La resilienza gioca un ruolo fondamentale nello sviluppo di qualsiasi carico di lavoro e IA generativa i carichi di lavoro non sono diversi. Quando si progettano carichi di lavoro di intelligenza artificiale generativa attraverso una lente di resilienza, ci sono considerazioni uniche. Comprendere e dare priorità alla resilienza è fondamentale affinché i carichi di lavoro di intelligenza artificiale generativa soddisfino i requisiti di disponibilità organizzativa e di continuità aziendale. In questo post, discutiamo i diversi stack di un carico di lavoro di intelligenza artificiale generativa e quali dovrebbero essere queste considerazioni.
IA generativa a stack completo
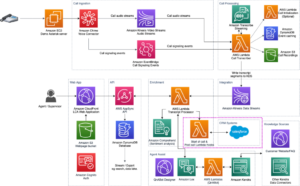
Sebbene gran parte dell’entusiasmo attorno all’intelligenza artificiale generativa si concentri sui modelli, una soluzione completa coinvolge persone, competenze e strumenti provenienti da diversi ambiti. Considera l'immagine seguente, che è una visione AWS dello stack di applicazioni emergenti a16z per modelli linguistici di grandi dimensioni (LLM).
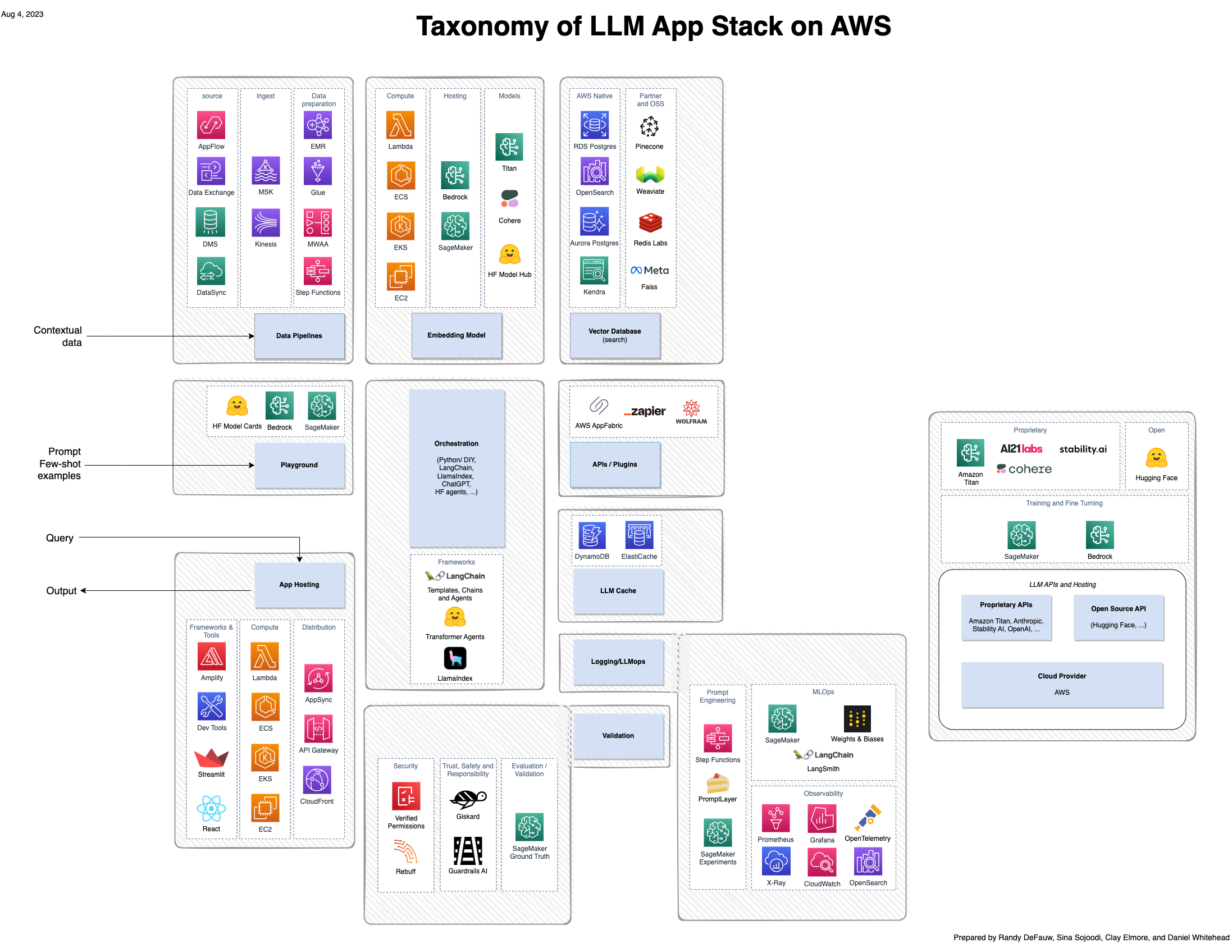
Rispetto a una soluzione più tradizionale basata sull’intelligenza artificiale e sull’apprendimento automatico (ML), una soluzione di intelligenza artificiale generativa ora prevede quanto segue:
- Nuovi ruoli – Devi considerare i preparatori di modelli così come i costruttori di modelli e gli integratori di modelli
- Nuovi strumenti – Lo stack MLOps tradizionale non si estende per coprire il tipo di tracciamento degli esperimenti o di osservabilità necessari per il prompt engineering o per gli agenti che invocano strumenti per interagire con altri sistemi
Ragionamento dell'agente
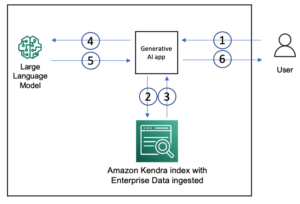
A differenza dei modelli tradizionali di intelligenza artificiale, il Retrieval Augmented Generation (RAG) consente risposte più accurate e contestualmente rilevanti integrando fonti di conoscenza esterne. Di seguito sono riportate alcune considerazioni sull'utilizzo di RAG:
- L'impostazione dei timeout appropriati è importante per l'esperienza del cliente. Non c'è niente di più indicativo di un'esperienza utente negativa che ritrovarsi nel bel mezzo di una chat e disconnettersi.
- Assicurati di convalidare i dati di input del prompt e la dimensione dell'input del prompt per i limiti di caratteri allocati definiti dal modello.
- Se stai eseguendo il prompt engineering, dovresti rendere persistenti i tuoi prompt in un archivio dati affidabile. Ciò salvaguarderà le tue richieste in caso di perdita accidentale o come parte della tua strategia complessiva di ripristino di emergenza.
Pipeline di dati
Nei casi in cui è necessario fornire dati contestuali al modello di fondazione utilizzando il modello RAG, è necessaria una pipeline di dati in grado di acquisire i dati di origine, convertirli in vettori di incorporamento e archiviare i vettori di incorporamento in un database vettoriale. Questa pipeline potrebbe essere una pipeline batch se prepari i dati contestuali in anticipo o una pipeline a bassa latenza se stai incorporando nuovi dati contestuali al volo. Nel caso batch, ci sono un paio di sfide rispetto alle tipiche pipeline di dati.
Le origini dati possono essere documenti PDF su un file system, dati da un sistema SaaS (Software as a Service) come uno strumento CRM o dati da un wiki o una knowledge base esistente. L'inserimento da queste origini è diverso dalle tipiche origini dati come i dati di registro in un file Servizio di archiviazione semplice Amazon (Amazon S3) o dati strutturati da un database relazionale. Il livello di parallelismo che è possibile ottenere potrebbe essere limitato dal sistema di origine, quindi è necessario tenere conto della limitazione e utilizzare tecniche di backoff. Alcuni dei sistemi di origine potrebbero essere fragili, quindi è necessario integrare la gestione degli errori e la logica dei tentativi.
Il modello di incorporamento potrebbe rappresentare un collo di bottiglia delle prestazioni, indipendentemente dal fatto che lo si esegua localmente nella pipeline o si chiami un modello esterno. I modelli di incorporamento sono modelli di base eseguiti su GPU e non hanno capacità illimitata. Se il modello viene eseguito localmente, è necessario assegnare il lavoro in base alla capacità della GPU. Se il modello viene eseguito esternamente, è necessario assicurarsi di non saturare il modello esterno. In entrambi i casi, il livello di parallelismo che è possibile ottenere sarà dettato dal modello di incorporamento piuttosto che dalla quantità di CPU e RAM disponibili nel sistema di elaborazione batch.
Nel caso di bassa latenza, è necessario tenere conto del tempo necessario per generare i vettori di incorporamento. L'applicazione chiamante deve richiamare la pipeline in modo asincrono.
Database vettoriali
Un database vettoriale ha due funzioni: memorizza i vettori incorporati ed esegue una ricerca di somiglianza per trovare quello più vicino k corrisponde a un nuovo vettore. Esistono tre tipi generali di database vettoriali:
- Opzioni SaaS dedicate come Pinecone.
- Funzionalità del database vettoriale integrate in altri servizi. Ciò include servizi AWS nativi come Servizio Amazon OpenSearch ed Amazon Aurora.
- Opzioni in memoria che possono essere usate per dati temporanei in scenari a bassa latenza.
Non trattiamo in dettaglio le funzionalità di ricerca per somiglianza in questo post. Sebbene siano importanti, rappresentano un aspetto funzionale del sistema e non influiscono direttamente sulla resilienza. Ci concentreremo invece sugli aspetti di resilienza di un database vettoriale come sistema di archiviazione:
- Latenza – Il database vettoriale può funzionare bene contro un carico elevato o imprevedibile? In caso contrario, l'applicazione chiamante deve gestire la limitazione della velocità, il backoff e riprovare.
- Scalabilità – Quanti vettori può contenere il sistema? Se superi la capacità del database vettoriale, dovrai esaminare lo sharding o altre soluzioni.
- Alta disponibilità e ripristino di emergenza – I vettori incorporati sono dati preziosi e ricrearli può essere costoso. Il tuo database vettoriale è altamente disponibile in una singola regione AWS? Ha la capacità di replicare i dati in un'altra regione a fini di ripristino di emergenza?
Livello dell'applicazione
Esistono tre considerazioni uniche per il livello applicativo quando si integrano soluzioni di intelligenza artificiale generativa:
- Latenza potenzialmente elevata – I modelli Foundation spesso vengono eseguiti su istanze GPU di grandi dimensioni e possono avere capacità limitata. Assicurati di utilizzare le migliori pratiche per la limitazione della velocità, il backoff, i nuovi tentativi e la riduzione del carico. Utilizza progetti asincroni in modo che la latenza elevata non interferisca con l'interfaccia principale dell'applicazione.
- Atteggiamento di sicurezza – Se utilizzi agenti, strumenti, plug-in o altri metodi per connettere un modello ad altri sistemi, presta particolare attenzione al tuo livello di sicurezza. I modelli potrebbero tentare di interagire con questi sistemi in modi inaspettati. Seguire la normale pratica di accesso con privilegi minimi, ad esempio limitando le richieste in arrivo da altri sistemi.
- Strutture in rapida evoluzione – I framework open source come LangChain si stanno evolvendo rapidamente. Utilizza un approccio basato sui microservizi per isolare altri componenti da questi framework meno maturi.
Ultra-Grande
Possiamo pensare alla capacità in due contesti: inferenza e pipeline di dati del modello di addestramento. La capacità è una considerazione da tenere in considerazione quando le organizzazioni costruiscono le proprie pipeline. I requisiti di CPU e memoria sono due dei requisiti più importanti quando si scelgono le istanze per eseguire i carichi di lavoro.
Le istanze in grado di supportare carichi di lavoro di intelligenza artificiale generativa possono essere più difficili da ottenere rispetto al tipo di istanza generica media. La flessibilità delle istanze può aiutare con la capacità e la pianificazione della capacità. A seconda della regione AWS in cui esegui il carico di lavoro, sono disponibili diversi tipi di istanze.
Per i percorsi utente critici, le organizzazioni vorranno prendere in considerazione la prenotazione o il pre-provisioning dei tipi di istanze per garantire la disponibilità quando necessario. Questo modello consente di ottenere un'architettura staticamente stabile, che rappresenta una procedura consigliata per la resilienza. Per ulteriori informazioni sulla stabilità statica nel pilastro di affidabilità del Canone di architettura AWS, fare riferimento a Utilizzare la stabilità statica per prevenire il comportamento bimodale.
osservabilità
Oltre alle metriche delle risorse che in genere raccogli, come l'utilizzo della CPU e della RAM, devi monitorare attentamente l'utilizzo della GPU se ospiti un modello su Amazon Sage Maker or Cloud di calcolo elastico di Amazon (Amazon EC2). L'utilizzo della GPU può cambiare in modo imprevisto se cambiano il modello di base o i dati di input e l'esaurimento della memoria della GPU può mettere il sistema in uno stato instabile.
Più in alto nello stack, vorrai anche tracciare il flusso delle chiamate attraverso il sistema, catturando le interazioni tra agenti e strumenti. Poiché l'interfaccia tra agenti e strumenti è definita in modo meno formale rispetto a un contratto API, è necessario monitorare queste tracce non solo per le prestazioni ma anche per acquisire nuovi scenari di errore. Per monitorare il modello o l'agente per eventuali rischi e minacce alla sicurezza, è possibile utilizzare strumenti come Amazon Guard Duty.
Dovresti anche acquisire le linee di base per l'incorporamento di vettori, prompt, contesto e output e le interazioni tra questi. Se questi cambiano nel tempo, potrebbe indicare che gli utenti stanno utilizzando il sistema in modi nuovi, che i dati di riferimento non coprono lo spazio delle domande nello stesso modo o che l'output del modello è improvvisamente diverso.
Disaster recovery
Avere un piano di continuità aziendale con una strategia di ripristino di emergenza è fondamentale per qualsiasi carico di lavoro. I carichi di lavoro dell’intelligenza artificiale generativa non sono diversi. Comprendere le modalità di errore applicabili al tuo carico di lavoro ti aiuterà a guidare la tua strategia. Se utilizzi servizi gestiti AWS per il tuo carico di lavoro, ad esempio Roccia Amazzonica e SageMaker, assicurati che il servizio sia disponibile nella tua regione AWS di ripristino. Al momento della stesura di questo documento, questi servizi AWS non supportano la replica dei dati tra regioni AWS in modo nativo, quindi è necessario pensare alle strategie di gestione dei dati per il ripristino di emergenza e potrebbe anche essere necessario ottimizzare più regioni AWS.
Conclusione
Questo post descrive come tenere conto della resilienza quando si creano soluzioni di intelligenza artificiale generativa. Sebbene le applicazioni di intelligenza artificiale generativa presentino alcune sfumature interessanti, i modelli di resilienza esistenti e le migliori pratiche continuano ad applicarsi. Si tratta solo di valutare ogni parte di un'applicazione di intelligenza artificiale generativa e di applicare le migliori pratiche pertinenti.
Per ulteriori informazioni sull'intelligenza artificiale generativa e sul suo utilizzo con i servizi AWS, fare riferimento alle seguenti risorse:
Informazioni sugli autori
 Jennifer Moran è un AWS Senior Resiliency Specialist Solutions Architect con sede a New York City. Ha un background diversificato, avendo lavorato in molte discipline tecniche, tra cui sviluppo software, leadership agile e DevOps, ed è una sostenitrice delle donne nella tecnologia. Le piace aiutare i clienti a progettare soluzioni resilienti per migliorare la postura di resilienza e parla pubblicamente di tutti gli argomenti relativi alla resilienza.
Jennifer Moran è un AWS Senior Resiliency Specialist Solutions Architect con sede a New York City. Ha un background diversificato, avendo lavorato in molte discipline tecniche, tra cui sviluppo software, leadership agile e DevOps, ed è una sostenitrice delle donne nella tecnologia. Le piace aiutare i clienti a progettare soluzioni resilienti per migliorare la postura di resilienza e parla pubblicamente di tutti gli argomenti relativi alla resilienza.
 Randy De Fauw è un Senior Principal Solutions Architect presso AWS. Ha conseguito un MSEE presso l'Università del Michigan, dove ha lavorato sulla visione artificiale per veicoli autonomi. Ha inoltre conseguito un MBA presso la Colorado State University. Randy ha ricoperto diversi incarichi nel settore tecnologico, dall'ingegneria del software alla gestione del prodotto. È entrato nello spazio dei big data nel 2013 e continua a esplorare quell'area. Sta lavorando attivamente a progetti nello spazio ML e ha presentato in numerose conferenze, tra cui Strata e GlueCon.
Randy De Fauw è un Senior Principal Solutions Architect presso AWS. Ha conseguito un MSEE presso l'Università del Michigan, dove ha lavorato sulla visione artificiale per veicoli autonomi. Ha inoltre conseguito un MBA presso la Colorado State University. Randy ha ricoperto diversi incarichi nel settore tecnologico, dall'ingegneria del software alla gestione del prodotto. È entrato nello spazio dei big data nel 2013 e continua a esplorare quell'area. Sta lavorando attivamente a progetti nello spazio ML e ha presentato in numerose conferenze, tra cui Strata e GlueCon.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/designing-generative-ai-workloads-for-resilience/
- :ha
- :È
- :non
- :Dove
- $ SU
- 100
- 2013
- 90
- a
- a16z
- capacità
- Chi siamo
- accesso
- accidentale
- Il mio account
- preciso
- Raggiungere
- Realizza
- operanti in
- attivamente
- avanzare
- avvocato
- influenzare
- contro
- Agente
- agenti
- agile
- AI
- Modelli AI
- Tutti
- allocato
- consente
- anche
- Sebbene il
- Amazon
- Amazon EC2
- Amazon Web Services
- an
- ed
- Un altro
- in qualsiasi
- api
- App
- applicabile
- Applicazioni
- applicazioni
- APPLICA
- AMMISSIONE
- approccio
- opportuno
- architettura
- SONO
- RISERVATA
- in giro
- AS
- aspetto
- aspetti
- At
- attenzione
- aumentata
- autonomo
- veicoli autonomi
- disponibilità
- disponibile
- media
- AWS
- sfondo
- Vasca
- base
- basato
- BE
- perché
- essendo
- MIGLIORE
- best practice
- fra
- Big
- Big Data
- Maggiore
- collo di bottiglia
- costruire
- costruttori
- Costruzione
- costruito
- affari
- business continuity
- ma
- by
- chiamata
- chiamata
- Bandi
- Materiale
- funzionalità
- Ultra-Grande
- catturare
- Catturare
- Custodie
- casi
- sfide
- il cambiamento
- Modifiche
- carattere
- chiacchierare
- la scelta
- Città
- strettamente
- raccogliere
- Colorado
- rispetto
- completamento di una
- componenti
- Calcolare
- computer
- Visione computerizzata
- conferenze
- Collegamento
- Prendere in considerazione
- considerazione
- Considerazioni
- contesto
- contesti
- contestuale
- continua
- continuità
- contratto
- convertire
- potuto
- Coppia
- coprire
- copertura
- CPU
- critico
- CRM
- cruciale
- cliente
- esperienza del cliente
- Clienti
- dati
- gestione dei dati
- Banca Dati
- banche dati
- definito
- Dipendente
- descritta
- Design
- progettazione
- disegni
- dettaglio
- Mercato
- DevOps
- dettato
- diverso
- difficile
- direttamente
- disastro
- discipline
- scollegato
- discutere
- paesaggio differenziato
- do
- documenti
- effettua
- non
- domini
- Dont
- ogni
- o
- incorporamento
- emergenti del mondo
- Ingegneria
- garantire
- inserito
- errore
- Etere (ETH)
- la valutazione
- evoluzione
- esempio
- superare
- Eccitazione
- esistente
- costoso
- esperienza
- esperimento
- esplora
- estendere
- esterno
- esternamente
- extra
- Fallimento
- Caratteristiche
- Compila il
- Trovare
- Flessibilità
- flusso
- Focus
- si concentra
- seguire
- i seguenti
- Nel
- formalmente
- Fondazione
- Contesto
- quadri
- da
- funzionale
- funzioni
- Generale
- scopo generale
- generare
- ELETTRICA
- generativo
- AI generativa
- ottenere
- GPU
- GPU
- guida
- maniglia
- Manovrabilità
- Avere
- avendo
- he
- Eroe
- Aiuto
- aiutare
- Alta
- vivamente
- tenere
- detiene
- host
- Come
- Tutorial
- HTML
- http
- HTTPS
- if
- importante
- competenze
- in
- inclusi
- Compreso
- In arrivo
- incorporando
- indicare
- informazioni
- ingresso
- esempio
- istanze
- invece
- Integrazione
- interagire
- interazioni
- interessante
- Interfaccia
- interferire
- ai miglioramenti
- comporta
- IT
- Journeys
- ad appena
- conoscenze
- Lingua
- grandi
- Latenza
- Leadership
- IMPARARE
- apprendimento
- lente
- meno
- Livello
- piace
- Limitato
- limitativo
- limiti
- lm
- caricare
- a livello locale
- ceppo
- logica
- Guarda
- spento
- lotto
- macchina
- machine learning
- Principale
- make
- gestito
- gestione
- molti
- fiammiferi
- Importanza
- alunni
- Maggio..
- MBA
- Soddisfare
- Memorie
- metodi
- Metrica
- Michigan
- microservices
- In mezzo
- ML
- MLOp
- modello
- modelli
- modalità di
- Monitorare
- Scopri di più
- molti
- multiplo
- devono obbligatoriamente:
- nativo
- nativamente
- necessaria
- Bisogno
- di applicazione
- esigenze
- New
- New York
- New York City
- no
- normale
- Niente
- adesso
- ombreggiatura
- numerose
- ottenere
- of
- di frequente
- on
- esclusivamente
- aprire
- open source
- Opzioni
- or
- organizzativa
- organizzazioni
- Altro
- su
- produzione
- ancora
- complessivo
- proprio
- parte
- Cartamodello
- modelli
- Paga le
- Persone
- eseguire
- performance
- esecuzione
- immagine
- Pilastro
- conduttura
- centrale
- piano
- pianificazione
- Platone
- Platone Data Intelligence
- PlatoneDati
- gioca
- i plugin
- posizioni
- Post
- pratica
- pratiche
- Preparare
- presentata
- prevenire
- Direttore
- prioritizzazione
- lavorazione
- Prodotto
- gestione del prodotto
- progetti
- istruzioni
- fornire
- pubblicamente
- fini
- metti
- domanda
- straccio
- RAM
- che vanno
- rapidamente
- tasso
- piuttosto
- recupero
- riferimento
- riferimento
- Indipendentemente
- regione
- regioni
- relazionato
- pertinente
- problemi di
- affidabile
- replicazione
- Requisiti
- elasticità
- elastico
- risorsa
- Risorse
- risposte
- limitando
- richiamo
- rischi
- Ruolo
- Correre
- running
- corre
- SaaS
- sagemaker
- stesso
- dice
- Scenari
- Cerca
- ricerca
- problemi di
- rischi per la sicurezza
- anziano
- servizio
- Servizi
- alcuni
- sharding
- lei
- muta
- dovrebbero
- Un'espansione
- singolo
- Taglia
- abilità
- So
- Software
- software come un servizio
- lo sviluppo del software
- Ingegneria del software
- soluzione
- Soluzioni
- alcuni
- Fonte
- fonti
- lo spazio
- Parla
- specialista
- Stabilità
- stabile
- pila
- Stacks
- Regione / Stato
- Ancora
- conservazione
- Tornare al suo account
- strategie
- Strategia
- strutturato
- tale
- supporto
- sicuro
- sistema
- SISTEMI DI TRATTAMENTO
- Fai
- prende
- tassonomia
- Tech
- Consulenza
- tecniche
- Tecnologia
- di
- che
- I
- L’ORIGINE
- loro
- Li
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- think
- questo
- quelli
- minacce
- tre
- Attraverso
- fila
- tempo
- a
- strumenti
- Argomenti
- tracciare
- Tracking
- tradizionale
- Training
- prova
- seconda
- Digitare
- Tipi di
- tipico
- tipicamente
- e una comprensione reciproca
- Inaspettato
- unico
- Università
- University of Michigan
- illimitato
- imprevedibile
- uso
- utilizzato
- Utente
- Esperienza da Utente
- utenti
- utilizzando
- CONVALIDARE
- Prezioso
- varietà
- Veicoli
- Visualizza
- visione
- volere
- Modo..
- modi
- we
- sito web
- servizi web
- WELL
- Che
- quando
- se
- quale
- volere
- con
- Donna
- donne in tecnologia
- Lavora
- lavorato
- lavoro
- scrittura
- York
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro