OpenAI Whisper è un modello avanzato di riconoscimento vocale automatico (ASR) con licenza MIT. La tecnologia ASR trova utilità nei servizi di trascrizione, negli assistenti vocali e nel miglioramento dell'accessibilità per le persone con problemi di udito. Questo modello all’avanguardia è addestrato su un vasto e diversificato set di dati multilingue e multitasking raccolti dal web. La sua elevata precisione e adattabilità lo rendono una risorsa preziosa per un'ampia gamma di attività legate alla voce.
Nel panorama in continua evoluzione del machine learning e dell’intelligenza artificiale, Amazon Sage Maker fornisce un ecosistema completo. SageMaker consente a data scientist, sviluppatori e organizzazioni di sviluppare, addestrare, distribuire e gestire modelli di machine learning su larga scala. Offrendo un'ampia gamma di strumenti e funzionalità, semplifica l'intero flusso di lavoro del machine learning, dalla pre-elaborazione dei dati e dallo sviluppo del modello alla semplice implementazione e monitoraggio. L’interfaccia user-friendly di SageMaker la rende una piattaforma fondamentale per sbloccare tutto il potenziale dell’intelligenza artificiale, affermandola come una soluzione rivoluzionaria nel regno dell’intelligenza artificiale.
In questo post, ci imbarchiamo in un'esplorazione delle capacità di SageMaker, concentrandoci in particolare sull'hosting di modelli Whisper. Approfondiremo due metodi per farlo: uno utilizzando il modello Whisper PyTorch e l'altro utilizzando l'implementazione Hugging Face del modello Whisper. Inoltre, condurremo un esame approfondito delle opzioni di inferenza di SageMaker, confrontandole su parametri quali velocità, costo, dimensione del carico utile e scalabilità. Questa analisi consente agli utenti di prendere decisioni informate quando integrano i modelli Whisper nei loro casi d'uso e sistemi specifici.
Panoramica della soluzione
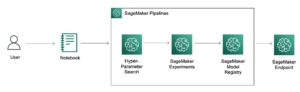
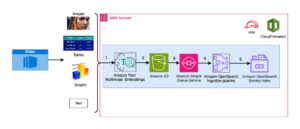
Lo schema seguente mostra i componenti principali di questa soluzione.
- Per ospitare il modello su Amazon SageMaker, il primo passaggio è salvare gli artefatti del modello. Questi artefatti si riferiscono ai componenti essenziali di un modello di machine learning necessario per varie applicazioni, inclusa la distribuzione e la riqualificazione. Possono includere parametri del modello, file di configurazione, componenti di pre-elaborazione, nonché metadati, come dettagli della versione, paternità ed eventuali note relative alle sue prestazioni. È importante notare che i modelli Whisper per le implementazioni PyTorch e Hugging Face sono costituiti da diversi artefatti del modello.
- Successivamente, creiamo script di inferenza personalizzati. All'interno di questi script definiamo come caricare il modello e specifichiamo il processo di inferenza. Qui è anche dove possiamo incorporare parametri personalizzati secondo necessità. Inoltre, puoi elencare i pacchetti Python richiesti in un file
requirements.txtfile. Durante la distribuzione del modello, questi pacchetti Python vengono installati automaticamente nella fase di inizializzazione. - Quindi selezioniamo i contenitori di deep learning (DLC) PyTorch o Hugging Face forniti e gestiti da AWS. Questi contenitori sono immagini Docker predefinite con framework di deep learning e altri pacchetti Python necessari. Per ulteriori informazioni, puoi controllare questo link.
- Con gli artefatti del modello, gli script di inferenza personalizzati e i DLC selezionati, creeremo modelli Amazon SageMaker rispettivamente per PyTorch e Hugging Face.
- Infine, i modelli possono essere distribuiti su SageMaker e utilizzati con le seguenti opzioni: endpoint di inferenza in tempo reale, processi di trasformazione batch ed endpoint di inferenza asincrona. Approfondiremo queste opzioni in modo più dettagliato più avanti in questo post.
Il notebook di esempio e il codice per questa soluzione sono disponibili qui Repository GitHub.
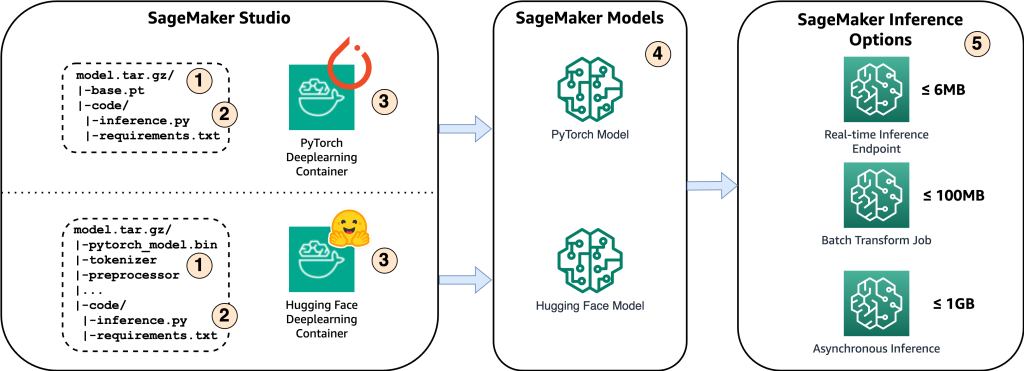
Figura 1. Panoramica dei componenti chiave della soluzione
Soluzione
Hosting del modello Whisper su Amazon SageMaker
In questa sezione, spiegheremo i passaggi per ospitare il modello Whisper su Amazon SageMaker, utilizzando rispettivamente PyTorch e Hugging Face Frameworks. Per sperimentare questa soluzione è necessario un account AWS e l'accesso al servizio Amazon SageMaker.
Quadro PyTorch
- Salva gli artefatti del modello
La prima opzione per ospitare il modello è utilizzare il file Pacchetto Python ufficiale di Whisper, che può essere installato utilizzando pip install openai-whisper. Questo pacchetto fornisce un modello PyTorch. Quando si salvano gli artefatti del modello nel repository locale, il primo passo è salvare i parametri apprendibili del modello, come pesi e bias del modello di ogni strato nella rete neurale, come file "pt". Puoi scegliere tra diverse dimensioni del modello, tra cui "minuscolo", "base", "piccolo", "medio" e "grande". Le dimensioni del modello più grandi offrono prestazioni di precisione più elevate, ma comportano una latenza di inferenza più lunga. Inoltre, è necessario salvare il dizionario dello stato del modello e il dizionario delle dimensioni, che contengono un dizionario Python che mappa ogni livello o parametro del modello PyTorch ai parametri apprendibili corrispondenti, insieme ad altri metadati e configurazioni personalizzate. Il codice seguente mostra come salvare gli artefatti Whisper PyTorch.
- Seleziona DLC
Il prossimo passo è selezionare il DLC precostruito da questo link. Fai attenzione quando scegli l'immagine corretta considerando le seguenti impostazioni: framework (PyTorch), versione del framework, attività (inferenza), versione Python e hardware (ad esempio GPU). Si consiglia di utilizzare le versioni più recenti del framework e di Python quando possibile, poiché ciò si traduce in prestazioni migliori e risolve problemi noti e bug delle versioni precedenti.
- Crea modelli Amazon SageMaker
Successivamente, utilizziamo il SDK Python di SageMaker per creare modelli PyTorch. È importante ricordare di aggiungere variabili di ambiente durante la creazione di un modello PyTorch. Per impostazione predefinita, TorchServe può elaborare solo file di dimensioni fino a 6 MB, indipendentemente dal tipo di inferenza utilizzato.
La tabella seguente mostra le impostazioni per le diverse versioni di PyTorch:
| Contesto | Variabili ambientali |
| PyTorch 1.8 (basato su TorchServe) | 'TS_MAX_REQUEST_SIZE': '100000000'' TS_MAX_RESPONSE_SIZE': '100000000'' TS_DEFAULT_RESPONSE_TIMEOUT': '1000' |
| PyTorch 1.4 (basato su MMS) | 'MMS_MAX_REQUEST_SIZE': '1000000000'' MMS_MAX_RESPONSE_SIZE': '1000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- Definire il metodo di caricamento del modello in inference.py
nella consuetudine inference.py script, controlliamo innanzitutto la disponibilità di una GPU compatibile con CUDA. Se una GPU di questo tipo è disponibile, assegniamo il file 'cuda' dispositivo per il DEVICE variabile; in caso contrario, assegniamo il 'cpu' dispositivo. Questo passaggio garantisce che il modello venga posizionato sull'hardware disponibile per un calcolo efficiente. Carichiamo il modello PyTorch utilizzando il pacchetto Whisper Python.
Quadro del viso abbracciante
- Salva gli artefatti del modello
La seconda opzione è usare Il sussurro di Face che abbraccia implementazione. Il modello può essere caricato utilizzando il file AutoModelForSpeechSeq2Seq classe dei trasformatori. I parametri apprendibili vengono salvati in un file binario (bin) utilizzando il file save_pretrained metodo. Anche il tokenizzatore e il preprocessore devono essere salvati separatamente per garantire il corretto funzionamento del modello Hugging Face. In alternativa, puoi distribuire un modello su Amazon SageMaker direttamente da Hugging Face Hub impostando due variabili di ambiente: HF_MODEL_ID ed HF_TASK. Per ulteriori informazioni, fare riferimento a questo pagina web.
- Seleziona DLC
Similmente al framework PyTorch, puoi scegliere un DLC Hugging Face precostruito dallo stesso link. Assicurati di selezionare un DLC che supporti gli ultimi trasformatori Hugging Face e includa il supporto GPU.
- Crea modelli Amazon SageMaker
Allo stesso modo, utilizziamo il SDK Python di SageMaker per creare modelli di facce abbracciate. Il modello Hugging Face Whisper ha una limitazione predefinita in cui può elaborare solo segmenti audio fino a 30 secondi. Per risolvere questa limitazione, è possibile includere il file chunk_length_s parametro nella variabile di ambiente durante la creazione del modello Hugging Face e successivamente passare questo parametro nello script di inferenza personalizzato durante il caricamento del modello. Infine, imposta le variabili di ambiente per aumentare le dimensioni del payload e il timeout della risposta per il contenitore Hugging Face.
| Contesto | Variabili ambientali |
|
Contenitore di inferenza HuggingFace (basato su MMS) |
'MMS_MAX_REQUEST_SIZE': '2000000000'' MMS_MAX_RESPONSE_SIZE': '2000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- Definire il metodo di caricamento del modello in inference.py
Quando creiamo uno script di inferenza personalizzato per il modello Hugging Face, utilizziamo una pipeline che ci consente di passare il file chunk_length_s come parametro. Questo parametro consente al modello di elaborare in modo efficiente file audio lunghi durante l'inferenza.
Esplorazione di diverse opzioni di inferenza su Amazon SageMaker
I passaggi per selezionare le opzioni di inferenza sono gli stessi per entrambi i modelli PyTorch e Hugging Face, quindi non li distingueremo di seguito. Tuttavia, vale la pena notare che, al momento della stesura di questo post, il inferenza senza server L'opzione di SageMaker non supporta le GPU e, di conseguenza, escludiamo questa opzione per questo caso d'uso.
Possiamo implementare il modello come endpoint in tempo reale, fornendo risposte in millisecondi. Tuttavia, è importante notare che questa opzione è limitata all'elaborazione di input inferiori a 6 MB. Definiamo il serializzatore come un serializzatore audio, responsabile della conversione dei dati di input in un formato adatto per il modello distribuito. Utilizziamo un'istanza GPU per l'inferenza, consentendo l'elaborazione accelerata dei file audio. L'input dell'inferenza è un file audio proveniente dal repository locale.
La seconda opzione di inferenza è il processo di trasformazione batch, in grado di elaborare payload di input fino a 100 MB. Tuttavia, questo metodo potrebbe richiedere alcuni minuti di latenza. Ogni istanza può gestire solo una richiesta batch alla volta e anche l'avvio e l'arresto dell'istanza richiedono alcuni minuti. I risultati dell'inferenza vengono salvati in un Amazon Simple Storage Service (Amazon S3) bucket al completamento del processo di trasformazione batch.
Quando si configura il trasformatore batch, assicurarsi di includere max_payload = 100 per gestire efficacemente carichi utili più grandi. L'input di inferenza deve essere il percorso Amazon S3 di un file audio o di una cartella del bucket Amazon S3 contenente un elenco di file audio, ciascuno con una dimensione inferiore a 100 MB.
La trasformazione batch suddivide gli oggetti Amazon S3 nell'input in base alla chiave e mappa gli oggetti Amazon S3 sulle istanze. Ad esempio, quando disponi di più file audio, un'istanza potrebbe elaborare input1.wav e un'altra istanza potrebbe elaborare il file denominato input2.wav per migliorare la scalabilità. La trasformazione batch consente di configurare max_concurrent_transforms per aumentare il numero di richieste HTTP effettuate ad ogni singolo contenitore trasformatore. Tuttavia, è importante notare che il valore di (max_concurrent_transforms* max_payload) non deve superare i 100 MB.
Infine, Amazon SageMaker Asynchronous Inference è ideale per elaborare più richieste contemporaneamente, offrendo una latenza moderata e supportando payload di input fino a 1 GB. Questa opzione fornisce un'eccellente scalabilità, consentendo la configurazione di un gruppo di scalabilità automatica per l'endpoint. Quando si verifica un aumento di richieste, si ridimensiona automaticamente per gestire il traffico e, una volta elaborate tutte le richieste, l'endpoint si riduce a 0 per risparmiare sui costi.
Utilizzando l'inferenza asincrona, i risultati vengono automaticamente salvati in un bucket Amazon S3. Nel AsyncInferenceConfig, è possibile configurare le notifiche per i completamenti riusciti o non riusciti. Il percorso di input punta a una posizione Amazon S3 del file audio. Per ulteriori dettagli fare riferimento al codice su GitHub.
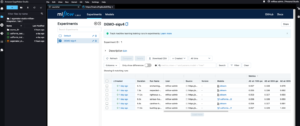
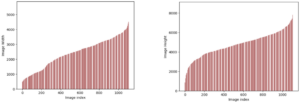
Opzionale: Come accennato in precedenza, abbiamo la possibilità di configurare un gruppo di scalabilità automatica per l'endpoint di inferenza asincrona, che gli consente di gestire un improvviso aumento delle richieste di inferenza. In questo viene fornito un esempio di codice Repository GitHub. Nel diagramma seguente è possibile osservare un grafico a linee che mostra due metriche da Amazon Cloud Watch: ApproximateBacklogSize ed ApproximateBacklogSizePerInstance. Inizialmente, quando venivano attivate 1000 richieste, era disponibile solo un'istanza per gestire l'inferenza. Per tre minuti, la dimensione del backlog ha costantemente superato tre (tieni presente che questi numeri possono essere configurati) e il gruppo di scalabilità automatica ha risposto avviando ulteriori istanze per eliminare in modo efficiente il backlog. Ciò ha comportato una significativa diminuzione del ApproximateBacklogSizePerInstance, consentendo di elaborare le richieste di arretrato molto più rapidamente rispetto alla fase iniziale.

Figura 2. Grafico a linee che illustra le modifiche temporali nei parametri Amazon CloudWatch
Analisi comparativa per le opzioni di inferenza
I confronti tra le diverse opzioni di inferenza si basano su casi d'uso comuni di elaborazione audio. L'inferenza in tempo reale offre la velocità di inferenza più elevata ma limita la dimensione del payload a 6 MB. Questo tipo di inferenza è adatto per i sistemi di comando audio, in cui gli utenti controllano o interagiscono con dispositivi o software utilizzando comandi vocali o istruzioni vocali. I comandi vocali sono in genere di piccole dimensioni e una bassa latenza di inferenza è fondamentale per garantire che i comandi trascritti possano attivare tempestivamente le azioni successive. La trasformazione batch è ideale per le attività offline pianificate, quando la dimensione di ciascun file audio è inferiore a 100 MB e non sono previsti requisiti specifici per tempi di risposta rapidi per l'inferenza. L'inferenza asincrona consente caricamenti fino a 1 GB e offre una latenza di inferenza moderata. Questo tipo di inferenza è particolarmente adatto per la trascrizione di film, serie TV e conferenze registrate in cui è necessario elaborare file audio di grandi dimensioni.
Sia le opzioni di inferenza in tempo reale che quelle asincrone forniscono funzionalità di scalabilità automatica, consentendo alle istanze dell'endpoint di aumentare o diminuire automaticamente in base al volume delle richieste. Nei casi senza richieste, la scalabilità automatica rimuove le istanze non necessarie, aiutandoti a evitare i costi associati alle istanze con provisioning che non sono attivamente in uso. Tuttavia, per l'inferenza in tempo reale, è necessario conservare almeno un'istanza persistente, il che potrebbe comportare costi più elevati se l'endpoint funziona ininterrottamente. Al contrario, l'inferenza asincrona consente di ridurre il volume dell'istanza a 0 quando non viene utilizzato. Quando si configura un processo di trasformazione batch, è possibile utilizzare più istanze per elaborare il processo e regolare max_concurrent_transforms per consentire a un'istanza di gestire più richieste. Pertanto, tutte e tre le opzioni di inferenza offrono una grande scalabilità.
Pulire
Una volta completato l'utilizzo della soluzione, assicurati di rimuovere gli endpoint SageMaker per evitare di incorrere in costi aggiuntivi. È possibile utilizzare il codice fornito per eliminare rispettivamente gli endpoint di inferenza in tempo reale e asincrona.
Conclusione
In questo post ti abbiamo mostrato come l'implementazione di modelli di machine learning per l'elaborazione audio sia diventata sempre più essenziale in vari settori. Prendendo come esempio il modello Whisper, abbiamo dimostrato come ospitare modelli ASR open source su Amazon SageMaker utilizzando gli approcci PyTorch o Hugging Face. L'esplorazione ha compreso varie opzioni di inferenza su Amazon SageMaker, offrendo approfondimenti sulla gestione efficiente dei dati audio, sulla formulazione di previsioni e sulla gestione efficace dei costi. Questo post mira a fornire conoscenze a ricercatori, sviluppatori e data scientist interessati a sfruttare il modello Whisper per attività relative all'audio e a prendere decisioni informate sulle strategie di inferenza.
Per informazioni più dettagliate sulla distribuzione dei modelli su SageMaker, fare riferimento a questo Guida per gli sviluppatori. Inoltre, il modello Whisper può essere distribuito utilizzando SageMaker JumpStart. Per ulteriori dettagli, si prega di controllare il Modelli Whisper per il riconoscimento vocale automatico ora disponibili in Amazon SageMaker JumpStart inviare.
Sentiti libero di controllare il taccuino e il codice per questo progetto su GitHub e condividi il tuo commento con noi.
L'autore
 Ying Hou, dottorato di ricerca, è un architetto di prototipazione di machine learning presso AWS. Le sue principali aree di interesse comprendono il deep learning, con particolare attenzione alla GenAI, alla visione artificiale, alla PNL e alla previsione dei dati delle serie temporali. Nel tempo libero ama trascorrere momenti di qualità con la sua famiglia, immergersi nei romanzi e fare escursioni nei parchi nazionali del Regno Unito.
Ying Hou, dottorato di ricerca, è un architetto di prototipazione di machine learning presso AWS. Le sue principali aree di interesse comprendono il deep learning, con particolare attenzione alla GenAI, alla visione artificiale, alla PNL e alla previsione dei dati delle serie temporali. Nel tempo libero ama trascorrere momenti di qualità con la sua famiglia, immergersi nei romanzi e fare escursioni nei parchi nazionali del Regno Unito.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/host-the-whisper-model-on-amazon-sagemaker-exploring-inference-options/
- :ha
- :È
- :non
- :Dove
- $ SU
- 1
- 10
- 100
- 12
- 14
- 16
- 19
- 30
- 32
- 8
- a
- accelerata
- accesso
- accessibilità
- Il mio account
- precisione
- operanti in
- azioni
- attivamente
- aggiungere
- aggiuntivo
- Inoltre
- indirizzo
- regolare
- Avanzate
- AI
- mira
- Tutti
- Consentire
- consente
- lungo
- anche
- Amazon
- Amazon Sage Maker
- Amazon Web Services
- an
- .
- ed
- Un altro
- in qualsiasi
- applicazioni
- approcci
- SONO
- aree
- Italia
- artificiale
- intelligenza artificiale
- AS
- attività
- assistenti
- associato
- At
- Audio
- Paternità
- Automatico
- automaticamente
- disponibilità
- disponibile
- evitare
- AWS
- base
- basato
- BE
- diventare
- sotto
- Meglio
- fra
- pregiudizi
- BIN
- entrambi
- bug
- ma
- by
- Materiale
- funzionalità
- capace
- attento
- casi
- Modifiche
- Grafico
- dai un'occhiata
- Scegli
- la scelta
- classe
- pulire campo
- codice
- Venire
- commento
- Uncommon
- confronto
- confronto
- Completato
- completamento
- componenti
- globale
- calcolo
- computer
- Visione computerizzata
- Segui il codice di Condotta
- conferenze
- Configurazione
- configurato
- configurazione
- considerando
- costantemente
- contenere
- Contenitore
- Tecnologie Container
- continuamente
- contrasto
- di controllo
- conversione
- correggere
- Corrispondente
- Costo
- Costi
- potuto
- CPU
- creare
- Creazione
- cruciale
- costume
- dati
- decisioni
- diminuire
- deep
- apprendimento profondo
- Predefinito
- definire
- dimostrato
- schierare
- schierato
- distribuzione
- deployment
- dettaglio
- dettagliati
- dettagli
- sviluppare
- sviluppatori
- Mercato
- dispositivo
- dispositivi
- diverso
- differenziare
- Dimensioni
- direttamente
- visualizzazione
- immersione
- paesaggio differenziato
- docker
- non
- fare
- giù
- durante
- e
- ogni
- In precedenza
- ecosistema
- in maniera efficace
- efficiente
- in modo efficiente
- senza sforzo
- o
- altro
- imbarcarsi
- Potenzia
- enable
- Abilita
- consentendo
- circondare
- endpoint
- endpoint
- accrescere
- migliorando
- garantire
- assicura
- Intero
- Ambiente
- essential
- stabilire
- Etere (ETH)
- esame
- esempio
- superare
- superato
- eccellente
- esperimento
- Spiegare
- esplorazione
- Esplorare
- Faccia
- fallito
- falso
- famiglia
- FAST
- più veloce
- più veloce
- pochi
- Compila il
- File
- trova
- Nome
- Focus
- messa a fuoco
- i seguenti
- Nel
- formato
- Contesto
- quadri
- Gratis
- da
- pieno
- GPU
- GPU
- grande
- Gruppo
- maniglia
- Manovrabilità
- Hardware
- Avere
- udito
- aiutare
- suo
- Alta
- superiore
- escursionismo
- host
- di hosting
- Come
- Tutorial
- Tuttavia
- HTML
- http
- HTTPS
- Hub
- abbracciare il viso
- i
- ideale
- if
- illustrante
- Immagine
- immagini
- implementazione
- implementazioni
- importare
- importante
- in
- Uno sguardo approfondito sui miglioramenti dei pneumatici da corsa di Bridgestone.
- includere
- inclusi
- Compreso
- incorporare
- Aumento
- sempre più
- individuale
- individui
- industrie
- informazioni
- informati
- inizialmente
- inizialmente
- iniziazione
- ingresso
- Ingressi
- intuizioni
- install
- esempio
- istanze
- istruzioni
- Integrazione
- Intelligence
- interagire
- interesse
- interessato
- Interfaccia
- ai miglioramenti
- sicurezza
- IT
- SUO
- Lavoro
- Offerte di lavoro
- jpg
- Le
- conoscenze
- conosciuto
- paesaggio
- superiore, se assunto singolarmente.
- infine
- Latenza
- dopo
- con i più recenti
- strato
- portare
- apprendimento
- meno
- leveraging
- Licenza
- limitazione
- Limitato
- linea
- Lista
- caricare
- Caricamento in corso
- locale
- località
- Lunghi
- più a lungo
- Basso
- macchina
- machine learning
- fatto
- Principale
- make
- FA
- Fare
- gestire
- gestione
- Maps
- Maggio..
- menzionato
- Metadati
- metodo
- metodi
- Metrica
- forza
- millisecondi
- verbale
- CON
- ML
- modello
- modelli
- moderata
- Moments
- monitoraggio
- Scopri di più
- Film
- molti
- multiplo
- devono obbligatoriamente:
- Detto
- il
- parchi nazionali
- necessaria
- Bisogno
- di applicazione
- Rete
- Neurale
- rete neurale
- GENERAZIONE
- nlp
- no
- Nota
- taccuino
- Note
- notifica
- notifiche
- notando
- adesso
- numero
- numeri
- oggetto
- oggetti
- osservare
- of
- offrire
- offerta
- Offerte
- ufficiale
- offline
- on
- una volta
- ONE
- esclusivamente
- open source
- opera
- Opzione
- Opzioni
- or
- minimo
- organizzazioni
- OS
- Altro
- altrimenti
- su
- panoramica
- pacchetto
- Packages
- parametro
- parametri
- parchi
- passare
- sentiero
- eseguire
- performance
- fase
- conduttura
- centrale
- posto
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- per favore
- punti
- possibile
- Post
- potenziale
- predizione
- Previsioni
- prevenire
- precedente
- primario
- processi
- elaborati
- lavorazione
- Processore
- progetto
- propriamente
- prototipazione
- fornire
- purché
- fornisce
- fornitura
- Python
- pytorch
- qualità
- gamma
- tempo reale
- regno
- riconoscimento
- raccomandato
- registrato
- Ridotto
- riferimento
- Indipendentemente
- relazionato
- Uscite
- ricorda
- rimuovere
- rimuove
- deposito
- richiesta
- richieste
- richiedere
- necessario
- requisito
- ricercatori
- rispettivamente
- risposta
- risposte
- responsabile
- colpevole
- risultato
- Risultati
- mantenuto
- riqualificazione
- ritorno
- sagemaker
- stesso
- Risparmi
- salvato
- risparmio
- Scalabilità
- Scala
- bilancia
- in programma
- scienziati
- copione
- script
- Secondo
- secondo
- Sezione
- segmenti
- select
- selezionato
- Selezione
- Serie
- servizio
- Servizi
- set
- regolazione
- impostazioni
- Condividi
- lei
- dovrebbero
- ha mostrato
- Spettacoli
- chiusura
- significativa
- Un'espansione
- semplifica
- Taglia
- Dimensioni
- piccole
- inferiore
- So
- Software
- soluzione
- specifico
- in particolare
- specificato
- discorso
- Riconoscimento vocale
- velocità
- Spendere
- parlato
- inizia a
- Regione / Stato
- state-of-the-art
- step
- Passi
- conservazione
- strategie
- successivo
- di successo
- tale
- improvviso
- adatto
- supporto
- Supporto
- supporti
- sicuro
- ondata
- SISTEMI DI TRATTAMENTO
- tavolo
- Fai
- presa
- Task
- task
- Tecnologia
- di
- che
- Il
- Regno Unito
- loro
- Li
- poi
- Là.
- perciò
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- tre
- tempo
- Serie storiche
- volte
- a
- strumenti
- torcia
- traffico
- Treni
- allenato
- Trasformare
- trasformatore
- trasformatori
- innescare
- innescato
- tv
- Serie TV
- seconda
- Digitare
- tipicamente
- Uk
- per
- sblocco
- su
- us
- uso
- utilizzato
- user-friendly
- utenti
- utilizzando
- utilità
- utilizzare
- Utilizzando
- Prezioso
- APPREZZIAMO
- variabile
- vario
- Fisso
- versione
- visione
- Voce
- comandi vocali
- volume
- aspettare
- volere
- Prima
- we
- sito web
- servizi web
- WELL
- sono stati
- quando
- ogni volta che
- quale
- Sussurro
- largo
- Vasta gamma
- con
- entro
- flusso di lavoro
- lavori
- valore
- scrittura
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro