Tanggal 29 Januari adalah Hari Teka-Teki Nasional, dan sebagai perayaannya, kami telah membuat blog menyenangkan yang merinci cara menyelesaikan Sudoku menggunakan kecerdasan buatan (AI).
Pengantar
Sebelum kata-kata, yang Teka-teki Sudoku adalah hal yang populer dan masih sangat populer. Dalam beberapa tahun terakhir, penggunaan optimasi metode untuk memecahkan teka-teki telah menjadi tema yang dominan. Melihat “Memecahkan Puzzle Sudoku Menggunakan Optimasi di Arkieva".
Saat ini, penggunaan AI difokuskan pada pembelajaran mesin yang mencakup berbagai metode mulai dari regresi laso hingga pembelajaran penguatan. Penggunaan AI telah muncul kembali untuk mengatasi yang rumit penjadwalan tantangan. Salah satu metode, pencarian dengan backtracking, umum digunakan dan sangat cocok untuk Sudoku.
Blog ini akan memberikan penjelasan rinci tentang cara menggunakan metode ini untuk menyelesaikan Sudoku. Ternyata, “backtracking” dapat ditemukan di dalam mesin pengoptimalan dan pembelajaran mesin dan merupakan landasan heuristik tingkat lanjut yang digunakan Arkieva untuk penjadwalan. Algoritma ini diimplementasikan dalam “Bahasa Pemrograman Array,” sebuah bahasa pemrograman berorientasi fungsi yang menangani a kumpulan struktur array yang kaya.
Dasar-dasar Sudoku
Dari Wikipedia: Sudoku adalah teka-teki penempatan angka kombinatorial berbasis logika. Tujuannya adalah untuk mengisi grid 9×9 dengan angka-angka sehingga setiap kolom, setiap baris, dan masing-masing dari sembilan sub-grid 3×3 yang membentuk grid (juga disebut “kotak”, “blok”, “wilayah”, atau “sub-kotak”) berisi semua digit dari 1 hingga 9. Pembuat teka-teki menyediakan kisi-kisi yang telah selesai sebagian, yang biasanya memiliki solusi unik. Teka-teki yang diselesaikan selalu berbentuk kotak Latin dengan batasan tambahan pada konten masing-masing wilayah. Misalnya, bilangan bulat tunggal yang sama tidak boleh muncul dua kali dalam baris atau kolom papan permainan 9×9 yang sama atau di salah satu dari sembilan subkawasan 3×3 dari papan permainan 9×9.
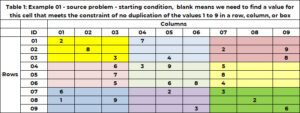
Tabel 1 memiliki contoh masalah. Ada 9 baris dan 9 kolom dengan total 81 sel. Masing-masing diperbolehkan memiliki satu dan hanya satu dari sembilan bilangan bulat antara 1 dan 9. Dalam solusi awal, sel memiliki satu nilai – yang menetapkan nilai dalam sel ini ke nilai tersebut, atau sel kosong, yang menunjukkan bahwa kita perlu untuk menemukan nilai sel ini. Sel (1,1) bernilai 2 dan sel (6,5) bernilai 6. Sel (1,2) dan sel (2,3) kosong, dan algoritma akan mencari nilai untuk sel tersebut.
Komplikasinya
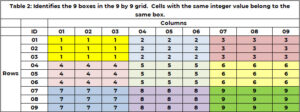
Selain menjadi milik satu dan hanya satu baris dan kolom, sebuah sel juga menjadi milik satu dan hanya 1 kotak. Terdapat 9 kotak, dan ditandai dengan warna pada Tabel 1. Tabel 2 menggunakan bilangan bulat unik antara 1 dan 9 untuk mengidentifikasi setiap kotak atau kisi. Sel dengan nilai baris (1, 2 atau 3) dan nilai kolom (1, 2 atau 3) termasuk dalam kotak 1. Kotak 6 adalah nilai baris (4, 5, 6) dan nilai kolom (7, 8 , 9). Id kotak ditentukan dengan rumus BOX_ID = {3x(floor((ROW_ID-1) /3)} + plafon (COL_ID/3). Untuk sel (5,7), 6 = 3x(floor(5-1) ))/3) + plafon (8/3)= 3×1 + 3 = 3+3.
Inti dari Teka-teki
Untuk mencari satu nilai bilangan bulat antara 1 dan 9 untuk setiap sel yang tidak diketahui sehingga bilangan bulat 1 hingga 9 digunakan satu kali dan hanya satu kali untuk setiap kolom, setiap baris, dan setiap kotak.
Mari kita lihat sel (1,3) yang kosong. Baris 1 sudah memiliki nilai 2 dan 7. Ini tidak diperbolehkan di sel ini. Kolom 3 sudah bernilai 3, 5,6, 7,9. Ini tidak diperbolehkan. Kotak 1 (kuning) berisi nilai 2, 3 dan 8. Ini tidak diperbolehkan. Nilai-nilai berikut tidak diperbolehkan (2,7); (3, 5, 6, 7, 9); (2, 3, 8). Nilai unik yang tidak diperbolehkan adalah (2, 3, 5, 6, 7, 8, 9). Satu-satunya nilai kandidat adalah (1,4).
Pendekatan solusinya adalah dengan menetapkan sementara 1 ke sel (1,3) dan kemudian mencoba menemukan nilai kandidat untuk sel lain.
Solusi Mundur: Komponen Awal
Struktur Array
Tempat awalnya adalah memutuskan struktur array untuk menyimpan sumber masalah dan mendukung pencarian. Tabel 3 memiliki struktur array ini. Kolom 1 adalah id bilangan bulat unik untuk setiap sel. Nilainya berkisar dari 1 hingga 81. Kolom 2 adalah ID baris sel. Kolom 3 adalah kolom ID sel. Kolom 4 adalah id kotak. Kolom 5 adalah nilai dalam sel. Amati sel tanpa nilai diberi nilai nol, bukan kosong atau nol. Hal ini menjadikannya “array bilangan bulat saja” – jauh lebih unggul dalam hal kinerja.

Di APL, array ini akan disimpan dalam array 2 dimensi yang bentuknya 81 kali 5. Asumsikan elemen Tabel 3 disimpan dalam variabel MAT. Contoh fungsinya adalah:
Perintah MAT[1 2 3;] mengambil 3 baris pertama MAT
1 1 1 1 2
2 1 2 1 0
3 1 3 1 0
MAT[1 2 3; 4 5] mengamankan baris 1, 2, 3 dan hanya kolom 4 dan 5
1
1
1
(MAT[;5]=0)/MAT[;1] menemukan semua sel yang membutuhkan nilai.
MASUKKAN TABEL 3
Pemeriksaan Kewarasan: Duplikat
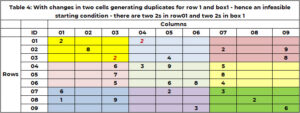
Sebelum memulai pencarian, penting untuk memeriksa kewarasan! Itu adalah solusi awal yang layak. Layak untuk Sudoku, apakah sekarang ada duplikat di baris, kolom, atau kotak mana pun. Solusi awal saat ini, misalnya 1 layak dilakukan. Tabel 4 mempunyai contoh dimana solusi awal memiliki duplikat. Baris 1 memiliki dua nilai 2. Area 1 memiliki dua nilai 2. Fungsi “SANITY_DUPE” menangani logika ini.
Pemeriksaan Sanitas: Opsi untuk Sel tanpa Nilai
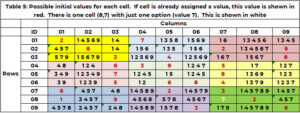
Informasi yang sangat berguna adalah semua nilai yang mungkin untuk sel tanpa nilai. Jika tidak ada kandidat, maka teka-teki ini tidak akan terpecahkan. Sebuah sel tidak dapat mengambil nilai yang sudah diklaim oleh sel tetangganya. Menggunakan Tabel 1 untuk Sel (1,3,'1' – 1 terakhir ini adalah kotak), tetangganya adalah baris 1, kolom 3, dan kotak 1. Baris 1 mempunyai nilai (2,7); kolom 3 bernilai (3,5,6,7,9); kotak 1 memiliki nilai (2,3,8). Sel (1,3.1) tidak dapat mengambil nilai berikut (2,3,5,6,7,8,9). Satu-satunya pilihan untuk sel (1,3,1) adalah (1,4). Untuk sel (4,1,2) nilai 1, 2, 3, 5, 6, 7, 9 sudah digunakan di baris 4, kolom 1, dan/atau kotak 4. Nilai kandidatnya hanya (4,8) . Pengurapan “SANITY_CAND” menangani logika ini.
Tabel 5 menunjukkan kandidat, misalnya 1 pada awal proses pencarian. Jika sel telah diberi nilai pada kondisi awal (Tabel 1), maka nilai ini diulang dan ditampilkan dengan warna merah. Jika sel yang memerlukan nilai hanya memiliki satu opsi, opsi ini ditampilkan dalam warna putih. Sel (8,7,9) memiliki nilai tunggal 7 berwarna putih. (2,5,8,4,3) diklaim oleh kolom tetangga 7. (1, 2, 9) oleh baris 8. (3,2,6) oleh kotak 9. Hanya nilai 7 yang tidak diklaim.
Pemeriksaan Sanitas: Mencari Konflik
Informasi yang mengidentifikasi semua opsi untuk sel yang memerlukan nilai (diposting pada Tabel 4), memungkinkan kita mengidentifikasi konflik sebelum memulai proses pencarian. Konflik terjadi ketika dua sel yang membutuhkan nilai hanya mempunyai satu kandidat, nilai kandidatnya sama, dan kedua sel tersebut bertetangga. Dari Tabel 4 kita mengetahui satu-satunya sel yang membutuhkan nilai dan hanya memiliki satu kandidat adalah sel (8,7,9). Contoh 1, tidak ada konflik.
Apa yang akan menjadi konflik? Jika satu-satunya nilai yang mungkin untuk sel (3,7,3) adalah 7 (bukannya 1, 6, 7), maka terjadi konflik. Sel (8,7) dan sel (3,7) bertetangga – kolom yang sama. Namun, jika satu-satunya nilai yang mungkin untuk sel (4,9,2) adalah 7 (bukannya 1, 2, 7), hal ini tidak akan menjadi konflik. Sel-sel ini bukan tetangga.
Ringkasan Pemeriksaan Kewarasan
- Jika terdapat duplikat, solusi awal tidak dapat dilakukan.
- Jika sel yang membutuhkan nilai tidak mempunyai kandidat, maka tidak ada solusi yang mungkin untuk teka-teki ini. Daftar nilai kandidat untuk setiap sel dapat digunakan untuk mengurangi ruang pencarian – baik untuk penelusuran mundur maupun pengoptimalan.
- Kemampuan untuk menemukan konflik mengidentifikasi teka-teki yang tidak mungkin – tidak memiliki solusi – tanpa proses pencarian. Selain itu, ini mengidentifikasi “sel masalah”.
Solusi Mundur: Proses Pencarian
Dengan struktur data inti dan pemeriksaan kewarasan, kami mengalihkan perhatian kami ke proses pencarian. Tema yang berulang lagi adalah menyiapkan struktur data untuk mendukung pencarian.
Melacak Pencarian
Array Pelacak melacak tugas yang dibuat
- Kol 1 adalah penghitungnya
- Kolom 2 adalah jumlah opsi yang tersedia untuk ditetapkan ke sel ini
- 1 berarti 1 pilihan tersedia, 2 berarti dua pilihan, dst.
- 0 berarti – tidak ada opsi yang tersedia atau menyetel ulang ke 0 (tidak ada nilai yang ditetapkan) dan menelusuri kembali
- Kolom 3 adalah sel yang diberi nomor indeks nilai (1 hingga 81)
- Kolom 4 adalah nilai yang ditetapkan ke sel dalam riwayat trek
- Nilai 9999 berarti sel ini berada saat jalan buntu ditemukan
- Nilai bilangan bulat antara 1 dan 9 inklusif, adalah nilai yang ditetapkan ke sel ini pada saat ini dalam proses pencarian.
- Nilai 0 berarti sel ini memerlukan tugas
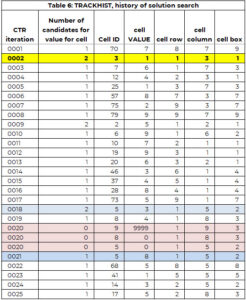
Array pelacak digunakan untuk mendukung proses pencarian. Array TRACKHIST memiliki struktur yang sama dengan pelacak tetapi menyimpan riwayat seluruh proses pencarian. Tabel 6 mempunyai bagian TRACKHIST misalnya 1. Dijelaskan lebih rinci di bagian selanjutnya.
Selain itu, larik PAV (vektor dari vektor), melacak Nilai yang Ditugaskan Sebelumnya ke sel ini. Hal ini memastikan kita tidak meninjau kembali solusi yang gagal – serupa dengan apa yang dilakukan di TABU.
Ada proses log opsional tempat proses pencarian menuliskan setiap langkah.
Memulai Pencarian
Setelah pembukuan dan pemeriksaan kewarasan selesai, sekarang kita dapat memulai proses pencarian. Langkah-langkahnya adalah:
- Apakah masih ada sel tersisa yang memerlukan nilai? – jika tidak, maka kita selesai.
- Untuk setiap sel yang memerlukan nilai, temukan semua opsi kandidat untuk setiap sel. Tabel 4 memiliki nilai-nilai ini pada awal proses solusi. Pada setiap iterasi, nilai ini diperbarui untuk mengakomodasi nilai yang ditetapkan ke sel.
- Evaluasi opsi dalam urutan ini.
- Jika sel memiliki opsi NOL, lakukan penelusuran mundur
- Temukan semua sel dengan satu opsi, pilih salah satu sel ini, buat tugas ini,
- dan perbarui tabel pelacakan, solusi saat ini, dan PAV.
- Jika semua sel memiliki lebih dari satu opsi, pilih satu sel dan satu nilai, lalu perbarui
- dan perbarui tabel pelacakan, solusi saat ini, dan PAV
Kita akan menggunakan Tabel 6 yang merupakan bagian dari sejarah proses solusi (disebut TRACKHIST) untuk mengilustrasikan setiap langkah.
Pada iterasi pertama (RKT=1), sel 70 (baris 8, kolom 7, kotak 9) dipilih untuk diberi nilai. Hanya ada kandidat (7), dan nilai ini ditetapkan ke sel 70. Selain itu, nilai 7 ditambahkan ke vektor nilai yang ditetapkan sebelumnya (PAV) untuk sel 70.
Pada iterasi kedua, sel 30 diberi nilai 1. Sel ini memiliki dua nilai kandidat. Nilai kandidat terkecil ditetapkan ke sel (hanya aturan arbitrer agar logikanya mudah diikuti).
Proses mengidentifikasi sel yang membutuhkan nilai dan memberikan nilai berfungsi dengan baik hingga iterasi (CTR) 20. Sel 9 membutuhkan nilai, tetapi jumlah kandidatnya NOL. Ada dua pilihan:
- Tidak ada solusi untuk teka-teki ini.
- Kami membatalkan (mundur) beberapa tugas dan mengambil jalur lain.
Kami mencari tugas sel yang paling dekat dengan ini, di mana terdapat lebih dari satu opsi. Dalam contoh ini, hal ini terjadi pada iterasi 18, di mana sel 5 diberi nilai 3, namun ada dua kandidat nilai untuk sel 5 – nilai 3 dan 8.
Di antara sel 5 (RKT = 18) dan sel 9 (RKT = 20), sel 8 diberi nilai 4 (RKT=19). Kami mengembalikan sel 8 dan 5 ke daftar "membutuhkan nilai". Hal ini ditangkap dalam entri CTR=20 kedua dan ketiga, yang nilainya ditetapkan ke 0. Nilai 3 disimpan dalam vektor PAV untuk sel 5. Artinya, mesin pencari tidak dapat menetapkan nilai 3 ke sel 5.
Mesin pencari mulai lagi untuk mengidentifikasi nilai untuk sel 5 (dengan 3 tidak lagi menjadi pilihan) dan memberikan nilai 8 ke sel 5 (RKT=21). Ini berlanjut sampai semua sel memiliki nilai atau ada sel yang tidak memiliki opsi dan tidak ada jalur mundur. Solusinya diposting pada Tabel 7.
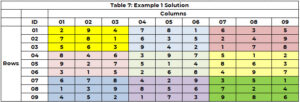
Amati, jika terdapat lebih dari satu kandidat untuk sebuah sel, ini adalah peluang untuk pemrosesan paralel.
Perbandingan dengan Solusi Optimasi MILP
Pada tingkat permukaan, representasi teka-teki Sudoku sangat berbeda. Pendekatan AI menggunakan bilangan bulat dan dengan ukuran apa pun merupakan representasi yang lebih ketat dan intuitif. Selain itu, pemeriksa kewarasan memberikan informasi berguna untuk membuat formulasi yang lebih kuat. Representasi MILP tidak ada habisnya binari (0/1). Namun, biner adalah representasi yang kuat mengingat kekuatan pemecah MILP modern.
Namun, secara internal, pemecah MILP tidak menyimpan biner tetapi menggunakan metode array renggang untuk menghilangkan penyimpanan semua angka nol. Selain itu, algoritma untuk memecahkan biner baru muncul pada tahun 1980an dan 1990an. Makalah tahun 1983 oleh Crowder, Johnson, dan Padberg melaporkan salah satu solusi praktis pertama optimasi dengan biner. Mereka mencatat pentingnya pra-pemrosesan yang cerdas dan metode bercabang dan terikat sebagai hal yang penting untuk solusi yang sukses.
Ledakan baru-baru ini dalam penggunaan pemrograman kendala dan perangkat lunak seperti pemecah lokal telah memperjelas pentingnya penggunaan metode AI dengan metode optimasi asli seperti pemrograman linier dan kuadrat terkecil.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://blog.arkieva.com/an-artificial-intelligence-based-solution-to-sudoku/?utm_source=rss&utm_medium=rss&utm_campaign=an-artificial-intelligence-based-solution-to-sudoku
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 1
- 20
- 29
- 30
- 31
- 600
- 7
- 70
- 8
- 9
- a
- kemampuan
- menampung
- menambahkan
- tambahan
- Tambahan
- Selain itu
- maju
- lagi
- AI
- algoritma
- algoritma
- Semua
- diizinkan
- sudah
- juga
- selalu
- Amazon
- an
- dan
- Lain
- Apa pun
- muncul
- pendekatan
- sewenang-wenang
- ADALAH
- DAERAH
- susunan
- buatan
- kecerdasan buatan
- Kecerdasan buatan (AI)
- AS
- ditugaskan
- menganggap
- At
- perhatian
- tersedia
- kembali
- BE
- menjadi
- sebelum
- termasuk
- milik
- antara
- kosong
- Blog
- papan
- kedua
- terikat
- Kotak
- kotak
- Cabang
- tapi
- by
- bernama
- CAN
- calon
- calon
- tidak bisa
- ditangkap
- plafon
- Perayaan
- sel
- Sel
- tantangan
- kesempatan
- memeriksa
- memeriksa
- diklaim
- jelas
- warna
- Kolom
- Kolom
- umum
- Lengkap
- kompleks
- Kondisi
- konflik
- Konflik
- mengandung
- isi
- terus
- Core
- landasan
- dibuat
- kritis
- terbaru
- data
- hari
- mati
- memutuskan
- deskripsi
- rinci
- terperinci
- rincian
- ditentukan
- berbeda
- digit
- do
- tidak
- dominan
- dilakukan
- Dont
- secara dramatis
- duplikat
- setiap
- Mudah
- antara
- elemen
- menghapuskan
- muncul
- memungkinkan
- meliputi
- akhir
- Tak berujung
- Mesin
- Mesin
- Memastikan
- Seluruh
- dll
- contoh
- menjelaskan
- ledakan
- Gagal
- jauh
- layak
- mengisi
- Menemukan
- menemukan
- akhir
- Pertama
- tetap
- terfokus
- mengikuti
- berikut
- Untuk
- rumus
- perumusan
- ditemukan
- dari
- kesenangan
- fungsi
- fungsi
- mendapatkan
- diberikan
- kisi
- memiliki
- Menangani
- Memiliki
- Hati
- bermanfaat
- sejarah
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTML
- HTTPS
- ID
- mengidentifikasi
- mengenali
- mengidentifikasi
- if
- menjelaskan
- diimplementasikan
- pentingnya
- in
- Inklusif
- indeks
- menunjukkan
- Menunjukkan
- sendiri-sendiri
- informasi
- menginformasikan
- dalam
- sebagai gantinya
- Lembaga
- Intelijen
- internal
- intuitif
- IT
- perulangan
- NYA
- Johnson
- jpg
- hanya
- Menjaga
- terus
- Tahu
- bahasa
- Terakhir
- kemudian
- Latin
- pengetahuan
- paling sedikit
- meninggalkan
- Tingkat
- linear
- Daftar
- mencatat
- logika
- lagi
- melihat
- tampak
- mencari
- mesin
- Mesin belajar
- terbuat
- membuat
- max-width
- Mungkin..
- cara
- mengukur
- metode
- metode
- modern
- lebih
- nasional
- Perlu
- kebutuhan
- tetangga
- sembilan
- tidak
- mencatat
- sekarang
- jumlah
- tujuan
- mengamati
- terjadi
- of
- on
- sekali
- ONE
- hanya
- optimasi
- pilihan
- Opsi
- or
- urutan
- asli
- kami
- di luar
- kertas
- Paralel
- bagian
- path
- sempurna
- prestasi
- bagian
- Tempat
- plato
- Kecerdasan Data Plato
- Data Plato
- bermain
- Titik
- Populer
- mungkin
- diposting
- kuat
- Praktis
- sebelumnya
- Masalah
- proses
- pengolahan
- Pemrograman
- memberikan
- menyediakan
- menempatkan
- teka-teki
- Puzzle
- Kemarahan
- jarak
- baru
- berulang
- Merah
- menurunkan
- daerah
- regresi
- penguatan pembelajaran
- ulang
- laporan
- perwakilan
- BARIS
- Aturan
- sama
- penjadwalan
- Pencarian
- mesin pencari
- Kedua
- Bagian
- Mengamankan
- melihat
- memilih
- terpilih
- set
- Bentuknya
- ditunjukkan
- Pertunjukkan
- mirip
- tunggal
- So
- Perangkat lunak
- larutan
- Solusi
- MEMECAHKAN
- beberapa
- sumber
- Space
- kotak
- kotak
- awal
- Mulai
- dimulai
- Langkah
- Tangga
- Masih
- menyimpan
- tersimpan
- kekuatan
- lebih kuat
- struktur
- struktur
- sukses
- seperti itu
- unggul
- mendukung
- Permukaan
- tabel
- memecahkan
- Mengambil
- dari
- bahwa
- Grafik
- Sumber
- tema
- kemudian
- Sana.
- Ini
- mereka
- Ketiga
- ini
- lebih ketat
- kali
- untuk
- Total
- jalur
- Pelacakan
- mencoba
- MENGHIDUPKAN
- ternyata
- Dua kali
- dua
- mengetik
- khas
- unik
- tidak dikenal
- sampai
- Memperbarui
- diperbarui
- us
- menggunakan
- bekas
- kegunaan
- menggunakan
- nilai
- Nilai - Nilai
- variabel
- sangat
- adalah
- we
- adalah
- Apa
- Apa itu
- ketika
- yang
- putih
- lebar
- Rentang luas
- Wikipedia
- akan
- dengan
- tanpa
- bekerja
- akan
- tahun
- kuning
- zephyrnet.dll
- nol