Mi az a dokumentumfeldolgozás?

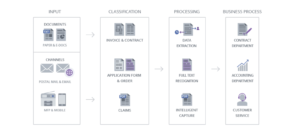
A dokumentumfeldolgozás a dokumentumokból strukturált adatok kinyerésének automatizálási folyamata. Ez lehet bármilyen dokumentum, például számla, önéletrajz, személyi igazolvány stb. A kihívást jelentő rész itt nem csak az OCR. Számos lehetőség áll rendelkezésre alacsony költségek mellett, amelyek kivonhatják a szöveget, és megadhatják a helyet. Az igazi kihívás ezeknek a szövegrészeknek a pontos és automatikus címkézése.
A dokumentumfeldolgozás üzleti hatása
Számos iparág napi tevékenysége során nagymértékben támaszkodik a dokumentumfeldolgozásra. A pénzügyi szervezeteknek hozzá kell férniük a SEC-bevallásokhoz, a biztosítási bejelentésekhez, az e-kereskedelmi vagy az ellátási lánccal foglalkozó társaságoknak pedig szükségük lehet a használt számlákhoz – a lista folytatódik. Ezen információk pontossága ugyanolyan fontos, mint a megtakarított idő, ezért mindig javasoljuk a fejlettebb mély tanulási módszerek használatát, amelyek jobban általánosítanak és pontosabbak.
A PwC jelentése szerint [link] még a legkezdetlegesebb mennyiségű strukturált adatkinyerés is 30-50%-át takaríthatja meg az alkalmazottak PDF-fájlokból az adatok Excel-táblázatokba való manuális másolására és beillesztésére fordított idejére. Az olyan modellek, mint a LayoutLM, természetesen nem kezdetlegesek, rendkívül intelligens ágensekként épültek fel, amelyek képesek pontos adatkinyerésre nagy léptékben, különböző felhasználási esetekben. Még sok saját ügyfelünknél is csökkentettük az adatok manuális kinyeréséhez szükséges időt a dokumentumonkénti 20 percről 10 másodperc alá. Ez egy hatalmas váltás, amely lehetővé teszi a dolgozók számára, hogy termelékenyebbek legyenek, és általánosságban nagyobb teljesítményt érjenek el.
Hol alkalmazható tehát a LayoutLM-hez hasonló mesterséges intelligencia? A Nanonets-nél ilyen technológiát használtunk
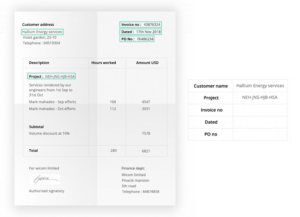
- A számlafeldolgozás automatizálása
- Táblázat adatkinyerése
- Űrlapadatok kinyerése
- Az elemzés folytatása
és sok más használati eset.
Miért a LayoutLM?
Hogyan érti meg a mélytanulási modell, hogy egy adott szövegrész a számlán szereplő cikkleírás, vagy a számlaszám? Leegyszerűsítve, hogyan tanulja meg a modell a címkék helyes hozzárendelését?
Az egyik módszer az, hogy egy hatalmas nyelvi modellből, például a BERT-ből vagy a GPT-3-ból származó szövegbeágyazásokat használunk, és egy osztályozón keresztül futtatjuk – bár ez nem túl hatékony. Sok olyan információ van, amelyet nem lehet tisztán szöveggel felmérni. Vagy használhatunk képalapú információkat. Ezt az R-CNN és a Faster R-CNN modellek használatával érték el. Ez azonban még mindig nem használja ki teljes mértékben a dokumentumokban rendelkezésre álló információkat. Egy másik megközelítés a Graph Convolutional Neural Networks volt, amely mind a hely-, mind a szöveges információkat kombinálta, de nem vette figyelembe a képinformációkat.
Hogyan használjuk tehát az információ mindhárom dimenzióját, azaz az adott szöveg szövegét, képét és helyét is? Itt jönnek be az olyan modellek, mint a LayoutLM. Annak ellenére, hogy sok évvel korábban aktív kutatási terület volt, a LayoutLM volt az egyik első olyan modell, amely sikeresen egyesítette a darabokat egy olyan egyedi modell létrehozására, amely helyzetinformációkat, szöveges információkat, és képinformációkat is.
LayoutLM oktatóanyag
Ez a cikk feltételezi, hogy megértette, mi az a nyelvi modell. Ha nem, ne aggódj, erről is írtunk egy cikket! Ha többet szeretne megtudni arról, hogy mik a transzformátormodellek, és mi a figyelem, itt egy csodálatos cikke Jay Alammartól.
Feltételezve, hogy ezeket a dolgokat félretettük, kezdjük az oktatóanyaggal. Fő referenciaként az eredeti LayoutLM-papírt fogjuk használni.
OCR szöveg kivonás
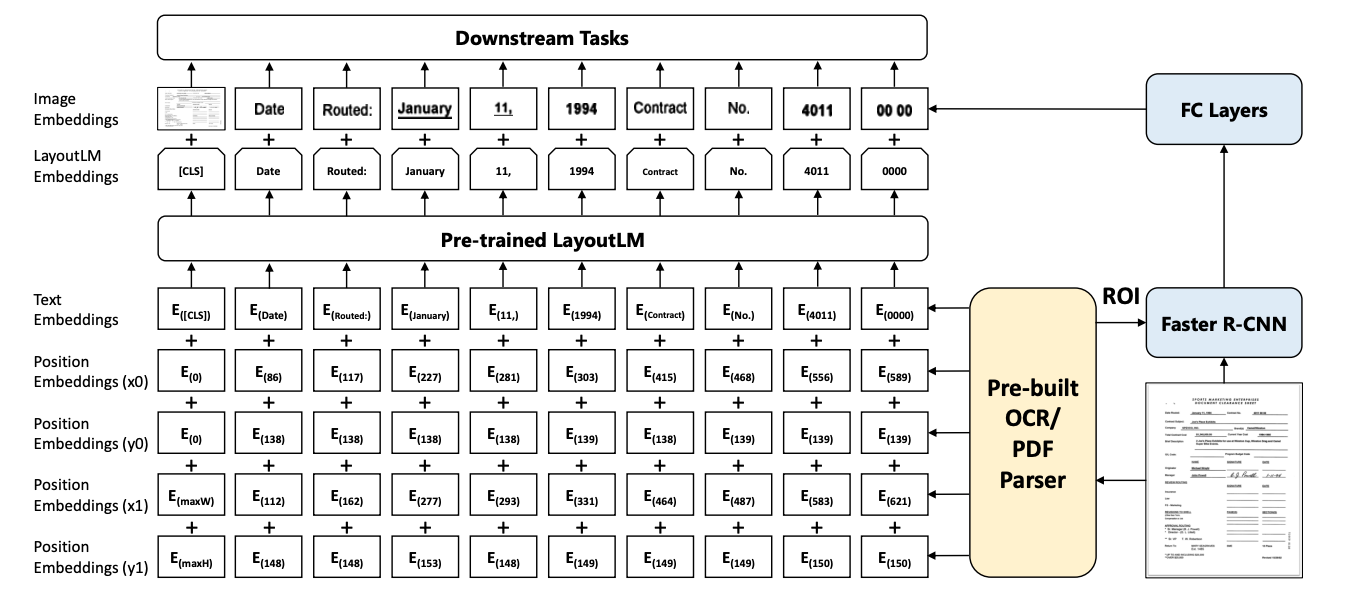
A legelső dolgunk, hogy egy dokumentummal kivonjuk a szöveges információkat a dokumentumból, és megkeressük a megfelelő helyüket. Hely szerint valami úgynevezett „határolókeretre” utalunk. A határolókeret egy téglalap, amely az oldalon lévő szövegrészt tartalmazza.

A legtöbb esetben azt feltételezzük, hogy a határolókeretnek a bal felső sarokban van az origója, és hogy a pozitív x tengely az origótól az oldal jobb oldala felé, a pozitív y tengely pedig az origótól az oldal felé irányul. az oldal alján, egy pixelt tekintve a mértékegységnek.
Nyelvi és hely beágyazások
Ezután öt különböző beágyazási réteget használunk. Az egyik a nyelvvel kapcsolatos információk – azaz a szövegbeágyazások – kódolása.
A másik négy helybeágyazáshoz van fenntartva. Feltételezve, hogy ismerjük az xmin, ymin, xmax és ymax értékeket, meg tudjuk határozni a teljes határolókeretet (ha nem tudod elképzelni, itt van egy link neked). Ezek a koordináták a megfelelő beágyazási rétegeiken haladnak át a hely információinak kódolásához.
Az öt beágyazást – egyet a szöveghez és négyet a koordinátákhoz – a rendszer összeadja, hogy létrehozza a beágyazás végső értékét, amely áthalad a LayoutLM-en. A kimenetre LayoutLM beágyazásként hivatkozunk.
Képbeágyazások
Rendben, sikerült megtalálnunk a szöveggel és a hellyel kapcsolatos információkat úgy, hogy kombináltuk a beágyazásukat, és átadtuk egy nyelvi modellen. Most hogyan járjuk körbe a képpel kapcsolatos információk kombinálásának folyamatát?
A szöveg és az elrendezési információk kódolása közben párhuzamosan a Faster R-CNN-t használjuk a dokumentumhoz kapcsolódó szövegrészek kibontására. A Faster R-CNN egy tárgyfelismerésre használt képmodell. Esetünkben arra használjuk, hogy felismerjük a különböző szövegrészeket (feltételezve, hogy minden kifejezés egy objektum), majd a szegmentált képeket egy teljesen összekapcsolt rétegen továbbítjuk, ezzel is segítve a képek beágyazását.
A LayoutLM beágyazások, valamint a képbeágyazások kombinálva egy végső beágyazást hoznak létre, amely aztán felhasználható a downstream feldolgozáshoz.
Előképzés LayoutLM
A fentieknek csak akkor van értelme, ha megértjük a LayoutLM képzési módszerét. Végül is, nem számít, milyen kapcsolatokat hozunk létre egy neurális hálózatban, amíg és hacsak nem képezik a megfelelő tanulási céllal, ez nem egészen okos. A LayoutLM szerzői a BERT előképzéséhez hasonló módszert kívántak alkalmazni.
Maszkolt vizuális nyelvi modell (MVLM)
Annak érdekében, hogy a modell megtanulja, milyen szöveg lehetett egy adott helyen, a szerzők véletlenszerűen maszkoltak néhány szövegjelet, miközben megtartották a helyhez kapcsolódó információkat és beágyazásokat. Ez lehetővé tette a LayoutLM számára, hogy túllépjen az egyszerű maszkolt nyelvi modellezésen, és segítette a szövegbeágyazásokat a helyhez kapcsolódó módozatokhoz is társítani.
Többcímkés dokumentumosztályozás (MDC)
A dokumentumban található összes információ kategóriákba sorolása segít a modellnek megérteni, hogy mely információk relevánsak egy bizonyos dokumentumosztály számára. A szerzők azonban megjegyzik, hogy nagyobb adatkészletek esetén előfordulhat, hogy a dokumentumosztályokra vonatkozó adatok nem állnak rendelkezésre azonnal. Ezért eredményalapot biztosítottak mind az MVLM képzés egyedül, mind az MVLM + MDC képzés.
Az elrendezés finomhangolása a downstream feladatokhoz
Számos downstream feladat is végrehajtható a LayoutLM-mel. Azokról lesz szó, amelyeket a szerzők vállaltak.
Űrlapértés
Ez a feladat egy címketípust egy adott szövegrészhez kapcsol. Ennek segítségével bármilyen dokumentumból strukturált adatokat kinyerhetünk. Adott a végső kimenet, azaz a LayouLM beágyazások + képbeágyazások, ezek áthaladnak egy teljesen összekapcsolt rétegen, majd egy softmaxon, hogy megjósolják az adott szövegrész címkéjének osztályvalószínűségét.
Nyugta Megértés
Ebben a feladatban több információs mező üresen maradt a nyugtákon, és a modellnek helyesen kellett elhelyeznie a szövegrészeket a megfelelő helyekre.
Dokumentumkép-osztályozás
A dokumentum szövegéből és képéből származó információk kombinálva segítik a dokumentum osztályának megértését azáltal, hogy egyszerűen áthaladnak egy softmax rétegen.
Huggingface LayoutLM
Az egyik fő oka annak, hogy a LayoutLM-et oly sokat vitatják, mert a modell nyílt forráskódú volt egy ideje. Ez elérhető Hugging Face, így a LayoutLM használata most lényegesen egyszerűbb.
Mielőtt belemerülnénk a LayoutLM saját igényeinek megfelelő finomhangolásának sajátosságaiba, néhány dolgot figyelembe kell venni.
Könyvtárak telepítése
A LayoutLM futtatásához szüksége lesz a Hugging Face transzformátorkönyvtárára, amely viszont a PyTorch könyvtártól függ. Telepítésükhöz (ha még nincsenek telepítve) futtassa a következő parancsokat
A határoló dobozokon
A képmérettől függetlenül egységes beágyazási séma létrehozásához a határolókeret koordinátáit 1000-es skálán normalizáljuk.
Configuration
A transzformátorok.LayoutLMConfig osztály használatával beállíthatja a modell méretét úgy, hogy a legjobban megfeleljen az Ön igényeinek, mivel ezek a modellek általában nehezek, és meglehetősen kevés számítási teljesítményt igényelnek. Ha kisebb modellre állítja, segíthet a helyi futtatásban. tudsz itt tudhat meg többet az osztályról.
LayoutLM a dokumentum osztályozáshoz (Link)
Ha dokumentumosztályozást szeretne végezni, akkor szüksége lesz az osztálytranszformátorokra.LayoutLMForSequenceClassification. A sorozat itt a kivont dokumentumból származó szövegsorozat. Itt van egy kis kódminta a Hugging Face.co-tól, amely elmagyarázza, hogyan kell használni
LayoutLM szövegcímkézéshez (Link)
A szemantikus címkézés végrehajtásához, azaz a címkék hozzárendeléséhez a dokumentum különböző szövegrészeihez szükség lesz az osztálytranszformátorokra.LayoutLMForTokenClassification. További részleteket találhat a itt is ugyanaz.Itt van egy kis kódminta, hogy megtudja, hogyan működik az Ön számára
Néhány megjegyzés az Arc-öleléssel kapcsolatos elrendezéssel kapcsolatban
- Jelenleg a Hugging Face LayoutLM modell a Tesseract nyílt forráskódú könyvtárát használja szövegkivonathoz, ami nem túl pontos. Érdemes lehet egy másik, fizetős OCR-eszköz használatát, például az AWS Textract vagy a Google Cloud Vision használatát
- A meglévő modell csak a nyelvi modellt, azaz a LayoutLM beágyazásokat biztosítja, a vizuális jellemzőket kombináló végső rétegeket nem. LayoutLMv2 (a következő részben tárgyaljuk) a Detectron könyvtárat használja, hogy lehetővé tegye a vizuális funkciók beágyazását is.
- A címkék besorolása szószinten történik, így valójában az OCR szövegkivonatoló motoron múlik, hogy egy mezőben minden szó folyamatos sorrendben legyen, vagy előfordulhat, hogy egy mező kettőnek számít.
LayoutLMv2
A LayoutLM forradalomként jelent meg a dokumentumokból való adatok kinyerésében. Ami azonban a mély tanulási kutatást illeti, a modellek idővel egyre jobban javulnak. A LayoutLM-et hasonlóképpen a LayoutLMv2 váltotta fel, ahol a szerzők néhány jelentős változtatást eszközöltek a modell betanításában.
Beleértve az egydimenziós térbeli beágyazásokat és a vizuális token beágyazásokat
A LayoutLMv2 információkat tartalmazott az egydimenziós relatív helyről, valamint az általános képpel kapcsolatos információkat. Ennek az az oka, hogy ez fontos, az új képzési célok miatt van, amelyekről most beszélünk
Új képzési célok
A LayoutLMv2 tartalmazott néhány módosított képzési célt. Ezek a következők:
- Maszkolt vizuális nyelvi modellezés: Ez ugyanaz, mint a LayoutLM-ben
- Szövegkép igazítása: A szöveget véletlenszerűen takarták le a képről, miközben a szöveg tokeneket a modell rendelkezésére bocsátották. A modellnek minden tokennél meg kellett tanulnia, hogy az adott szöveget lefedték-e vagy sem. Ezáltal a modell képes volt kombinálni a vizuális és szöveges modalitásokból származó információkat
- Szövegkép-illesztés: A modellt arra kérik, hogy ellenőrizze, hogy az adott kép megfelel-e az adott szövegnek. A negatív mintákat vagy hamis képként adják meg, vagy egyáltalán nem biztosítanak képbeágyazást. Ez azért történik, hogy a modell többet tudjon meg a szöveg és a képek kapcsolatáról.
Ezekkel az új módszerekkel és beágyazásokkal a modell magasabb F1 pontszámot tudott elérni szinte az összes tesztadatkészleten, mint LayoutLM.
- Rólunk
- hozzáférés
- Fiók
- pontos
- elért
- át
- aktív
- fejlett
- szerek
- AI
- Minden termék
- már
- Bár
- összeg
- Másik
- megközelítés
- TERÜLET
- körül
- cikkben
- szerzők
- elérhető
- AWS
- alap
- hogy
- BEST
- Bit
- Doboz
- Kártyák
- esetek
- kihívás
- besorolás
- felhő
- kód
- kombinált
- vállalat
- Kiszámít
- Configuration
- kapcsolatok
- megfontolás
- kiadások
- tudott
- Ügyfelek
- dátum
- nap
- Ellenére
- Érzékelés
- DID
- különböző
- dokumentumok
- le-
- e-commerce
- Hatékony
- lehetővé téve
- létrehozni
- Excel
- Arc
- gyorsabb
- Funkció
- Jellemzők
- Fed
- pénzügyi
- vezetéknév
- következő
- generál
- GitHub
- segít
- segít
- itt
- Hogyan
- How To
- HTTPS
- kép
- Hatás
- fontos
- javul
- beleértve
- iparágak
- információ
- biztosítás
- Intelligens
- IT
- címkézés
- Címkék
- nyelv
- nagyobb
- TANUL
- tanulás
- szint
- könyvtár
- LINK
- Lista
- helyileg
- elhelyezkedés
- helyszínek
- kézzel
- tömeges
- egyező
- Anyag
- modell
- modellek
- a legtöbb
- hálózat
- hálózatok
- nyitva
- nyílt forráskódú
- Művelet
- Opciók
- érdekében
- szervezetek
- Más
- fizetett
- Papír
- darab
- hatalom
- folyamat
- biztosít
- PWC
- miatt
- ajánl
- jelentést
- kötelező
- követelmények
- kutatás
- Eredmények
- folytatás
- futás
- Skála
- rendszer
- SEC
- értelemben
- készlet
- beállítás
- váltás
- jelentős
- hasonló
- Egyszerű
- Méret
- kicsi
- okos
- So
- valami
- kezdődött
- siker
- kínálat
- ellátási lánc
- feladatok
- Technológia
- teszt
- Keresztül
- idő
- jelképes
- tokenek
- felső
- Képzések
- megért
- használ
- hasznosít
- érték
- Mit
- vajon
- szavak
- Munka
- dolgozók
- év