- chiedere
- associato
- assumere
- At
- autorizzazione
- disponibile
- evitare
- AWS
- AWS CloudFormazione
- precedente
- base
- BE
- diventare
- prima
- Inizio
- sotto
- vantaggi
- Meglio
- fra
- del browser
- costruisce
- affari
- ma
- pulsante
- by
- Materiale
- Custodie
- centro
- il cambiamento
- Modifiche
- controllato
- Scegli
- clicca
- cliente
- Cloud
- Cluster
- codice
- combinazione
- combinando
- Uncommon
- completamento di una
- Completato
- complesso
- Calcolare
- configurato
- configurazione
- Connettiti
- Consumer
- Consumatori
- contenuto
- continua
- di controllo
- convertire
- Aziende
- Corrispondente
- Costi
- creare
- creato
- crea
- Creazione
- Credenziali
- costume
- Clienti
- dati
- l'accesso ai dati
- decentrata
- Predefinito
- defaults
- schierare
- deployment
- Costruttori
- diverso
- direttamente
- do
- documentazione
- fatto
- giù
- scaricare
- autista
- e
- ogni
- più facile
- facilmente
- facile
- effetto
- Efficace
- emersione
- enable
- endpoint
- imporre
- ingegnere
- Ingegneri
- Migliora
- garantire
- ambienti
- errore
- Etere (ETH)
- Anche
- Esempi
- eseguire
- Autunno
- Moda
- sentire
- pochi
- campi
- Compila il
- File
- filtraggio
- Infine
- Trovate
- finire
- Nome
- seguire
- i seguenti
- Nel
- Gratis
- da
- futuro
- porta
- generare
- ottenere
- Dare
- Go
- andando
- ha ottenuto
- concedere
- concesso
- borse di studio
- Gruppo
- Gruppo
- a portata di mano
- Hard
- Avere
- he
- Aiuto
- vivamente
- il suo
- Alveare
- Come
- Tutorial
- HTML
- HTTPS
- i
- IAM
- ID
- identità
- Identità
- identità e gestione degli accessi
- ids
- if
- importare
- importante
- in
- sempre più
- individuale
- informazioni
- esempio
- invece
- integrazione
- interattivo
- Interfaccia
- ai miglioramenti
- introdotto
- IT
- Lavoro
- Offerte di lavoro
- jpg
- ad appena
- Le
- kubernetes
- dopo
- con i più recenti
- lanciare
- IMPARARE
- Lasciare
- livelli
- piace
- LIMITE
- linea
- Lives
- a livello locale
- località
- ceppo
- accesso
- macchina
- mantenimento
- make
- gestire
- gestione
- gestione
- manualmente
- molti
- carta geografica
- mappatura
- Maggio..
- maglia
- minuto
- verbale
- Scopri di più
- multiplo
- devono obbligatoriamente:
- Nome
- necessaria
- Bisogno
- Rete
- New
- GENERAZIONE
- no
- Nota
- taccuino
- computer portatili
- adesso
- of
- on
- una volta
- ONE
- esclusivamente
- aprire
- Opzioni
- or
- minimo
- organizzazione
- Altro
- nostro
- produzione
- uscite
- al di fuori
- proprio
- pagina
- parte
- particolare
- Cartamodello
- modelli
- autorizzazione
- permessi
- posto
- Platone
- Platone Data Intelligence
- PlatoneDati
- contento
- Termini e Condizioni
- politica
- Post
- in precedenza
- Direttore
- presidi
- un bagno
- produttore
- Produttori
- fornire
- purché
- fornitore
- fornitori
- fornisce
- fornitura
- la percezione
- scopo
- query
- Domande
- Presto
- raggiungere
- Leggi
- Lettore
- si riferisce
- regione
- registrazione
- rilasciare
- pertinente
- rimanente
- sostituire
- richiesta
- necessario
- risorsa
- Risorse
- risposta
- risultante
- Ruolo
- ruoli
- strada
- Correre
- corre
- stesso
- Risparmi
- Scala
- scenario
- Scenari
- portata
- copione
- Secondo
- secondo
- Segreto
- Sezione
- sicuro
- problemi di
- vedere
- select
- serverless
- servizio
- Servizi
- sessioni
- set
- regolazione
- flessibile.
- Condividi
- dovrebbero
- mostrare attraverso le sue creazioni
- ha mostrato
- mostrato
- lato
- simile
- Un'espansione
- semplicità
- semplifica
- situazioni
- frammento
- So
- alcuni
- Fonte
- Scintilla
- specifico
- in particolare
- Si divide
- SQL
- pila
- Stacks
- iniziato
- Di partenza
- inizio
- Regione / Stato
- dichiarazione
- Stato dei servizi
- Passi
- Ancora
- conservazione
- studio
- inviare
- sottoreti
- il successo
- supportato
- sicuro
- sistema
- Fai
- prende
- modello
- temporaneo
- test
- che
- Il
- loro
- poi
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- quelli
- Attraverso
- tempo
- a
- strumenti
- Traduzione
- prova
- seconda
- Digitare
- Tipi di
- ui
- per
- URL
- uso
- utilizzato
- Utente
- utenti
- usa
- utilizzando
- utilizzare
- APPREZZIAMO
- Valori
- versione
- via
- Visualizza
- virtuale
- camminare
- a piedi
- vuole
- Modo..
- we
- Tempo
- sito web
- servizi web
- WELL
- Che
- Che cosa è l'
- quando
- quale
- while
- volere
- finestra
- con
- Lavora
- lavori
- scrivere
- scrittore
- YAML
- anno
- Tu
- Trasferimento da aeroporto a Sharm
- te stesso
- zefiro