A képességesebb, gyorsabb, kisebb és alacsonyabb energiafelhasználású rendszerek felé vezető úton a Moore-törvény több mint 30 évre szabad utat biztosított a szoftvereknek, pusztán a félvezető folyamatok evolúciója miatt. A számítási hardver minden évben javított teljesítmény/terület/teljesítmény mérőszámokat eredményezett, lehetővé téve a szoftverek komplexitásának bővítését és több képesség biztosítását hátrányok nélkül. Aztán a könnyű győzelmek kevésbé könnyűek lettek. A fejlettebb folyamatok továbbra is magasabb kapuszámot eredményeztek egységnyi területre vetítve, de a teljesítmény és a teljesítmény növekedése csökkenni kezdett. Mióta az innovációval kapcsolatos várakozásaink nem szűntek meg, a hardverarchitektúra fejlődése egyre fontosabbá vált a laza felzárkóztatásában.

Illesztőprogramok a magszám növeléséhez
Az ebbe az irányba tett korai lépésként többmagos CPU-kat használtak a teljes átviteli sebesség felgyorsítására az egyidejű feladatok magok közötti szálakba fűzésével vagy virtualizálásával, szükség szerint csökkentve az energiát az üresjáratban vagy az inaktív magok kikapcsolásával. A többmagos ma már szabványos, és a sokmagos (még több CPU egy chipen) trendje már nyilvánvaló az AWS, Azure, Alibaba és mások felhőplatformjaiban elérhető szerverpéldány-lehetőségekben.
A több-/sokmagos architektúrák előrelépést jelentenek, de a CPU-fürtökön keresztüli párhuzamosság durva szemcsés, és az Amdahl-törvénynek köszönhetően megvannak a maga teljesítmény- és teljesítménykorlátai. Az architektúrák heterogénebbé váltak, és gyorsítókkal bővültek a kép-, hang- és egyéb speciális igényekhez. Az AI-gyorsítók a finomszemcsés párhuzamosságot is előmozdították, áttértek a szisztolés tömbökre és más tartomány-specifikus technikákra. Ami egészen jól működött egészen addig, amíg a ChatGPT meg nem jelent 175 milliárd paraméterrel, miközben a GPT-3 4 billió paraméterű GPT-100-vé fejlődött – ami nagyságrendekkel bonyolultabb, mint a mai mesterséges intelligencia-rendszerek –, még speciálisabb gyorsítási funkciókat kényszerítve az AI-gyorsítókra.
Egy másik fronton az autóipari alkalmazások több érzékelős rendszereit egyetlen SoC-be integrálják a jobb környezettudatosság és a jobb PPA érdekében. Itt az autonómia új szintjei az autóiparban attól függnek, hogy több érzékelőtípusból származó bemeneteket egyesítenek egyetlen eszközön belül, a 2X, 4X vagy 8X replikációs alrendszerekben.
Michał Siwinski (CMO, Arteris) szerint a több mint egy hónapon át tartó, több tervezőcsapattal folytatott megbeszélések az alkalmazások széles skálájáról azt sugallja, hogy ezek a csapatok aktívan fordulnak a magasabb alapszámok felé, hogy teljesítsék a képességekkel, teljesítményekkel és teljesítményekkel kapcsolatos céljaikat. Azt mondja, ők is azt látják, hogy ez a tendencia felgyorsul. A folyamatok előrehaladása továbbra is segít az SoC kapuk számában, de a teljesítmény- és teljesítménycélok teljesítéséért való felelősség most határozottan az építészek kezében van.
Több mag, több összekapcsolás
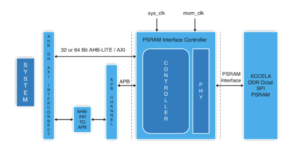
Több mag egy chipen több adatkapcsolatot jelent a magok között. Egy gyorsítón belül a szomszédos feldolgozó elemek között, a helyi gyorsítótárba, a ritka mátrix gyorsítóihoz és egyéb speciális kezelésekhez. Adjon hozzá hierarchikus kapcsolatot a gyorsítócsempék és a rendszerszintű buszok között. Adjon hozzá csatlakozást a súlytároláshoz, a kibontáshoz, a sugárzáshoz, az összegyűjtéshez és az újratömörítéshez. HBM-kapcsolat hozzáadása a gyorsítótárhoz. Ha szükséges, adjon hozzá fúziós motort.
A CPU-alapú vezérlőfürtnek csatlakoznia kell az említett replikált alrendszerek mindegyikéhez és az összes szokásos funkcióhoz – kodekekhez, memóriakezeléshez, biztonsági szigethez és bizalom gyökeréhez, ha szükséges, UCIe-hez, ha több chipet tartalmaz, PCIe-hez nagy sávszélességű I/O-hoz. és Ethernet vagy optikai szál a hálózatépítéshez.
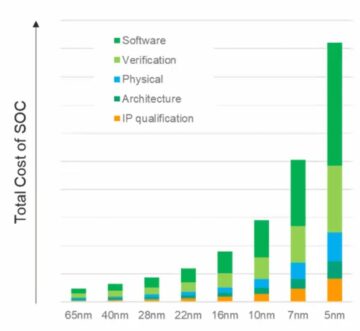
Ez egy csomó összekapcsolódás, amelynek közvetlen következményei vannak a termék értékesíthetőségére nézve. A 16 nm alatti folyamatokban a NoC infrastruktúra most 10-12%-ot tesz ki a területből. Még ennél is fontosabb, hogy a magok közötti kommunikációs főútként jelentős hatással lehet a teljesítményre és a teljesítményre. Valós a veszélye annak, hogy egy nem optimális megvalósítás elpazarolja a várt architektúra teljesítményt és teljesítménynövekedést, vagy ami még rosszabb, számos újratervezési hurok konvergálásához vezet. A jó megvalósítás megtalálása egy összetett SoC alaprajzban azonban továbbra is a lassú próba-hiba optimalizálásokon múlik az amúgy is szűk tervezési ütemtervben. Át kell lépnünk a fizikailag tudatos NoC tervezés felé, hogy garantáljuk a teljes teljesítményt és az energiaellátást az összetett NoC hierarchiákból, és gyorsabbá kell tennünk ezeket az optimalizálásokat.
A fizikailag tudatos NoC-tervek nyomon tartják Moore törvényét
Lehet, hogy Moore törvénye nem halt meg, de a teljesítmény és teljesítmény ma már az architektúrából és a NoC összekapcsolásból fakad, nem pedig a folyamatból. Az architektúra több gyorsítómagot, több gyorsítót a gyorsítókon belül, és több alrendszer-replikációt tesz lehetővé a chipen. Mindegyik növeli a chipen belüli összekapcsolás bonyolultságát. Mivel a tervek növelik a magok számát, és áttérnek a 16 nm-es és az alatti folyamatgeometriákra, az SoC-n és alrendszerein átívelő számos NoC összeköttetés csak akkor tudja támogatni ezekben az összetett tervekben rejlő teljes potenciált, ha a fizikai és időzítési korlátokkal szemben optimálisan valósítják meg őket – a fizikailag tudatos hálózaton keresztül. chip tervezésen.
Ha Ön is aggódik ezek miatt a trendek miatt, érdemes többet megtudnia az Arteris FlexNoC 5 IP technológiáról ITT.
Oszd meg ezt a bejegyzést ezen keresztül:
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://semiwiki.com/artificial-intelligence/326727-interconnect-under-the-spotlight-as-core-counts-accelerate/
- :is
- $ UP
- 100
- a
- Rólunk
- gyorsul
- gyorsuló
- gyorsulás
- gázpedál
- gyorsítók
- át
- aktívan
- fejlett
- előlegek
- ellen
- AI
- AI rendszerek
- Alibaba
- Minden termék
- lehetővé téve
- már
- és a
- megjelent
- alkalmazások
- megfelelő
- építészet
- VANNAK
- TERÜLET
- AS
- At
- hang-
- autóipari
- elérhető
- tudatosság
- AWS
- Égszínkék
- Sávszélesség
- BE
- válik
- lent
- között
- Billió
- rádióadás
- buszok
- by
- cache
- TUD
- képes
- ChatGPT
- csip
- felhő
- Fürt
- CMO
- hogyan
- közlés
- bonyolult
- bonyolultság
- Kiszámít
- egyidejű
- Csatlakozás
- kapcsolatok
- Connectivity
- Következmények
- korlátok
- tovább
- ellenőrzés
- konvergálni
- Mag
- CPU
- VESZÉLY
- dátum
- halott
- szállít
- szállított
- függ
- Design
- tervek
- eszköz
- különböző
- közvetlen
- irány
- megbeszélések
- le-
- hátrányok
- minden
- Korai
- elemek
- Motor
- Környezet
- Még
- Minden
- evolúció
- fejlődik
- Bontsa
- várakozások
- várható
- gyorsabb
- Jellemzők
- megtalálása
- határozottan
- A
- Előre
- Ingyenes
- ból ből
- front
- Tele
- funkciók
- magfúzió
- Nyereség
- Célok
- jó
- garancia
- Kezelés
- kezek
- hardver
- Legyen
- segít
- itt
- Magas
- <p></p>
- Országút
- HTTPS
- kép
- Hatás
- végrehajtás
- végre
- fontos
- javított
- in
- tétlen
- Növelje
- növekvő
- Infrastruktúra
- Innováció
- példa
- integrálása
- IP
- sziget
- IT
- ITS
- ugrás
- Törvény
- TANUL
- szint
- szintek
- határértékek
- helyi
- Sok
- csinál
- vezetés
- március
- Mátrix
- max-width
- Találkozik
- találkozó
- Memory design
- Metrics
- esetleg
- Hónap
- több
- mozog
- mozgó
- többszörös
- Szükség
- szükséges
- igények
- hálózat
- hálózatba
- Új
- számos
- of
- on
- Opciók
- rendelés
- Más
- Egyéb
- saját
- paraméterek
- teljesítmény
- fizikai
- fizikailag
- Platformok
- Plató
- Platón adatintelligencia
- PlatoData
- állás
- potenciális
- hatalom
- Bekapcsolom
- szép
- folyamat
- Folyamatok
- feldolgozás
- Termékek
- tisztán
- meglökött
- Toló
- hatótávolság
- Inkább
- igazi
- csökkentő
- többszörözött
- replikáció
- felelősség
- eredményez
- Lovagol
- gyökér
- Biztonság
- félvezető
- jelentős
- óta
- egyetlen
- laza
- lassú
- kisebb
- So
- szoftver
- ritka mátrix
- specializált
- reflektorfény
- standard
- kezdődött
- Lépés
- Még mindig
- megáll
- tárolás
- javasolja,
- támogatás
- rendszer
- Systems
- feladatok
- csapat
- technikák
- Technológia
- megmondja
- hogy
- A
- Ezek
- Keresztül
- áteresztőképesség
- időzítés
- nak nek
- Ma
- mai
- Végösszeg
- tendencia
- Trends
- Trillió
- Bízzon
- Turning
- típusok
- alatt
- egység
- keresztül
- súly
- JÓL
- ami
- széles
- Széleskörű
- lesz
- Győzelem
- val vel
- belül
- dolgozó
- év
- év
- zephyrnet