Immagine di frimufilms on Freepik
Questa è un'era in cui la svolta dell'IA arriva ogni giorno. Qualche anno fa non avevamo molte IA generate in pubblico, ma ora la tecnologia è accessibile a tutti. È eccellente per molti creatori individuali o aziende che vogliono sfruttare in modo significativo la tecnologia per sviluppare qualcosa di complesso, che potrebbe richiedere molto tempo.
Una delle scoperte più incredibili che cambiano il modo in cui lavoriamo è il rilascio del Modello GPT-3.5 di OpenAI. Cos'è il modello GPT-3.5? Se lascio che la modella parli da sola. In tal caso, la risposta è "un modello di intelligenza artificiale altamente avanzato nel campo dell'elaborazione del linguaggio naturale, con enormi miglioramenti nella generazione di tex contestualmente accurati e pertinentit”.
OpenAI fornisce un'API per il modello GPT-3.5 che possiamo utilizzare per sviluppare una semplice app, come un riepilogo di testo. Per fare ciò, possiamo usare Python per integrare perfettamente l'API del modello nella nostra applicazione prevista. Che aspetto ha il processo? Entriamo in esso.
Ci sono alcuni prerequisiti prima di seguire questo tutorial, tra cui:
– Conoscenza di Python, inclusa la conoscenza dell'uso di librerie esterne e IDE
– Comprensione delle API e gestione dell'endpoint con Python
– Avere accesso alle API OpenAI
Per ottenere l'accesso alle API OpenAI, dobbiamo registrarci sul Piattaforma per sviluppatori OpenAI e visita le chiavi API View all'interno del tuo profilo. Sul Web, fai clic sul pulsante "Crea nuova chiave segreta" per acquisire l'accesso API (vedi immagine sotto). Ricordati di salvare le chiavi, poiché dopo non verranno più mostrate.

Immagine dell'autore
Con tutta la preparazione pronta, proviamo a capire le basi del modello API OpenAI.
Il Modello della famiglia GPT-3.5 è stato specificato per molti compiti linguistici e ogni modello della famiglia eccelle in alcuni compiti. Per questo esempio tutorial, useremmo il file gpt-3.5-turbo poiché era il modello corrente consigliato quando questo articolo è stato scritto per le sue capacità e l'efficienza in termini di costi.
Usiamo spesso il text-davinci-003 nel tutorial OpenAI, ma useremmo il modello corrente per questo tutorial. Faremmo affidamento sul Completamento chat endpoint invece di Completamento perché il modello corrente consigliato è un modello di chat. Anche se il nome era un modello di chat, funziona per qualsiasi attività linguistica.
Proviamo a capire come funziona l'API. Innanzitutto, dobbiamo installare gli attuali pacchetti OpenAI.
pip install openai
Dopo aver terminato l'installazione del pacchetto, proveremo a utilizzare l'API collegandoci tramite l'endpoint ChatCompletion. Tuttavia, dobbiamo impostare l'ambiente prima di continuare.
Nel tuo IDE preferito (per me è VS Code), crea due file chiamati .env ed summarizer_app.py, simile all'immagine qui sotto.
Immagine dell'autore
Il summarizer_app.py è dove costruiremo la nostra semplice applicazione di riepilogo, e il file .env file è dove memorizzeremmo la nostra chiave API. Per motivi di sicurezza, si consiglia sempre di separare la nostra chiave API in un altro file piuttosto che codificarla nel file Python.
Nel .env file inserire la seguente sintassi e salvare il file. Sostituisci your_api_key_here con la tua vera chiave API. Non modificare la chiave API in un oggetto stringa; lasciali così com'è.
OPENAI_API_KEY=your_api_key_here
Comprendere meglio l'API GPT-3.5; useremmo il seguente codice per generare la parola riassunto.
openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, top_p=0.5, frequency_penalty=0.5, messages=[ { "role": "system", "content": "You are a helpful assistant for text summarization.", }, { "role": "user", "content": f"Summarize this for a {person_type}: {prompt}", }, ],
)
Il codice sopra è il modo in cui interagiamo con il modello GPT-3.5 delle API OpenAI. Utilizzando l'API ChatCompletion, creiamo una conversazione e otterremo il risultato desiderato dopo aver superato il prompt.
Analizziamo ogni parte per capirli meglio. Nella prima riga, usiamo il openai.ChatCompletion.create codice per creare la risposta dal prompt che passeremo all'API.
Nella riga successiva, abbiamo i nostri iperparametri che usiamo per migliorare le nostre attività di testo. Ecco il riepilogo di ogni funzione iperparametrica:
model: la famiglia di modelli che vogliamo utilizzare. In questo tutorial, utilizziamo il modello consigliato corrente (gpt-3.5-turbo).max_tokens: Il limite superiore delle parole generate dal modello. Aiuta a limitare la lunghezza del testo generato.temperature: La casualità dell'output del modello, con una temperatura più alta, significa un risultato più vario e creativo. L'intervallo di valori è compreso tra 0 e infinito, anche se i valori superiori a 2 non sono comuni.top_p: Il campionamento Top P o top-k o il campionamento del nucleo è un parametro per controllare il pool di campionamento dalla distribuzione dell'output. Ad esempio, il valore 0.1 indica che il modello campiona solo l'output dal 10% superiore della distribuzione. L'intervallo di valori era compreso tra 0 e 1; valori più alti significano un risultato più diversificato.frequency_penalty: La penalità per il token di ripetizione dall'output. L'intervallo di valori è compreso tra -2 e 2, dove i valori positivi impedirebbero al modello di ripetere il token mentre i valori negativi incoraggiano il modello a utilizzare parole più ripetitive. 0 significa nessuna penalità.messages: Il parametro in cui passiamo il nostro prompt di testo da elaborare con il modello. Passiamo un elenco di dizionari in cui la chiave è l'oggetto ruolo (o "sistema", "utente" o "assistente") che aiuta il modello a comprendere il contesto e la struttura mentre i valori sono il contesto.- Il ruolo "sistema" è la linea guida stabilita per il modello di comportamento "assistente",
- Il ruolo "utente" rappresenta il prompt della persona che interagisce con il modello,
- Il ruolo "assistente" è la risposta al prompt "utente".
Dopo aver spiegato il parametro sopra, possiamo vedere che il messages il parametro sopra ha due oggetti dizionario. Il primo dizionario è il modo in cui impostiamo il modello come riepilogo testuale. Il secondo è dove passeremmo il nostro testo e otterremmo l'output di riepilogo.
Nel secondo dizionario, vedrai anche la variabile person_type ed prompt. person_type è una variabile che ho usato per controllare lo stile riassunto, che mostrerò nel tutorial. Mentre il prompt è dove passeremmo il nostro testo da riassumere.
Continuando con il tutorial, inserisci il codice seguente nel file summarizer_app.py file e cercheremo di esaminare come funziona la funzione seguente.
import openai
import os
from dotenv import load_dotenv load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY") def generate_summarizer( max_tokens, temperature, top_p, frequency_penalty, prompt, person_type,
): res = openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, top_p=0.5, frequency_penalty=0.5, messages= [ { "role": "system", "content": "You are a helpful assistant for text summarization.", }, { "role": "user", "content": f"Summarize this for a {person_type}: {prompt}", }, ], ) return res["choices"][0]["message"]["content"]
Il codice sopra è dove creiamo una funzione Python che accetterebbe vari parametri che abbiamo discusso in precedenza e restituirà l'output di riepilogo del testo.
Prova la funzione sopra con il tuo parametro e guarda l'output. Quindi continuiamo il tutorial per creare una semplice applicazione con il pacchetto streamlit.
Snello è un pacchetto Python open source progettato per creare app Web di machine learning e data science. È facile da usare e intuitivo, quindi è consigliato a molti principianti.
Installiamo il pacchetto streamlit prima di continuare con il tutorial.
pip install streamlit
Al termine dell'installazione, inserire il seguente codice nel file summarizer_app.py.
import streamlit as st #Set the application title
st.title("GPT-3.5 Text Summarizer") #Provide the input area for text to be summarized
input_text = st.text_area("Enter the text you want to summarize:", height=200) #Initiate three columns for section to be side-by-side
col1, col2, col3 = st.columns(3) #Slider to control the model hyperparameter
with col1: token = st.slider("Token", min_value=0.0, max_value=200.0, value=50.0, step=1.0) temp = st.slider("Temperature", min_value=0.0, max_value=1.0, value=0.0, step=0.01) top_p = st.slider("Nucleus Sampling", min_value=0.0, max_value=1.0, value=0.5, step=0.01) f_pen = st.slider("Frequency Penalty", min_value=-1.0, max_value=1.0, value=0.0, step=0.01) #Selection box to select the summarization style
with col2: option = st.selectbox( "How do you like to be explained?", ( "Second-Grader", "Professional Data Scientist", "Housewives", "Retired", "University Student", ), ) #Showing the current parameter used for the model with col3: with st.expander("Current Parameter"): st.write("Current Token :", token) st.write("Current Temperature :", temp) st.write("Current Nucleus Sampling :", top_p) st.write("Current Frequency Penalty :", f_pen) #Creating button for execute the text summarization
if st.button("Summarize"): st.write(generate_summarizer(token, temp, top_p, f_pen, input_text, option))
Prova a eseguire il seguente codice nel prompt dei comandi per avviare l'applicazione.
streamlit run summarizer_app.py
Se tutto funziona correttamente, vedrai la seguente applicazione nel tuo browser predefinito.
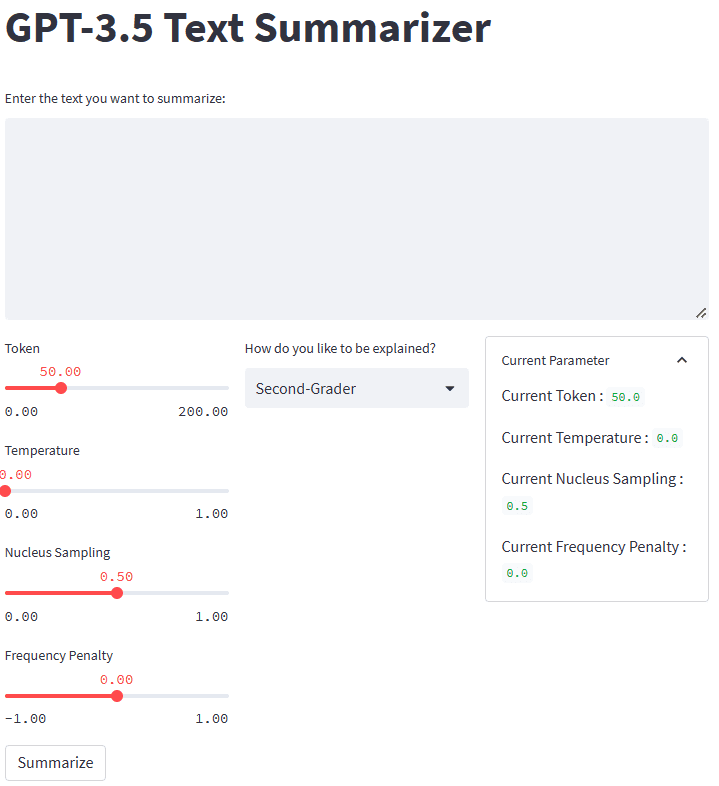
Immagine dell'autore
Quindi, cosa è successo nel codice sopra? Permettetemi di spiegare brevemente ogni funzione che abbiamo usato:
.st.title: Fornire il testo del titolo dell'applicazione web..st.write: Scrive l'argomento nell'applicazione; potrebbe essere qualsiasi cosa tranne principalmente un testo stringa..st.text_area: Fornire un'area per l'immissione di testo che può essere memorizzata nella variabile e utilizzata per il prompt per il nostro riepilogo testuale.st.columns: Contenitori di oggetti per fornire un'interazione fianco a fianco..st.slider: fornisce un widget di scorrimento con valori impostati con cui l'utente può interagire. Il valore viene memorizzato su una variabile utilizzata come parametro del modello..st.selectbox: fornisce un widget di selezione per consentire agli utenti di selezionare lo stile di riepilogo desiderato. Nell'esempio sopra, usiamo cinque stili diversi..st.expander: fornisce un contenitore che gli utenti possono espandere e contenere più oggetti..st.button: fornisce un pulsante che esegue la funzione prevista quando l'utente lo preme.
Poiché streamlit progetterebbe automaticamente l'interfaccia utente seguendo il codice fornito dall'alto verso il basso, potremmo concentrarci maggiormente sull'interazione.
Con tutti i pezzi a posto, proviamo la nostra applicazione di riepilogo con un esempio di testo. Per il nostro esempio, userei il Pagina di Wikipedia sulla teoria della relatività testo da riassumere. Con un parametro predefinito e uno stile di seconda elementare, otteniamo il seguente risultato.
Albert Einstein was a very smart scientist who came up with two important ideas about how the world works. The first one, called special relativity, talks about how things move when there is no gravity. The second one, called general relativity, explains how gravity works and how it affects things in space like stars and planets. These ideas helped us understand many things in science, like how particles interact with each other and even helped us discover black holes!
Potresti ottenere un risultato diverso da quello sopra. Proviamo lo stile Housewives e modifichiamo un po' il parametro (Token 100, Temperature 0.5, Nucleus Sampling 0.5, Frequency Penalty 0.3).
The theory of relativity is a set of physics theories proposed by Albert Einstein in 1905 and 1915. It includes special relativity, which applies to physical phenomena without gravity, and general relativity, which explains the law of gravitation and its relation to the forces of nature. The theory transformed theoretical physics and astronomy in the 20th century, introducing concepts like 4-dimensional spacetime and predicting astronomical phenomena like black holes and gravitational waves.
Come possiamo vedere, c'è una differenza di stile per lo stesso testo che forniamo. Con una richiesta di modifica e un parametro, la nostra applicazione può essere più funzionale.
L'aspetto generale della nostra applicazione di riepilogo del testo può essere visto nell'immagine qui sotto.
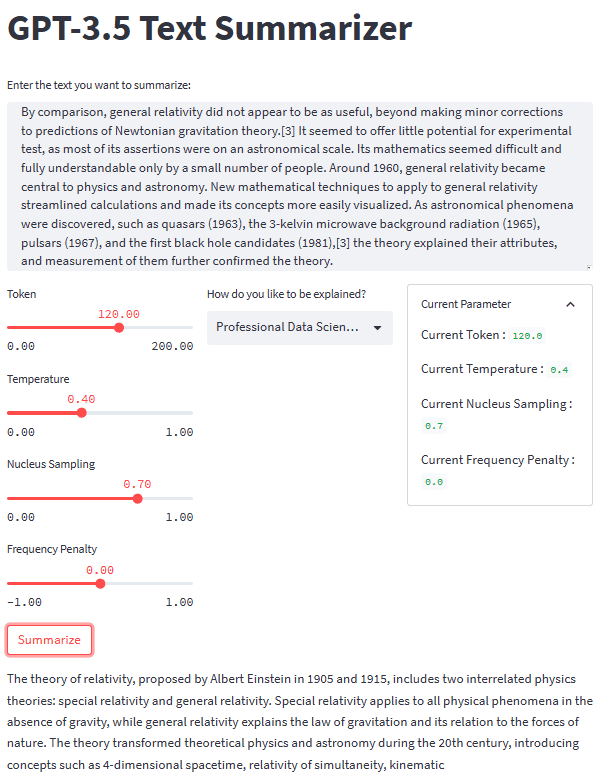
Immagine dell'autore
Questo è il tutorial sulla creazione dello sviluppo di applicazioni di riepilogo del testo con GPT-3.5. È possibile modificare ulteriormente l'applicazione e distribuirla.
L'IA generativa è in aumento e dovremmo sfruttare l'opportunità creando un'applicazione fantastica. In questo tutorial impareremo come funzionano le API OpenAI GPT-3.5 e come utilizzarle per creare un'applicazione di riepilogo del testo con l'aiuto di Python e del pacchetto streamlit.
Cornellio Yudha Wijaya è un assistente manager di data science e scrittore di dati. Mentre lavora a tempo pieno presso Allianz Indonesia, ama condividere suggerimenti su Python e dati tramite social media e mezzi di scrittura.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://www.kdnuggets.com/2023/04/text-summarization-development-python-tutorial-gpt35.html?utm_source=rss&utm_medium=rss&utm_campaign=text-summarization-development-a-python-tutorial-with-gpt-3-5
- :È
- ][P
- $ SU
- 1
- 100
- 28
- 7
- a
- WRI
- sopra
- Accetta
- accesso
- accessibile
- preciso
- acquisire
- Avanzate
- Vantaggio
- Dopo shavasana, sedersi in silenzio; saluti;
- AI
- Tutti
- Allianz
- Sebbene il
- sempre
- ed
- Un altro
- rispondere
- api
- Accesso API
- API
- App
- Applicazioni
- Sviluppo di applicazioni
- applicazioni
- SONO
- RISERVATA
- argomento
- articolo
- AS
- Assistant
- astronomia
- At
- automaticamente
- basic
- BE
- perché
- prima
- principianti
- sotto
- Meglio
- fra
- Po
- Nero
- buchi neri
- Parte inferiore
- Scatola
- Rompere
- sfondamento
- innovazioni
- brevemente
- del browser
- costruire
- pulsante
- by
- detto
- Materiale
- Custodie
- Secolo
- il cambiamento
- scelte
- clicca
- codice
- colonne
- arrivo
- Uncommon
- Aziende
- completamento
- complesso
- concetti
- Collegamento
- Contenitore
- Tecnologie Container
- contenuto
- contesto
- continua
- di controllo
- Conversazione
- potuto
- creare
- Creazione
- Creative
- creatori
- Corrente
- alle lezioni
- dati
- scienza dei dati
- scienziato di dati
- Predefinito
- schierare
- Design
- progettato
- sviluppare
- Costruttori
- Mercato
- differenza
- diverso
- scopri
- discusso
- distribuzione
- paesaggio differenziato
- Dont
- giù
- ogni
- o
- incoraggiare
- endpoint
- entrare
- Ambiente
- epoca
- Etere (ETH)
- Anche
- tutti
- qualunque cosa
- esempio
- eccellente
- eseguire
- Espandere
- Spiegare
- ha spiegato
- Spiega
- esterno
- famiglia
- fantastico
- preferito
- pochi
- campo
- Compila il
- File
- Nome
- Focus
- i seguenti
- Nel
- Forze
- Frequenza
- da
- function
- funzionale
- ulteriormente
- Generale
- generare
- generato
- la generazione di
- ottenere
- dato
- di gravitazione
- Onde gravitazionali
- gravità
- linee guida
- Manovrabilità
- successo
- Avere
- avendo
- Aiuto
- aiutato
- utile
- aiuta
- qui
- superiore
- vivamente
- tenere
- Fori
- Come
- Tutorial
- Come lavoriamo
- Tuttavia
- HTTPS
- i
- idee
- Immagine
- importare
- importante
- competenze
- miglioramenti
- in
- inclusi
- Compreso
- incredibile
- individuale
- Indonesia
- infinito
- avviare
- ingresso
- install
- installazione
- invece
- integrare
- interagire
- si interagisce
- interazione
- l'introduzione di
- intuitivo
- IT
- SUO
- jpg
- KDnuggets
- Le
- Tasti
- conoscenze
- Lingua
- Legge
- IMPARARE
- apprendimento
- Lunghezza
- biblioteche
- piace
- LIMITE
- linea
- Lista
- Lunghi
- a lungo
- Guarda
- una
- macchina
- machine learning
- direttore
- molti
- si intende
- Media
- messaggio
- forza
- modello
- Scopri di più
- maggior parte
- cambiano
- multiplo
- Nome
- Naturale
- Linguaggio naturale
- Elaborazione del linguaggio naturale
- Natura
- Bisogno
- negativo.
- New
- GENERAZIONE
- oggetto
- oggetti
- ottenere
- of
- on
- ONE
- open source
- OpenAI
- Opportunità
- Opzione
- OS
- Altro
- produzione
- complessivo
- pacchetto
- Packages
- parametro
- parametri
- parte
- Di passaggio
- persona
- Fisico
- Fisica
- pezzi
- posto
- Pianeti
- Platone
- Platone Data Intelligence
- PlatoneDati
- pool
- positivo
- previsione
- prerequisiti
- in precedenza
- processi
- lavorazione
- professionale
- Profilo
- proposto
- fornire
- fornisce
- la percezione
- metti
- Python
- casualità
- gamma
- piuttosto
- pronto
- motivi
- raccomandato
- registro
- relazione
- rilasciare
- pertinente
- ricorda
- ripetitivo
- sostituire
- rappresenta
- risposta
- colpevole
- ritorno
- crescita
- Ruolo
- Correre
- stesso
- Risparmi
- Scienze
- Scienziato
- senza soluzione di continuità
- Secondo
- Segreto
- Sezione
- problemi di
- prodotti
- separato
- set
- Condividi
- dovrebbero
- mostrare attraverso le sue creazioni
- mostrato
- significativamente
- simile
- Un'espansione
- cursore
- smart
- So
- Social
- Social Media
- alcuni
- qualcosa
- lo spazio
- la nostra speciale
- specificato
- Stelle
- Tornare al suo account
- memorizzati
- Corda
- La struttura
- studente
- style
- stili
- tale
- riassumere
- SOMMARIO
- sintassi
- sistema
- Fai
- Parlare
- trattativa
- Task
- task
- Tecnologia
- che
- Il
- la legge
- il mondo
- Li
- si
- teorico
- Strumenti Bowman per analizzare le seguenti finiture:
- cose
- tre
- Attraverso
- tempo
- suggerimenti
- Titolo
- a
- token
- top
- trasformato
- lezione
- ui
- capire
- e una comprensione reciproca
- Università
- us
- uso
- Utente
- utenti
- utilizzare
- APPREZZIAMO
- Valori
- vario
- Fisso
- via
- Visualizza
- Visita
- vs
- vs codice
- onde
- sito web
- applicazione web
- WELL
- Che
- Che cosa è l'
- quale
- while
- OMS
- wikipedia
- volere
- con
- entro
- senza
- Word
- parole
- Lavora
- lavoro
- lavori
- mondo
- sarebbe
- scrittore
- scrittura
- scritto
- anni
- Trasferimento da aeroporto a Sharm
- zefiro