यह एक दिलचस्प विचार है, जिसमें सिमुलेशन में तेजी लाने के लिए हार्डवेयर-समर्थित सट्टा समानता का उपयोग किया जाता है, जिसमें कस्टम हार्डवेयर की आवश्यकता होती है। पॉल कनिंघम (सीनियर वीपी/जीएम, वेरिफिकेशन एट कैडेंस), राउल कैंपोसानो (सिलिकॉन कैटलिस्ट, उद्यमी, पूर्व सिनोप्सिस सीटीओ और अब सिल्वाको सीटीओ) और मैं शोध विचारों पर हमारी श्रृंखला जारी रखते हैं। हमेशा की तरह, प्रतिक्रिया का स्वागत है।

द इनोवेशन
इस महीने की पसंद है क्रोनोस: त्वरक के लिए कुशल सट्टा समानता. लेखकों ने प्रोग्रामिंग भाषाओं और ऑपरेटिंग सिस्टम के लिए आर्किटेक्चरल सपोर्ट पर 2020 सम्मेलन में पेपर प्रस्तुत किया और वे एमआईटी से हैं।
मल्टीकोर प्रोसेसर का उपयोग करके समानता का फायदा उठाना उन अनुप्रयोगों के लिए एक विकल्प है जहां समानता स्वयं-स्पष्ट है। अन्य एल्गोरिदम को इतनी आसानी से विभाजित नहीं किया जा सकता है, लेकिन आंतरिक समानता का फायदा उठाते हुए सट्टा निष्पादन से लाभ हो सकता है। आमतौर पर, सट्टा निष्पादन कैश सुसंगतता पर निर्भर करता है, विशेष रूप से सिमुलेशन के लिए एक उच्च ओवरहेड। यह विधि सुसंगतता की आवश्यकता को दरकिनार कर देती है, लक्ष्य पढ़ने-लिखने वाली वस्तु द्वारा टाइल्स की गणना करने के लिए कार्य निष्पादन को भौतिक रूप से स्थानीयकृत करती है, यह सुनिश्चित करती है कि वैश्विक सुसंगतता प्रबंधन की आवश्यकता के बिना, संघर्ष का पता स्थानीय रूप से लगाया जा सकता है। कार्य समानांतर में सट्टा रूप से निष्पादित हो सकते हैं; पाए गए किसी भी विरोध को किसी कार्य से उसके चाइल्ड कार्यों के माध्यम से हटाया जा सकता है और फिर अन्य थ्रेड्स को रोकने की आवश्यकता के बिना पुन: निष्पादित किया जा सकता है।
यहां ध्यान देने योग्य एक और बात। अधिकांश हार्डवेयर त्वरण तकनीकों के विपरीत, यह विधि विलंब-आधारित सिमुलेशन का समर्थन करती है।
पॉल की राय
वाह, एमआईटी का क्या अद्भुत हाई-ऑक्टेन पेपर है! जब समानांतर गणना के बारे में पूछा गया तो मैं तुरंत थ्रेड्स, म्यूटेक्स और मेमोरी सुसंगतता के बारे में सोचता हूं। निःसंदेह आधुनिक मल्टी-कोर सीपीयू इसी प्रकार डिज़ाइन किए जाते हैं। लेकिन यह हार्डवेयर में समानांतरीकरण का समर्थन करने का एकमात्र तरीका नहीं है।
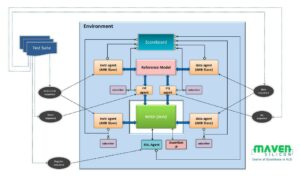
यह पेपर क्रोनोस नामक समानांतरीकरण के लिए एक वैकल्पिक वास्तुकला का प्रस्ताव करता है जो कार्यों की एक क्रमबद्ध कतार पर आधारित है। रनटाइम पर, कार्यों को टाइमस्टैम्प क्रम में निष्पादित किया जाता है और प्रत्येक कार्य नए उप-कार्य बना सकता है जो गतिशील रूप से कतार में जोड़े जाते हैं। निष्पादन कुछ प्रारंभिक कार्यों को कतार में डालने से शुरू होता है और तब समाप्त होता है जब कतार में कोई और कार्य नहीं होते हैं।
कतार में कार्यों को समानांतर में कई प्रसंस्करण तत्वों (पीई) में तैयार किया जाता है - जिसका अर्थ है कि क्रोनोस वर्तमान कार्य पूरा होने से पहले भविष्य के कार्यों को अनुमानित रूप से निष्पादित कर रहा है। यदि वर्तमान कार्य किसी भी अनुमानित रूप से निष्पादित भविष्य के कार्यों को अमान्य कर देता है तो उन भविष्य के कार्यों की कार्रवाइयां "पूर्ववत" हो जाती हैं और उन्हें फिर से कतारबद्ध कर दिया जाता है। हार्डवेयर में इस अवधारणा को सही ढंग से लागू करना आसान नहीं है, लेकिन बाहरी उपयोगकर्ता के लिए यह सुंदर है: आप बस अपने एल्गोरिदम को कोड करते हैं जैसे कि कार्य कतार को एकल पीई पर क्रमिक रूप से निष्पादित किया जा रहा हो। किसी म्यूटेक्स को कोड करने या गतिरोध के बारे में चिंता करने की कोई आवश्यकता नहीं है।
लेखक सिस्टमवेरिलॉग में क्रोनोस को लागू करते हैं और इसे एफपीजीए में संकलित करते हैं। अधिकांश पेपर यह समझाने के लिए समर्पित है कि उन्होंने अधिकतम दक्षता के लिए कार्य कतार और हार्डवेयर में किसी आवश्यक अनरोलिंग को कैसे लागू किया है। क्रोनोस को चार एल्गोरिदम पर बेंचमार्क किया गया है जो कार्य-कतार आधारित वास्तुकला के लिए उपयुक्त है। प्रत्येक एल्गोरिदम को दो तरीकों से कार्यान्वित किया जाता है: पहला एक समर्पित एल्गोरिदम-विशिष्ट पीई का उपयोग करना, और दूसरा पीई के रूप में एक ऑफ द शेल्फ ओपन सोर्स 32-बिट एम्बेडेड आरआईएससी-वी सीपीयू का उपयोग करना। फिर क्रोनोस के प्रदर्शन की तुलना इंटेल ज़ीऑन सर्वर पर चलने वाले एल्गोरिदम के बहु-थ्रेडेड सॉफ़्टवेयर कार्यान्वयन से की जाती है, जिसकी कीमत क्रोनोस के लिए उपयोग किए जा रहे एफपीजीए के समान होती है। परिणाम प्रभावशाली हैं - Xeon सर्वर का उपयोग करने की तुलना में क्रोनोस का स्केल 3x से 15x बेहतर है। हालाँकि, तालिका 3 की चित्र 14 से तुलना करने से मुझे थोड़ी चिंता होती है कि इनमें से अधिकांश लाभ क्रोनोस आर्किटेक्चर के बजाय एल्गोरिदम-विशिष्ट पीई से आए हैं।
यह देखते हुए कि यह एक सत्यापन ब्लॉग है, मैंने स्वाभाविक रूप से गेट-स्तरीय सिमुलेशन बेंचमार्क पर ज़ूम इन किया। ईडीए उद्योग ने तर्क सिमुलेशन को आजमाने और समानांतर करने के लिए भारी निवेश किया है और कुछ विशिष्ट उपयोग के मामलों से परे बड़े लाभ देखना मुश्किल साबित हुआ है। यह मुख्य रूप से अधिकांश वास्तविक दुनिया सिमुलेशन के प्रदर्शन के कारण L3-कैश में लोड/स्टोर निर्देशों के गायब होने और DRAM में जाने के कारण होता है। इस पेपर में केवल एक टेस्टकेस बेंचमार्क किया गया है और यह एक छोटा 32-बिट कैरी सेव एडर है। यदि आप इस ब्लॉग को पढ़ रहे हैं और कुछ और गहन बेंचमार्किंग करने में रुचि रखते हैं तो कृपया मुझे बताएं - यदि क्रोनोस वास्तव में वास्तविक दुनिया सिमुलेशन पर अच्छा स्केल कर सकता है तो इसका बहुत बड़ा व्यावसायिक मूल्य होगा!
राउल की राय
इस पेपर का मुख्य योगदान है स्थानिक रूप से स्थित आदेशित कार्य (एसएलओटी) निष्पादन मॉडल जो हार्डवेयर त्वरक के लिए कुशल है जो समानता और अटकलों का फायदा उठाते हैं, और उन अनुप्रयोगों के लिए जो रनटाइम पर गतिशील रूप से कार्य उत्पन्न करते हैं। सिमुलेशन के लिए गतिशील समानता समर्थन अपरिहार्य है और सट्टा सिंक्रनाइज़ेशन एक आकर्षक विकल्प है, लेकिन सुसंगतता ओवरहेड बहुत अधिक है।
SLOT प्रत्येक कार्य को एक ही वस्तु पर संचालित (लिखने) तक सीमित करके सुसंगतता की आवश्यकता से बचता है और बहु-वस्तु परमाणुता को सक्षम करने के लिए आदेशित कार्यों का समर्थन करता है। स्लॉट एप्लिकेशन को ऑर्डर किया जाता है, टाइमस्टैम्प और ऑब्जेक्ट आईडी द्वारा विशेषता वाले गतिशील रूप से बनाए गए कार्य। टाइमस्टैम्प ऑर्डर की बाधाओं को निर्दिष्ट करते हैं; ऑब्जेक्ट आईडी डेटा निर्भरता निर्दिष्ट करती हैं, यानी, कार्य डेटा-निर्भर होते हैं यदि और केवल तभी जब उनकी ऑब्जेक्ट आईडी समान हो। (यदि पढ़ने पर निर्भरता है तो कार्य को अनुमानतः निष्पादित किया जा सकता है)। ऑब्जेक्ट आईडी को कोर या टाइल्स पर मैप करके और प्रत्येक कार्य को वहां भेजकर जहां उसकी ऑब्जेक्ट आईडी मैप की गई है, संघर्ष का पता लगाना स्थानीय (जटिल ट्रैकिंग संरचनाओं के बिना) हो जाता है।
RSI Chronos सिस्टम को AWS FPGA फ्रेमवर्क में 16 टाइल्स वाले सिस्टम के रूप में लागू किया गया था, प्रत्येक में 4 एप्लिकेशन विशिष्ट प्रोसेसिंग तत्व (PE) थे, जो 125MHz पर चल रहे थे। इस प्रणाली की तुलना 20-कोर/40-थ्रेड 2.4 GHz Intel Xeon E5-2676v3 से युक्त बेसलाइन से की जाती है, जिसे विशेष रूप से इसलिए चुना गया है क्योंकि इसकी कीमत FPGA वन (लगभग $2/घंटा) के साथ तुलनीय है। एक पीई पर एकल कार्य चलाना, क्रोनोस बेसलाइन से 2.45 गुना तेज है। जैसे-जैसे समवर्ती कार्यों की संख्या बढ़ती है, क्रोनोस कार्यान्वयन 44.9 टाइल्स पर 8x के स्व-सापेक्ष स्पीडअप तक बढ़ जाता है, जो सीपीयू कार्यान्वयन पर 15.3x स्पीडअप के अनुरूप होता है। उन्होंने अनुप्रयोग विशिष्ट पीई के बजाय सामान्य प्रयोजन आरआईएससी-वी पर आधारित कार्यान्वयन की तुलना भी की; पीई आरआईएससी-वी से 5 गुना तेज थे।
मुझे पेपर प्रभावशाली लगा क्योंकि इसमें एक अवधारणा से लेकर स्लॉट निष्पादन मॉडल की परिभाषा, हार्डवेयर के कार्यान्वयन और 4 अनुप्रयोगों के लिए पारंपरिक ज़ीऑन सीपीयू के साथ विस्तृत तुलना तक सब कुछ शामिल है। प्रयास पर्याप्त है, क्रोनोस SystemVerilog की 20,000 से अधिक लाइनें हैं। अधिक समानता और सट्टा निष्पादन के अधिक उपयोग के कारण, परिणाम सॉफ्टवेयर-समानांतर संस्करणों पर 5.4x औसत (4 अनुप्रयोगों में से) स्पीडअप है। गैर-सिमुलेशन कार्यों के अनुप्रयोग के लिए भी यह पेपर पढ़ने लायक है; पेपर में तीन उदाहरण शामिल हैं।
इस पोस्ट को इसके माध्यम से साझा करें:
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://semiwiki.com/eda/326261-speculation-for-simulation-innovation-in-verification/
- :है
- 000
- 2020
- 8
- a
- About
- में तेजी लाने के
- त्वरण
- त्वरक
- एसीएम
- कार्रवाई
- जोड़ा
- कलन विधि
- एल्गोरिदम
- वैकल्पिक
- हमेशा
- और
- आकर्षक
- आवेदन
- आवेदन विशिष्ट
- अनुप्रयोगों
- वास्तु
- स्थापत्य
- हैं
- AS
- At
- लेखकों
- एडब्ल्यूएस
- आधारित
- आधारभूत
- BE
- सुंदर
- क्योंकि
- हो जाता है
- से पहले
- जा रहा है
- बेंचमार्क
- बेंचमार्क
- लाभ
- बेहतर
- परे
- बड़ा
- बिट
- ब्लॉग
- by
- कैश
- ताल
- बुलाया
- कर सकते हैं
- ले जाना
- मामलों
- उत्प्रेरक
- विशेषता
- बच्चा
- करने के लिए चुना
- कोड
- वाणिज्यिक
- तुलनीय
- तुलना
- की तुलना
- तुलना
- पूरा
- जटिल
- गणना
- गणना करना
- संकल्पना
- समवर्ती
- सम्मेलन
- संघर्ष
- मिलकर
- की कमी
- जारी रखने के
- योगदान
- इसी
- पाठ्यक्रम
- शामिल किया गया
- सी पी यू
- बनाना
- बनाया
- सीटीओ
- वर्तमान
- रिवाज
- तिथि
- समर्पित
- निर्भरता
- निर्भर करता है
- बनाया गया
- विस्तृत
- पता चला
- खोज
- मुश्किल
- गतिशील
- गतिशील
- e
- से प्रत्येक
- आसानी
- दक्षता
- कुशल
- प्रयास
- तत्व
- एम्बेडेड
- सक्षम
- समाप्त होता है
- सुनिश्चित
- उद्यमी
- विशेष रूप से
- सब कुछ
- उदाहरण
- निष्पादित
- को क्रियान्वित
- निष्पादन
- समझा
- शोषण करना
- और तेज
- प्रतिक्रिया
- कुछ
- आकृति
- प्रथम
- के लिए
- पूर्व
- पाया
- FPGA
- ढांचा
- से
- भविष्य
- लाभ
- सामान्य जानकारी
- उत्पन्न
- गीगाहर्ट्ज इंटेल
- वैश्विक
- जा
- हार्डवेयर
- है
- भारी
- यहाँ उत्पन्न करें
- हाई
- कैसे
- तथापि
- HTTPS
- विशाल
- i
- ID
- विचार
- विचारों
- तुरंत
- लागू करने के
- कार्यान्वयन
- कार्यान्वित
- कार्यान्वयन
- प्रभावशाली
- in
- शामिल
- बढ़ जाती है
- उद्योग
- अपरिहार्य
- प्रारंभिक
- नवोन्मेष
- निर्देश
- इंटेल
- रुचि
- दिलचस्प
- आंतरिक
- निवेश
- IT
- आईटी इस
- खुद
- जानना
- भाषाऐं
- पंक्तियां
- स्थानीय
- स्थानीय स्तर पर
- स्थित
- मुख्य
- बनाता है
- प्रबंध
- मानचित्रण
- अधिकतम-चौड़ाई
- अधिकतम
- साधन
- याद
- तरीका
- हो सकता है
- लापता
- एमआईटी
- आदर्श
- आधुनिक
- अधिक
- अधिकांश
- विभिन्न
- आवश्यक
- आवश्यकता
- नया
- संख्या
- वस्तु
- of
- on
- ONE
- खुला
- खुला स्रोत
- संचालित
- परिचालन
- ऑपरेटिंग सिस्टम
- विकल्प
- आदेश
- अन्य
- बाहर
- पी.ई
- काग़ज़
- समानांतर
- पॉल
- प्रदर्शन
- शारीरिक रूप से
- चुनना
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- कृप्या अ
- बिन्दु
- पद
- प्रस्तुत
- मूल्य
- प्रसंस्करण
- प्रोसेसर
- प्रोग्रामिंग
- प्रोग्रामिंग की भाषाएँ
- का प्रस्ताव
- साबित
- उद्देश्य
- लाना
- बल्कि
- पढ़ना
- पढ़ना
- वास्तविक
- असली दुनिया
- अनुसंधान
- सीमित
- परिणाम
- परिणाम
- दौड़ना
- वही
- सहेजें
- स्केल
- तराजू
- दूसरा
- भेजना
- वरिष्ठ
- कई
- शेल्फ
- सिलिकॉन
- समान
- अनुकार
- एक
- So
- सॉफ्टवेयर
- कुछ
- स्रोत
- विशिष्ट
- विशेष रूप से
- सट्टा
- पर्याप्त
- समर्थन
- समर्थन करता है
- तुल्यकालन
- प्रणाली
- सिस्टम
- तालिका
- टैग
- लक्ष्य
- कार्य
- कार्य
- तकनीक
- कि
- RSI
- इन
- तीन
- यहाँ
- टाइमस्टैम्प
- सेवा मेरे
- भी
- ट्रैकिंग
- परंपरागत
- मोड़
- उपयोग
- उपयोगकर्ता
- आमतौर पर
- सत्यापन
- के माध्यम से
- मार्ग..
- तरीके
- में आपका स्वागत है
- कुंआ
- क्या
- कौन कौन से
- साथ में
- बिना
- अद्भुत
- विश्व
- लायक
- होगा
- लिखना
- आपका
- जेफिरनेट