Pandas è una libreria open source potente e ampiamente utilizzata per la manipolazione e l'analisi dei dati tramite Python. Una delle sue caratteristiche principali è la capacità di raggruppare i dati utilizzando la funzione groupby suddividendo un DataFrame in gruppi basati su una o più colonne e quindi applicando varie funzioni di aggregazione a ciascuna di esse.

Immagine da Unsplash
Il groupby La funzione è incredibilmente potente, in quanto consente di riassumere e analizzare rapidamente grandi set di dati. Ad esempio, è possibile raggruppare un set di dati in base a una colonna specifica e calcolare la media, la somma o il conteggio delle colonne rimanenti per ciascun gruppo. Puoi anche raggruppare per più colonne per ottenere una comprensione più granulare dei tuoi dati. Inoltre, consente di applicare funzioni di aggregazione personalizzate, che possono essere uno strumento molto potente per attività di analisi dei dati complesse.
In questo tutorial imparerai come utilizzare la funzione groupby in Pandas per raggruppare diversi tipi di dati ed eseguire diverse operazioni di aggregazione. Alla fine di questo tutorial, dovresti essere in grado di utilizzare questa funzione per analizzare e riepilogare i dati in vari modi.
I concetti vengono interiorizzati se praticati bene e questo è ciò che faremo dopo, ovvero mettere in pratica la funzione groupby di Panda. Si consiglia di utilizzare un Notebook Jupyter per questo tutorial in quanto puoi vedere l'output ad ogni passaggio.
Genera dati di esempio
Importa le seguenti librerie:
- Panda: per creare un dataframe e applicare il raggruppamento per
- Casuale – Per generare dati casuali
- Pprint – Per stampare dizionari
import pandas as pd
import random
import pprint
Successivamente, inizializzeremo un dataframe vuoto e inseriremo i valori per ogni colonna come mostrato di seguito:
df = pd.DataFrame()
names = [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard",
] major = [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology",
] yr_adm = random.sample(list(range(2018, 2023)) * 100, 15)
marks = random.sample(range(40, 101), 15)
num_add_sbj = random.sample(list(range(2)) * 100, 15) df["St_Name"] = names
df["Major"] = random.sample(major * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
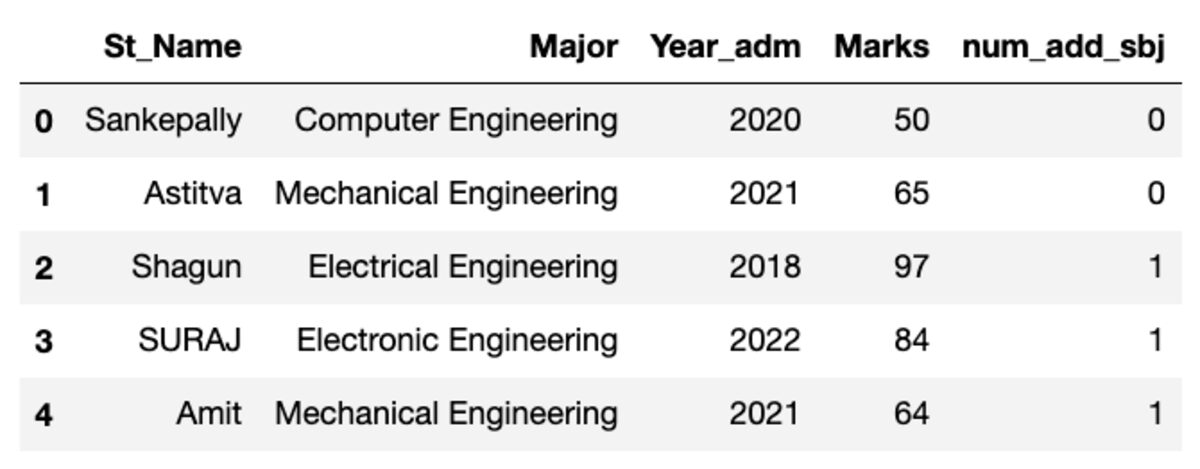
df.head()
Suggerimento bonus: un modo più pulito per eseguire la stessa attività è creare un dizionario di tutte le variabili e i valori e successivamente convertirlo in un dataframe.
student_dict = { "St_Name": [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard", ], "Major": random.sample( [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology", ] * 100, 15, ), "Year_adm": random.sample(list(range(2018, 2023)) * 100, 15), "Marks": random.sample(range(40, 101), 15), "num_add_sbj": random.sample(list(range(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
Il dataframe è simile a quello mostrato di seguito. Quando si esegue questo codice, alcuni dei valori non corrisponderanno poiché stiamo utilizzando un campione casuale.
Fare gruppi
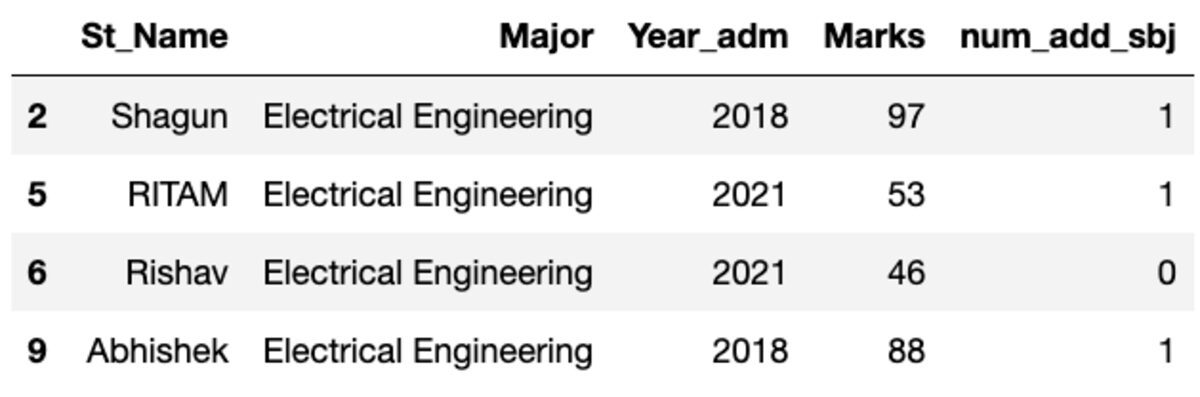
Raggruppiamo i dati in base all'oggetto "Principale" e applichiamo il filtro di gruppo per vedere quanti record rientrano in questo gruppo.
groups = df.groupby('Major')
groups.get_group('Electrical Engineering')
Quindi, quattro studenti appartengono alla specializzazione in Ingegneria Elettrica.
Puoi anche raggruppare per più di una colonna (Major e num_add_sbj in questo caso).
groups = df.groupby(['Major', 'num_add_sbj'])
Si noti che tutte le funzioni aggregate che possono essere applicate a gruppi con una colonna possono essere applicate a gruppi con più colonne. Per il resto dell'esercitazione, concentriamoci sui diversi tipi di aggregazioni utilizzando una singola colonna come esempio.
Creiamo i gruppi usando groupby nella colonna "Major".
groups = df.groupby('Major')Applicazione di funzioni dirette
Diciamo che vuoi trovare i voti medi in ogni Major. Cosa faresti?
- Scegli la colonna Marchi
- Applicare la funzione media
- Applica la funzione di arrotondamento per arrotondare i segni a due cifre decimali (facoltativo)
groups['Marks'].mean().round(2)
Major
Artificial Intelligence 63.6
Computer Engineering 45.5
Electrical Engineering 71.0
Electronic Engineering 92.0
Mechanical Engineering 64.5
Name: Marks, dtype: float64
Aggregato
Un altro modo per ottenere lo stesso risultato è utilizzare una funzione aggregata come mostrato di seguito:
groups['Marks'].aggregate('mean').round(2)
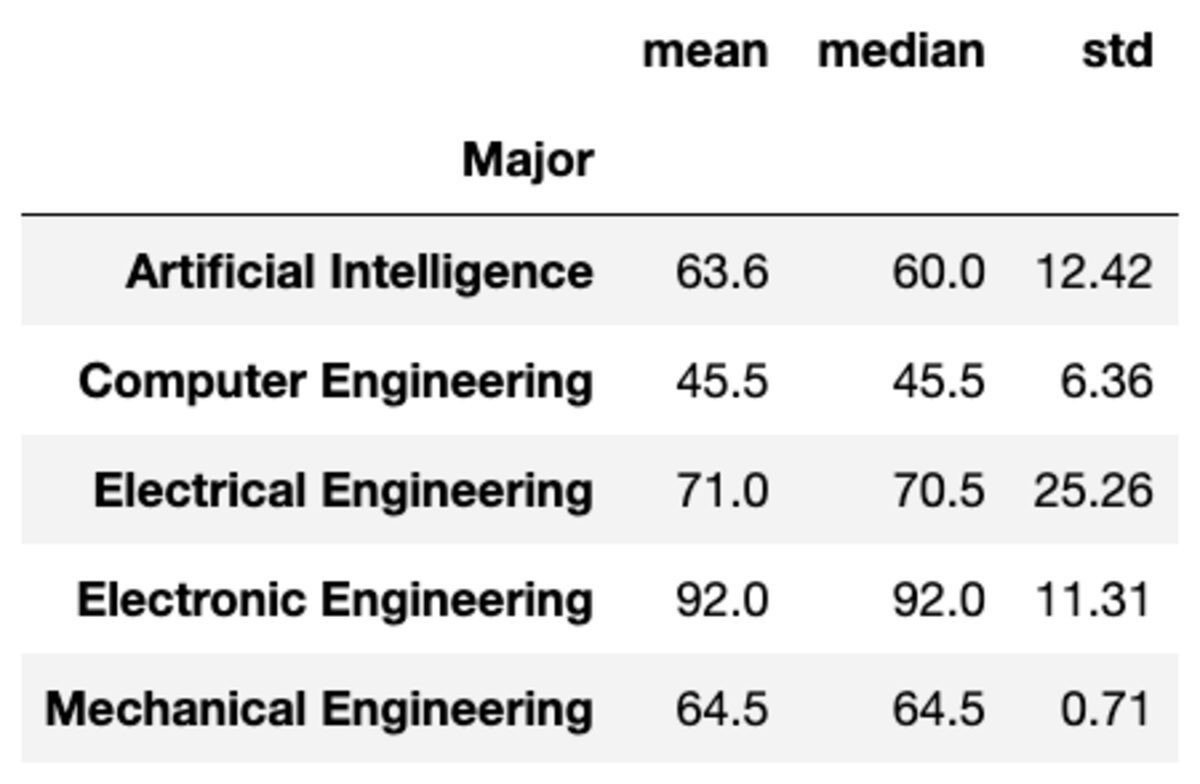
È inoltre possibile applicare più aggregazioni ai gruppi passando le funzioni come un elenco di stringhe.
groups['Marks'].aggregate(['mean', 'median', 'std']).round(2)
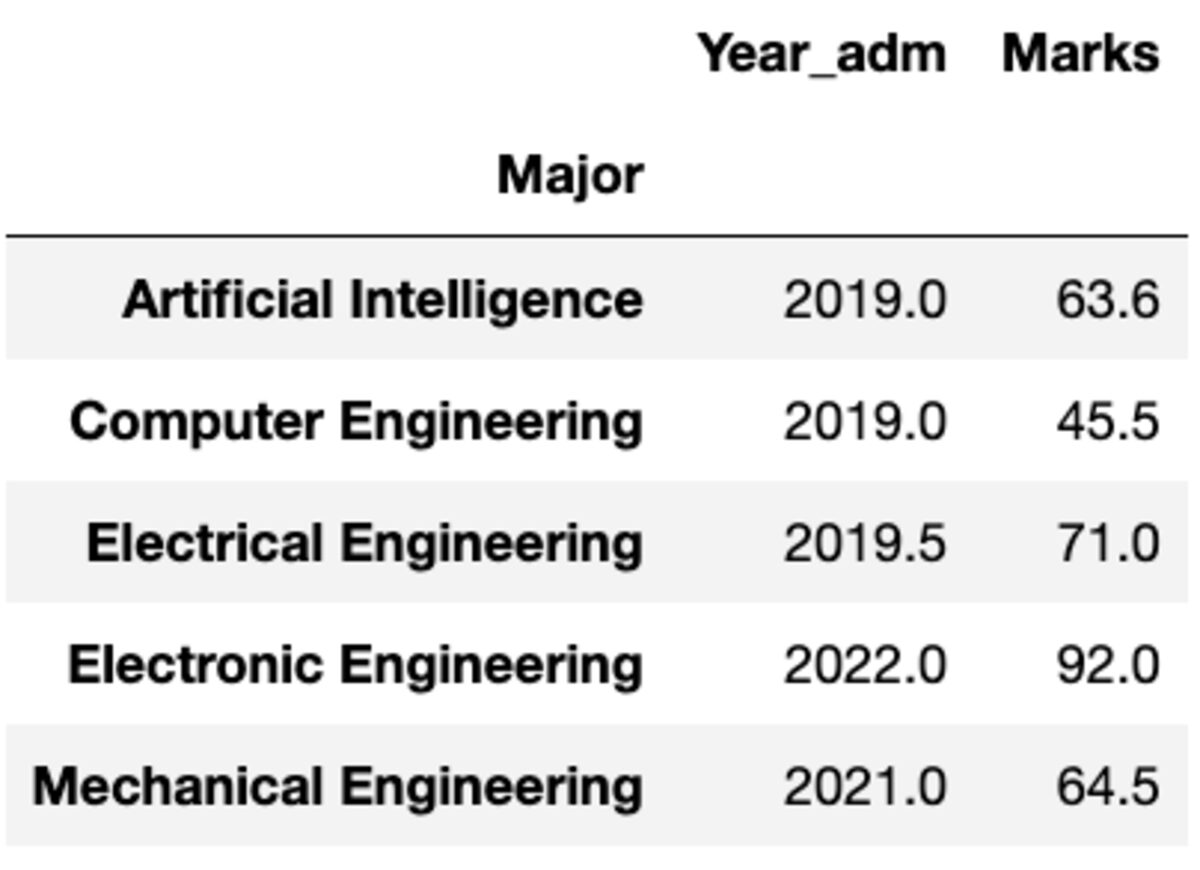
Ma cosa succede se è necessario applicare una funzione diversa a una colonna diversa. Non preoccuparti. Puoi anche farlo passando la coppia {column: function}.
groups.aggregate({'Year_adm': 'median', 'Marks': 'mean'})
Trasformazioni
Potrebbe benissimo essere necessario eseguire trasformazioni personalizzate in una particolare colonna che possono essere facilmente ottenute utilizzando groupby(). Definiamo uno scalare standard simile a quello disponibile nel modulo di preelaborazione di sklearn. Puoi trasformare tutte le colonne chiamando il metodo transform e passando la funzione personalizzata.
def standard_scalar(x): return (x - x.mean())/x.std()
groups.transform(standard_scalar)
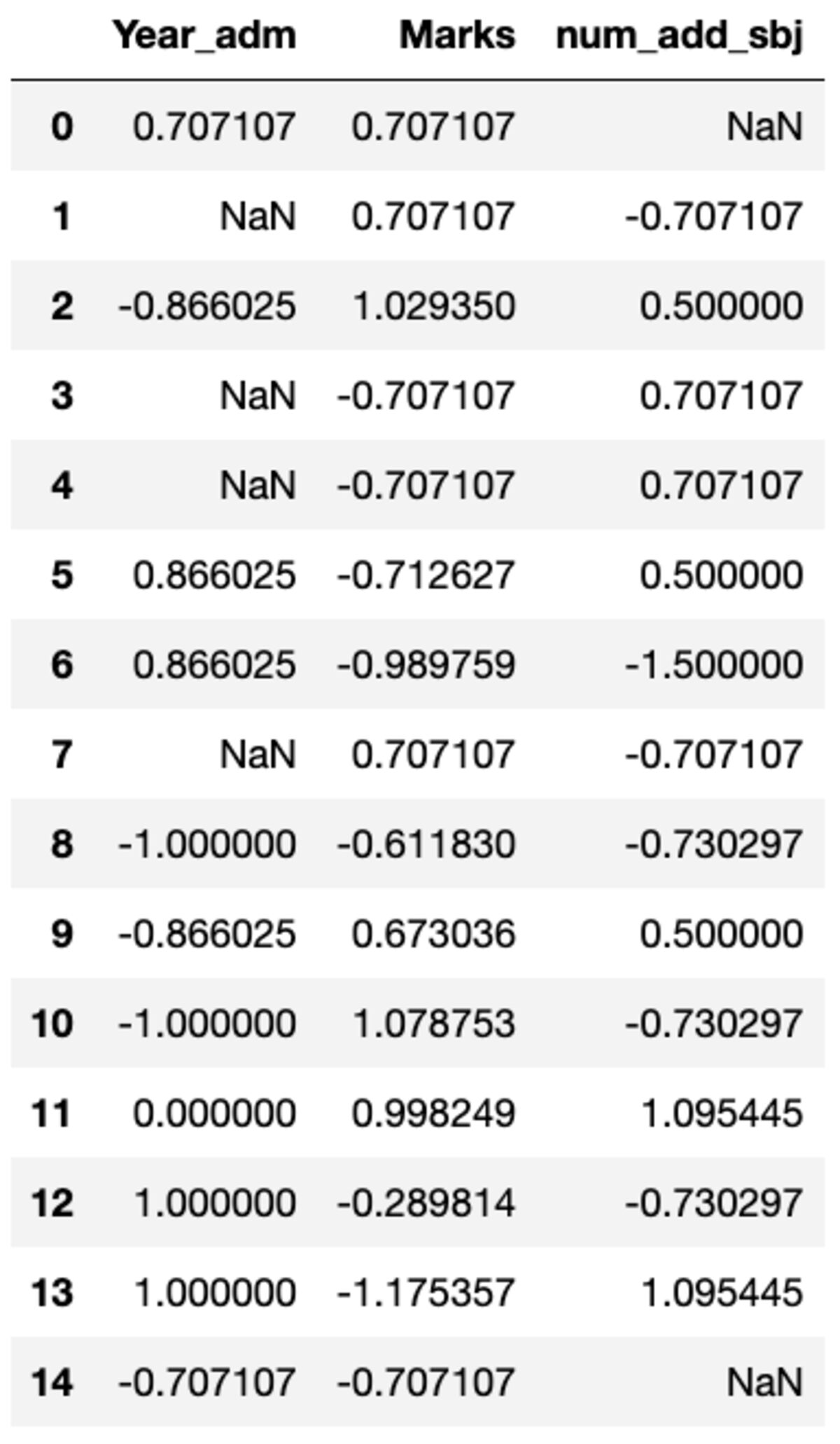
Si noti che "NaN" rappresenta i gruppi con deviazione standard pari a zero.
Filtro
Potresti voler verificare quale "Major" è meno performante, ad esempio quello in cui i "voti" medi degli studenti sono inferiori a 60. Richiede l'applicazione di un metodo di filtro ai gruppi con una funzione al suo interno. Il codice seguente utilizza a funzione lambda per ottenere i risultati filtrati.
groups.filter(lambda x: x['Marks'].mean() 60)

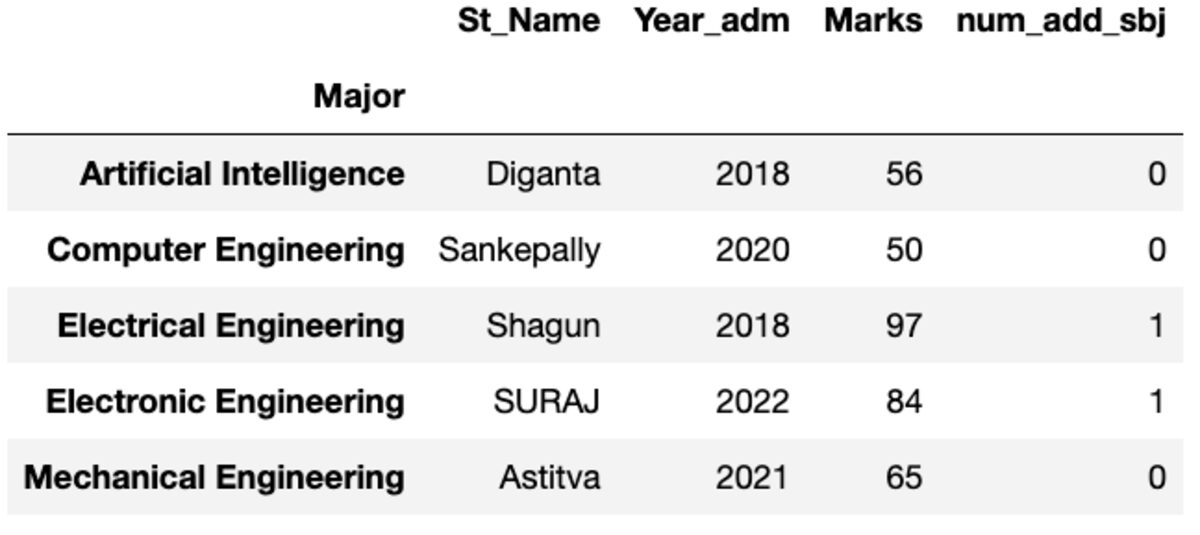
Nome
Ti dà la sua prima istanza ordinata per indice.
groups.first()
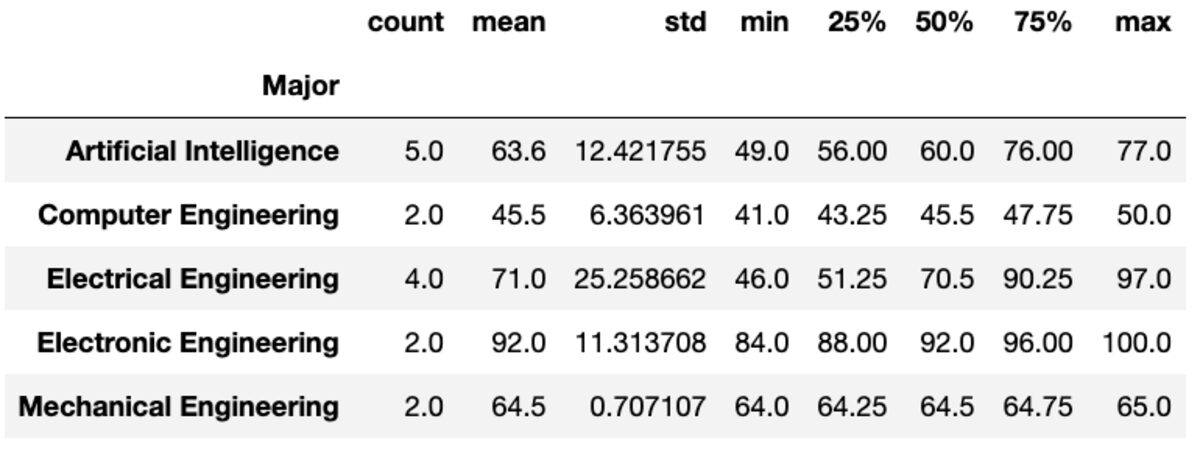
Descrivere
Il metodo "descrivi" restituisce statistiche di base come conteggio, media, std, min, max, ecc. per le colonne specificate.
groups['Marks'].describe()
Taglia
Size, come suggerisce il nome, restituisce la dimensione di ciascun gruppo in termini di numero di record.
groups.size()
Major
Artificial Intelligence 5
Computer Engineering 2
Electrical Engineering 4
Electronic Engineering 2
Mechanical Engineering 2
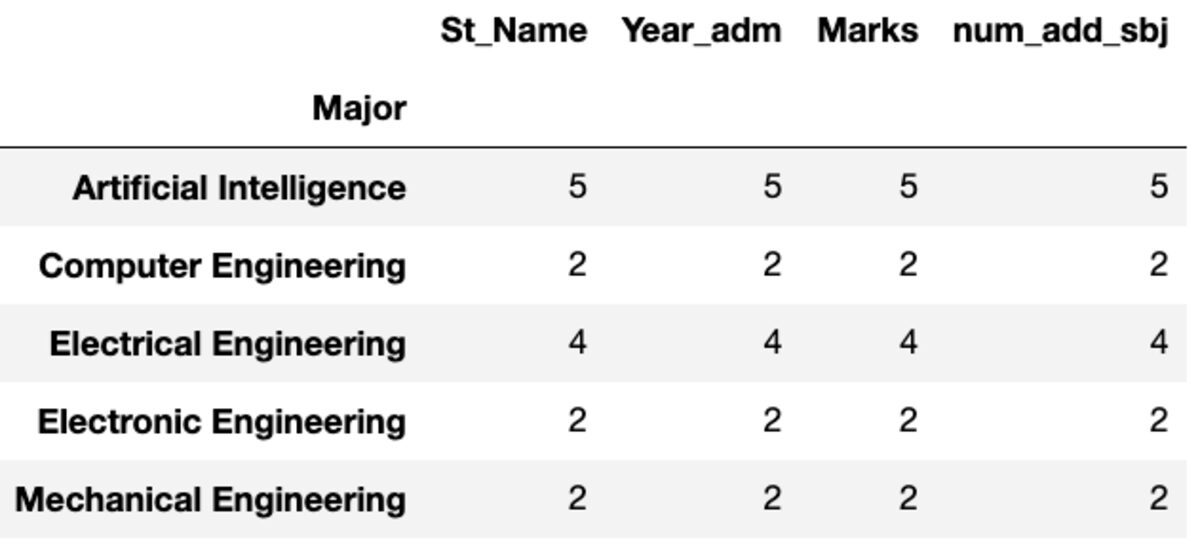
dtype: int64Conte e Nunique
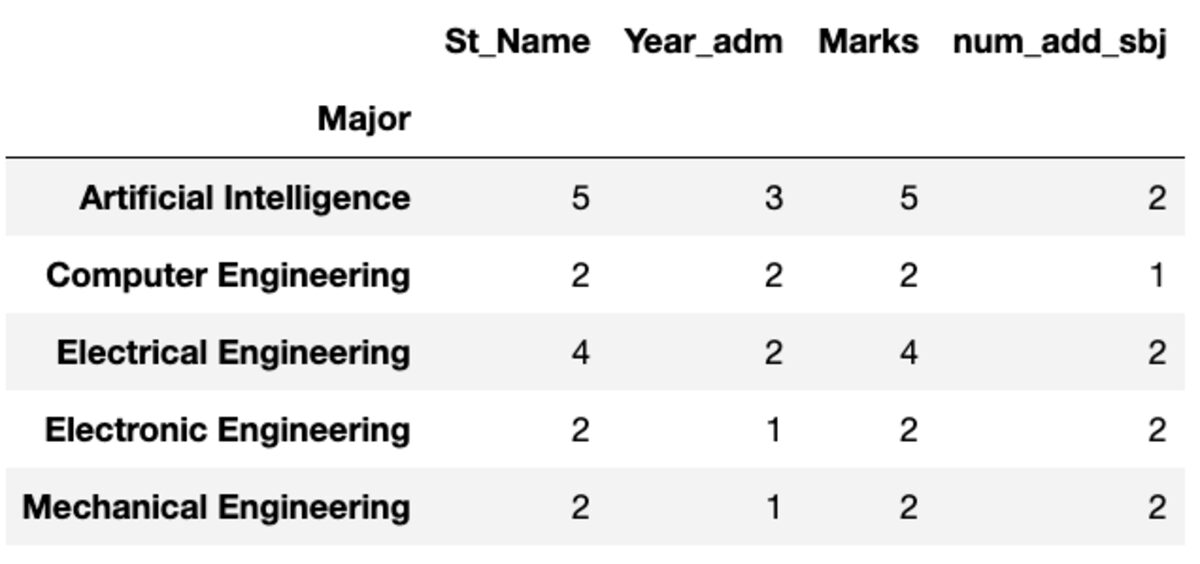
"Count" restituisce tutti i valori mentre "Nunique" restituisce solo i valori univoci in quel gruppo.
groups.count()
groups.nunique()
Rinominare
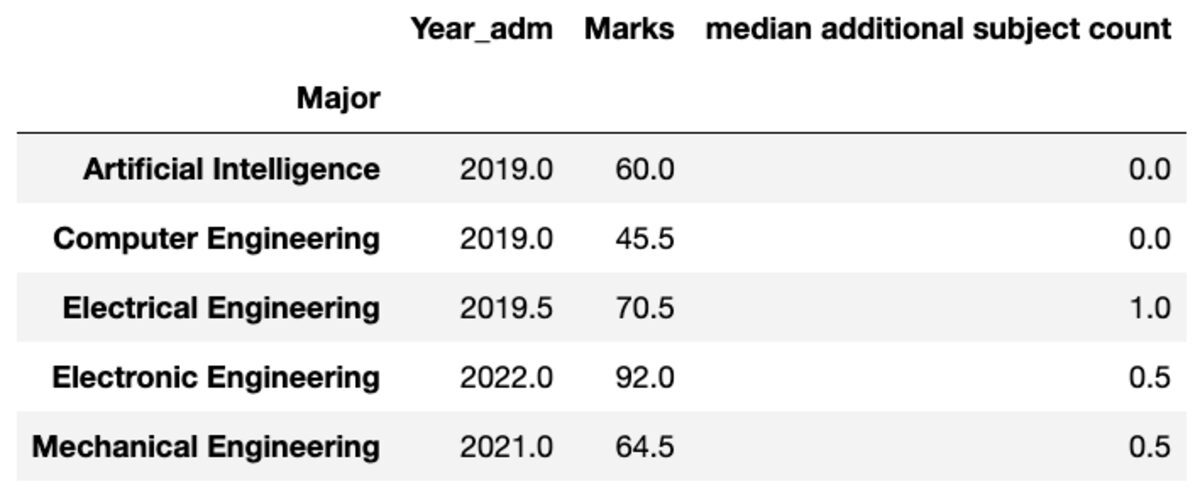
Puoi anche rinominare il nome delle colonne aggregate secondo le tue preferenze.
groups.aggregate("median").rename( columns={ "yr_adm": "median year of admission", "num_add_sbj": "median additional subject count", }
)
- Sii chiaro sullo scopo del gruppo: Stai cercando di raggruppare i dati per una colonna per ottenere la media di un'altra colonna? O stai cercando di raggruppare i dati per più colonne per ottenere il conteggio delle righe in ciascun gruppo?
- Comprendere l'indicizzazione del frame di dati: La funzione groupby utilizza l'indice per raggruppare i dati. Se desideri raggruppare i dati per colonna, assicurati che la colonna sia impostata come indice oppure puoi utilizzare .set_index()
- Utilizzare la funzione aggregata appropriata: Può essere utilizzato con varie funzioni di aggregazione come mean(), sum(), count(), min(), max()
- Usa il parametro as_index: Se impostato su False, questo parametro indica ai panda di utilizzare le colonne raggruppate come colonne normali invece dell'indice.
Puoi anche utilizzare groupby() insieme ad altre funzioni panda come pivot_table(), crosstab() e cut() per estrarre più informazioni dai tuoi dati.
Una funzione groupby è un potente strumento per l'analisi e la manipolazione dei dati in quanto consente di raggruppare righe di dati in base a una o più colonne e quindi eseguire calcoli aggregati sui gruppi. L'esercitazione ha dimostrato vari modi per usare la funzione groupby con l'aiuto di esempi di codice. Spero che ti fornisca una comprensione delle diverse opzioni che ne derivano e anche di come aiutano nell'analisi dei dati.
Vidhi Chug è uno stratega dell'intelligenza artificiale e un leader della trasformazione digitale che lavora all'intersezione di prodotto, scienza e ingegneria per costruire sistemi di apprendimento automatico scalabili. È una pluripremiata leader dell'innovazione, un'autrice e una relatrice internazionale. La sua missione è democratizzare l'apprendimento automatico e rompere il gergo affinché tutti possano far parte di questa trasformazione.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://www.kdnuggets.com/2023/01/effectively-pandas-groupby.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-effectively-use-pandas-groupby
- 10
- 100
- 2018
- 2023
- 7
- 9
- a
- capacità
- capace
- Raggiungere
- raggiunto
- aggiuntivo
- Inoltre
- aggregazione
- AI
- Tutti
- consente
- .
- analizzare
- ed
- Un altro
- applicato
- APPLICA
- AMMISSIONE
- opportuno
- artificiale
- intelligenza artificiale
- autore
- disponibile
- media
- premiata
- basato
- basic
- sotto
- biotecnologie
- Rompere
- costruire
- calcolare
- chiamata
- Custodie
- dai un'occhiata
- pulire campo
- codice
- Colonna
- colonne
- Venire
- complesso
- computer
- Ingegneria Informatica
- creare
- Creazione
- costume
- dati
- analisi dei dati
- dataset
- democratizzare
- dimostrato
- deviazione
- diverso
- digitale
- DIGITAL TRANSFORMATION
- dirette
- Dont
- ogni
- facilmente
- in maniera efficace
- Ingegneria Elettrica
- Elettronico
- Ingegneria
- eccetera
- tutti
- esempio
- Esempi
- estratto
- Autunno
- Caratteristiche
- riempire
- filtro
- Trovate
- Nome
- Focus
- i seguenti
- TELAIO
- da
- function
- funzioni
- generare
- ottenere
- dato
- dà
- andando
- Gruppo
- Gruppo
- mani su
- Aiuto
- speranza
- Come
- Tutorial
- HTML
- HTTPS
- importare
- in
- incredibilmente
- Index
- Innovazione
- intuizioni
- esempio
- invece
- Intelligence
- Internazionale
- intersezione
- IT
- gergo
- KDnuggets
- Le
- grandi
- leader
- IMPARARE
- apprendimento
- biblioteche
- Biblioteca
- Lista
- SEMBRA
- macchina
- machine learning
- maggiore
- make
- Manipolazione
- molti
- partita
- max
- meccanico
- Ingegneria meccanica
- medie
- metodo
- Missione
- modulo
- Scopri di più
- multiplo
- Nome
- nomi
- Bisogno
- GENERAZIONE
- numero
- ONE
- open source
- Operazioni
- Opzioni
- Altro
- panda
- parametro
- parte
- particolare
- Di passaggio
- eseguire
- Partner
- Platone
- Platone Data Intelligence
- PlatoneDati
- potente
- Stampa
- Prodotto
- fornisce
- scopo
- Python
- rapidamente
- casuale
- raccomandato
- record
- Basic
- rimanente
- rappresenta
- richiede
- REST
- colpevole
- Risultati
- ritorno
- problemi
- Richard
- tondo
- running
- stesso
- scalabile
- SCIENZE
- set
- dovrebbero
- mostrato
- simile
- singolo
- Taglia
- alcuni
- Speaker
- specifico
- Standard
- statistica
- step
- Stratega
- studente
- Gli studenti
- soggetto
- suggerisce
- riassumere
- SISTEMI DI TRATTAMENTO
- Task
- task
- dice
- condizioni
- Il
- tipo
- a
- Trasformare
- Trasformazione
- trasformazioni
- lezione
- Tipi di
- e una comprensione reciproca
- unico
- uso
- Valori
- vario
- modi
- Che
- quale
- volere
- lavoro
- sarebbe
- X
- anno
- Trasferimento da aeroporto a Sharm
- zefiro
- zero








