AWS ragasztóstúdió egy grafikus felület, amely megkönnyíti a kivonatolási, átalakítási és betöltési (ETL) feladatok létrehozását, futtatását és figyelését. AWS ragasztó. Lehetővé teszi az adatátalakítási munkafolyamatok vizuális összeállítását különböző adatkezelési lépéseket képviselő csomópontok segítségével, amelyeket később automatikusan futtatható kóddá alakítanak át.
AWS ragasztóstúdió A közelmúltban megjelent 10 további vizuális átalakítás, amely lehetővé teszi a fejlettebb feladatok vizuális módon történő létrehozását kódolási ismeretek nélkül. Ebben a bejegyzésben olyan lehetséges felhasználási eseteket tárgyalunk, amelyek tükrözik a közös ETL-szükségleteket.
Az ebben a bejegyzésben bemutatott új átalakítások a következők: Összefűzés, Karakterlánc felosztása, Tömb oszlopokhoz, Aktuális időbélyeg hozzáadása, Sorok elforgatása az oszlopokhoz, Oszlopok forgatása sorokhoz, Keresés, Tömb felrobbanása vagy oszlopokba való leképezés, Származtatott oszlop és Automatikus kiegyensúlyozás feldolgozása .
Megoldás áttekintése
Ebben a használati esetben van néhány JSON-fájlunk részvényopciós műveletekkel. Az adatok tárolása előtt szeretnénk néhány átalakítást végrehajtani a könnyebb elemzés érdekében, valamint külön adatkészlet-összefoglalót is szeretnénk készíteni.
Ebben az adatkészletben minden sor az opciós szerződések kereskedelmét jelenti. Az opciók olyan pénzügyi eszközök, amelyek jogot – de nem kötelezettséget – biztosítanak részvények fix áron történő vételére vagy eladására (ún. kötési ár) meghatározott lejárati idő előtt.
Beviteli adat
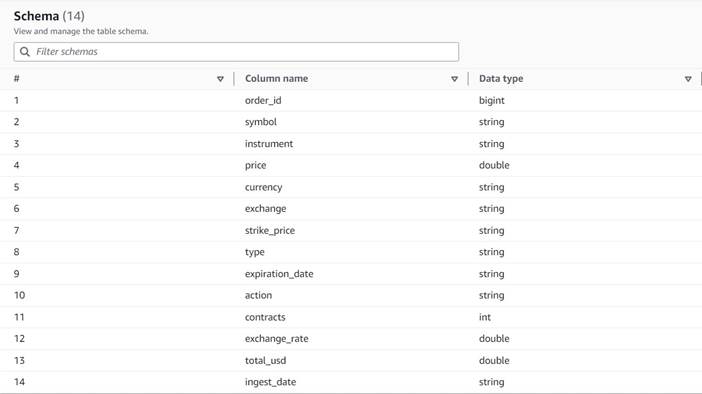
Az adatok a következő sémát követik:
- Rendelés azonosító – Egyedi azonosító
- szimbólum – Általában néhány betűn alapuló kód, amely azonosítja a mögöttes részvényeket kibocsátó vállalatot
- műszer – A név, amely azonosítja a vásárolt vagy eladott opciót
- valuta – Az ISO pénznemkód, amelyben az árat kifejezik
- ár – Az egyes opciós szerződések vásárlásáért fizetett összeg (a legtöbb tőzsdén egy szerződés 100 részvény vételét vagy eladását teszi lehetővé)
- csere – Annak a tőzsdei központnak vagy helyszínnek a kódja, ahol az opcióval kereskedtek
- eladott – Azon szerződések számának listája, amelyeket az eladási megbízás kitöltésére rendeltek, ha ez eladási ügylet
- megvett – A vételi megbízás kitöltésére kiosztott szerződések számának listája, ha ez vételi kereskedelem
A következő példa az ehhez a bejegyzéshez generált szintetikus adatokból:
ETL követelmények
Ezek az adatok számos egyedi jellemzővel rendelkeznek, amelyek gyakran megtalálhatók a régebbi rendszereken, amelyek megnehezítik az adatok használatát.
A következők az ETL követelmények:
- A műszer neve értékes információkat tartalmaz, amelyeket az emberek megértenek; külön oszlopokba szeretnénk normalizálni a könnyebb elemzés érdekében.
- Az attribútumok
boughtés asoldkölcsönösen kizárják egymást; ezeket egyetlen oszlopba vonhatjuk össze a szerződésszámokkal, és van egy másik oszlop, amely jelzi, hogy a szerződéseket ebben a sorrendben vették vagy értékesítették. - Meg akarjuk őrizni az egyes szerződések kiosztásával kapcsolatos információkat, de egyedi sorokként, ahelyett, hogy számsorral kényszerítenénk a felhasználókat. Összeadhatnánk a számokat, de elveszítenénk a megbízás kitöltésének módját (piaci likviditást jelezve). Ehelyett úgy döntünk, hogy denormalizáljuk a táblázatot, így minden sorban egyetlen számú szerződés szerepel, a több számot tartalmazó rendeléseket külön sorokra bontva. Tömörített oszlopos formátumban ennek az ismétlődésnek az extra adatkészlet mérete gyakran kicsi, ha tömörítést alkalmaznak, ezért elfogadható az adatkészlet lekérdezésének megkönnyítése.
- Összefoglaló táblázatot szeretnénk létrehozni az egyes opciótípusokhoz (hívás és eladás) minden részvényhez. Ez jelzi az egyes részvények piaci hangulatát és általában a piacot (kapzsiság vs. félelem).
- Az átfogó kereskedési összefoglalók lehetővé tételéhez minden művelethez meg szeretnénk adni a végösszeget, és a valutát USA-dollárra standardizálni egy hozzávetőleges átváltási hivatkozás segítségével.
- Szeretnénk hozzáadni a dátumot, amikor ezek az átalakulások megtörténtek. Ez hasznos lehet például, ha utalást tesz arra, hogy mikor történt a valutaváltás.
Ezen követelmények alapján a munka két kimenetet fog eredményezni:
- CSV-fájl az egyes szimbólumokhoz és típusokhoz tartozó szerződések számának összefoglalásával
- Katalógustábla a rendelés történetének megőrzéséhez, a jelzett átalakítások elvégzése után
Előfeltételek
Ehhez a használati esethez saját S3-vödörre lesz szüksége. Új vödör létrehozásához lásd: Vödör létrehozása.
Szintetikus adatok generálása
A bejegyzés követéséhez (vagy önálló kísérletezéshez) szintetikusan előállíthatja ezt az adatkészletet. A következő Python-szkript futtatható Python-környezetben, amelyen Boto3 telepítve van, és amelyhez hozzáfér Amazon egyszerű tárolási szolgáltatás (Amazon S3).
Az adatok generálásához hajtsa végre a következő lépéseket:
- Az AWS Glue Studio alkalmazásban hozzon létre egy új munkát a lehetőséggel Python shell szkriptszerkesztő.
- Adjon nevet a munkának, és a Munka részletei lapon válassza ki a megfelelő szerepet és egy nevet a Python szkriptnek.
- A Munka részletei szakaszt, bontsa ki Speciális tulajdonságok és görgessen lefelé Munka paraméterei.
- Adja meg a nevű paramétert
--bucketés értékként rendelje hozzá a mintaadatok tárolására használni kívánt vödör nevét. - Írja be a következő szkriptet az AWS Glue shell szerkesztőjébe:
- Futtassa a feladatot, és várja meg, amíg sikeresen befejezettként jelenik meg a Futtatások lapon (csak néhány másodpercet vesz igénybe).
Minden egyes futtatás egy JSON-fájlt hoz létre, amely 1,000 sort tartalmaz a megadott gyűjtőhely és előtag alatt transformsblog/inputdata/. A feladatot többször is futtathatja, ha több bemeneti fájllal szeretné tesztelni.
A szintetikus adatok minden sora egy adatsor, amely egy JSON-objektumot képvisel, például:
Hozza létre az AWS Glue vizuális feladatot
Az AWS Glue vizuális feladat létrehozásához hajtsa végre a következő lépéseket:
- Lépjen az AWS Glue Studio oldalára, és hozzon létre egy feladatot az opció segítségével Vizuális üres vászonnal.
- szerkesztése
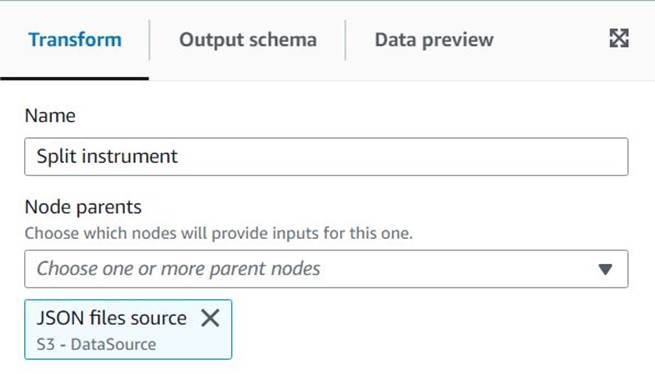
Untitled jobnevet adni és hozzárendelni AWS Glue számára megfelelő szerep a Munka részletei Tab. - Adjon hozzá egy S3 adatforrást (nevezheti
JSON files source), és adja meg az S3 URL-t, amely alatt a fájlok tárolva vannak (példáuls3://<your bucket name>/transformsblog/inputdata/), majd válassza ki JSON mint az adatformátum. - választ Következzen séma tehát az adatok alapján állítja be a kimeneti sémát.
Ebből a forráscsomópontból továbbra is láncolni fogja a transzformációkat. Minden egyes transzformáció hozzáadásakor győződjön meg arról, hogy a kiválasztott csomópont az utoljára hozzáadott csomópont, hogy a rendszer szülőként legyen hozzárendelve, hacsak az utasítások másként nem jelzik.
Ha nem a megfelelő szülőt választotta, bármikor szerkesztheti a szülőt úgy, hogy kijelöli, majd kiválaszt egy másik szülőt a konfigurációs ablaktáblán.
Minden egyes hozzáadott csomóponthoz egy konkrét nevet kell adni (így a csomópont célja megjelenik a grafikonon) és konfigurációt a Átalakítás Tab.
Minden alkalommal, amikor egy átalakítás megváltoztatja a sémát (például új oszlop hozzáadása), a kimeneti sémát frissíteni kell, hogy az látható legyen a későbbi átalakítások számára. A kimeneti sémát manuálisan is szerkesztheti, de praktikusabb és biztonságosabb az adatok előnézetével.
Ezenkívül így ellenőrizheti, hogy az átalakítás a várt módon működik-e. Ehhez nyissa meg a Adatok előnézete lapon az átalakítás kiválasztásával, és indítsa el az előnézeti munkamenetet. Miután ellenőrizte, hogy az átalakított adatok a várt módon néznek ki, lépjen a Kimeneti séma lapot és válasszon Adat-előnézeti séma használata a séma automatikus frissítéséhez.
Amikor új típusú átalakításokat ad hozzá, az előnézet üzenetet jeleníthet meg a hiányzó függőségről. Amikor ez megtörténik, válasszon Munkamenet befejezése és indítson egy újat, így az előnézet felveszi az új típusú csomópontot.
A műszer információinak kinyerése
Kezdjük azzal, hogy foglalkozunk az eszköz nevével kapcsolatos információkkal, és normalizáljuk azokat oszlopokba, amelyek könnyebben elérhetők a kapott kimeneti táblában.
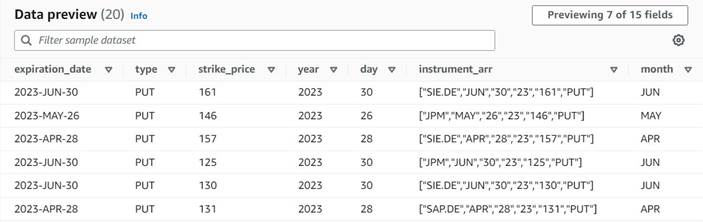
- Hozzáadása Split String csomópontot, és nevezd el
Split instrument, amely egy szóköz reguláris kifejezéssel tokenizálja a műszeroszlopot:s+(Ebben az esetben egyetlen szóköz is megteszi, de ez a mód rugalmasabb és vizuálisan áttekinthetőbb). - Meg akarjuk tartani az eredeti eszközinformációkat, ezért adjon meg egy új oszlopnevet az osztott tömbhöz:
instrument_arr.
- Adjon hozzá egy Tömb oszlopokba csomópontot, és nevezd el
Instrument columnshogy az imént létrehozott tömboszlopot új mezőkké konvertálja, kivéve asymbol, amelyhez már van rovatunk. - Válassza ki az oszlopot
instrument_arr, hagyja ki az első tokent, és mondja meg neki, hogy bontsa ki a kimeneti oszlopokatmonth, day, year, strike_price, typeindexek segítségével2, 3, 4, 5, 6(a vessző utáni szóköz az olvashatóságot szolgálja, nincs hatással a konfigurációra).
A kivont évszám csak két számjeggyel van kifejezve; tegyünk egy megállót, és feltételezzük, hogy ez ebben a században van, ha csak két számjegyet használnak.
- Hozzáadása Származtatott oszlop csomópontot, és nevezd el
Four digits year. - belép
yearszármaztatott oszlopként, így felülírja azt, és írja be a következő SQL kifejezést:CASE WHEN length(year) = 2 THEN ('20' || year) ELSE year END
A kényelem érdekében egy expiration_date mező, amelyet a felhasználó referenciaként használhat az opció gyakorlásának utolsó dátumára.
- Hozzáadása Oszlopok összefűzése csomópontot, és nevezd el
Build expiration date. - Nevezze el az új oszlopot
expiration_date, válassza ki az oszlopokatyear,monthésday(ebben a sorrendben), és egy kötőjelet távtartóként.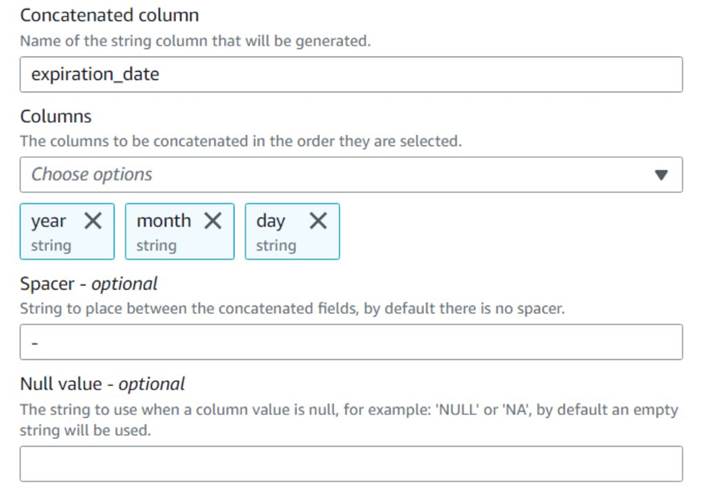
Az eddigi diagramnak a következő példa szerint kell kinéznie.
![]()
Az új oszlopok eddigi adat-előnézete a következő képernyőképen néz ki.
Normalizálja a szerződések számát
Az adatok minden sora jelzi az egyes opciók vásárolt vagy eladott szerződéseinek számát, valamint azokat a kötegeket, amelyeken a megrendeléseket kitöltötték. Anélkül, hogy elveszítenénk az egyes kötegekre vonatkozó információkat, azt szeretnénk, hogy minden összeg egy egyedi sorban legyen egyetlen összeg értékkel, míg a többi információ replikálódik minden egyes sorba.
Először is vonjuk össze az összegeket egyetlen oszlopba.
- Adjon hozzá egy Oszlopok forgatása sorokká csomópontot, és nevezd el
Unpivot actions. - Válassza ki az oszlopokat
boughtés asolda forgatás feloldásához és a nevek és értékek elnevezésű oszlopokban való tárolásáhozactionés acontracts, Ill.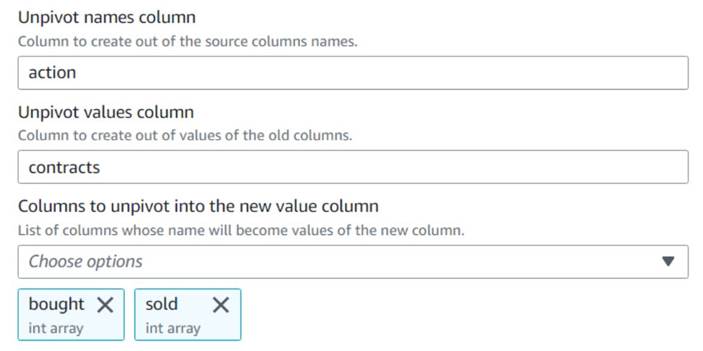
Figyeljük meg az előnézetben, hogy az új oszlopcontractsa transzformáció után is egy számtömb.
- Adjon hozzá egy Robbantsd fel a tömböt vagy térképezd fel sorokba nevű sor
Explode contracts. - Válassza a
contractsoszlopot és írja becontractsúj oszlopként, hogy felülbírálhassuk (nem kell megtartanunk az eredeti tömböt).
Az előnézet most azt mutatja, hogy minden sorhoz tartozik egy contracts összeget, és a többi mező ugyanaz.
Ez azt is jelenti order_id már nem egyedi kulcs. Saját felhasználási eseteihez el kell döntenie, hogyan modellezze adatait, és hogy szeretné-e denormalizálni vagy sem.
Az alábbi képernyőkép egy példa arra, hogyan néznek ki az új oszlopok az eddigi átalakítások után.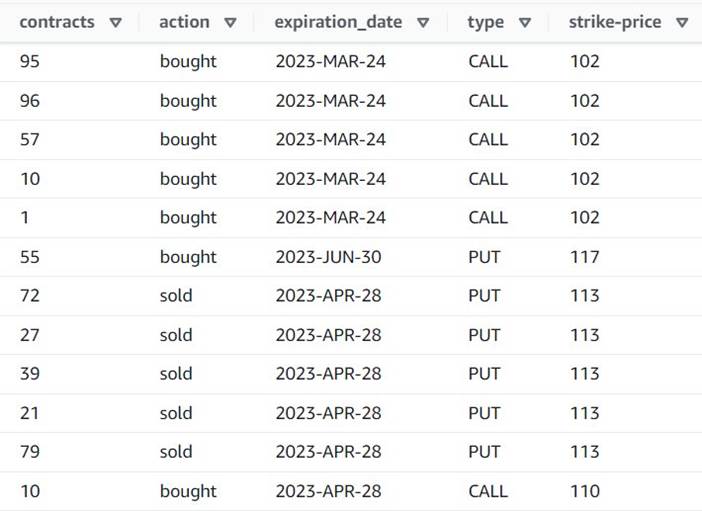
Hozzon létre egy összefoglaló táblázatot
Most hozzon létre egy összefoglaló táblázatot az egyes típusokhoz és minden részvényszimbólumhoz kapcsolódó szerződések számával.
Szemléltetésképpen tegyük fel, hogy a feldolgozott fájlok egy naphoz tartoznak, így ez az összefoglaló információt nyújt az üzleti felhasználóknak arról, hogy az adott napon milyen piaci érdeklődés és hangulat uralkodik.
- Hozzáadása Válassza a Mezők lehetőséget csomópontot, és jelölje ki a következő oszlopokat, amelyeket meg szeretne őrizni az összegzés számára:
symbol,typeéscontracts.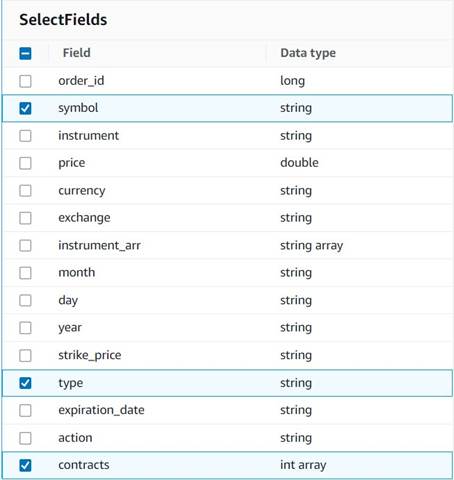
- Hozzáadása Forgassa a sorokat oszlopokba csomópontot, és nevezd el
Pivot summary. - Összesítés a
contractsoszlop használatávalsumés válassza ki a konvertálásttypeoszlop.
Általában valamilyen külső adatbázisban vagy fájlban tárolja referenciaként; Ebben a példában CSV-fájlként mentjük el az Amazon S3-on.
- Adjon hozzá egy Automatikus egyensúly feldolgozás csomópontot, és nevezd el
Single output file. - Bár ezt a transzformációs típust általában a párhuzamosság optimalizálására használják, itt a kimenet egyetlen fájlra való csökkentésére használjuk. Ezért lépjen be
1a partíciók számának konfigurációjában.
- Adjon hozzá egy S3 célt, és nevezze el
CSV Contract summary. - Válassza ki a CSV-t adatformátumként, és adjon meg egy S3 elérési utat, ahol a job szerepkör fájlokat tárolhat.
A munka utolsó részének most úgy kell kinéznie, mint a következő példa.![]()
- Mentse el és futtassa a munkát. Használja a Runs lapon ellenőrizheti, hogy sikeresen befejeződött-e.
Az elérési út alatt talál egy CSV-fájlt, annak ellenére, hogy nem rendelkezik ezzel a kiterjesztéssel. Valószínűleg a letöltés után hozzá kell adnia a bővítményt a megnyitásához.
Egy olyan eszközön, amely képes olvasni a CSV-fájlt, az összefoglalónak az alábbi példához hasonlónak kell lennie.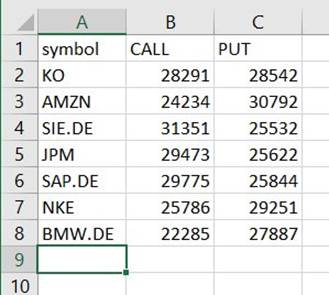
Tisztítsa meg az ideiglenes oszlopokat
A rendelések elõzménytáblázatba történõ mentésére való felkészülés érdekében a jövõbeni elemzés céljából tisztítsunk meg néhány, az út során létrehozott ideiglenes oszlopot.
- Hozzáadása Drop Fields csomópont a
Explode contractsszülőként kiválasztott csomópont (az adatfolyamot elágazzuk, hogy külön kimenetet generáljunk). - Válassza ki az eldobandó mezőket:
instrument_arr,month,dayésyear.
A többit meg akarjuk tartani, hogy elmentsük őket a későbbiekben elkészítendő történeti táblázatba.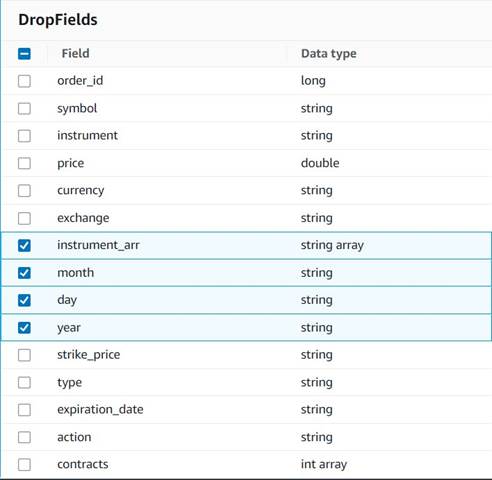
Pénznemek szabványosítása
Ezek a szintetikus adatok fiktív műveleteket tartalmaznak két pénznemre vonatkozóan, de egy valós rendszerben a világ minden tájáról kaphat valutákat a piacokról. Hasznos a kezelt pénznemeket egyetlen referenciavalutává standardizálni, így könnyen összehasonlíthatók és összesíthetők jelentéskészítés és elemzés céljából.
Az általunk használt Amazon Athéné a hozzávetőleges devizakonverziókat tartalmazó táblázat szimulálásához, amely időszakonként frissül (itt feltételezzük, hogy elég időben dolgozzuk fel a rendeléseket ahhoz, hogy az átváltás ésszerű reprezentatív legyen az összehasonlítás szempontjából).
- Nyissa meg az Athena konzolt ugyanabban a régióban, ahol az AWS ragasztót használja.
- Futtassa a következő lekérdezést a táblázat létrehozásához úgy, hogy beállít egy S3 helyet, ahol az Athena és az AWS Glue szerepkörök is tudnak olvasni és írni. Ezenkívül érdemes lehet a táblát egy másik adatbázisban tárolni, mint
default(Ha ezt teszi, frissítse a táblázat minősített nevét a megadott példákban). - Írjon be néhány minta konverziót a táblázatba:
INSERT INTO default.exchange_rates VALUES ('usd', 1.0), ('eur', 1.09), ('gbp', 1.24); - Most már meg kell tudnia nézni a táblázatot a következő lekérdezéssel:
SELECT * FROM default.exchange_rates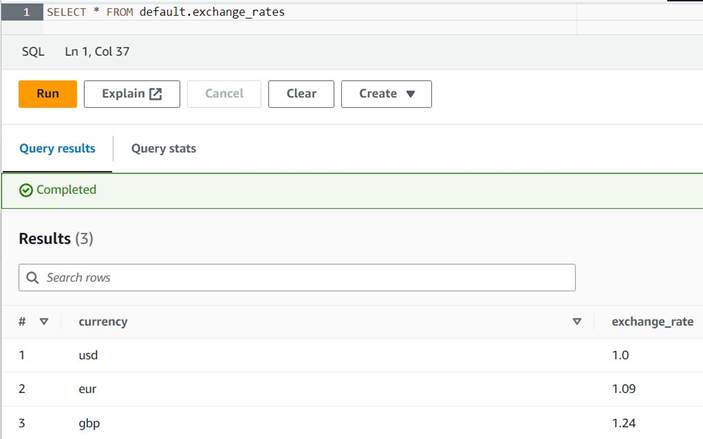
- Visszatérve az AWS Glue vizuális munkához, adja hozzá a Lookup csomópont (gyermekeként
Drop Fields) és nevezd elExchange rate. - Adja meg az imént létrehozott táblázat minőségi nevét a segítségével
currencygombot, és válassza ki aexchange_ratehasználni kívánt mezőt.
Mivel a mező neve az adatokban és a keresési táblában is ugyanaz, csak megadhatjuk a nevetcurrencyés nincs szükség leképezés meghatározására.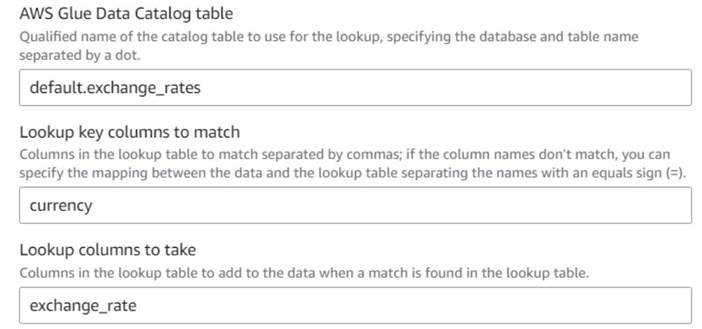
Az írás idején a keresési transzformációt nem támogatja az adatok előnézete, és hibát fog jelezni, hogy a tábla nem létezik. Ez csak az adatok előnézetére vonatkozik, és nem akadályozza meg a feladat megfelelő futtatását. A bejegyzés néhány hátralévő lépése nem igényli a séma frissítését. Ha adat-előnézetet kell futtatnia más csomópontokon, ideiglenesen eltávolíthatja a keresési csomópontot, majd visszahelyezheti. - Hozzáadása Származtatott oszlop csomópontot, és nevezd el
Total in usd. - Nevezze el a származtatott oszlopot
total_usdés használja a következő SQL kifejezést:round(contracts * price * exchange_rate, 2)
- Hozzáadása Adja hozzá az aktuális időbélyeget csomópontot, és nevezze el az oszlopot
ingest_date. - Használja a formátumot
%Y-%m-%daz időbélyeghez (bemutató célból csak a dátumot használjuk; ha akarod, pontosíthatod).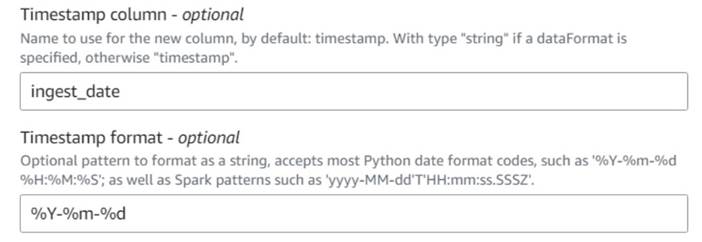
Mentse el a történelmi rendelések táblázatát
A rendelési előzmények táblázatának mentéséhez hajtsa végre a következő lépéseket:
- Adjon hozzá egy S3 célcsomópontot, és nevezze el
Orders table. - Konfigurálja a Parquet formátumot frappáns tömörítéssel, és adjon meg egy S3 célútvonalat az eredmények tárolására (az összefoglalótól elkülönítve).
- választ Hozzon létre egy táblát az adatkatalógusban és a későbbi futtatások során, frissítse a sémát és adjon hozzá új partíciókat.
- Adjon meg egy céladatbázist és egy nevet az új tábla számára, például:
option_orders.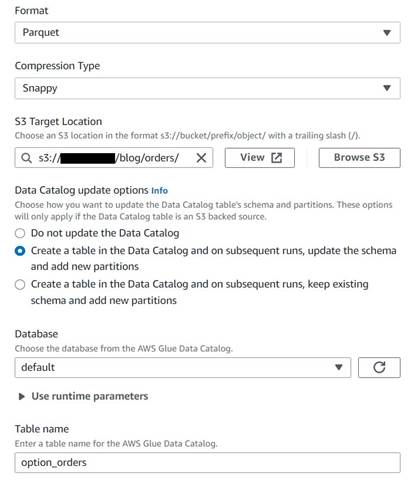
A diagram utolsó részének most a következőhöz hasonlóan kell kinéznie, két ággal a két külön kimenethez.![]()
A feladat sikeres futtatása után egy olyan eszközzel, mint az Athena, áttekintheti a job által az új tábla lekérdezésével létrehozott adatokat. A táblázatot megtalálja az Athena listán, és válassza ki Előnézeti táblázat vagy csak futtasson egy SELECT lekérdezést (frissítse a tábla nevét a használt névre és katalógusra):
SELECT * FROM default.option_orders limit 10
A táblázat tartalmának az alábbi képernyőképhez hasonlóan kell kinéznie.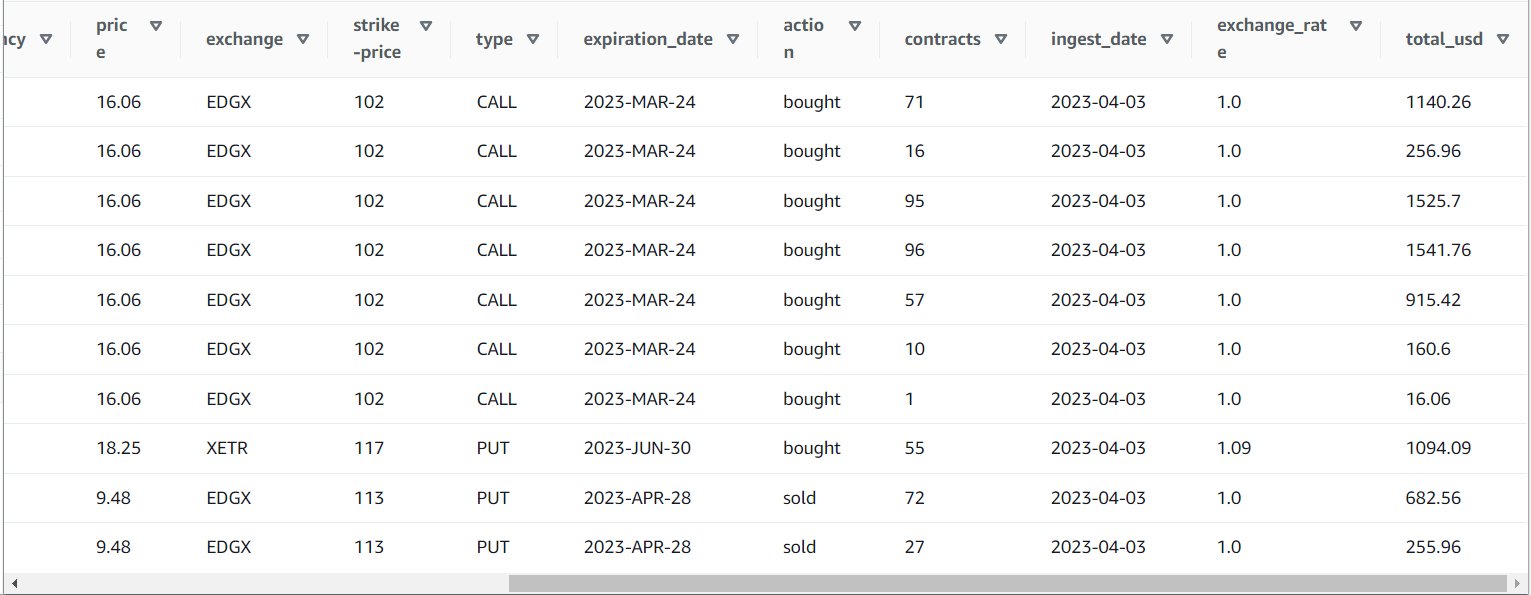
Tisztítsuk meg
Ha nem szeretné megtartani ezt a példát, törölje a két létrehozott jobot, az Athena két tábláját és az S3 elérési utat, ahol a bemeneti és kimeneti fájlokat tárolták.
Következtetés
Ebben a bejegyzésben bemutattuk, hogy az AWS Glue Studio új átalakításai hogyan segíthetnek a minimális konfiguráció mellett haladó átalakítások elvégzésében. Ez azt jelenti, hogy több ETL-használati esetet implementálhat anélkül, hogy kódot kellene írnia és karbantartania. Az új átalakítások már elérhetőek az AWS Glue Studio-ban, így már ma is használhatja az új átalakításokat vizuális munkáiban.
A szerzőről
![]() Gonzalo Herreros az AWS Glue csapatának vezető Big Data építésze.
Gonzalo Herreros az AWS Glue csapatának vezető Big Data építésze.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoAiStream. Web3 adatintelligencia. Felerősített tudás. Hozzáférés itt.
- A jövő pénzverése – Adryenn Ashley. Hozzáférés itt.
- Részvények vásárlása és eladása PRE-IPO társaságokban a PREIPO® segítségével. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/big-data/ten-new-visual-transforms-in-aws-glue-studio/
- :van
- :is
- :nem
- :ahol
- $ UP
- 000
- 1
- 10
- 100
- 102
- 11
- 12
- 13
- 14
- 15%
- 20
- 23
- 24
- 26
- 28
- 30
- 49
- 67
- 7
- 8
- 9
- 937
- 98
- a
- Képes
- Rólunk
- elfogadható
- hozzáférés
- Eszerint
- hozzá
- hozzáadott
- hozzáadásával
- fejlett
- Után
- Minden termék
- elkülönített
- juttatások
- lehetővé
- lehetővé teszi, hogy
- mentén
- már
- Is
- mindig
- amazon
- összeg
- Összegek
- an
- elemzés
- elemez
- és a
- Másik
- bármilyen
- alkalmazott
- hozzávetőleges
- április
- VANNAK
- érv
- Sor
- AS
- kijelölt
- At
- attribútumok
- automatikusan
- elérhető
- AWS
- AWS ragasztó
- vissza
- alapján
- BE
- előtt
- hogy
- Nagy
- Big adatok
- üres
- BMW
- mindkét
- megvett
- ágak
- épít
- üzleti
- de
- megvesz
- by
- hívás
- TUD
- eset
- esetek
- katalógus
- Központ
- Század
- Változások
- jellemzők
- ellenőrizze
- gyermek
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a
- választja
- világosabb
- kód
- Kódolás
- Oszlop
- Oszlopok
- Közös
- képest
- összehasonlítás
- teljes
- Befejezett
- Configuration
- Konzol
- megszilárdítása
- tartalmaz
- tartalom
- szerződés
- szerződések
- kényelem
- Átalakítás
- konverziók
- megtérít
- átalakított
- VÁLLALAT
- tudott
- teremt
- készítette
- létrehozása
- pénznem
- Valuta
- Jelenlegi
- DAG
- dátum
- adatbázis
- találka
- Időpontok
- dátum idő
- nap
- üzlet
- foglalkozó
- dönt
- alapértelmezett
- meghatározott
- igazolták
- Függőség
- Származtatott
- Ellenére
- részletek
- különböző
- számjegy
- megvitatni
- do
- Nem
- Ennek
- dollár
- ne
- kétszeresére
- le-
- Csepp
- csökkent
- minden
- könnyebb
- könnyen
- könnyű
- szerkesztő
- lehetővé
- elég
- belép
- Környezet
- hiba
- Eter (ETH)
- EUR
- példa
- példák
- Kivéve
- csere
- Feltételek
- Kizárólagos
- létezik
- Bontsa
- várható
- kísérlet
- lejárat
- kifejezve
- kiterjesztés
- külső
- külön-
- kivonat
- messze
- félelem
- kevés
- kitalált
- mező
- Fields
- filé
- Fájlok
- kitöltése
- megtöltött
- pénzügyi
- Pénzügyi eszközök
- Találjon
- vezetéknév
- rögzített
- rugalmas
- következik
- következő
- következik
- A
- formátum
- talált
- ból ből
- jövő
- angol font
- általános
- általában
- generál
- generált
- kap
- Ad
- ad
- Go
- grafikon
- Kapzsiság
- Kezelés
- megtörténik
- Legyen
- tekintettel
- segít
- itt
- történeti
- történelem
- Hogyan
- How To
- HTML
- http
- HTTPS
- Az emberek
- i
- azonosítja
- azonosítani
- if
- Hatás
- végre
- importál
- in
- indexek
- jelzett
- jelzi
- jelezve
- jelzés
- egyéni
- információ
- bemenet
- példa
- helyette
- utasítás
- műszer
- eszközök
- kamat
- Felület
- bele
- ISO
- IT
- ITS
- Munka
- Állások
- jpg
- json
- éppen
- Tart
- Kulcs
- Kedves
- keresztnév
- a későbbiekben
- mint
- LIMIT
- vonal
- fizetőképesség
- Lista
- kiszámításának
- elhelyezkedés
- hosszabb
- néz
- hasonló
- MEGJELENÉS
- lookup
- veszít
- vesztes
- készült
- fenntartása
- csinál
- KÉSZÍT
- kézzel
- térkép
- térképészet
- piacára
- piaci hangulat
- piacok
- Lehet..
- eszközök
- megy
- üzenet
- esetleg
- minimum
- hiányzó
- modell
- monitor
- több
- a legtöbb
- többszörös
- közösen
- név
- Nevezett
- nevek
- Szükség
- igények
- Új
- nem
- csomópont
- csomópontok
- rendszerint
- Most
- szám
- számok
- tárgy
- of
- gyakran
- on
- ONE
- csak
- nyitva
- működés
- Művelet
- Optimalizálja
- opció
- Opciók
- or
- érdekében
- rendelés
- eredeti
- Más
- másképp
- teljesítmény
- felett
- átfogó
- felülírás
- saját
- fizetett
- üvegtábla
- paraméter
- rész
- ösvény
- választás
- csővezeték
- tengely
- Hely
- Plató
- Platón adatintelligencia
- PlatoData
- állás
- potenciális
- Gyakorlati
- pontos
- megakadályozása
- Preview
- ár
- valószínűleg
- folyamat
- feldolgozás
- gyárt
- Készült
- ad
- feltéve,
- biztosít
- Vásárlás
- cél
- célokra
- tesz
- Piton
- képzett
- emel
- véletlen
- Olvass
- igazi
- ésszerű
- csökkenteni
- tükröznie
- vidék
- megmaradó
- eltávolítása
- többszörözött
- Jelentő
- képvisel
- reprezentatív
- képviselő
- jelentése
- szükség
- követelmények
- megköveteli,
- illetőleg
- REST
- kapott
- Eredmények
- Kritika
- Szerep
- szerepek
- SOR
- futás
- futás
- biztonságosabb
- azonos
- nedv
- Megtakarítás
- megtakarítás
- lapozzunk
- másodperc
- kiválasztott
- kiválasztása
- elad
- idősebb
- érzés
- különálló
- ülés
- Szettek
- beállítás
- Megoszt
- Héj
- kellene
- előadás
- Műsorok
- hasonló
- Egyszerű
- egyetlen
- Méret
- készségek
- kicsi
- So
- eddig
- eladott
- néhány
- valami
- forrás
- Hely
- terek
- különleges
- meghatározott
- osztott
- táblázatkezelő
- SQL
- kezdet
- Lépései
- Még mindig
- készlet
- tárolás
- tárolni
- memorizált
- Húr
- stúdió
- későbbi
- sikeresen
- megfelelő
- ÖSSZEFOGLALÓ
- Támogatott
- szimbólum
- szintetikus
- szintetikus adatok
- szintetikusan
- rendszer
- Systems
- táblázat
- Vesz
- cél
- csapat
- mondd
- ideiglenes
- tíz
- teszt
- mint
- hogy
- A
- A grafikon
- az információ
- a világ
- Őket
- akkor
- ebből adódóan
- Ezek
- ők
- ezt
- azok
- idő
- alkalommal
- időbélyeg
- nak nek
- Ma
- jelképes
- tokenizálni
- vett
- szerszám
- Végösszeg
- kereskedelem
- forgalmazott
- Átalakítás
- Átalakítás
- transzformációk
- át
- kettő
- típus
- alatt
- mögöttes
- megért
- egyedi
- -ig
- Frissítések
- frissítve
- frissítése
- URL
- us
- USA dollár
- USAdollár
- használ
- használati eset
- használt
- használó
- Felhasználók
- segítségével
- Értékes
- Értékes információ
- érték
- Értékek
- helyszín
- ellenőrzött
- ellenőrzése
- Megnézem
- látható
- kötet
- vs
- várjon
- akar
- volt
- Út..
- we
- voltak
- Mit
- amikor
- ami
- míg
- lesz
- val vel
- nélkül
- munkafolyamatok
- dolgozó
- világ
- lenne
- ír
- írás
- év
- te
- A te
- zephyrnet











