A pénzügyi szolgáltatások ügyfelei különböző forrásokból származó adatokat használnak, amelyek különböző gyakorisággal származnak, beleértve a valós idejű, kötegelt és archivált adatkészleteket. Ezenkívül streaming architektúrákra van szükségük a növekvő kereskedelmi volumen, a piaci volatilitás és a szabályozási igények kezelésére. Az alábbiakban felsorolunk néhány olyan kulcsfontosságú üzleti felhasználási esetet, amelyek rávilágítanak erre az igényre:
- Kereskedelmi jelentés – A 2007–2008-as globális pénzügyi válság óta a szabályozó hatóságok megerősítették a hatósági jelentésekkel kapcsolatos követeléseiket és ellenőrzésüket. A szabályozók fokozott hangsúlyt fektettek a fogyasztók védelmére a tranzakciós jelentésekkel (jellemzően T+1, azaz 1 munkanappal a kereskedés dátuma után), valamint a piacok átláthatóságának növelésére a közel valós idejű kereskedési jelentési követelmények révén.
- Kockázat kezelés – A tőkepiacok összetettebbé válásával és a szabályozók új kockázati keretek bevezetésével, mint pl A kereskedési könyv alapvető áttekintése (FRTB) és Bázel III, a pénzintézetek arra törekszenek, hogy növeljék a teljes piaci kockázat, a likviditási kockázat, a partnerkockázat és egyéb kockázati mérések számítási gyakoriságát, és a lehető legközelebb szeretnének kerülni a valós idejű számításokhoz.
- Kereskedelmi minőség és optimalizálás – A kereskedés minőségének nyomon követése és optimalizálása érdekében folyamatosan értékelnie kell a piac jellemzőit, például a mennyiséget, az irányt, a piac mélységét, a kitöltési arányt és az ügyletek teljesítésével kapcsolatos egyéb benchmarkokat. A kereskedelem minősége nem csak a bróker teljesítményével függ össze, hanem a szabályozóktól is követelmény, kezdve MiFID II.
A kihívás az, hogy olyan megoldást találjunk, amely képes kezelni ezeket az eltérő forrásokat, változatos frekvenciákat és alacsony késleltetésű fogyasztási követelményeket. A megoldásnak méretezhetőnek, költséghatékonynak és könnyen átvehetőnek és működtethetőnek kell lennie. Amazon RedShift olyan funkciók, mint az adatfolyam-feldolgozás, Amazon Aurora nulla-ETL integrációés adatmegosztás a következővel AWS adatcsere lehetővé teszi a közel valós idejű feldolgozást a kereskedelmi jelentésekhez, a kockázatkezeléshez és a kereskedés optimalizálásához.
Ebben a bejegyzésben olyan megoldás-architektúrát kínálunk, amely leírja, hogyan dolgozhat fel adatokat három különböző típusú forrásból – streaming, tranzakciós és harmadik féltől származó referenciaadatok –, és hogyan összesítheti azokat az Amazon Redshiftben az üzleti intelligencia (BI) jelentésekhez.
Megoldás áttekintése
Ez a megoldás-architektúra az alacsony kódú/kód nélküli megközelítést helyezi előtérbe a következő vezérelvekkel:
- Egyszerű használat – Intuitív felhasználói felületekkel való megvalósítása és működtetése kevésbé legyen bonyolult
- Skálázható – Igény szerint zökkenőmentesen növelheti és csökkentheti a kapacitást
- Natív integráció – Az összetevőket további csatlakozók vagy szoftverek nélkül kell integrálni
- Költséghatékony – Kiegyensúlyozott ár/teljesítményt kell biztosítania
- Alacsony karbantartási – Kevesebb irányítási és üzemeltetési többletköltséget kell igényelnie
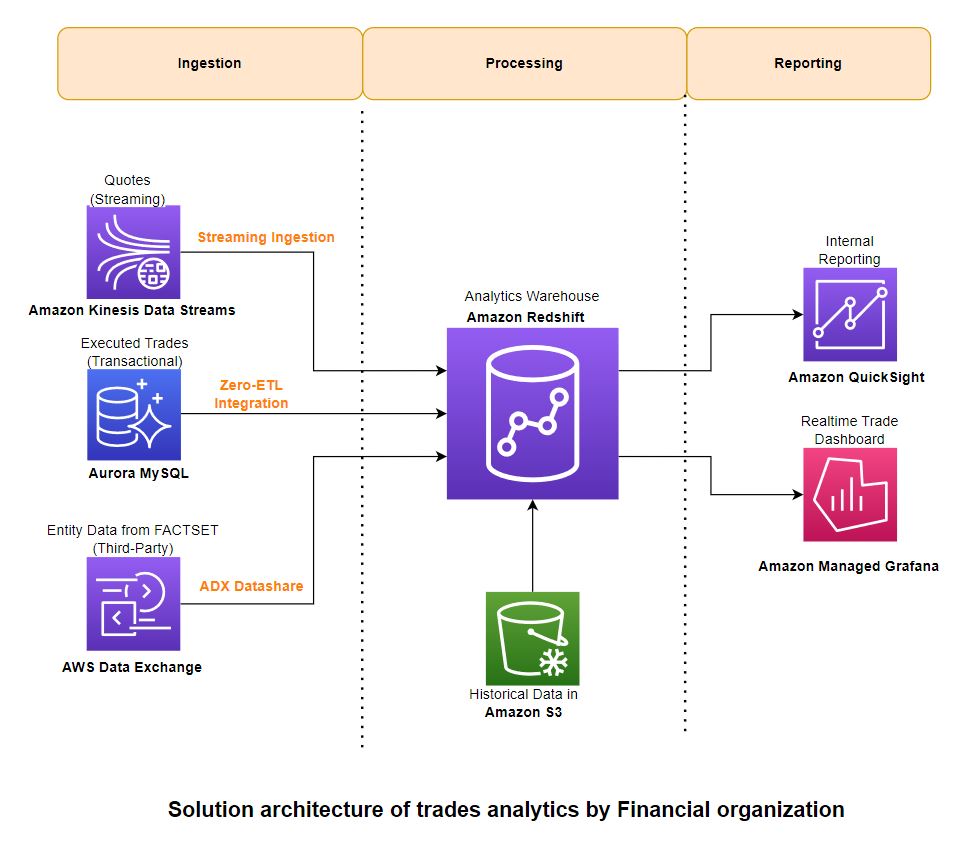
A következő diagram bemutatja a megoldás architektúráját, és azt, hogy hogyan alkalmazták ezeket az irányadó elveket a feldolgozási, összesítési és jelentési összetevőkre.
![]()
Telepítse a megoldást
Használhatja a következőket AWS felhőképződés sablon a megoldás üzembe helyezéséhez.
![]()
Ez a verem a következő erőforrásokat és szükséges engedélyeket hozza létre a szolgáltatások integrálásához:
táplálékfelvétel
Az adatok feldolgozásához használja Amazon Redshift Streaming Ingestion a streaming adatok betöltéséhez a Kinesis adatfolyamból. A tranzakciós adatokhoz használja a Redshift nulla-ETL integráció az Amazon Aurora MySQL-lel. Harmadik fél referenciaadataihoz használja ki AWS Data Exchange adatmegosztások. Ezek a képességek lehetővé teszik a méretezhető adatfolyamok gyors felépítését, mivel növelheti a Kinesis Data Streams szilánkok kapacitását, kiszámíthatja a nulla-ETL forrásokat és célokat, és Redshift számításokat végezhet az adatmegosztásokra, amikor az adatok növekednek. A Redshift adatfolyam-feldolgozás és a nulla-ETL-integráció olyan alacsony kódú/kód nélküli megoldások, amelyeket egyszerű SQL-ekkel építhet meg anélkül, hogy jelentős időt és pénzt fektetne összetett egyéni kód fejlesztésébe.
A megoldás létrehozásához felhasznált adatok tekintetében partneri viszonyt alakítottunk ki FactSet, vezető pénzügyi adatok, elemzési és nyílt technológiai szolgáltató. A FactSetnek több is van adatkészletek elérhető az AWS Data Exchange piactéren, amelyet referenciaadatokhoz használtunk. Használtuk a FactSet-et is piaci adatmegoldások történelmi és streaming piaci jegyzésekhez és kereskedésekhez.
Feldolgozás
Az adatok feldolgozása az Amazon Redshiftben történik, a kivonat, betöltés és átalakítás (ELT) módszertan szerint. Gyakorlatilag korlátlan méretarányú és munkaterhelési elkülönítéssel az ELT jobban megfelel a felhőalapú adattárház-megoldásoknak.
A Redshift adatfolyam-feldolgozást használja a streaming idézetek (licit/ask) valós idejű feldolgozásához a Kinesis adatfolyamból közvetlenül egy streaming materializált nézetbe, és a következő lépésben feldolgozza az adatokat a PartiQL segítségével az adatfolyam-bemenetek elemzéséhez. Ne feledje, hogy a streaming materializált nézetek az automatikus frissítés működése és a használt adatkezelési SQL-parancsok tekintetében különböznek a szokásos materializált nézetektől. Hivatkozni Streaming feldolgozási szempontok a részletekért.
A nulla-ETL Aurora integrációt használja a tranzakciós adatok (kereskedések) OLTP-forrásokból történő feldolgozásához. Hivatkozni Nulla-ETL integrációkkal való munka a jelenleg támogatott forrásokhoz. Az összes ilyen forrásból származó adatokat egyesítheti nézetek segítségével, és tárolt eljárásokat használhat az üzleti átalakítási szabályok végrehajtására, például az ágazatok és tőzsdék súlyozott átlagainak kiszámítására.
A történelmi kereskedelmi és jegyzési adatok hatalmasak, és gyakran nem kérdezik le gyakran. Te tudod használni Amazon Red Shift Spectrum hogy a helyükön hozzáférjen ezekhez az adatokhoz anélkül, hogy betöltené őket az Amazon Redshiftbe. Külső táblákat hoz létre, amelyek az adatokra mutatnak Amazon egyszerű tárolási szolgáltatás (Amazon S3), és ugyanúgy kérdezzen le, mint bármely más helyi táblát az Amazon Redshiftben. Több Redshift adattárház egyidejűleg lekérdezheti ugyanazokat az adatkészleteket az Amazon S3-ban anélkül, hogy az egyes adattárházak adatairól másolatokat kellene készíteni. Ez a funkció leegyszerűsíti a külső adatokhoz való hozzáférést anélkül, hogy bonyolult ETL-folyamatokat kellene írni, és javítja a teljes megoldás egyszerű használatát.
Tekintsünk át néhány mintalekérdezést az árajánlatok és kereskedések elemzéséhez. A mintalekérdezésekben a következő táblázatokat használjuk:
- dt_hist_quote – A vételi árat és mennyiséget, az eladási árat és mennyiséget, valamint a tőzsdéket és a szektorokat tartalmazó történelmi jegyzési adatok. Olyan releváns adatkészleteket kell használnia a szervezetben, amelyek tartalmazzák ezeket az adatattribútumokat.
- dt_hist_trades – Történelmi kereskedési adatok, amelyek a kereskedési árat, mennyiséget, szektort és tőzsdei adatokat tartalmazzák. Olyan releváns adatkészleteket kell használnia a szervezetben, amelyek tartalmazzák ezeket az adatattribútumokat.
- factset_sector_map – Szektorok és tőzsdék közötti feltérképezés. Ezt beszerezheti a FactSet Fundamentals ADX adatkészlet.
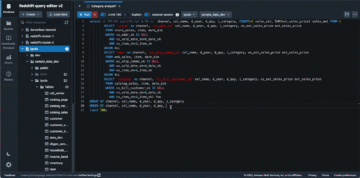
Mintalekérdezés történelmi idézetek elemzéséhez
A következő lekérdezéssel megkeresheti az árajánlatok súlyozott átlagos felárait:
Mintalekérdezés a múltbeli kereskedések elemzéséhez
A kereséshez a következő lekérdezést használhatja $-volume részletes tőzsdén, szektoronként és főbb tőzsdén (NYSE és Nasdaq) végzett kereskedésekről:
Jelentő
Használhatja Amazon QuickSight és a Amazon által kezelt Grafana BI és valós idejű jelentésekhez. Ezek a szolgáltatások natív módon integrálódnak az Amazon Redshift szolgáltatásba anélkül, hogy további csatlakozókat vagy szoftvereket kellene használniuk.
Közvetlen lekérdezést futtathat a QuickSight-ból BI-jelentésekhez és irányítópultokhoz. A QuickSight segítségével helyileg is tárolhat adatokat a SPICE gyorsítótárában az automatikus frissítéssel az alacsony késleltetés érdekében. Hivatkozni Az Amazon QuickSight és az Amazon Redshift fürtök közötti kapcsolatok engedélyezése átfogó részletekért a QuickSight és az Amazon Redshift integrációjáról.
Az Amazon Managed Grafana segítségével közel valós idejű kereskedési irányítópultokat készíthet, amelyek néhány másodpercenként frissülnek. A valós idejű irányítópultok a kereskedelmi feldolgozási késések figyelésére a Grafana segítségével jönnek létre, az adatok pedig az Amazon Redshift rendszernézeteiből származnak. Hivatkozni Az Amazon Redshift adatforrás használata megtudhatja, hogyan konfigurálhatja az Amazon Redshiftet a Grafana adatforrásaként.
A szabályozási jelentési rendszerekkel interakcióba lépő felhasználók elemzők, kockázatkezelők, operátorok és más olyan személyek, akik támogatják az üzleti és technológiai műveleteket. A szabályozási jelentések elkészítése mellett ezeknek a csapatoknak szüksége van a jelentési rendszerek állapotának áttekintésére.
Történelmi idézetek elemzése
Ebben a részben a történelmi idézetek elemzésére mutatunk be néhány példát Amazon QuickSight műszerfal.
Súlyozott átlag szektoronkénti megoszlás
Az alábbi diagram a NASDAQ és a NYSE egyes kereskedéseinek súlyozott átlagos bid-ask szpredeinek napi összesítését mutatja szektoronként 3 hónapra. Az átlagos napi felára kiszámításához minden felárat súlyozunk az ajánlat és az eladási dollár mennyiségének összegével. A diagram létrehozásához szükséges lekérdezés összesen 103 milliárd adatpontot dolgoz fel, minden kereskedést összekapcsol a szektor referenciatáblázatával, és kevesebb mint 10 másodpercen belül lefut.
![]()
Súlyozott átlag felár a tőzsdék szerint
Az alábbi diagram a NASDAQ és a NYSE egyes kereskedéseinek súlyozott átlagos bid-ask szpredeinek napi összesítését mutatja 3 hónapra. A számítási módszer és a lekérdezési teljesítménymutatók hasonlóak az előző diagramhoz.
![]()
Történelmi kereskedések elemzése
Ebben a részben megvizsgálunk néhány példát a történelmi kereskedések elemzésére Amazon QuickSight műszerfal.
Kereskedelmi volumen ágazatonként
A következő diagram a NASDAQ és a NYSE egyes kereskedéseinek napi összesítését mutatja szektoronként 3 hónapra. A diagram létrehozására szolgáló lekérdezés összesen 3.6 milliárd kereskedést dolgoz fel, minden kereskedést összekapcsol a szektor referenciatáblázatával, és 5 másodpercen belül lefut.
![]()
Kereskedelmi volumen a főbb tőzsdéken
A következő diagram az egyes ügyletek tőzsdecsoportonkénti napi összesítését mutatja 3 hónapra vonatkozóan. A diagramot létrehozó lekérdezés teljesítménymutatói hasonlóak az előző diagramhoz.
![]()
Valós idejű irányítópultok
A megfigyelés és a megfigyelhetőség fontos követelmény minden kritikus üzleti alkalmazásnál, mint például a kereskedelmi jelentésekben, a kockázatkezelésben és a kereskedelmi menedzsment rendszerekben. A rendszerszintű mérőszámok mellett fontos a fő teljesítménymutatók valós időben történő nyomon követése is, hogy a kezelők riasztást kapjanak, és a lehető leghamarabb reagálhassanak az üzletet érintő eseményekre. Ehhez a demonstrációhoz a Grafana-ban irányítópultokat építettünk, amelyek figyelik a Kinesis adatfolyamból és az Aurora-ból származó jegyzési és kereskedési adatok késését.
Az árajánlat feldolgozási késleltetési irányítópultja azt mutatja, hogy mennyi idő szükséges ahhoz, hogy az egyes árajánlatrekordokat feldolgozzák az adatfolyamból, és lekérdezhetők legyenek az Amazon Redshiftben.
![]()
A kereskedelem feldolgozási késleltetési irányítópultja azt mutatja, hogy mennyi időbe telik, amíg egy Aurora-tranzakció elérhetővé válik az Amazon Redshiftben lekérdezésre.
![]()
Tisztítsuk meg
Az erőforrások megtisztításához törölje az AWS CloudFormation segítségével telepített veremet. Az utasításokat lásd: Verem törlése az AWS CloudFormation konzolon.
Következtetés
A növekvő mennyiségű kereskedési tevékenység, az összetettebb kockázatkezelés és a fokozott szabályozási követelmények arra késztetik a tőkepiaci cégeket, hogy alkalmazzák a valós idejű és közel valós idejű adatfeldolgozást, még a közép- és back-office platformokon is, ahol a nap végi és éjszakai feldolgozása történik. volt a mérce. Ebben a bejegyzésben bemutattuk, hogyan használhatja az Amazon Redshift képességeit a könnyű használat, az alacsony karbantartás és a költséghatékonyság érdekében. Megvitattuk a szolgáltatások közötti integrációkat is, amelyek lehetővé teszik a piaci adatok streamelését, az OLTP-adatbázisok frissítéseinek feldolgozását és a harmadik féltől származó referenciaadatok felhasználását anélkül, hogy bonyolult és költséges ETL- vagy ELT-feldolgozást kellene végrehajtani, mielőtt az adatokat elérhetővé tennénk elemzéshez és jelentésekhez.
Kérjük, forduljon hozzánk, ha bármilyen útmutatásra van szüksége a megoldás megvalósításához. Hivatkozni Valós idejű elemzés az Amazon Redshift adatfolyam-feldolgozással, Útmutató az első lépésekhez a közel valós idejű működési elemzéshez az Amazon Aurora nulla-ETL integrációjával az Amazon Redshifttelés Az AWS Data Exchange adatmegosztásokkal való együttműködés előállítóként további információért.
A szerzőkről
![]() Satesh Sonti az atlantai székhelyű Sr. Analytics Specialist Solutions Architect vállalati adatplatformok, adattárház- és elemzési megoldások kiépítésére szakosodott. Több mint 18 éves tapasztalattal rendelkezik az adatvagyon felépítésében és komplex adatplatform-programok vezetésében banki és biztosítási ügyfelek számára szerte a világon.
Satesh Sonti az atlantai székhelyű Sr. Analytics Specialist Solutions Architect vállalati adatplatformok, adattárház- és elemzési megoldások kiépítésére szakosodott. Több mint 18 éves tapasztalattal rendelkezik az adatvagyon felépítésében és komplex adatplatform-programok vezetésében banki és biztosítási ügyfelek számára szerte a világon.
![]() Alket Memushaj vezető építészként dolgozik az AWS pénzügyi szolgáltatások piacfejlesztési csapatában. Az Alket felelős a tőkepiacok technikai stratégiájáért, partnerekkel és ügyfelekkel együttműködve alkalmazások telepítését a teljes kereskedelmi életciklusban az AWS Cloudba, beleértve a piaci kapcsolódást, a kereskedési rendszereket, valamint a kereskedés előtti és utáni elemzési és kutatási platformokat.
Alket Memushaj vezető építészként dolgozik az AWS pénzügyi szolgáltatások piacfejlesztési csapatában. Az Alket felelős a tőkepiacok technikai stratégiájáért, partnerekkel és ügyfelekkel együttműködve alkalmazások telepítését a teljes kereskedelmi életciklusban az AWS Cloudba, beleértve a piaci kapcsolódást, a kereskedési rendszereket, valamint a kereskedés előtti és utáni elemzési és kutatási platformokat.
![]() Ruben Falk tőkepiaci szakértő, aki a mesterséges intelligenciára, valamint az adatokra és elemzésekre összpontosít. Ruben konzultál a tőkepiaci szereplőkkel a modern adatarchitektúráról és a szisztematikus befektetési folyamatokról. Az S&P Global Market Intelligence-től csatlakozott az AWS-hez, ahol a befektetéskezelési megoldások globális vezetője volt.
Ruben Falk tőkepiaci szakértő, aki a mesterséges intelligenciára, valamint az adatokra és elemzésekre összpontosít. Ruben konzultál a tőkepiaci szereplőkkel a modern adatarchitektúráról és a szisztematikus befektetési folyamatokról. Az S&P Global Market Intelligence-től csatlakozott az AWS-hez, ahol a befektetéskezelési megoldások globális vezetője volt.
![]() jeff wilson egy világméretű, piacra lépő szakértő, aki 15 éves tapasztalattal rendelkezik analitikai platformokkal kapcsolatban. Jelenleg az Amazon Redshift, az Amazon natív felhőadattárháza használatának előnyeinek megosztására összpontosít. Jeff Floridában él, és 2019 óta dolgozik az AWS-nél.
jeff wilson egy világméretű, piacra lépő szakértő, aki 15 éves tapasztalattal rendelkezik analitikai platformokkal kapcsolatban. Jelenleg az Amazon Redshift, az Amazon natív felhőadattárháza használatának előnyeinek megosztására összpontosít. Jeff Floridában él, és 2019 óta dolgozik az AWS-nél.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/big-data/combine-transactional-streaming-and-third-party-data-on-amazon-redshift-for-financial-services/
- :van
- :is
- :nem
- :ahol
- ][p
- $ UP
- 1
- 10
- 100
- 130
- 15 év
- 15%
- 150
- 16
- 20
- 2019
- 27
- 30
- a
- Képes
- Rólunk
- hozzáférés
- Hozzáférés
- át
- tevékenység
- További
- Ezen kívül
- ragaszkodva
- elfogadja
- Előny
- adx
- Után
- adalékanyag
- összesítés
- AI
- Minden termék
- lehetővé
- Is
- amazon
- Amazon által kezelt Grafana
- Amazon QuickSight
- Az Amazon Web Services
- összeg
- an
- elemzés
- Az elemzők
- Analitikus
- analitika
- elemzése
- és a
- bármilyen
- külön
- Alkalmazás
- alkalmazások
- alkalmazott
- megközelítés
- építészet
- architektúrák
- VANNAK
- AS
- kérdez
- Eszközök
- At
- Atlanta
- attribútumok
- Sárgásvörös
- auto
- elérhető
- átlagos
- AWS
- AWS felhőképződés
- b
- Kiegyensúlyozott
- Banking
- alapján
- BE
- mert
- válik
- óta
- előtt
- referenciaértékek
- Előnyök
- között
- kínálat
- Billió
- bis
- mindkét
- bróker
- épít
- Épület
- épült
- üzleti
- üzleti intelligencia
- Üzleti átalakulás
- de
- by
- cache
- számít
- kiszámítása
- számítás
- TUD
- képességek
- Kapacitás
- tőke
- Tőkepiacok
- eset
- esetek
- CBOE
- kihívás
- jellemzők
- Táblázatos
- ragadozó ölyv
- ügyfél részére
- közel
- felhő
- kód
- össze
- hogyan
- befejezés
- bonyolult
- alkatrészek
- átfogó
- Kiszámít
- kapcsolatok
- Connectivity
- fogyasztó
- fogyasztás
- tartalmaz
- folyamatosan
- példányban
- teremt
- készítette
- teremt
- válság
- kritikai
- Jelenlegi
- Jelenleg
- szokás
- Ügyfelek
- napi
- műszerfal
- műszerfalak
- dátum
- Adatcsere
- adatkezelés
- Adatplatform
- adat pontok
- adatfeldolgozás
- adatmegosztás
- adattárház
- adattárházak
- adatbázisok
- adatkészletek
- találka
- nap
- csökkenés
- késleltetés
- szállít
- igények
- igazolták
- telepíteni
- telepített
- mélység
- körülír
- részletes
- részletek
- fejlesztése
- Fejlesztés
- fejlesztői csapat
- diagram
- különböző
- közvetlen
- irány
- közvetlenül
- tárgyalt
- eltérő
- Dollár
- minden
- könnyű
- egyszerű használat
- ölelés
- lehetővé
- végén
- fokozott
- Javítja
- Vállalkozás
- Eter (ETH)
- értékelni
- Még
- események
- Minden
- példák
- csere
- Feltételek
- drága
- tapasztalat
- feltárása
- külső
- kivonat
- Funkció
- Jellemzők
- kevés
- kitöltése
- pénzügyi
- pénzügyi válság
- pénzügyi adat
- Pénzintézetek
- pénzügyi szolgáltatások
- Találjon
- cégek
- Florida
- Összpontosít
- összpontosított
- következő
- A
- keretek
- Frekvencia
- gyakran
- ból ből
- alapjai
- generál
- generáló
- kap
- Globális
- globális pénzügyi
- Globális pénzügyi válság
- világpiac
- földgolyó
- Piacra megy
- Csoport
- Növekvő
- növekszik
- útmutatást
- útmutató
- irányadó
- fogantyú
- Legyen
- tekintettel
- he
- fej
- Egészség
- Kiemel
- övé
- történeti
- Hogyan
- How To
- HTML
- http
- HTTPS
- hatalmas
- if
- illusztrálja
- végre
- végrehajtási
- fontos
- in
- tartalmaz
- magában foglalja a
- Beleértve
- Növelje
- <p></p>
- mutatók
- egyéni
- információ
- bemenet
- intézmények
- utasítás
- biztosítás
- integrálni
- integráció
- integrációk
- Intelligencia
- kölcsönhatásba
- bele
- intuitív
- befektetés
- beruházás
- szigetelés
- IT
- csatlakozik
- csatlakozott
- csatlakozik
- jpg
- Kulcs
- Kinesis adatfolyamok
- Késleltetés
- indít
- vezető
- TANUL
- kevesebb
- életciklus
- mint
- fizetőképesség
- kiszámításának
- betöltés
- helyi
- helyileg
- keres
- Elő/Utó
- karbantartás
- fontos
- csinál
- Gyártás
- sikerült
- vezetés
- Menedzserek
- térképészet
- piacára
- Piaci adatok
- Piaci volatilitás
- piactér
- piacok
- jelenti
- mérések
- Módszertan
- Metrics
- modern
- pénz
- monitor
- ellenőrzés
- hónap
- több
- többszörös
- MySQL
- Nasdaq
- bennszülött
- natívan
- elengedhetetlen
- Szükség
- Új
- New York
- New York Stock Exchange-
- következő
- megjegyezni
- NYSE
- szerez
- of
- gyakran
- on
- csak
- nyitva
- működik
- operatív
- Művelet
- üzemeltetők
- optimalizálás
- Optimalizálja
- or
- érdekében
- szervezet
- Más
- ki
- felett
- átfogó
- éjszakai
- résztvevők
- társult
- partnerek
- teljesít
- teljesítmény
- engedélyek
- Hely
- helyezett
- emelvény
- Platformok
- Plató
- Platón adatintelligencia
- PlatoData
- pont
- lehetséges
- állás
- kereskedés utáni
- megelőző
- ár
- Fő
- elvek
- prioritások
- eljárások
- folyamat
- feldolgozott
- Folyamatok
- feldolgozás
- Programok
- védelme
- ad
- ellátó
- világítás
- lekérdezések
- kérdés
- gyorsan
- idézet
- idézetek
- Arány
- el
- igazi
- real-time
- rekord
- utal
- referencia
- szabályos
- Szabályozók
- szabályozók
- összefüggő
- Jelentő
- Jelentések
- szükség
- követelmény
- követelmények
- kutatás
- Tudástár
- illetőleg
- Reagálni
- felelős
- Kritika
- Kockázat
- kockázatkezelés
- szabályok
- futás
- fut
- S&P
- S&P Global
- azonos
- skálázható
- Skála
- ellenőrzéssel
- zökkenőmentesen
- másodperc
- Rész
- szektor
- ágazatok
- válasszuk
- Szolgáltatások
- számos
- Megoszt
- megosztás
- kellene
- Műsorok
- jelentős
- hasonló
- Hasonlóképpen
- Egyszerű
- egyszerűsíti
- óta
- So
- szoftver
- megoldások
- Megoldások
- néhány
- Nemsokára
- forrás
- származó
- Források
- szakember
- specializált
- fűszer
- terjedése
- Kenhető
- SQL
- verem
- standard
- kezdődött
- Kezdve
- Lépés
- készlet
- Tőzsde
- tárolás
- tárolni
- memorizált
- egyértelmű
- Stratégia
- folyam
- folyó
- patakok
- ilyen
- összeg
- támogatás
- Támogatott
- rendszer
- Systems
- táblázat
- Vesz
- tart
- célok
- csapat
- csapat
- Műszaki
- Technológia
- sablon
- feltételek
- mint
- hogy
- A
- azok
- Őket
- akkor
- Ezek
- ők
- harmadik fél
- harmadik fél adatai
- ezt
- azok
- három
- Keresztül
- idő
- nak nek
- Végösszeg
- kereskedelem
- forgalmazott
- szakmák
- Kereskedés
- tranzakció
- ügyleti
- Átalakítás
- Átalakítás
- Átláthatóság
- típusok
- jellemzően
- alatt
- korlátlan
- Frissítés
- us
- használ
- használt
- használó
- Felhasználók
- segítségével
- keresztül
- Megnézem
- nézetek
- gyakorlatilag
- láthatóság
- Illékonyság
- kötet
- kötetek
- akar
- Raktár
- Raktározás
- volt
- we
- háló
- webes szolgáltatások
- súly
- voltak
- amikor
- ami
- WHO
- val vel
- nélkül
- dolgozó
- művek
- írás
- yaml
- év
- york
- te
- A te
- zephyrnet