A generatív mesterséges intelligencia megjelenésével a mai alapmodellek (FM-ek), mint például a nagy nyelvi modellek (LLM-ek), a Claude 2 és a Llama 2, számos generatív feladatot képesek végrehajtani, mint például a kérdések megválaszolása, az összegzés és a tartalom létrehozása szöveges adatokon. A valós adatok azonban többféle módozatban is léteznek, például szöveg, kép, videó és hang. Vegyünk például egy PowerPoint slide decket. Tartalmazhat információkat szöveg formájában, vagy grafikonokba, táblázatokba és képekbe ágyazva.
Ebben a bejegyzésben egy olyan megoldást mutatunk be, amely olyan multimodális FM-eket használ, mint a Amazon Titan multimodális beágyazások modell és LLaVA 1.5 és AWS szolgáltatások, beleértve Amazon alapkőzet és a Amazon SageMaker hasonló generatív feladatok elvégzésére multimodális adatokon.
Megoldás áttekintése
A megoldás implementációt biztosít a kérdések megválaszolására a diacsomag szövegében és vizuális elemeiben található információk felhasználásával. A tervezés a Retrieval Augmented Generation (RAG) koncepciójára támaszkodik. A RAG-t hagyományosan az LLM-ek által feldolgozható szöveges adatokkal társították. Ebben a bejegyzésben a RAG-ot kiterjesztjük képekre is. Ez hatékony keresési lehetőséget biztosít a kontextus szempontjából releváns tartalom kinyeréséhez a vizuális elemekből, például táblázatokból és grafikonokból, valamint szöveget.
A képeket tartalmazó RAG-megoldások tervezésének különböző módjai vannak. Itt bemutattunk egy megközelítést, és ennek a három részes sorozatnak a második bejegyzésében egy alternatív megközelítést fogunk követni.
Ez a megoldás a következő összetevőket tartalmazza:
- Amazon Titan Multimodal Embeddings modell – Ezt az FM-et arra használják, hogy beágyazásokat generáljanak az ebben a bejegyzésben használt slide deck tartalmához. Multimodális modellként ez a Titan modell képes szöveget, képeket vagy kombinációkat feldolgozni bemenetként, és beágyazásokat generálni. A Titan Multimodal Embeddings modell 1,024 dimenziós vektorokat (beágyazásokat) generál, és az Amazon Bedrock segítségével érhető el.
- Nagy nyelvi és látási asszisztens (LLaVA) – A LLaVA egy nyílt forráskódú multimodális modell a vizuális és nyelvi megértéshez, és a diákban található adatok értelmezésére szolgál, beleértve a vizuális elemeket, például grafikonokat és táblázatokat. Mi a 7 milliárdos paraméteres verziót használjuk LLaVA 1.5-7b ebben a megoldásban.
- Amazon SageMaker – A LLaVA-modell egy SageMaker-végponton van üzembe helyezve SageMaker-tárhelyszolgáltatások használatával, és az eredményül kapott végpontot használjuk a LLaVA-modellre vonatkozó következtetések futtatására. A SageMaker notebookokat is használjuk a megoldás hangszereléséhez és bemutatásához.
- Amazon OpenSearch kiszolgáló nélküli – Az OpenSearch Serverless egy igény szerinti kiszolgáló nélküli konfiguráció a következőhöz Amazon OpenSearch szolgáltatás. Az OpenSearch Serverless vektor adatbázist használjuk a Titan Multimodal Embeddings modell által generált beágyazások tárolására. Az OpenSearch Serverless gyűjteményben létrehozott index a RAG-megoldásunk vektortárolójaként szolgál.
- Amazon OpenSearch feldolgozás (OSI) – Az OSI egy teljesen felügyelt, kiszolgáló nélküli adatgyűjtő, amely adatokat szállít az OpenSearch szolgáltatási tartományokhoz és az OpenSearch szerver nélküli gyűjteményekhez. Ebben a bejegyzésben egy OSI folyamatot használunk az adatok eljuttatására az OpenSearch Serverless vektortárolóba.
Megoldás architektúra
A megoldás kialakítása két részből áll: bevitelből és felhasználói interakcióból. A feldolgozás során feldolgozzuk a bemeneti diakészletet úgy, hogy minden diát képpé alakítunk, beágyazásokat generálunk ezekhez a képekhez, majd feltöltjük a vektoradattárat. Ezeket a lépéseket a felhasználói interakciós lépések előtt kell végrehajtani.
A felhasználói interakció fázisában a felhasználó egy kérdése beágyazásokká konvertálódik, és a vektoros adatbázisban hasonlósági keresést hajtanak végre, hogy megtalálják azt a diát, amely potenciálisan válaszokat tartalmazhat a felhasználói kérdésre. Ezután ezt a diát (képfájl formájában) biztosítjuk az LLaVA modellnek és a felhasználói kérdésnek, hogy a lekérdezésre választ generáljunk. A bejegyzéshez tartozó összes kód elérhető a GitHub pihenés.
A következő diagram a feldolgozási architektúrát mutatja be.
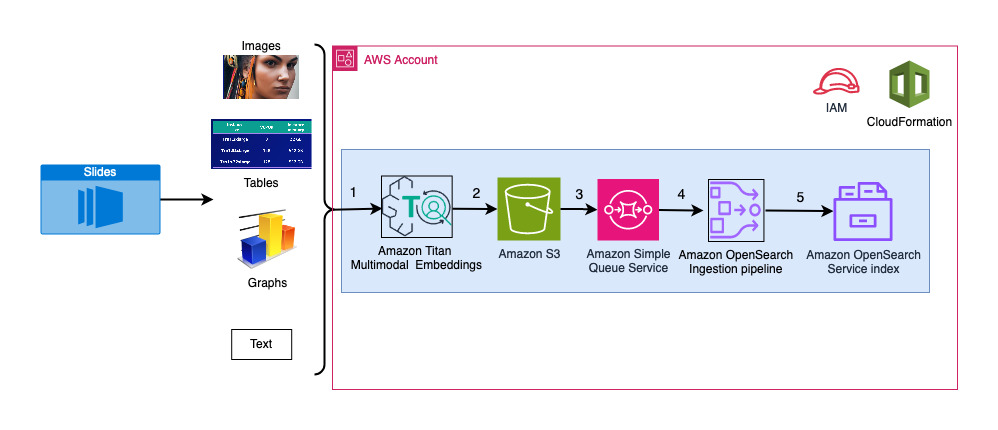
A munkafolyamat lépései a következők:
- A diák képfájlokká konvertálja (diánként egyet) JPG formátumban, és átadja a Titan Multimodal Embeddings modellnek a beágyazások létrehozásához. Ebben a bejegyzésben a slide decket használjuk A Stable Diffusion betanítása és telepítése az AWS Trainium és az AWS Inferentia segítségével a 2023. júniusi torontói AWS-csúcstalálkozóról a megoldás bemutatására. A mintacsomag 31 diát tartalmaz, így 31 vektorbeágyazási készletet hozunk létre, mindegyik 1,024 dimenzióval. További metaadatmezőket adunk hozzá ezekhez a generált vektorbeágyazásokhoz, és létrehozunk egy JSON-fájlt. Ezek a további metaadatmezők az OpenSearch hatékony keresési funkcióinak segítségével bővített keresési lekérdezések végrehajtására használhatók.
- A generált beágyazások egyetlen JSON-fájlba kerülnek, amelybe feltöltésre kerül Amazon egyszerű tárolási szolgáltatás (Amazon S3).
- Keresztül Amazon S3 eseményértesítések, egy eseményt egy Amazon Simple Queue Service (Amazon SQS) sor.
- Ez az esemény az SQS-sorban az OSI-folyamat indításához működik, amely viszont az adatokat (JSON-fájlt) dokumentumokként feldolgozza az OpenSearch Serverless indexbe. Vegye figyelembe, hogy az OpenSearch Serverless index a folyamat nyelőjeként van konfigurálva, és az OpenSearch Serverless gyűjtemény részeként jön létre.
A következő diagram a felhasználói interakciós architektúrát mutatja be.
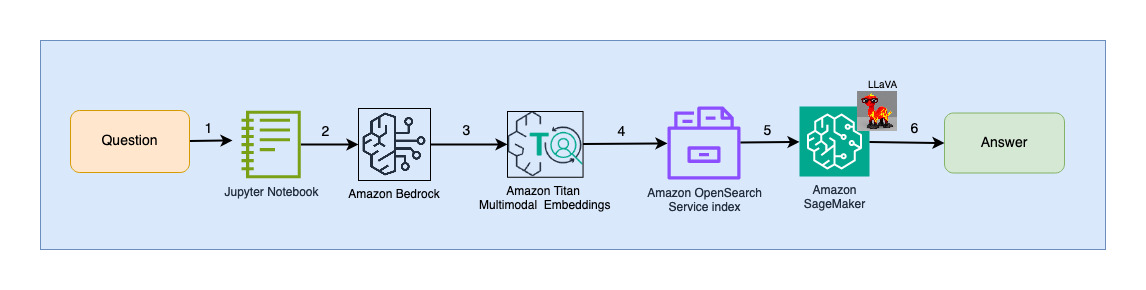
A munkafolyamat lépései a következők:
- Egy felhasználó kérdést tesz fel a felvett diakészlettel kapcsolatban.
- A felhasználói bevitel beágyazásokká alakul az Amazon Bedrock segítségével elérhető Titan Multimodal Embeddings modell segítségével. Az OpenSearch vektorkeresés ezeknek a beágyazásoknak a használatával történik. K-os legközelebbi szomszéd (k=1) keresést végzünk, hogy lekérjük a felhasználói lekérdezésnek megfelelő legrelevánsabb beágyazást. A k=1 beállítás a felhasználói kérdéshez leginkább kapcsolódó diát kéri le.
- Az OpenSearch Serverless válaszának metaadatai tartalmazzák a legrelevánsabb diának megfelelő kép elérési útját.
- A felhasználói kérdés és a kép elérési útja kombinálásával egy prompt jön létre, és a SageMaker-en tárolt LLaVA-hoz kerül. A LLaVA modell képes megérteni a felhasználói kérdést, és a képen szereplő adatok vizsgálatával válaszolni rá.
- Ennek a következtetésnek az eredménye visszakerül a felhasználóhoz.
Ezeket a lépéseket részletesen tárgyaljuk a következő szakaszokban. Lásd a Eredmények szakasz a képernyőképekhez és a kimenet részleteihez.
Előfeltételek
Az ebben a bejegyzésben található megoldás megvalósításához rendelkeznie kell egy AWS-fiók valamint az FM-ek, az Amazon Bedrock, a SageMaker és az OpenSearch Service ismerete.
Ez a megoldás a Titan Multimodal Embeddings modellt használja. Győződjön meg arról, hogy ez a modell engedélyezve van az Amazon Bedrockban. Az Amazon Bedrock konzolon válassza a lehetőséget Modell hozzáférés a navigációs ablakban. Ha a Titan Multimodal Embeddings be van kapcsolva, a hozzáférési állapot a következőt fogja jelezni Hozzáférés biztosított.
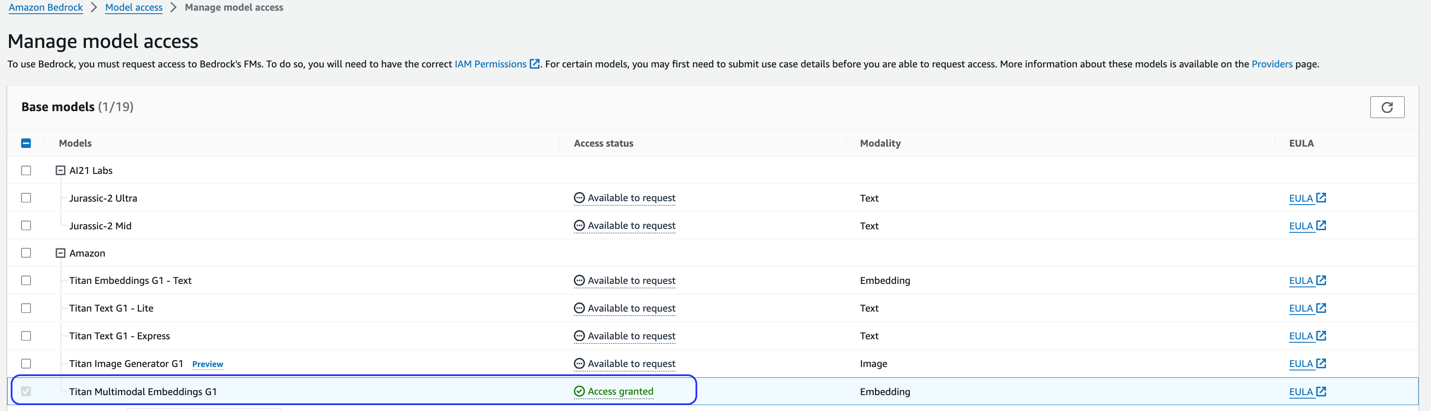
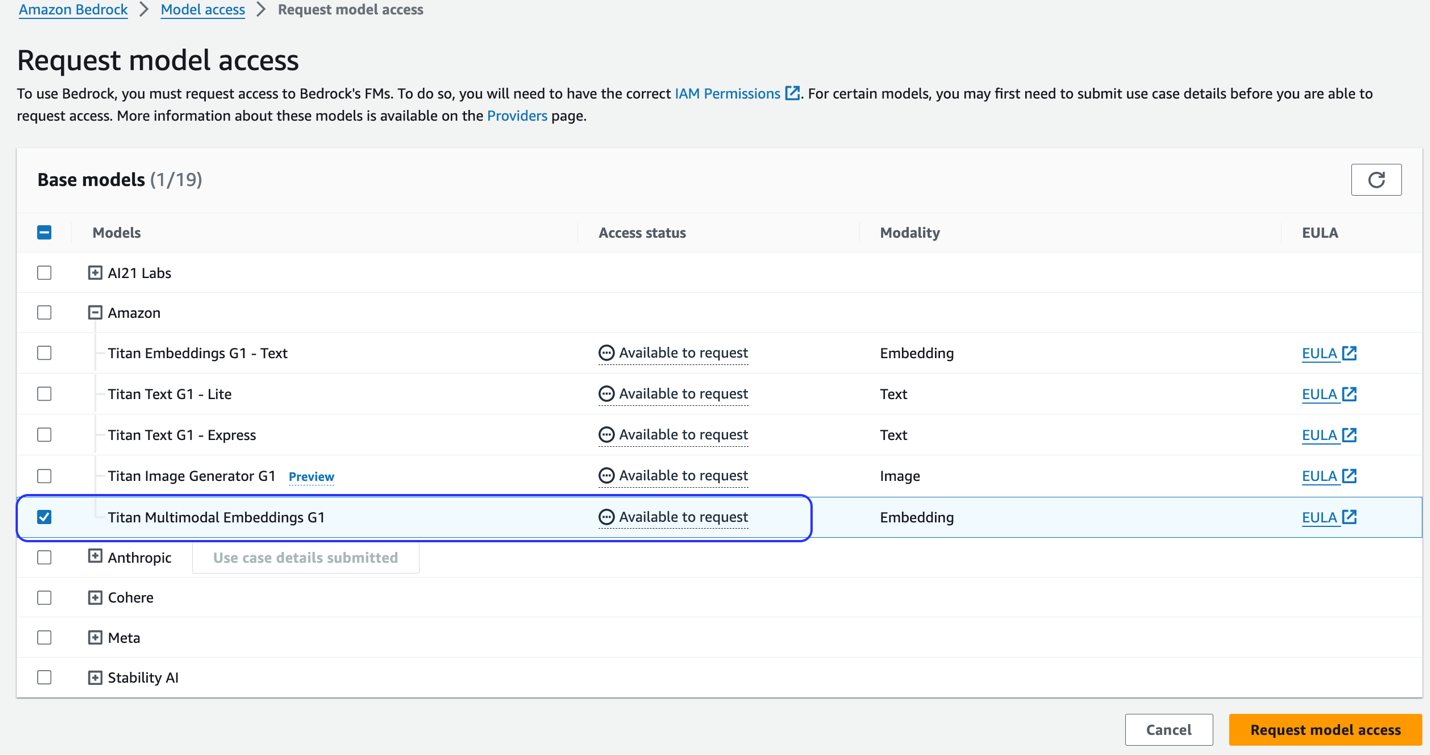
Ha a modell nem érhető el, a választással engedélyezze a hozzáférést a modellhez Model Access kezelése, kiválasztás Titan Multimodális beágyazások G1, és választ Kérjen hozzáférést a modellhez. A modell azonnal használhatóvá válik.
Használjon AWS CloudFormation sablont a megoldásverem létrehozásához
Használja a következők egyikét AWS felhőképződés sablonok (régiójától függően) a megoldási erőforrások elindításához.
| AWS régió | Link |
|---|---|
us-east-1 |
|
us-west-2 |
A verem sikeres létrehozása után navigáljon a veremhez Kimenetek fület az AWS CloudFormation konzolon, és jegyezze fel az értékét MultimodalCollectionEndpoint, amelyet a következő lépésekben használunk.
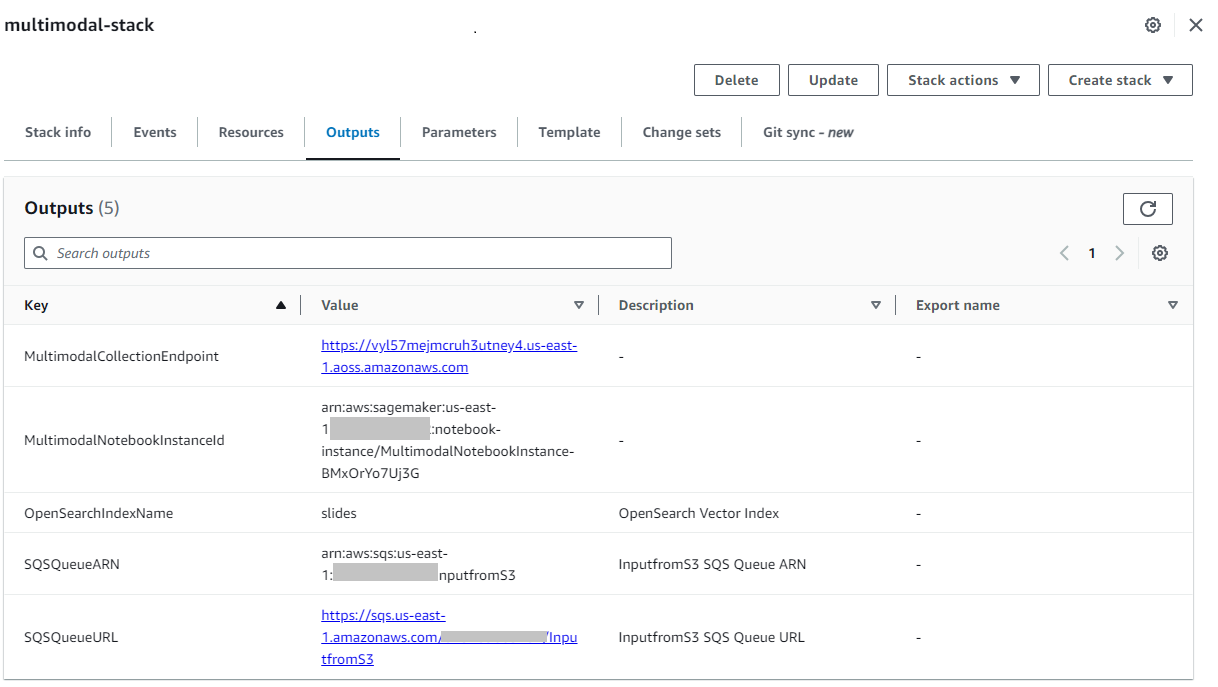
A CloudFormation sablon a következő erőforrásokat hozza létre:
- IAM szerepek - A következő AWS Identity and Access Management (IAM) szerepkörök jönnek létre. Frissítse ezeket a szerepköröket az alkalmazáshoz a legkevesebb jogosultságokkal rendelkező engedélyek.
SMExecutionRoleAmazon S3, SageMaker, OpenSearch Service és Bedrock teljes hozzáféréssel.OSPipelineExecutionRolehozzáféréssel bizonyos Amazon SQS és OSI műveletekhez.
- SageMaker notebook – A bejegyzéshez tartozó összes kód ezen a notebookon keresztül fut.
- OpenSearch szerver nélküli gyűjtemény – Ez a vektoradatbázis a beágyazások tárolására és lekérésére.
- OSI csővezeték – Ez a folyamat az adatok OpenSearch Serverlessbe történő beviteléhez.
- S3 vödör – A bejegyzéshez tartozó összes adat ebben a tárolóban van tárolva.
- SQS várólista – Az OSI-folyamat futtatását kiváltó események ebbe a sorba kerülnek.
A CloudFormation-sablon konfigurálja az OSI-folyamatot Amazon S3 és Amazon SQS feldolgozással forrásként és OpenSearch Serverless indexel fogadóként. A megadott S3 vödörben és előtagban létrehozott objektumok (multimodal/osi-embeddings-json) SQS-értesítéseket indít el, amelyeket az OSI-folyamat arra használ, hogy adatokat töltsön be az OpenSearch Serverlessbe.
A CloudFormation sablon is létrehozza hálózat, titkosításés adat hozzáférés az OpenSearch Serverless gyűjteményhez szükséges házirendek. Frissítse ezeket a házirendeket a legkevesebb jogosultság használatához.
Vegye figyelembe, hogy a CloudFormation sablon nevére hivatkoznak a SageMaker jegyzetfüzetek. Ha az alapértelmezett sablonnév módosul, feltétlenül frissítse a sablonban globals.py
Tesztelje az oldatot
Az előfeltétel lépések végrehajtása és a CloudFormation verem sikeres létrehozása után készen áll a megoldás tesztelésére:
- A SageMaker konzolon válassza a lehetőséget notebookok a navigációs ablaktáblában.
- Válassza ki a
MultimodalNotebookInstancenotebook példány és válassza ki Nyissa meg a JupyterLabot.
- In File Browser, lépjen a notebookok mappába a jegyzetfüzetek és a támogató fájlok megtekintéséhez.
A jegyzetfüzetek a futási sorrendben vannak számozva. Az egyes jegyzetfüzetekben található utasítások és megjegyzések leírják az adott jegyzetfüzet által végrehajtott műveleteket. Ezeket a füzeteket egyenként futtatjuk.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a 0_deploy_llava.ipynb hogy nyissa meg a JupyterLabban.
- A futás menüben válasszon Futtassa az összes cellát a kód futtatásához ebben a notebookban.
Ez a notebook a LLaVA-v1.5-7B modellt telepíti egy SageMaker végpontra. Ebben a jegyzetfüzetben letöltjük a LLaVA-v1.5-7B modellt a HuggingFace Hubról, az inference.py szkriptet lecseréljük a következőre: llava_inference.py, és hozzon létre egy model.tar.gz fájlt ehhez a modellhez. A model.tar.gz fájl feltöltődik az Amazon S3-ba, és a modell SageMaker végponton történő üzembe helyezésére szolgál. A llava_inference.py A szkript további kóddal rendelkezik, amely lehetővé teszi egy képfájl olvasását az Amazon S3-ból, és következtetéseket futtathat rajta.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a 1_data_prep.ipynb hogy nyissa meg a JupyterLabban.
- A futás menüben válasszon Futtassa az összes cellát a kód futtatásához ebben a notebookban.
Ez a notebook letölti a csúszdafedélzet, minden diákat JPG fájlformátumba konvertál, és feltölti az ehhez a bejegyzéshez használt S3 tárolóba.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a 2_data_ingestion.ipynb hogy nyissa meg a JupyterLabban.
- A futás menüben válasszon Futtassa az összes cellát a kód futtatásához ebben a notebookban.
Ebben a füzetben a következőket tesszük:
- Létrehozunk egy indexet az OpenSearch Serverless gyűjteményben. Ez az index a diacsomag beágyazási adatait tárolja. Lásd a következő kódot:
- A Titan Multimodal Embeddings modellt használjuk az előző notebookban készített JPG képek vektoros beágyazásokká alakítására. Ezeket a beágyazásokat és további metaadatokat (például a képfájl S3 elérési útját) a rendszer egy JSON-fájlban tárolja, és feltölti az Amazon S3-ba. Vegye figyelembe, hogy egyetlen JSON-fájl jön létre, amely tartalmazza az összes beágyazássá konvertált diák (kép) dokumentumait. A következő kódrészlet bemutatja, hogy egy kép (Base64 kódolású karakterlánc formájában) hogyan konvertálódik beágyazásokká:
- Ez a művelet elindítja az OpenSearch feldolgozási folyamatot, amely feldolgozza a fájlt, és betölti az OpenSearch Serverless indexbe. A következő egy példa a létrehozott JSON-fájlra. (A példakódban egy négydimenziós vektor látható. A Titan Multimodal Embeddings modell 1,024 dimenziót generál.)
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a 3_rag_inference.ipynb hogy nyissa meg a JupyterLabban.
- A futás menüben válasszon Futtassa az összes cellát a kód futtatásához ebben a notebookban.
Ez a notebook a RAG megoldást valósítja meg: a felhasználói kérdést beágyazásokká alakítjuk, keresünk egy hasonló képet (diát) a vektoros adatbázisból, és a visszakeresett képet továbbítjuk az LLaVA-nak, hogy választ generáljon a felhasználói kérdésre. A következő prompt sablont használjuk:
A következő kódrészlet biztosítja a RAG munkafolyamatot:
Eredmények
Az alábbiakban összeállításunk néhány felhasználói kérdést és válaszokat tartalmaz, amelyeket a megvalósításunk generált. A Kérdés oszlop rögzíti a felhasználói kérdést, és a Válasz oszlop az LLaVA által generált szöveges válasz. Kép az OpenSearch Serverless vektorkeresés által visszaadott, k legközelebbi (k=1) diaegyezés. Ezt a diát az LLaVA értelmezi, hogy megadja a választ.
Multimodális RAG eredmények
| Kérdés | Válasz | Kép |
|---|---|---|
| Hogyan viszonyul az Inf2 teljesítménye a hasonló EC2-példányokhoz? Számokra van szükségem. | A slide deck szerint az AWS Inferentia2 Inf2 példányai akár 4-szer nagyobb átviteli sebességet és 10-szer alacsonyabb késleltetést kínálnak a hasonló EC2 példányokhoz képest. |  |
| Az AI/ML lendkerék szerint mit nyújtanak az AWS AI/ML szolgáltatások? | Az AWS AI/ML szolgáltatások jobb $/perfer képességeket, új képességeket és innovációba való befektetést biztosítanak. | 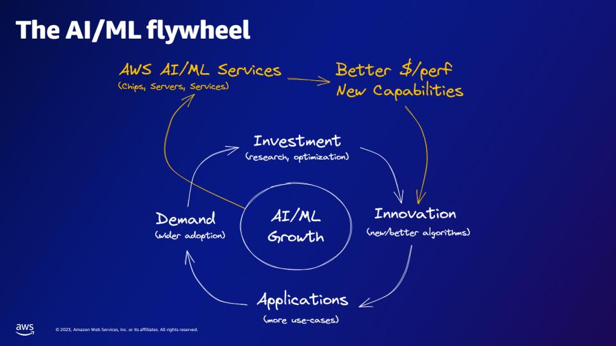 |
| A GPT-2-höz képest mennyivel több paramétere van a GPT-3-nak? Mi a számszerű különbség a GPT-2 és a GPT-3 paramétermérete között? | A dia szerint a GPT-3 175 milliárd, míg a GPT-2 1.5 milliárd paraméterrel rendelkezik. A GPT-2 és a GPT-3 paramétermérete közötti számbeli különbség 173.5 milliárd. | 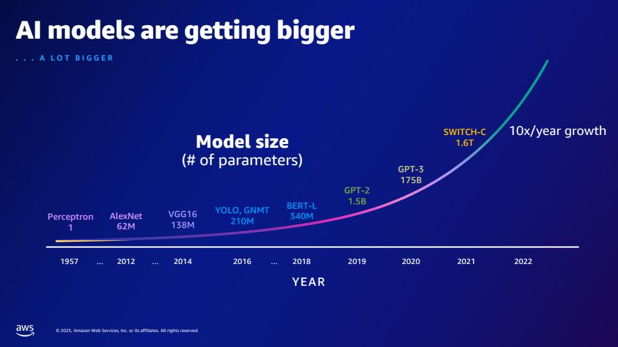 |
| Mik a kvarkok a részecskefizikában? | Erre a kérdésre nem találtam meg a választ a slide deckben. |  |
Nyugodtan terjessze ki ezt a megoldást a csúszdákra. Egyszerűen frissítse a SLIDE_DECK változót a globals.py fájlban a diacsomag URL-jével, és futtassa az előző szakaszban részletezett feldolgozási lépéseket.
típus
Az OpenSearch irányítópultok segítségével interakcióba léphet az OpenSearch API-val, és gyorsteszteket futtathat az indexen és a feldolgozott adatokon. A következő képernyőképen egy OpenSearch irányítópult GET példája látható.
Tisztítsuk meg
A jövőbeni költségek elkerülése érdekében törölje a létrehozott erőforrásokat. Ezt megteheti a verem törlésével a CloudFormation konzolon keresztül.

Ezenkívül törölje az LLaVA-következtetéshez létrehozott SageMaker következtetési végpontot. Ezt úgy teheti meg, hogy törölje a megjegyzést a tisztítási lépésről 3_rag_inference.ipynb és futtassa a cellát, vagy törölje a végpontot a SageMaker konzolon keresztül: válasszon Következtetés és a Végpontok a navigációs ablakban, majd válassza ki a végpontot, és törölje azt.
Következtetés
A vállalatok folyamatosan új tartalmat hoznak létre, és a slide deckek gyakori mechanizmusok az információk megosztására és terjesztésére a szervezeten belül, illetve kívülről az ügyfelekkel vagy konferenciákon. Idővel a gazdag információ eltemetve és rejtve maradhat a nem szöveges modalitásokban, például grafikonokban és táblázatokban ezekben a diacsomagokban. Használhatja ezt a megoldást és a multimodális FM-ek, például a Titan Multimodal Embeddings modell és az LLaVA erejét, hogy új információkat fedezzen fel, vagy új perspektívákat tárjon fel a diapaklikban található tartalommal kapcsolatban.
Javasoljuk, hogy többet tudjon meg felfedezés útján Amazon SageMaker JumpStart, Amazon Titan modellek, az Amazon Bedrock és az OpenSearch Service szolgáltatást, valamint megoldást készítünk az ebben a bejegyzésben található mintamegvalósítással.
Nézze meg két további bejegyzést a sorozat részeként. A 2. rész egy másik megközelítést mutat be, amellyel beszélhet a csúszdával. Ez a megközelítés LLaVA következtetéseket állít elő és tárol, és ezeket a tárolt következtetéseket használja a felhasználói lekérdezések megválaszolására. A 3. rész összehasonlítja a két megközelítést.
A szerzőkről
 Amit Arora az Amazon Web Services mesterséges intelligencia és ML specialistája, aki segít a vállalati ügyfeleknek felhőalapú gépi tanulási szolgáltatások használatában innovációik gyors skálázásához. Emellett adjunktus az MS adattudományi és analitikai programban a Washington DC-i Georgetown Egyetemen.
Amit Arora az Amazon Web Services mesterséges intelligencia és ML specialistája, aki segít a vállalati ügyfeleknek felhőalapú gépi tanulási szolgáltatások használatában innovációik gyors skálázásához. Emellett adjunktus az MS adattudományi és analitikai programban a Washington DC-i Georgetown Egyetemen.
 Manju Prasad az Amazon Web Services stratégiai fiókjainak vezető megoldási építésze. Arra összpontosít, hogy műszaki útmutatást adjon számos területen, beleértve az AI/ML-t is egy sátor M&E ügyfele számára. Mielőtt csatlakozott volna az AWS-hez, megoldásokat tervezett és épített a pénzügyi szolgáltatási szektorban tevékenykedő vállalatok és egy startup számára is.
Manju Prasad az Amazon Web Services stratégiai fiókjainak vezető megoldási építésze. Arra összpontosít, hogy műszaki útmutatást adjon számos területen, beleértve az AI/ML-t is egy sátor M&E ügyfele számára. Mielőtt csatlakozott volna az AWS-hez, megoldásokat tervezett és épített a pénzügyi szolgáltatási szektorban tevékenykedő vállalatok és egy startup számára is.
 Archana Inapudi az AWS vezető megoldástervezője, aki stratégiai ügyfeleket támogat. Több mint egy évtizedes tapasztalattal rendelkezik az ügyfelek adatelemzési és adatbázis-megoldások tervezésében és felépítésében. Szenvedélyesen használja a technológiát, hogy értéket biztosítson az ügyfeleknek és üzleti eredményeket érjen el.
Archana Inapudi az AWS vezető megoldástervezője, aki stratégiai ügyfeleket támogat. Több mint egy évtizedes tapasztalattal rendelkezik az ügyfelek adatelemzési és adatbázis-megoldások tervezésében és felépítésében. Szenvedélyesen használja a technológiát, hogy értéket biztosítson az ügyfeleknek és üzleti eredményeket érjen el.
 Antara Raisa az Amazon Web Services mesterséges intelligenciával és ML megoldásokkal foglalkozó építésze, aki a texasi Dallasból származó stratégiai ügyfeleket támogatja. Korábbi tapasztalata is van nagyvállalati partnerekkel az AWS-nél, ahol a digitális natív ügyfelek partner sikermegoldások építészeként dolgozott.
Antara Raisa az Amazon Web Services mesterséges intelligenciával és ML megoldásokkal foglalkozó építésze, aki a texasi Dallasból származó stratégiai ügyfeleket támogatja. Korábbi tapasztalata is van nagyvállalati partnerekkel az AWS-nél, ahol a digitális natív ügyfelek partner sikermegoldások építészeként dolgozott.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/machine-learning/talk-to-your-slide-deck-using-multimodal-foundation-models-hosted-on-amazon-bedrock-and-amazon-sagemaker-part-1/
- :van
- :is
- :nem
- :ahol
- $ UP
- 1
- 10
- 100
- 13
- 15%
- 16
- 173
- 20
- 2023
- 26
- 29
- 31
- 8
- 9
- a
- Képes
- Rólunk
- hozzáférés
- igénybe vett
- Fiókok
- Elérése
- Akció
- cselekvések
- cselekmények
- hozzá
- További
- adjunktus
- megérkezés
- ellen
- AI
- AI / ML
- Minden termék
- lehetővé
- mentén
- Is
- amazon
- Amazon SageMaker
- Az Amazon Web Services
- an
- analitika
- és a
- Másik
- válasz
- üzenetrögzítő
- válaszok
- bármilyen
- api
- alkalmaz
- megközelítés
- megközelít
- építészet
- VANNAK
- AS
- kérdez
- Helyettes
- társult
- At
- hang-
- bővített
- Auth
- elérhető
- elkerülése érdekében
- AWS
- AWS felhőképződés
- alapján
- BE
- óta
- Jobb
- között
- Billió
- test
- épít
- Épület
- épült
- üzleti
- by
- TUD
- képességek
- képesség
- fogások
- sejt
- megváltozott
- díjak
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a
- választja
- vásárló
- kód
- gyűjtemény
- gyűjtemény
- gyűjtő
- Oszlop
- kombináció
- kombinálása
- Hozzászólások
- Közös
- Companies
- hasonló
- összehasonlítani
- képest
- teljes
- Befejezett
- alkatrészek
- koncepció
- konferenciák
- Configuration
- konfigurálva
- áll
- Konzol
- tartalmaz
- tartalmazott
- tartalmaz
- tartalom
- tartalomalkotás
- megtérít
- átalakított
- konvertáló
- Megfelelő
- tudott
- burkolatok
- teremt
- készítette
- teremt
- létrehozása
- teremtés
- Hitelesítő adatok
- vevő
- Ügyfelek
- Dallas
- műszerfal
- műszerfalak
- dátum
- Adatelemzés
- adat-tudomány
- adatbázis
- évtized
- fedélzet
- alapértelmezett
- szállít
- szállít
- bizonyítani
- attól
- telepíteni
- telepített
- bevezetéséhez
- bevet
- leírni
- Design
- tervezett
- részlet
- részletes
- részletek
- diagram
- DICT
- DID
- különbség
- különböző
- Diffusion
- digitális
- Dimenzió
- méretek
- felfedez
- tárgyalt
- kijelző
- do
- dokumentumok
- nem
- domainek
- letöltés
- letöltések
- alatt
- e
- minden
- elemek
- beágyazott
- beágyazás
- lehetővé
- engedélyezve
- kódolt
- ösztönzése
- végén
- Endpoint
- Motor
- biztosítására
- Vállalkozás
- vállalati ügyfelek
- hiba
- Eter (ETH)
- esemény
- események
- vizsgálva
- példa
- Kivéve
- kivétel
- létezik
- tapasztalat
- Feltárása
- terjed
- külsőleg
- kivonat
- bizalmasság
- Fields
- filé
- Fájlok
- pénzügyi
- pénzügyi szolgáltatások
- Találjon
- koncentrál
- következik
- következő
- következik
- A
- forma
- formátum
- Alapítvány
- négy
- Ingyenes
- ból ből
- Tele
- teljesen
- jövő
- generál
- generált
- generál
- generáció
- nemző
- Generatív AI
- Georgetown
- kap
- GitHub
- megy
- grafikonok
- útmutatást
- Legyen
- he
- hasznos
- segít
- itt
- Rejtett
- <p></p>
- Találat
- vendéglátó
- házigazdája
- tárhely
- hosts
- Hogyan
- azonban
- HTML
- http
- HTTPS
- Kerékagy
- HuggingFace
- i
- IAM
- Identitás
- if
- illusztrálja
- kép
- képek
- azonnal
- végre
- végrehajtás
- munkagépek
- in
- tartalmaz
- magában foglalja a
- Beleértve
- index
- indexek
- információ
- Innováció
- újítások
- bemenet
- példa
- példányok
- utasítás
- kölcsönhatásba
- kölcsönhatás
- belsőleg
- bele
- beruházás
- IT
- csatlakozott
- jpg
- json
- június
- nyelv
- nagy
- Késleltetés
- indít
- TANUL
- tanulás
- előadó
- mint
- LINK
- Láma
- helyi
- alacsonyabb
- gép
- gépi tanulás
- csinál
- kezelése
- sikerült
- sok
- Mérkőzés
- egyező
- mechanizmus
- Menü
- Metaadatok
- módszer
- ML
- modalitások
- modell
- modellek
- több
- a legtöbb
- MS
- többszörös
- név
- bennszülött
- Keresse
- Navigáció
- Szükség
- Új
- Egyik sem
- megjegyezni
- jegyzetfüzet
- laptopok
- értesítések
- Most
- számozott
- számok
- objektumok
- of
- ajánlat
- on
- Igény szerint
- ONE
- csak
- nyitva
- nyílt forráskódú
- or
- szervezet
- OS
- mi
- ki
- eredmények
- teljesítmény
- felett
- üvegtábla
- paraméter
- paraméterek
- rész
- részecske
- partner
- partnerek
- alkatrészek
- Elmúlt
- szenvedélyes
- ösvény
- mert
- teljesít
- teljesítmény
- teljesített
- engedélyek
- perspektívák
- fázis
- Fizika
- képek
- csővezeték
- Plató
- Platón adatintelligencia
- PlatoData
- Politikák
- állás
- Hozzászólások
- potenciálisan
- hatalom
- erős
- Predictor
- be
- bemutatott
- előző
- Előzetes
- folyamat
- feldolgozott
- Folyamatok
- feldolgozás
- Program
- ingatlanait
- ad
- feltéve,
- biztosít
- amely
- tesz
- kvarkok
- lekérdezések
- kérdés
- kérdés
- Kérdések
- Quick
- rongy
- hatótávolság
- gyorsan
- Olvasás
- kész
- való Világ
- kapott
- hivatkozott
- vidék
- összefüggő
- marad
- cserélni
- kérni
- kötelező
- Tudástár
- Reagálni
- válasz
- válaszok
- eredményez
- kapott
- Eredmények
- visszakeresés
- visszatérés
- Gazdag
- szerepek
- futás
- futás
- sagemaker
- SageMaker következtetés
- azonos
- azt mondják
- Skála
- Tudomány
- screenshotok
- forgatókönyv
- Keresés
- Második
- Rész
- szakaszok
- szektor
- lát
- válasszuk
- kiválasztása
- idősebb
- Sorozat
- Series of
- vagy szerver
- szolgálja
- szolgáltatás
- Szolgáltatások
- ülés
- Szettek
- beállítás
- beállítások
- Megosztás
- ő
- kellene
- mutatott
- Műsorok
- hasonló
- Egyszerű
- egyszerűen
- egyetlen
- Méret
- Csúszik
- Diák
- töredék
- So
- megoldások
- Megoldások
- néhány
- forrás
- szakember
- különleges
- meghatározott
- stabil
- verem
- indítás
- Állami
- Állapot
- Lépés
- Lépései
- tárolás
- tárolni
- memorizált
- árnyékolók
- Stratégiai
- Húr
- későbbi
- siker
- sikeresen
- ilyen
- Csúcstalálkozó
- Támogató
- biztos
- táblázat
- Vesz
- Beszél
- feladatok
- Műszaki
- Technológia
- sablon
- sablonok
- teszt
- tesztek
- Texas
- szöveg
- szövegi
- hogy
- A
- az információ
- azok
- akkor
- Ezek
- ezt
- azok
- áteresztőképesség
- idő
- titán-
- címmel
- nak nek
- mai
- együtt
- toronto
- hagyományosan
- áthalad
- kiváltó
- kioldás
- igaz
- megpróbál
- FORDULAT
- kettő
- típus
- feltárni
- megért
- megértés
- egyetemi
- Frissítések
- feltöltve
- URL
- használ
- használt
- használó
- használ
- segítségével
- érték
- változó
- fajta
- változat
- keresztül
- videó
- Megnézem
- látomás
- vizuális
- washington
- módon
- we
- háló
- webes szolgáltatások
- JÓL
- Mit
- Mi
- ami
- míg
- lesz
- val vel
- belül
- dolgozott
- munkafolyamat
- dolgozó
- te
- A te
- zephyrnet