एआई पर प्राप्त ज्ञान का एक पहलू यह है कि सभी नवाचार क्लाउड में बड़े मशीन लर्निंग/प्रशिक्षण इंजनों में शुरू होते हैं। उस नवाचार में से कुछ अंततः कम/सीमित रूप में किनारे पर स्थानांतरित हो सकते हैं। यह कुछ हद तक क्षेत्र के नयेपन को दर्शाता है। शायद यह कुछ हद तक IoT विजेट्स के लिए पहले से पैक किए गए एक-आकार-कई फिट समाधानों की आवश्यकता को भी प्रतिबिंबित करता है। जहां डिज़ाइनर अपने उत्पादों में स्मार्ट तो चाहते थे लेकिन एमएल डिज़ाइन विशेषज्ञ बनने के लिए बिल्कुल तैयार नहीं थे। लेकिन अब वे डिज़ाइनर तेजी से आगे बढ़ रहे हैं। वे वही प्रेस विज्ञप्तियाँ और शोध पढ़ते हैं जो हम सभी पढ़ते हैं, जैसा कि उनके प्रतिस्पर्धी करते हैं। वे बिजली और लागत की बाधाओं पर टिके रहते हुए उन्हीं अग्रिमों का लाभ उठाना चाहते हैं।

चेहरे की पहचान
किनारे पर एआई भेदभाव
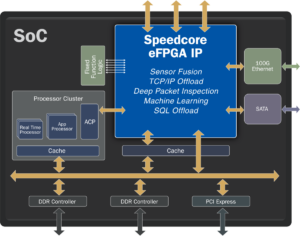
यह सब एक स्वीकार्य लागत/शक्ति लिफाफे के भीतर भेदभाव के बारे में है। पहले से पैक किए गए समाधानों से इसे प्राप्त करना कठिन है। आख़िरकार प्रतिस्पर्धियों के पास समान समाधानों तक पहुंच होती है। आप वास्तव में जो चाहते हैं वह प्रोसेसर में तैयार किए गए एल्गोरिदम विकल्पों का एक सेट है जो उपयोग के लिए तैयार समर्पित त्वरक के रूप में है, जिसमें आपके स्वयं के सॉफ़्टवेयर-आधारित मूल्य-जोड़ने की क्षमता है। आप सोच सकते हैं कि कुछ व्यवस्थापक और ट्यूनिंग के अलावा, आप यहां बहुत कुछ नहीं कर सकते हैं। समय बदल गया है। CEVA ने हाल ही में अपना NeuPro-M एम्बेडेड AI प्रोसेसर पेश किया है जो एल्गोरिदम डिज़ाइन में गहराई से कुछ नवीनतम ML अग्रिमों का उपयोग करके अनुकूलन की अनुमति देता है।
ठीक है, एल्गोरिथम पर इतना अधिक नियंत्रण, लेकिन किस अंत तक? आप प्रति वाट प्रदर्शन को अनुकूलित करना चाहते हैं, लेकिन मानक मीट्रिक - TOPS/W - बहुत मोटा है। इमेजिंग अनुप्रयोगों को फ़्रेम प्रति सेकंड (एफपीएस) प्रति वाट के विरुद्ध मापा जाना चाहिए। सुरक्षा अनुप्रयोगों के लिए, ऑटोमोटिव सुरक्षा, या ड्रोन टकराव से बचाव के लिए, प्रति फ्रेम पहचान समय प्रति सेकंड कच्चे संचालन की तुलना में बहुत अधिक प्रासंगिक है। तो NeuPro-M जैसा प्लेटफ़ॉर्म, जो सैद्धांतिक रूप से हजारों एफपीएस/डब्ल्यू तक प्रदान कर सकता है, बहुत कम पावर पर 30-60 फ्रेम प्रति सेकंड की यथार्थवादी एफपीएस दरों को संभाल लेगा। यह पारंपरिक प्री-पैकेज्ड एआई समाधानों पर एक वास्तविक प्रगति है।
इसे संभव बनाना
अंतिम एल्गोरिदम उन सुविधाओं को डायल करके बनाए जाते हैं जिनके बारे में आपने पढ़ा है, जो परिमाणीकरण विकल्पों की एक विस्तृत श्रृंखला से शुरू होती है। यही बात बिट-आकार की श्रेणी में सक्रियण और भार में डेटा प्रकार की विविधता पर भी लागू होती है। न्यूरल मल्टीप्लायर यूनिट (एनएमयू) सक्रियण और वजन के लिए 8×2 या 16×4 जैसे कई बिट-चौड़ाई विकल्पों का इष्टतम समर्थन करता है और 8×10 जैसे वेरिएंट का भी समर्थन करेगा।
प्रोसेसर विनोग्राड ट्रांसफॉर्म या कुशल कनवल्शन का समर्थन करता है, जो सीमित परिशुद्धता गिरावट के साथ 2X प्रदर्शन लाभ और कम शक्ति प्रदान करता है। शून्य-मानों की मात्रा (या तो डेटा या वजन में) के आधार पर 4X त्वरण के लिए मॉडल में स्पार्सिटी इंजन जोड़ें। यहां, न्यूरल मल्टीप्लायर यूनिट 2×2 से 16×16 तक निश्चित डेटा प्रकारों और 16×16 से 32×32 तक फ्लोटिंग पॉइंट (और बीफ्लोट) का भी समर्थन करता है।
स्ट्रीमिंग लॉजिक निश्चित बिंदु स्केलिंग, सक्रियण और पूलिंग के लिए विकल्प प्रदान करता है। वेक्टर प्रोसेसर आपको मॉडल में अपनी स्वयं की कस्टम परतें जोड़ने की अनुमति देता है। "तो क्या, हर कोई इसका समर्थन करता है", आप सोच सकते हैं लेकिन थ्रूपुट के बारे में नीचे देखें। इसमें विज़न ट्रांसफॉर्मर, 3डी कन्वोल्यूशन, आरएनएन सपोर्ट और मैट्रिक्स डीकंपोजिशन सहित अगली पीढ़ी के एआई फीचर्स का एक सेट भी है।
बहुत सारे एल्गोरिदम विकल्प, सभी आपके एमएल एल्गोरिदम की शक्ति का पूरी तरह से दोहन करने के लिए सीडीएनएन ढांचे के माध्यम से आपके एम्बेडेड समाधान के लिए नेटवर्क अनुकूलन द्वारा समर्थित हैं। CDNN एक नेटवर्क अनुमान ग्राफ़ कंपाइलर और एक समर्पित PyTorch ऐड-ऑन टूल का एक संयोजन है। यह उपकरण मॉडल की छँटाई करेगा, वैकल्पिक रूप से मैट्रिक्स अपघटन के माध्यम से मॉडल संपीड़न का समर्थन करता है, और परिमाणीकरण-जागरूक पुन: प्रशिक्षण जोड़ता है।
थ्रूपुट अनुकूलन
अधिकांश एआई प्रणालियों में, इनमें से कुछ कार्यों को विशेष इंजनों में नियंत्रित किया जा सकता है, जिसके लिए डेटा को ऑफलोड करना होगा और पूरा होने पर ट्रांसफॉर्म को वापस लोड करना होगा। यह बहुत अधिक विलंबता (और शायद बिजली समझौता) है, जो आपके अन्यथा मजबूत मॉडल में प्रदर्शन को पूरी तरह से कमजोर कर देता है। NeuPro-M कनेक्ट करके उस समस्या को समाप्त कर देता है सब ये त्वरक सीधे साझा L1 कैश में जाते हैं। पारंपरिक त्वरक की तुलना में बहुत अधिक बैंडविड्थ बनाए रखना।
एक उल्लेखनीय उदाहरण के रूप में, वेक्टर प्रसंस्करण इकाई, जो आमतौर पर कस्टम परतों को परिभाषित करने के लिए उपयोग की जाती है, अन्य त्वरक के समान स्तर पर बैठती है। वीपीयू में कार्यान्वित आपके एल्गोरिदम बाकी मॉडल के समान त्वरण से लाभान्वित होते हैं। फिर, कस्टम परतों में तेजी लाने के लिए किसी ऑफलोड और पुनः लोड की आवश्यकता नहीं है। इसके अलावा, आपके पास इनमें से 8 एनपीएम इंजन (सभी त्वरक, साथ ही एनपीएम एल1 कैश) हो सकते हैं। NeuPro-M L2 कैश और L1 कैश के बीच सॉफ्टवेयर-नियंत्रित बैंडविड्थ अनुकूलन का एक महत्वपूर्ण स्तर भी प्रदान करता है, फ्रेम हैंडलिंग को अनुकूलित करता है और DDR एक्सेस की आवश्यकता को कम करता है।
स्वाभाविक रूप से NeuPro-M डेटा और वज़न ट्रैफ़िक को भी कम करेगा। डेटा के लिए, त्वरक समान L1 कैश साझा करते हैं। एक होस्ट प्रोसेसर सीधे NeuPro-M L2 के साथ डेटा संचार कर सकता है, जिससे फिर से DDR ट्रांसफर की आवश्यकता कम हो जाती है। न्यूप्रो-एम डीडीआर मेमोरी के साथ स्थानांतरण में ऑन-चिप वजन को संपीड़ित और विघटित करता है। यह सक्रियणों के साथ भी ऐसा ही कर सकता है.
एफपीएस/डब्ल्यू त्वरण में प्रमाण
सीईवीए ने एक्सेलेरेटर में तैयार किए गए एल्गोरिदम के संयोजन का उपयोग करके मानक बेंचमार्क चलाया, मूल से विनोग्राद के माध्यम से, विनोग्राड + स्पार्सिटी से, विनोग्राड + स्पार्सिटी + 4 × 4 तक। दोनों बेंचमार्क ने ISP NN के लिए लगभग 3X पावर (एफपीएस/डब्ल्यू) के साथ 5X तक प्रदर्शन में सुधार दिखाया। NeuPro-M समाधान उनकी पिछली पीढ़ी के NeuPro-S की तुलना में छोटा क्षेत्र, 4X प्रदर्शन, 1/3 शक्ति प्रदान करता है।
एक प्रवृत्ति है जिसे मैं आम तौर पर कई एल्गोरिदम के संयोजन से सर्वोत्तम प्रदर्शन प्राप्त करने के लिए देख रहा हूं। जिसे CEVA ने अब इस प्लेटफॉर्म के साथ संभव बना दिया है। आप और अधिक पढ़ सकते हैं यहाँ.
इस पोस्ट को इसके माध्यम से साझा करें: स्रोत: https://semiwiki.com/artificial-intelligence/306655-ai-at-the-edge-no-longer-means-dumbed-down-ai/
- 3d
- About
- त्वरक
- पहुँच
- के पार
- ऐड ऑन
- इसके अलावा
- व्यवस्थापक
- लाभ
- AI
- एआई सिस्टम
- कलन विधि
- एल्गोरिदम
- सब
- अनुप्रयोगों
- क्षेत्र
- चारों ओर
- मोटर वाहन
- कैश
- CEVA
- बादल
- संयोजन
- प्रतियोगियों
- तिथि
- डिज़ाइन
- विविधता
- परजीवी
- Edge
- उदाहरण
- विशेषज्ञों
- शोषण करना
- चेहरा
- चेहरा पहचान
- विशेषताएं
- प्रपत्र
- ढांचा
- कार्यों
- हैंडलिंग
- यहाँ उत्पन्न करें
- HTTPS
- इमेजिंग
- कार्यान्वित
- सहित
- नवोन्मेष
- शुरू की
- IOT
- आईएसपी
- IT
- ताज़ा
- स्तर
- सीमित
- मैट्रिक्स
- ML
- एमएल एल्गोरिदम
- आदर्श
- अधिक
- जरूरत
- नेटवर्क
- तंत्रिका
- ऑफर
- संचालन
- ऑप्शंस
- अन्य
- अन्यथा
- प्रदर्शन
- शायद
- मंच
- बिजली
- शुद्धता
- दबाना
- प्रेस प्रकाशनी
- उत्पाद
- प्रमाण
- प्रदान करता है
- pytorch
- रेंज
- दरें
- कच्चा
- यथार्थवादी
- विज्ञप्ति
- अनुसंधान
- बाकी
- सुरक्षा
- स्केलिंग
- सुरक्षा
- सेट
- Share
- साझा
- So
- समाधान ढूंढे
- विशेषीकृत
- समर्थन
- समर्थित
- समर्थन करता है
- सिस्टम
- यहाँ
- साधन
- परंपरागत
- यातायात
- बदालना
- दृष्टि
- क्या
- अंदर