Miközben az OpenAI ChatGPT kiszívja az összes oxigént a 24 órás hírciklusból, a Google csendben bemutatta az új mesterséges intelligencia modellt, amely video-, kép- és szövegbevitel esetén képes videókat generálni. Az új Google Dreamix AI videószerkesztő most közelebb hozza a generált videót a valósághoz.
A GitHubon megjelent kutatás szerint a Dreamix videó és szöveges prompt alapján szerkeszti a videót. Az eredményül kapott videó megőrzi színhűségét, testtartását, tárgyméretét és a kamera pózát, ami időbeli konzisztens videót eredményez. Jelenleg a Dreamix nem tud videókat generálni pusztán egy promptból, azonban képes a meglévő anyagokat átvenni, és szöveges promptokkal módosítani a videót.
A Google videodiffúziós modelleket használ a Dreamixhez, ezt a megközelítést sikeresen alkalmazzák a legtöbb képi AI-ban, például a DALL-E2-ben vagy a nyílt forráskódú Stable Diffusion-ban.
A megközelítés magában foglalja a bemeneti videó nagymértékű csökkentését, mesterséges zaj hozzáadását, majd a videó diffúziós modellben történő feldolgozását, amely ezután egy szöveges prompt segítségével új videót generál belőle, amely megtartja az eredeti videó bizonyos tulajdonságait, és a többit újra rendereli. a szövegbevitelhez.
A videó diffúziós modell ígéretes jövőt kínál, amely új korszakot nyithat meg a videókkal való munkavégzésben.

Például az alábbi videóban a Dreamix az evő majmot (balra) táncoló medvévé változtatja (jobbra), amint a „Egy medve táncol és ugrál vidám zenére, egész testét megmozgatja.”
Egy másik alábbi példában a Dreamix egyetlen fényképet használ sablonként (mint a kép-videó esetében), majd egy objektumot animál belőle egy videóban egy prompt segítségével. A kamera mozgása is lehetséges az új jelenetben vagy egy későbbi time-lapse felvételben.
Egy másik példában a Dreamix a vízmedencében lévő orangutánt (balra) narancssárga hajú orangutánná változtatja egy gyönyörű fürdőszobában.
„Míg a diffúziós modelleket sikeresen alkalmazták képszerkesztésre, nagyon kevés munka végezte el ezt a videószerkesztést. Bemutatjuk az első diffúzió alapú módszert, amely képes általános videók szöveges mozgás- és megjelenésszerkesztésére.”
A Google kutatási tanulmánya szerint a Dreamix egy videó diffúziós modellt használ, hogy a következtetés időpontjában az eredeti videóból származó kis felbontású téridő-információkat kombinálja az új, nagy felbontású információval, amelyet szintetizált, hogy igazodjon a vezérlő szöveges prompthoz.”
A Google azt mondta, azért választotta ezt a megközelítést, mert „az eredeti videó nagy pontosságának eléréséhez meg kell őrizni a nagyfelbontású információ egy részét, hozzáadjuk a modell finomhangolásának előzetes szakaszát az eredeti videóhoz, jelentősen javítva a hűséget”.
Az alábbiakban egy videó áttekintést talál a Dreamix működéséről.
[Beágyazott tartalmat]
Hogyan működnek a Dreamix videó diffúziós modellek
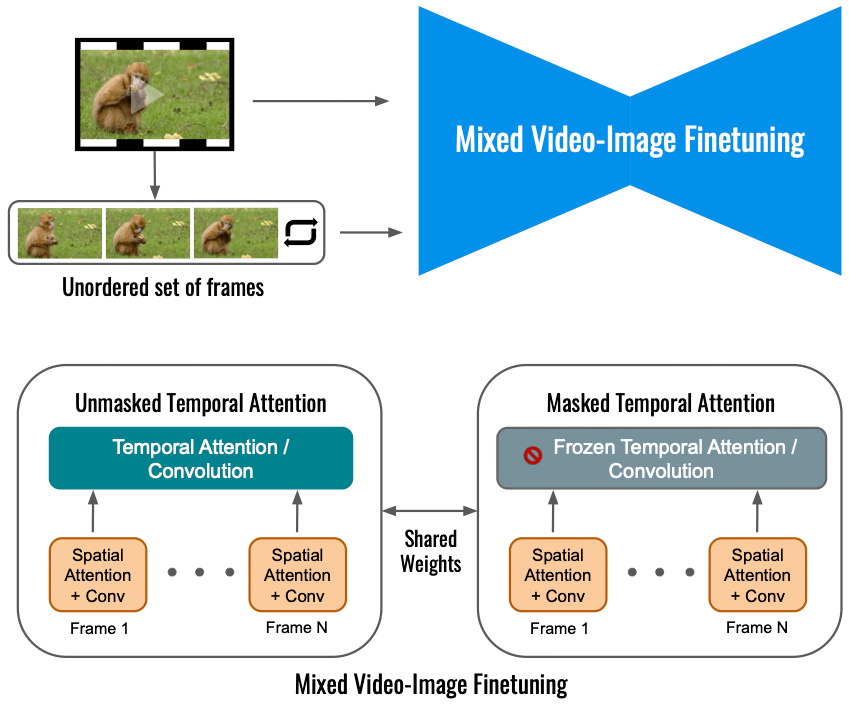
A Google szerint a Dreamix videó diffúziós modelljének finomhangolása a bemeneti videón önmagában korlátozza a mozgásváltozás mértékét. Ehelyett egy vegyes objektívet használunk, amely az eredeti objektív (bal alsó) mellett a rendezetlen képkockákon is finomhangol. Ez a „maszkolt időbeli figyelem” használatával történik, megakadályozva az időbeli figyelem és a konvolúció finomhangolását (jobbra lent). Ez lehetővé teszi mozgás hozzáadását egy statikus videóhoz.
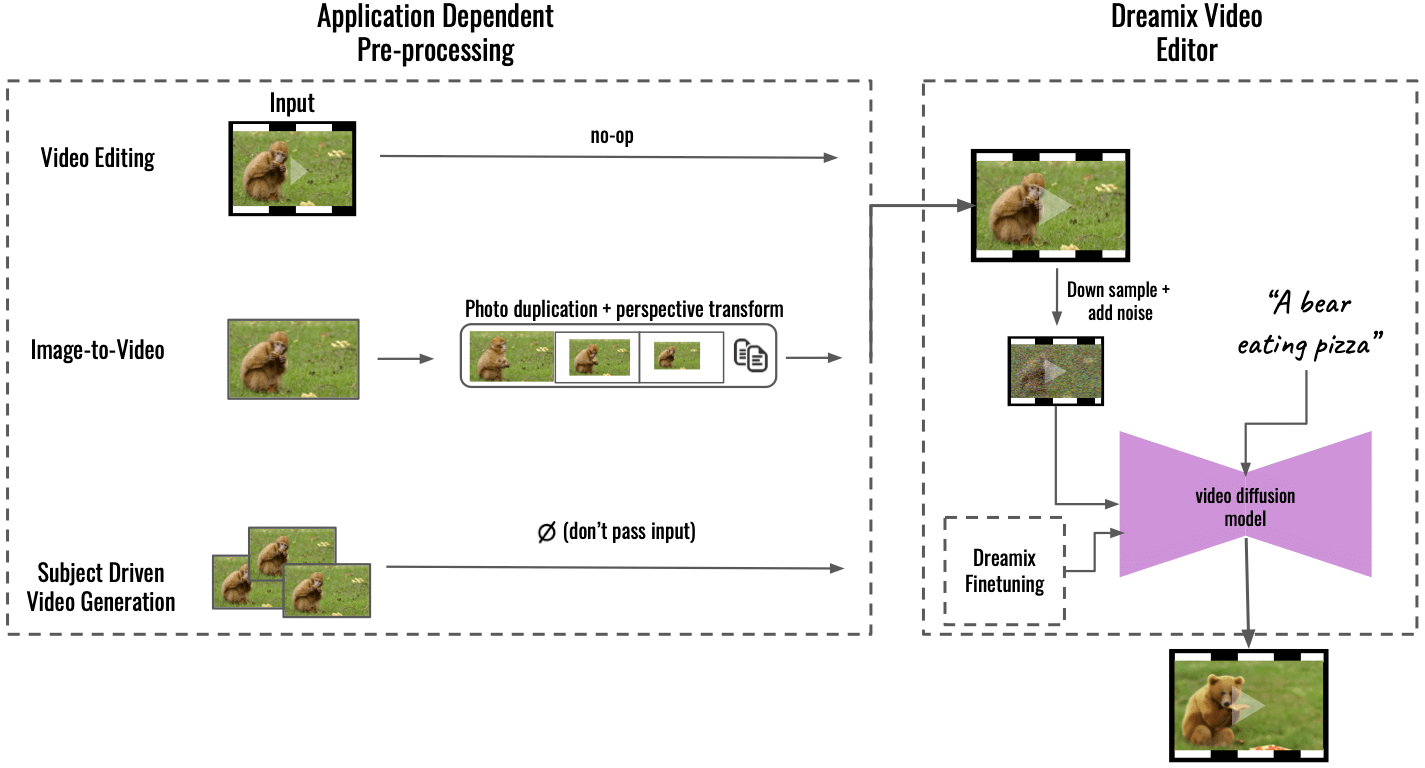
„Módszerünk több alkalmazást is támogat alkalmazásfüggő előfeldolgozással (balra), a bemeneti tartalmat egységes videoformátummá alakítva. Kép-videó esetén a bemeneti kép megkettőződik és perspektivikus transzformációkkal átalakul, így szintetizálva egy durva videót némi kameramozgással. A téma által vezérelt videógenerálásnál a bemenetet kihagyjuk – a finomhangolás önmagában gondoskodik a hűségről. Ezt a durva videót az általános „Dreamix Video Editor” (jobbra) segítségével szerkesztjük: először a videót rontjuk le mintavételezéssel, majd zaj hozzáadásával. Ezután alkalmazzuk a finomhangolt szövegvezérelt videó diffúziós modellt, amely felskálázza a videót a végső térbeli és időbeli felbontásra” – írta Dream. GitHub.
A kutatási anyagot alább olvashatja.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://techstartups.com/2023/02/10/google-launches-ai-powered-video-editor-dreamix-to-create-edit-videos-and-animate-images/
- a
- Képes
- Szerint
- AI
- ai videó
- AI-hajtású
- Minden termék
- lehetővé teszi, hogy
- kizárólag
- és a
- Másik
- alkalmazások
- alkalmazott
- alkalmaz
- megközelítés
- mesterséges
- figyelem
- alapján
- Viselik
- szép
- mert
- hogy
- lent
- test
- fellendítése
- Alsó
- Bring
- szoba
- nem tud
- ami
- változik
- ChatGPT
- közelebb
- szín
- össze
- következetes
- tartalom
- létrehozása
- ciklus
- Tánc
- Diffusion
- álom
- szerkesztő
- beágyazott
- Ez volt
- példa
- létező
- kevés
- hűség
- utolsó
- vezetéknév
- követ
- formátum
- ból ből
- jövő
- általános
- generál
- generált
- generáció
- gif
- GitHub
- adott
- Haj
- súlyosan
- nagy felbontású
- Hogyan
- azonban
- HTTPS
- kép
- képek
- in
- információ
- bemenet
- helyette
- IT
- elindítja
- határértékek
- fenntartja
- anyag
- max
- módszer
- vegyes
- modell
- modellek
- módosítása
- pillanat
- a legtöbb
- mozgás
- mozgások
- mozgó
- többszörös
- zene
- Új
- hír
- Zaj
- tárgy
- célkitűzés
- Ajánlatok
- nyílt forráskódú
- OpenAI
- narancs
- eredeti
- Egyéb
- áttekintés
- Oxigén
- Papír
- teljesít
- perspektíva
- Plató
- Platón adatintelligencia
- PlatoData
- medence
- lehetséges
- be
- megakadályozása
- feldolgozás
- biztató
- ingatlanait
- közzétett
- csendesen
- Olvass
- Valóság
- felvétel
- csökkentő
- megköveteli,
- kutatás
- Felbontás
- kapott
- visszatartó
- Mondott
- színhely
- készlet
- jelentősen
- egyetlen
- Méret
- So
- néhány
- stabil
- Színpad
- későbbi
- sikeresen
- ilyen
- Támogatja
- Vesz
- sablon
- A
- idő
- nak nek
- transzformációk
- át
- bemutatta
- használ
- keresztül
- videó
- Videók
- Víz
- ami
- dolgozó
- művek
- youtube
- zephyrnet