A Standard Scaler segítségével normálissá tesszük adatainkat, és egy szórási grafikont ábrázoltunk.
Most importáljuk a DBSCAN-t, hogy pontokat adjunk a fürtöknek. Ha nem sikerül, -1-et mutat.
Most megvannak az eredmények, de hogyan ellenőrizzük, hogy melyik érték min, max és van-e -1 értékünk? Az arg min értékkel ellenőrizzük a klaszter legkisebb értékét.
Az eredményből láthatunk hat értéket, amelyek -1.
Rajzoljunk most egy szórási grafikont.
Az általunk alkalmazott fenti módszerek egyváltozós kiugró értékekre vonatkoznak.
A többváltozós kiugró értékek észleléséhez meg kell értenünk a többváltozós kiugró értékeket.
Például vesszük az Autó leolvasását. Láttunk két leolvasási mérőt, az egyiket a kilométer-számlálóhoz, amely rögzíti vagy méri a jármű mozgási sebességét, a második pedig a fordulatszámot, amely az autó kerekének percenkénti fordulatszámát rögzíti.
Tegyük fel, hogy a kilométer-számláló 0-60 mph tartományban mutat, és 0-750 fordulat/perc. Feltételezzük, hogy az összes érkező értéknek korrelálnia kell egymással. Ha a kilométer-számláló 50-es fordulatszámot mutat, a fordulatszám pedig 0-t, akkor a leolvasások hibásak. Ha a kilométer-számláló nullánál nagyobb értéket mutat, az azt jelenti, hogy az autó mozgott, tehát a fordulatszámnak magasabbnak kell lennie, de esetünkben 0 értéket mutat. azaz többváltozós kiugró értékek.
C. Mahalanobis távolsági módszer
A DBSCAN-ban euklideszi távolságmérőket használtunk, de ebben az esetben a Mahalanobis távolságmódszerről beszélünk. A Mahalanobis távolságot is használhatjuk a DBSCAN segítségével.
DBSCAN(eps=0.5, min_samples=3, metric='mahalanobis', metric_params={'V':np.cov(X)}, algorithm='brute', leaf_size=30, n_jobs=-1)Miért alkalmatlan az euklideszi entitások számára, amelyek egymással korrelálnak? Az euklideszi távolság nem talál, vagy hibás adatokat ad arról, hogy milyen közel van a két pont.
A Mahalanobis módszer a pontok és az eloszlás közötti távolságot használja, amely tiszta adat. Az euklideszi távolság gyakran két pont között van, és a z-pontszámát x mínusz átlaggal számítják ki, és elosztják a szórással. Mahalanobisban a z-pontszám x mínusz az átlag, osztva a kovarianciamátrixszal.
Tehát milyen hatása van a kovarianciamátrixszal való osztásnak? A kovarianciaértékek magasak lesznek, ha az adatkészletben lévő változók erősen korrelálnak.
Hasonlóképpen, ha a kovariancia értékek alacsonyak, a távolság nem csökken jelentősen, ha az adatok nem korrelálnak. Olyan jól működik, hogy a változók léptékével és korrelációjával is foglalkozik.
Kód
Az adatkészlet innen vehető Anomaly-/caret.csv at main · aster28/Anomaly- (github.com)
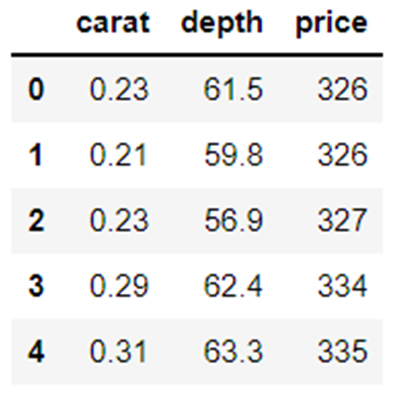
df = pd.read_csv('caret.csv').iloc[:, [0,4,6]] df.head()
A függvény távolságát a következőképpen határoztuk meg: x= nincs, adat= nincs, és kovariancia = nincs. A függvényen belül az adatok átlagát vettük, és ott az érték kovariancia értékét használtuk. Ellenkező esetben a kovarianciamátrixot számítjuk ki. A T a transzponálást jelenti.
Például, ha a tömb mérete öt vagy hat, és azt szeretné, hogy két változóban legyen, akkor transzponálni kell a mátrixot.
np.random.multivariate_normal(mean, cov, size = 5)
array([[ 0.0509196, 0.536808 ], [ 0.1081547, 0.9308906], [ 0.4545248, 1.4000731], [ 0.9803848, 0.9660610], [ 0.8079491 , 0.9687909]])np.random.multivariate_normal(mean, cov, size = 5).T
array([[ 0.0586423, 0.8538419, 0.2910855, 5.3047358, 0.5449706], [ 0.6819089, 0.8020285, 0.7109037, 0.9969768, -0.7155739]])Az sp.linalg-ot használtuk, ami egy lineáris algebra, és különböző funkciókat tartalmaz a lineáris algebrán. A mátrix megfordítására szolgáló inv funkcióval rendelkezik. NumPy pont, mint a mátrix szorzásának eszköze.
import scipy mint sp def distance(x=nincs, adat=nincs, cov=nincs): x_m = x - np.mean(data) ha nem cov: cov = np.cov(data.values.T) inv_cov = sp. linalg.inv(cov) left = np.pont(x_m, inv_cov) m_distance = np.pont(left, x_m.T) return m_distance.diagonal() df_g= df[['karát', 'mélység', 'ár' ]].head(50) df_g['m_distance'] = távolság(x=df_g, adat=df[['karát', 'mélység', 'ár']]) df_g.head()

B. Tukey módszer a kiugró értékek kimutatására
A Tukey módszert gyakran Box and Whisker vagy Box plot módszernek is nevezik.
A Tukey módszer a felső és alsó tartományt használja.
Felső tartomány = 75. Percentilis -k*IQR
Alsó tartomány = 25. Percentilis + k* IQR

Nézzük meg Titanic adatainkat életkor változóval egy dobozdiagram segítségével.
sns.boxplot(titanic['age'].values)
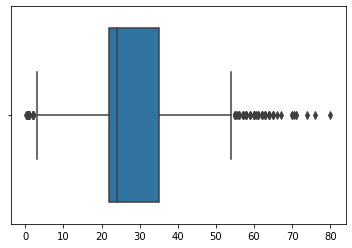
A képen láthatjuk, hogy a Seaborn által készített box blot azt mutatja, hogy 55 és 80 év között sok pont a kvartiliseken belüli kiugró érték. Az alsó és felső tartományt az outliers_detect függvény segítségével észleljük.
def outliers_detect(x, k = 1.5): x = np.array(x).copy().astype(float) first = np.quantile(x, .25) third = np.quantile(x, .75) # IQR számítás iqr = harmadik - első #Felső tartomány és alsó tartomány alsó = első - (k * iqr) felső = harmadik + (k * iqr) vissza alsó, felső
outliers_detect(titanic['age'], k = 1.5)
(2.5, 54.5)
D. PyCaret észlelése
Ugyanazt az adatkészletet fogjuk használni a PyCaret általi észleléshez.
from pycaret.anomaly import * setup_anomaly_data = setup(df)
A Pycaret egy nyílt forráskódú gépi tanulás, amely nem felügyelt tanulási modellt használ a kiugró értékek észlelésére. Van egy get_data metódusa magában a pycaret-ben lévő adatkészlet használatához, set_up az észlelés előtti előfeldolgozási feladathoz, általában adatkeretet vesz fel, de számos egyéb funkcióval is rendelkezik, például az ignore_features stb.
Más módszerek create_model egy algoritmus használatához. Először az Isolation Forestet fogjuk használni.
ifor = create_model("iforest") plot_model(ifor) ifor_predictions = előrejelzés_modell(ifor, data = df) print(ifor_predictions) ifor_anomaly = ifor_predictions[ifor_predictions["Anomália"] == 1] print(ifor_anomaly()) print(.head()) ifor_anomaly.shape)
Az 1-es anomália kiugró értékeket jelez, a 0-ás anomália pedig nem mutat kiugró értékeket.

A sárga szín itt a kiugró értékeket jelzi.
Most pedig lássunk egy másik algoritmust, a K Nearest Neighbors (KNN)
knn = create_model("knn") plot_model(knn) knn_pred = előrejelzés_modell(knn, data = df) print(knn_pred) knn_anomaly = knn_pred[knn_pred["Anomália"] == 1] knn_anomaly.head.

Most egy klaszterezési algoritmust fogunk használni.
clus = create_model("cluster") plot_model(clus) clus_pred = ennusta_modell(clus, data = df) print(clus_pred) clus_anomaly = clus_predictions[clus_pred["Anomália"] == 1] print(clus_anomaly.head()) clus._anomaly. alak

E. Anomália észlelése PyOD segítségével
A PyOD egy python könyvtár a többváltozós adatok kiugró értékeinek észlelésére. Felügyelt és felügyelet nélküli tanuláshoz egyaránt jó.
innen: pyod.models.iforest import IForest innen: pyod.models.knn import KNN
Importáltuk a könyvtárat és az algoritmust.
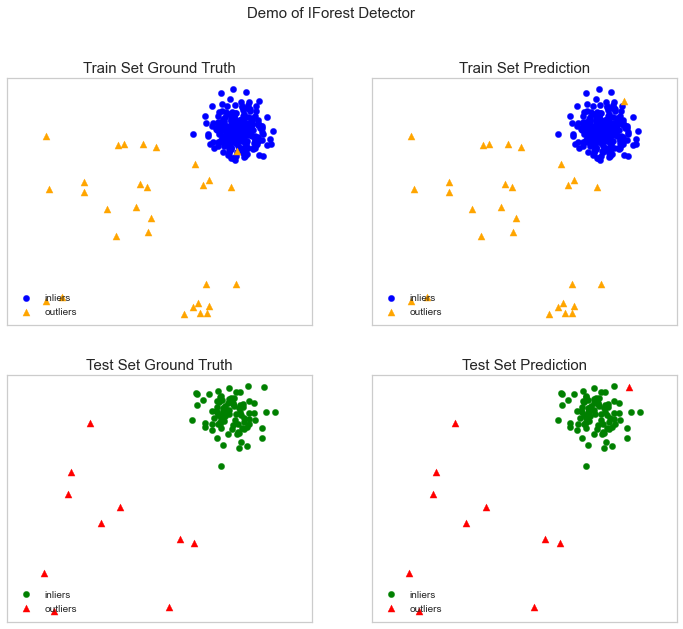
from pyod.utils.data import generate_data from pyod.utils.data import assessment_print from pyod.utils.example import visualize train= 300 test=100 contaminate = 0.1 X_train, X_test, y_train, y_test = gener_data(n_train=teszt=teszt , n_features=2,contamination=contaminate,random_state=42)
cname_alg = 'KNN' # az algoritmus neve K Legközelebbi szomszédok c = KNN() c.fit(X_train) #Algoritmus illesztése y_trainpred = c.labels_ y_trainscores = c.decision_scores_ y_testpred = c.testscore)sdicty c.decision_function(X_test) print("Training Data:") assessment_print(cname_alg, y_train, y_train_scores) print("Tesztadatok:") assessment_print(cname_alg, y_test, y_test_scores) visualize(cname_alg, X_train, X_test y_trainpred,y_testpred, show_figure=Igaz, save_figure=Igaz)

Az IForest algoritmust fogjuk használni.
fname_alg = 'IFerest' # az algoritmus neve K Legközelebbi szomszédok f = IFerdő() f.fit(X_train) #Algoritmus illesztése y_train_pred = c.labels_ y_train_scores = c.decision_scores_ =c_test_scored(c_test_score) c.decision_function(X_test) print("Képzési adatok:") assessment_print(fname_alg, y_train_pred, y_train_scores) print("Tesztadatok:") assessment_print(fname_alg, y_test_pred, y_test_scores) visualize(fname_a,_test_tra_in, Xpre_tra_a, Xpre_tra_a, Xpre_train y_train_pred,y_test_pred, show_figure=Igaz, save_figure=Igaz)
F. Anomália észlelése próféta által
A légi utasok adatkészletét használjuk idősorokkal prophet/example_air_passengers.csv at main · aster28/prophet (github.com)
import próféta próféta import előrejelző próféta importból Prophet m = Prophet()
data = pd.read_csv('air_pass.csv') data.head()

data.columns = ['ds', 'y'] data['y'] = np.where(data['y'] != 0, np.log(data['y']), 0)
Az y oszlop naplója nem engedélyez negatív értéket. Adatainkat vonatokra bontottuk, teszteltük, és az előrejelzést a változó előrejelzésben tároltuk.
vonat, teszt= train_test_split(data, random_state =42) m.fit(train[['ds','y']]) előrejelzés = m.predict(test) def detect(forecast): forcast = előrejelzés[['ds ', 'yhat', 'yhat_lower', 'yhat_upper']].copy() forcast['real']= data['y'] forcast['anomaly'] =0 forcast.loc[forcast['real'] > forcast['yhat_upper'], 'anomaly']=1 forcast.loc[forcast['real']< forcast['yhat_lower'], 'anomaly']=-1 forcast['imp']=0 in_range = előrejelzés ['yhat_upper']-forcast['yhat_lower'] forcast.loc[forcast['anomaly']==1, 'imp'] = forcast['real']-forcast['yhat_upper']/in_range forcast.loc[ forcast['anomaly']==-1, 'imp']= forcast['yhat_lower']-forcast['real']/in_range return forcast
észlel (előrejelzés)
Az anomáliát -1-nek vettük.

Következtetés
A kiugró értékek megtalálásának folyamatát egy adott adathalmazban anomália-detektálásnak nevezzük. A kiugró értékek olyan adatobjektumok, amelyek kitűnnek az adatkészlet többi objektumértéke közül, és nem viselkednek megfelelően.
Az anomália-észlelési feladatok távolság- és sűrűségalapú klaszterezési módszereket használhatnak a kiugró értékek fürtként történő azonosítására.
Itt tárgyaljuk az anomália-észlelés különféle módszereit, és elmagyarázzuk azokat a három adatkészleten található kóddal: Titanic, Air travels és Caret.
Főbb pontok
1. A kiugró értékek vagy anomáliák észlelése a Box-Whisker módszerrel vagy a DBSCAN segítségével észlelhető.
2. Az euklideszi távolság módszert alkalmazzuk a nem korrelált tételekkel.
3. A Mahalanobis módszert többváltozós kiugró értékekkel használjuk.
4. Az összes érték vagy pont nem kiugró érték. Vannak olyan zajok, amelyeknek szemétnek kell lenniük. A kiugró értékek érvényes adatok, amelyeket módosítani kell.
5. PyCaret-et használtunk a kiugró értékek észlelésére különböző algoritmusok használatával, ahol az anomália egy, sárga színnel jelenik meg, és nincs olyan kiugró érték, ahol a kiugró érték 0.
6. PyOD-t használtunk, amely a Python Outlier észlelési könyvtár. Több mint 40 algoritmusa van. Felügyelt és felügyelet nélküli technikákat alkalmaznak.
7. A Prophetet használtuk, és meghatároztuk a detektálás függvényt a kiugró értékek körvonalazására.
A cikkben bemutatott média nem az Analytics Vidhya tulajdona, és a szerző saját belátása szerint használja.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://www.analyticsvidhya.com/blog/2023/01/learning-different-techniques-of-anomaly-detection/
- 1
- 10
- 11
- 7
- a
- Rólunk
- felett
- címek
- Beállított
- AIR
- algoritmus
- algoritmusok
- Minden termék
- analitika
- Analytics Vidhya
- és a
- anomália észlelése
- Másik
- alkalmazott
- Sor
- cikkben
- előtt
- között
- Doboz
- számított
- hívott
- nem tud
- autó
- eset
- ellenőrizze
- közel
- Fürt
- csoportosítás
- kód
- szín
- Oszlop
- Oszlopok
- COM
- hogyan
- Összefüggés
- készítette
- dátum
- adatkészletek
- mélység
- észlelt
- Érzékelés
- eltérés
- különböző
- belátása
- megvitatni
- távolság
- terjesztés
- megosztott
- ne
- DOT
- minden
- hatás
- lehetővé teszi
- Szervezetek
- stb.
- Eter (ETH)
- példa
- Magyarázza
- nem sikerül
- Jellemzők
- Találjon
- megtalálása
- vezetéknév
- Úszó
- Előrejelzés
- erdő
- KERET
- ból ből
- funkció
- funkciók
- GitHub
- Ad
- adott
- jó
- grafikon
- boldog
- itt
- Magas
- <p></p>
- nagyon
- Hogyan
- HTTPS
- azonosítani
- kép
- importál
- in
- jelzi
- inverzió
- szigetelés
- kérdések
- IT
- tételek
- maga
- tanulás
- könyvtár
- Elő/Utó
- gép
- gépi tanulás
- készült
- Fő
- csinál
- Gyártás
- sok
- Mátrix
- max
- eszközök
- intézkedések
- Média
- módszer
- mód
- Metrics
- modell
- modellek
- több
- mozgó
- név
- Szükség
- negatív
- szomszédok
- normális
- rendszerint
- szám
- számtalan
- tárgy
- objektumok
- ONE
- nyílt forráskódú
- Más
- másképp
- vázlat
- tulajdonú
- Plató
- Platón adatintelligencia
- PlatoData
- pont
- előrejelzés
- ár
- folyamat
- Piton
- véletlen
- hatótávolság
- Olvasás
- igazi
- nyilvántartások
- Csökkent
- REST
- eredményez
- Eredmények
- visszatérés
- azonos
- Skála
- tengeren született
- Második
- Alak
- kellene
- előadás
- mutatott
- Műsorok
- jelentősen
- SIX
- Méret
- So
- néhány
- sebesség
- osztott
- állvány
- standard
- állványok
- memorizált
- Vesz
- tart
- beszéd
- Feladat
- feladatok
- technikák
- teszt
- A
- Ott.
- Harmadik
- három
- idő
- nak nek
- Vonat
- Képzések
- megért
- felügyelet nélküli tanulás
- us
- használ
- rendszerint
- hasznosítja
- érték
- Értékek
- különféle
- jármű
- Mit
- Kerék
- vajon
- ami
- lesz
- belül
- X
- A te
- zephyrnet
- nulla