In questo post, dimostriamo come utilizzare l'eliminazione strutturale basata sulla ricerca di architettura neurale (NAS) per comprimere un modello BERT ottimizzato per migliorare le prestazioni del modello e ridurre i tempi di inferenza. I modelli linguistici pre-addestrati (PLM) sono in fase di rapida adozione commerciale e aziendale nelle aree degli strumenti di produttività, del servizio clienti, della ricerca e dei consigli, dell'automazione dei processi aziendali e della creazione di contenuti. L'implementazione di endpoint di inferenza PLM è in genere associata a una latenza più elevata e a costi infrastrutturali più elevati a causa dei requisiti di elaborazione e a una ridotta efficienza computazionale a causa dell'elevato numero di parametri. L'eliminazione di un PLM riduce le dimensioni e la complessità del modello mantenendone le capacità predittive. I PLM ridotti ottengono un ingombro di memoria inferiore e una latenza inferiore. Lo dimostriamo eliminando un PLM e scambiando il conteggio dei parametri e l'errore di convalida per un'attività target specifica e siamo in grado di ottenere tempi di risposta più rapidi rispetto al modello PLM di base.
L'ottimizzazione multi-obiettivo è un'area del processo decisionale che ottimizza più di una funzione obiettivo, come il consumo di memoria, il tempo di formazione e le risorse di calcolo, da ottimizzare simultaneamente. L'eliminazione strutturale è una tecnica per ridurre le dimensioni e i requisiti computazionali del PLM eliminando strati o neuroni/nodi tentando al tempo stesso di preservare l'accuratezza del modello. Rimuovendo gli strati, l'eliminazione strutturale raggiunge tassi di compressione più elevati, il che porta a una scarsità strutturata compatibile con l'hardware che riduce i tempi di esecuzione e di risposta. L'applicazione di una tecnica di potatura strutturale a un modello PLM si traduce in un modello più leggero con un ingombro di memoria inferiore che, se ospitato come endpoint di inferenza in SageMaker, offre una migliore efficienza delle risorse e costi ridotti rispetto al PLM ottimizzato originale.
I concetti illustrati in questo post possono essere applicati ad applicazioni che utilizzano funzionalità PLM, come sistemi di consigli, analisi del sentiment e motori di ricerca. Nello specifico, è possibile utilizzare questo approccio se si dispone di team dedicati al machine learning (ML) e alla scienza dei dati che ottimizzano i propri modelli PLM utilizzando set di dati specifici del dominio e distribuiscono un gran numero di endpoint di inferenza utilizzando Amazon Sage Maker. Un esempio è un rivenditore online che distribuisce un gran numero di endpoint di inferenza per il riepilogo del testo, la classificazione del catalogo prodotti e la classificazione del sentiment del feedback sul prodotto. Un altro esempio potrebbe essere un operatore sanitario che utilizza endpoint di inferenza PLM per la classificazione di documenti clinici, il riconoscimento di entità denominate da referti medici, chatbot medici e stratificazione del rischio dei pazienti.
Panoramica della soluzione
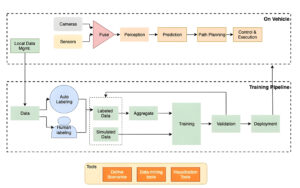
In questa sezione presentiamo il flusso di lavoro complessivo e spieghiamo l'approccio. Per prima cosa usiamo an Amazon Sage Maker Studio taccuino per mettere a punto un modello BERT pre-addestrato su un'attività target utilizzando un set di dati specifico del dominio. BERTA (Rappresentazioni di codificatori bidirezionali da Transformers) è un modello linguistico preaddestrato basato su architettura del trasformatore utilizzato per attività di elaborazione del linguaggio naturale (PNL). La ricerca dell'architettura neurale (NAS) è un approccio per automatizzare la progettazione di reti neurali artificiali ed è strettamente correlato all'ottimizzazione degli iperparametri, un approccio ampiamente utilizzato nel campo dell'apprendimento automatico. L'obiettivo del NAS è trovare l'architettura ottimale per un dato problema effettuando una ricerca su un ampio insieme di architetture candidate utilizzando tecniche come l'ottimizzazione senza gradienti o ottimizzando le metriche desiderate. Le prestazioni dell'architettura vengono generalmente misurate utilizzando parametri come la perdita di convalida. Sintonizzazione automatica del modello SageMaker (AMT) automatizza il processo noioso e complesso di ricerca delle combinazioni ottimali di iperparametri del modello ML che garantiscono le migliori prestazioni del modello. AMT utilizza algoritmi di ricerca intelligenti e valutazioni iterative utilizzando una gamma di iperparametri specificati. Sceglie i valori dell'iperparametro che creano un modello con le prestazioni migliori, misurate da parametri prestazionali quali precisione e punteggio F-1.
L'approccio di perfezionamento descritto in questo post è generico e può essere applicato a qualsiasi set di dati basato su testo. L'attività assegnata a BERT PLM può essere un'attività basata su testo come l'analisi del sentiment, la classificazione del testo o domande e risposte. In questa demo, l'attività di destinazione è un problema di classificazione binaria in cui BERT viene utilizzato per identificare, da un set di dati costituito da una raccolta di coppie di frammenti di testo, se il significato di un frammento di testo può essere dedotto dall'altro frammento. Noi usiamo il Riconoscimento del set di dati degli allegati testuali dalla suite di benchmarking GLUE. Eseguiamo una ricerca multi-obiettivo utilizzando SageMaker AMT per identificare le sottoreti che offrono compromessi ottimali tra il conteggio dei parametri e l'accuratezza della previsione per l'attività target. Quando eseguiamo una ricerca multi-obiettivo, iniziamo definendo l'accuratezza e il conteggio dei parametri come obiettivi che miriamo a ottimizzare.
All'interno della rete BERT PLM possono esserci sottoreti modulari e autonome che consentono al modello di avere capacità specializzate come la comprensione del linguaggio e la rappresentazione della conoscenza. BERT PLM utilizza una sottorete di auto-attenzione multi-head e una sottorete feed-forward. Uno strato di autoattenzione a più teste consente a BERT di mettere in relazione diverse posizioni di una singola sequenza al fine di calcolare una rappresentazione della sequenza consentendo a più teste di occuparsi di più segnali di contesto. L'input è suddiviso in più sottospazi e l'attenzione al sé viene applicata a ciascuno dei sottospazi separatamente. Più teste in un trasformatore PLM consentono al modello di gestire congiuntamente le informazioni provenienti da diversi sottospazi di rappresentazione. Una sottorete feed-forward è una semplice rete neurale che prende l'output dalla sottorete di autoattenzione multi-testa, elabora i dati e restituisce le rappresentazioni finali del codificatore.
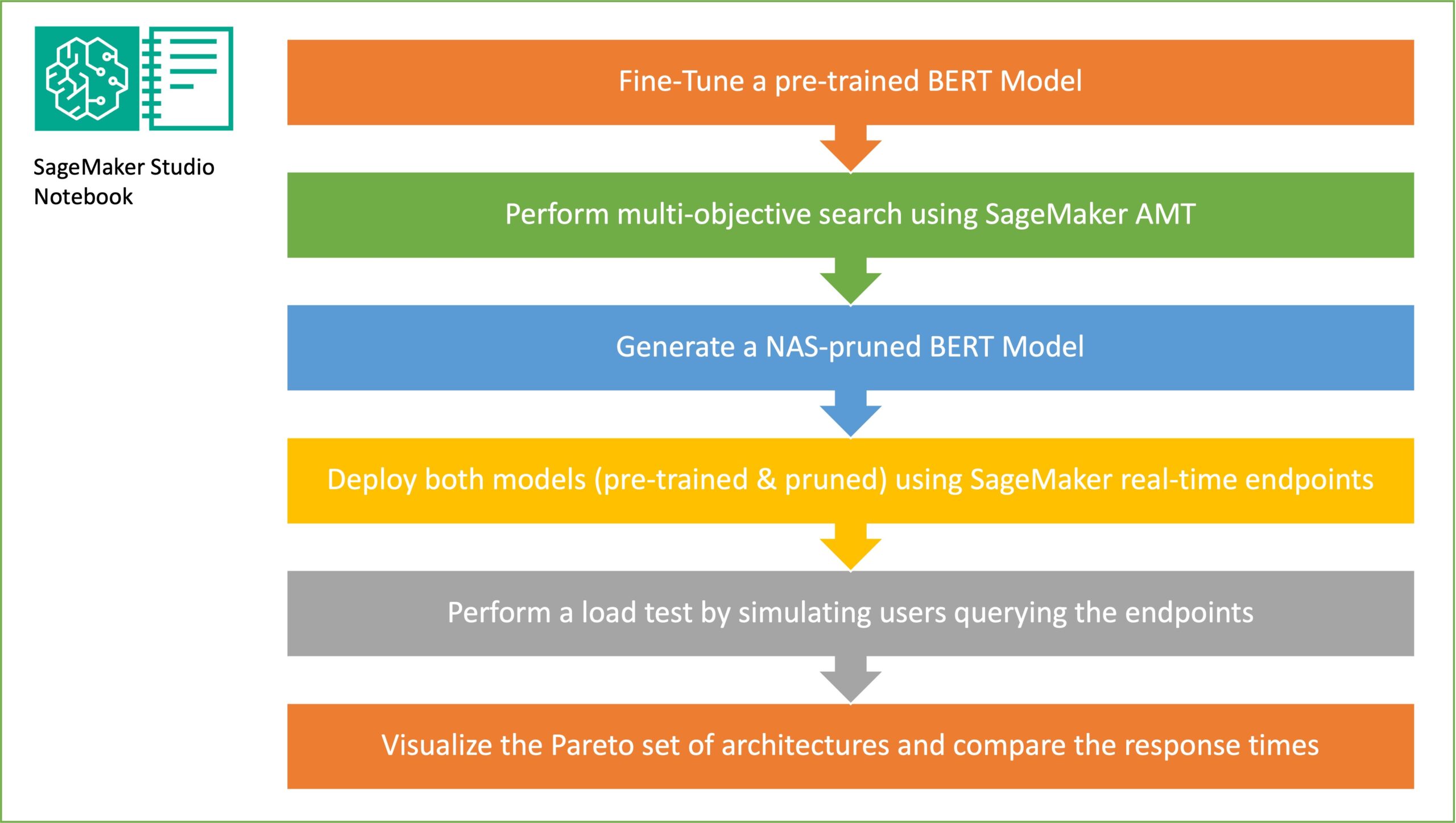
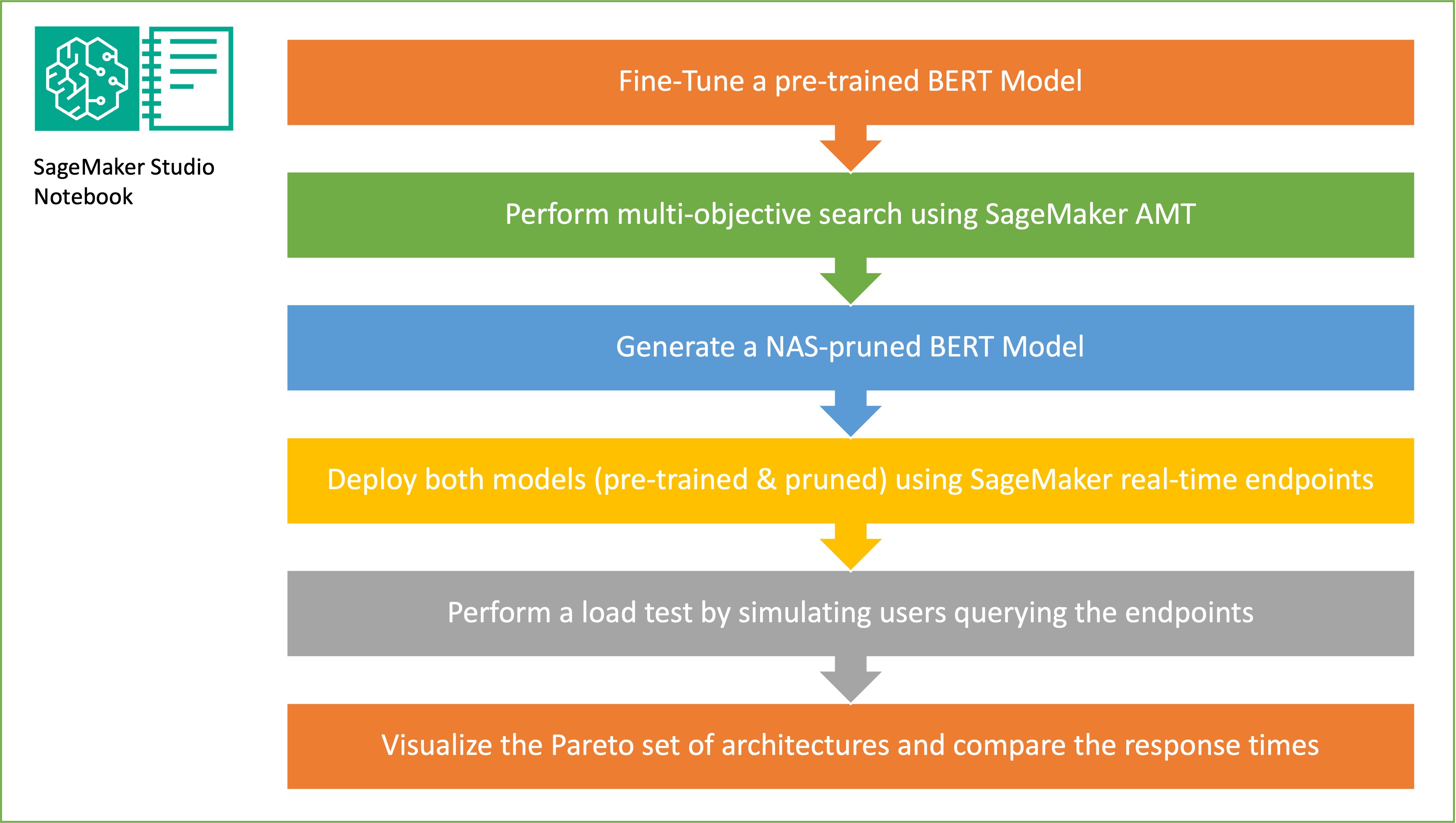
L'obiettivo del campionamento casuale della sottorete è addestrare modelli BERT più piccoli che possano funzionare abbastanza bene nelle attività target. Campioniamo 100 sottoreti casuali dal modello BERT di base ottimizzato e valutiamo 10 reti contemporaneamente. Le sottoreti addestrate vengono valutate per le metriche oggettive e il modello finale viene scelto in base ai compromessi trovati tra le metriche oggettive. Visualizziamo il Fronte di Pareto per le sottoreti campionate, che contengono il modello ridotto che offre il compromesso ottimale tra accuratezza del modello e dimensione del modello. Selezioniamo la sottorete candidata (modello BERT ottimizzato dal NAS) in base alle dimensioni e all'accuratezza del modello che siamo disposti a sacrificare. Successivamente, ospitiamo gli endpoint, il modello base BERT pre-addestrato e il modello BERT eliminato dal NAS utilizzando SageMaker. Per eseguire test di carico, utilizziamo Locusta, uno strumento di test di carico open source che puoi implementare utilizzando Python. Eseguiamo test di carico su entrambi gli endpoint utilizzando Locust e visualizziamo i risultati utilizzando il fronte di Pareto per illustrare il compromesso tra tempi di risposta e accuratezza per entrambi i modelli. Il diagramma seguente fornisce una panoramica del flusso di lavoro spiegato in questo post.
Prerequisiti
Per questo incarico sono richiesti i seguenti prerequisiti:
È inoltre necessario aumentare il quota di servizio per accedere ad almeno tre istanze di istanze ml.g4dn.xlarge in SageMaker. Il tipo di istanza ml.g4dn.xlarge è l'istanza GPU economicamente vantaggiosa che ti consente di eseguire PyTorch in modo nativo. Per aumentare la quota del servizio, completare i seguenti passaggi:
- Nella console, vai a Quote di servizio.
- Nel Gestisci le quotescegli Amazon Sage Maker, Quindi scegliere Visualizza le quote.

- Cerca "ml-g4dn.xlarge per l'utilizzo del lavoro di formazione" e seleziona l'elemento quota.
- Scegli Richiedi un aumento a livello di account.
- Nel Aumentare il valore della quota, inserisci un valore pari o superiore a 5.
- Scegli RICHIEDI.
Il completamento dell'approvazione della quota richiesta potrebbe richiedere del tempo a seconda delle autorizzazioni dell'account.

- Apri SageMaker Studio dalla console SageMaker.

- Scegli Terminale di sistema per Utilità e file.

- Esegui il comando seguente per clonare il file Repository GitHub all'istanza di SageMaker Studio:
- Spostarsi
amazon-sagemaker-examples/hyperparameter_tuning/neural_architecture_search_llm. - Aprire il file
nas_for_llm_with_amt.ipynb. - Configura l'ambiente con un file
ml.g4dn.xlargeistanza e scegli Seleziona.

Configurare il modello BERT preaddestrato
In questa sezione importiamo il set di dati Recognizing Textual Entailment dalla libreria del set di dati e dividiamo il set di dati in set di training e di convalida. Questo set di dati è costituito da coppie di frasi. Il compito del BERT PLM è riconoscere, dati due frammenti di testo, se il significato di un frammento di testo può essere dedotto dall'altro frammento. Nell'esempio seguente possiamo dedurre il significato della prima frase dalla seconda frase:
Carichiamo il dataset di implicazione del riconoscimento testuale dal file COLLA suite di benchmarking tramite libreria di set di dati da Hugging Face all'interno del nostro script di formazione (./training.py). Abbiamo diviso il set di dati di training originale da GLUE in un set di training e validazione. Nel nostro approccio, perfezioniamo il modello BERT di base utilizzando il set di dati di addestramento, quindi eseguiamo una ricerca multi-obiettivo per identificare l'insieme di sottoreti che bilanciano in modo ottimale le metriche oggettive. Utilizziamo il set di dati di addestramento esclusivamente per mettere a punto il modello BERT. Tuttavia, utilizziamo i dati di convalida per la ricerca multi-obiettivo misurando l'accuratezza sul set di dati di convalida dei controlli.
Ottimizza il PLM BERT utilizzando un set di dati specifico del dominio
I casi d'uso tipici per un modello BERT grezzo includono la previsione della frase successiva o la modellazione del linguaggio mascherato. Per utilizzare il modello BERT di base per attività a valle come il riconoscimento testuale, dobbiamo perfezionare ulteriormente il modello utilizzando un set di dati specifico del dominio. È possibile utilizzare un modello BERT ottimizzato per attività quali la classificazione delle sequenze, la risposta alle domande e la classificazione dei token. Tuttavia, ai fini di questa demo, utilizziamo il modello ottimizzato per la classificazione binaria. Perfezioniamo il modello BERT pre-addestrato con il set di dati di addestramento che abbiamo preparato in precedenza, utilizzando i seguenti iperparametri:
Salviamo il checkpoint dell'addestramento del modello in un file Servizio di archiviazione semplice Amazon (Amazon S3), in modo che il modello possa essere caricato durante la ricerca multi-obiettivo basata su NAS. Prima di addestrare il modello, definiamo le metriche quali epoca, perdita di addestramento, numero di parametri ed errore di convalida:
Dopo l'avvio del processo di messa a punto, il completamento del processo di formazione richiede circa 15 minuti.
Eseguire una ricerca multi-obiettivo per selezionare sottoreti e visualizzare i risultati
Nella fase successiva, eseguiamo una ricerca multi-obiettivo sul modello BERT di base ottimizzato campionando sottoreti casuali utilizzando SageMaker AMT. Per accedere a una sottorete all'interno della superrete (il modello BERT perfezionato), mascheriamo tutti i componenti del PLM che non fanno parte della sottorete. Mascherare una superrete per trovare sottoreti in un PLM è una tecnica utilizzata per isolare e identificare modelli di comportamento del modello. Tieni presente che i trasformatori Hugging Face necessitano che la dimensione nascosta sia un multiplo del numero di teste. La dimensione nascosta in un PLM del trasformatore controlla la dimensione dello spazio vettoriale degli stati nascosti, che influisce sulla capacità del modello di apprendere rappresentazioni e modelli complessi nei dati. In un BERT PLM, il vettore degli stati nascosti ha una dimensione fissa (768). Non possiamo modificare la dimensione nascosta, quindi il numero di teste deve essere compreso tra [1, 3, 6, 12].
A differenza dell’ottimizzazione a obiettivo singolo, nell’impostazione multi-obiettivo, in genere non abbiamo un’unica soluzione che ottimizzi contemporaneamente tutti gli obiettivi. Invece, miriamo a raccogliere un insieme di soluzioni che dominano tutte le altre soluzioni in almeno un obiettivo (come l'errore di validazione). Ora possiamo avviare la ricerca multi-obiettivo tramite AMT impostando le metriche che vogliamo ridurre (errore di validazione e numero di parametri). Le sottoreti casuali sono definite dal parametro max_jobs e il numero di lavori simultanei è definito dal parametro max_parallel_jobs. Il codice per caricare il checkpoint del modello e valutare la sottorete è disponibile nel file evaluate_subnetwork.py script.
L'esecuzione del processo di ottimizzazione AMT richiede circa 2 ore e 20 minuti. Una volta eseguito correttamente il processo di ottimizzazione AMT, analizziamo la cronologia del lavoro e raccogliamo le configurazioni della sottorete, come numero di teste, numero di livelli, numero di unità e le metriche corrispondenti come errore di convalida e numero di parametri. La schermata seguente mostra il riepilogo di un lavoro di sintonizzazione AMT riuscito.
Successivamente, visualizziamo i risultati utilizzando un insieme di Pareto (noto anche come frontiera di Pareto o insieme ottimale di Pareto), che ci aiuta a identificare insiemi ottimali di sottoreti che dominano tutte le altre sottoreti nella metrica oggettiva (errore di convalida):
Innanzitutto, raccogliamo i dati dal lavoro di ottimizzazione AMT. Quindi tracciamo l'insieme di Pareto utilizzando matplotlob.pyplot con numero di parametri sull'asse x ed errore di convalida sull'asse y. Ciò implica che quando ci spostiamo da una sottorete dell'insieme di Pareto a un'altra, dobbiamo sacrificare le prestazioni o la dimensione del modello ma migliorare l'altra. In definitiva, il set di Pareto ci offre la flessibilità di scegliere la sottorete che meglio si adatta alle nostre preferenze. Possiamo decidere quanto vogliamo ridurre le dimensioni della nostra rete e quante prestazioni siamo disposti a sacrificare.

Distribuisci il modello BERT ottimizzato e il modello di sottorete ottimizzato per NAS utilizzando SageMaker
Successivamente, distribuiamo il modello più grande nel nostro set di Pareto che porta alla minima quantità di degenerazione delle prestazioni a a Endpoint di SageMaker. Il modello migliore è quello che fornisce un compromesso ottimale tra l'errore di validazione e il numero di parametri per il nostro caso d'uso.
Confronto di modelli
Abbiamo preso un modello BERT di base pre-addestrato, lo abbiamo perfezionato utilizzando un set di dati specifico del dominio, abbiamo eseguito una ricerca NAS per identificare le sottoreti dominanti in base alle metriche oggettive e abbiamo distribuito il modello ridotto su un endpoint SageMaker. Inoltre, abbiamo preso il modello BERT di base pre-addestrato e lo abbiamo distribuito su un secondo endpoint SageMaker. Successivamente, abbiamo corso test di carico utilizzando Locust su entrambi gli endpoint di inferenza e valutando le prestazioni in termini di tempo di risposta.
Per prima cosa importiamo le librerie Locust e Boto3 necessarie. Quindi costruiamo i metadati della richiesta e registriamo l'ora di inizio da utilizzare per il test di carico. Quindi il payload viene passato all'API di richiamo dell'endpoint SageMaker tramite BotoClient per simulare le richieste degli utenti reali. Utilizziamo Locust per generare più utenti virtuali per inviare richieste in parallelo e misurare le prestazioni dell'endpoint sotto carico. I test vengono eseguiti aumentando rispettivamente il numero di utenti per ciascuno dei due endpoint. Una volta completati i test, Locust genera un file CSV delle statistiche della richiesta per ciascuno dei modelli distribuiti.
Successivamente, generiamo i grafici dei tempi di risposta dai file CSV scaricati dopo aver eseguito i test con Locust. Lo scopo di tracciare il tempo di risposta rispetto al numero di utenti è quello di analizzare i risultati del test di carico visualizzando l'impatto del tempo di risposta degli endpoint del modello. Nel grafico seguente, possiamo vedere che l'endpoint del modello eliminato dal NAS raggiunge un tempo di risposta inferiore rispetto all'endpoint del modello BERT di base.
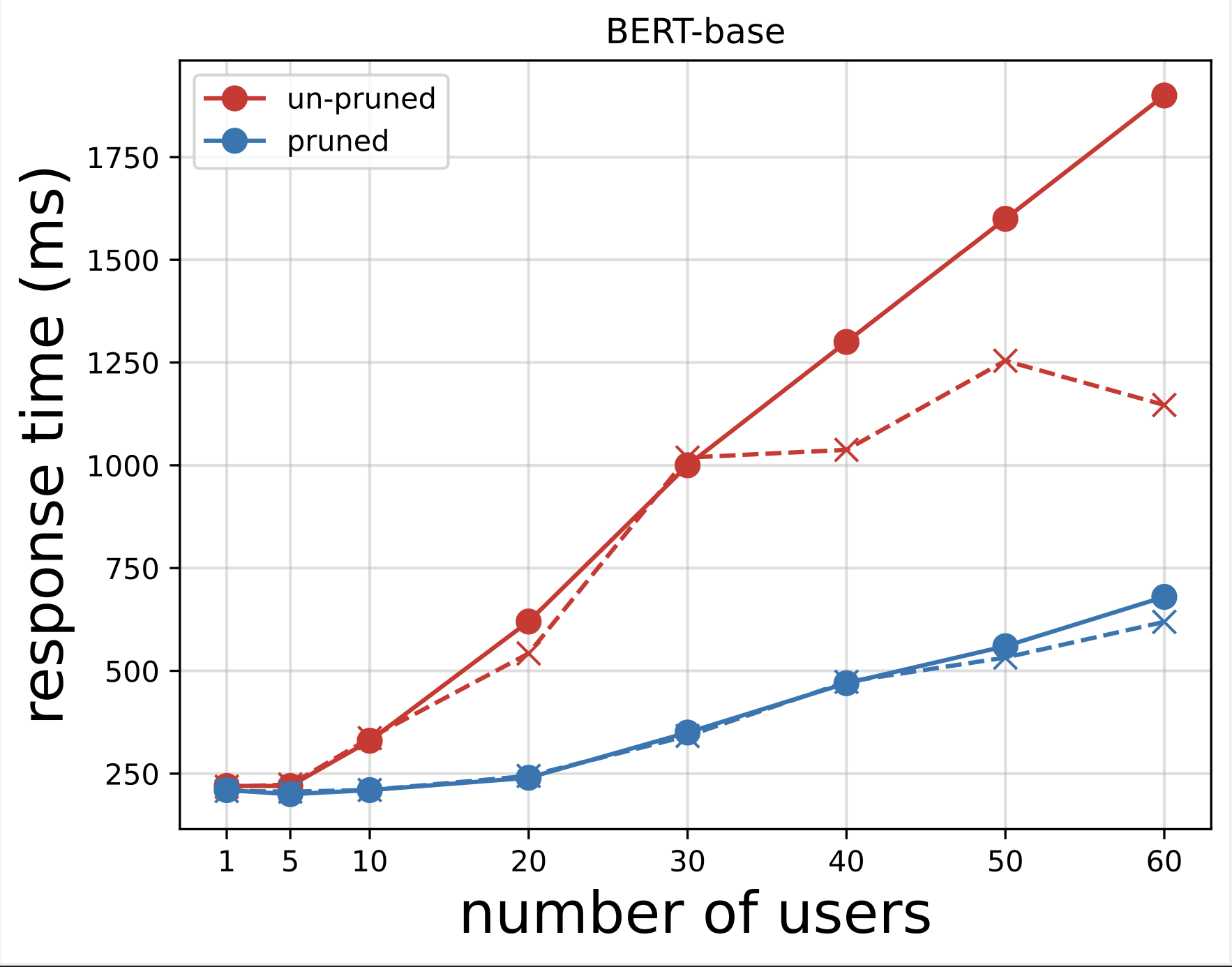
Nel secondo grafico, che è un'estensione del primo grafico, osserviamo che dopo circa 70 utenti, SageMaker inizia a limitare l'endpoint del modello BERT di base e genera un'eccezione. Tuttavia, per l'endpoint del modello eliminato dal NAS, la limitazione avviene tra 90 e 100 utenti e con un tempo di risposta inferiore.

Dai due grafici osserviamo che il modello ridotto ha un tempo di risposta più rapido e si adatta meglio rispetto al modello non ridotto. Man mano che si aumenta il numero di endpoint di inferenza, come nel caso degli utenti che distribuiscono un gran numero di endpoint di inferenza per le proprie applicazioni PLM, i vantaggi in termini di costi e il miglioramento delle prestazioni iniziano a diventare piuttosto sostanziali.
ripulire
Per eliminare gli endpoint SageMaker per il modello BERT di base ottimizzato e il modello eliminato NAS, completare i seguenti passaggi:
- Sulla console di SageMaker, scegli Inferenza ed endpoint nel pannello di navigazione.
- Seleziona l'endpoint ed eliminalo.
In alternativa, dal notebook SageMaker Studio, esegui i seguenti comandi fornendo i nomi degli endpoint:
Conclusione
In questo post abbiamo discusso di come utilizzare il NAS per eliminare un modello BERT ottimizzato. Per prima cosa abbiamo addestrato un modello BERT di base utilizzando dati specifici del dominio e lo abbiamo distribuito a un endpoint SageMaker. Abbiamo eseguito una ricerca multi-obiettivo sul modello BERT di base ottimizzato utilizzando SageMaker AMT per un'attività target. Abbiamo visualizzato il fronte Pareto e selezionato il modello BERT Pareto ottimale eliminato dal NAS e distribuito il modello su un secondo endpoint SageMaker. Abbiamo eseguito test di carico utilizzando Locust per simulare gli utenti che interrogavano entrambi gli endpoint e abbiamo misurato e registrato i tempi di risposta in un file CSV. Abbiamo tracciato il tempo di risposta rispetto al numero di utenti per entrambi i modelli.
Abbiamo osservato che il modello BERT ridotto ha ottenuto risultati significativamente migliori sia in termini di tempo di risposta che di soglia di limitazione delle istanze. Abbiamo concluso che il modello eliminato dal NAS era più resistente a un aumento del carico sull'endpoint, mantenendo un tempo di risposta inferiore anche quando un numero maggiore di utenti stressava il sistema rispetto al modello BERT di base. È possibile applicare la tecnica NAS descritta in questo post a qualsiasi modello linguistico di grandi dimensioni per trovare un modello ridotto in grado di eseguire l'attività di destinazione con tempi di risposta significativamente inferiori. È possibile ottimizzare ulteriormente l'approccio utilizzando la latenza come parametro oltre alla perdita di convalida.
Sebbene in questo post utilizziamo il NAS, la quantizzazione è un altro approccio comune utilizzato per ottimizzare e comprimere i modelli PLM. La quantizzazione riduce la precisione dei pesi e delle attivazioni in una rete addestrata da virgola mobile a 32 bit a larghezze di bit inferiori come interi a 8 bit o 16 bit, il che si traduce in un modello compresso che genera un'inferenza più rapida. La quantizzazione non riduce il numero di parametri; riduce invece la precisione dei parametri esistenti per ottenere un modello compresso. L'eliminazione del NAS rimuove le reti ridondanti in un PLM, creando un modello sparso con meno parametri. In genere, l'eliminazione e la quantizzazione del NAS vengono utilizzate insieme per comprimere PLM di grandi dimensioni per mantenere l'accuratezza del modello, ridurre le perdite di convalida migliorando al contempo le prestazioni e ridurre le dimensioni del modello. Le altre tecniche comunemente utilizzate per ridurre le dimensioni dei PLM includono distillazione della conoscenza, fattorizzazione di matricie cascate di distillazione.
L'approccio proposto nel post del blog è adatto ai team che utilizzano SageMaker per addestrare e mettere a punto i modelli utilizzando dati specifici del dominio e distribuire gli endpoint per generare inferenza. Se stai cercando un servizio completamente gestito che offra una scelta di modelli di base ad alte prestazioni necessari per creare applicazioni di intelligenza artificiale generativa, prendi in considerazione l'utilizzo Roccia Amazzonica. Se stai cercando modelli open source preaddestrati per un'ampia gamma di casi d'uso aziendali e desideri accedere a modelli di soluzioni e notebook di esempio, considera l'utilizzo JumpStart di Amazon SageMaker. Una versione pre-addestrata del modello con custodia base Hugging Face BERT che abbiamo utilizzato in questo post è disponibile anche presso SageMaker JumpStart.
Informazioni sugli autori
 Aparajithan Vaidyanathan è Principal Enterprise Solutions Architect presso AWS. È un Cloud Architect con oltre 24 anni di esperienza nella progettazione e nello sviluppo di sistemi software distribuiti, aziendali e su larga scala. È specializzato in intelligenza artificiale generativa e ingegneria dei dati con machine learning. È un aspirante maratoneta e i suoi hobby includono l'escursionismo, il ciclismo e passare il tempo con sua moglie e i suoi due figli.
Aparajithan Vaidyanathan è Principal Enterprise Solutions Architect presso AWS. È un Cloud Architect con oltre 24 anni di esperienza nella progettazione e nello sviluppo di sistemi software distribuiti, aziendali e su larga scala. È specializzato in intelligenza artificiale generativa e ingegneria dei dati con machine learning. È un aspirante maratoneta e i suoi hobby includono l'escursionismo, il ciclismo e passare il tempo con sua moglie e i suoi due figli.
 Aaron Klein è uno scienziato applicato senior presso AWS che lavora su metodi di machine learning automatizzati per reti neurali profonde.
Aaron Klein è uno scienziato applicato senior presso AWS che lavora su metodi di machine learning automatizzati per reti neurali profonde.
 Jacek Golebiowski è Sr Applied Scientist presso AWS.
Jacek Golebiowski è Sr Applied Scientist presso AWS.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/reduce-inference-time-for-bert-models-using-neural-architecture-search-and-sagemaker-automated-model-tuning/
- :ha
- :È
- :non
- :Dove
- ][P
- $ SU
- 1
- 10
- 100
- 11
- 12
- 13
- 15%
- 17
- 19
- 20
- 26
- 30
- 31
- 320
- 7
- 70
- 72
- 8
- 9
- a
- capacità
- capace
- accesso
- Il mio account
- precisione
- Raggiungere
- Realizza
- attivazioni
- aggiunta
- Adozione
- Dopo shavasana, sedersi in silenzio; saluti;
- AI
- puntare
- Mirare
- Algoritmi
- Tutti
- consentire
- Consentire
- consente
- anche
- Amazon
- Amazon Web Services
- quantità
- an
- .
- analitica
- analizzare
- ed
- Un altro
- rispondere
- in qualsiasi
- api
- applicazioni
- applicato
- APPLICA
- AMMISSIONE
- approccio
- approvazione
- circa
- architettura
- SONO
- RISERVATA
- aree
- argomenti
- in giro
- artificiale
- reti neurali artificiali
- AS
- aspirante
- addetto
- associato
- At
- il tentativo
- assistere
- Automatizzata
- apprendimento automatico automatizzato
- automatizza
- Automatico
- Automatizzare
- Automazione
- disponibile
- AWS
- Axis
- Equilibrio
- base
- basato
- BE
- diventare
- prima
- comportamento
- analisi comparativa
- vantaggi
- MIGLIORE
- Meglio
- fra
- Po
- stile di vita
- entrambi
- costruire
- affari
- Processo Di Business
- Business Process Automation
- ma
- by
- Materiale
- candidato
- funzionalità
- Custodie
- casi
- catalogo
- il cambiamento
- Grafico
- Grafici
- chatbots
- scegliere
- Scegli
- scelto
- classe
- classificazione
- Info su
- strettamente
- Cloud
- codice
- raccogliere
- collezione
- combinazioni
- Uncommon
- comunemente
- rispetto
- completamento di una
- Completato
- complesso
- complessità
- componenti
- computazionale
- Calcolare
- concetti
- concluso
- Prendere in considerazione
- consiste
- consolle
- vincoli
- costruire
- consumo
- contiene
- contenuto
- creazione di contenuti
- contesto
- continua
- contrasto
- controlli
- Corrispondente
- Costo
- Costi
- contare
- creare
- crea
- creazione
- cliente
- Servizio clienti
- dati
- scienza dei dati
- dataset
- datetime
- decide
- Decision Making
- dedicato
- deep
- reti neurali profonde
- definire
- definito
- definizione
- Dimo
- dimostrare
- Dipendente
- schierare
- schierato
- distribuzione
- Distribuisce
- descritta
- Design
- progettazione
- desiderato
- in via di sviluppo
- diverso
- discusso
- distribuito
- documento
- non
- dominante
- dominare
- Dont
- dovuto
- durante
- e
- ogni
- efficienza
- efficiente
- o
- endpoint
- endpoint
- Ingegneria
- Motori
- abbastanza
- entrare
- Impresa
- adozione aziendale
- Enterprise Solutions
- entità
- iscrizione
- Ambiente
- epoca
- errore
- Etere (ETH)
- valutare
- valutato
- valutazioni
- Anche
- eventi
- esempio
- Tranne
- eccezione
- esclusivamente
- esistente
- esperienza
- Spiegare
- ha spiegato
- estensione
- Faccia
- falso
- più veloce
- Caratteristiche
- feedback
- meno
- campo
- Compila il
- File
- finale
- Trovate
- ricerca
- Nome
- fisso
- Flessibilità
- galleggiante
- i seguenti
- Orma
- Nel
- essere trovato
- Fondazione
- da
- anteriore
- Frontier
- completamente
- function
- ulteriormente
- generare
- genera
- generativo
- AI generativa
- ottenere
- dato
- scopo
- GPU
- grigio
- accade
- Avere
- he
- capo
- teste
- assistenza sanitaria
- aiuta
- nascosto
- ad alte prestazioni
- superiore
- escursionismo
- il suo
- storia
- Hobby
- host
- ospitato
- ORE
- Come
- Tutorial
- Tuttavia
- HTML
- http
- HTTPS
- abbracciare il viso
- Ottimizzazione dell'iperparametro
- Sintonia iperparametro
- i
- identificare
- IDX
- if
- illustrare
- Impact
- impatti
- realizzare
- importare
- competenze
- migliorata
- miglioramento
- miglioramento
- in
- includere
- Aumento
- è aumentato
- crescente
- informazioni
- Infrastruttura
- ingresso
- esempio
- istanze
- invece
- Intelligente
- ai miglioramenti
- IT
- SUO
- Lavoro
- Offerte di lavoro
- jpg
- json
- conoscenze
- conosciuto
- Lingua
- grandi
- larga scala
- maggiore
- Latenza
- strato
- galline ovaiole
- Leads
- IMPARARE
- apprendimento
- meno
- lasciare
- biblioteche
- Biblioteca
- linea
- caricare
- ceppo
- registrazione
- cerca
- spento
- perdite
- inferiore
- macchina
- machine learning
- mantenere
- mantenimento
- uomo
- gestito
- Maratona
- mask
- matplotlib
- massimo
- Maggio..
- significato
- misurare
- misurato
- di misura
- medicale
- Soddisfare
- Memorie
- Metadati
- metodi
- metrico
- Metrica
- forza
- ridurre al minimo
- verbale
- ML
- modello
- modellismo
- modelli
- componibile
- Scopri di più
- cambiano
- molti
- multiplo
- devono obbligatoriamente:
- Nome
- Detto
- nomi
- alla
- Naturale
- Linguaggio naturale
- Elaborazione del linguaggio naturale
- Navigare
- Navigazione
- necessaria
- Bisogno
- di applicazione
- esigenze
- Rete
- reti
- Neurale
- rete neurale
- reti neurali
- GENERAZIONE
- nlp
- Nessuna
- Nota
- taccuino
- computer portatili
- adesso
- numero
- oggetto
- obiettivo
- Obiettivi d'Esame
- osservare
- osservato
- of
- MENO
- offrire
- Offerte
- on
- ONE
- online
- rivenditore online
- esclusivamente
- aprire
- open source
- ottimale
- ottimizzazione
- OTTIMIZZA
- ottimizzati
- Ottimizza
- ottimizzazione
- or
- minimo
- i
- Altro
- nostro
- su
- produzione
- uscite
- ancora
- complessivo
- panoramica
- proprio
- coppie
- vetro
- Parallel
- parametro
- parametri
- Pareto
- parte
- Passato
- sentiero
- paziente
- modelli
- eseguire
- performance
- eseguita
- esecuzione
- esegue
- permessi
- Platone
- Platone Data Intelligence
- PlatoneDati
- punto
- punti
- posizioni
- Post
- Precisione
- predizione
- predittiva
- Predictor
- preferenze
- preparato
- prerequisiti
- presenti
- in precedenza
- Direttore
- Problema
- processi
- Automazione di Processo
- i processi
- lavorazione
- Prodotto
- della produttività
- Strumenti di produttività
- proposto
- fornitore
- fornisce
- fornitura
- traino
- Maglioni
- scopo
- fini
- Python
- pytorch
- Domande e risposte
- domanda
- abbastanza
- casuale
- gamma
- veloce
- Crudo
- di rose
- riconoscimento
- riconoscere
- riconoscendo
- Consigli
- raccomandazioni
- record
- registrato
- Rosso
- ridurre
- Ridotto
- riduce
- regressione
- relazionato
- rimuove
- rimozione
- Report
- rappresentazione
- richiesta
- richiesto
- richieste
- necessario
- Requisiti
- elastico
- risorsa
- Risorse
- rispettivamente
- risposta
- Risultati
- rivenditore
- di ritegno
- problemi
- equitazione
- Rischio
- RIGA
- Correre
- corridore
- running
- corre
- s
- sacrificio
- sagemaker
- Inferenza di SageMaker
- Risparmi
- Scala
- bilancia
- Scienze
- Scienziato
- Punto
- copione
- Cerca
- Motori di ricerca
- ricerca
- Secondo
- Sezione
- vedere
- select
- selezionato
- AUTO
- inviare
- condanna
- sentimento
- Sequenza
- servizio
- Servizi
- Sessione
- set
- Set
- regolazione
- Spettacoli
- Segnali
- significativamente
- Un'espansione
- simultaneo
- contemporaneamente
- singolo
- Taglia
- inferiore
- So
- Software
- soluzione
- Soluzioni
- alcuni
- Fonte
- lo spazio
- Deporre le uova
- specializzata
- specializzata
- specifico
- in particolare
- Spendere
- dividere
- inizia a
- inizio
- Regione / Stato
- statistica
- step
- Passi
- conservazione
- strutturale
- strutturato
- studio
- sostanziale
- di successo
- Con successo
- tale
- adatto
- suite
- SOMMARIO
- sistema
- SISTEMI DI TRATTAMENTO
- T
- Fai
- prende
- Target
- Task
- task
- le squadre
- per l'esame
- tecniche
- modelli
- condizioni
- Testing
- test
- testo
- Classificazione del testo
- testuale
- di
- che
- Il
- loro
- poi
- Là.
- perciò
- Strumenti Bowman per analizzare le seguenti finiture:
- questo
- tre
- soglia
- Attraverso
- tempo
- volte
- a
- insieme
- token
- ha preso
- strumenti
- commercio
- Trading
- Treni
- allenato
- Training
- trasformatore
- trasformatori
- vero
- prova
- seconda
- Digitare
- Tipi di
- tipico
- tipicamente
- in definitiva
- per
- sottoposti
- e una comprensione reciproca
- unità
- us
- uso
- caso d'uso
- utilizzato
- Utente
- utenti
- usa
- utilizzando
- convalida
- APPREZZIAMO
- Valori
- versione
- via
- virtuale
- visualizzare
- vs
- volere
- Prima
- we
- sito web
- servizi web
- WELL
- quando
- se
- quale
- while
- OMS
- largo
- Vasta gamma
- ampiamente
- moglie
- wikipedia
- volere
- disposto
- con
- entro
- Lavora
- flusso di lavoro
- lavoro
- X
- anni
- dare la precedenza
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro