Con l'avvento dell'intelligenza artificiale generativa, gli odierni modelli di fondazione (FM), come i modelli linguistici di grandi dimensioni (LLM) Claude 2 e Llama 2, possono eseguire una serie di attività generative come la risposta alle domande, il riepilogo e la creazione di contenuti su dati di testo. Tuttavia, i dati del mondo reale esistono in molteplici modalità, come testo, immagini, video e audio. Prendi una presentazione di PowerPoint, ad esempio. Potrebbe contenere informazioni sotto forma di testo o incorporate in grafici, tabelle e immagini.
In questo post presentiamo una soluzione che utilizza FM multimodali come il Incorporamenti multimodali di Amazon Titan modello e LLaVA 1.5 e servizi AWS inclusi Roccia Amazzonica ed Amazon Sage Maker per eseguire compiti generativi simili su dati multimodali.
Panoramica della soluzione
La soluzione fornisce un'implementazione per rispondere alle domande utilizzando le informazioni contenute nel testo e negli elementi visivi di una presentazione. Il design si basa sul concetto di Retrieval Augmented Generation (RAG). Tradizionalmente, RAG è stato associato a dati testuali che possono essere elaborati da LLM. In questo post estendiamo RAG per includere anche le immagini. Ciò fornisce una potente capacità di ricerca per estrarre contenuti contestualmente rilevanti da elementi visivi come tabelle e grafici insieme al testo.
Esistono diversi modi per progettare una soluzione RAG che includa immagini. Abbiamo presentato un approccio qui e seguiremo un approccio alternativo nel secondo post di questa serie in tre parti.
Questa soluzione include i seguenti componenti:
- Modello di incorporamento multimodale di Amazon Titan – Questo FM viene utilizzato per generare incorporamenti per il contenuto nello slide deck utilizzato in questo post. In quanto modello multimodale, questo modello Titan può elaborare testo, immagini o una combinazione come input e generare incorporamenti. Il modello Titan Multimodal Embeddings genera vettori (embedding) di 1,024 dimensioni ed è accessibile tramite Amazon Bedrock.
- Assistente per il linguaggio e la visione di grandi dimensioni (LLaVA) – LLaVA è un modello multimodale open source per la comprensione visiva e del linguaggio e viene utilizzato per interpretare i dati nelle diapositive, inclusi elementi visivi come grafici e tabelle. Usiamo la versione da 7 miliardi di parametri LLaVA 1.5-7b in questa soluzione.
- Amazon Sage Maker – Il modello LLaVA viene distribuito su un endpoint SageMaker utilizzando i servizi di hosting SageMaker e utilizziamo l'endpoint risultante per eseguire inferenze rispetto al modello LLaVA. Utilizziamo anche i notebook SageMaker per orchestrare e dimostrare questa soluzione end-to-end.
- Amazon OpenSearch senza server – OpenSearch Serverless è una configurazione serverless su richiesta per Servizio Amazon OpenSearch. Utilizziamo OpenSearch Serverless come database vettoriale per archiviare gli incorporamenti generati dal modello Titan Multimodal Embeddings. Un indice creato nella raccolta OpenSearch Serverless funge da archivio vettoriale per la nostra soluzione RAG.
- Inserimento Amazon OpenSearch (OSI) – OSI è un raccoglitore di dati serverless completamente gestito che fornisce dati ai domini del servizio OpenSearch e alle raccolte Serverless di OpenSearch. In questo post utilizziamo una pipeline OSI per fornire dati all'archivio vettoriale OpenSearch Serverless.
Architettura della soluzione
La progettazione della soluzione è composta da due parti: acquisizione e interazione con l'utente. Durante l'acquisizione, elaboriamo il gruppo di diapositive di input convertendo ciascuna diapositiva in un'immagine, generiamo incorporamenti per queste immagini e quindi popoliamo l'archivio dati vettoriali. Questi passaggi vengono completati prima dei passaggi di interazione con l'utente.
Nella fase di interazione con l'utente, una domanda dell'utente viene convertita in incorporamenti e viene eseguita una ricerca di somiglianza nel database vettoriale per trovare una diapositiva che potrebbe potenzialmente contenere risposte alla domanda dell'utente. Forniamo quindi questa diapositiva (sotto forma di file immagine) al modello LLaVA e alla domanda dell'utente come suggerimento per generare una risposta alla query. Tutto il codice per questo post è disponibile nel file GitHub riposo.
Il diagramma seguente illustra l'architettura di inserimento.
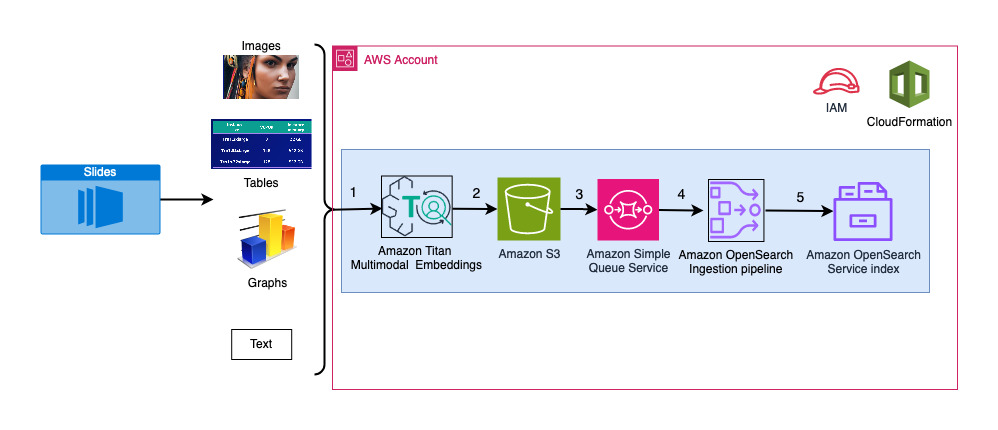
I passaggi del flusso di lavoro sono i seguenti:
- Le diapositive vengono convertite in file di immagine (uno per diapositiva) in formato JPG e passati al modello Titan Multimodal Embeddings per generare incorporamenti. In questo post utilizziamo la presentazione intitolata Addestra e distribuisci Stable Diffusion utilizzando AWS Trainium e AWS Inferentia dal Summit AWS di Toronto, giugno 2023, per dimostrare la soluzione. Il mazzo di campioni ha 31 diapositive, quindi generiamo 31 serie di incorporamenti di vettori, ciascuno con 1,024 dimensioni. Aggiungiamo ulteriori campi di metadati a questi incorporamenti di vettori generati e creiamo un file JSON. Questi campi di metadati aggiuntivi possono essere utilizzati per eseguire query di ricerca avanzate utilizzando le potenti funzionalità di ricerca di OpenSearch.
- Gli incorporamenti generati vengono riuniti in un singolo file JSON su cui viene caricato Servizio di archiviazione semplice Amazon (Amazon S3).
- via Notifiche di eventi di Amazon S3, un evento viene inserito in un Servizio Amazon Simple Queue (Amazon SQS) coda.
- Questo evento nella coda SQS funge da trigger per eseguire la pipeline OSI, che a sua volta inserisce i dati (file JSON) come documenti nell'indice OpenSearch Serverless. Tieni presente che l'indice OpenSearch Serverless è configurato come sink per questa pipeline e viene creato come parte della raccolta OpenSearch Serverless.
Il diagramma seguente illustra l'architettura di interazione dell'utente.
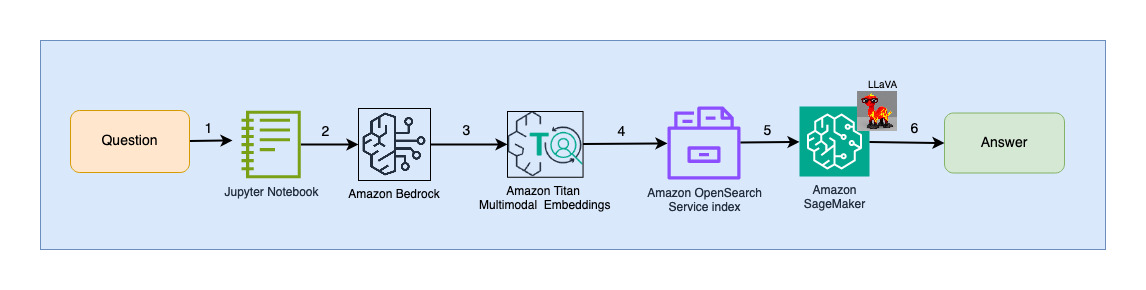
I passaggi del flusso di lavoro sono i seguenti:
- Un utente invia una domanda relativa alla presentazione che è stata importata.
- L'input dell'utente viene convertito in incorporamenti utilizzando il modello Titan Multimodal Embeddings a cui si accede tramite Amazon Bedrock. Una ricerca vettoriale OpenSearch viene eseguita utilizzando questi incorporamenti. Eseguiamo una ricerca k-vicino più vicino (k=1) per recuperare l'incorporamento più pertinente che corrisponde alla query dell'utente. L'impostazione k=1 recupera la diapositiva più pertinente alla domanda dell'utente.
- I metadati della risposta di OpenSearch Serverless contengono un percorso all'immagine corrispondente alla diapositiva più rilevante.
- Viene creato un prompt combinando la domanda dell'utente e il percorso dell'immagine e fornito a LLaVA ospitato su SageMaker. Il modello LLaVA è in grado di comprendere la domanda dell'utente e rispondere esaminando i dati presenti nell'immagine.
- Il risultato di questa inferenza viene restituito all'utente.
Questi passaggi vengono discussi in dettaglio nelle sezioni seguenti. Vedi il Risultati sezione per screenshot e dettagli sull'output.
Prerequisiti
Per implementare la soluzione fornita in questo post, dovresti avere un file Account AWS e familiarità con FM, Amazon Bedrock, SageMaker e OpenSearch Service.
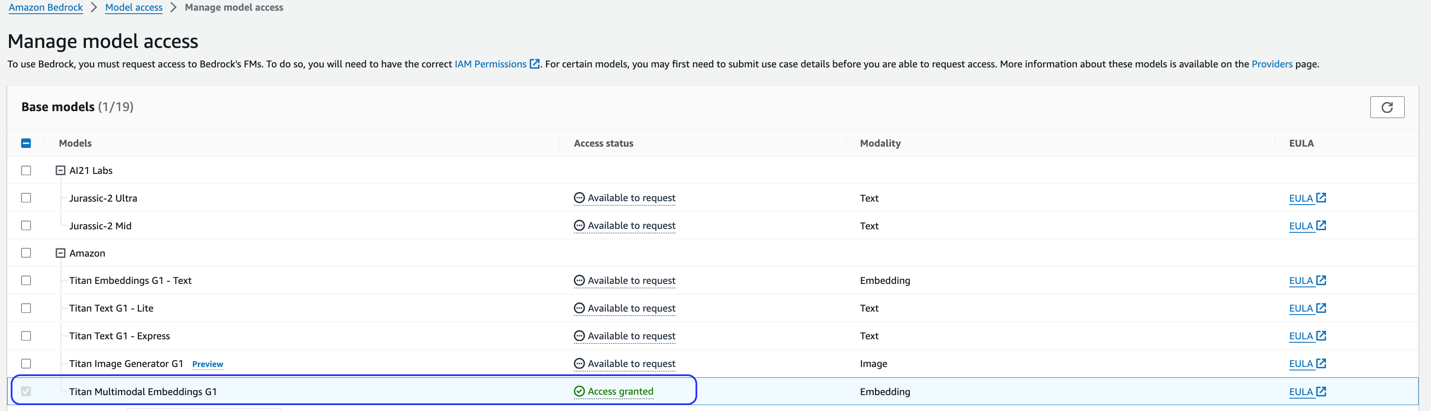
Questa soluzione utilizza il modello Titan Multimodal Embeddings. Assicurati che questo modello sia abilitato per l'uso in Amazon Bedrock. Sulla console Amazon Bedrock, scegli Accesso al modello nel riquadro di navigazione. Se gli incorporamenti multimodali Titan sono abilitati, verrà indicato lo stato di accesso Accesso garantito.
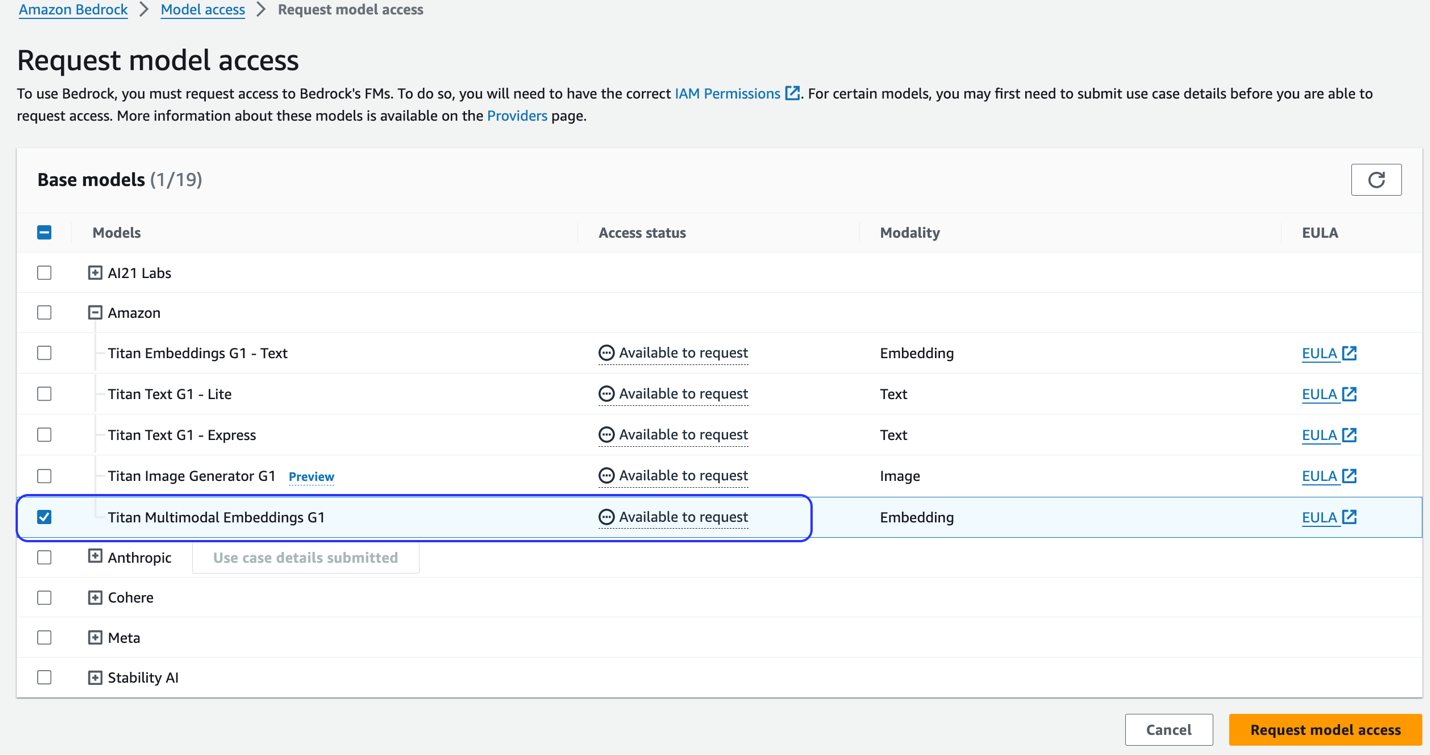
Se il modello non è disponibile, abilitare l'accesso al modello scegliendo Gestisci l'accesso al modello, selezionando Incorporamenti multimodali Titan G1e scegliendo Richiedi l'accesso al modello. Il modello è abilitato per l'uso immediatamente.
Utilizza un modello AWS CloudFormation per creare lo stack di soluzioni
Utilizzare uno dei seguenti AWS CloudFormazione modelli (a seconda della regione) per avviare le risorse della soluzione.
| Regione AWS | Link |
|---|---|
us-east-1 |
|
us-west-2 |
Dopo che lo stack è stato creato correttamente, vai allo stack Uscite scheda sulla console AWS CloudFormation e annota il valore di MultimodalCollectionEndpoint, che utilizzeremo nei passaggi successivi.
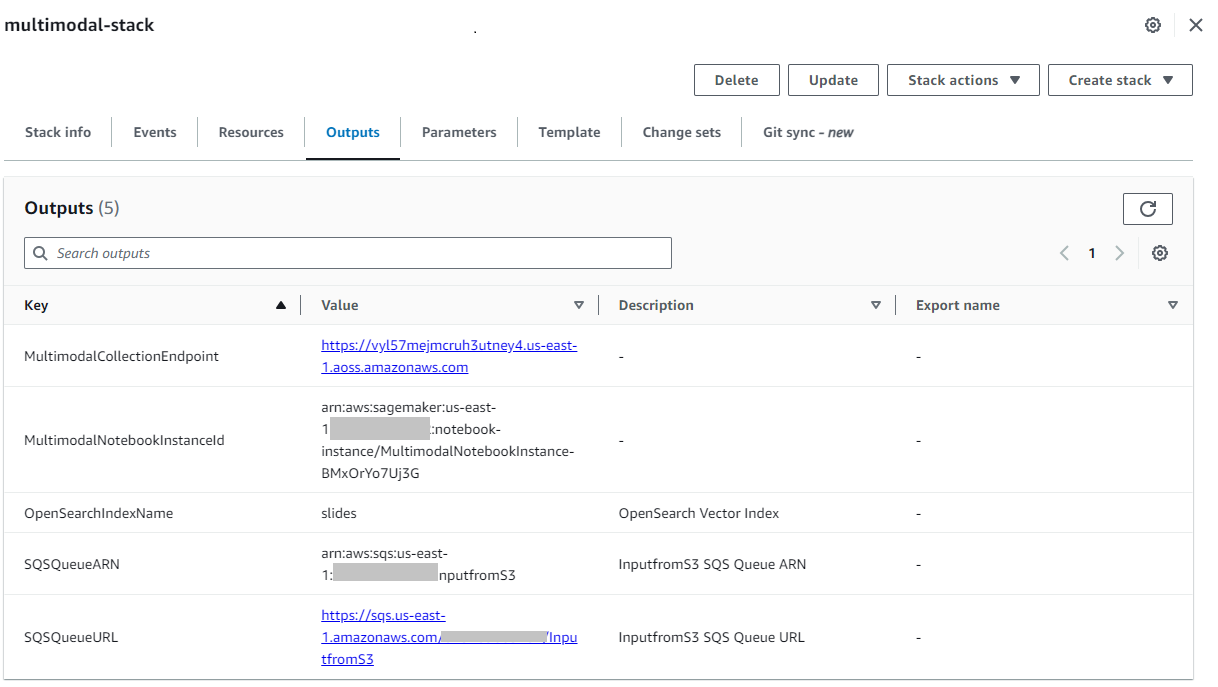
Il modello CloudFormation crea le seguenti risorse:
- Ruoli IAM - Il seguente Gestione dell'identità e dell'accesso di AWS (IAM) vengono creati i ruoli. Aggiorna questi ruoli da applicare autorizzazioni con privilegi minimi.
SMExecutionRolecon accesso completo ad Amazon S3, SageMaker, OpenSearch Service e Bedrock.OSPipelineExecutionRolecon accesso a specifiche azioni Amazon SQS e OSI.
- Taccuino SageMaker – Tutto il codice per questo post viene eseguito tramite questo notebook.
- Raccolta OpenSearch Serverless – Questo è il database vettoriale per la memorizzazione e il recupero degli incorporamenti.
- Gasdotto OSI – Questa è la pipeline per l'inserimento dei dati in OpenSearch Serverless.
- Benna S3 – Tutti i dati per questo post sono archiviati in questo bucket.
- Coda SQS – Gli eventi per l'attivazione dell'esecuzione della pipeline OSI vengono inseriti in questa coda.
Il modello CloudFormation configura la pipeline OSI con l'elaborazione Amazon S3 e Amazon SQS come origine e un indice OpenSearch Serverless come sink. Qualsiasi oggetto creato nel bucket S3 e nel prefisso specificati (multimodal/osi-embeddings-json) attiverà le notifiche SQS, utilizzate dalla pipeline OSI per inserire dati in OpenSearch Serverless.
Viene creato anche il modello CloudFormation Rete, crittografiae l'accesso ai dati policy richieste per la raccolta OpenSearch Serverless. Aggiorna queste policy per applicare le autorizzazioni con privilegi minimi.
Tieni presente che il nome del modello CloudFormation viene fatto riferimento nei notebook SageMaker. Se il nome del modello predefinito viene modificato, assicurati di aggiornare lo stesso in globals.py
Prova la soluzione
Una volta completati i passaggi prerequisiti e creato correttamente lo stack CloudFormation, sei pronto per testare la soluzione:
- Sulla console di SageMaker, scegli Notebook nel pannello di navigazione.
- Seleziona il
MultimodalNotebookInstanceistanza del notebook e scegli Apri JupyterLab.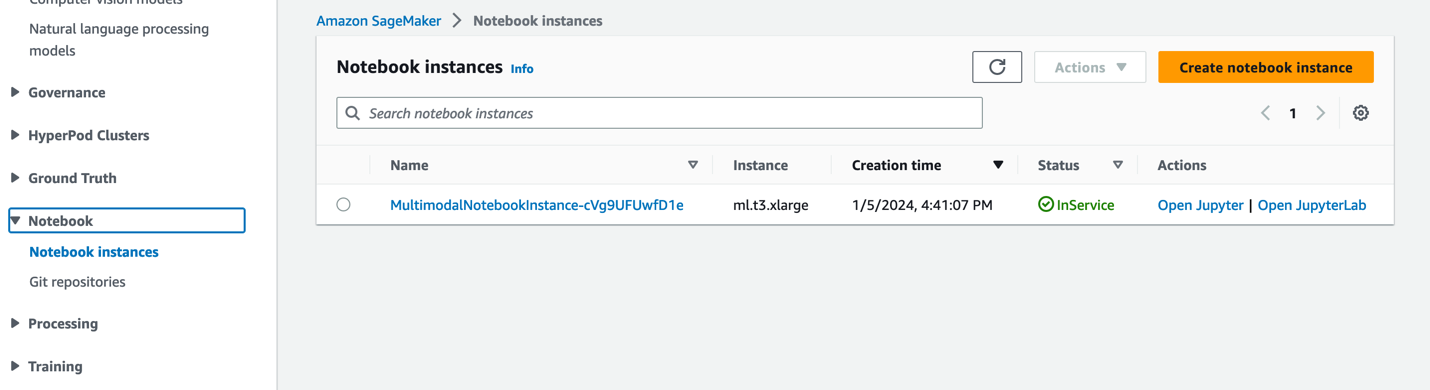
- In File Browser, passare alla cartella dei taccuini per visualizzare i taccuini e i file di supporto.
I taccuini sono numerati nella sequenza in cui vengono eseguiti. Le istruzioni e i commenti in ciascun taccuino descrivono le azioni eseguite da quel taccuino. Eseguiamo questi notebook uno per uno.
- Scegli 0_deploy_llava.ipynb per aprirlo in JupyterLab.
- Sulla Correre menù, scegliere Esegui tutte le celle per eseguire il codice in questo blocco appunti.
Questo notebook distribuisce il modello LLaVA-v1.5-7B su un endpoint SageMaker. In questo notebook scarichiamo il modello LLaVA-v1.5-7B da HuggingFace Hub, sostituiamo lo script inference.py con llava_inference.pye creare un file model.tar.gz per questo modello. Il file model.tar.gz viene caricato su Amazon S3 e utilizzato per distribuire il modello sull'endpoint SageMaker. IL llava_inference.py Lo script dispone di codice aggiuntivo per consentire la lettura di un file immagine da Amazon S3 e l'esecuzione di inferenze su di esso.
- Scegli 1_data_prep.ipynb per aprirlo in JupyterLab.
- Sulla Correre menù, scegliere Esegui tutte le celle per eseguire il codice in questo blocco appunti.
Questo notebook scarica il Ponte scivolo, converte ogni diapositiva nel formato file JPG e la carica nel bucket S3 utilizzato per questo post.
- Scegli 2_data_ingestion.ipynb per aprirlo in JupyterLab.
- Sulla Correre menù, scegliere Esegui tutte le celle per eseguire il codice in questo blocco appunti.
Facciamo quanto segue in questo taccuino:
- Creiamo un indice nella raccolta OpenSearch Serverless. Questo indice memorizza i dati di incorporamento per lo slide deck. Vedere il seguente codice:
- Utilizziamo il modello Titan Multimodal Embeddings per convertire le immagini JPG create nel notebook precedente in incorporamenti vettoriali. Questi incorporamenti e metadati aggiuntivi (come il percorso S3 del file immagine) vengono archiviati in un file JSON e caricati su Amazon S3. Tieni presente che viene creato un singolo file JSON, che contiene i documenti per tutte le diapositive (immagini) convertite in incorporamenti. Il seguente frammento di codice mostra come un'immagine (sotto forma di stringa codificata Base64) viene convertita in incorporamenti:
- Questa azione attiva la pipeline di inserimento di OpenSearch, che elabora il file e lo inserisce nell'indice OpenSearch Serverless. Di seguito è riportato un esempio del file JSON creato. (Nel codice di esempio è mostrato un vettore con quattro dimensioni. Il modello Titan Multimodal Embeddings genera 1,024 dimensioni.)
- Scegli 3_rag_inference.ipynb per aprirlo in JupyterLab.
- Sulla Correre menù, scegliere Esegui tutte le celle per eseguire il codice in questo blocco appunti.
Questo notebook implementa la soluzione RAG: convertiamo la domanda dell'utente in incorporamenti, troviamo un'immagine simile (diapositiva) dal database vettoriale e forniamo l'immagine recuperata a LLaVA per generare una risposta alla domanda dell'utente. Utilizziamo il seguente modello di prompt:
Il seguente frammento di codice fornisce il flusso di lavoro RAG:
Risultati
Di seguito è riportata una raccolta di alcune domande e risposte degli utenti generate dalla nostra implementazione. IL Question la colonna cattura la domanda dell'utente e il file Risposta colonna è la risposta testuale generata da LLaVA. Immagine è la corrispondenza della diapositiva k-più vicina (k=1) restituita dalla ricerca vettoriale OpenSearch Serverless. Questa diapositiva è interpretata da LLaVA per fornire la risposta.
Risultati RAG multimodali
| Question | Risposta | Immagine |
|---|---|---|
| Come si confronta Inf2 in termini di prestazioni con istanze EC2 comparabili? Ho bisogno di numeri. | Secondo la presentazione, le istanze Inf2 di AWS Inferentia2 offrono un throughput fino a 4 volte superiore e una latenza 10 volte inferiore rispetto a istanze EC2 comparabili. |  |
| Secondo il volano AI/ML, cosa forniscono i servizi AI/ML di AWS? | I servizi AI/ML di AWS offrono migliori funzionalità in termini di rapporto qualità-prezzo, nuove funzionalità e investimenti nell'innovazione. | 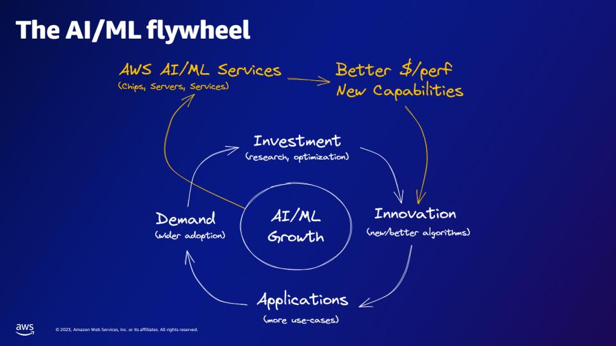 |
| Rispetto a GPT-2, quanti parametri in più ha GPT-3? Qual è la differenza numerica tra la dimensione dei parametri di GPT-2 e GPT-3? | Secondo la diapositiva, GPT-3 ha 175 miliardi di parametri, mentre GPT-2 ha 1.5 miliardi di parametri. La differenza numerica tra la dimensione dei parametri di GPT-2 e GPT-3 è 173.5 miliardi. | 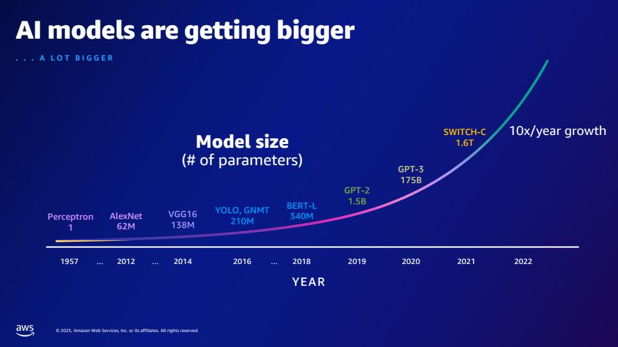 |
| Cosa sono i quark nella fisica delle particelle? | Non ho trovato la risposta a questa domanda nelle diapositive. |  |
Sentiti libero di estendere questa soluzione ai tuoi slide deck. Aggiorna semplicemente la variabile SLIDE_DECK in globals.py con un URL per la tua presentazione ed esegui i passaggi di importazione dettagliati nella sezione precedente.
Consiglio
Puoi utilizzare OpenSearch Dashboards per interagire con l'API OpenSearch per eseguire test rapidi sull'indice e sui dati importati. Lo screenshot seguente mostra un esempio GET del dashboard OpenSearch.
ripulire
Per evitare di incorrere in addebiti futuri, elimina le risorse che hai creato. Puoi farlo eliminando lo stack tramite la console CloudFormation.

Inoltre, elimina l'endpoint di inferenza SageMaker creato per l'inferenza LLaVA. Puoi farlo rimuovendo il commento dal passaggio di pulizia 3_rag_inference.ipynb ed eseguendo la cella oppure eliminando l'endpoint tramite la console SageMaker: scegli Inferenza ed endpoint nel riquadro di navigazione, quindi seleziona l'endpoint ed eliminalo.
Conclusione
Le aziende generano continuamente nuovi contenuti e le presentazioni sono un meccanismo comune utilizzato per condividere e diffondere informazioni all'interno dell'organizzazione e all'esterno con i clienti o durante le conferenze. Nel corso del tempo, informazioni ricche possono rimanere sepolte e nascoste in modalità non testuali come grafici e tabelle in queste presentazioni. È possibile utilizzare questa soluzione e la potenza dei FM multimodali come il modello Titan Multimodal Embeddings e LLaVA per scoprire nuove informazioni o scoprire nuove prospettive sui contenuti nelle presentazioni.
Ti invitiamo a saperne di più esplorando JumpStart di Amazon SageMaker, Modelli Amazon Titan, Amazon Bedrock e OpenSearch Service e creando una soluzione utilizzando l'implementazione di esempio fornita in questo post.
Cerca due post aggiuntivi come parte di questa serie. La parte 2 tratta un altro approccio che potresti adottare per parlare con le tue diapositive. Questo approccio genera e archivia inferenze LLaVA e utilizza tali inferenze archiviate per rispondere alle query dell'utente. La terza parte mette a confronto i due approcci.
Circa gli autori
 Amit Arora è un AI e ML Specialist Architect presso Amazon Web Services, che aiuta i clienti aziendali a utilizzare i servizi di machine learning basati su cloud per scalare rapidamente le loro innovazioni. È anche docente a contratto nel programma MS data science and analytics presso la Georgetown University di Washington DC
Amit Arora è un AI e ML Specialist Architect presso Amazon Web Services, che aiuta i clienti aziendali a utilizzare i servizi di machine learning basati su cloud per scalare rapidamente le loro innovazioni. È anche docente a contratto nel programma MS data science and analytics presso la Georgetown University di Washington DC
 Manju Prasad è un Senior Solutions Architect presso Strategic Accounts presso Amazon Web Services. Si concentra sulla fornitura di consulenza tecnica in una varietà di domini, tra cui AI/ML, a un cliente principale di M&E. Prima di entrare in AWS, ha progettato e realizzato soluzioni per aziende del settore dei servizi finanziari e anche per una startup.
Manju Prasad è un Senior Solutions Architect presso Strategic Accounts presso Amazon Web Services. Si concentra sulla fornitura di consulenza tecnica in una varietà di domini, tra cui AI/ML, a un cliente principale di M&E. Prima di entrare in AWS, ha progettato e realizzato soluzioni per aziende del settore dei servizi finanziari e anche per una startup.
 Archana Inapudi è un Senior Solutions Architect presso AWS che supporta i clienti strategici. Ha oltre un decennio di esperienza nell'aiutare i clienti a progettare e creare soluzioni di analisi dei dati e database. La sua passione è l'utilizzo della tecnologia per fornire valore ai clienti e ottenere risultati aziendali.
Archana Inapudi è un Senior Solutions Architect presso AWS che supporta i clienti strategici. Ha oltre un decennio di esperienza nell'aiutare i clienti a progettare e creare soluzioni di analisi dei dati e database. La sua passione è l'utilizzo della tecnologia per fornire valore ai clienti e ottenere risultati aziendali.
 Antara Raissa è un AI e ML Solutions Architect presso Amazon Web Services che supporta clienti strategici con sede a Dallas, in Texas. Ha anche precedenti esperienze di lavoro con partner di grandi aziende presso AWS, dove ha lavorato come Partner Success Solutions Architect per clienti nativi digitali.
Antara Raissa è un AI e ML Solutions Architect presso Amazon Web Services che supporta clienti strategici con sede a Dallas, in Texas. Ha anche precedenti esperienze di lavoro con partner di grandi aziende presso AWS, dove ha lavorato come Partner Success Solutions Architect per clienti nativi digitali.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/talk-to-your-slide-deck-using-multimodal-foundation-models-hosted-on-amazon-bedrock-and-amazon-sagemaker-part-1/
- :ha
- :È
- :non
- :Dove
- $ SU
- 1
- 10
- 100
- 13
- 15%
- 16
- 173
- 20
- 2023
- 26
- 29
- 31
- 8
- 9
- a
- capace
- Chi siamo
- accesso
- accessibile
- conti
- Raggiungere
- Action
- azioni
- atti
- aggiungere
- aggiuntivo
- aggiunto
- Avvento
- contro
- AI
- AI / ML
- Tutti
- consentire
- lungo
- anche
- Amazon
- Amazon Sage Maker
- Amazon Web Services
- an
- analitica
- ed
- Un altro
- rispondere
- rispondere
- risposte
- in qualsiasi
- api
- APPLICA
- approccio
- approcci
- architettura
- SONO
- AS
- chiedere
- Assistant
- associato
- At
- Audio
- aumentata
- auth
- disponibile
- evitare
- AWS
- AWS CloudFormazione
- basato
- BE
- stato
- Meglio
- fra
- Miliardo
- stile di vita
- costruire
- Costruzione
- costruito
- affari
- by
- Materiale
- funzionalità
- capacità
- cattura
- cella
- cambiato
- oneri
- Scegli
- la scelta
- cliente
- codice
- collezione
- collezioni
- collettore
- Colonna
- combinazione
- combinando
- Commenti
- Uncommon
- Aziende
- paragonabile
- confrontare
- rispetto
- completamento di una
- Completato
- componenti
- concetto
- conferenze
- Configurazione
- configurato
- consiste
- consolle
- contenere
- contenute
- contiene
- contenuto
- creazione di contenuti
- convertire
- convertito
- conversione
- Corrispondente
- potuto
- copre
- creare
- creato
- crea
- Creazione
- creazione
- Credenziali
- cliente
- Clienti
- Dallas
- cruscotto
- cruscotti
- dati
- Dati Analytics
- scienza dei dati
- Banca Dati
- decennio
- ponte
- Predefinito
- consegnare
- fornisce un monitoraggio
- dimostrare
- Dipendente
- schierare
- schierato
- distribuzione
- Distribuisce
- descrivere
- Design
- progettato
- dettaglio
- dettagliati
- dettagli
- diagramma
- DITT
- DID
- differenza
- diverso
- Emittente
- digitale
- Dimensioni
- dimensioni
- scopri
- discusso
- Dsiplay
- do
- documenti
- effettua
- domini
- scaricare
- download
- durante
- e
- ogni
- elementi
- incorporato
- incorporamento
- enable
- abilitato
- codificati
- incoraggiare
- fine
- endpoint
- motore
- garantire
- Impresa
- clienti aziendali
- errore
- Etere (ETH)
- Evento
- eventi
- esaminando
- esempio
- Tranne
- eccezione
- esiste
- esperienza
- Esplorare
- estendere
- esternamente
- estratto
- Familiarità
- campi
- Compila il
- File
- finanziario
- servizi finanziari
- Trovare
- si concentra
- seguire
- i seguenti
- segue
- Nel
- modulo
- formato
- Fondazione
- quattro
- Gratis
- da
- pieno
- completamente
- futuro
- generare
- generato
- genera
- ELETTRICA
- generativo
- AI generativa
- georgetown
- ottenere
- GitHub
- andando
- grafici
- guida
- Avere
- he
- utile
- aiutare
- qui
- nascosto
- superiore
- Visualizzazioni
- host
- ospitato
- di hosting
- padroni di casa
- Come
- Tuttavia
- HTML
- http
- HTTPS
- Hub
- abbracciare il viso
- i
- IAM
- Identità
- if
- illustra
- Immagine
- immagini
- subito
- realizzare
- implementazione
- attrezzi
- in
- includere
- inclusi
- Compreso
- Index
- Indici
- informazioni
- Innovazione
- innovazioni
- ingresso
- esempio
- istanze
- istruzioni
- interagire
- interazione
- internamente
- ai miglioramenti
- investimento
- IT
- accoppiamento
- jpg
- json
- giugno
- Lingua
- grandi
- Latenza
- lanciare
- IMPARARE
- apprendimento
- docente
- piace
- LINK
- Lama
- locale
- inferiore
- macchina
- machine learning
- make
- gestire
- gestito
- molti
- partita
- corrispondenza
- meccanismo
- Menu
- Metadati
- metodo
- ML
- modalità
- modello
- modelli
- Scopri di più
- maggior parte
- MS
- multiplo
- Nome
- nativo
- Navigare
- Navigazione
- Bisogno
- New
- Nessuna
- Nota
- taccuino
- computer portatili
- notifiche
- adesso
- numerato
- numeri
- oggetti
- of
- offrire
- on
- On-Demand
- ONE
- esclusivamente
- aprire
- open source
- or
- organizzazione
- OS
- nostro
- su
- risultati
- produzione
- ancora
- vetro
- parametro
- parametri
- parte
- particella
- partner
- partner
- Ricambi
- Passato
- appassionato
- sentiero
- per
- eseguire
- performance
- eseguita
- permessi
- prospettive
- fase
- Fisica
- Immagini
- conduttura
- Platone
- Platone Data Intelligence
- PlatoneDati
- Termini e Condizioni
- Post
- Post
- potenzialmente
- energia
- potente
- Predictor
- presenti
- presentata
- precedente
- Precedente
- processi
- elaborati
- i processi
- lavorazione
- Programma
- proprietà
- fornire
- purché
- fornisce
- fornitura
- metti
- quark
- query
- domanda
- domanda
- Domande
- Presto
- straccio
- gamma
- rapidamente
- Lettura
- pronto
- mondo reale
- ricevuto
- riferimento
- regione
- relazionato
- pertinente
- rimanere
- sostituire
- richiesta
- necessario
- Risorse
- Rispondere
- risposta
- risposte
- colpevole
- risultante
- Risultati
- richiamo
- ritorno
- Ricco
- ruoli
- Correre
- running
- sagemaker
- Inferenza di SageMaker
- stesso
- dire
- Scala
- Scienze
- screenshot
- copione
- Cerca
- Secondo
- Sezione
- sezioni
- settore
- vedere
- select
- Selezione
- anziano
- Sequenza
- Serie
- serverless
- serve
- servizio
- Servizi
- Sessione
- Set
- regolazione
- impostazioni
- Condividi
- lei
- dovrebbero
- mostrato
- Spettacoli
- simile
- Un'espansione
- semplicemente
- singolo
- Taglia
- scivolo
- Diapositive
- frammento
- So
- soluzione
- Soluzioni
- alcuni
- Fonte
- specialista
- specifico
- specificato
- stabile
- pila
- startup
- Regione / Stato
- Stato dei servizi
- step
- Passi
- conservazione
- Tornare al suo account
- memorizzati
- negozi
- Strategico
- Corda
- successivo
- il successo
- Con successo
- tale
- Vertice
- Supporto
- sicuro
- tavolo
- Fai
- Parlare
- task
- Consulenza
- Tecnologia
- modello
- modelli
- test
- test
- Texas
- testo
- testuale
- che
- I
- le informazioni
- loro
- poi
- Strumenti Bowman per analizzare le seguenti finiture:
- questo
- quelli
- portata
- tempo
- titano
- titolato
- a
- di oggi
- insieme
- toronto
- tradizionalmente
- attraversare
- innescare
- innescando
- vero
- prova
- TURNO
- seconda
- Digitare
- scoprire
- capire
- e una comprensione reciproca
- Università
- Aggiornanento
- caricato
- URL
- uso
- utilizzato
- Utente
- usa
- utilizzando
- APPREZZIAMO
- variabile
- varietà
- versione
- via
- Video
- Visualizza
- visione
- visivo
- Washington
- modi
- we
- sito web
- servizi web
- WELL
- Che
- Che cosa è l'
- quale
- while
- volere
- con
- entro
- lavorato
- flusso di lavoro
- lavoro
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro