Szervezetek szerte a világon – mind a profitorientált, mind a nonprofit szervezetek – az adatelemzést keresik az üzleti teljesítmény javítása érdekében. Megállapítások a McKinsey felmérés azt mutatják, hogy az adatvezérelt szervezetek 23-szor nagyobb valószínűséggel szereznek ügyfeleket, hatszor nagyobb valószínűséggel megtartanak ügyfeleket, és 19-szer nagyobb a nyereségességük [1]. Az MIT kutatása megállapította, hogy a digitálisan érett cégek 26%-kal jövedelmezőbbek társaiknál [2]. Sok vállalat azonban – annak ellenére, hogy rengeteg adatot tartalmaz – küzd az adatelemzés bevezetésével az üzleti igények, a rendelkezésre álló képességek és az erőforrások közötti ellentmondásos prioritások miatt. A Gartner kutatása megállapította, hogy az adat- és elemzési projektek több mint 85%-a meghiúsul [3] és a közös jelentés Az IBM és a Carnegie Melon eredményei azt mutatják, hogy egy szervezetben az adatok 90%-át soha nem használják fel sikeresen semmilyen stratégiai célra [4].
Ezzel a háttérrel bevezetjük az „adatelemző szövet (DAF)” koncepciót, mint olyan ökoszisztémát vagy struktúrát, amely lehetővé teszi az adatelemzés hatékony működését (a) üzleti igények vagy célok, (b) rendelkezésre álló képességek, például emberek/készségek alapján. , folyamatok, kultúra, technológiák, betekintések, döntéshozatali kompetenciák és egyebek, valamint (c) erőforrások (vagyis olyan összetevők, amelyekre egy vállalkozásnak szüksége van a vállalkozás működtetéséhez).
Az adatelemzési szövet bevezetésének elsődleges célja, hogy választ adjunk erre az alapvető kérdésre: „Mi kell ahhoz, hogy hatékonyan építsünk fel egy döntést lehetővé tevő rendszert Data Science algoritmusok az üzleti teljesítmény mérésére és javítására?” Az adatelemzési szövetet és annak öt kulcsfontosságú megnyilvánulását az alábbiakban mutatjuk be és tárgyaljuk.
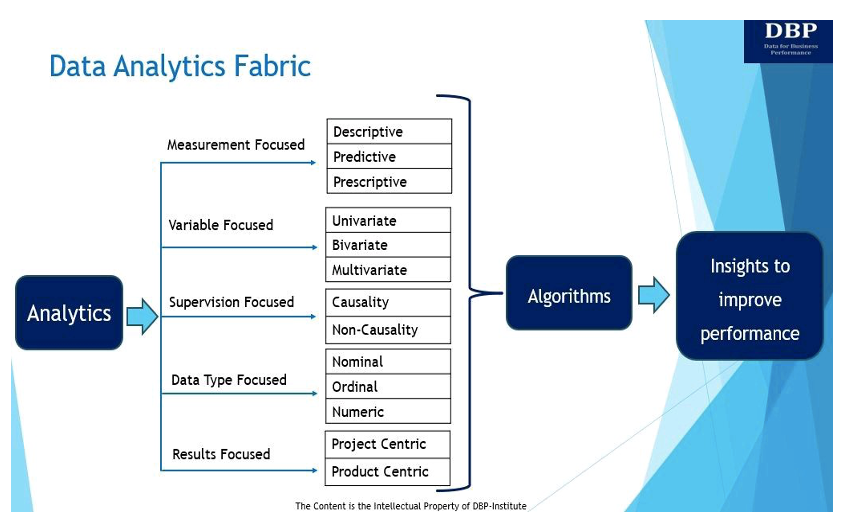
1. Mérés-központú
Az analitika lényege az, hogy adatokat használjunk az üzleti teljesítmény mérésére és javítására [5]. Három fő típusú elemzés létezik az üzleti teljesítmény mérésére és javítására:
- Leíró elemzés felteszi a kérdést: "Mi történt?" A leíró elemzést a történelmi adatok elemzésére használják feltáró, asszociatív és következtetéses adatelemzési technikák segítségével minták, trendek és kapcsolatok azonosítására. A feltáró adatelemzési technikák az adatsorokat elemzik és összegzik. Az asszociatív leíró elemzés megmagyarázza a változók közötti kapcsolatot. Következtető leíró adatelemzés arra szolgál, hogy a mintaadatkészlet alapján egy nagyobb populációra vonatkozó tendenciákat vonjunk le vagy vonjunk le.
- Prediktív elemzés megnézi a választ arra a kérdésre: „Mi fog történni?” Alapvetően a prediktív analitika az adatok felhasználásának folyamata a jövőbeli trendek és események előrejelzésére. A prediktív elemzés elvégezhető manuálisan (analitikus által vezérelt prediktív elemzésként) vagy a gépi tanulási algoritmusok (más néven adatvezérelt prediktív elemzés). Akárhogy is, a történelmi adatokat a jövőbeli előrejelzések készítésére használják fel.
- Vényköteles elemzés segít megválaszolni a kérdést: „Hogyan tudjuk megvalósítani?” Alapvetően az előíró analitika a legjobb cselekvési módot ajánlja az optimalizálási és szimulációs technikák használatával történő előrelépéshez. A prediktív elemzés és az előíró elemzés általában együtt jár, mert a prediktív elemzés segít megtalálni a lehetséges eredményeket, míg az előíró elemzés ezeket az eredményeket vizsgálja, és további lehetőségeket talál.
2. Változó-fókuszált
Az adatok a rendelkezésre álló változók száma alapján is elemezhetők. Ebben a tekintetben a változók száma alapján az adatelemzési technikák lehetnek egyváltozósak, kétváltozósak vagy többváltozósak.
- Egyváltozós elemzés: Az egyváltozós elemzés magában foglalja az egyetlen változóban jelenlévő mintázat elemzését a centralitás (átlag, medián, módus stb.) és a variáció (szórás, standard hiba, variancia stb.) mérőszámai segítségével.
- Kétváltozós elemzés: Két olyan változó van, ahol az elemzés az okokra és a két változó közötti kapcsolatra vonatkozik. Ez a két változó lehet egymástól függő vagy független. A korrelációs technika a leggyakrabban használt kétváltozós elemzési technika.
- Többváltozós elemzés: Ezt a technikát kettőnél több változó elemzésére használják. Többváltozós környezetben általában a prediktív analitikai arénában dolgozunk, és a legtöbb jól ismert gépi tanulási (ML) algoritmus, mint például a lineáris regresszió, a logisztikus regresszió, a regressziós fák, a támogatási vektorgépek és a neurális hálózatok jellemzően többváltozósra alkalmazzák. beállítás.
3. Felügyelet-központú
Az adatelemzési szövet harmadik típusa a bemeneti adatok vagy független változó adatok betanításával foglalkozik, amelyeket egy adott kimenethez (azaz a függő változóhoz) jelöltek meg. Alapvetően a független változó az, amelyet a kísérletező irányít. A függő változó az a változó, amely a független változó hatására változik. A felügyeletre összpontosító DAF két típus egyike lehet.
- Kauzalitás: A felcímkézett adatok, akár automatikusan, akár manuálisan generálódnak, elengedhetetlenek a felügyelt tanuláshoz. A címkézett adatok lehetővé teszik egy függő változó világos definiálását, majd a prediktív analitikai algoritmus dolga, hogy olyan AI/ML eszközt építsen, amely kapcsolatot épít ki a címke (függő változó) és a független változók halmaza között. Az a tény, hogy határozottan elhatároljuk a függő változó fogalmát és a független változók halmazát, megengedjük magunknak, hogy bevezessük az „oksági összefüggés” kifejezést, hogy a legjobban megmagyarázzuk a kapcsolatot.
- Nem okozati összefüggés: Amikor a „szupervízió-fókuszált” dimenziót jelöljük, akkor a „szupervízió hiányát” is értjük, és ez a nem oksági modelleket hozza a vitába. A nem oksági modellek említést érdemelnek, mert nem igényelnek címkézett adatokat. Az alapvető technika itt a klaszterezés, a legnépszerűbb módszerek pedig a k-Means és a Hierarchical Clustering.
4. Adattípus-központú
Az adatelemzési szerkezetnek ez a dimenziója vagy megnyilvánulása a három különböző típusú adatváltozóra összpontosít, amelyek mind a független, mind a függő változókhoz kapcsolódnak, amelyeket az adatelemzési technikákban használnak a betekintések származtatására.
- Névleges adatok adatok címkézésére vagy kategorizálására használják. Ez nem tartalmaz számértéket, ezért névleges adatokkal nem lehet statisztikai számításokat végezni. A névleges adatok például a nem, a termékleírás, az ügyfél címe és hasonlók.
- Sorozati vagy rangsorolt adatok az értékek sorrendje, de az egyes értékek közötti különbségek nem igazán ismertek. Gyakori példa erre a vállalatok rangsorolása piaci kapitalizáció, szállítói fizetési feltételek, ügyfél-elégedettségi pontszámok, szállítási prioritás stb. alapján.
- Numerikus adatok nem igényel bemutatást, és számszerű. Ezek a változók a legalapvetőbb adattípusok, amelyek minden típusú algoritmus modellezésére használhatók.
5. Eredményközpontú
Az ilyen típusú adatelemzési szövet azt vizsgálja, hogy az elemzésből származó betekintésekből milyen módon lehet üzleti értéket teremteni. Az elemzés kétféleképpen növelheti az üzleti értéket, ezek pedig termékek vagy projektek. Míg a termékeknek további következményekkel kell számolniuk a felhasználói élmény és a szoftverfejlesztés körül, a modell levezetéséhez végzett modellezési gyakorlat hasonló lesz mind a projektben, mind a termékben.
- A adatelemző termék egy újrafelhasználható adateszköz, amely a vállalkozás hosszú távú igényeit szolgálja ki. Adatokat gyűjt a releváns adatforrásokból, biztosítja az adatok minőségét, feldolgozza azokat, és bárki számára hozzáférhetővé teszi, akinek szüksége van rá. A termékeket jellemzően személyek számára tervezték, és több életciklus-szakaszuk vagy iterációjuk van, amelyeknél a termékérték realizálódik.
- A adatelemző projekt egy adott vagy egyedi üzleti igény kielégítésére készült, és meghatározott vagy szűk felhasználói bázissal vagy céllal rendelkezik. Alapvetően a projekt egy átmeneti törekvés, amelynek célja a megoldás egy meghatározott terjedelemben, a költségvetésen belül és időben történő szállítása.
A világ gazdasága drámai módon átalakul az elkövetkező években, mivel a szervezetek egyre gyakrabban használják majd az adatokat és az elemzéseket, hogy betekintést nyerjenek, és döntéseket hozzanak az üzleti teljesítmény mérésére és javítására. McKinsey azt találta, hogy a betekintés-vezérelt vállalatok az EBITDA (kamat, adó, értékcsökkenés és amortizáció előtti eredmény) 25%-os növekedéséről számolnak be [5]. Sok szervezet azonban nem sikeres az adatok és az elemzések kihasználásában az üzleti eredmények javítása érdekében. De nincs egyetlen szabványos módszer vagy megközelítés az adatelemzés biztosítására. Az adatelemzési megoldások telepítése vagy megvalósítása az üzleti céloktól, képességektől és erőforrásoktól függ. A DAF és az itt tárgyalt öt megjelenési formája lehetővé teszi az elemzések hatékony alkalmazását az üzleti igények, a rendelkezésre álló képességek és erőforrások alapján.
Referenciák
- mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/five-facts-how-customer-analytics-boosts-corporate-performance
- ide.mit.edu/insights/digitally-mature-firms-are-26-more-profitable-than-their-their-their-
- gartner.com/en/newsroom/press-releases/2018-02-13-gartner-says-nearly-half-of-cios-are-planning-to-deploy-artificial-intelligence
- forbes.com/sites/forbestechcouncil/2023/04/04/three-key-misconceptions-of-data-quality/?sh=58570fc66f98
- Southekal, Prashanth, „Analytics Best Practices”, Technics, 2020
- mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/insights-to-impact-creating-and-sustaining-data-driven-commercial-growth
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Autóipar / elektromos járművek, Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- ChartPrime. Emelje fel kereskedési játékát a ChartPrime segítségével. Hozzáférés itt.
- BlockOffsets. A környezetvédelmi ellentételezési tulajdon korszerűsítése. Hozzáférés itt.
- Forrás: https://www.dataversity.net/introducing-the-data-analytics-fabric-concept/
- :van
- :is
- :nem
- $ UP
- 1
- 19
- 23
- a
- Rólunk
- hozzáférhető
- szerez
- Akció
- További
- cím
- AI / ML
- algoritmus
- algoritmusok
- Minden termék
- lehetővé
- lehetővé teszi, hogy
- Is
- amortizáció
- an
- elemzés
- analitika
- elemez
- elemzett
- elemzése
- és a
- válasz
- bármilyen
- bárki
- alkalmazott
- megközelítés
- VANNAK
- Arena
- körül
- AS
- vagyontárgy
- At
- automatikusan
- elérhető
- b
- háttér
- bázis
- alapján
- alapvető
- Alapvetően
- BE
- mert
- óta
- előtt
- hogy
- lent
- BEST
- között
- mindkét
- Bring
- költségvetés
- épít
- üzleti
- üzleti teljesítmény
- de
- by
- TUD
- képességek
- tőkésítés
- kategorizálása
- Okoz
- Centrality
- Változások
- világosan
- csoportosítás
- összegyűjti
- COM
- érkező
- Közös
- általában
- Companies
- alkatrészek
- koncepció
- megállapítja,
- lefolytatott
- Ellentmondó
- ellenőrzések
- Mag
- Összefüggés
- tudott
- tanfolyam
- kultúra
- vevő
- Vevői elégedettség
- Ügyfelek
- dátum
- adatelemzés
- Adatelemzés
- adatminőség
- adatkészlet
- adatkészletek
- adatalapú
- ADATVERZITÁS
- Ajánlatok
- Döntéshozatal
- határozatok
- meghatározott
- meghatározott
- szállít
- szállított
- kézbesítés
- függő
- függ
- telepített
- bevetés
- értékcsökkenés
- Származtatott
- leírás
- megérdemel
- tervezett
- Ellenére
- eltérés
- különbségek
- különböző
- digitálisan
- Dimenzió
- tárgyalt
- vita
- különböző
- do
- nem
- csinált
- drámaian
- hajtott
- két
- e
- minden
- Kereset
- EBITDA
- gazdaság
- ökoszisztéma
- hatékonyan
- bármelyik
- lehetővé
- lehetővé teszi
- törekvés
- Mérnöki
- biztosítja
- hiba
- alapvető
- események
- példák
- Gyakorol
- tapasztalat
- Magyarázza
- Elmagyarázza
- Feltáró adatelemzés
- szövet
- tény
- FAIL
- Találjon
- megállapítások
- leletek
- cégek
- öt
- koncentrál
- A
- Forbes
- Előrejelzés
- Előre
- talált
- ból ből
- funkció
- alapvető
- jövő
- Gartner
- nem
- generált
- Go
- cél
- történik
- történt
- Legyen
- segít
- ennélfogva
- itt
- történeti
- azonban
- HTTPS
- i
- IBM
- azonosítani
- végre
- végrehajtás
- javul
- javított
- javuló
- in
- Növeli
- egyre inkább
- független
- jelez
- bemenet
- meglátások
- szándékolt
- kamat
- bevezet
- bevezetéséről
- Bevezetés
- vonja
- jár
- IT
- iterációk
- ITS
- Kulcs
- ismert
- Címke
- címkézés
- nagyobb
- tanulás
- erőfölény
- életciklus
- mint
- Valószínű
- hosszú lejáratú
- keres
- MEGJELENÉS
- gép
- gépi tanulás
- gép
- Fő
- csinál
- KÉSZÍT
- kézzel
- sok
- piacára
- Piac tőkésítés
- Anyag
- érett
- max-width
- Lehet..
- McKinsey
- jelent
- intézkedés
- intézkedések
- említ
- mód
- MIT
- ML
- Mód
- modell
- modellezés
- modellek
- több
- a legtöbb
- Legnepszerubb
- mozgó
- többszörös
- Szükség
- igények
- hálózatok
- ideg-
- neurális hálózatok
- soha
- nem
- nonprofit
- fogalom
- szám
- célok
- of
- on
- ONE
- működik
- optimalizálás
- Opciók
- or
- érdekében
- szervezet
- szervezetek
- Más
- mi
- magunkat
- eredmények
- teljesítmény
- felett
- különös
- Mintás
- minták
- fizetés
- teljesítmény
- Plató
- Platón adatintelligencia
- PlatoData
- Népszerű
- népesség
- lehetséges
- potenciális
- Tippek
- jósló
- Prediktív elemzés
- Prediktív elemzés
- be
- elsődleges
- prioritás
- folyamat
- Folyamatok
- Termékek
- Termékek
- Nyereség
- nyereséges
- program
- projektek
- cél
- világítás
- kérdés
- elágazások
- rangsorolt
- Ranking
- realizált
- tényleg
- ajánlja
- tekintik
- regresszió
- összefüggő
- kapcsolat
- Kapcsolatok
- jelentést
- szükség
- kötelező
- Tudástár
- válasz
- megtartása
- újrahasználható
- elégedettség
- hatálya
- pontszámok
- szolgál
- készlet
- Szettek
- beállítás
- mutatott
- Műsorok
- hasonló
- tettetés
- egyetlen
- SIX
- So
- szoftver
- szoftverfejlesztés
- megoldások
- Megoldások
- forrás
- Források
- állapota
- standard
- statisztikai
- Stratégiai
- struktúra
- Küzdelem
- sikeres
- sikeresen
- ilyen
- összegez
- felügyelt tanulás
- felügyelet
- támogatás
- rendszer
- Adók
- technikák
- Technologies
- ideiglenes
- kifejezés
- feltételek
- mint
- hogy
- A
- a világ
- azok
- akkor
- Ott.
- Ezek
- ők
- Harmadik
- ezt
- azok
- három
- Keresztül
- idő
- alkalommal
- nak nek
- együtt
- szerszám
- Képzések
- Átalakítás
- Fák
- Trends
- kettő
- típus
- típusok
- jellemzően
- egyedi
- használ
- használt
- használó
- User Experience
- segítségével
- érték
- Értékek
- változó
- eladó
- Út..
- módon
- we
- jól ismert
- amikor
- vajon
- ami
- míg
- WHO
- lesz
- val vel
- belül
- világ
- világ
- lenne
- év
- zephyrnet









