Kép a szerkesztőtől
Kulcs elvezetések
- A t-próba egy statisztikai teszt, amellyel megállapítható, hogy van-e szignifikáns különbség két független adatminta átlaga között.
- Bemutatjuk, hogyan lehet t-tesztet alkalmazni az írisz adatkészlet és a Python Scipy könyvtár segítségével.
The t-test is a statistical test that can be used to determine if there is a significant difference between the means of two independent samples of data. In this tutorial, we illustrate the most basic version of the t-test, for which we will assume that the two samples have equal variances. Other advanced versions of the t-test include the Welch’s t-test, which is an adaptation of the t-test, and is more reliable when the two samples have unequal variances and possibly unequal sample sizes.
A t statisztikát vagy t-értéket a következőképpen számítjuk ki:
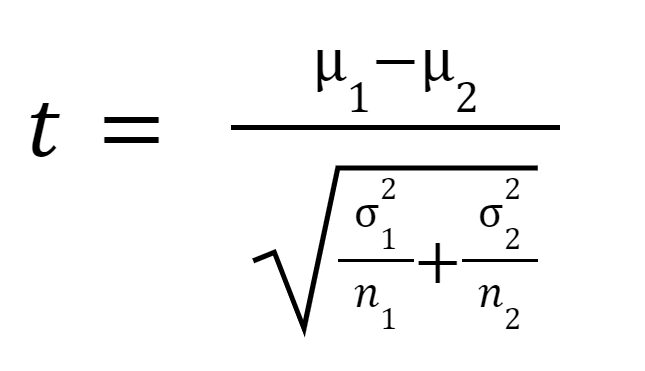
ahol
az 1. minta átlaga,
az 2. minta átlaga,
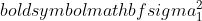 az 1. minta varianciája,
az 1. minta varianciája, 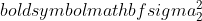 az 2. minta varianciája,
az 2. minta varianciája, 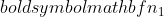 az 1. minta mintanagysága, és
az 1. minta mintanagysága, és 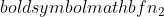 a 2. minta mintanagysága.
a 2. minta mintanagysága.
A t-próba használatának illusztrálására egy egyszerű példát mutatunk be az írisz adatkészlet használatával. Tegyük fel, hogy két független mintát figyelünk meg, pl. a virágcsészelevél hosszát, és mérlegeljük, hogy a két mintát ugyanabból a populációból (például ugyanazon virágfajtából vagy két hasonló csészelevél jellemzőkkel rendelkező fajból) vagy két különböző populációból vettük-e.
A t-próba számszerűsíti a két minta számtani átlaga közötti különbséget. A p-érték számszerűsíti a megfigyelt eredmények megszerzésének valószínűségét, feltételezve, hogy a nullhipotézis (ami szerint a minták azonos populációs átlagú populációkból származnak) igaz. A kiválasztott küszöbnél nagyobb p-érték (például 5% vagy 0.05) azt jelzi, hogy megfigyelésünk nem olyan valószínűtlen, hogy véletlenül történt. Ezért elfogadjuk az egyenlő populációs átlag nullhipotézisét. Ha a p-érték kisebb, mint a mi küszöbünk, akkor bizonyítékunk van az egyenlő populációs átlag nullhipotézisére.
T-teszt bemenet
A t-próba végrehajtásához szükséges bemenetek vagy paraméterek:
- Két tömb a és a b az 1. és a 2. minta adatait tartalmazza
T-teszt kimenetek
A t-teszt a következőket adja vissza:
- A számított t-statisztika
- A p-érték
Importálja a szükséges könyvtárakat
import numpy as np
from scipy import stats import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
Írisz adatkészlet betöltése
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
Számítsa ki a minta átlagát és a minta szórását!
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Végezze el a t-próbát
stats.ttest_ind(a_1, b_1, equal_var = False)
teljesítmény
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
teljesítmény
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
teljesítmény
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)Észrevételek
Megfigyeltük, hogy az "igaz" vagy "hamis" használata az "equal-var" paraméternél nem változtatja meg annyira a t-próba eredményeit. Azt is megfigyeljük, hogy az a_1 és b_1 mintatömbök sorrendjének felcserélése negatív t-teszt értéket ad, de nem változtatja meg a t-teszt értékének nagyságát, ahogy az várható volt. Mivel a számított p-érték jóval nagyobb, mint a 0.05-ös küszöbérték, elvethetjük azt a nullhipotézist, hogy az 1. minta és a 2. minta átlaga közötti különbség szignifikáns. Ez azt mutatja, hogy az 1. és a 2. minta csészelevélhosszát azonos populációs adatokból vettük.
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
Számítsa ki a minta átlagát és a minta szórását!
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Végezze el a t-próbát
stats.ttest_ind(a_1, b_1, equal_var = False)
teljesítmény
stats.ttest_ind(a_1, b_1, equal_var = False)Észrevételek
Megfigyeltük, hogy az egyenlőtlen méretű minták használata nem változtatja meg szignifikánsan a t-statisztikát és a p-értéket.
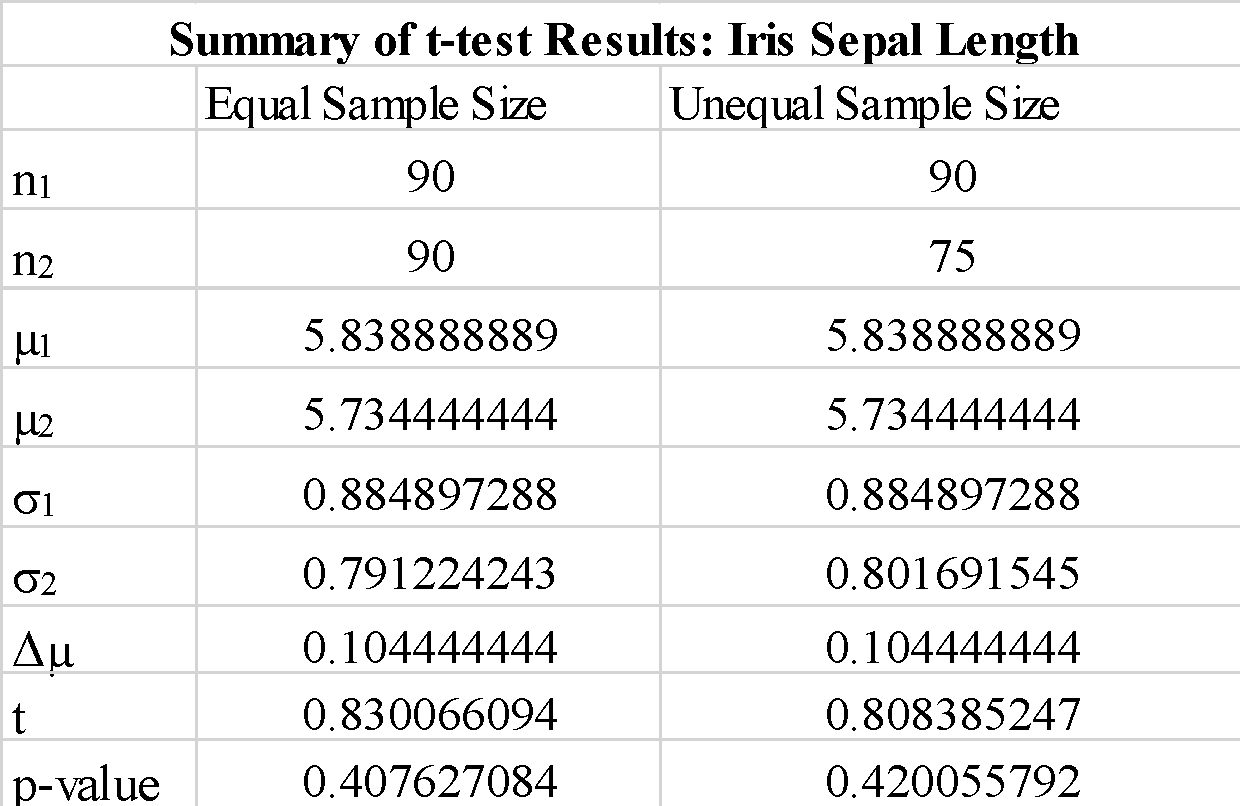
Összefoglalva, megmutattuk, hogyan valósítható meg egy egyszerű t-teszt a scipy könyvtár használatával a pythonban.
Benjamin O. Tayo fizikus, adattudományi oktató és író, valamint a DataScienceHub tulajdonosa. Korábban Benjamin mérnököt és fizikát tanított az U. of Central Oklahoma-ban, a Grand Canyon U.-ban és a Pittsburgh State U.-ban.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://www.kdnuggets.com/2023/01/performing-ttest-python.html?utm_source=rss&utm_medium=rss&utm_campaign=performing-a-t-test-in-python
- 1
- 7
- 9
- a
- Elfogad!
- fejlett
- ellen
- és a
- alkalmazott
- alapvető
- Benjámin
- között
- számított
- központi
- esély
- változik
- jellemzők
- választott
- figyelembe véve
- tudott
- dátum
- adat-tudomány
- adatkészletek
- Határozzuk meg
- különbség
- különböző
- húzott
- Mérnöki
- bizonyíték
- példa
- várható
- virág
- következő
- következik
- ból ből
- Hogyan
- HTTPS
- végre
- importál
- in
- tartalmaz
- független
- jelzi
- KDnuggets
- nagyobb
- könyvtár
- matplotlib
- eszközök
- több
- a legtöbb
- elengedhetetlen
- negatív
- számtalan
- megfigyelni
- megszerzése
- történt
- Oklahoma
- érdekében
- Más
- tulajdonos
- paraméter
- paraméterek
- előadó
- Fizika
- Pittsburgh
- Plató
- Platón adatintelligencia
- PlatoData
- népesség
- populációk
- korábban
- valószínűség
- Piton
- megbízható
- Eredmények
- Visszatér
- azonos
- Tudomány
- előadás
- mutatott
- Műsorok
- jelentős
- jelentősen
- hasonló
- Egyszerű
- óta
- Méret
- méretek
- kisebb
- So
- Állami
- statisztikai
- statisztika
- ÖSSZEFOGLALÓ
- Tanítási
- teszt
- A
- ebből adódóan
- küszöb
- nak nek
- igaz
- oktatói
- használ
- érték
- változat
- vajon
- ami
- lesz
- író
- hozamok
- zephyrnet