A kép szerzője
Az adattudomány egy interdiszciplináris terület, amely nagymértékben támaszkodik a hatalmas mennyiségű adatból származó betekintések kinyerésére és megalapozott döntések meghozatalára. Az adattudósok eszköztárának egyik alapvető eszköze az SQL (Structured Query Language), egy relációs adatbázisok kezelésére és manipulálására tervezett programozási nyelv.
Ebben a cikkben az SQL egyik leghatékonyabb funkciójára összpontosítok: a csatlakozásokra.
Az SQL Joins lehetővé teszi több adatbázistábla adatainak kombinálását közös oszlopok alapján. Így egyesítheti az információkat, és értelmes kapcsolatokat hozhat létre a kapcsolódó adatkészletek között.
Számos SQL csatlakozások típusai:
- Belső összekapcsolás
- Bal külső csatlakozás
- Jobb külső csatlakozás
- Teljes külső csatlakozás
- Keresztcsatlakozás
Magyarázzuk el az egyes típusokat.
A belső összekapcsolás csak azokat a sorokat adja vissza, ahol mindkét egyesített táblában egyezés található. Két tábla sorait kombinálja egy megosztott kulcs vagy oszlop alapján, és elveti a nem egyező sorokat.
Ezt a következő módon képzeljük el.
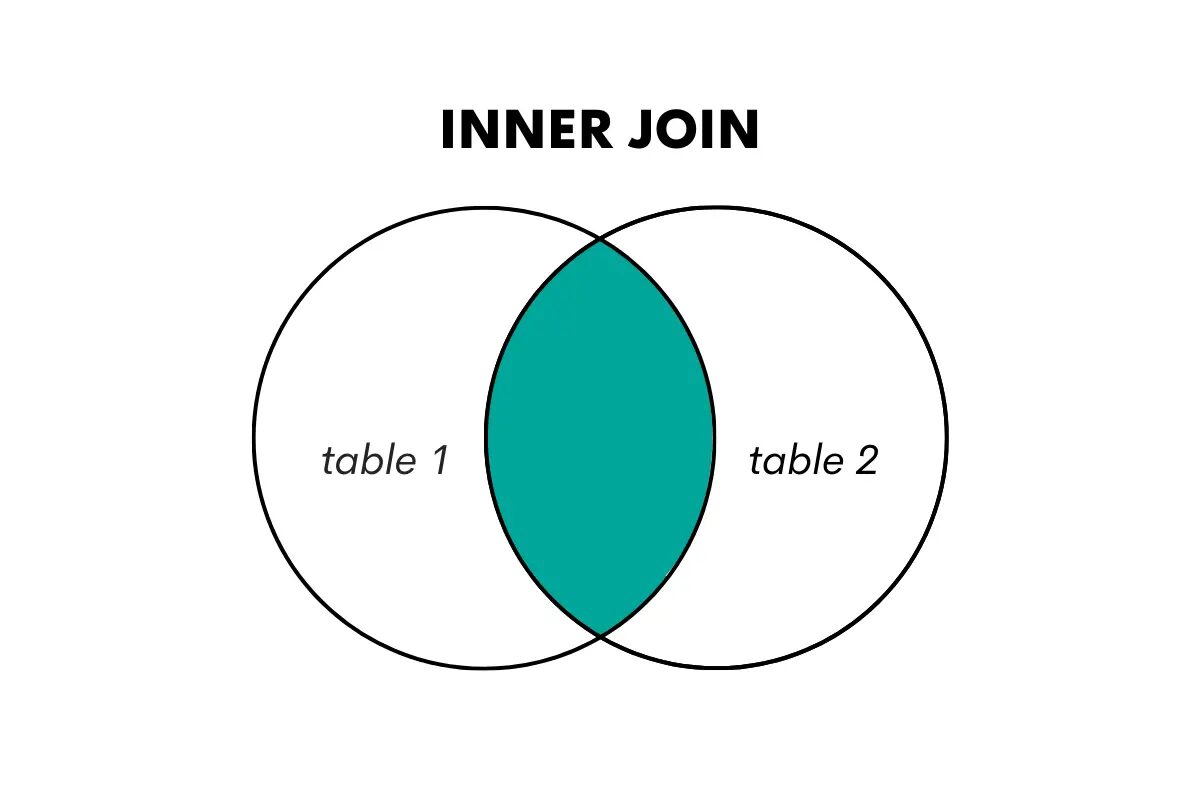
A kép szerzője
Az SQL-ben ez a fajta összekapcsolás a JOIN vagy INNER JOIN kulcsszavakkal történik.
A bal oldali külső összekapcsolás visszaadja a bal (vagy az első) tábla összes sorát és a jobb (vagy második) tábla egyező sorait. Ha nincs egyezés, akkor NULL értékeket ad vissza a jobb oldali tábla oszlopaihoz.
Ezt így is elképzelhetjük.
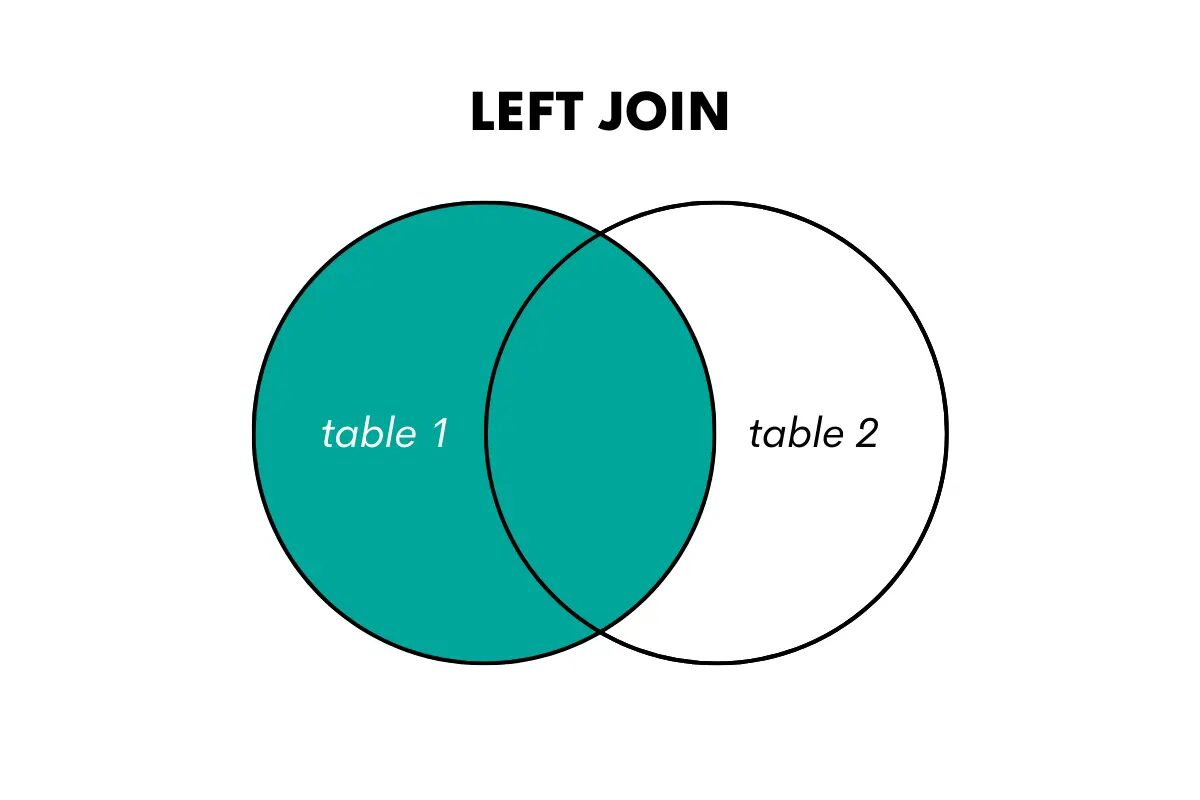
A kép szerzője
Ha ezt az összekapcsolást szeretné használni az SQL-ben, ezt a LEFT OUTER JOIN vagy LEFT JOIN kulcsszavak használatával teheti meg. Itt van egy cikk, ami erről szól bal oldali csatlakozás vs bal külső csatlakozás.
A jobb oldali illesztés a bal oldali csatlakozás ellentéte. Visszaadja az összes sort a jobb oldali táblából és az egyező sorokat a bal oldali táblázatból. Ha nincs egyezés, akkor NULL értékeket ad vissza a bal oldali tábla oszlopaihoz.
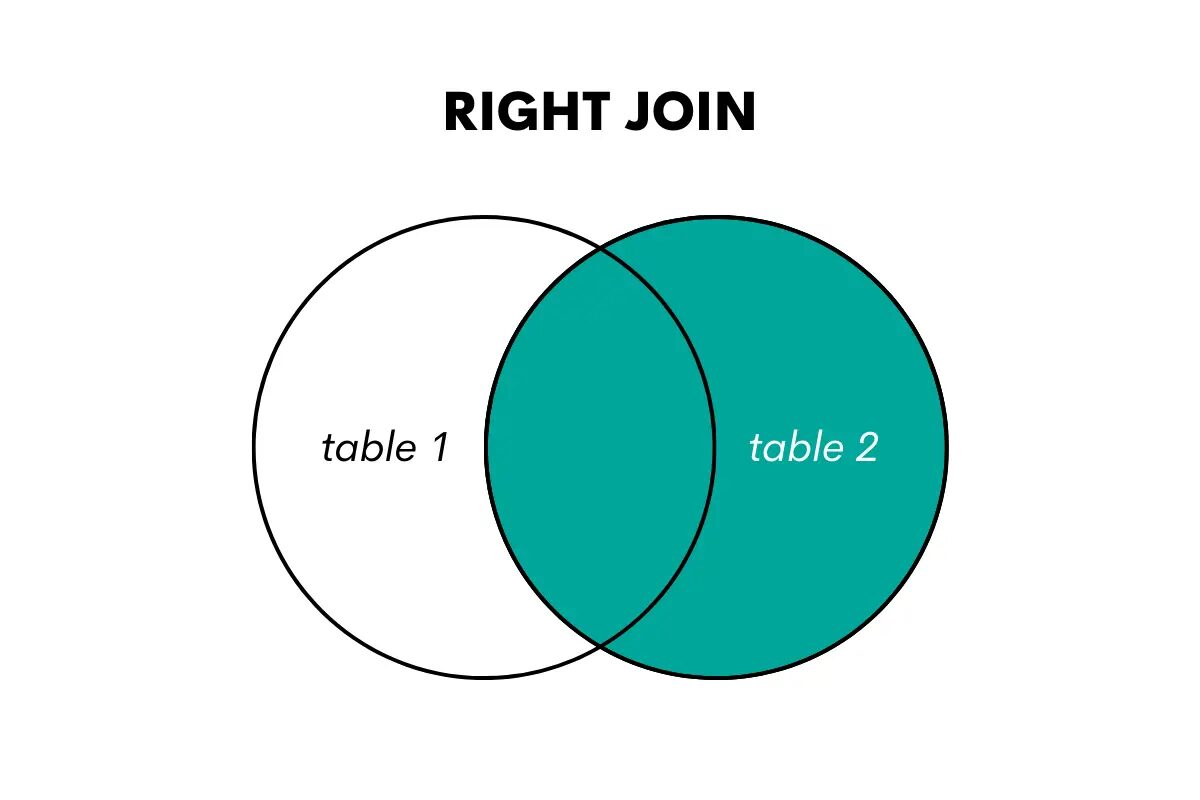
A kép szerzője
Az SQL-ben ezt a csatlakozási típust a RIGHT OUTER JOIN vagy RIGHT JOIN kulcsszavakkal hajtják végre.
A teljes külső összekapcsolás mindkét tábla összes sorát visszaadja, lehetőség szerint egyeztetve a sorokat, és kitöltve NULL értékeket a nem egyező sorok esetén.
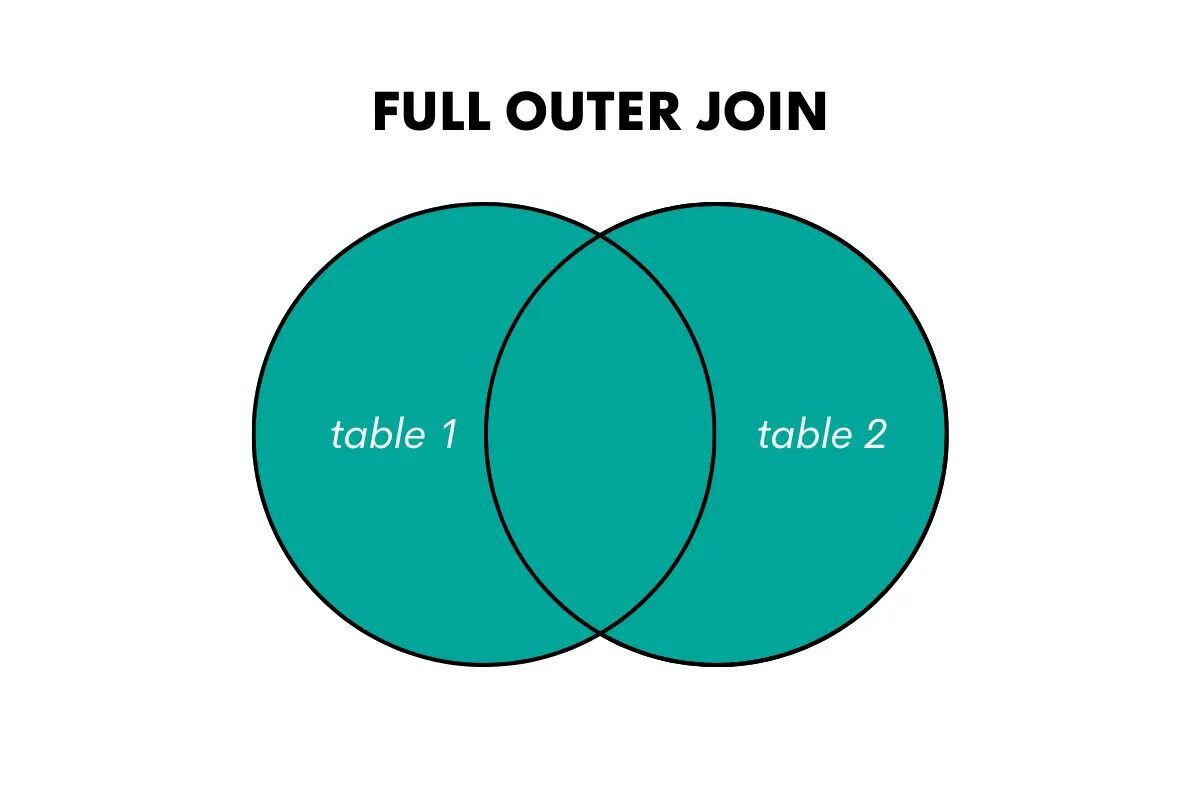
A kép szerzője
Az SQL-ben ehhez az összekapcsoláshoz a kulcsszavak a következők: FULL OUTER JOIN vagy FULL JOIN.
Ez a fajta összekapcsolás egy tábla összes sorát egyesíti a második tábla összes sorával. Más szóval, a derékszögű szorzatot adja vissza, azaz a két tábla sorának összes lehetséges kombinációját.
Íme a vizualizáció, amely megkönnyíti a megértést.
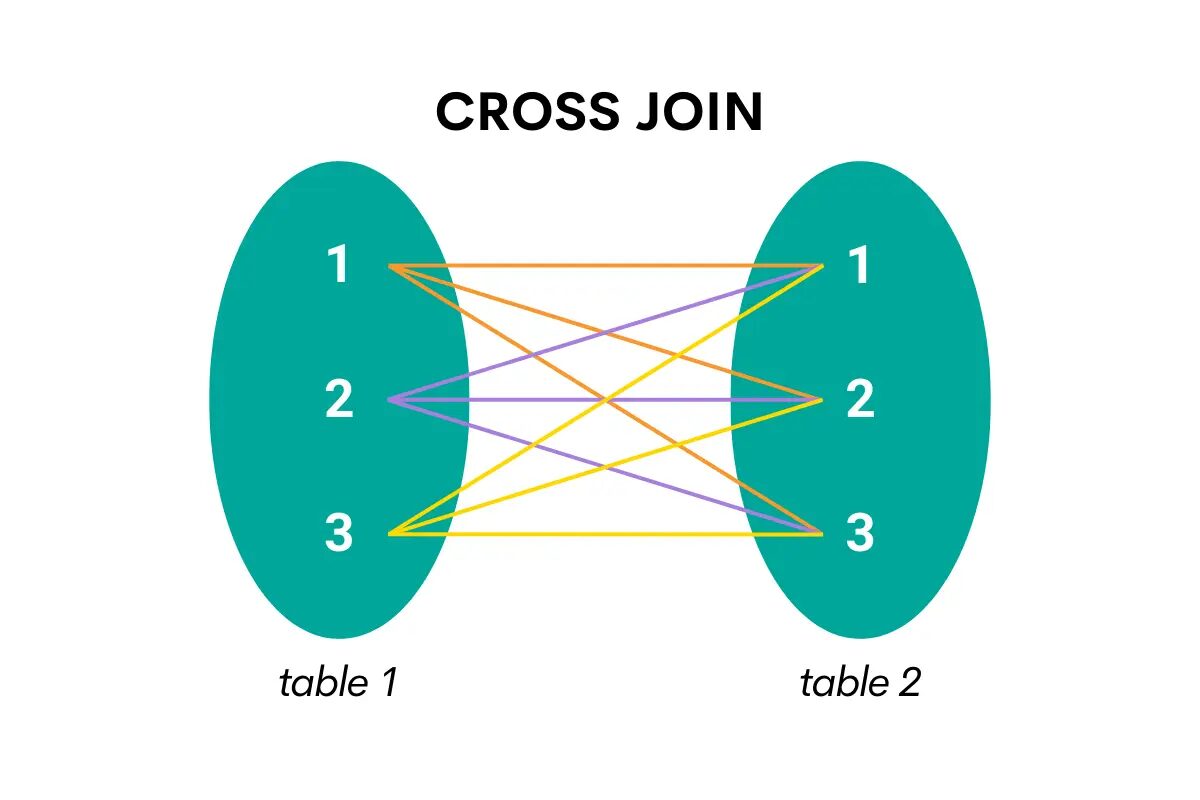
A kép szerzője
Ha SQL-ben keresztcsatlakozás történik, a kulcsszó a CROSS JOIN.
Az összekapcsolás SQL-ben történő végrehajtásához meg kell adni az egyesíteni kívánt táblákat, az illesztéshez használt oszlopokat és az összekapcsolás típusát. Az SQL-ben a táblák összekapcsolásának alapvető szintaxisa a következő:
SELECT columns
FROM table1
JOIN table2
ON table1.column = table2.column;
Ez a példa bemutatja a JOIN használatát.
A FROM záradék első (vagy bal oldali) táblájára hivatkozik. Ezután kövesse a JOIN parancsot, és hivatkozzon a második (vagy jobb oldali) táblázatra.
Ezután jön a csatlakozási feltétel az ON záradékban. Itt adhatja meg, hogy mely oszlopokat fogja használni a két tábla összekapcsolásához. Általában ez egy megosztott oszlop, amely az egyik táblában elsődleges kulcs, a másodikban pedig az idegen kulcs.
Megjegyzés: Az elsődleges kulcs a tábla minden rekordjának egyedi azonosítója. Az idegen kulcs kapcsolatot hoz létre két tábla között, azaz a második tábla egyik oszlopa, amely az első táblára hivatkozik. A példákban megmutatjuk, mit jelent ez.
Ha a LEFT JOIN, RIGHT JOIN vagy FULL JOIN kifejezést szeretné használni, csak ezeket a kulcsszavakat használja a JOIN helyett – minden más a kódban pontosan ugyanaz!
A CROSS JOIN-szal egy kicsit más a helyzet. Ennek lényege, hogy mindkét tábla összes sorkombinációját összekapcsolja. Ezért nincs szükség az ON záradékra, és a szintaxis így néz ki.
SELECT columns
FROM table1
CROSS JOIN table2;
Más szavakkal, egyszerűen hivatkozhat egy táblára a FROM-ban, a másodikra pedig a CROSS JOIN-ban.
Alternatív megoldásként hivatkozhat mindkét táblára a FROM-ban, és vesszővel választhatja el őket – ez a CROSS JOIN rövidítése.
SELECT columns
FROM table1, table2;Az asztalok összekapcsolásának egy sajátos módja is van – az asztal összekapcsolása önmagával. Ezt az asztalhoz való öncsatlakozásnak is nevezik.
Ez nem teljesen különálló csatlakozási típus, mivel a korábban említett csatlakozási típusok bármelyike használható önálló csatlakozásra is.
Az öncsatlakozás szintaxisa hasonló ahhoz, amit korábban mutattam. A fő különbség az, hogy ugyanarra a táblázatra hivatkozik a FROM és a JOIN.
SELECT columns
FROM table1 t1
JOIN table1 t2
ON t1.column = t2.column;
Ezenkívül a táblázatnak két álnevet kell megadnia, hogy megkülönböztesse őket. Amit csinálsz, az az, hogy összekapcsolod a táblát önmagával, és két táblaként kezeled.
Csak ezt akartam itt megemlíteni, de nem részletezem tovább. Ha érdekli az önálló csatlakozás, kérjük, olvassa el ezt az illusztrált útmutatót öncsatlakozás SQL-ben.
Itt az ideje, hogy megmutassam, hogyan működik mindaz, amit említettem a gyakorlatban. használni fogom SQL JOIN interjúkérdések a StrataScratch-ből, hogy bemutassa az egyes egyesülési típusokat az SQL-ben.
1. JOIN Példa
Ez a kérdés a Microsofttól azt akarja, hogy felsoroljon minden projektet, és kiszámítsa a projekt költségvetését az alkalmazott által.
Drága projektek
„Adott egy listát a projektekről és az egyes projektekhez társított alkalmazottakról, és számolja ki az egyes alkalmazottakra kiosztott projektköltségvetés összegével. A kimenetnek tartalmaznia kell a projekt címét és a projekt költségvetését a legközelebbi egész számra kerekítve. Először rendezze a listát a legmagasabb alkalmazottankénti költségvetéssel rendelkező projektek szerint.”
dátum
A kérdés két táblázatot ad.
ms_projects
| id: | int |
| cím: | varchar |
| költségvetés: | int |
ms_emp_projects
| emp_id: | int |
| project_id: | int |
Most az oszlopazonosító a táblázatban ms_projects a tábla elsődleges kulcsa. Ugyanez az oszlop a táblázatban is megtalálható ms_emp_projects, bár más néven: projekt_azonosítója. Ez a tábla idegen kulcsa, amely az első táblára hivatkozik.
Ezt a két oszlopot fogom használni a táblázatok összekapcsolásához a megoldásomban.
Kód
SELECT title AS project, ROUND((budget/COUNT(emp_id)::FLOAT)::NUMERIC, 0) AS budget_emp_ratio
FROM ms_projects a
JOIN ms_emp_projects b ON a.id = b.project_id
GROUP BY title, budget
ORDER BY budget_emp_ratio DESC;
A két táblát a JOIN segítségével egyesítettem. Az asztal ms_projects hivatkozásra a FROM, míg ms_emp_projects a JOIN után hivatkozik. Mindkét táblának álnevet adtam, így a későbbiekben nem használhatom a tábla hosszú nevét.
Most meg kell adnom azokat az oszlopokat, amelyeken csatlakozni akarok a táblákhoz. Már említettem, hogy az egyik táblában mely oszlopok az elsődleges kulcsok, a másikban pedig az idegen kulcsok, ezért itt ezeket fogom használni.
Ezzel a két oszloppal egyenlő vagyok, mert minden olyan adatot szeretnék megkapni, ahol a projektazonosító megegyezik. A táblázatok álneveit is használtam az egyes oszlopok előtt.
Most, hogy mindkét tábla adataihoz hozzáférek, kilistázhatom az oszlopokat a SELECT-ben. Az első oszlop a projekt neve, a második oszlop pedig kiszámításra kerül.
Ez a számítás a COUNT() függvényt használja az egyes projektek alkalmazottainak számbavételéhez. Ezután elosztom az egyes projektek költségvetését az alkalmazottak számával. Az eredményt tizedesjegyekre is konvertálom, és nulla tizedesjegyre kerekítem.
teljesítmény
Íme, mit ad vissza a lekérdezés.
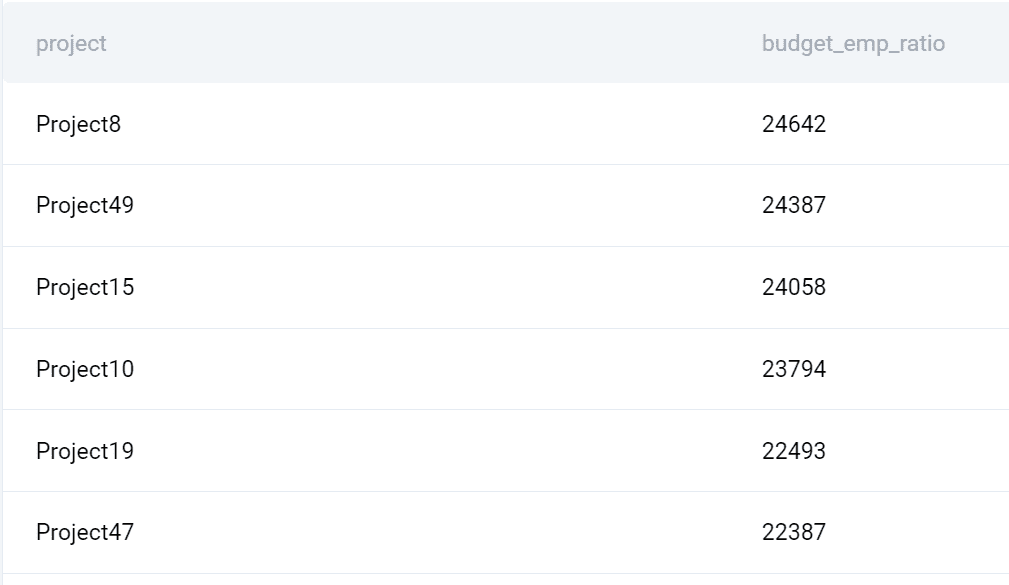
2. LEFT JOIN Példa
Gyakoroljuk ezt a csatlakozást a Airbnb interjú kérdése. Azt akarja, hogy megtalálja a megrendelések számát, az ügyfelek számát és a megrendelések teljes költségét az egyes városok esetében.
Ügyfélrendelések és részletek
„Keresse meg a megrendelések számát, a vásárlók számát és a megrendelések teljes költségét az egyes városokban. Csak azokat a városokat foglalja bele, amelyek legalább 5 rendelést adtak le, és minden város összes vásárlóját számolja bele, még akkor is, ha nem adtak le rendelést.
Minden számítást írjon ki a megfelelő városnévvel együtt."
dátum
Átadják az asztalokat ügyfelek, és a rendelés.
ügyfelek
| id: | int |
| keresztnév: | varchar |
| vezetéknév: | varchar |
| város: | varchar |
| cím: | varchar |
| telefonszám: | varchar |
rendelés
| id: | int |
| cust_id: | int |
| rendelés dátuma: | dátum idő |
| order_details: | varchar |
| total_order_cost: | int |
A megosztott oszlopok azonosítója a táblázatból ügyfelek és cust_id a táblázatból rendelés. Ezeket az oszlopokat fogom használni a táblázatok összekapcsolásához.
Kód
A következőképpen oldhatja meg ezt a kérdést a LEFT JOIN használatával.
SELECT c.city, COUNT(DISTINCT o.id) AS orders_per_city, COUNT(DISTINCT c.id) AS customers_per_city, SUM(o.total_order_cost) AS orders_cost_per_city
FROM customers c
LEFT JOIN orders o ON c.id = o.cust_id
GROUP BY c.city
HAVING COUNT(o.id) >=5;
Hivatkozom a táblázatra ügyfelek a FROM-ban (ez a bal oldali táblázatunk) és a LEFT JOIN -vel rendelés az ügyfélazonosító oszlopokban.
Most kiválaszthatom a várost, a COUNT() segítségével lekérhetem a megrendelések és ügyfelek számát városonként, a SUM() segítségével pedig kiszámíthatom a rendelések teljes költségét városonként.
Ahhoz, hogy ezeket a számításokat városonként megkaphassa, a kimenetet városok szerint csoportosítom.
A kérdésben van egy extra kérés: „Csak azokat a városokat foglalja bele, amelyek legalább 5 rendelést adtak le…” A HAVING segítségével csak azokat a városokat jelenítem meg, amelyeknek öt vagy több megrendelése van.
A kérdés az, hogy miért használtam BAL EGYSZER és nem JOIN? A kérdésben rejlik a nyom: "...és számolja meg az összes vásárlót az egyes városokban, még akkor is, ha nem adtak le rendelést." Lehetséges, hogy nem minden ügyfél adott le rendelést. Ez azt jelenti, hogy az összes vásárlót meg akarom mutatni az asztalról ügyfelek, ami tökéletesen megfelel a LEFT JOIN definíciójának.
Ha a JOIN-t használtam volna, az eredmény rossz lett volna, mivel hiányoltam volna azokat a vásárlókat, akik nem adtak le rendelést.
Megjegyzés: Az SQL-ben a csatlakozások összetettsége nem a szintaxisukban, hanem a szemantikában tükröződik! Mint láthatta, minden egyes csatlakozás ugyanúgy van megírva, csak a kulcsszó változik. Azonban minden egyes összekapcsolás másként működik, és ezért az adatoktól függően eltérő eredményeket adhat ki. Emiatt kulcsfontosságú, hogy teljesen megértse az egyes csatlakozások működését, és válassza ki azt, amely pontosan azt adja vissza, amit szeretne!
teljesítmény
Most pedig nézzük a kimenetet.

3. RIGHT JOIN Példa
A RIGHT JOIN a LEFT JOIN tükörképe. Ezért könnyen meg tudtam volna oldani az előző problémát a RIGHT JOIN használatával. Hadd mutassam meg, hogyan kell csinálni.
dátum
Az asztalok ugyanazok maradnak; Csak másfajta csatlakozást fogok használni.
Kód
SELECT c.city, COUNT(DISTINCT o.id) AS orders_per_city, COUNT(DISTINCT c.id) AS customers_per_city, SUM(o.total_order_cost) AS orders_cost_per_city
FROM orders o
RIGHT JOIN customers c ON o.cust_id = c.id GROUP BY c.city
HAVING COUNT(o.id) >=5;
Íme, mi változott. Mivel a RIGHT JOIN-t használom, megváltoztattam a táblázatok sorrendjét. Most az asztal rendelés lesz a bal oldali, és az asztal ügyfelek a megfelelőt. A csatlakozási feltétel változatlan marad. Csak átállítottam az oszlopok sorrendjét, hogy tükrözze a táblázatok sorrendjét, de nem szükséges.
Az asztalok sorrendjének megváltoztatásával és a RIGHT JOIN használatával ismét kiírom az összes vásárlót, még akkor is, ha nem adtak le rendelést.
A lekérdezés többi része ugyanaz, mint az előző példában. Ugyanez vonatkozik a kimenetre is.
Megjegyzés: A gyakorlatban JOBB CSATLAKOZÁS viszonylag ritkán használják. A LEFT JOIN természetesebbnek tűnik az SQL felhasználók számára, ezért sokkal gyakrabban használják. Bármi, amit meg lehet tenni a RIGHT JOIN-nel, megtehető a LEFT JOIN-nel is. Emiatt nincs olyan konkrét helyzet, ahol a RIGHT JOIN előnyben részesülhetne.
teljesítmény
4. TELJES CSATLAKOZÁS Példa
A Salesforce és a Tesla kérdése azt szeretné, ha megszámolná a nettó különbséget a 2020-ban piacra dobott termékek és az előző évben piacra dobott termékek száma között.
Új termékek
„Egy táblázatot kap a termékbevezetésekről cégenként, évenként. Írjon lekérdezést, hogy megszámolja a nettó különbséget a 2020-ban piacra dobott termékek és az előző évben piacra dobott termékek száma között. Adja meg a cégek nevét és a 2020-ra kiadott nettó termékek nettó különbségét az előző évhez képest.”
dátum
A kérdés egy táblázatot tartalmaz a következő oszlopokkal.
car_launches
| év: | int |
| Cégnév: | varchar |
| termék név: | varchar |
Hogy a fenébe csatlakozhatok asztalokhoz, amikor csak egy asztal van? Hmm, lássuk azt is!
Kód
Ez a lekérdezés egy kicsit bonyolultabb, ezért fokozatosan fogom felfedni.
SELECT company_name, product_name AS brand_2020
FROM car_launches
WHERE YEAR = 2020;
Az első SELECT utasítás 2020-ban találja meg a céget és a termék nevét. Ez a lekérdezés később részlekérdezéssé válik.
A kérdés azt akarja, hogy megtalálja a különbséget 2020 és 2019 között. Tehát írjuk meg ugyanazt a lekérdezést, de 2019-re.
SELECT company_name, product_name AS brand_2019
FROM car_launches
WHERE YEAR = 2019;
Ezeket a lekérdezéseket most részlekérdezésekké alakítom, és a FULL OUTER JOIN segítségével csatlakozom hozzájuk.
SELECT *
FROM (SELECT company_name, product_name AS brand_2020 FROM car_launches WHERE YEAR = 2020) a
FULL OUTER JOIN (SELECT company_name, product_name AS brand_2019 FROM car_launches WHERE YEAR = 2019) b ON a.company_name = b.company_name;
Az allekérdezések táblaként kezelhetők, és ezért összekapcsolhatók. Az első segédlekérdezésnek álnevet adtam, és a FROM záradékba helyeztem. Ezután a FULL OUTER JOIN-t használom, hogy összekapcsoljam a cégnév oszlop második allekérdezésével.
Az ilyen típusú SQL-csatlakozás használatával 2020-ban az összes vállalatot és terméket egyesítem a 2019-es összes vállalattal és termékkel.
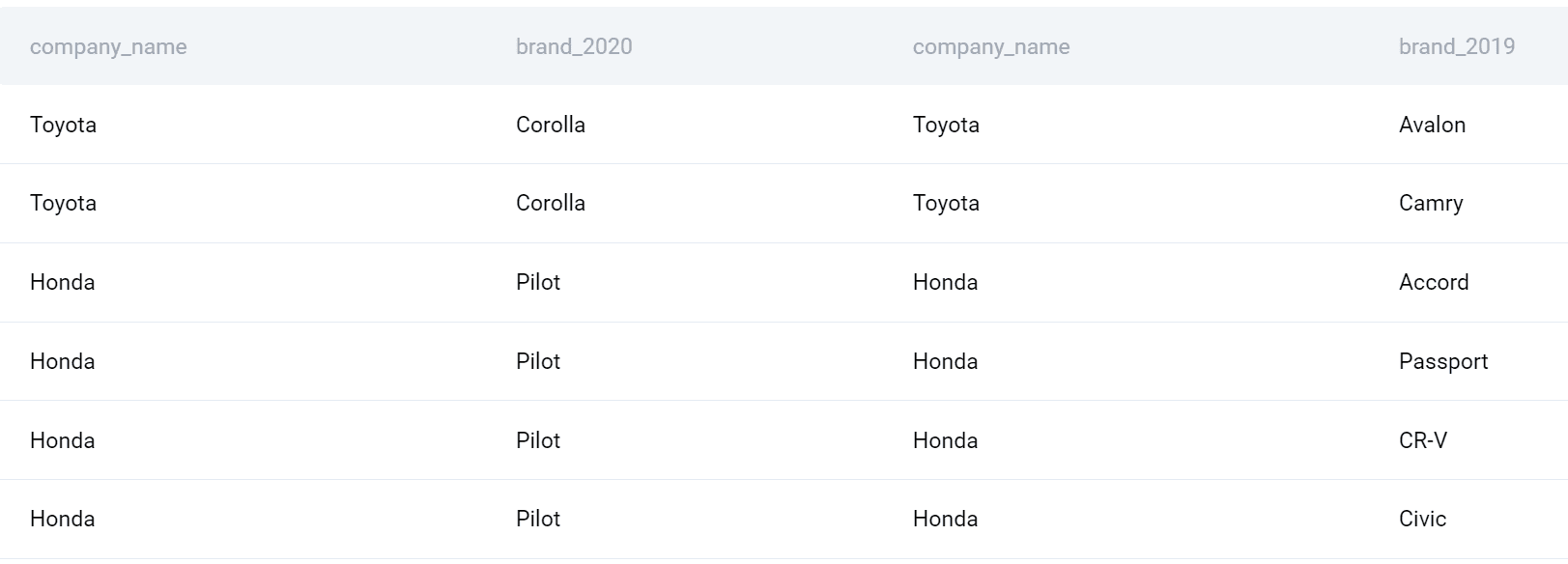
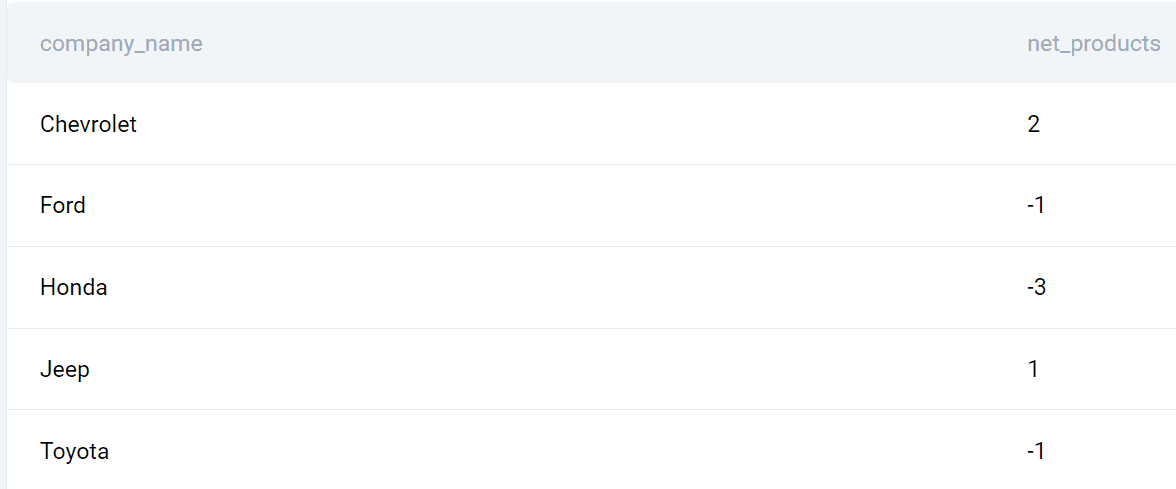
Most már véglegesíthetem a kérdésem. Válasszuk ki a cég nevét. Ezenkívül a COUNT() függvényt használom az egyes években piacra dobott termékek számának megállapítására, majd kivonom belőle a különbséget. Végül a kimenetet cégenként csoportosítom, és cégenként is ábécé szerint rendezem.
Itt az egész lekérdezés.
SELECT a.company_name, (COUNT(DISTINCT a.brand_2020)-COUNT(DISTINCT b.brand_2019)) AS net_products
FROM (SELECT company_name, product_name AS brand_2020 FROM car_launches WHERE YEAR = 2020) a
FULL OUTER JOIN (SELECT company_name, product_name AS brand_2019 FROM car_launches WHERE YEAR = 2019) b ON a.company_name = b.company_name
GROUP BY a.company_name
ORDER BY company_name;teljesítmény
Íme a cégek listája és a piacra dobott termékek közötti különbség 2020 és 2019 között.
5. KERESZTÖSSZETÉTEL Példa
Ez a kérdés a Deloitte-tól kiválóan alkalmas a CROSS JOIN működésének bemutatására.
Maximum két szám
„Egyetlen számoszlop esetén vegyük figyelembe két szám összes lehetséges permutációját, feltételezve, hogy az (x,y) és (y,x) számpárok két különböző permutáció. Ezután minden permutációhoz keresse meg a két szám maximumát.
Írjon ki három oszlopot: az első számot, a második számot és a kettő közül a maximumot.
A kérdés két szám összes lehetséges permutációját szeretné megkeresni, feltételezve, hogy az (x,y) és (y,x) számpárok két különböző permutáció. Ezután minden permutációhoz meg kell találnunk a számok maximumát.
dátum
A kérdés egy táblázatot ad egy oszloppal.
deloitte_számok
| szám: | int |
Kód
Ez a kód egy példa a CROSS JOIN-ra, de az öncsatlakozásra is.
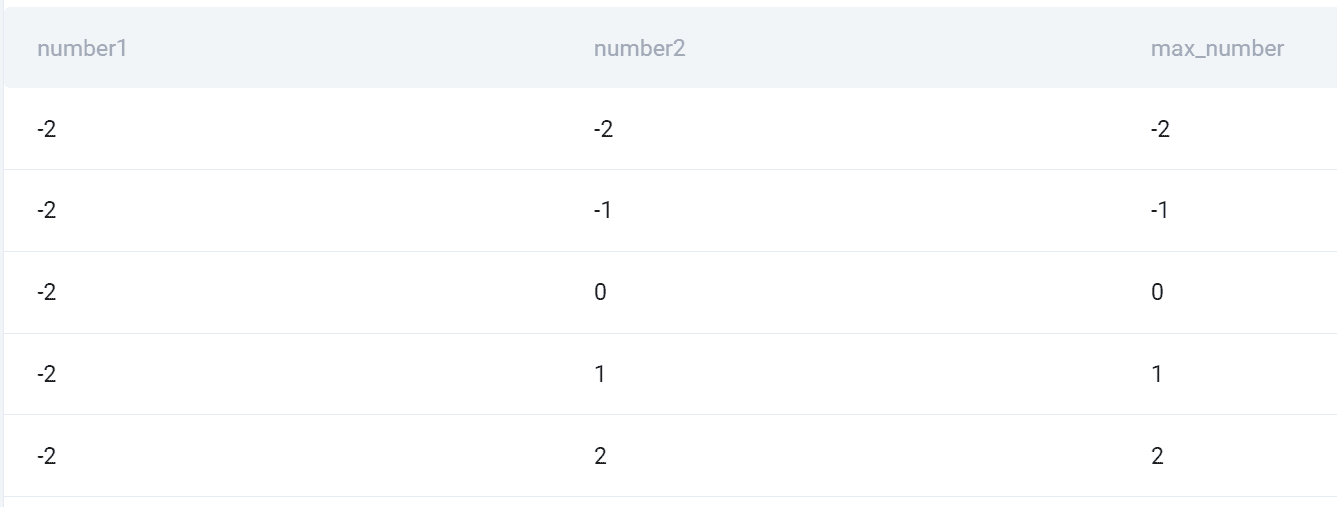
SELECT dn1.number AS number1, dn2.number AS number2, CASE WHEN dn1.number > dn2.number THEN dn1.number ELSE dn2.number END AS max_number
FROM deloitte_numbers AS dn1
CROSS JOIN deloitte_numbers AS dn2;
Hivatkozom a FROM-ban lévő táblázatra, és adok neki egy álnevet. Ezután I CROSS JOIN saját magával úgy, hogy a CROSS JOIN után hivatkozom rá, és egy másik álnevet adok a táblának.
Mostantól lehetséges egy tábla használata, mivel kettő. Minden táblázatból kiválasztom az oszlop számát. Ezután a CASE utasítással beállítok egy feltételt, amely a két szám maximális számát mutatja.
Miért használjuk itt a CROSS JOIN-t? Ne feledje, hogy ez egy olyan típusú SQL-illesztés, amely az összes tábla összes sorának összes kombinációját mutatja. Pontosan ezt teszi fel a kérdés!
teljesítmény
Íme az összes kombináció pillanatképe és a kettő nagyobb száma.
Most, hogy tudja, hogyan kell használni az SQL-illesztéseket, a kérdés az, hogyan hasznosíthatja ezt a tudást az adattudományban.
Az SQL Join-ok kulcsfontosságú szerepet játszanak az olyan adattudományi feladatokban, mint az adatfeltárás, az adatok tisztítása és a funkciótervezés.
Íme néhány példa az SQL csatlakozások kihasználására:
- Adatok kombinálása: A táblák összekapcsolása lehetővé teszi a különböző adatforrások összegyűjtését, lehetővé téve a kapcsolatok és korrelációk elemzését több adatkészlet között. Például egy vevőtábla és egy tranzakciós tábla összekapcsolása betekintést nyújthat az ügyfelek viselkedésébe és a vásárlási mintákba.
- Adatok érvényesítése: Az összekapcsolások segítségével ellenőrizhető az adatok minősége és integritása. A különböző táblák adatainak összehasonlításával azonosíthatja az inkonzisztenciákat, a hiányzó értékeket vagy a kiugró értékeket. Ez segít az adatok tisztításában, és biztosítja, hogy az elemzéshez használt adatok pontosak és megbízhatóak legyenek.
- Feature Engineering: A csatlakozások fontos szerepet játszhatnak a gépi tanulási modellek új funkcióinak létrehozásában. A releváns táblák egyesítésével értelmes információkat nyerhet ki, és olyan funkciókat hozhat létre, amelyek rögzítik az adatokon belüli fontos kapcsolatokat. Ez növelheti a modellek előrejelző erejét.
- Összesítés és elemzés: Az összekapcsolások lehetővé teszik összetett összesítések és elemzések végrehajtását több táblán keresztül. A különböző forrásokból származó adatok kombinálásával átfogó képet kaphat az adatokról, és értékes betekintést nyerhet. Például egy értékesítési táblázat és egy terméktáblázat összekapcsolása segíthet az értékesítési teljesítmény termékkategória vagy régió szerinti elemzésében.
Ahogy már említettem, az összekapcsolások összetettsége nem látszik a szintaxisukban. Láttad, hogy a szintaxis viszonylag egyszerű.
A csatlakozások bevált gyakorlatai is ezt tükrözik, mivel nem magával a kódolással foglalkoznak, hanem azzal, hogy mit és hogyan teljesít az összekapcsolás.
Ha a legtöbbet szeretné kihozni az SQL összekapcsolásából, vegye figyelembe a következő bevált módszereket.
- Az Ön adatainak megértése: Ismerkedjen meg az adatok szerkezetével és kapcsolataival. Ez segít kiválasztani a megfelelő csatlakozástípust, és kiválasztani a megfelelő oszlopokat az illesztéshez.
- Indexek használata: Ha a táblák nagyok vagy gyakran vannak összekapcsolva, fontolja meg indexek hozzáadását az összekapcsoláshoz használt oszlopokhoz. Az indexek jelentősen javíthatják a lekérdezés teljesítményét.
- Ügyeljen a teljesítményre: A nagy vagy több tábla összekapcsolása számítási szempontból költséges lehet. Optimalizálja lekérdezéseit az adatok szűrésével, megfelelő csatlakozási típusok használatával, valamint ideiglenes táblák vagy részlekérdezések használatának megfontolásával.
- Tesztelés és érvényesítés: Mindig ellenőrizze a csatlakozási eredményeket a helyesség biztosítása érdekében. Végezzen józansági ellenőrzéseket, és ellenőrizze, hogy az egyesített adatok összhangban vannak-e az Ön elvárásaival és üzleti logikájával.
Az SQL Joins olyan alapvető koncepció, amely lehetővé teszi adattudósként, hogy több forrásból származó adatokat egyesítsen és elemezzen. Az SQL-illesztések különböző típusainak megértésével, szintaxisuk elsajátításával és hatékony kihasználásával az adattudósok értékes betekintést nyerhetnek, ellenőrizhetik az adatminőséget, és előmozdíthatják az adatvezérelt döntéshozatalt.
Öt példán mutattam meg, hogyan kell ezt csinálni. Most már Önön múlik, hogy kihasználja-e az SQL erejét és csatlakozik-e adattudományi projektjeihez, és jobb eredményeket érhet el.
Nate Rosidi adattudós és termékstratégia. Emellett analitikát tanító adjunktus, és az alapítója StrataScratch, egy platform, amely segíti az adattudósokat az interjúkra való felkészülésben a vezető cégektől származó valódi interjúkérdések segítségével. Kapcsolatba lépni vele Twitter: StrataScratch or LinkedIn.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Autóipar / elektromos járművek, Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- BlockOffsets. A környezetvédelmi ellentételezési tulajdon korszerűsítése. Hozzáférés itt.
- Forrás: https://www.kdnuggets.com/2023/08/sql-data-science-understanding-leveraging-joins.html?utm_source=rss&utm_medium=rss&utm_campaign=sql-for-data-science-understanding-and-leveraging-joins
- :is
- :nem
- :ahol
- $ UP
- 1
- 11
- 12
- 13
- 2019
- 2020
- 7
- 8
- a
- Rólunk
- hozzáférés
- Az adatokhoz való hozzáférés
- pontos
- Elérése
- át
- hozzáadásával
- adjunktus
- Után
- újra
- összesítés
- Igazítás
- Minden termék
- elkülönített
- lehetővé
- lehetővé téve
- lehetővé teszi, hogy
- mentén
- már
- Is
- mindig
- összeg
- Összegek
- an
- elemzés
- analitika
- elemez
- és a
- Másik
- bármilyen
- bármi
- megfelelő
- VANNAK
- cikkben
- AS
- At
- b
- alapján
- alapvető
- BE
- mert
- válik
- óta
- hogy
- BEST
- legjobb gyakorlatok
- Jobb
- között
- mindkét
- hoz
- költségvetés
- üzleti
- de
- by
- számít
- számított
- hívott
- TUD
- elfog
- eset
- Kategória
- megváltozott
- Változások
- Ellenőrzések
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a
- városok
- Város
- Takarításra
- kód
- Kódolás
- Oszlop
- Oszlopok
- COM
- kombinációk
- össze
- kombájnok
- kombinálása
- jön
- Közös
- Companies
- vállalat
- képest
- összehasonlítva
- bonyolult
- bonyolultság
- bonyolult
- átfogó
- koncepció
- az érintett
- feltétel
- Csatlakozás
- kapcsolatok
- Fontolja
- figyelembe véve
- megtérít
- Megfelelő
- Költség
- teremt
- létrehozása
- Kereszt
- kritikus
- vevő
- vevői viselkedés
- Ügyfelek
- dátum
- adatminőség
- adat-tudomány
- adattudós
- adatalapú
- adatbázis
- adatbázisok
- adatkészletek
- Döntéshozatal
- határozatok
- definíció
- attól
- tervezett
- részlet
- DID
- különbség
- különböző
- különböző
- különbséget tesz
- do
- nem
- Nem
- Ennek
- csinált
- hajtás
- e
- minden
- Korábban
- könnyebb
- könnyen
- hatékonyan
- más
- munkavállaló
- alkalmazottak
- felhatalmazza
- lehetővé
- lehetővé téve
- végén
- Mérnöki
- növelése
- biztosítására
- biztosítja
- egyenlő
- megállapítja
- Még
- minden
- pontosan
- példa
- példák
- várakozások
- drága
- Magyarázza
- kutatás
- külön-
- kivonat
- Funkció
- Jellemzők
- kevés
- mező
- töltő
- szűrő
- véglegesítése
- Végül
- Találjon
- leletek
- vezetéknév
- öt
- Úszó
- Összpontosít
- következik
- következő
- következik
- A
- külföldi
- talált
- alapító
- gyakran
- ból ből
- front
- Tele
- teljesen
- funkció
- alapvető
- további
- Nyereség
- generál
- kap
- Ad
- adott
- ad
- Giving
- Goes
- megy
- fokozatosan
- nagy
- Csoport
- útmutató
- hám
- Legyen
- tekintettel
- he
- súlyosan
- segít
- segít
- segít
- itt
- <p></p>
- legnagyobb
- őt
- Hogyan
- How To
- azonban
- HTTPS
- i
- BETEG
- ID
- azonosító
- azonosítani
- if
- kép
- fontos
- javul
- in
- Más
- tartalmaz
- indexek
- információ
- tájékoztatták
- meglátások
- helyette
- hangszeres
- sértetlenség
- érdekelt
- Interjú
- interjú kérdések
- interjúk
- bele
- IT
- ITS
- maga
- csatlakozik
- csatlakozott
- csatlakozott
- csatlakozik
- jpg
- éppen
- KDnuggets
- Kulcs
- kulcsszavak
- Ismer
- tudás
- nyelv
- nagy
- a későbbiekben
- indított
- elindítja
- tanulás
- legkevésbé
- balra
- erőfölény
- mint
- LINK
- Lista
- kis
- logika
- Hosszú
- néz
- MEGJELENÉS
- gép
- gépi tanulás
- készült
- Fő
- csinál
- Gyártás
- kezelése
- manipuláló
- mastering
- Mérkőzés
- párosított
- egyező
- maximális
- me
- jelentőségteljes
- eszközök
- említett
- megy
- egyesülő
- esetleg
- tükör
- Tükörkép
- megszakított
- hiányzó
- modellek
- több
- a legtöbb
- sok
- többszörös
- my
- név
- nevek
- Természetes
- Természet
- elengedhetetlen
- Szükség
- szükséges
- háló
- Új
- Új funkciók
- nem
- Most
- szám
- számok
- of
- gyakran
- on
- ONE
- csak
- szemben
- Optimalizálja
- or
- érdekében
- rendelés
- Más
- mi
- ki
- teljesítmény
- párok
- minták
- mert
- teljesít
- teljesítmény
- teljesített
- Előadja
- Hely
- Helyek
- emelvény
- Plató
- Platón adatintelligencia
- PlatoData
- játszani
- kérem
- lehetséges
- hatalom
- erős
- gyakorlat
- gyakorlat
- előnyben részesített
- Készít
- előző
- elsődleges
- Probléma
- Termékek
- Termékek
- Egyetemi tanár
- Programozás
- program
- projektek
- ad
- biztosít
- beszerzési
- világítás
- lekérdezések
- kérdés
- Kérdések
- ritkán
- igazi
- rekord
- referenciák
- referenciái
- tükröznie
- tükrözi
- vidék
- összefüggő
- Kapcsolatok
- viszonylag
- felszabaduló
- megbízható
- eszébe jut
- kérni
- REST
- eredményez
- Eredmények
- visszatérés
- Visszatér
- mutatják
- jobb
- Szerep
- körül
- s
- értékesítés
- értékesítési erő
- azonos
- látta
- Tudomány
- Tudós
- tudósok
- Második
- lát
- Úgy tűnik,
- MAGA
- különálló
- készlet
- számos
- megosztott
- gyorsírás
- kellene
- előadás
- kirakat
- kimutatta,
- mutató
- Műsorok
- jelentősen
- hasonló
- egyszerűen
- egyetlen
- helyzet
- Pillanatkép
- So
- megoldások
- SOLVE
- Források
- különleges
- SQL
- nyilatkozat
- tartózkodás
- egyértelmű
- Stratégia
- struktúra
- szerkesztett
- ilyen
- kapcsolva
- szintaxis
- T1
- táblázat
- Talks
- feladatok
- Tanítási
- ideiglenes
- teszt
- hogy
- A
- azok
- Őket
- akkor
- Ott.
- ebből adódóan
- Ezek
- ők
- ezt
- három
- idő
- Cím
- nak nek
- együtt
- Eszköztár
- szerszámok
- felső
- Végösszeg
- tranzakció
- kezelt
- kezelésére
- Fordult
- kettő
- típus
- típusok
- megért
- megértés
- egyedi
- kinyit
- us
- használ
- használt
- Felhasználók
- használ
- segítségével
- rendszerint
- hasznosít
- ÉRVÉNYESÍT
- érvényesítés
- Értékes
- Értékek
- különféle
- Hatalmas
- ellenőrzése
- Megnézem
- megjelenítés
- vs
- akar
- kívánatos
- hiányzó
- akar
- Út..
- we
- Mit
- amikor
- ami
- míg
- egész
- miért
- lesz
- val vel
- belül
- szavak
- művek
- ír
- írott
- Rossz
- X
- év
- te
- A te
- magad
- zephyrnet
- nulla