
20 settembre 2023
Modelli fondamentali (FM) stanno segnando l’inizio di una nuova era apprendimento automatico (ML) ed intelligenza artificiale (AI), che sta portando a uno sviluppo più rapido dell’intelligenza artificiale che può essere adattata a un’ampia gamma di attività a valle e messa a punto per una serie di applicazioni.
Con la crescente importanza dell’elaborazione dei dati nel luogo in cui viene svolto il lavoro, la fornitura di modelli di intelligenza artificiale all’edge aziendale consente previsioni quasi in tempo reale, rispettando al tempo stesso i requisiti di sovranità dei dati e privacy. Combinando il IBM wasonx dati e funzionalità della piattaforma AI per FM con l'edge computing, le aziende possono eseguire carichi di lavoro AI per la messa a punto e l'inferenza FM all'edge operativo. Ciò consente alle aziende di scalare le distribuzioni di intelligenza artificiale all’edge, riducendo i tempi e i costi di implementazione con tempi di risposta più rapidi.
Assicurati di controllare tutte le puntate di questa serie di post del blog sull'edge computing:
Cosa sono i modelli fondamentali?
I modelli fondamentali (FM), addestrati su un’ampia gamma di dati senza etichetta su larga scala, stanno guidando applicazioni di intelligenza artificiale (AI) all’avanguardia. Possono essere adattati a un'ampia gamma di attività a valle e ottimizzati per una vasta gamma di applicazioni. I moderni modelli di intelligenza artificiale, che eseguono compiti specifici in un singolo dominio, stanno lasciando il posto ai FM perché apprendono in modo più generale e lavorano su domini e problemi diversi. Come suggerisce il nome, un FM può costituire la base per molte applicazioni del modello AI.
I FM affrontano due sfide chiave che hanno impedito alle aziende di ampliare l’adozione dell’intelligenza artificiale. Innanzitutto, le aziende producono una grande quantità di dati non etichettati, solo una frazione dei quali viene etichettata per l’addestramento dei modelli di intelligenza artificiale. In secondo luogo, questo compito di etichettatura e annotazione è estremamente dispendioso in termini di risorse umane e spesso richiede diverse centinaia di ore di lavoro di un esperto in materia (PMI). Ciò rende proibitivo il costo della scalabilità tra i diversi casi d’uso poiché richiederebbe eserciti di PMI ed esperti di dati. Inserendo grandi quantità di dati senza etichetta e utilizzando tecniche di auto-supervisione per l'addestramento dei modelli, i FM hanno rimosso questi colli di bottiglia e aperto la strada all'adozione su larga scala dell'intelligenza artificiale in tutta l'azienda. Queste enormi quantità di dati presenti in ogni azienda aspettano di essere liberate per generare insight.
Cosa sono i grandi modelli linguistici?
I modelli linguistici di grandi dimensioni (LLM) sono una classe di modelli fondazionali (FM) costituiti da strati di reti neurali che sono stati addestrati su queste enormi quantità di dati non etichettati. Usano algoritmi di apprendimento autocontrollati per eseguire una varietà di elaborazione del linguaggio naturale (PNL) compiti in modi simili a come gli esseri umani usano il linguaggio (vedi Figura 1).
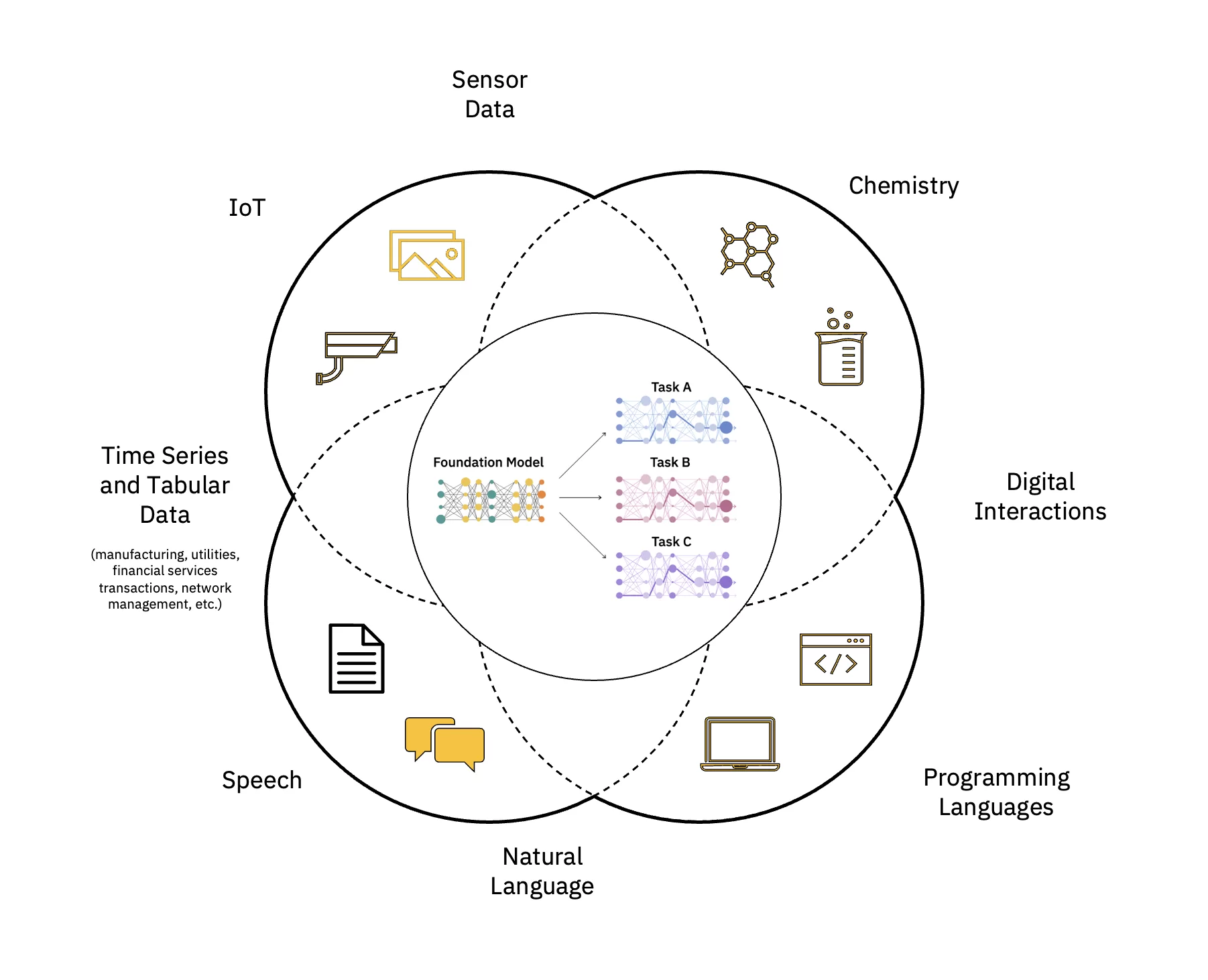
Scalare e accelerare l'impatto dell'intelligenza artificiale
Esistono diversi passaggi per creare e distribuire un modello fondamentale (FM). Questi includono l'inserimento dei dati, la selezione dei dati, la pre-elaborazione dei dati, la pre-formazione FM, l'ottimizzazione del modello per una o più attività downstream, il servizio di inferenza, la governance dei modelli di dati e intelligenza artificiale e la gestione del ciclo di vita, che possono essere descritti come FMOps.
Per aiutare in tutto questo, IBM offre alle aziende gli strumenti e le capacità necessari per sfruttare la potenza di questi FM tramite IBM wasonx, una piattaforma dati e IA di livello enterprise progettata per moltiplicare l'impatto dell'IA in tutta l'azienda. IBM Watsonx è costituito da quanto segue:
- IBM watsonx.ai porta nuovo IA generativa funzionalità, basate su FM e machine learning (ML) tradizionali, in un potente studio che abbraccia il ciclo di vita dell'intelligenza artificiale.
- IBM watsonx.data è un archivio dati adatto allo scopo costruito su un'architettura Lakehouse aperta per scalare i carichi di lavoro AI per tutti i tuoi dati, ovunque.
- IBM watsonx.governance è un toolkit automatizzato end-to-end per la governance del ciclo di vita dell'IA, creato per consentire flussi di lavoro IA responsabili, trasparenti e spiegabili.
Un altro vettore chiave è la crescente importanza dell'informatica a livello aziendale, come siti industriali, stabilimenti di produzione, negozi al dettaglio, siti edge di telecomunicazioni, ecc. Più specificamente, l'intelligenza artificiale a livello aziendale consente l'elaborazione di dati laddove viene svolto il lavoro. analisi quasi in tempo reale. L’edge aziendale è il luogo in cui vengono generate grandi quantità di dati aziendali e dove l’intelligenza artificiale può fornire informazioni aziendali preziose, tempestive e utilizzabili.
Servire modelli di intelligenza artificiale all’edge consente previsioni quasi in tempo reale rispettando i requisiti di sovranità dei dati e privacy. Ciò riduce significativamente la latenza spesso associata all'acquisizione, trasmissione, trasformazione ed elaborazione dei dati di ispezione. Lavorare all'edge ci consente di salvaguardare i dati aziendali sensibili e ridurre i costi di trasferimento dei dati con tempi di risposta più rapidi.
Scalare le implementazioni dell’intelligenza artificiale all’edge, tuttavia, non è un compito facile tra le sfide legate ai dati (eterogeneità, volume e normative) e alle risorse limitate (elaborazione, connettività di rete, archiviazione e persino competenze IT). Questi possono essere ampiamente descritti in due categorie:
- Tempo/costo per l'implementazione: Ogni distribuzione è costituita da diversi livelli di hardware e software che devono essere installati, configurati e testati prima della distribuzione. Oggi, un professionista dell'assistenza può impiegare fino a una settimana o due per l'installazione in ogni luogo, limitando fortemente la rapidità e la convenienza con cui le aziende possono ampliare le implementazioni all’interno della propria organizzazione.
- Gestione del secondo giorno: Il vasto numero di edge distribuiti e la posizione geografica di ciascuna implementazione potrebbero spesso rendere proibitivamente costoso fornire supporto IT locale in ciascuna sede per monitorare, mantenere e aggiornare tali implementazioni.
Implementazioni di intelligenza artificiale perimetrale
IBM ha sviluppato un'architettura edge che affronta queste sfide portando un modello di dispositivo hardware/software (HW/SW) integrato nelle implementazioni AI edge. È costituito da diversi paradigmi chiave che aiutano la scalabilità delle implementazioni dell’intelligenza artificiale:
- Provisioning zero-touch basato su policy dell'intero stack software.
- Monitoraggio continuo dell'integrità del sistema edge
- Funzionalità per gestire e inviare aggiornamenti software/di sicurezza/configurazione a numerose edge location, il tutto da una posizione centrale basata su cloud per la gestione day-2.
Un'architettura distribuita hub-and-spoke può essere utilizzata per scalare le distribuzioni di intelligenza artificiale aziendale all'edge, in cui un cloud centrale o un data center aziendale funge da hub e l'appliance edge-in-a-box funge da raggio in una posizione edge. Questo modello hub and speak, che si estende agli ambienti cloud ibridi ed edge, illustra al meglio l'equilibrio necessario per utilizzare in modo ottimale le risorse necessarie per le operazioni FM (vedere Figura 2).
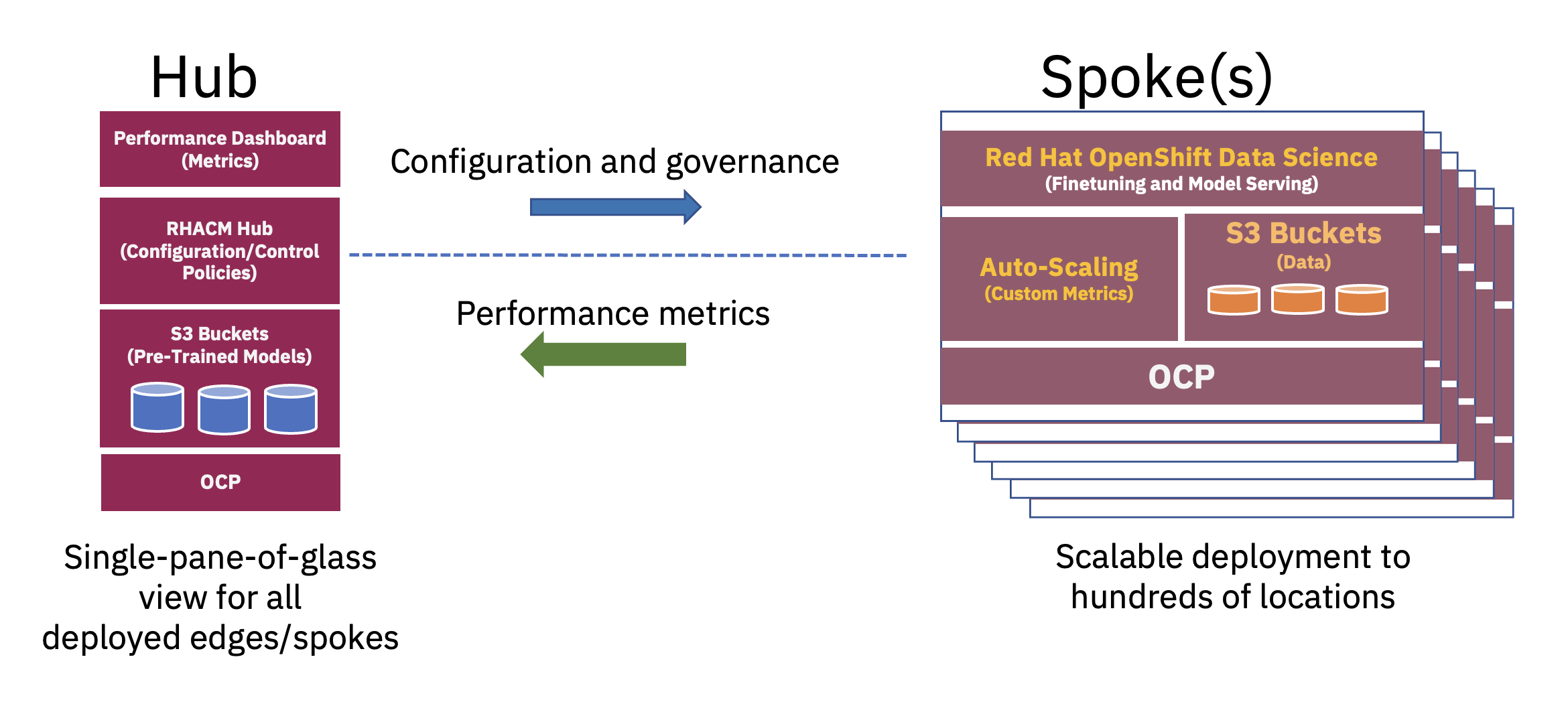
Il pre-addestramento di questi modelli LLM (Large Language Model) di base e di altri tipi di modelli di base che utilizzano tecniche di auto-supervisione su vasti set di dati senza etichetta spesso richiede notevoli risorse di elaborazione (GPU) ed è meglio eseguirlo presso un hub. Le risorse di elaborazione virtualmente illimitate e le grandi quantità di dati spesso archiviati nel cloud consentono il pre-addestramento di modelli con parametri di grandi dimensioni e il miglioramento continuo dell'accuratezza di questi modelli di base.
D'altro canto, l'ottimizzazione di questi FM di base per le attività downstream, che richiedono solo poche decine o centinaia di campioni di dati etichettati e servizi di inferenza, può essere eseguita solo con poche GPU a livello aziendale. Ciò consente ai dati etichettati sensibili (o ai dati fiore all'occhiello dell'azienda) di rimanere in sicurezza all'interno dell'ambiente operativo aziendale, riducendo al tempo stesso i costi di trasferimento dei dati.
Utilizzando un approccio full-stack per la distribuzione delle applicazioni all'edge, un data scientist può eseguire la messa a punto, il test e la distribuzione dei modelli. Ciò può essere realizzato in un unico ambiente riducendo al contempo il ciclo di vita dello sviluppo per fornire nuovi modelli di intelligenza artificiale agli utenti finali. Piattaforme come Red Hat OpenShift Data Science (RHODS) e Red Hat OpenShift AI recentemente annunciate forniscono strumenti per sviluppare e distribuire rapidamente modelli AI pronti per la produzione in nuvola distribuita e ambienti periferici.
Infine, servire il modello di intelligenza artificiale ottimizzato a livello aziendale riduce significativamente la latenza spesso associata all’acquisizione, trasmissione, trasformazione ed elaborazione dei dati. Disaccoppiando la formazione preliminare nel cloud dalla messa a punto e dall'inferenza sull'edge si riducono i costi operativi complessivi riducendo il tempo richiesto e i costi di spostamento dei dati associati a qualsiasi attività di inferenza (vedere la Figura 3).
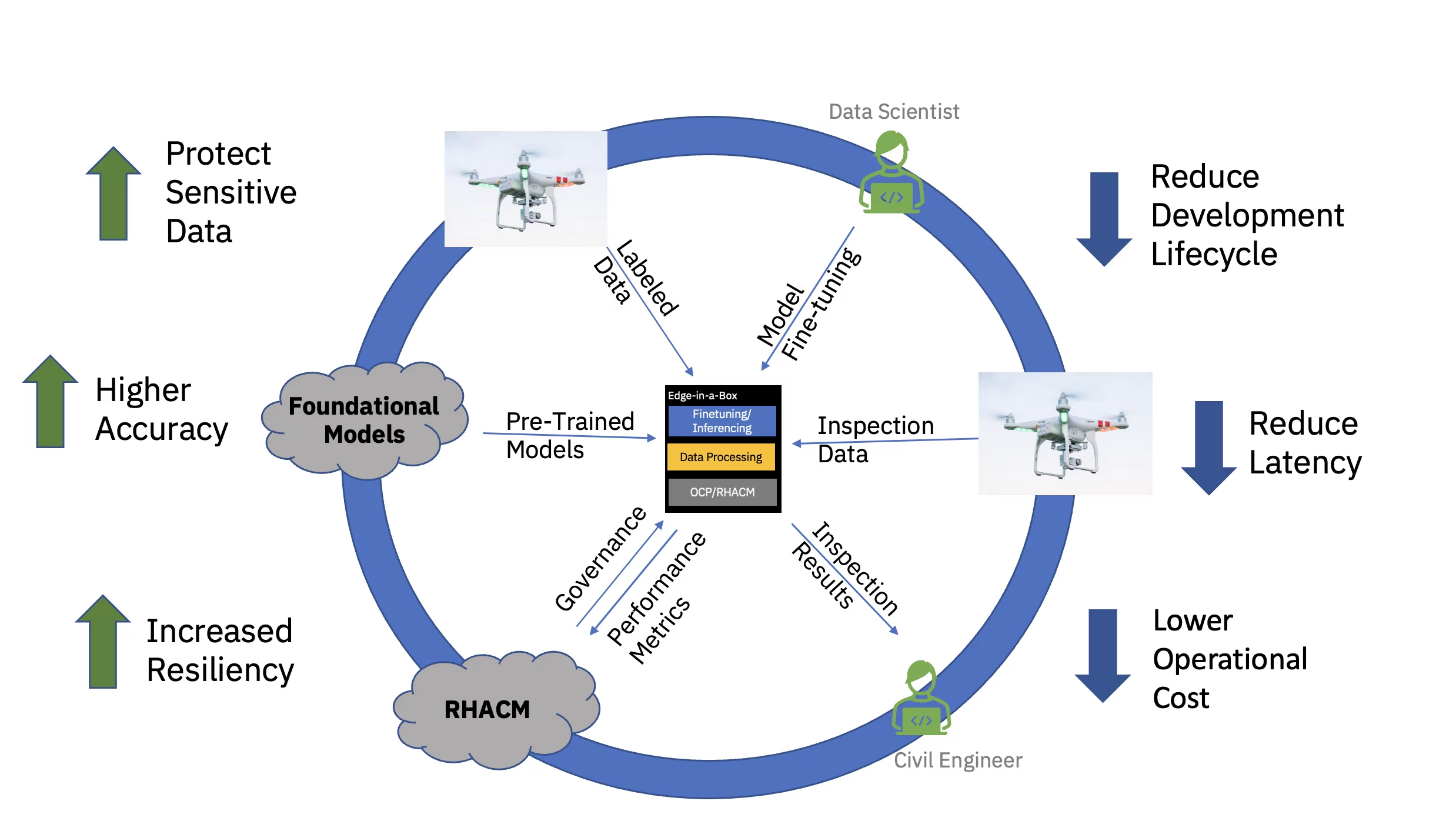
Per dimostrare questa proposta di valore end-to-end, un esemplare modello di base basato su un trasformatore di visione per le infrastrutture civili (pre-addestrato utilizzando set di dati pubblici e personalizzati specifici del settore) è stato messo a punto e distribuito per l'inferenza su un edge a tre nodi (parlato) grappolo. Lo stack software includeva Red Hat OpenShift Container Platform e Red Hat OpenShift Data Science. Questo cluster edge era inoltre connesso a un'istanza dell'hub Red Hat Advanced Cluster Management for Kubernetes (RHACM) in esecuzione nel cloud.
Provisioning zero-touch
Il provisioning zero-touch basato su policy è stato eseguito con Red Hat Advanced Cluster Management for Kubernetes (RHACM) tramite policy e tag di posizionamento, che collegano cluster edge specifici a una serie di componenti e configurazioni software. Questi componenti software, che si estendono all'intero stack e coprono elaborazione, storage, rete e carico di lavoro AI, sono stati installati utilizzando vari operatori OpenShift, fornendo i servizi applicativi necessari e S3 Bucket (storage).
Il modello fondazionale (FM) pre-addestrato per le infrastrutture civili è stato messo a punto tramite un Jupyter Notebook all'interno di Red Hat OpenShift Data Science (RHODS) utilizzando dati etichettati per classificare sei tipi di difetti riscontrati sui ponti di cemento. Il servizio di inferenza di questo FM ottimizzato è stato dimostrato anche utilizzando un server Triton. Inoltre, il monitoraggio dello stato di questo sistema edge è stato reso possibile aggregando i parametri di osservabilità dai componenti hardware e software tramite Prometheus al dashboard centrale RHACM nel cloud. Le imprese di infrastrutture civili possono implementare questi FM nelle loro edge location e utilizzare le immagini dei droni per rilevare i difetti quasi in tempo reale, accelerando il time-to-insight e riducendo i costi di spostamento di grandi volumi di dati ad alta definizione da e verso il cloud.
Sommario
La combinazione di IBM wasonx le funzionalità della piattaforma dati e AI per Foundation Model (FM) con un'appliance edge-in-a-box consentono alle aziende di eseguire carichi di lavoro AI per la messa a punto e l'inferenza FM a livello operativo. Questa appliance è in grado di gestire casi d'uso complessi immediatamente e crea il framework hub-and-spoke per la gestione centralizzata, l'automazione e il self-service. Le implementazioni Edge FM possono essere ridotte da settimane a ore con successo ripetibile, maggiore resilienza e sicurezza.
Ulteriori informazioni sui modelli fondamentali
Assicurati di controllare tutte le puntate di questa serie di post del blog sull'edge computing:
Altro da Cloud




- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://www.ibm.com/blog/foundational-models-at-the-edge/
- :ha
- :È
- :non
- :Dove
- $ SU
- 08
- 1
- 10
- 13
- 15%
- 20
- 2023
- 22
- 28
- 29
- 30
- 300
- 39
- 400
- 41
- 7
- 70
- 9
- a
- WRI
- accelerare
- accesso
- compiuto
- precisione
- acquisizione
- operanti in
- atti
- adattato
- Inoltre
- indirizzo
- indirizzi
- Adozione
- Avanzate
- avanzamenti
- Pubblicità
- AI
- Adozione AI
- Modelli AI
- Piattaforma AI
- aiuto
- Algoritmi
- Tutti
- consentire
- consente
- anche
- Tra
- quantità
- importi
- amp
- an
- .
- analitica
- ed
- ha annunciato
- in qualsiasi
- ovunque
- Applicazioni
- applicazioni
- approccio
- architettura
- SONO
- Italia
- articolo
- artificiale
- intelligenza artificiale
- Intelligenza artificiale (AI)
- AS
- associato
- At
- autore
- Automatizzata
- Automazione
- disponibile
- Avenue
- precedente
- Equilibrio
- Banca
- Banche
- base
- BE
- perché
- diventare
- diventando
- stato
- Inizio
- essendo
- CREDIAMO
- MIGLIORE
- legare
- Blog
- Post di Blog
- blog
- entrambi
- Scatola
- ponti
- Portare
- Porta
- ampio
- in linea di massima
- Costruzione
- costruisce
- costruito
- affari
- by
- Materiale
- funzionalità
- capitale
- Catturare
- carbonio
- carta
- Carte
- casi
- CAT
- categoria
- Causare
- centro
- centrale
- Banca Centrale
- valute digitali della banca centrale
- centralizzata
- catena
- sfide
- il cambiamento
- cambiando
- dai un'occhiata
- scelte
- cerchi
- CIS
- civile
- classe
- classificare
- pulire campo
- clienti
- strettamente
- Cloud
- Cluster
- colore
- colorato
- combinando
- competitivo
- complesso
- complessità
- conformità
- componenti
- Calcolare
- informatica
- Configurazione
- configurato
- collegato
- Connettività
- consiste
- Contenitore
- continua
- di controllo
- Costo
- Costi
- potuto
- copertura
- criptovaluta
- CSS
- valute
- costume
- cliente
- esperienza del cliente
- Clienti
- cruscotto
- dati
- Banca dati
- Piattaforma dati
- scienza dei dati
- scienziato di dati
- dataset
- Data
- dedicato
- Predefinito
- definizioni
- consegnare
- dimostrare
- dimostrato
- schierare
- schierato
- distribuzione
- deployment
- implementazioni
- descritta
- descrizione
- progettato
- sviluppare
- sviluppato
- Mercato
- digitale
- valute digitali
- digitalizzazione
- Rottura
- dirompente
- Disgregatori
- distribuito
- distretto
- dominio
- domini
- fatto
- guidare
- guida
- fuco
- ogni
- facile
- ecosistema
- bordo
- edge computing
- ELEVATE
- elevata
- enable
- Abilita
- fine
- da un capo all'altro
- ingegnere
- Ingegneria
- entrare
- Impresa
- aziende
- arrivo
- Ambiente
- ambienti
- epoca
- particolarmente
- eccetera
- Etere (ETH)
- Anche
- eventi
- Ogni
- si è evoluta
- esaminando
- Esempi
- eseguire
- esistere
- uscita
- costoso
- esperienza
- esperti
- AI spiegabile
- spiegando
- estendendo
- estremamente
- Fattori
- FAST
- più veloce
- pochi
- campo
- figura
- finanziario
- Istituzioni finanziarie
- finanziamento
- Nome
- pavimenti
- seguire
- i seguenti
- font
- Nel
- prima linea
- essere trovato
- Fondazione
- frazione
- Contesto
- da
- pieno
- Stack completo
- Inoltre
- generalmente
- generato
- generatore
- geografico
- Geopolitica
- Dare
- globali
- commercio globale
- la governance
- GPU
- GPU
- Griglia
- cura
- maniglia
- Hardware
- ha
- Avere
- Salute e benessere
- altezza
- Aiuto
- aiutare
- aiuta
- alta definizione
- superiore
- vivamente
- storia
- host
- ORE
- Come
- Tutorial
- Tuttavia
- HTTPS
- Hub
- Gli esseri umani
- centinaia
- IBRIDO
- nuvola ibrida
- IBM
- IBM Cloud
- ICO
- ICON
- illustra
- Immagine
- Impact
- importanza
- miglioramento
- in
- includere
- incluso
- crescente
- sempre più
- Index
- industriale
- industrie
- industria
- specifici del settore
- inflazione
- Inflessione
- Punto di flessione
- influenzato
- Infrastruttura
- iniziativa
- Innovazione
- creativi e originali
- Ingressi
- intuizioni
- esempio
- istituzioni
- integrato
- Intelligence
- intrinseco
- l'introduzione di
- IT
- Assistenza informatica
- Journeys
- jpg
- saltare
- Notebook Jupyter
- ad appena
- solo uno
- tenere
- Le
- kubernetes
- etichettatura
- Lingua
- grandi
- maggiormente
- Latenza
- con i più recenti
- galline ovaiole
- principale
- IMPARARE
- apprendimento
- Leva
- ciclo di vita
- piace
- senza limiti
- linux
- locale
- località
- località
- posizioni
- Lunghi
- Guarda
- macchina
- machine learning
- fatto
- mantenere
- make
- FA
- gestire
- gestione
- consigliato per la
- molti
- marcatura
- massiccio
- Mastercard
- Importanza
- max-width
- meccanismi di
- metodi
- Metrica
- verbale
- minimizzando
- verbale
- ML
- Mobile
- modello
- modelli
- moderno
- modernizzazione
- modernizzare
- Monitorare
- monitoraggio
- Scopri di più
- movimento
- in movimento
- Nome
- Navigazione
- Vicino
- necessaria
- Bisogno
- di applicazione
- esigenze
- Rete
- New
- GENERAZIONE
- nlp
- taccuino
- Niente
- adesso
- numero
- numerose
- of
- offerta
- di frequente
- on
- ONE
- esclusivamente
- aprire
- ha aperto
- operativa
- Operazioni
- Operatori
- ottimizzati
- or
- organizzazione
- Altro
- nostro
- su
- complessivo
- Packages
- pagina
- parametro
- Pagamento
- metodi di pagamento
- pagamenti
- eseguire
- eseguita
- PHP
- collocamento
- piattaforma
- Piattaforme
- Platone
- Platone Data Intelligence
- PlatoneDati
- plug-in
- punto
- Termini e Condizioni
- politica
- posizione
- possibile
- Post
- Post
- potenziale
- energia
- potente
- Previsioni
- Precedente
- Privacy
- un bagno
- problemi
- lavorazione
- produrre
- professionale
- proposizione
- fornire
- la percezione
- Spingi
- gamma
- rapidamente
- Lettura
- tempo reale
- recentemente
- record
- registrazione
- Rosso
- Red Hat
- ridurre
- Ridotto
- riduce
- riducendo
- normativa
- Regolatori
- normativo
- relazionato
- rimosso
- ripetibile
- richiedere
- necessario
- Requisiti
- requisito
- riparazioni
- Risorse
- risposta
- responsabile
- di risposta
- nello specifico retail
- Aumento
- robot
- Correre
- running
- tranquillamente
- stesso
- Scalabilità
- Scala
- scala ai
- scala
- Scienze
- Scienziato
- allo
- script
- Secondo
- in modo sicuro
- problemi di
- vedere
- vedendo
- prodotti
- Fai da te
- delicata
- SEO
- Settembre
- Serie
- server
- servizio
- Servizi
- servizio
- Sessione
- sessioni
- set
- alcuni
- Condividi
- mostrare attraverso le sue creazioni
- significativa
- significativamente
- simile
- da
- Singapore
- singolo
- unico ambiente
- site
- Siti
- SIX
- abilità
- piccole
- EMS
- PMI
- Software
- componenti software
- soluzione
- sovranità
- lo spazio
- tensione
- specifico
- in particolare
- Sponsored
- pila
- inizia a
- state-of-the-art
- soggiorno
- Passi
- conservazione
- Tornare al suo account
- memorizzati
- negozi
- Tempesta
- studio
- soggetto
- il successo
- tale
- suggerisce
- fornire
- supply chain
- supporto
- sicuro
- sistema
- Fai
- preso
- Task
- task
- tecniche
- Tecnologia
- Telco
- Temenos
- decine
- Terraform
- testato
- Testing
- che
- Il
- loro
- tema
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- Attraverso
- tempo
- tempestivo
- volte
- Titolo
- a
- oggi
- insieme
- toolkit
- strumenti
- top
- commercio
- tradizionale
- Treni
- allenato
- Training
- trasferimento
- Trasformare
- Trasformazione
- trasformazioni
- trasparente
- tritone
- seconda
- Digitare
- Tipi di
- scatenato
- Aggiornanento
- Aggiornamenti
- URL
- us
- uso
- utilizzato
- utenti
- utilizzando
- utilizzare
- utilizzati
- Prezioso
- APPREZZIAMO
- proposta di valore
- varietà
- vario
- Fisso
- via
- Visualizza
- potenzialmente
- volume
- volumi
- W
- In attesa
- Portafoglio
- Prima
- Wave
- Modo..
- modi
- we
- settimana
- Settimane
- Che
- Che cosa è l'
- quando
- quale
- while
- OMS
- perché
- largo
- Vasta gamma
- con
- entro
- donna
- WordPress
- Lavora
- flussi di lavoro
- lavoro
- sarebbe
- scritto
- Trasferimento da aeroporto a Sharm
- zefiro











