Hasonló oszlopok keresése a adattó fontos alkalmazásai vannak az adattisztításban és annotálásban, a sémaillesztésben, az adatfelderítésben és az elemzésben több adatforráson keresztül. A különböző forrásokból származó adatok pontos megtalálásának és elemzésének képtelensége potenciális hatékonysággyilkos lehet az adattudósoktól, orvoskutatóktól, akadémikusoktól kezdve a pénzügyi és kormányzati elemzőkig mindenki számára.
A hagyományos megoldások közé tartozik a lexikális kulcsszókeresés vagy a reguláris kifejezés-egyeztetés, amelyek érzékenyek az olyan adatminőségi problémákra, mint például a hiányzó oszlopnevek vagy az eltérő oszlopelnevezési konvenciók a különböző adatkészletekben (például zip_code, zcode, postalcode).
Ebben a bejegyzésben egy megoldást mutatunk be hasonló oszlopok keresésére az oszlop neve, az oszlop tartalma vagy mindkettő alapján. A megoldás használ hozzávetőleges legközelebbi szomszédok algoritmusai elérhető Amazon OpenSearch szolgáltatás szemantikailag hasonló oszlopok kereséséhez. A keresés megkönnyítése érdekében az adattó egyes oszlopaihoz jellemző reprezentációkat (beágyazásokat) hozunk létre az előre betanított Transformer modellek segítségével. mondatátalakítók könyvtára in Amazon SageMaker. Végül a megoldásunkkal való interakcióhoz és annak eredményeinek megjelenítéséhez interaktívat építünk Áramlatos futó webalkalmazás AWS Fargate.
Tartalmazzuk a kód oktatóanyag hogy telepítse az erőforrásokat a megoldás mintaadatokon vagy saját adatain történő futtatásához.
Megoldás áttekintése
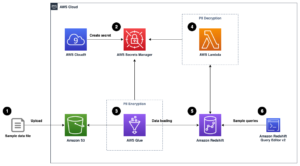
A következő architektúra diagram szemantikailag hasonló oszlopok keresésének kétlépcsős munkafolyamatát szemlélteti. Az első szakasz egy AWS lépésfunkciók munkafolyamat, amely táblázatos oszlopokból beágyazásokat hoz létre, és létrehozza az OpenSearch Service keresési indexét. A második szakasz vagy az online következtetési szakasz egy Streamlit alkalmazást futtat a Fargate-en keresztül. A webalkalmazás összegyűjti a bemeneti keresési lekérdezéseket, és lekéri az OpenSearch Service indexéből a hozzávetőlegesen k-leghasonlóbb oszlopot a lekérdezéshez.

1. ábra Megoldás architektúra
Az automatizált munkafolyamat a következő lépésekben zajlik:
- A felhasználó táblázatos adatkészleteket tölt fel egy Amazon egyszerű tárolási szolgáltatás (Amazon S3) vödör, amely meghív egy AWS Lambda funkció, amely elindítja a Step Functions munkafolyamatot.
- A munkafolyamat egy AWS ragasztó feladat, amely átalakítja a CSV-fájlokat Apache parketta adatformátum.
- A SageMaker feldolgozási feladat minden oszlophoz beágyazásokat hoz létre előre betanított modellek vagy egyéni oszlopbeágyazási modellek segítségével. A SageMaker Processing feladat elmenti az oszlopbeágyazásokat az Amazon S3 minden egyes táblájához.
- Egy Lambda-függvény létrehozza az OpenSearch szolgáltatási tartományt és fürtöt az előző lépésben előállított oszlopbeágyazások indexeléséhez.
- Végül egy interaktív Streamlit webalkalmazás kerül bevezetésre a Fargate-tel. A webalkalmazás felületet biztosít a felhasználó számára, amellyel lekérdezéseket adhat meg, és hasonló oszlopokat kereshet az OpenSearch Service tartományában.
A kód oktatóanyagát innen töltheti le GitHub hogy kipróbálja ezt a megoldást mintaadatokon vagy saját adatain. Az oktatóanyaghoz szükséges erőforrások telepítésével kapcsolatos utasítások itt érhetők el GitHub.
Előfeltételek
A megoldás megvalósításához a következőkre van szüksége:
- An AWS-fiók.
- Alapvető ismeretek az AWS szolgáltatásokról, mint pl AWS Cloud Development Kit (AWS CDK), Lambda, OpenSearch Service és SageMaker Processing.
- Táblázatos adatkészlet a keresési index létrehozásához. Meghozhatja saját táblázatos adatait, vagy letöltheti a mintaadatkészleteket GitHub.
Készítsen keresési indexet
Az első lépésben az oszlop keresőmotor indexe épül fel. A következő ábra az ezt a szakaszt futtató Step Functions munkafolyamatot mutatja be.

2. ábra – Lépésfüggvények munkafolyamata – több beágyazási modell
Datasets
Ebben a bejegyzésben egy keresési indexet építünk fel, amely több mint 400 oszlopot tartalmazhat több mint 25 táblázatos adatkészletből. Az adatkészletek a következő nyilvános forrásokból származnak:
Az indexben szereplő táblázatok teljes listáját lásd a kód oktatóanyagában GitHub.
Saját táblázatos adatkészlettel bővítheti a mintaadatokat, vagy létrehozhatja saját keresési indexét. Tartalmazunk két Lambda-függvényt, amelyek elindítják a Step Functions munkafolyamatot az egyes CSV-fájlok vagy egy köteg CSV-fájlok keresési indexének felépítéséhez.
Alakítsa át a CSV-t parkettává
A nyers CSV-fájlokat az AWS ragasztóval parketta adatformátumba konvertálják. A Parquet egy oszloporientált formátumú fájlformátum, amelyet a nagy adatelemzésben részesítenek előnyben, és amely hatékony tömörítést és kódolást biztosít. Kísérleteink során a Parquet adatformátum jelentősen csökkentette a tárolási méretet a nyers CSV-fájlokhoz képest. A Parquet-et más adatformátumok (például JSON és NDJSON) konvertálására is használtuk, mivel támogatja a fejlett beágyazott adatstruktúrákat.
Hozzon létre táblázatos oszlopbeágyazásokat
Az egyes táblázatoszlopok beágyazásainak kinyeréséhez ebben a bejegyzésben a táblázatos mintaadatkészletekben a következő előre betanított modelleket használjuk a sentence-transformers könyvtár. További modellekért lásd Előképzett modellek.
A SageMaker Processing job fut create_embeddings.py(kód) egyetlen modellhez. A beágyazások több modellből történő kibontásához a munkafolyamat párhuzamos SageMaker feldolgozási feladatokat futtat, amint az a Step Functions munkafolyamatban látható. A modellt két beágyazási készlet létrehozására használjuk:
- oszlop_név_beágyazások – Oszlopnevek (fejlécek) beágyazása
- oszlop_tartalom_beágyazásai – Az oszlop összes sorának átlagos beágyazása
Az oszlopbeágyazási folyamattal kapcsolatos további információkért tekintse meg a kód oktatóanyagát GitHub.
A SageMaker feldolgozási lépés alternatívája egy SageMaker kötegelt transzformáció létrehozása, hogy oszlopbeágyazásokat kapjon nagy adatkészleteken. Ehhez a modellt egy SageMaker végpontra kell telepíteni. További információkért lásd Kötegelt transzformáció használata.
Beágyazások indexelése az OpenSearch szolgáltatással
Ennek a szakasznak az utolsó lépésében egy Lambda függvény hozzáadja az oszlop beágyazásait egy OpenSearch Service hozzávetőleges k-közelebbi szomszédhoz (kNN) keresési index. Minden modellhez saját keresési index tartozik. A hozzávetőleges kNN keresési index paramétereivel kapcsolatos további információkért lásd: k-NN.
Online következtetés és szemantikai keresés webalkalmazással
A munkafolyamat második szakasza a Áramlatos webalkalmazás, ahol bemeneteket adhat meg, és szemantikailag hasonló, az OpenSearch szolgáltatásban indexelt oszlopokat kereshet. Az alkalmazási réteg egy Alkalmazás terheléselosztó, Fargate és Lambda. Az alkalmazási infrastruktúra automatikusan telepítésre kerül a megoldás részeként.
Az alkalmazás lehetővé teszi bevitel megadását és szemantikailag hasonló oszlopnevek, oszloptartalom vagy mindkettő keresését. Ezenkívül kiválaszthatja a beágyazás modelljét és a keresésből visszatérni kívánt legközelebbi szomszédok számát. Az alkalmazás fogad bemeneteket, beágyazza a bemenetet a megadott modellbe, és használja kNN keresés az OpenSearch szolgáltatásban indexelt oszlopbeágyazások kereséséhez és az adott bemenethez leginkább hasonló oszlopok megtalálásához. A megjelenített keresési eredmények tartalmazzák a táblázatok neveit, oszlopneveit és az azonosított oszlopok hasonlósági pontszámait, valamint az Amazon S3-ban található adatok helyét a további feltáráshoz.
A következő ábra a webalkalmazásra mutat példát. Ebben a példában olyan oszlopokat kerestünk az adattóban, amelyek hasonlóak Column Names (hasznos teher típusa) A district (hasznos teher). A használt alkalmazás all-MiniLM-L6-v2 mint a beágyazó modell és visszatért 10 (k) a legközelebbi szomszédok az OpenSearch Service indexünkből.
A pályázat visszakerült transit_district, city, boroughés location mint a négy leginkább hasonló oszlop az OpenSearch szolgáltatásban indexelt adatok alapján. Ez a példa bemutatja a keresési megközelítés azon képességét, hogy szemantikailag hasonló oszlopokat azonosítson az adatkészletekben.

3. ábra: Webalkalmazás felhasználói felület
Tisztítsuk meg
Az oktatóanyagban az AWS CDK által létrehozott erőforrások törléséhez futtassa a következő parancsot:
cdk destroy --allKövetkeztetés
Ebben a bejegyzésben bemutattunk egy teljes munkafolyamatot a táblázatos oszlopok szemantikus keresőjének felépítéséhez.
Kezdje el még ma saját adataival a következő címen elérhető kódoktatóanyagunk segítségével GitHub. Ha segítségre van szüksége az ML használatának felgyorsításához termékeiben és folyamataiban, kérjük, forduljon a Amazon Machine Learning Solutions Lab.
A szerzőkről
![]() Kachi Odoemene az AWS AI alkalmazott tudósa. AI/ML megoldásokat épít az AWS ügyfelek üzleti problémáinak megoldására.
Kachi Odoemene az AWS AI alkalmazott tudósa. AI/ML megoldásokat épít az AWS ügyfelek üzleti problémáinak megoldására.
![]() Taylor McNally az Amazon Machine Learning Solutions Lab Deep Learning Architect-je. Különböző iparágak ügyfeleit segíti olyan megoldások kidolgozásában, amelyek az AI/ML-t AWS-re használják. Szeret egy csésze kávét, a szabadban, és a családjával és az energikus kutyájával eltöltött időt.
Taylor McNally az Amazon Machine Learning Solutions Lab Deep Learning Architect-je. Különböző iparágak ügyfeleit segíti olyan megoldások kidolgozásában, amelyek az AI/ML-t AWS-re használják. Szeret egy csésze kávét, a szabadban, és a családjával és az energikus kutyájával eltöltött időt.
![]() Austin Welch az Amazon ML Solutions Lab adatkutatója. Egyedi mély tanulási modelleket fejleszt, hogy segítse az AWS közszektorbeli ügyfeleit az AI és a felhő alkalmazásának felgyorsításában. Szabadidejében szeret olvasni, utazni és a jiu-jitsut szereti.
Austin Welch az Amazon ML Solutions Lab adatkutatója. Egyedi mély tanulási modelleket fejleszt, hogy segítse az AWS közszektorbeli ügyfeleit az AI és a felhő alkalmazásának felgyorsításában. Szabadidejében szeret olvasni, utazni és a jiu-jitsut szereti.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- képesség
- Rólunk
- hiányzó
- gyorsul
- gyorsuló
- pontosan
- át
- További
- Ezen kívül
- Hozzáteszi
- Örökbefogadás
- fejlett
- AI
- AI / ML
- Minden termék
- lehetővé teszi, hogy
- alternatív
- amazon
- Amazon gépi tanulás
- Amazon ML Solutions Lab
- Az elemzők
- analitika
- elemez
- és a
- Apache
- Alkalmazás
- alkalmazások
- alkalmazott
- megközelítés
- építészet
- kijelölt
- Automatizált
- automatikusan
- elérhető
- átlagos
- AWS
- AWS ragasztó
- alapján
- mert
- Nagy
- Big adatok
- hoz
- épít
- Épület
- épít
- üzleti
- Takarításra
- felhő
- felhő elfogadása
- Fürt
- kód
- Kávé
- összegyűjti
- Oszlop
- Oszlopok
- Közös
- képest
- kapcsolat
- tartalom
- egyezmények
- megtérít
- átalakított
- teremt
- készítette
- teremt
- Csésze
- szokás
- Ügyfelek
- dátum
- Adatelemzés
- adattó
- adatminőség
- adattudós
- adatkészletek
- mély
- mély tanulás
- bizonyítani
- mutatja
- telepíteni
- telepített
- bevezetéséhez
- elpusztítani
- Fejlesztés
- fejleszt
- különböző
- felfedezés
- eltérő
- számos
- Kutya
- domain
- letöltés
- minden
- hatékonyság
- hatékony
- végtől végig
- Endpoint
- Motor
- Eter (ETH)
- mindenki
- példa
- kutatás
- kivonat
- megkönnyítése
- bizalmasság
- család
- Jellemzők
- Ábra
- filé
- Fájlok
- utolsó
- Végül
- pénzügyi
- Találjon
- megtalálása
- vezetéknév
- következő
- formátum
- ból ből
- Tele
- funkció
- funkciók
- további
- kap
- adott
- jó
- Kormány
- fejlécek
- segít
- segít
- Hogyan
- How To
- HTML
- HTTPS
- azonosított
- azonosítani
- végre
- fontos
- in
- képtelenség
- tartalmaz
- beleértve
- index
- egyéni
- iparágak
- információ
- Infrastruktúra
- kezdeményez
- beavatottak
- bemenet
- utasítás
- kölcsönhatásba
- interaktív
- Felület
- behívja
- vonja
- kérdések
- IT
- Munka
- Állások
- json
- labor
- tó
- nagy
- réteg
- tanulás
- erőfölény
- könyvtár
- Lista
- kiszámításának
- helyszínek
- gép
- gépi tanulás
- egyező
- orvosi
- ML
- modell
- modellek
- több
- a legtöbb
- többszörös
- név
- nevek
- elnevezési
- Szükség
- szomszédok
- szám
- felajánlott
- online
- Más
- szabadban
- saját
- Párhuzamos
- paraméterek
- rész
- Plató
- Platón adatintelligencia
- PlatoData
- kérem
- állás
- potenciális
- előnyben részesített
- bemutatott
- előző
- problémák
- bevétel
- folyamat
- Folyamatok
- feldolgozás
- Készült
- Termékek
- ad
- biztosít
- nyilvános
- világítás
- Nyers
- Olvasás
- kap
- szabályos
- jelentése
- szükség
- kötelező
- kutatók
- Tudástár
- illetőleg
- Eredmények
- visszatérés
- futás
- futás
- sagemaker
- Tudós
- tudósok
- Keresés
- kereső
- keres
- Második
- szektor
- szolgáltatás
- Szolgáltatások
- Szettek
- mutatott
- Műsorok
- jelentős
- hasonló
- Egyszerű
- egyetlen
- Méret
- megoldások
- Megoldások
- SOLVE
- Források
- meghatározott
- Színpad
- kezdődött
- Lépés
- Lépései
- tárolás
- ilyen
- Támogatja
- fogékony
- táblázat
- A
- azok
- Keresztül
- idő
- nak nek
- Ma
- Átalakítás
- transzformerek
- Utazó
- oktatói
- használ
- használó
- felhasználói felület
- különféle
- háló
- webalkalmazás
- ami
- munkafolyamat
- lenne
- A te
- zephyrnet