छवि द्वारा फ्रिमुफ़िल्म्स on Freepik
यह एक ऐसा युग है जहां एआई में प्रतिदिन प्रगति हो रही है। कुछ साल पहले हमारे पास सार्वजनिक तौर पर जनरेट किए गए बहुत सारे AI नहीं थे, लेकिन अब तकनीक हर किसी के लिए सुलभ है। यह कई व्यक्तिगत रचनाकारों या कंपनियों के लिए उत्कृष्ट है जो कुछ जटिल विकसित करने के लिए प्रौद्योगिकी का महत्वपूर्ण लाभ उठाना चाहते हैं, जिसमें लंबा समय लग सकता है।
सबसे अविश्वसनीय सफलताओं में से एक जो हमारे काम करने के तरीके को बदल देती है, वह है इसकी रिलीज OpenAI द्वारा GPT-3.5 मॉडल. GPT-3.5 मॉडल क्या है? अगर मैं मॉडल को अपने बारे में बात करने दूँ। उस स्थिति में, उत्तर है "प्राकृतिक भाषा प्रसंस्करण के क्षेत्र में एक अत्यधिक उन्नत एआई मॉडल, प्रासंगिक रूप से सटीक और प्रासंगिक टेक्स्ट उत्पन्न करने में व्यापक सुधार के साथटी "।
OpenAI GPT-3.5 मॉडल के लिए एक एपीआई प्रदान करता है जिसका उपयोग हम एक सरल ऐप विकसित करने के लिए कर सकते हैं, जैसे कि टेक्स्ट सारांश। ऐसा करने के लिए, हम मॉडल एपीआई को अपने इच्छित एप्लिकेशन में निर्बाध रूप से एकीकृत करने के लिए पायथन का उपयोग कर सकते हैं। प्रक्रिया कैसी दिखती है? आइए इसमें शामिल हों।
इस ट्यूटोरियल का अनुसरण करने से पहले कुछ आवश्यक शर्तें हैं, जिनमें शामिल हैं:
- पायथन का ज्ञान, जिसमें बाहरी पुस्तकालयों और आईडीई का उपयोग करने का ज्ञान शामिल है
- एपीआई को समझना और पायथन के साथ समापन बिंदु को संभालना
– OpenAI API तक पहुंच होना
OpenAI API एक्सेस प्राप्त करने के लिए, हमें इस पर पंजीकरण करना होगा OpenAI डेवलपर प्लेटफ़ॉर्म और अपनी प्रोफ़ाइल में एपीआई कुंजी देखें पर जाएं। वेब पर, एपीआई एक्सेस प्राप्त करने के लिए "नई गुप्त कुंजी बनाएं" बटन पर क्लिक करें (नीचे छवि देखें)। कुंजियाँ सहेजना याद रखें, क्योंकि उसके बाद उन्हें कुंजियाँ दिखाई नहीं देंगी।

लेखक द्वारा छवि
पूरी तैयारी के साथ, आइए OpenAI API मॉडल की मूल बातें समझने का प्रयास करें।
RSI GPT-3.5 परिवार मॉडल कई भाषा कार्यों के लिए निर्दिष्ट किया गया था, और परिवार में प्रत्येक मॉडल कुछ कार्यों में उत्कृष्टता प्राप्त करता है। इस ट्यूटोरियल उदाहरण के लिए, हम इसका उपयोग करेंगे gpt-3.5-turbo क्योंकि जब यह लेख लिखा गया था तब इसकी क्षमता और लागत-दक्षता के लिए यह अनुशंसित वर्तमान मॉडल था।
हम अक्सर उपयोग करते हैं text-davinci-003 OpenAI ट्यूटोरियल में, लेकिन हम इस ट्यूटोरियल के लिए वर्तमान मॉडल का उपयोग करेंगे। हम पर भरोसा करेंगे चैटसमापन समापन के बजाय समापन बिंदु क्योंकि वर्तमान अनुशंसित मॉडल एक चैट मॉडल है। भले ही नाम एक चैट मॉडल था, यह किसी भी भाषा कार्य के लिए काम करता है।
आइए समझने की कोशिश करें कि एपीआई कैसे काम करता है। सबसे पहले, हमें वर्तमान OpenAI पैकेज स्थापित करने की आवश्यकता है।
pip install openai
पैकेज स्थापित करने के बाद, हम चैटकंप्लीशन एंडपॉइंट के माध्यम से कनेक्ट करके एपीआई का उपयोग करने का प्रयास करेंगे। हालाँकि, आगे बढ़ने से पहले हमें माहौल तैयार करना होगा।
अपने पसंदीदा आईडीई में (मेरे लिए, यह वीएस कोड है), नामक दो फ़ाइलें बनाएं .env और summarizer_app.py, नीचे दी गई छवि के समान।
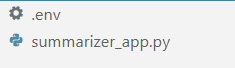
लेखक द्वारा छवि
RSI summarizer_app.py वह जगह है जहां हम अपना सरल सारांश एप्लिकेशन बनाएंगे, और .env फ़ाइल वह जगह है जहां हम अपनी एपीआई कुंजी संग्रहीत करेंगे। सुरक्षा कारणों से, हमेशा यह सलाह दी जाती है कि हमारी एपीआई कुंजी को पायथन फ़ाइल में हार्ड-कोड करने के बजाय किसी अन्य फ़ाइल में अलग करें।
में .env फ़ाइल में निम्नलिखित सिंटैक्स डालें और फ़ाइल को सहेजें। your_api_key_here को अपनी वास्तविक API कुंजी से बदलें। एपीआई कुंजी को स्ट्रिंग ऑब्जेक्ट में न बदलें; उन्हें वैसे ही रहने दो जैसे वे हैं.
OPENAI_API_KEY=your_api_key_here
GPT-3.5 API को बेहतर ढंग से समझने के लिए; हम सारांश शब्द उत्पन्न करने के लिए निम्नलिखित कोड का उपयोग करेंगे।
openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, top_p=0.5, frequency_penalty=0.5, messages=[ { "role": "system", "content": "You are a helpful assistant for text summarization.", }, { "role": "user", "content": f"Summarize this for a {person_type}: {prompt}", }, ],
)
उपरोक्त कोड बताता है कि हम OpenAI API GPT-3.5 मॉडल के साथ कैसे इंटरैक्ट करते हैं। चैटकंप्लीशन एपीआई का उपयोग करके, हम एक वार्तालाप बनाते हैं और प्रॉम्प्ट पास करने के बाद इच्छित परिणाम प्राप्त करेंगे।
आइए उन्हें बेहतर ढंग से समझने के लिए प्रत्येक भाग को तोड़ें। पहली पंक्ति में, हम का उपयोग करते हैं openai.ChatCompletion.create प्रॉम्प्ट से प्रतिक्रिया बनाने के लिए कोड जिसे हम एपीआई में पास करेंगे।
अगली पंक्ति में, हमारे पास हमारे हाइपरपैरामीटर हैं जिनका उपयोग हम अपने टेक्स्ट कार्यों को बेहतर बनाने के लिए करते हैं। यहां प्रत्येक हाइपरपैरामीटर फ़ंक्शन का सारांश दिया गया है:
model: वह मॉडल परिवार जिसका हम उपयोग करना चाहते हैं। इस ट्यूटोरियल में, हम वर्तमान अनुशंसित मॉडल का उपयोग करते हैं (gpt-3.5-turbo).max_tokens: मॉडल द्वारा उत्पन्न शब्दों की ऊपरी सीमा. यह जेनरेट किए गए टेक्स्ट की लंबाई को सीमित करने में मदद करता है।temperature: उच्च तापमान के साथ मॉडल आउटपुट की यादृच्छिकता का मतलब अधिक विविध और रचनात्मक परिणाम है। मान सीमा 0 से अनंत के बीच है, हालाँकि 2 से अधिक मान सामान्य नहीं हैं।top_p: टॉप पी या टॉप-के सैंपलिंग या न्यूक्लियस सैंपलिंग आउटपुट वितरण से सैंपलिंग पूल को नियंत्रित करने के लिए एक पैरामीटर है। उदाहरण के लिए, मान 0.1 का मतलब है कि मॉडल केवल वितरण के शीर्ष 10% से आउटपुट का नमूना लेता है। मान सीमा 0 और 1 के बीच थी; उच्च मूल्यों का मतलब अधिक विविध परिणाम है।frequency_penalty: आउटपुट से पुनरावृत्ति टोकन के लिए जुर्माना। मान की सीमा -2 से 2 के बीच होती है, जहां सकारात्मक मान मॉडल को टोकन दोहराने से रोकेंगे जबकि नकारात्मक मान मॉडल को अधिक दोहराव वाले शब्दों का उपयोग करने के लिए प्रोत्साहित करेंगे। 0 का मतलब कोई जुर्माना नहीं.messages: वह पैरामीटर जहां हम मॉडल के साथ संसाधित होने के लिए अपना टेक्स्ट प्रॉम्प्ट पास करते हैं। हम शब्दकोशों की एक सूची पास करते हैं जहां कुंजी भूमिका वस्तु है (या तो "सिस्टम", "उपयोगकर्ता", या "सहायक") जो मॉडल को संदर्भ और संरचना को समझने में मदद करती है जबकि मान संदर्भ हैं।- भूमिका "सिस्टम" मॉडल "सहायक" व्यवहार के लिए निर्धारित दिशानिर्देश है,
- भूमिका "उपयोगकर्ता" मॉडल के साथ बातचीत करने वाले व्यक्ति के संकेत का प्रतिनिधित्व करती है,
- "सहायक" की भूमिका "उपयोगकर्ता" संकेत की प्रतिक्रिया है
उपरोक्त पैरामीटर की व्याख्या करने के बाद, हम देख सकते हैं कि messages उपरोक्त पैरामीटर में दो शब्दकोश ऑब्जेक्ट हैं। पहला शब्दकोश यह है कि हम मॉडल को पाठ सारांश के रूप में कैसे सेट करते हैं। दूसरा वह स्थान है जहां हम अपना पाठ पास करेंगे और सारांश आउटपुट प्राप्त करेंगे।
दूसरी डिक्शनरी में आपको वेरिएबल भी दिखेगा person_type और prompt। person_type एक वेरिएबल है जिसका उपयोग मैंने सारांशित शैली को नियंत्रित करने के लिए किया है, जिसे मैं ट्यूटोरियल में दिखाऊंगा। जब prompt वह वह जगह है जहां हम अपने पाठ को सारांशित करने के लिए पास करेंगे।
ट्यूटोरियल को जारी रखते हुए, नीचे दिए गए कोड को इसमें रखें summarizer_app.py फ़ाइल और हम यह देखने का प्रयास करेंगे कि नीचे दिया गया फ़ंक्शन कैसे काम करता है।
import openai
import os
from dotenv import load_dotenv load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY") def generate_summarizer( max_tokens, temperature, top_p, frequency_penalty, prompt, person_type,
): res = openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, top_p=0.5, frequency_penalty=0.5, messages= [ { "role": "system", "content": "You are a helpful assistant for text summarization.", }, { "role": "user", "content": f"Summarize this for a {person_type}: {prompt}", }, ], ) return res["choices"][0]["message"]["content"]
उपरोक्त कोड वह है जहां हम एक पायथन फ़ंक्शन बनाते हैं जो विभिन्न मापदंडों को स्वीकार करेगा जिनकी हमने पहले चर्चा की है और पाठ सारांश आउटपुट लौटाएगा।
उपरोक्त फ़ंक्शन को अपने पैरामीटर के साथ आज़माएं और आउटपुट देखें। तो चलिए स्ट्रीमलिट पैकेज के साथ एक सरल एप्लिकेशन बनाने के लिए ट्यूटोरियल जारी रखें।
स्ट्रीमलाइट एक ओपन-सोर्स पायथन पैकेज है जिसे मशीन लर्निंग और डेटा साइंस वेब ऐप बनाने के लिए डिज़ाइन किया गया है। इसका उपयोग करना आसान और सहज है, इसलिए कई शुरुआती लोगों के लिए इसकी अनुशंसा की जाती है।
आइए ट्यूटोरियल जारी रखने से पहले स्ट्रीमलिट पैकेज इंस्टॉल करें।
pip install streamlit
इंस्टॉलेशन समाप्त होने के बाद, निम्नलिखित कोड डालें summarizer_app.py.
import streamlit as st #Set the application title
st.title("GPT-3.5 Text Summarizer") #Provide the input area for text to be summarized
input_text = st.text_area("Enter the text you want to summarize:", height=200) #Initiate three columns for section to be side-by-side
col1, col2, col3 = st.columns(3) #Slider to control the model hyperparameter
with col1: token = st.slider("Token", min_value=0.0, max_value=200.0, value=50.0, step=1.0) temp = st.slider("Temperature", min_value=0.0, max_value=1.0, value=0.0, step=0.01) top_p = st.slider("Nucleus Sampling", min_value=0.0, max_value=1.0, value=0.5, step=0.01) f_pen = st.slider("Frequency Penalty", min_value=-1.0, max_value=1.0, value=0.0, step=0.01) #Selection box to select the summarization style
with col2: option = st.selectbox( "How do you like to be explained?", ( "Second-Grader", "Professional Data Scientist", "Housewives", "Retired", "University Student", ), ) #Showing the current parameter used for the model with col3: with st.expander("Current Parameter"): st.write("Current Token :", token) st.write("Current Temperature :", temp) st.write("Current Nucleus Sampling :", top_p) st.write("Current Frequency Penalty :", f_pen) #Creating button for execute the text summarization
if st.button("Summarize"): st.write(generate_summarizer(token, temp, top_p, f_pen, input_text, option))
एप्लिकेशन आरंभ करने के लिए अपने कमांड प्रॉम्प्ट में निम्नलिखित कोड को चलाने का प्रयास करें।
streamlit run summarizer_app.py
यदि सब कुछ ठीक से काम करता है, तो आपको अपने डिफ़ॉल्ट ब्राउज़र में निम्नलिखित एप्लिकेशन दिखाई देगा।
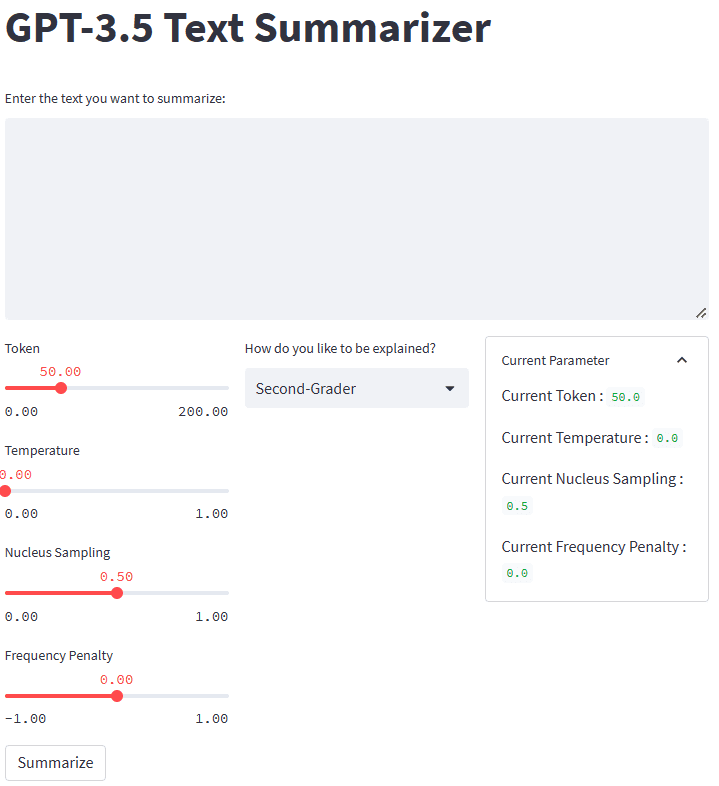
लेखक द्वारा छवि
तो, उपरोक्त कोड में क्या हुआ? आइए हम हमारे द्वारा उपयोग किए गए प्रत्येक फ़ंक्शन को संक्षेप में समझाएं:
.st.title: वेब एप्लिकेशन का शीर्षक पाठ प्रदान करें।.st.write: आवेदन में तर्क लिखता है; यह मुख्य रूप से एक स्ट्रिंग टेक्स्ट के अलावा कुछ भी हो सकता है।.st.text_area: टेक्स्ट इनपुट के लिए एक क्षेत्र प्रदान करें जिसे वेरिएबल में संग्रहीत किया जा सकता है और हमारे टेक्स्ट सारांश के लिए संकेत के लिए उपयोग किया जा सकता है.st.columns: साइड-बाय-साइड इंटरैक्शन प्रदान करने के लिए ऑब्जेक्ट कंटेनर।.st.slider: सेट मानों के साथ एक स्लाइडर विजेट प्रदान करें जिसके साथ उपयोगकर्ता इंटरैक्ट कर सके। मान को मॉडल पैरामीटर के रूप में उपयोग किए जाने वाले वेरिएबल पर संग्रहीत किया जाता है।.st.selectbox: उपयोगकर्ताओं को अपनी इच्छित सारांश शैली का चयन करने के लिए एक चयन विजेट प्रदान करें। उपरोक्त उदाहरण में, हम पाँच अलग-अलग शैलियों का उपयोग करते हैं।.st.expander: एक कंटेनर प्रदान करें जिसे उपयोगकर्ता विस्तारित कर सकें और कई ऑब्जेक्ट रख सकें।.st.button: एक बटन प्रदान करें जो उपयोगकर्ता द्वारा दबाए जाने पर इच्छित फ़ंक्शन चलाता है।
चूंकि स्ट्रीमलाइट स्वचालित रूप से ऊपर से नीचे तक दिए गए कोड का पालन करते हुए यूआई को डिजाइन करेगा, हम इंटरैक्शन पर अधिक ध्यान केंद्रित कर सकते हैं।
सभी टुकड़ों को सही जगह पर रखते हुए, आइए एक पाठ उदाहरण के साथ हमारे सारांश अनुप्रयोग को आज़माएँ। हमारे उदाहरण के लिए, मैं इसका उपयोग करूंगा सापेक्षता का सिद्धांत विकिपीडिया पृष्ठ पाठ को संक्षेप में प्रस्तुत किया जाना है। एक डिफ़ॉल्ट पैरामीटर और दूसरे-ग्रेडर शैली के साथ, हम निम्नलिखित परिणाम प्राप्त करते हैं।
Albert Einstein was a very smart scientist who came up with two important ideas about how the world works. The first one, called special relativity, talks about how things move when there is no gravity. The second one, called general relativity, explains how gravity works and how it affects things in space like stars and planets. These ideas helped us understand many things in science, like how particles interact with each other and even helped us discover black holes!
आपको उपरोक्त से भिन्न परिणाम प्राप्त हो सकता है। आइए गृहिणियों की शैली को आज़माएं और पैरामीटर को थोड़ा संशोधित करें (टोकन 100, तापमान 0.5, न्यूक्लियस नमूनाकरण 0.5, आवृत्ति दंड 0.3)।
The theory of relativity is a set of physics theories proposed by Albert Einstein in 1905 and 1915. It includes special relativity, which applies to physical phenomena without gravity, and general relativity, which explains the law of gravitation and its relation to the forces of nature. The theory transformed theoretical physics and astronomy in the 20th century, introducing concepts like 4-dimensional spacetime and predicting astronomical phenomena like black holes and gravitational waves.
जैसा कि हम देख सकते हैं, हमारे द्वारा प्रदान किए गए समान पाठ की शैली में अंतर है। परिवर्तन संकेत और पैरामीटर के साथ, हमारा एप्लिकेशन अधिक कार्यात्मक हो सकता है।
हमारे टेक्स्ट सारांश एप्लिकेशन का समग्र स्वरूप नीचे दी गई छवि में देखा जा सकता है।
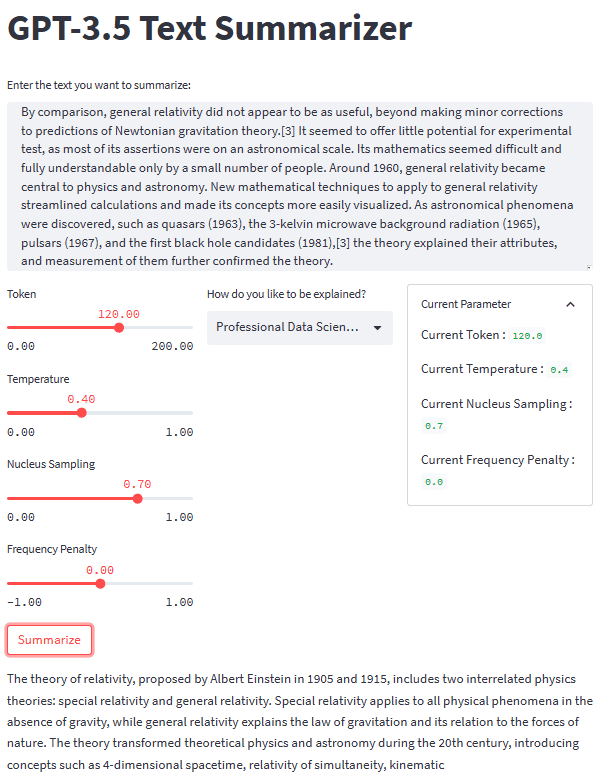
लेखक द्वारा छवि
यह GPT-3.5 के साथ टेक्स्ट सारांश अनुप्रयोग विकास बनाने पर ट्यूटोरियल है। आप एप्लिकेशन में और भी बदलाव कर सकते हैं और एप्लिकेशन को तैनात कर सकते हैं।
जेनरेटिव एआई बढ़ रहा है, और हमें एक शानदार एप्लिकेशन बनाकर अवसर का उपयोग करना चाहिए। इस ट्यूटोरियल में, हम सीखेंगे कि GPT-3.5 OpenAI API कैसे काम करते हैं और पायथन और स्ट्रीमलिट पैकेज की मदद से टेक्स्ट समराइज़र एप्लिकेशन बनाने के लिए उनका उपयोग कैसे करें।
कार्नेलियस युधा विजया एक डेटा साइंस असिस्टेंट मैनेजर और डेटा राइटर है। एलियांज इंडोनेशिया में पूर्णकालिक काम करते हुए, उन्हें सोशल मीडिया और राइटिंग मीडिया के माध्यम से पायथन और डेटा टिप्स साझा करना पसंद है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/2023/04/text-summarization-development-python-tutorial-gpt35.html?utm_source=rss&utm_medium=rss&utm_campaign=text-summarization-development-a-python-tutorial-with-gpt-3-5
- :है
- ][पी
- $यूपी
- 1
- 100
- 28
- 7
- a
- About
- ऊपर
- स्वीकार करें
- पहुँच
- सुलभ
- सही
- अधिग्रहण
- उन्नत
- लाभ
- बाद
- AI
- सब
- एलिआंज़
- हालांकि
- हमेशा
- और
- अन्य
- जवाब
- एपीआई
- एपीआई एक्सेस
- एपीआई
- अनुप्रयोग
- आवेदन
- अनुप्रयोग विकास
- क्षुधा
- हैं
- क्षेत्र
- तर्क
- लेख
- AS
- सहायक
- खगोल
- At
- स्वतः
- बुनियादी
- BE
- क्योंकि
- से पहले
- शुरुआती
- नीचे
- बेहतर
- के बीच
- बिट
- काली
- काला छेद
- तल
- मुक्केबाज़ी
- टूटना
- सफलता
- सफलताओं
- संक्षिप्त
- ब्राउज़र
- निर्माण
- बटन
- by
- बुलाया
- कर सकते हैं
- मामला
- सदी
- परिवर्तन
- विकल्प
- क्लिक करें
- कोड
- स्तंभ
- अ रहे है
- सामान्य
- कंपनियों
- समापन
- जटिल
- अवधारणाओं
- कनेक्ट कर रहा है
- कंटेनर
- कंटेनरों
- सामग्री
- प्रसंग
- जारी रखने के
- नियंत्रण
- कन्वर्सेशन (Conversation)
- सका
- बनाना
- बनाना
- क्रिएटिव
- रचनाकारों
- वर्तमान
- दैनिक
- तिथि
- डेटा विज्ञान
- आँकड़े वाला वैज्ञानिक
- चूक
- तैनात
- डिज़ाइन
- बनाया गया
- विकसित करना
- डेवलपर
- विकास
- अंतर
- विभिन्न
- अन्य वायरल पोस्ट से
- चर्चा की
- वितरण
- कई
- dont
- नीचे
- से प्रत्येक
- भी
- प्रोत्साहित करना
- endpoint
- दर्ज
- वातावरण
- युग
- ईथर (ईटीएच)
- और भी
- हर कोई
- सब कुछ
- उदाहरण
- उत्कृष्ट
- निष्पादित
- विस्तार
- समझाना
- समझाया
- बताते हैं
- बाहरी
- परिवार
- शानदार
- पसंदीदा
- कुछ
- खेत
- पट्टिका
- फ़ाइलें
- प्रथम
- फोकस
- निम्नलिखित
- के लिए
- ताकतों
- आवृत्ति
- से
- समारोह
- कार्यात्मक
- आगे
- सामान्य जानकारी
- उत्पन्न
- उत्पन्न
- सृजन
- मिल
- दी
- गुरूत्वीय
- गुरुत्वाकर्षण लहरों
- गंभीरता
- दिशा निर्देशों
- हैंडलिंग
- हुआ
- है
- होने
- मदद
- मदद की
- सहायक
- मदद करता है
- यहाँ उत्पन्न करें
- उच्चतर
- अत्यधिक
- पकड़
- छेद
- कैसे
- How To
- हम कैसे काम करते हैं
- तथापि
- HTTPS
- i
- विचारों
- की छवि
- आयात
- महत्वपूर्ण
- में सुधार
- सुधार
- in
- शामिल
- सहित
- अविश्वसनीय
- व्यक्ति
- इंडोनेशिया
- अनन्तता
- आरंभ
- निवेश
- स्थापित
- स्थापित कर रहा है
- बजाय
- एकीकृत
- बातचीत
- बातचीत
- बातचीत
- शुरू करने
- सहज ज्ञान युक्त
- IT
- आईटी इस
- जेपीजी
- केडनगेट्स
- कुंजी
- Instagram पर
- ज्ञान
- भाषा
- कानून
- जानें
- सीख रहा हूँ
- लंबाई
- पुस्तकालयों
- पसंद
- सीमा
- लाइन
- लिंक्डइन
- सूची
- लंबा
- लंबे समय तक
- देखिए
- हमशक्ल
- मशीन
- यंत्र अधिगम
- प्रबंधक
- बहुत
- साधन
- मीडिया
- message
- हो सकता है
- आदर्श
- अधिक
- अधिकांश
- चाल
- विभिन्न
- नाम
- प्राकृतिक
- प्राकृतिक भाषा
- प्राकृतिक भाषा संसाधन
- प्रकृति
- आवश्यकता
- नकारात्मक
- नया
- अगला
- वस्तु
- वस्तुओं
- प्राप्त
- of
- on
- ONE
- खुला स्रोत
- OpenAI
- अवसर
- विकल्प
- OS
- अन्य
- उत्पादन
- कुल
- पैकेज
- संकुल
- प्राचल
- पैरामीटर
- भाग
- पासिंग
- व्यक्ति
- भौतिक
- भौतिक विज्ञान
- टुकड़े
- जगह
- ग्रह
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- पूल
- सकारात्मक
- की भविष्यवाणी
- आवश्यक शर्तें
- पहले से
- प्रक्रिया
- प्रसंस्करण
- पेशेवर
- प्रोफाइल
- प्रस्तावित
- प्रदान करना
- प्रदान करता है
- सार्वजनिक
- रखना
- अजगर
- अनियमितता
- रेंज
- बल्कि
- तैयार
- कारण
- की सिफारिश की
- रजिस्टर
- संबंध
- और
- प्रासंगिक
- याद
- बार - बार आने वाला
- की जगह
- का प्रतिनिधित्व करता है
- प्रतिक्रिया
- परिणाम
- वापसी
- वृद्धि
- भूमिका
- रन
- वही
- सहेजें
- विज्ञान
- वैज्ञानिक
- मूल
- दूसरा
- गुप्त
- अनुभाग
- सुरक्षा
- चयन
- अलग
- सेट
- Share
- चाहिए
- दिखाना
- दिखाया
- काफी
- समान
- सरल
- स्लाइडर
- स्मार्ट
- So
- सोशल मीडिया
- सोशल मीडिया
- कुछ
- कुछ
- अंतरिक्ष
- विशेष
- विनिर्दिष्ट
- सितारे
- की दुकान
- संग्रहित
- तार
- संरचना
- छात्र
- अंदाज
- शैलियों
- ऐसा
- संक्षेप में प्रस्तुत करना
- सारांश
- वाक्यविन्यास
- प्रणाली
- लेना
- बातचीत
- बाते
- कार्य
- कार्य
- टेक्नोलॉजी
- कि
- RSI
- कानून
- दुनिया
- उन
- अपने
- सैद्धांतिक
- इन
- चीज़ें
- तीन
- यहाँ
- पहर
- सुझावों
- शीर्षक
- सेवा मेरे
- टोकन
- ऊपर का
- तब्दील
- ट्यूटोरियल
- ui
- समझना
- समझ
- विश्वविद्यालय
- us
- उपयोग
- उपयोगकर्ता
- उपयोगकर्ताओं
- उपयोग
- मूल्य
- मान
- विभिन्न
- व्यापक
- के माध्यम से
- देखें
- भेंट
- vs
- बनाम कोड
- लहर की
- वेब
- वेब एप्लीकेशन
- कुंआ
- क्या
- एचएमबी क्या है?
- कौन कौन से
- जब
- कौन
- विकिपीडिया
- मर्जी
- साथ में
- अंदर
- बिना
- शब्द
- शब्द
- काम
- काम कर रहे
- कार्य
- विश्व
- होगा
- लेखक
- लिख रहे हैं
- लिखा हुआ
- साल
- आपका
- जेफिरनेट