A Pandas egy erőteljes és széles körben használt nyílt forráskódú könyvtár az adatok Python használatával történő manipulálására és elemzésére. Egyik kulcsfontosságú jellemzője az adatok csoportosításának képessége a groupby függvény használatával úgy, hogy egy DataFrame-et egy vagy több oszlop alapján csoportokra oszt, majd mindegyikre különböző aggregációs függvényeket alkalmaz.

Kép Unsplash
A groupby A funkció hihetetlenül hatékony, mivel lehetővé teszi nagy adatkészletek gyors összefoglalását és elemzését. Például csoportosíthat egy adatkészletet egy adott oszlop szerint, és kiszámíthatja az egyes csoportok fennmaradó oszlopainak átlagát, összegét vagy számát. Az adatok részletesebb megértése érdekében több oszlop szerint is csoportosíthat. Ezenkívül lehetővé teszi egyéni összesítő függvények alkalmazását, amelyek nagyon hatékony eszközt jelenthetnek összetett adatelemzési feladatokhoz.
Ebből az oktatóanyagból megtudhatja, hogyan használhatja a Pandas csoportby funkcióját különböző típusú adatok csoportosítására és különböző összesítési műveletek végrehajtására. Az oktatóanyag végére képesnek kell lennie arra, hogy ezt a funkciót különféle módokon elemezze és összegezze az adatokat.
A fogalmak belsővé válnak, ha jól gyakoroljuk, és ezt fogjuk tenni a következő lépésben, azaz gyakorlatba ültetni a Pandas groupby funkciót. Használata javasolt a Jupyter Jegyzetfüzet ehhez az oktatóanyaghoz, mivel minden lépésnél láthatja a kimenetet.
Mintaadatok generálása
Importálja a következő könyvtárakat:
- Pandák: Adatkeret létrehozása és a csoport alkalmazása
- Véletlenszerű – Véletlenszerű adatok generálásához
- Pprint – Szótárak nyomtatása
import pandas as pd
import random
import pprint
Ezután inicializálunk egy üres adatkeretet, és minden oszlophoz kitöltjük az értékeket az alábbiak szerint:
df = pd.DataFrame()
names = [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard",
] major = [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology",
] yr_adm = random.sample(list(range(2018, 2023)) * 100, 15)
marks = random.sample(range(40, 101), 15)
num_add_sbj = random.sample(list(range(2)) * 100, 15) df["St_Name"] = names
df["Major"] = random.sample(major * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
df.head()
Bónusztipp – ugyanazt a feladatot tisztább módon végezheti el, ha létrehoz egy szótárt az összes változóból és értékből, majd később adatkeretté konvertálja.
student_dict = { "St_Name": [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard", ], "Major": random.sample( [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology", ] * 100, 15, ), "Year_adm": random.sample(list(range(2018, 2023)) * 100, 15), "Marks": random.sample(range(40, 101), 15), "num_add_sbj": random.sample(list(range(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
Az adatkeret az alábbiak szerint néz ki. A kód futtatásakor néhány érték nem egyezik, mivel véletlenszerű mintát használunk.
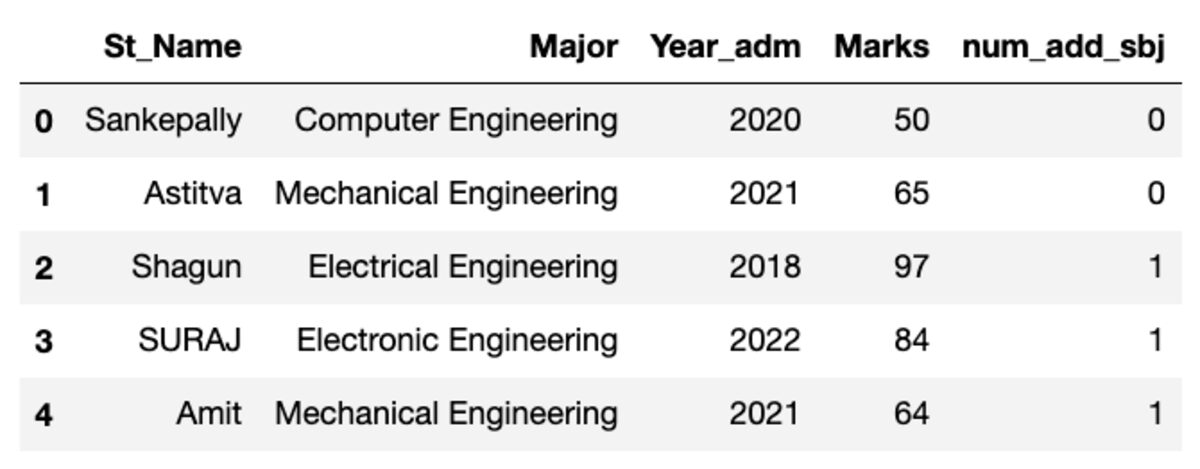
Csoportok készítése
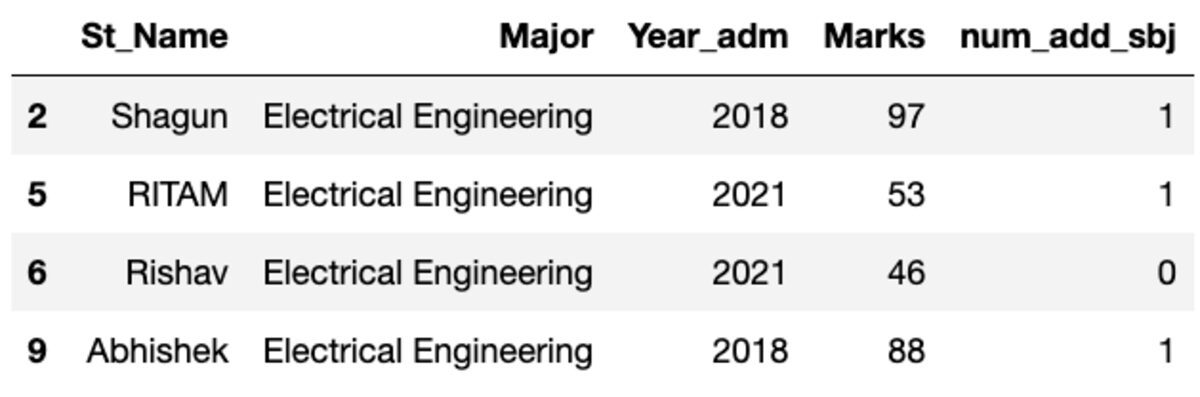
Csoportosítsuk az adatokat a „Fő” tárgy szerint, és alkalmazzuk a csoportszűrőt, hogy megtudjuk, hány rekord tartozik ebbe a csoportba.
groups = df.groupby('Major')
groups.get_group('Electrical Engineering')
Tehát négy hallgató tartozik a villamosmérnök szakra.
Egynél több oszlop szerint is csoportosíthat (ebben az esetben Major és num_add_sbj).
groups = df.groupby(['Major', 'num_add_sbj'])
Vegye figyelembe, hogy az összes összesítő függvény, amely egy oszlopos csoportokra alkalmazható, alkalmazható több oszlopos csoportokra is. Az oktatóanyag további részében összpontosítsunk a különböző típusú összesítésekre, példaként egyetlen oszlopot használva.
Hozzunk létre csoportokat a groupby használatával a „Major” oszlopban.
groups = df.groupby('Major')Közvetlen függvények alkalmazása
Tegyük fel, hogy minden szakon meg szeretné találni az átlagos pontszámokat. Mit csinálnál?
- Válassza a Jelek oszlopot
- Közepes függvény alkalmazása
- Kerekítés funkció alkalmazása a jelek két tizedesjegyre történő kerekítéséhez (opcionális)
groups['Marks'].mean().round(2)
Major
Artificial Intelligence 63.6
Computer Engineering 45.5
Electrical Engineering 71.0
Electronic Engineering 92.0
Mechanical Engineering 64.5
Name: Marks, dtype: float64
adalékanyag
Ugyanezen eredmény elérésének másik módja az alább látható összesítő függvény használata:
groups['Marks'].aggregate('mean').round(2)
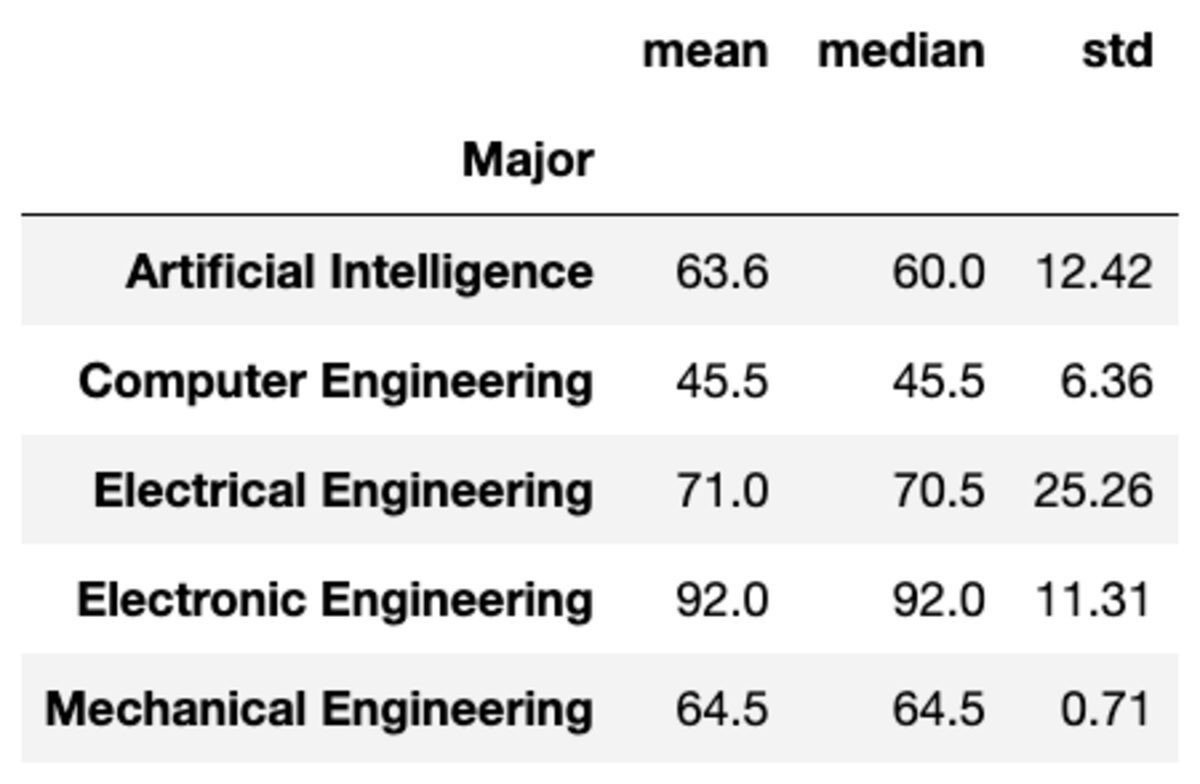
Több aggregációt is alkalmazhat a csoportokra, ha a függvényeket karakterláncok listájaként adja át.
groups['Marks'].aggregate(['mean', 'median', 'std']).round(2)
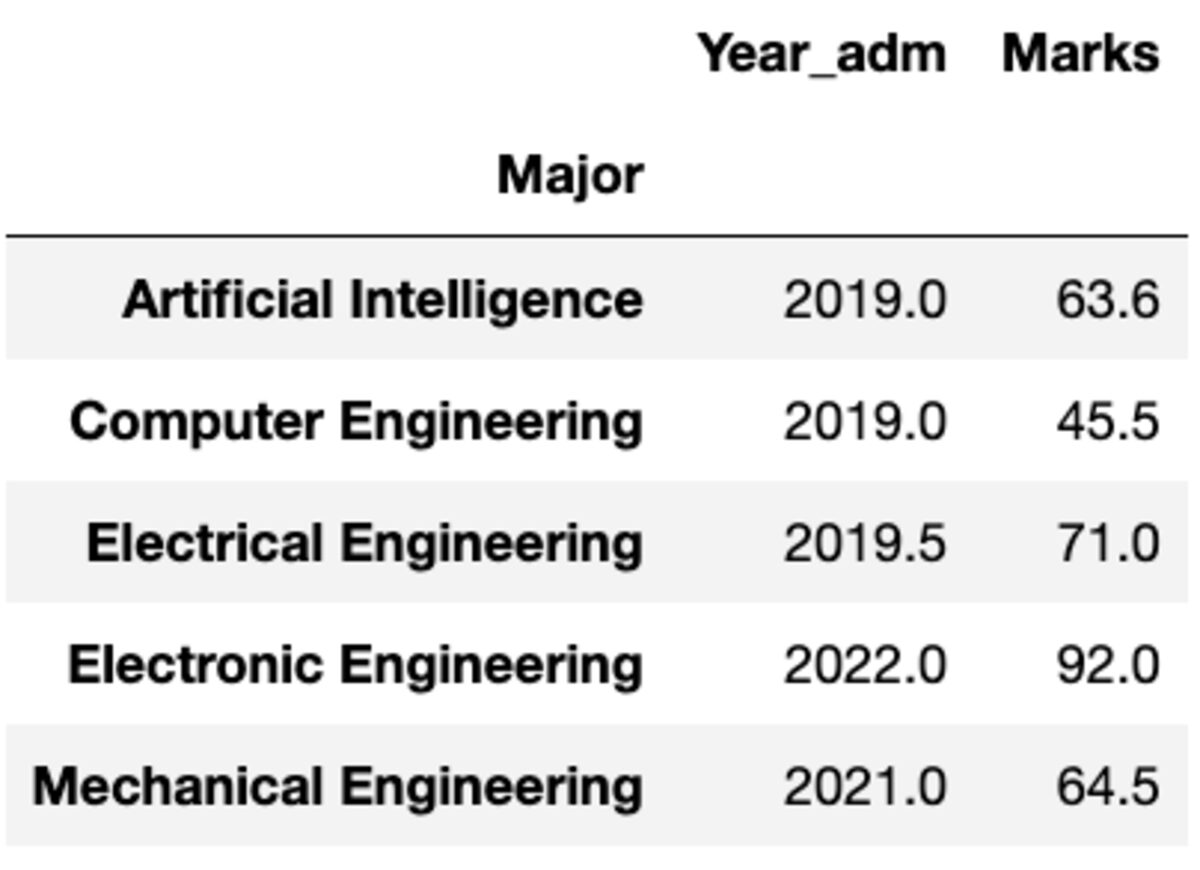
De mi van akkor, ha más függvényt kell alkalmazni egy másik oszlopra. ne aggódj. Ezt az {oszlop: függvény} pár átadásával is megteheti.
groups.aggregate({'Year_adm': 'median', 'Marks': 'mean'})
Átalakítások
Lehetséges, hogy egyéni átalakításokat kell végrehajtania egy adott oszlopban, ami könnyen megvalósítható a groupby() segítségével. Definiáljunk egy szabványos skalárt, amely hasonló a sklearn előfeldolgozó moduljában elérhetőhöz. Az összes oszlopot átalakíthatja a transzformációs metódus meghívásával és az egyéni függvény átadásával.
def standard_scalar(x): return (x - x.mean())/x.std()
groups.transform(standard_scalar)
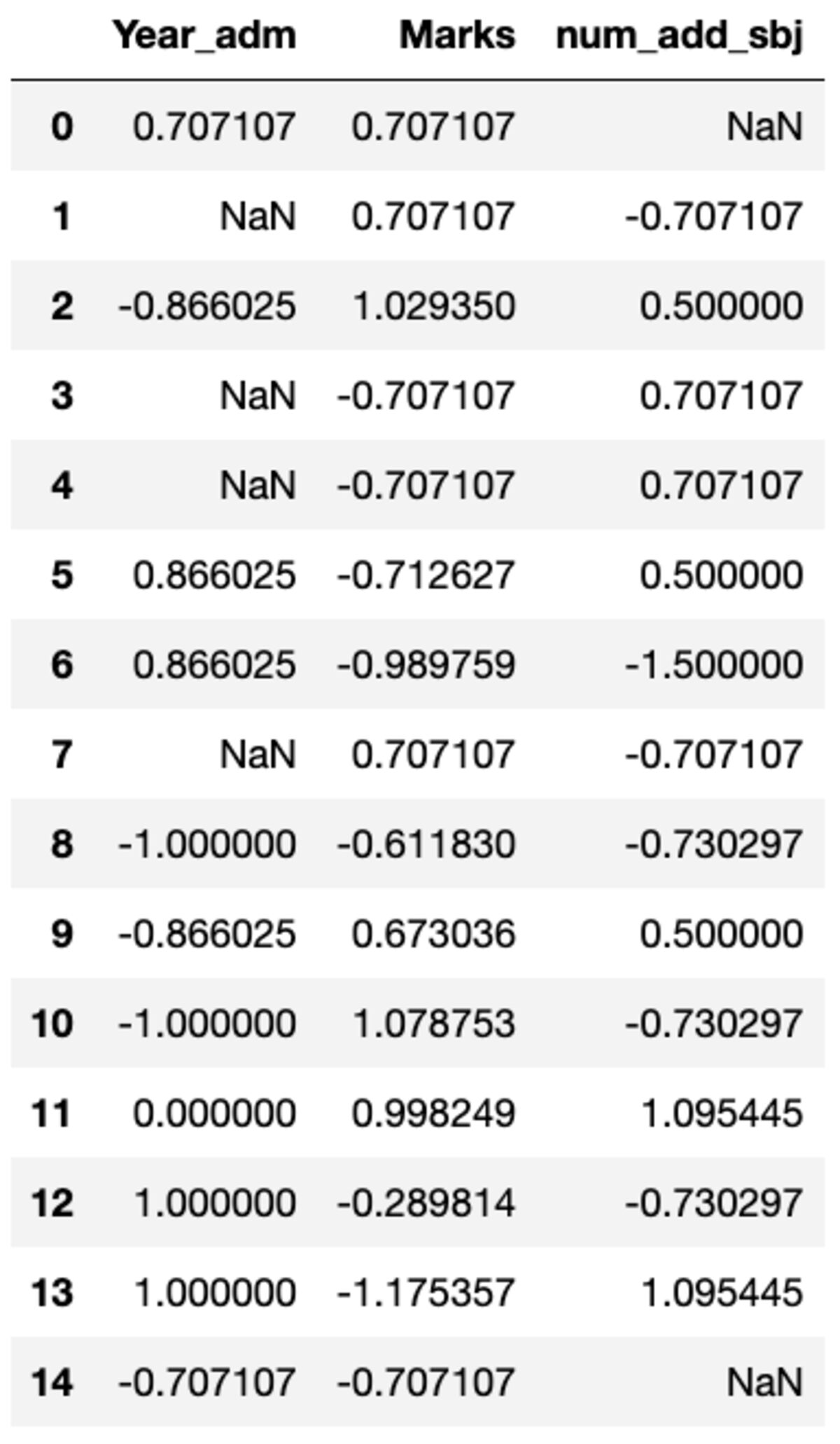
Vegye figyelembe, hogy a „NaN” nulla szórással rendelkező csoportokat jelöl.
Szűrő
Érdemes ellenőrizni, hogy melyik „szak” teljesít alul, vagyis az, ahol az átlagos tanulói „pontszám” kevesebb, mint 60. Ehhez szűrőmódszert kell alkalmaznia olyan csoportokra, amelyekben egy függvény található. Az alábbi kód a lambda funkció a szűrt eredmények eléréséhez.
groups.filter(lambda x: x['Marks'].mean() 60)

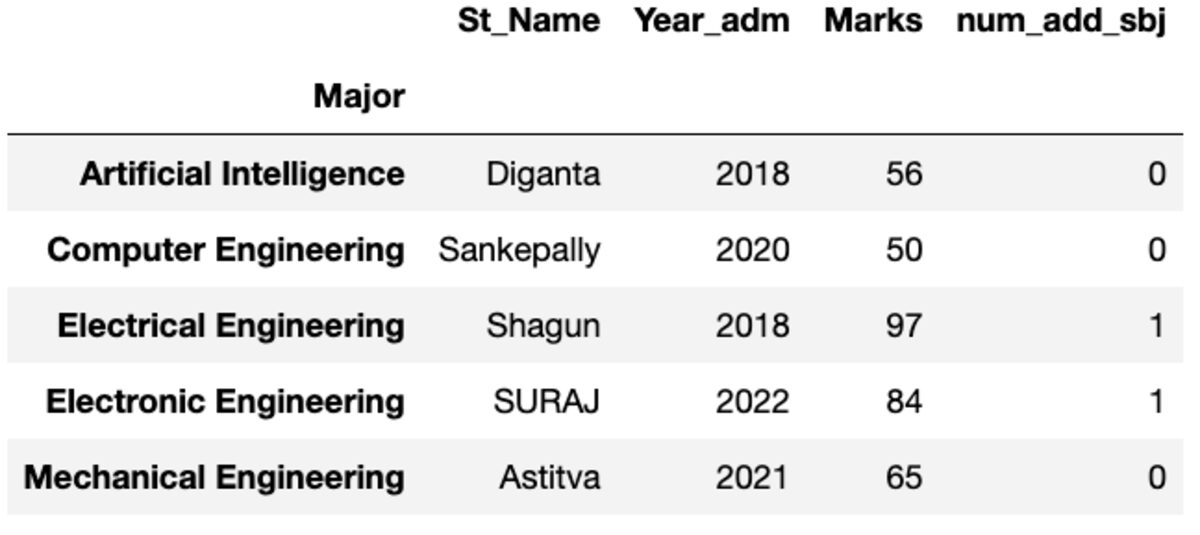
vezetéknév
Megadja az első példányt index szerint rendezve.
groups.first()
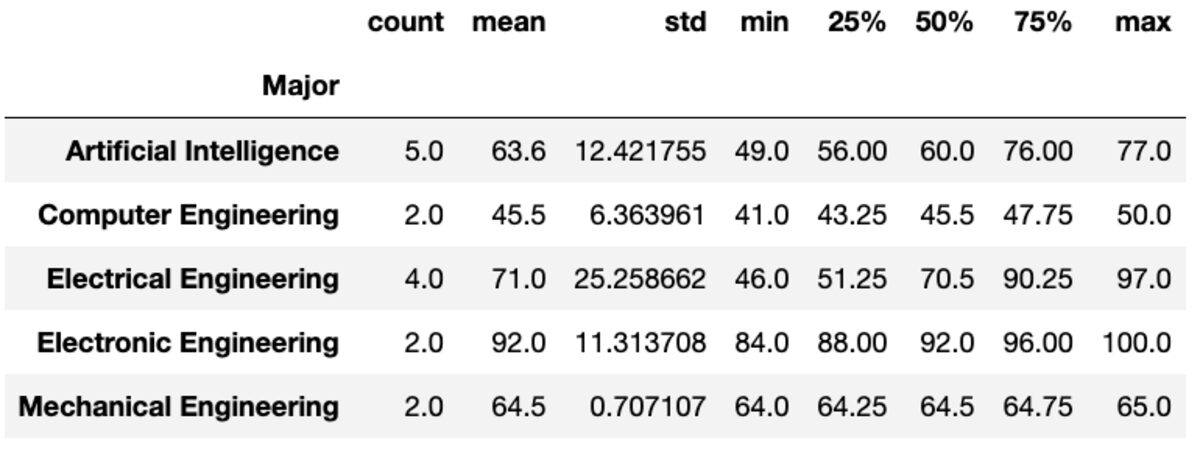
Írja le
A „describe” metódus alapvető statisztikákat ad vissza az adott oszlopokhoz, mint például a count, mean, std, min, max stb.
groups['Marks'].describe()
Méret
A méret, ahogy a neve is sugallja, az egyes csoportok méretét adja vissza a rekordok számában.
groups.size()
Major
Artificial Intelligence 5
Computer Engineering 2
Electrical Engineering 4
Electronic Engineering 2
Mechanical Engineering 2
dtype: int64Gróf és Nunique
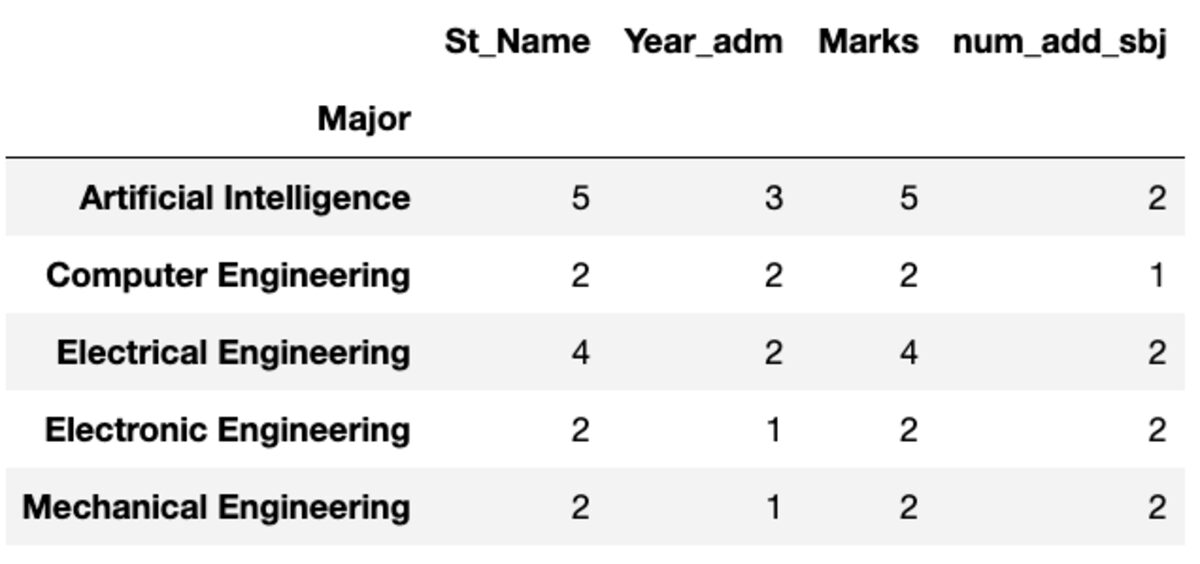
A „Count” az összes értéket, míg a „Nunique” csak az adott csoport egyedi értékeit adja vissza.
groups.count()
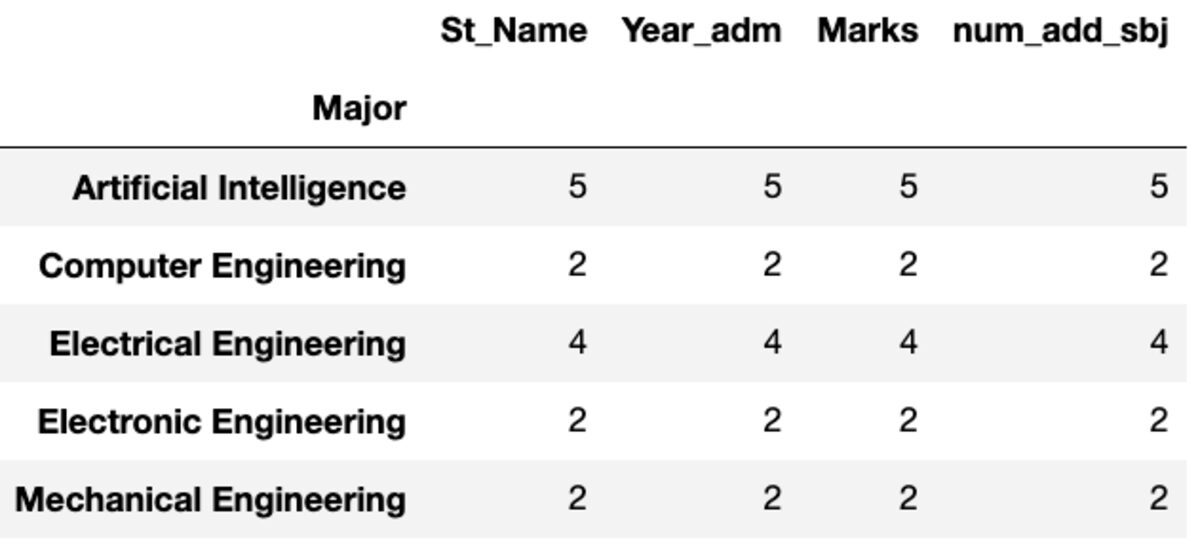
groups.nunique()
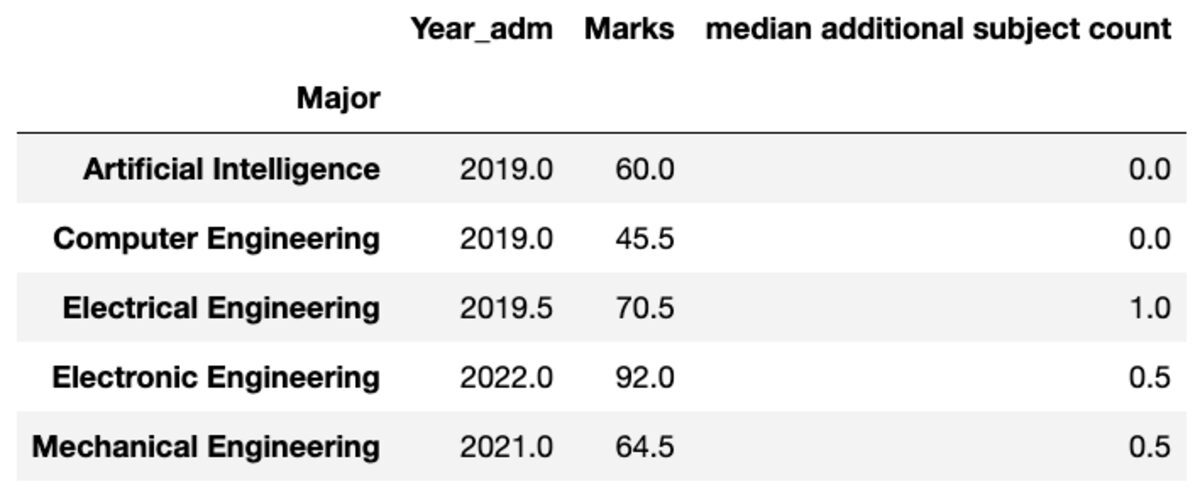
átnevezése
Tetszés szerint át is nevezheti az összesített oszlopok nevét.
groups.aggregate("median").rename( columns={ "yr_adm": "median year of admission", "num_add_sbj": "median additional subject count", }
)
- Tisztázza a csoport célját: Megpróbálja csoportosítani az adatokat egy oszlop szerint, hogy megkapja egy másik oszlop átlagát? Vagy több oszlopra próbálja csoportosítani az adatokat, hogy megkapja az egyes csoportok sorainak számát?
- Az adatkeret indexelésének megértése: A groupby függvény az indexet használja az adatok csoportosítására. Ha oszlop szerint szeretné csoportosítani az adatokat, győződjön meg arról, hogy az oszlop van beállítva indexként, vagy használhatja a .set_index()
- Használja a megfelelő összesítő függvényt: Különféle aggregációs függvényekkel használható, mint a mean(), sum(), count(), min(), max()
- Használja az as_index paramétert: Ha Hamis értékre van állítva, ez a paraméter arra utasítja a pandákat, hogy a csoportosított oszlopokat normál oszlopként használják index helyett.
A groupby()-t más pandafüggvényekkel, például a pivot_table(), a crosstab() és a cut()-szal együtt is használhatja, hogy több betekintést nyerjen az adatokból.
A groupby függvény hatékony eszköz az adatok elemzéséhez és manipulálásához, mivel lehetővé teszi adatsorok csoportosítását egy vagy több oszlop alapján, majd összesített számítások végrehajtását a csoportokon. Az oktatóprogram kódpéldák segítségével mutatta be a groupby függvény használatának különféle módjait. Remélhetőleg megértheti a vele járó különféle lehetőségeket, és azt is, hogy ezek hogyan segítenek az adatelemzésben.
Vidhi Chugh egy mesterséges intelligencia-stratégia és a digitális transzformáció vezetője, aki a termék, a tudomány és a mérnöki tudományok metszéspontjában dolgozik, hogy méretezhető gépi tanulási rendszereket építsen. Díjnyertes innovációs vezető, író és nemzetközi előadó. Az a küldetése, hogy demokratizálja a gépi tanulást, és megtörje a szakzsargont, hogy mindenki részese legyen ennek az átalakulásnak.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://www.kdnuggets.com/2023/01/effectively-pandas-groupby.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-effectively-use-pandas-groupby
- 10
- 100
- 2018
- 2023
- 7
- 9
- a
- képesség
- Képes
- Elérése
- elért
- További
- Ezen kívül
- összesítés
- AI
- Minden termék
- lehetővé teszi, hogy
- elemzés
- elemez
- és a
- Másik
- alkalmazott
- alkalmaz
- Alkalmazása
- megfelelő
- mesterséges
- mesterséges intelligencia
- szerző
- elérhető
- átlagos
- díjnyertes
- alapján
- alapvető
- lent
- biotechnológia
- szünet
- épít
- számít
- hívás
- eset
- ellenőrizze
- világos
- kód
- Oszlop
- Oszlopok
- hogyan
- bonyolult
- számítógép
- Informatika
- teremt
- létrehozása
- szokás
- dátum
- adatelemzés
- adatkészletek
- demokratizálni
- igazolták
- eltérés
- különböző
- digitális
- digitális átalakítás
- közvetlen
- ne
- minden
- könnyen
- hatékonyan
- villamosmérnök
- Elektronikus
- Mérnöki
- stb.
- mindenki
- példa
- példák
- kivonat
- Esik
- Jellemzők
- kitöltése
- szűrő
- Találjon
- vezetéknév
- Összpontosít
- következő
- KERET
- ból ből
- funkció
- funkciók
- generál
- kap
- adott
- ad
- megy
- Csoport
- Csoportok
- hands-on
- segít
- remény
- Hogyan
- How To
- HTML
- HTTPS
- importál
- in
- hihetetlenül
- index
- Innováció
- meglátások
- példa
- helyette
- Intelligencia
- Nemzetközi
- útkereszteződés
- IT
- zsargon
- KDnuggets
- Kulcs
- nagy
- vezető
- TANUL
- tanulás
- könyvtárak
- könyvtár
- Lista
- MEGJELENÉS
- gép
- gépi tanulás
- fontos
- csinál
- Manipuláció
- sok
- Mérkőzés
- max
- mechanikai
- gépészet
- közepes
- módszer
- Küldetés
- modul
- több
- többszörös
- név
- nevek
- Szükség
- következő
- szám
- ONE
- nyílt forráskódú
- Művelet
- Opciók
- Más
- pandák
- paraméter
- rész
- különös
- Múló
- teljesít
- Helyek
- Plató
- Platón adatintelligencia
- PlatoData
- erős
- Termékek
- biztosít
- cél
- Piton
- gyorsan
- véletlen
- ajánlott
- nyilvántartások
- szabályos
- megmaradó
- jelentése
- megköveteli,
- REST
- eredményez
- Eredmények
- visszatérés
- Visszatér
- Richard
- körül
- futás
- azonos
- skálázható
- TUDOMÁNYOK
- készlet
- kellene
- mutatott
- hasonló
- egyetlen
- Méret
- néhány
- Hangszóró
- különleges
- standard
- statisztika
- Lépés
- Stratéga
- diák
- Diákok
- tárgy
- javasolja,
- összegez
- Systems
- Feladat
- feladatok
- megmondja
- feltételek
- A
- típus
- nak nek
- szerszám
- Átalakítás
- Átalakítás
- transzformációk
- oktatói
- típusok
- megértés
- egyedi
- használ
- Értékek
- különféle
- módon
- Mit
- ami
- lesz
- dolgozó
- lenne
- X
- év
- A te
- zephyrnet
- nulla






