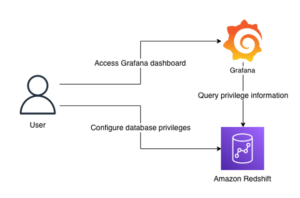
Amazon Athéné egy interaktív lekérdező szolgáltatás, amely megkönnyíti az adatok elemzését Amazon egyszerű tárolási szolgáltatás (Amazon S3) és az AWS-ben, helyszíni vagy más, SQL-t vagy Pythont használó felhőrendszerekben található adatforrások. Az Athena nyílt forráskódú Trino és Presto motorokra, valamint Apache Spark keretrendszerekre épül, nincs szükség hozzárendelésre vagy konfigurációra. Az Athena szerver nélküli, így nincs kezelhető infrastruktúra, és csak a futtatott lekérdezésekért kell fizetni.
Apache jéghegy egy nyílt táblázatformátum nagyon nagy analitikai adatkészletekhez. Táblázatként kezeli a fájl nagy gyűjteményét, és támogatja a modern analitikai adattó-műveleteket, például rekordszintű beszúrási, frissítési, törlési és időutazási lekérdezéseket. Az Athena támogatja az olvasási, időutazási, írási és DDL-lekérdezéseket az Apache Iceberg táblákhoz, amelyek az Apache Parquet formátumot használják az adatokhoz és a AWS ragasztóadat-katalógus metaboltjuk számára.
Funkciótervezés A nyers adatok (képek, szöveges fájlok, videók stb.) azonosításának és átalakításának folyamata, a hiányzó adatok háttérkitöltése, valamint egy vagy több értelmes adatelem hozzáadása kontextus biztosításához, hogy a gépi tanulási (ML) modell tanulhasson belőlük. Az adatcímkézés különféle felhasználási esetekben szükséges, beleértve az előrejelzést, a számítógépes látást, a természetes nyelvi feldolgozást és a beszédfelismerést.
Az Athena képességeivel kombinálva az Apache Iceberg leegyszerűsített munkafolyamatot biztosít az adattudósok számára új adatszolgáltatások létrehozásához anélkül, hogy a teljes adatkészletet másolni vagy újra létrehozni kellene. Létrehozhat szolgáltatásokat az Athena szabványos SQL használatával anélkül, hogy bármilyen más szolgáltatást használna a funkciótervezéshez. Az adattudósok csökkenthetik az adatkészletek előkészítésére és másolására fordított időt, és ehelyett az adatelemzésre, a kísérletezésre és az adatok nagyarányú elemzésére összpontosíthatnak.
Ebben a bejegyzésben áttekintjük az Athena és az Apache Iceberg nyílt táblázat formátum előnyeit, és azt, hogy miként egyszerűsíti le az adattudósok általános jellemzőinek tervezési feladatait. Bemutatjuk, hogyan tud az Athena átalakítani egy meglévő táblát Apache Iceberg formátumban, majd hozzáadni oszlopokat, törölni oszlopokat és módosítani a táblázatban lévő adatokat anélkül, hogy újra létrehozná vagy másolná az adatkészletet, és hogyan használhatja ezeket a lehetőségeket új szolgáltatások létrehozására az Apache Iceberg táblákon.
Megoldás áttekintése
Az adattudósok általában hozzászoktak ahhoz, hogy nagy adatkészletekkel dolgozzanak. Az adatkészleteket általában JSON, CSV, ORC vagy formátumban tárolják Apache parketta formátum, vagy hasonló, olvasásra optimalizált formátumok a gyors olvasási teljesítmény érdekében. Az adattudósok gyakran hoznak létre új adatszolgáltatásokat, és ezeket az adatszolgáltatásokat összesített és kiegészítő adatokkal töltik ki. Korábban ezt a feladatot úgy hajtották végre, hogy a táblázat tetején egy nézetet hoztak létre az alapul szolgáló adatokkal Apache Parquet formátumban, ahol az ilyen oszlopok és adatok futás közben kerültek hozzáadásra, vagy egy új táblázat létrehozása további oszlopokkal. Bár ez a munkafolyamat sok felhasználási esetre jól használható, nagy adatkészletek esetén nem hatékony, mivel az adatokat futás közben kell előállítani, vagy az adatkészleteket másolni és átalakítani.
Athena bemutatkozott ACID (atomosság, konzisztencia, izoláció, tartósság) tranzakció olyan képességek, amelyek hozzáadják az INSERT, UPDATE, DELETE, MERGE és időutazási műveleteket Apache Iceberg asztalok. Ezek a képességek lehetővé teszik az adattudósok számára, hogy új adatszolgáltatásokat hozzanak létre, és meglévő adatszolgáltatásokat helyezzenek el a meglévő adatkészleteken anélkül, hogy aggódniuk kellene az adatkészlet másolása, átalakítása vagy egy nézetből való absztrahálása miatt. Az adattudósok a funkciótervezési munkára összpontosíthatnak, és elkerülhetik az adatkészletek másolását és átalakítását.
Az Athena Iceberg UPDATE művelet az Apache Iceberg pozíciótörlési fájlokat és az újonnan frissített sorokat adatfájlként írja ugyanabban a tranzakcióban. A rekordjavításokat egyetlen UPDATE utasítással végezheti el.
Az Athena motor 3-as verziójának kiadásával az Apache Iceberg táblák képességei olyan műveletek támogatásával bővültek, mint pl. TÁBLÁZAT LÉTREHOZÁSA KIVÁLASZTÁSKÉNT (CTAS) és MERGE parancsok, amelyek leegyszerűsítik az Iceberg-adatok életciklus-kezelését. A CTAS segítségével gyorsan és hatékonyan készíthet táblázatokat más formátumokból, például Apache Paquetből és BEVEZETÉS feltételes frissítések, törlések vagy sorok beszúrása egy Iceberg táblába. Egyetlen utasítás kombinálhatja a frissítési, törlési és beszúrási műveleteket.
Előfeltételek
Hozzon létre egy Athena-munkacsoportot az Athena motor 3-as verziójával, hogy CTAS és MERGE parancsokat használhasson Apache Iceberg táblával. Ha meglévő Athena-motorját 3-as verzióra szeretné frissíteni az Athena-munkacsoportban, kövesse az alábbi utasításokat Frissítsen az Athena motor 3-as verziójára, hogy növelje a lekérdezési teljesítményt és hozzáférjen több elemzési funkcióhoz vagy hivatkozni Motorverzió módosítása az Athena konzolban.
adatbázisba
A demonstrációhoz egy Apache Parquet táblát használunk, amely több millió rekordot tartalmaz véletlenszerűen elosztott fiktív eladási adatokról az elmúlt néhány évből, amelyeket egy S3 vödörben tároltak. Letöltés az adatkészletet, csomagolja ki a helyi számítógépére, és töltse fel az S3 tárolójába. Ebben a bejegyzésben feltöltöttük adatkészletünket ide s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/.
A következő táblázat a táblázat elrendezését mutatja be customer_orders.
| Oszlop neve | Adattípus | Leírás |
| rendeléskulcs | húr | Rendelési szám a rendeléshez |
| custkey | húr | Ügyfélazonosító szám |
| rendelés állapota | húr | A megrendelés állapota |
| teljes ár | húr | A megrendelés teljes ára |
| rendelés dátuma | húr | A megrendelés dátuma |
| elsőbbségi sorrend | húr | A megrendelés elsőbbsége |
| hivatalnok | húr | A rendelést feldolgozó ügyintéző neve |
| szállítási prioritás | húr | Elsőbbség a szállításnál |
| név | húr | Ügyfél neve |
| cím | húr | Ügyfél címe |
| nemzetkulcs | húr | Ügyfél nemzet kulcsa |
| telefon | húr | Ügyfél telefonszáma |
| acctbal | húr | Ügyfélszámla egyenlege |
| mktsegment | húr | Ügyfélpiaci szegmens |
Hajtsa végre a funkciótervezést
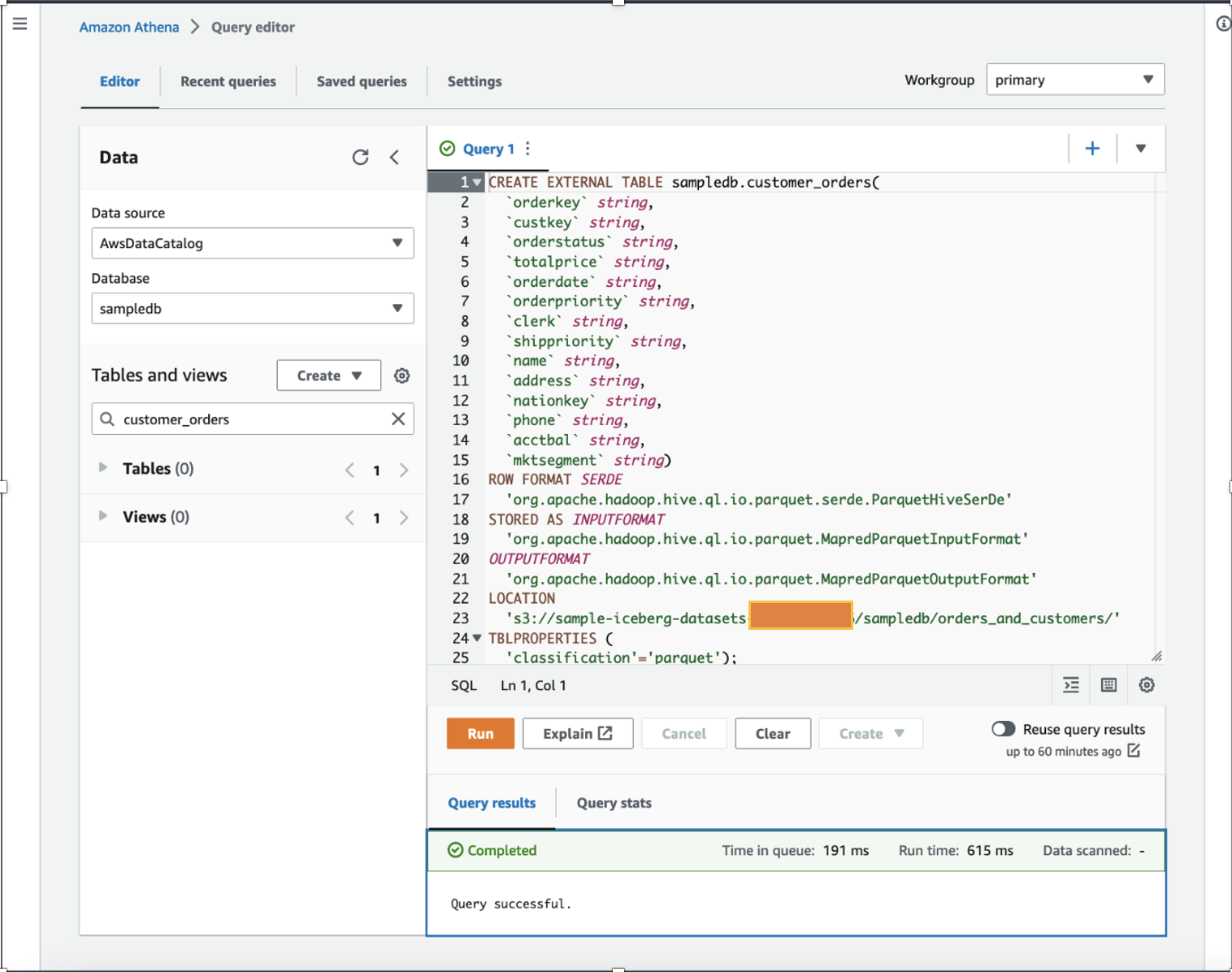
Adattudósként teljesíteni szeretnénk jellemző tervezés a vevői rendelések adataira úgy, hogy a meglévő adatkészletben minden egyes vásárlóhoz hozzáadjuk a számított egy éves összes vásárlást és egy éves átlagos vásárlást. Bemutató céllal hoztuk létre a customer_orders táblázat a sampledb adatbázist az Athena használatával, ahogy az a következő DDL-parancsban látható. (Használhatja bármelyik meglévő adatkészletét, és kövesse az ebben a bejegyzésben említett lépéseket.) A customer_orders adatkészletet generált és tárolt az S3 vödör helyén s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/ parketta formátumban. Ez az asztal nem egy Apache Iceberg asztal.
![]()
Érvényesítse a táblázat adatait egy lekérdezés futtatásával:
![]()
Új funkciókkal szeretnénk kiegészíteni ezt a táblázatot, hogy jobban megértsük az ügyfelek értékesítését, ami gyorsabb modellképzést és értékesebb betekintést eredményezhet. Ha új funkciókat szeretne hozzáadni az adatkészlethez, konvertálja a customer_orders Athena asztal az Apache Iceberg asztalhoz az Athénén. Kiadás a CTAS lekérdezés utasítással új tábla létrehozásához Apache Iceberg formátumban a customer_orders asztal. Ennek során egy új funkcióval egészül ki, amellyel minden vásárló lekéri a teljes vásárlás összegét az elmúlt évben (maximum az adatkészlet évében).
A következő CTAS-lekérdezésben egy új oszlop neve one_year_sales_aggregate az alapértelmezett értékkel mint 0.0 adattípusból double hozzáadódik és table_type be van állítva ICEBERG:
![]()
Adja ki a következő lekérdezést az Apache Iceberg tábla adatainak az új oszloppal történő ellenőrzéséhez one_year_sales_aggregate értékek mint 0.0:
![]()
Szeretnénk feltölteni az új funkció értékeit one_year_sales_aggregate az adatkészletben, hogy megkapja az egyes vásárlók teljes vásárlási összegét az elmúlt év vásárlásai alapján (az adatkészlet max. éve). Adjon ki egy MERGE lekérdezési utasítást az Apache Iceberg táblának az Athena használatával a one_year_sales_aggregate funkció:
![]()
Adja ki a következő lekérdezést az egyes ügyfelek elmúlt évi összköltésének frissített értékének érvényesítéséhez:
![]()
Úgy döntünk, hogy hozzáadunk egy másik funkciót egy meglévő Apache Iceberg táblához, hogy kiszámítsuk és tároljuk az egyes ügyfelek átlagos vásárlási összegét az elmúlt évben. Adjon ki egy ALTER lekérdezési utasítást, hogy új oszlopot adjon a szolgáltatás meglévő táblájához one_year_sales_average:
![]()
Az új szolgáltatás értékeinek feltöltése előtt beállíthatja a szolgáltatás alapértelmezett értékét one_year_sales_average nak nek 0.0. Ugyanazt az Apache Iceberg táblát használva az Athenában, adjon ki egy UPDATE lekérdezési utasítást az új szolgáltatás értékének kitöltéséhez 0.0:
![]()
Adja ki a következő lekérdezést annak ellenőrzésére, hogy az egyes ügyfelek átlagos költésének frissített értéke az elmúlt évben a következőre van állítva: 0.0:
![]()
Most szeretnénk feltölteni az új funkció értékeit one_year_sales_average az adatkészletben, hogy megkapja az egyes ügyfelek átlagos vásárlási összegét az elmúlt év vásárlásai alapján (max az adatkészlet éve). Adjon ki egy MERGE lekérdezési utasítást az Athena meglévő Apache Iceberg táblájához az Athena motor használatával a szolgáltatás értékeinek feltöltéséhez one_year_sales_average:
![]()
Adja ki a következő lekérdezést az egyes ügyfelek átlagos költésének frissített értékeinek ellenőrzéséhez:
![]()
Miután további adatszolgáltatásokat adtak az adatkészlethez, az adatkutatók általában folytatják az ML modellek betanítását, és következtetéseket vonnak le az Amazon Sagemaker vagy azzal egyenértékű eszközkészlet segítségével.
Következtetés
Ebben a bejegyzésben bemutattuk, hogyan hajthatunk végre funkciótervezést az Athena és az Apache Iceberg segítségével. Azt is bemutattuk a CTAS lekérdezés használatával, hogy Apache Iceberg táblát hozzunk létre Athena rendszeren egy meglévő adatkészletből Apache Parquet formátumban, új funkciókat adjunk hozzá egy meglévő Apache Iceberg táblához az Athena rendszeren az ALTER lekérdezéssel, valamint az UPDATE és MERGE lekérdezési utasítások használatával frissítsük a meglévő oszlopok jellemző értékei.
Javasoljuk, hogy CTAS-lekérdezéseket használjon a táblák gyors és hatékony létrehozásához, és használja a MERGE lekérdezési utasítást a táblák egy lépésben történő szinkronizálására, hogy egyszerűsítse az adat-előkészítést és a frissítési feladatokat, amikor a szolgáltatásokat az Athena és az Apache Iceberg segítségével átalakítja. Ha észrevétele vagy visszajelzése van, kérjük, hagyja azokat a megjegyzés rovatban.
A szerzőkről
![]() Vivek Gautam Data Architect, az AWS Professional Services adattóira szakosodott. Vállalati ügyfelekkel dolgozik, akik adattermékeket, elemzési platformokat és megoldásokat építenek az AWS-re. Amikor nem modern adatplatformokat építünk és tervezünk, Vivek az ételek rajongója, aki szeret új úti célokat felfedezni és kirándulni.
Vivek Gautam Data Architect, az AWS Professional Services adattóira szakosodott. Vállalati ügyfelekkel dolgozik, akik adattermékeket, elemzési platformokat és megoldásokat építenek az AWS-re. Amikor nem modern adatplatformokat építünk és tervezünk, Vivek az ételek rajongója, aki szeret új úti célokat felfedezni és kirándulni.
![]() Mihail Vaynshteyn az Amazon Web Services megoldástervezője. Mikhail egészségügyi és élettudományi ügyfelekkel dolgozik azon megoldások kidolgozásán, amelyek javítják a betegek kimenetelét. Mikhail adatelemzési szolgáltatásokra specializálódott.
Mihail Vaynshteyn az Amazon Web Services megoldástervezője. Mikhail egészségügyi és élettudományi ügyfelekkel dolgozik azon megoldások kidolgozásán, amelyek javítják a betegek kimenetelét. Mikhail adatelemzési szolgáltatásokra specializálódott.
![]() Naresh Gautam az AWS Data Analytics és AI/ML vezetője 20 éves tapasztalattal, aki szívesen segít ügyfeleinek magas rendelkezésre állású, nagy teljesítményű és költséghatékony adatelemzési és AI/ML megoldások kialakításában, hogy az ügyfeleket adatvezérelt döntéshozatalban részesítse. . Szabadidejében szívesen meditál és főz.
Naresh Gautam az AWS Data Analytics és AI/ML vezetője 20 éves tapasztalattal, aki szívesen segít ügyfeleinek magas rendelkezésre állású, nagy teljesítményű és költséghatékony adatelemzési és AI/ML megoldások kialakításában, hogy az ügyfeleket adatvezérelt döntéshozatalban részesítse. . Szabadidejében szívesen meditál és főz.
![]() Harsha Tadiparthi az AWS fő megoldási építészének szakértője. Szeret összetett ügyfélproblémák megoldásában adatbázisokban és elemzésekben, és sikeres eredményeket ér el. Munkán kívül szeret a családjával tölteni az idejét, filmeket nézni, és lehetőség szerint utazni.
Harsha Tadiparthi az AWS fő megoldási építészének szakértője. Szeret összetett ügyfélproblémák megoldásában adatbázisokban és elemzésekben, és sikeres eredményeket ér el. Munkán kívül szeret a családjával tölteni az idejét, filmeket nézni, és lehetőség szerint utazni.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- EVM Finance. Egységes felület a decentralizált pénzügyekhez. Hozzáférés itt.
- Quantum Media Group. IR/PR erősített. Hozzáférés itt.
- PlatoAiStream. Web3 adatintelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/big-data/accelerate-data-science-feature-engineering-on-transactional-data-lakes-using-amazon-athena-with-apache-iceberg/
- :van
- :is
- :nem
- :ahol
- $ UP
- 10
- 100
- 12
- 17
- 20
- 20 év
- 23
- 27
- 7
- a
- Rólunk
- gyorsul
- hozzáférés
- megvalósítható
- Fiók
- cselekvések
- hozzá
- hozzáadott
- hozzáadásával
- További
- cím
- AI / ML
- Is
- Bár
- amazon
- Amazon Athéné
- Amazon SageMaker
- Az Amazon Web Services
- összeg
- an
- Analitikus
- Analitikai
- analitika
- elemez
- elemzése
- és a
- Másik
- bármilyen
- Apache
- Apache Spark
- VANNAK
- AS
- At
- elérhető
- átlagos
- elkerülése érdekében
- AWS
- AWS professzionális szolgáltatások
- alapján
- BE
- mert
- óta
- Előnyök
- épít
- Épület
- épült
- by
- számított
- TUD
- képességek
- esetek
- besorolás
- felhő
- gyűjtemény
- Oszlop
- Oszlopok
- össze
- Hozzászólások
- Közös
- bonyolult
- Kiszámít
- számítógép
- Számítógépes látás
- Configuration
- tartalmaz
- kontextus
- megtérít
- főzés
- másolás
- Hiba
- költséghatékony
- teremt
- készítette
- létrehozása
- vevő
- Ügyfelek
- dátum
- Adatelemzés
- adattó
- adat-tudomány
- adattudós
- adatalapú
- adatbázis
- adatbázisok
- adatkészletek
- találka
- dönt
- Döntéshozatal
- mélyebb
- alapértelmezett
- átadó
- szállít
- bizonyítani
- igazolták
- tervezés
- úticél
- megosztott
- Ennek
- kétszeresére
- Csepp
- tartósság
- minden
- könnyű
- hatékony
- eredményesen
- erőfeszítés
- bármelyik
- elemek
- képessé
- lehetővé
- ösztönzése
- Motor
- Mérnöki
- Motorok
- fokozott
- Vállalkozás
- vállalati ügyfelek
- rajongó
- Egész
- Egyenértékű
- Eter (ETH)
- létező
- tapasztalat
- feltárása
- külső
- hamis
- család
- GYORS
- gyorsabb
- Funkció
- Jellemzők
- Visszacsatolás
- Fájlok
- Összpontosít
- következik
- következő
- élelmiszer
- A
- formátum
- keretek
- Ingyenes
- ból ből
- általában
- generált
- kap
- Go
- Csoport
- Hadoop
- Legyen
- he
- egészségügyi
- segít
- segít
- nagy teljesítményű
- nagyon
- Kirándulások
- övé
- történelmileg
- Kaptár
- Hogyan
- How To
- HTML
- HTTPS
- Azonosítás
- azonosító
- if
- képek
- javul
- in
- Beleértve
- Növelje
- nem hatékony
- Infrastruktúra
- Betétek
- meglátások
- helyette
- utasítás
- interaktív
- bele
- Bevezetett
- szigetelés
- kérdés
- IT
- jpg
- json
- címkézés
- tó
- nyelv
- nagy
- keresztnév
- elrendezés
- vezető
- TANUL
- tanulás
- Szabadság
- élet
- Life Sciences
- életciklus
- LIMIT
- helyi
- elhelyezkedés
- szeret
- gép
- gépi tanulás
- csinál
- KÉSZÍT
- kezelése
- vezetés
- kezeli
- sok
- piacára
- párosított
- max
- jelentőségteljes
- Elmélkedés
- említett
- megy
- millió
- hiányzó
- ML
- modell
- modellek
- modern
- módosítása
- több
- Filmek
- név
- Nevezett
- nemzet
- Természetes
- Természetes nyelv
- Természetes nyelvi feldolgozás
- Szükség
- igénylő
- Új
- új funkció
- Új funkciók
- újonnan
- nem
- szám
- of
- gyakran
- on
- ONE
- csak
- nyitva
- nyílt forráskódú
- működés
- Művelet
- or
- rendelés
- Más
- mi
- eredmények
- kívül
- múlt
- Fizet
- teljesít
- teljesítmény
- telefon
- Platformok
- Plató
- Platón adatintelligencia
- PlatoData
- kérem
- pozíció
- lehetséges
- állás
- előkészítése
- ár
- Fő
- problémák
- folyamat
- feldolgozott
- feldolgozás
- Termékek
- szakmai
- ad
- Vásárlás
- vásárlások
- célokra
- Piton
- lekérdezések
- gyorsan
- Nyers
- nyers adatok
- Olvass
- elismerés
- rekord
- nyilvántartások
- csökkenteni
- engedje
- kötelező
- eredményez
- Kritika
- SOR
- futás
- futás
- sagemaker
- értékesítés
- azonos
- Skála
- Tudomány
- TUDOMÁNYOK
- Tudós
- tudósok
- Rész
- vagy szerver
- szolgáltatás
- Szolgáltatások
- készlet
- számos
- mutatott
- Műsorok
- hasonló
- Egyszerű
- egyszerűsített
- egyszerűsítése
- egyetlen
- So
- Megoldások
- Megoldása
- Források
- Szikra
- szakember
- specializálódott
- beszéd
- Speech Recognition
- költ
- költött
- SQL
- standard
- nyilatkozat
- nyilatkozatok
- Lépés
- Lépései
- tárolás
- tárolni
- memorizált
- áramvonal
- Húr
- sikeres
- ilyen
- támogatás
- Támogatja
- Systems
- táblázat
- Feladat
- feladatok
- hogy
- A
- Az egyesítés
- azok
- Őket
- akkor
- Ott.
- Ezek
- ezt
- idő
- időutazás
- nak nek
- felső
- Végösszeg
- Vonat
- Képzések
- tranzakció
- ügyleti
- át
- transzformáló
- utazás
- típus
- mögöttes
- megértés
- Frissítések
- frissítve
- Frissítés
- frissítés
- feltöltve
- használ
- segítségével
- rendszerint
- ÉRVÉNYESÍT
- Értékes
- érték
- Értékek
- különféle
- ellenőrzése
- változat
- nagyon
- keresztül
- Videók
- Megnézem
- látomás
- akar
- volt
- Nézz
- we
- háló
- webes szolgáltatások
- voltak
- amikor
- bármikor
- ami
- míg
- WHO
- val vel
- nélkül
- Munka
- munkafolyamat
- Munkacsoport
- dolgozó
- művek
- lenne
- ír
- év
- év
- te
- A te
- zephyrnet
- Postai irányítószám