OpenAI Whisper egy fejlett automatikus beszédfelismerő (ASR) modell MIT licenccel. Az ASR technológia hasznosítható az átírási szolgáltatásokban, a hangasszisztensekben és a hallássérült egyének hozzáférésének javításában. Ezt a korszerű modellt az internetről gyűjtött, többnyelvű és többfeladatos felügyelt adatok hatalmas és változatos adatkészletére képezték ki. Nagy pontossága és alkalmazkodóképessége értékes eszközzé teszi a hanggal kapcsolatos feladatok széles skálájához.
A gépi tanulás és a mesterséges intelligencia folyamatosan fejlődő világában Amazon SageMaker átfogó ökoszisztémát biztosít. A SageMaker felhatalmazza az adattudósokat, fejlesztőket és szervezeteket a gépi tanulási modellek széles körű fejlesztésére, képzésére, üzembe helyezésére és kezelésére. Eszközök és képességek széles skáláját kínálva leegyszerűsíti a teljes gépi tanulási munkafolyamatot, az adat-előfeldolgozástól és a modellfejlesztéstől a könnyű üzembe helyezésig és felügyeletig. A SageMaker felhasználóbarát felülete kulcsfontosságú platformmá teszi a mesterséges intelligencia teljes potenciáljának kiaknázásához, és a mesterséges intelligencia területén a játékot megváltoztató megoldássá teszi.
Ebben a bejegyzésben a SageMaker képességeinek feltárását kezdjük, különös tekintettel a Whisper modellek fogadására. Ennek két módszerét vizsgáljuk meg: az egyik a Whisper PyTorch modellt, a másik pedig a Whisper modell Hugging Face implementációját használja. Ezenkívül alaposan megvizsgáljuk a SageMaker következtetési lehetőségeit, összehasonlítva azokat olyan paraméterekkel, mint a sebesség, a költség, a hasznos teher mérete és a méretezhetőség. Ez az elemzés lehetővé teszi a felhasználók számára, hogy megalapozott döntéseket hozzanak, amikor a Whisper modelleket integrálják sajátos használati eseteikbe és rendszereikbe.
Megoldás áttekintése
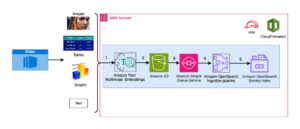
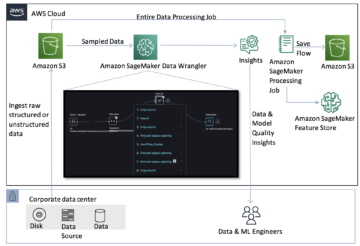
A következő ábra a megoldás főbb összetevőit mutatja be.
- Ahhoz, hogy a modellt az Amazon SageMaker-en tárolhassuk, az első lépés a modell műtermékeinek mentése. Ezek a műtermékek a különféle alkalmazásokhoz szükséges gépi tanulási modell alapvető összetevőire utalnak, beleértve a telepítést és az átképzést. Tartalmazhatnak modellparamétereket, konfigurációs fájlokat, előfeldolgozási összetevőket, valamint metaadatokat, például a verzió részleteit, a szerzőséget és a teljesítményével kapcsolatos megjegyzéseket. Fontos megjegyezni, hogy a PyTorch és Hugging Face megvalósításához készült Whisper modellek különböző modelltermékekből állnak.
- Ezután egyéni következtetési szkripteket hozunk létre. Ezeken a szkripteken belül meghatározzuk, hogyan kell betölteni a modellt, és megadjuk a következtetési folyamatot. Ez az a hely, ahol szükség szerint egyéni paramétereket is beépíthetünk. Ezenkívül felsorolhatja a szükséges Python-csomagokat a
requirements.txtfájlt. A modell üzembe helyezése során ezek a Python-csomagok automatikusan telepítésre kerülnek az inicializálási fázisban. - Ezután kiválasztjuk a PyTorch vagy a Hugging Face mély tanulási konténereket (DLC), amelyeket az általa biztosított és karbantart. AWS. Ezek a tárolók előre beépített Docker-képek mély tanulási keretrendszerrel és egyéb szükséges Python-csomagokkal. További információért ezt ellenőrizheti link.
- A modelltermékekkel, egyéni következtetési szkriptekkel és kiválasztott DLC-kkel Amazon SageMaker modelleket hozunk létre a PyTorch és Hugging Face számára.
- Végül a modellek üzembe helyezhetők a SageMakerben, és a következő lehetőségekkel használhatók: valós idejű következtetési végpontok, kötegelt átalakítási feladatok és aszinkron következtetési végpontok. Ebben a bejegyzésben később részletesebben foglalkozunk ezekkel a lehetőségekkel.
A megoldás példafüzete és kódja ezen a helyen érhető el GitHub tárház.
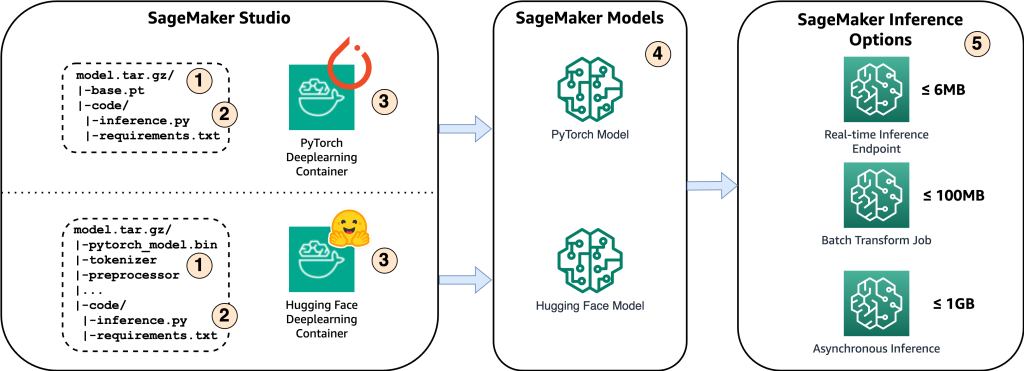
1. ábra: A megoldás kulcsfontosságú összetevőinek áttekintése
Végigjátszás
A Whisper modell tárolása az Amazon SageMakeren
Ebben a részben elmagyarázzuk a Whisper-modell Amazon SageMaker-en való elhelyezésének lépéseit a PyTorch és Hugging Face Frameworks használatával. A megoldással való kísérletezéshez AWS-fiókra és az Amazon SageMaker szolgáltatáshoz való hozzáférésre van szüksége.
PyTorch keretrendszer
- Mentse el a modell műtermékeit
A modell tárolásának első lehetősége a Whisper hivatalos Python csomagsegítségével telepíthető pip install openai-whisper. Ez a csomag PyTorch modellt biztosít. Amikor a modell műtermékeit menti a helyi tárolóba, az első lépés a modell tanulható paramétereinek, például a modell súlyainak és a neurális hálózat egyes rétegeinek torzításainak mentése 'pt' fájlként. Különböző modellméretek közül választhat, beleértve a "pici", "alap", "kicsi", "közepes" és "nagy" méreteket. A nagyobb modellméretek nagyobb pontosságú teljesítményt nyújtanak, de hosszabb következtetési késleltetés ára. Ezenkívül el kell mentenie a modellállapot-szótárat és a dimenziószótárt, amelyek tartalmaznak egy Python-szótárt, amely a PyTorch-modell minden egyes rétegét vagy paraméterét leképezi a megfelelő tanulható paraméterekre, más metaadatokkal és egyéni konfigurációkkal együtt. Az alábbi kód megmutatja, hogyan kell menteni a Whisper PyTorch műtermékeket.
- Válassza a DLC-t
A következő lépés az előre elkészített DLC kiválasztása ebből link. Legyen óvatos a megfelelő kép kiválasztásakor a következő beállítások figyelembevételével: keretrendszer (PyTorch), keretrendszer verziója, feladat (következtetés), Python verzió és hardver (pl. GPU). Javasoljuk, hogy lehetőség szerint a legújabb verziókat használja a keretrendszerhez és a Pythonhoz, mivel ez jobb teljesítményt eredményez, és kiküszöböli a korábbi kiadások ismert problémáit és hibáit.
- Hozzon létre Amazon SageMaker modelleket
Ezt követően használjuk a SageMaker Python SDK PyTorch modellek létrehozásához. Fontos, hogy PyTorch-modell létrehozásakor ne feledje a környezeti változók hozzáadását. Alapértelmezés szerint a TorchServe legfeljebb 6 MB fájlméretet tud feldolgozni, függetlenül a használt következtetés típusától.
Az alábbi táblázat a különböző PyTorch-verziók beállításait mutatja be:
| Keretrendszer | Környezeti változók |
| PyTorch 1.8 (TorchServe alapján) | "TS_MAX_REQUEST_SIZE": "100000000"" TS_MAX_RESPONSE_SIZE": "100000000"" TS_DEFAULT_RESPONSE_TIMEOUT": "1000" |
| PyTorch 1.4 (MMS alapú) | "MMS_MAX_REQUEST_SIZE": "1000000000"" MMS_MAX_RESPONSE_SIZE": "1000000000"" MMS_DEFAULT_RESPONSE_TIMEOUT": "900" |
- Határozza meg a modellbetöltési módszert az inference.py fájlban
A szokásban inference.py szkriptet, először ellenőrizzük a CUDA-képes GPU elérhetőségét. Ha elérhető ilyen GPU, akkor hozzárendeljük a 'cuda' eszköz a DEVICE változó; ellenkező esetben hozzárendeljük a 'cpu' eszköz. Ez a lépés biztosítja, hogy a modell a rendelkezésre álló hardverre kerüljön a hatékony számítás érdekében. A PyTorch modellt a Whisper Python csomag segítségével töltjük be.
Átölelő arc keret
- Mentse el a modell műtermékeit
A második lehetőség a használata Átölelő Arc Suttogása végrehajtás. A modell a segítségével tölthető be AutoModelForSpeechSeq2Seq transzformátorok osztálya. A tanulható paraméterek bináris (bin) fájlba kerülnek mentésre a save_pretrained módszer. A tokenizátort és az előfeldolgozót külön is el kell menteni, hogy a Hugging Face modell megfelelően működjön. Alternatív megoldásként telepíthet egy modellt az Amazon SageMakeren közvetlenül a Hugging Face Hubból két környezeti változó beállításával: HF_MODEL_ID és a HF_TASK. További információért kérjük, tekintse meg ezt weboldal.
- Válassza a DLC-t
A PyTorch keretrendszerhez hasonlóan választhatunk egy előre elkészített Hugging Face DLC-t is link. Ügyeljen arra, hogy olyan DLC-t válasszon, amely támogatja a legújabb Hugging Face transzformátorokat és GPU-támogatást.
- Hozzon létre Amazon SageMaker modelleket
Hasonlóképpen használjuk a SageMaker Python SDK átölelő arc modellek létrehozásához. A Hugging Face Whisper modellnek van egy alapértelmezett korlátozása, amely szerint legfeljebb 30 másodpercig képes feldolgozni a hangszegmenseket. Ennek a korlátozásnak a kiküszöbölése érdekében a chunk_length_s paramétert a környezeti változóban a Hugging Face modell létrehozásakor, és később adja át ezt a paramétert az egyéni következtetési szkriptnek a modell betöltésekor. Végül állítsa be a környezeti változókat, hogy növelje a hasznos adatmennyiséget és a válaszidőt a Hugging Face tárolóhoz.
| Keretrendszer | Környezeti változók |
|
HuggingFace Inference Container (MMS alapján) |
"MMS_MAX_REQUEST_SIZE": "2000000000"" MMS_MAX_RESPONSE_SIZE": "2000000000"" MMS_DEFAULT_RESPONSE_TIMEOUT": "900" |
- Határozza meg a modellbetöltési módszert az inference.py fájlban
Amikor egyéni következtetési szkriptet hozunk létre a Hugging Face modellhez, egy folyamatot használunk, amely lehetővé teszi a chunk_length_s paraméterként. Ez a paraméter lehetővé teszi, hogy a modell hatékonyan dolgozzon fel hosszú hangfájlokat a következtetés során.
Különböző következtetési lehetőségek felfedezése az Amazon SageMakeren
A következtetési opciók kiválasztásának lépései ugyanazok a PyTorch és Hugging Face modelleknél, ezért az alábbiakban nem teszünk különbséget köztük. Érdemes azonban megjegyezni, hogy a bejegyzés írásakor a szerver nélküli következtetés A SageMaker opció nem támogatja a GPU-kat, és ennek eredményeként ezt a lehetőséget kizárjuk ebben a használati esetben.
A modellt valós idejű végpontként telepíthetjük, amely ezredmásodperceken belül ad választ. Fontos azonban megjegyezni, hogy ez a lehetőség a 6 MB alatti bemenetek feldolgozására korlátozódik. A szerializálót audió szerializálóként definiáljuk, amely a bemeneti adatoknak a telepített modellnek megfelelő formátumba való konvertálásáért felelős. GPU-példányt használunk a következtetéshez, amely lehetővé teszi az audiofájlok gyorsított feldolgozását. A következtetés bemenete egy hangfájl, amely a helyi tárolóból származik.
A második következtetési lehetőség a kötegelt átalakítási feladat, amely 100 MB-ig képes feldolgozni a bemeneti hasznos adatokat. Ez a módszer azonban eltarthat néhány perc késleltetésig. Minden példány egyszerre csak egy kötegelt kérést tud kezelni, és a példány kezdeményezése és leállítása is néhány percet vesz igénybe. A következtetések eredményeit egy Amazon Simple Storage Service menti (Amazon S3) vödör a kötegelt átalakítási feladat befejezésekor.
A kötegelt transzformátor konfigurálásakor feltétlenül vegye fel max_payload = 100 nagyobb rakományok hatékony kezelésére. A következtetési bemenetnek egy hangfájl Amazon S3 elérési útja vagy egy 3 MB-nál kisebb méretű hangfájlok listáját tartalmazó Amazon S100 Bucket mappa kell, hogy legyen.
Batch Transform particionálja az Amazon S3 objektumokat a bemenetben kulcs alapján, és leképezi az Amazon S3 objektumokat példányokra. Ha például több hangfájlja van, az egyik példány feldolgozhatja az input1.wav fájlt, egy másik pedig az input2.wav nevű fájlt a méretezhetőség javítása érdekében. A Batch Transform lehetővé teszi a konfigurálást max_concurrent_transforms hogy növelje az egyes transzformátorkonténerekhez intézett HTTP-kérések számát. Fontos azonban megjegyezni, hogy a (max_concurrent_transforms* max_payload) nem haladhatja meg a 100 MB-ot.
Végül, az Amazon SageMaker Asynchronous Inference ideális több kérés egyidejű feldolgozásához, mérsékelt késleltetést kínál, és akár 1 GB-os bemeneti adatmennyiséget is támogat. Ez a beállítás kiváló méretezhetőséget biztosít, lehetővé téve egy automatikus skálázási csoport konfigurálását a végponthoz. Amikor megnövekszik a kérelmek száma, automatikusan felnagyítja a forgalom kezelését, és az összes kérés feldolgozása után a végpont 0-ra skálázódik a költségek megtakarítása érdekében.
Aszinkron következtetés segítségével az eredményeket automatikusan elmenti egy Amazon S3 tárolóba. Ban,-ben AsyncInferenceConfig, konfigurálhatja a sikeres vagy sikertelen befejezésekről szóló értesítéseket. A bemeneti útvonal az audiofájl Amazon S3 helyére mutat. További részletekért olvassa el a következő kódot GitHub.
Opcionális: Amint korábban említettük, lehetőségünk van egy automatikus skálázási csoport konfigurálására az aszinkron következtetési végponthoz, amely lehetővé teszi a következtetési kérések hirtelen megugrását. Ebben található egy kódpélda GitHub tárház. A következő diagramon egy vonaldiagramot láthat, amely két metrikát jelenít meg amazonfelhőóra: ApproximateBacklogSize és a ApproximateBacklogSizePerInstance. Kezdetben, amikor 1000 kérés indult, csak egy példány állt rendelkezésre a következtetés kezelésére. Három percig a lemaradás mérete folyamatosan meghaladta a hármat (kérjük, vegye figyelembe, hogy ezek a számok konfigurálhatók), és az automatikus skálázási csoport további példányok felpörgetésével válaszolt a lemaradás hatékony törlésére. Ez jelentős csökkenést eredményezett a ApproximateBacklogSizePerInstance, ami lehetővé teszi a hátralékos kérések sokkal gyorsabb feldolgozását, mint a kezdeti szakaszban.

2. ábra: Vonaldiagram, amely az Amazon CloudWatch mérőszámainak időbeli változásait szemlélteti
Összehasonlító elemzés a következtetési lehetőségekhez
A különböző következtetési lehetőségek összehasonlítása az általános hangfeldolgozási felhasználási eseteken alapul. A valós idejű következtetés a leggyorsabb következtetési sebességet kínálja, de a hasznos adat méretét 6 MB-ra korlátozza. Ez a következtetéstípus olyan hangparancs-rendszerekhez alkalmas, ahol a felhasználók hangutasítások vagy szóbeli utasítások segítségével vezérlik az eszközöket vagy szoftvereket, illetve interakcióba lépnek velük. A hangutasítások általában kis méretűek, és az alacsony következtetési késleltetés döntő fontosságú annak biztosításához, hogy az átírt parancsok azonnal kiválthassanak további műveleteket. A Batch Transform ideális az ütemezett offline feladatokhoz, amikor az egyes hangfájlok mérete 100 MB alatt van, és nincs külön követelmény a gyors következtetési válaszidőre. Az aszinkron következtetés legfeljebb 1 GB feltöltést tesz lehetővé, és mérsékelt következtetési késleltetést biztosít. Ez a következtetéstípus kiválóan alkalmas filmek, tévésorozatok és rögzített konferenciák átírására, ahol nagyobb hangfájlokat kell feldolgozni.
Mind a valós idejű, mind az aszinkron következtetési opciók automatikus skálázási lehetőségeket biztosítanak, lehetővé téve a végpontpéldányok számára, hogy automatikusan felfelé vagy lefelé lépkedjenek a kérések mennyisége alapján. Azokban az esetekben, amikor nincs kérés, az automatikus skálázás eltávolítja a szükségtelen példányokat, és segít elkerülni a nem aktívan használt, kiépített példányokkal kapcsolatos költségeket. A valós idejű következtetéshez azonban legalább egy állandó példányt meg kell tartani, ami magasabb költségekhez vezethet, ha a végpont folyamatosan működik. Ezzel szemben az aszinkron következtetés lehetővé teszi a példány térfogatának 0-ra csökkentését, amikor nincs használatban. Egy kötegelt átalakítási feladat konfigurálásakor több példány is használható a job feldolgozásához, és a max_concurrent_transforms beállításával lehetővé válik, hogy egy példány több kérést is kezelhessen. Ezért mindhárom következtetési lehetőség nagyszerű skálázhatóságot kínál.
Takarítás
Miután befejezte a megoldás használatát, gondoskodjon a SageMaker végpontok eltávolításáról, hogy elkerülje a további költségeket. A megadott kód segítségével törölheti a valós idejű és az aszinkron következtetési végpontokat.
Következtetés
Ebben a bejegyzésben megmutattuk, hogyan vált egyre fontosabbá a gépi tanulási modellek hangfeldolgozáshoz való alkalmazása a különböző iparágakban. A Whisper modellt példának véve bemutattuk, hogyan lehet nyílt forráskódú ASR-modelleket tárolni az Amazon SageMakeren PyTorch vagy Hugging Face megközelítésekkel. A feltárás az Amazon SageMaker különféle következtetési lehetőségeit foglalta magában, betekintést nyújtva a hangadatok hatékony kezelésére, az előrejelzések készítésére és a költségek hatékony kezelésébe. Ennek a bejegyzésnek az a célja, hogy ismereteket nyújtson azoknak a kutatóknak, fejlesztőknek és adattudósoknak, akik érdeklődnek a Whisper-modell hanggal kapcsolatos feladatokhoz való hasznosításában, és megalapozott döntések meghozatalában a következtetési stratégiákkal kapcsolatban.
A modellek SageMakeren történő telepítésével kapcsolatos részletesebb információkért tekintse meg ezt Fejlesztői útmutató. Ezenkívül a Whisper modell a SageMaker JumpStart segítségével telepíthető. További részletekért kérjük, ellenőrizze a Az automatikus beszédfelismerő Whisper modellek már elérhetőek az Amazon SageMaker JumpStartban post.
Nyugodtan tekintse meg a projekt notebookját és kódját GitHub és ossza meg velünk megjegyzését.
A szerzőről
 Ying Hou, PhD, az AWS gépi tanulási prototípus-készítő építésze. Elsődleges érdeklődési területe a Deep Learning, amelynek középpontjában a GenAI, a Computer Vision, az NLP és az idősoros adatok előrejelzése áll. Szabadidejében szívesen tölt el minőségi pillanatokat családjával, elmélyül a regényekben, és túrázik az Egyesült Királyság nemzeti parkjaiban.
Ying Hou, PhD, az AWS gépi tanulási prototípus-készítő építésze. Elsődleges érdeklődési területe a Deep Learning, amelynek középpontjában a GenAI, a Computer Vision, az NLP és az idősoros adatok előrejelzése áll. Szabadidejében szívesen tölt el minőségi pillanatokat családjával, elmélyül a regényekben, és túrázik az Egyesült Királyság nemzeti parkjaiban.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/machine-learning/host-the-whisper-model-on-amazon-sagemaker-exploring-inference-options/
- :van
- :is
- :nem
- :ahol
- $ UP
- 1
- 10
- 100
- 12
- 14
- 16
- 19
- 30
- 32
- 8
- a
- felgyorsult
- hozzáférés
- megközelíthetőség
- Fiók
- pontosság
- át
- cselekvések
- aktívan
- hozzá
- További
- Ezen kívül
- cím
- állítsa
- fejlett
- AI
- célok
- Minden termék
- lehetővé téve
- lehetővé teszi, hogy
- mentén
- Is
- amazon
- Amazon SageMaker
- Az Amazon Web Services
- an
- elemzés
- és a
- Másik
- bármilyen
- alkalmazások
- megközelít
- VANNAK
- területek
- Sor
- mesterséges
- mesterséges intelligencia
- AS
- vagyontárgy
- asszisztensek
- társult
- At
- hang-
- Szerzőség
- Automatikus
- automatikusan
- elérhetőség
- elérhető
- elkerülése érdekében
- AWS
- bázis
- alapján
- BE
- válik
- lent
- Jobb
- között
- torzítások
- BIN
- mindkét
- bogarak
- de
- by
- TUD
- képességek
- képes
- óvatos
- esetek
- Változások
- Táblázatos
- ellenőrizze
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a
- választja
- osztály
- világos
- kód
- hogyan
- megjegyzés
- Közös
- összehasonlítva
- összehasonlítások
- Befejezett
- befejezés
- alkatrészek
- átfogó
- számítás
- számítógép
- Számítógépes látás
- Magatartás
- konferenciák
- Configuration
- konfigurálva
- konfigurálása
- figyelembe véve
- következetesen
- tartalmaz
- Konténer
- Konténerek
- folyamatosan
- kontraszt
- ellenőrzés
- konvertáló
- kijavítására
- Megfelelő
- Költség
- kiadások
- tudott
- CPU
- teremt
- létrehozása
- kritikus
- szokás
- dátum
- határozatok
- csökkenés
- mély
- mély tanulás
- alapértelmezett
- meghatározott
- igazolták
- telepíteni
- telepített
- bevezetéséhez
- bevetés
- részlet
- részletes
- részletek
- Fejleszt
- fejlesztők
- Fejlesztés
- eszköz
- Eszközök
- különböző
- különbséget
- Dimenzió
- közvetlenül
- megjelenítő
- merülés
- számos
- Dokkmunkás
- Nem
- Ennek
- le-
- alatt
- e
- minden
- Korábban
- ökoszisztéma
- hatékonyan
- hatékony
- eredményesen
- megerőltetés nélküli
- bármelyik
- más
- induljon
- felhatalmazza
- lehetővé
- lehetővé teszi
- lehetővé téve
- felölel
- Endpoint
- végpontok
- növelése
- fokozása
- biztosítására
- biztosítja
- Egész
- Környezet
- alapvető
- létrehozó
- Eter (ETH)
- vizsgálat
- példa
- haladja meg
- meghaladta
- kiváló
- kísérlet
- Magyarázza
- kutatás
- Feltárása
- Arc
- Sikertelen
- hamis
- család
- GYORS
- gyorsabb
- leggyorsabb
- kevés
- filé
- Fájlok
- leletek
- vezetéknév
- Összpontosít
- összpontosítás
- következő
- A
- formátum
- Keretrendszer
- keretek
- Ingyenes
- ból ből
- Tele
- GPU
- GPU
- nagy
- Csoport
- fogantyú
- Kezelés
- hardver
- Legyen
- hallás
- segít
- neki
- Magas
- <p></p>
- turisztika
- vendéglátó
- tárhely
- Hogyan
- How To
- azonban
- HTML
- http
- HTTPS
- Kerékagy
- HuggingFace
- i
- ideális
- if
- szemléltető
- kép
- képek
- végrehajtás
- megvalósítások
- importál
- fontos
- in
- mélyreható
- tartalmaz
- magában foglalja a
- Beleértve
- bele
- Növelje
- egyre inkább
- egyéni
- egyének
- iparágak
- információ
- tájékoztatták
- kezdetben
- alapvetően
- kezdeményezés
- bemenet
- bemenet
- meglátások
- telepíteni
- példa
- példányok
- utasítás
- integrálása
- Intelligencia
- kölcsönhatásba
- kamat
- érdekelt
- Felület
- bele
- kérdések
- IT
- ITS
- Munka
- Állások
- jpg
- Kulcs
- tudás
- ismert
- táj
- nagyobb
- végül
- Késleltetés
- a későbbiekben
- legutolsó
- réteg
- vezet
- tanulás
- legkevésbé
- erőfölény
- Engedély
- korlátozás
- Korlátozott
- vonal
- Lista
- kiszámításának
- betöltés
- helyi
- elhelyezkedés
- Hosszú
- hosszabb
- Elő/Utó
- gép
- gépi tanulás
- készült
- Fő
- csinál
- KÉSZÍT
- Gyártás
- kezelése
- kezelése
- Térképek
- Lehet..
- említett
- Metaadatok
- módszer
- mód
- Metrics
- esetleg
- ezredmásodperc
- jegyzőkönyv
- MIT
- ML
- modell
- modellek
- közepesen
- Pillanatok
- ellenőrzés
- több
- Filmek
- sok
- többszörös
- kell
- Nevezett
- nemzeti
- Nemzeti parkok
- elengedhetetlen
- Szükség
- szükséges
- hálózat
- ideg-
- neurális hálózat
- következő
- NLP
- nem
- megjegyezni
- jegyzetfüzet
- Megjegyzések
- bejelentés
- értesítések
- megjegyezve,
- Most
- szám
- számok
- tárgy
- objektumok
- megfigyelni
- of
- ajánlat
- felajánlás
- Ajánlatok
- hivatalos
- Nem elérhető
- on
- egyszer
- ONE
- csak
- nyílt forráskódú
- működik
- opció
- Opciók
- or
- érdekében
- szervezetek
- OS
- Más
- másképp
- ki
- áttekintés
- csomag
- csomagok
- paraméter
- paraméterek
- parkok
- elhalad
- ösvény
- teljesít
- teljesítmény
- fázis
- csővezeték
- döntő
- helyezett
- emelvény
- Plató
- Platón adatintelligencia
- PlatoData
- kérem
- pont
- lehetséges
- állás
- potenciális
- előrejelzés
- Tippek
- megakadályozása
- előző
- elsődleges
- folyamat
- feldolgozott
- feldolgozás
- Processzor
- program
- megfelelően
- prototípus
- ad
- feltéve,
- biztosít
- amely
- Piton
- pytorch
- világítás
- hatótávolság
- real-time
- birodalom
- elismerés
- ajánlott
- feljegyzett
- Csökkent
- utal
- Tekintet nélkül
- összefüggő
- Releases
- eszébe jut
- eltávolítása
- elmozdít
- raktár
- kérni
- kéri
- szükség
- kötelező
- követelmény
- kutatók
- illetőleg
- válasz
- válaszok
- felelős
- eredményez
- eredményezett
- Eredmények
- visszatartott
- átképzés
- visszatérés
- sagemaker
- azonos
- Megtakarítás
- mentett
- megtakarítás
- skálázhatóság
- Skála
- Mérleg
- tervezett
- tudósok
- forgatókönyv
- szkriptek
- Második
- másodperc
- Rész
- szegmensek
- válasszuk
- kiválasztott
- kiválasztása
- Series of
- szolgáltatás
- Szolgáltatások
- készlet
- beállítás
- beállítások
- Megosztás
- ő
- kellene
- kimutatta,
- Műsorok
- üzemszünet
- jelentős
- Egyszerű
- egyszerűsíti
- Méret
- méretek
- kicsi
- kisebb
- So
- szoftver
- megoldások
- különleges
- kifejezetten
- meghatározott
- beszéd
- Speech Recognition
- sebesség
- Költési
- beszélt
- kezdet
- Állami
- csúcs-
- Lépés
- Lépései
- tárolás
- stratégiák
- későbbi
- sikeres
- ilyen
- hirtelen
- megfelelő
- támogatás
- Támogató
- Támogatja
- biztos
- túlfeszültség
- Systems
- táblázat
- Vesz
- bevétel
- Feladat
- feladatok
- Technológia
- mint
- hogy
- A
- Az Egyesült Királyságban
- azok
- Őket
- akkor
- Ott.
- ebből adódóan
- Ezek
- ők
- ezt
- három
- idő
- Idősorok
- alkalommal
- nak nek
- szerszámok
- fáklya
- forgalom
- Vonat
- kiképzett
- Átalakítás
- transzformátor
- transzformerek
- kiváltó
- váltott
- tv
- TV sorozat
- kettő
- típus
- jellemzően
- Uk
- alatt
- kinyitó
- upon
- us
- használ
- használt
- barátságos felhasználói
- Felhasználók
- segítségével
- hasznosság
- hasznosít
- kihasználva
- Értékes
- érték
- változó
- különféle
- Hatalmas
- változat
- látomás
- Hang
- hangparancsok
- kötet
- várjon
- akar
- volt
- we
- háló
- webes szolgáltatások
- JÓL
- voltak
- amikor
- bármikor
- ami
- Suttogás
- széles
- Széleskörű
- val vel
- belül
- munkafolyamat
- művek
- érdemes
- írás
- te
- A te
- zephyrnet