BukaAI Whisper adalah model pengenalan suara otomatis (ASR) tingkat lanjut dengan lisensi MIT. Teknologi ASR berguna dalam layanan transkripsi, asisten suara, dan meningkatkan aksesibilitas bagi individu dengan gangguan pendengaran. Model canggih ini dilatih pada kumpulan data multibahasa dan data yang diawasi multitugas yang luas dan beragam yang dikumpulkan dari web. Akurasi dan kemampuan beradaptasinya yang tinggi menjadikannya aset berharga untuk beragam tugas terkait suara.
Dalam lanskap pembelajaran mesin dan kecerdasan buatan yang terus berkembang, Amazon SageMaker menyediakan ekosistem yang komprehensif. SageMaker memberdayakan ilmuwan data, pengembang, dan organisasi untuk mengembangkan, melatih, menerapkan, dan mengelola model pembelajaran mesin dalam skala besar. Menawarkan berbagai alat dan kemampuan, ini menyederhanakan seluruh alur kerja pembelajaran mesin, mulai dari pra-pemrosesan data dan pengembangan model hingga penerapan dan pemantauan yang mudah. Antarmuka SageMaker yang ramah pengguna menjadikannya platform penting untuk membuka potensi penuh AI, menjadikannya sebagai solusi terobosan dalam bidang kecerdasan buatan.
Dalam postingan ini, kami memulai eksplorasi kemampuan SageMaker, khususnya berfokus pada hosting model Whisper. Kami akan mendalami dua metode untuk melakukan hal ini: satu menggunakan model Whisper PyTorch dan yang lainnya menggunakan implementasi Hugging Face dari model Whisper. Selain itu, kami akan melakukan pemeriksaan mendalam terhadap opsi inferensi SageMaker, membandingkannya di seluruh parameter seperti kecepatan, biaya, ukuran muatan, dan skalabilitas. Analisis ini memberdayakan pengguna untuk membuat keputusan yang tepat ketika mengintegrasikan model Whisper ke dalam kasus penggunaan dan sistem spesifik mereka.
Ikhtisar solusi
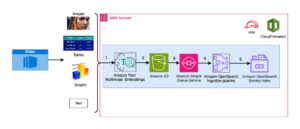
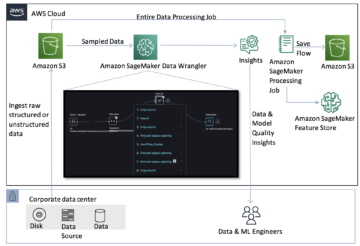
Diagram berikut menunjukkan komponen utama dari solusi ini.
- Untuk menghosting model di Amazon SageMaker, langkah pertama adalah menyimpan artefak model. Artefak ini mengacu pada komponen penting model pembelajaran mesin yang diperlukan untuk berbagai aplikasi, termasuk penerapan dan pelatihan ulang. Mereka dapat mencakup parameter model, file konfigurasi, komponen pra-pemrosesan, serta metadata, seperti detail versi, kepengarangan, dan catatan apa pun yang terkait dengan kinerjanya. Penting untuk diperhatikan bahwa model Whisper untuk implementasi PyTorch dan Hugging Face terdiri dari artefak model yang berbeda.
- Selanjutnya, kami membuat skrip inferensi khusus. Dalam skrip ini, kami menentukan bagaimana model harus dimuat dan menentukan proses inferensi. Di sinilah kita juga dapat memasukkan parameter khusus sesuai kebutuhan. Selain itu, Anda dapat membuat daftar paket Python yang diperlukan di a
requirements.txtmengajukan. Selama penerapan model, paket Python ini secara otomatis diinstal pada tahap inisialisasi. - Kemudian kami memilih wadah pembelajaran mendalam (DLC) PyTorch atau Hugging Face yang disediakan dan dikelola oleh AWS. Kontainer ini adalah image Docker yang dibuat sebelumnya dengan kerangka pembelajaran mendalam dan paket Python lain yang diperlukan. Untuk informasi lebih lanjut, Anda dapat memeriksa ini link.
- Dengan artefak model, skrip inferensi khusus, dan DLC pilihan, kami akan membuat model Amazon SageMaker untuk PyTorch dan Hugging Face.
- Terakhir, model dapat diterapkan di SageMaker dan digunakan dengan opsi berikut: titik akhir inferensi real-time, tugas transformasi batch, dan titik akhir inferensi asinkron. Kami akan mendalami opsi ini lebih detail nanti di postingan ini.
Contoh buku catatan dan kode untuk solusi ini tersedia di sini Repositori GitHub.
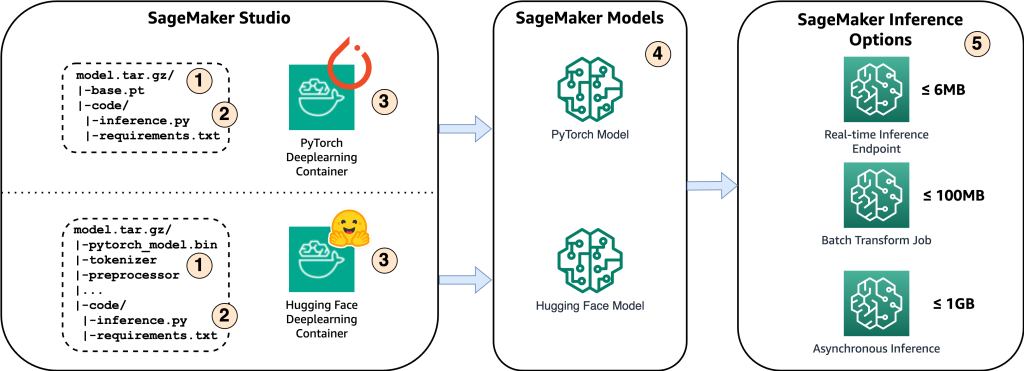
Gambar 1. Ikhtisar Komponen Solusi Utama
Walkthrough
Menghosting Model Bisikan di Amazon SageMaker
Di bagian ini, kami akan menjelaskan langkah-langkah untuk menghosting model Whisper di Amazon SageMaker, masing-masing menggunakan PyTorch dan Hugging Face Frameworks. Untuk bereksperimen dengan solusi ini, Anda memerlukan akun AWS dan akses ke layanan Amazon SageMaker.
Kerangka kerja PyTorch
- Simpan artefak model
Opsi pertama untuk menghosting model adalah menggunakan Paket Python resmi bisikan, yang dapat diinstal menggunakan pip install openai-whisper. Paket ini menyediakan model PyTorch. Saat menyimpan artefak model di repositori lokal, langkah pertama adalah menyimpan parameter model yang dapat dipelajari, seperti bobot model dan bias setiap lapisan di jaringan saraf, sebagai file 'pt'. Anda dapat memilih dari berbagai ukuran model, termasuk 'kecil', 'dasar', 'kecil', 'sedang', dan 'besar'. Ukuran model yang lebih besar menawarkan performa akurasi yang lebih tinggi, namun mengorbankan latensi inferensi yang lebih lama. Selain itu, Anda perlu menyimpan kamus status model dan kamus dimensi, yang berisi kamus Python yang memetakan setiap lapisan atau parameter model PyTorch ke parameter terkait yang dapat dipelajari, bersama dengan metadata dan konfigurasi khusus lainnya. Kode di bawah ini menunjukkan cara menyimpan artefak Whisper PyTorch.
- Pilih DLC
Langkah selanjutnya adalah memilih DLC yang sudah dibuat sebelumnya link. Berhati-hatilah saat memilih gambar yang benar dengan mempertimbangkan pengaturan berikut: kerangka kerja (PyTorch), versi kerangka kerja, tugas (inferensi), versi Python, dan perangkat keras (yaitu GPU). Disarankan untuk menggunakan versi terbaru untuk kerangka kerja dan Python bila memungkinkan, karena ini menghasilkan kinerja yang lebih baik dan mengatasi masalah umum dan bug dari rilis sebelumnya.
- Buat model Amazon SageMaker
Selanjutnya, kami memanfaatkan SDK Python SageMaker untuk membuat model PyTorch. Penting untuk diingat untuk menambahkan variabel lingkungan saat membuat model PyTorch. Secara default, TorchServe hanya dapat memproses ukuran file hingga 6 MB, apa pun jenis inferensi yang digunakan.
Tabel berikut memperlihatkan pengaturan untuk versi PyTorch yang berbeda:
| Kerangka | Variabel lingkungan |
| PyTorch 1.8 (berdasarkan TorchServe) | 'TS_MAX_REQUEST_SIZE':'100000000'' TS_MAX_RESPONSE_SIZE':'100000000'' TS_DEFAULT_RESPONSE_TIMEOUT':'1000' |
| PyTorch 1.4 (berdasarkan MMS) | 'MMS_MAX_REQUEST_SIZE':'1000000000'' MMS_MAX_RESPONSE_SIZE':'1000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT':'900' |
- Tentukan metode pemuatan model di inference.py
Dalam adat inference.py scriptnya, kita cek dulu ketersediaan GPU berkemampuan CUDA. Jika GPU tersebut tersedia, maka kami menetapkannya 'cuda' perangkat ke DEVICE variabel; jika tidak, kami menetapkan 'cpu' perangkat. Langkah ini memastikan bahwa model ditempatkan pada perangkat keras yang tersedia untuk komputasi yang efisien. Kami memuat model PyTorch menggunakan paket Whisper Python.
Kerangka Memeluk Wajah
- Simpan artefak model
Opsi kedua adalah menggunakan Bisikan Wajah Memeluk penerapan. Model dapat dimuat menggunakan AutoModelForSpeechSeq2Seq kelas transformator. Parameter yang dapat dipelajari disimpan dalam file biner (bin) menggunakan save_pretrained metode. Tokenizer dan preprocessor juga perlu disimpan secara terpisah untuk memastikan model Hugging Face berfungsi dengan baik. Alternatifnya, Anda dapat menerapkan model di Amazon SageMaker langsung dari Hugging Face Hub dengan mengatur dua variabel lingkungan: HF_MODEL_ID dan HF_TASK. Untuk informasi lebih lanjut, silakan lihat ini halaman web.
- Pilih DLC
Mirip dengan kerangka PyTorch, Anda dapat memilih DLC Hugging Face yang sudah dibuat sebelumnya link. Pastikan untuk memilih DLC yang mendukung transformator Hugging Face terbaru dan menyertakan dukungan GPU.
- Buat model Amazon SageMaker
Demikian pula, kami memanfaatkan SDK Python SageMaker untuk membuat model Wajah Memeluk. Model Hugging Face Whisper memiliki batasan default yaitu hanya dapat memproses segmen audio hingga 30 detik. Untuk mengatasi keterbatasan ini, Anda dapat menyertakan chunk_length_s parameter dalam variabel lingkungan saat membuat model Hugging Face, dan kemudian meneruskan parameter ini ke dalam skrip inferensi khusus saat memuat model. Terakhir, atur variabel lingkungan untuk meningkatkan ukuran muatan dan waktu tunggu respons untuk kontainer Hugging Face.
| Kerangka | Variabel lingkungan |
|
Wadah Inferensi HuggingFace (berdasarkan MMS) |
'MMS_MAX_REQUEST_SIZE':'2000000000'' MMS_MAX_RESPONSE_SIZE':'2000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT':'900' |
- Tentukan metode pemuatan model di inference.py
Saat membuat skrip inferensi khusus untuk model Hugging Face, kami menggunakan pipeline, yang memungkinkan kami meneruskannya chunk_length_s sebagai parameter. Parameter ini memungkinkan model memproses file audio panjang secara efisien selama inferensi.
Menjelajahi berbagai opsi inferensi di Amazon SageMaker
Langkah-langkah untuk memilih opsi inferensi sama untuk model PyTorch dan Hugging Face, jadi kami tidak akan membedakannya di bawah. Namun, perlu dicatat bahwa, pada saat penulisan postingan ini, inferensi tanpa server opsi dari SageMaker tidak mendukung GPU, dan oleh karena itu, kami mengecualikan opsi ini untuk kasus penggunaan ini.
Kita dapat menerapkan model ini sebagai titik akhir real-time dan memberikan respons dalam hitungan milidetik. Namun, penting untuk diingat bahwa opsi ini terbatas pada pemrosesan input di bawah 6 MB. Kami mendefinisikan serializer sebagai serializer audio, yang bertanggung jawab untuk mengubah data input ke dalam format yang sesuai untuk model yang diterapkan. Kami menggunakan instance GPU untuk inferensi, memungkinkan pemrosesan file audio yang dipercepat. Input inferensi adalah file audio yang berasal dari repositori lokal.
Opsi inferensi kedua adalah tugas transformasi batch, yang mampu memproses muatan input hingga 100 MB. Namun, metode ini mungkin memerlukan latensi beberapa menit. Setiap instans hanya dapat menangani satu permintaan batch dalam satu waktu, dan inisiasi serta penghentian instans juga memerlukan beberapa menit. Hasil inferensi disimpan di Amazon Simple Storage Service (Amazon S3) bucket setelah menyelesaikan tugas transformasi batch.
Saat mengonfigurasi trafo batch, pastikan untuk menyalakannya max_payload = 100 untuk menangani muatan yang lebih besar secara efektif. Input inferensi harus berupa jalur Amazon S3 ke file audio atau folder Amazon S3 Bucket yang berisi daftar file audio, masing-masing berukuran lebih kecil dari 100 MB.
Batch Transform mempartisi objek Amazon S3 dalam input berdasarkan kunci dan memetakan objek Amazon S3 ke instans. Misalnya, ketika Anda memiliki beberapa file audio, satu instance mungkin memproses input1.wav, dan instance lainnya mungkin memproses file bernama input2.wav untuk meningkatkan skalabilitas. Transformasi Batch memungkinkan Anda untuk mengonfigurasi max_concurrent_transforms untuk meningkatkan jumlah permintaan HTTP yang dibuat ke setiap kontainer transformator. Namun, penting untuk dicatat bahwa nilai (max_concurrent_transforms* max_payload) tidak boleh melebihi 100 MB.
Terakhir, Inferensi Asinkron Amazon SageMaker ideal untuk memproses beberapa permintaan secara bersamaan, menawarkan latensi sedang dan mendukung muatan input hingga 1 GB. Opsi ini memberikan skalabilitas yang sangat baik, memungkinkan konfigurasi grup penskalaan otomatis untuk titik akhir. Ketika lonjakan permintaan terjadi, secara otomatis skalanya ditingkatkan untuk menangani lalu lintas, dan setelah semua permintaan diproses, titik akhir skalanya diturunkan ke 0 untuk menghemat biaya.
Menggunakan inferensi asinkron, hasilnya secara otomatis disimpan ke bucket Amazon S3. Dalam AsyncInferenceConfig, Anda dapat mengonfigurasi pemberitahuan untuk penyelesaian yang berhasil atau gagal. Jalur input menunjuk ke lokasi file audio Amazon S3. Untuk detail tambahan, silakan lihat kode di GitHub.
Opsional: Seperti disebutkan sebelumnya, kami memiliki opsi untuk mengonfigurasi grup penskalaan otomatis untuk titik akhir inferensi asinkron, yang memungkinkannya menangani lonjakan permintaan inferensi secara tiba-tiba. Contoh kode disediakan di sini Repositori GitHub. Dalam diagram berikut, Anda dapat mengamati diagram garis yang menampilkan dua metrik amazoncloudwatch: ApproximateBacklogSize dan ApproximateBacklogSizePerInstance. Awalnya, ketika 1000 permintaan dipicu, hanya satu instance yang tersedia untuk menangani inferensi. Selama tiga menit, ukuran backlog secara konsisten melebihi tiga (harap diperhatikan bahwa angka-angka ini dapat dikonfigurasi), dan grup penskalaan otomatis merespons dengan menjalankan instance tambahan untuk menghapus backlog secara efisien. Hal ini berdampak pada penurunan yang cukup signifikan ApproximateBacklogSizePerInstance, memungkinkan permintaan backlog diproses lebih cepat dibandingkan tahap awal.

Gambar 2. Bagan garis yang mengilustrasikan perubahan temporal dalam metrik Amazon CloudWatch
Analisis komparatif untuk opsi inferensi
Perbandingan untuk opsi inferensi yang berbeda didasarkan pada kasus penggunaan pemrosesan audio yang umum. Inferensi waktu nyata menawarkan kecepatan inferensi tercepat tetapi membatasi ukuran payload hingga 6 MB. Jenis inferensi ini cocok untuk sistem perintah audio, di mana pengguna mengontrol atau berinteraksi dengan perangkat atau perangkat lunak menggunakan perintah suara atau instruksi lisan. Perintah suara biasanya berukuran kecil, dan latensi inferensi rendah sangat penting untuk memastikan bahwa perintah yang ditranskripsikan dapat segera memicu tindakan selanjutnya. Transformasi Batch ideal untuk tugas offline terjadwal, ketika ukuran setiap file audio di bawah 100 MB, dan tidak ada persyaratan khusus untuk waktu respons inferensi yang cepat. Inferensi asinkron memungkinkan unggahan hingga 1 GB dan menawarkan latensi inferensi sedang. Jenis inferensi ini sangat cocok untuk menyalin film, serial TV, dan rekaman konferensi yang memerlukan pemrosesan file audio yang lebih besar.
Opsi inferensi real-time dan asinkron memberikan kemampuan penskalaan otomatis, memungkinkan instans titik akhir meningkatkan atau menurunkan skala secara otomatis berdasarkan volume permintaan. Jika tidak ada permintaan, penskalaan otomatis akan menghapus instance yang tidak diperlukan, sehingga membantu Anda menghindari biaya yang terkait dengan instance yang tersedia dan tidak digunakan secara aktif. Namun, untuk inferensi real-time, setidaknya satu instance persisten harus dipertahankan, sehingga dapat menyebabkan biaya lebih tinggi jika titik akhir beroperasi terus-menerus. Sebaliknya, inferensi asinkron memungkinkan volume instans dikurangi menjadi 0 saat tidak digunakan. Saat mengonfigurasi tugas transformasi batch, dimungkinkan untuk menggunakan beberapa instans untuk memproses tugas dan menyesuaikan max_concurrent_transforms untuk mengaktifkan satu instans menangani banyak permintaan. Oleh karena itu, ketiga opsi inferensi menawarkan skalabilitas yang luar biasa.
Membersihkan
Setelah Anda selesai menggunakan solusi, pastikan untuk menghapus titik akhir SageMaker untuk mencegah timbulnya biaya tambahan. Anda dapat menggunakan kode yang disediakan untuk menghapus masing-masing titik akhir inferensi real-time dan asinkron.
Kesimpulan
Dalam postingan ini, kami menunjukkan kepada Anda bagaimana penerapan model pembelajaran mesin untuk pemrosesan audio menjadi semakin penting di berbagai industri. Dengan mengambil model Whisper sebagai contoh, kami mendemonstrasikan cara menghosting model ASR sumber terbuka di Amazon SageMaker menggunakan pendekatan PyTorch atau Hugging Face. Eksplorasi ini mencakup berbagai opsi inferensi di Amazon SageMaker, menawarkan wawasan tentang penanganan data audio secara efisien, membuat prediksi, dan mengelola biaya secara efektif. Postingan ini bertujuan untuk memberikan pengetahuan bagi para peneliti, pengembang, dan ilmuwan data yang tertarik memanfaatkan model Whisper untuk tugas terkait audio dan membuat keputusan yang tepat mengenai strategi inferensi.
Untuk informasi lebih detail tentang penerapan model di SageMaker, lihat ini Panduan pengembang. Selain itu, model Whisper dapat diterapkan menggunakan SageMaker JumpStart. Untuk detail tambahan, silakan periksa Model bisikan untuk pengenalan ucapan otomatis kini tersedia di Amazon SageMaker JumpStart pos.
Jangan ragu untuk memeriksa buku catatan dan kode untuk proyek ini GitHub dan bagikan komentar Anda kepada kami.
tentang Penulis
 Ying Hou, PhD, adalah Arsitek Prototipe Pembelajaran Mesin di AWS. Bidang minat utamanya mencakup Pembelajaran Mendalam, dengan fokus pada GenAI, Computer Vision, NLP, dan prediksi data deret waktu. Di waktu luangnya, dia menikmati menghabiskan momen berkualitas bersama keluarganya, menyelami novel, dan hiking di taman nasional Inggris.
Ying Hou, PhD, adalah Arsitek Prototipe Pembelajaran Mesin di AWS. Bidang minat utamanya mencakup Pembelajaran Mendalam, dengan fokus pada GenAI, Computer Vision, NLP, dan prediksi data deret waktu. Di waktu luangnya, dia menikmati menghabiskan momen berkualitas bersama keluarganya, menyelami novel, dan hiking di taman nasional Inggris.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/host-the-whisper-model-on-amazon-sagemaker-exploring-inference-options/
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 1
- 10
- 100
- 12
- 14
- 16
- 19
- 30
- 32
- 8
- a
- dipercepat
- mengakses
- aksesibilitas
- Akun
- ketepatan
- di seluruh
- tindakan
- aktif
- menambahkan
- Tambahan
- Selain itu
- alamat
- menyesuaikan
- maju
- AI
- bertujuan
- Semua
- Membiarkan
- memungkinkan
- sepanjang
- juga
- Amazon
- Amazon SageMaker
- Amazon Web Services
- an
- analisis
- dan
- Lain
- Apa pun
- aplikasi
- pendekatan
- ADALAH
- daerah
- susunan
- buatan
- kecerdasan buatan
- AS
- aset
- asisten
- terkait
- At
- audio
- Kepengarangan
- secara otomatis
- secara otomatis
- tersedianya
- tersedia
- menghindari
- AWS
- mendasarkan
- berdasarkan
- BE
- menjadi
- di bawah
- Lebih baik
- antara
- bias
- BIN
- kedua
- bug
- tapi
- by
- CAN
- kemampuan
- mampu
- hati-hati
- kasus
- Perubahan
- Grafik
- memeriksa
- Pilih
- memilih
- kelas
- jelas
- kode
- bagaimana
- komentar
- Umum
- pembandingan
- perbandingan
- Lengkap
- penyelesaian
- komponen
- luas
- komputasi
- komputer
- Visi Komputer
- Mengadakan
- konferensi
- konfigurasi
- dikonfigurasi
- mengkonfigurasi
- mengingat
- secara konsisten
- mengandung
- Wadah
- Wadah
- terus menerus
- kontras
- kontrol
- mengkonversi
- benar
- Sesuai
- Biaya
- Biaya
- bisa
- CPU
- membuat
- membuat
- sangat penting
- adat
- data
- keputusan
- mengurangi
- mendalam
- belajar mendalam
- Default
- menetapkan
- menunjukkan
- menyebarkan
- dikerahkan
- penggelaran
- penyebaran
- rinci
- terperinci
- rincian
- mengembangkan
- pengembang
- Pengembangan
- alat
- Devices
- berbeda
- membedakan
- Dimensi
- langsung
- menampilkan
- menyelam
- beberapa
- Buruh pelabuhan
- Tidak
- melakukan
- turun
- selama
- e
- setiap
- Terdahulu
- ekosistem
- efektif
- efisien
- efisien
- tanpa usaha
- antara
- lain
- memulai
- memberdayakan
- aktif
- memungkinkan
- memungkinkan
- mencakup
- Titik akhir
- endpoint
- mempertinggi
- meningkatkan
- memastikan
- Memastikan
- Seluruh
- Lingkungan Hidup
- penting
- membangun
- Eter (ETH)
- pemeriksaan
- contoh
- melebihi
- melampaui
- unggul
- eksperimen
- Menjelaskan
- eksplorasi
- Menjelajahi
- Menghadapi
- Gagal
- palsu
- keluarga
- FAST
- lebih cepat
- tercepat
- beberapa
- File
- File
- menemukan
- Pertama
- Fokus
- berfokus
- berikut
- Untuk
- format
- Kerangka
- kerangka
- Gratis
- dari
- penuh
- GPU
- GPU
- besar
- Kelompok
- menangani
- Penanganan
- Perangkat keras
- Memiliki
- pendengaran
- membantu
- dia
- High
- lebih tinggi
- mendaki
- tuan rumah
- tuan
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTML
- http
- HTTPS
- Pusat
- MemelukWajah
- i
- ideal
- if
- menggambarkan
- gambar
- gambar
- implementasi
- implementasi
- mengimpor
- penting
- in
- secara mendalam
- memasukkan
- termasuk
- Termasuk
- menggabungkan
- Meningkatkan
- makin
- sendiri-sendiri
- individu
- industri
- informasi
- informasi
- mulanya
- mulanya
- inisiasi
- memasukkan
- input
- wawasan
- install
- contoh
- contoh
- instruksi
- Mengintegrasikan
- Intelijen
- berinteraksi
- bunga
- tertarik
- Antarmuka
- ke
- masalah
- IT
- NYA
- Pekerjaan
- Jobs
- jpg
- kunci
- pengetahuan
- dikenal
- pemandangan
- lebih besar
- akhirnya
- Latensi
- kemudian
- Terbaru
- lapisan
- memimpin
- pengetahuan
- paling sedikit
- leveraging
- Lisensi
- pembatasan
- Terbatas
- baris
- Daftar
- memuat
- pemuatan
- lokal
- tempat
- Panjang
- lagi
- Rendah
- mesin
- Mesin belajar
- terbuat
- Utama
- membuat
- MEMBUAT
- Membuat
- mengelola
- pelaksana
- Peta
- Mungkin..
- tersebut
- Metadata
- metode
- metode
- Metrik
- mungkin
- milidetik
- menit
- MIT
- ML
- model
- model
- moderat
- Waktu
- pemantauan
- lebih
- bioskop
- banyak
- beberapa
- harus
- Bernama
- nasional
- Taman Nasional
- perlu
- Perlu
- dibutuhkan
- jaringan
- saraf
- saraf jaringan
- berikutnya
- nLP
- tidak
- mencatat
- buku catatan
- Catatan
- pemberitahuan
- pemberitahuan
- mencatat
- sekarang
- jumlah
- nomor
- obyek
- objek
- mengamati
- of
- menawarkan
- menawarkan
- Penawaran
- resmi
- Pengunjung
- on
- sekali
- ONE
- hanya
- open source
- beroperasi
- pilihan
- Opsi
- or
- urutan
- organisasi
- OS
- Lainnya
- jika tidak
- di luar
- ikhtisar
- paket
- paket
- parameter
- parameter
- taman
- lulus
- path
- melakukan
- prestasi
- tahap
- pipa saluran
- sangat penting
- ditempatkan
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- silahkan
- poin
- mungkin
- Pos
- potensi
- ramalan
- Prediksi
- mencegah
- sebelumnya
- primer
- proses
- diproses
- pengolahan
- Prosesor
- proyek
- tepat
- prototyping
- memberikan
- disediakan
- menyediakan
- menyediakan
- Ular sanca
- pytorch
- kualitas
- jarak
- real-time
- dunia
- pengakuan
- direkomendasikan
- tercatat
- mengurangi
- lihat
- Bagaimanapun juga
- terkait
- Pers
- ingat
- menghapus
- menghapus
- gudang
- permintaan
- permintaan
- membutuhkan
- wajib
- kebutuhan
- peneliti
- masing-masing
- tanggapan
- tanggapan
- tanggung jawab
- mengakibatkan
- mengakibatkan
- Hasil
- dipertahankan
- pelatihan ulang
- kembali
- pembuat bijak
- sama
- Save
- disimpan
- penghematan
- Skalabilitas
- Skala
- sisik
- dijadwalkan
- ilmuwan
- naskah
- script
- Kedua
- detik
- Bagian
- segmen
- memilih
- terpilih
- memilih
- Seri
- layanan
- Layanan
- set
- pengaturan
- pengaturan
- Share
- dia
- harus
- menunjukkan
- Pertunjukkan
- penutupan
- penting
- Sederhana
- disederhanakan
- Ukuran
- ukuran
- kecil
- lebih kecil
- So
- Perangkat lunak
- larutan
- tertentu
- Secara khusus
- ditentukan
- pidato
- Speech Recognition
- kecepatan
- Pengeluaran
- lisan
- awal
- Negara
- state-of-the-art
- Langkah
- Tangga
- penyimpanan
- strategi
- selanjutnya
- sukses
- seperti itu
- tiba-tiba
- cocok
- mendukung
- pendukung
- Mendukung
- yakin
- gelora
- sistem
- tabel
- Mengambil
- pengambilan
- tugas
- tugas
- Teknologi
- dari
- bahwa
- Grafik
- Inggris
- mereka
- Mereka
- kemudian
- Sana.
- karena itu
- Ini
- mereka
- ini
- tiga
- waktu
- Seri waktu
- kali
- untuk
- alat
- obor
- lalu lintas
- Pelatihan VE
- terlatih
- Mengubah
- transformator
- transformer
- memicu
- dipicu
- tv
- TV Series
- dua
- mengetik
- khas
- Uk
- bawah
- unlocking
- atas
- us
- menggunakan
- bekas
- user-friendly
- Pengguna
- menggunakan
- kegunaan
- Penggunaan
- Memanfaatkan
- Berharga
- nilai
- variabel
- berbagai
- Luas
- versi
- penglihatan
- Suara
- perintah suara
- volume
- menunggu
- ingin
- adalah
- we
- jaringan
- layanan web
- BAIK
- adalah
- ketika
- kapan saja
- yang
- Berbisik
- lebar
- Rentang luas
- dengan
- dalam
- alur kerja
- bekerja
- bernilai
- penulisan
- kamu
- Anda
- zephyrnet.dll