लेखक द्वारा छवि
मशीन लर्निंग और डेटा साइंस पर कई पाठ्यक्रम और संसाधन उपलब्ध हैं, लेकिन डेटा इंजीनियरिंग पर बहुत कम हैं। इससे कुछ सवाल खड़े होते हैं. क्या यह एक कठिन क्षेत्र है? क्या यह कम वेतन की पेशकश कर रहा है? क्या इसे अन्य तकनीकी भूमिकाओं की तरह रोमांचक नहीं माना जाता? हालाँकि, वास्तविकता यह है कि कई कंपनियाँ सक्रिय रूप से डेटा इंजीनियरिंग प्रतिभा की तलाश कर रही हैं और पर्याप्त वेतन की पेशकश कर रही हैं, कभी-कभी $200,000 USD से भी अधिक। डेटा इंजीनियर डेटा प्लेटफ़ॉर्म के आर्किटेक्ट के रूप में महत्वपूर्ण भूमिका निभाते हैं, मूलभूत प्रणालियों को डिज़ाइन और निर्माण करते हैं जो डेटा वैज्ञानिकों और मशीन लर्निंग विशेषज्ञों को प्रभावी ढंग से कार्य करने में सक्षम बनाते हैं।
इस उद्योग अंतर को संबोधित करते हुए, डेटाटॉकक्लब ने एक परिवर्तनकारी और मुफ्त बूटकैंप पेश किया है।डेटा इंजीनियरिंग ज़ूमकैंप“. यह पाठ्यक्रम डेटा इंजीनियरिंग में आवश्यक कौशल और व्यावहारिक अनुभव के साथ करियर बदलने की चाह रखने वाले शुरुआती या पेशेवरों को सशक्त बनाने के लिए डिज़ाइन किया गया है।
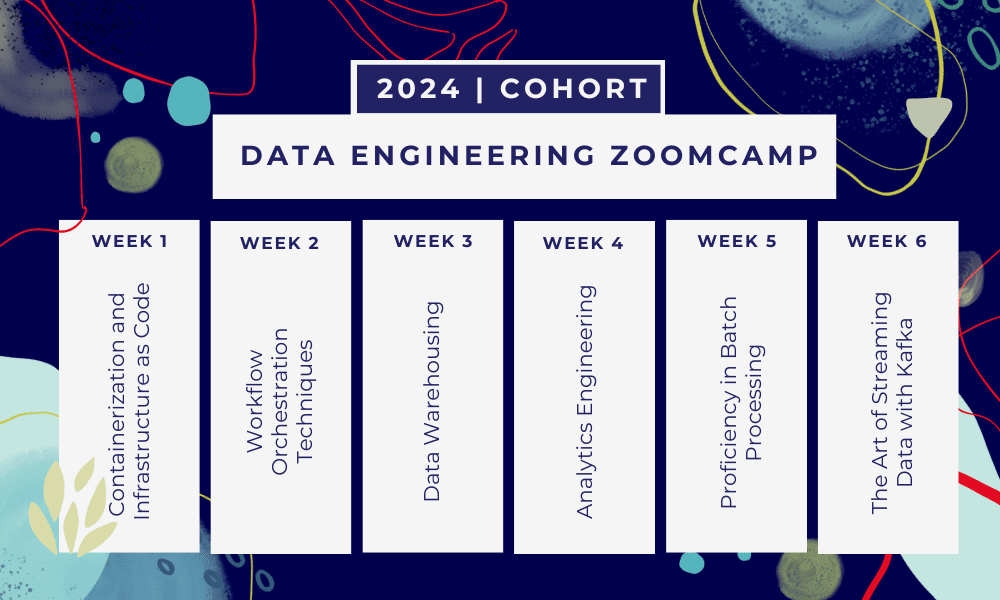
यह एक है 6-सप्ताह का बूटकैंप जहां आप कई पाठ्यक्रमों, पठन सामग्री, कार्यशालाओं और परियोजनाओं के माध्यम से सीखेंगे। प्रत्येक मॉड्यूल के अंत में, आपने जो सीखा है उसका अभ्यास करने के लिए आपको होमवर्क दिया जाएगा।
- सप्ताह 1: जीसीपी, डॉकर, पोस्टग्रेज, टेराफॉर्म और पर्यावरण सेटअप का परिचय।
- सप्ताह 2: मैज के साथ वर्कफ़्लो ऑर्केस्ट्रेशन।
- सप्ताह 3: BigQuery के साथ डेटा वेयरहाउसिंग और BigQuery के साथ मशीन लर्निंग।
- सप्ताह 4: डीबीटी, गूगल डेटा स्टूडियो और मेटाबेस के साथ विश्लेषणात्मक इंजीनियर।
- सप्ताह 5: स्पार्क के साथ बैच प्रसंस्करण।
- सप्ताह 6: काफ्का के साथ स्ट्रीमिंग.
से छवि DataTalksClub/डेटा-इंजीनियरिंग-ज़ूमकैंप
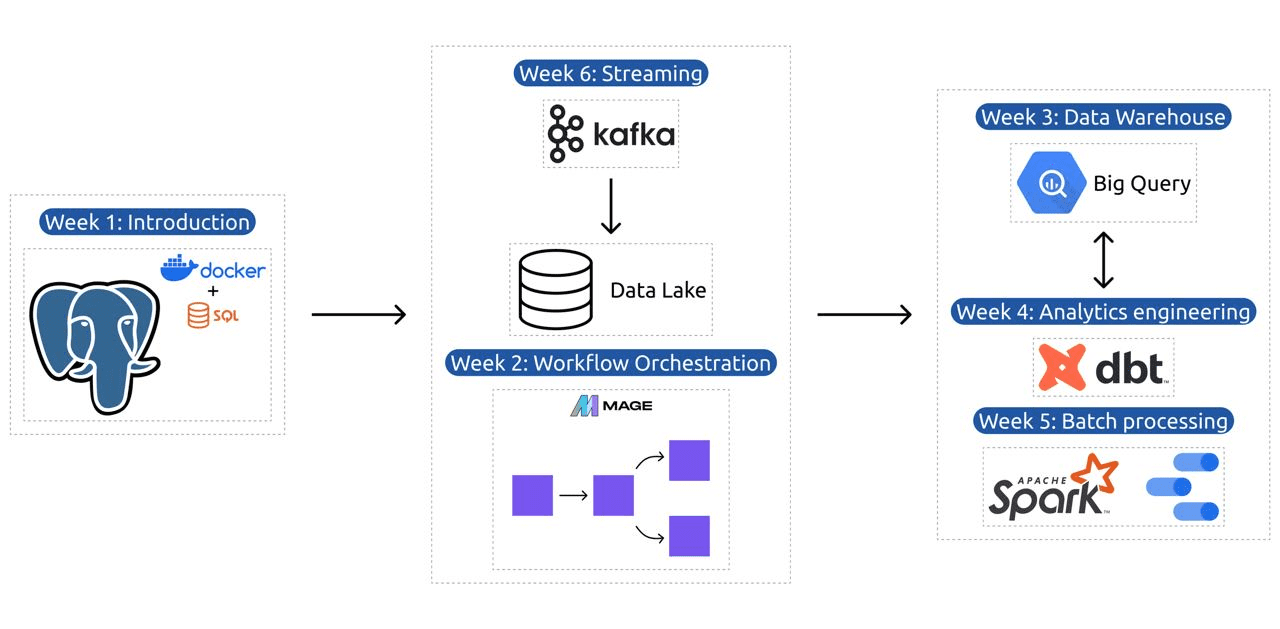
पाठ्यक्रम में 6 मॉड्यूल, 2 कार्यशालाएं और एक प्रोजेक्ट शामिल है जो एक पेशेवर डेटा इंजीनियर बनने के लिए आवश्यक सभी चीजों को शामिल करता है।
मॉड्यूल 1: कोड के रूप में कंटेनरीकरण और बुनियादी ढांचे में महारत हासिल करना
इस मॉड्यूल में, आप डॉकर और पोस्टग्रेज के बारे में सीखेंगे, बुनियादी बातों से शुरू करेंगे और डेटा पाइपलाइन बनाने, डॉकर के साथ पोस्टग्रेज चलाने आदि पर विस्तृत ट्यूटोरियल के माध्यम से आगे बढ़ेंगे।
मॉड्यूल में डॉकर नेटवर्किंग पर वैकल्पिक सामग्री और विंडोज सबसिस्टम लिनक्स उपयोगकर्ताओं के लिए एक विशेष वॉक-थ्रू के साथ पीजीएडमिन, डॉकर-कंपोज़ और एसक्यूएल रिफ्रेशर विषयों जैसे आवश्यक टूल भी शामिल हैं। अंत में, पाठ्यक्रम आपको जीसीपी और टेराफॉर्म से परिचित कराता है, जो आधुनिक क्लाउड-आधारित वातावरण के लिए आवश्यक कोड के रूप में कंटेनरीकरण और बुनियादी ढांचे की समग्र समझ प्रदान करता है।
मॉड्यूल 2: वर्कफ़्लो ऑर्केस्ट्रेशन तकनीकें
मॉड्यूल डेटा परिवर्तन और एकीकरण के लिए एक अभिनव ओपन-सोर्स हाइब्रिड फ्रेमवर्क, मैज की गहन खोज प्रदान करता है। यह मॉड्यूल वर्कफ़्लो ऑर्केस्ट्रेशन की मूल बातें से शुरू होता है, मैज के साथ हाथों-हाथ अभ्यास में प्रगति करता है, जिसमें इसे डॉकर के माध्यम से स्थापित करना और एपीआई से पोस्टग्रेज और Google क्लाउड स्टोरेज (जीसीएस) और फिर बिगक्वेरी में ईटीएल पाइपलाइन बनाना शामिल है।
मॉड्यूल का वीडियो, संसाधनों और व्यावहारिक कार्यों का मिश्रण एक व्यापक शिक्षण अनुभव सुनिश्चित करता है, जो शिक्षार्थियों को मैज का उपयोग करके परिष्कृत डेटा वर्कफ़्लो प्रबंधित करने के कौशल से लैस करता है।
कार्यशाला 1: डेटा अंतर्ग्रहण रणनीतियाँ
पहली कार्यशाला में आप कुशल डेटा अंतर्ग्रहण पाइपलाइनों के निर्माण में महारत हासिल करेंगे। कार्यशाला एपीआई और फ़ाइलों से डेटा निकालने, डेटा को सामान्य बनाने और लोड करने और वृद्धिशील लोडिंग तकनीकों जैसे आवश्यक कौशल पर केंद्रित है। इस कार्यशाला को पूरा करने के बाद, आप एक वरिष्ठ डेटा इंजीनियर की तरह कुशल डेटा पाइपलाइन बनाने में सक्षम होंगे।
मॉड्यूल 3: डेटा वेयरहाउसिंग
मॉड्यूल डेटा भंडारण और विश्लेषण की गहन खोज है, जो BigQuery का उपयोग करके डेटा वेयरहाउसिंग पर ध्यान केंद्रित करता है। यह विभाजन और क्लस्टरिंग जैसी प्रमुख अवधारणाओं को शामिल करता है, और BigQuery की सर्वोत्तम प्रथाओं में गोता लगाता है। मॉड्यूल उन्नत विषयों में प्रगति करता है, विशेष रूप से BigQuery के साथ मशीन लर्निंग (एमएल) का एकीकरण, एमएल के लिए एसक्यूएल के उपयोग पर प्रकाश डालता है, और हाइपरपैरामीटर ट्यूनिंग, फीचर प्रीप्रोसेसिंग और मॉडल परिनियोजन पर संसाधन प्रदान करता है।
मॉड्यूल 4: एनालिटिक्स इंजीनियरिंग
एनालिटिक्स इंजीनियरिंग मॉड्यूल मौजूदा डेटा वेयरहाउस, BigQuery या PostgreSQL के साथ dbt (डेटा बिल्ड टूल) का उपयोग करके एक प्रोजेक्ट बनाने पर केंद्रित है।
मॉड्यूल में क्लाउड और स्थानीय दोनों वातावरणों में डीबीटी स्थापित करना, एनालिटिक्स इंजीनियरिंग अवधारणाओं, ईटीएल बनाम ईएलटी और डेटा मॉडलिंग को शामिल करना शामिल है। इसमें वृद्धिशील मॉडल, टैग, हुक और स्नैपशॉट जैसी उन्नत डीबीटी सुविधाएं भी शामिल हैं।
अंत में, मॉड्यूल Google डेटा स्टूडियो और मेटाबेस जैसे टूल का उपयोग करके रूपांतरित डेटा को विज़ुअलाइज़ करने के लिए तकनीकों का परिचय देता है, और यह समस्या निवारण और कुशल डेटा लोडिंग के लिए संसाधन प्रदान करता है।
मॉड्यूल 5: बैच प्रोसेसिंग में दक्षता
यह मॉड्यूल अपाचे स्पार्क का उपयोग करके बैच प्रोसेसिंग को कवर करता है, जो बैच प्रोसेसिंग और स्पार्क के परिचय के साथ-साथ विंडोज, लिनक्स और मैकओएस के लिए इंस्टॉलेशन निर्देशों से शुरू होता है।
इसमें स्पार्क एसक्यूएल और डेटाफ्रेम की खोज करना, डेटा तैयार करना, एसक्यूएल संचालन करना और स्पार्क आंतरिक को समझना शामिल है। अंत में, यह क्लाउड में स्पार्क चलाने और बिगक्वेरी के साथ स्पार्क को एकीकृत करने के साथ समाप्त होता है।
मॉड्यूल 6: काफ्का के साथ डेटा स्ट्रीम करने की कला
मॉड्यूल स्ट्रीम प्रोसेसिंग अवधारणाओं के परिचय के साथ शुरू होता है, इसके बाद काफ्का की गहन खोज होती है, जिसमें इसके बुनियादी सिद्धांत, कंफ्लुएंट क्लाउड के साथ एकीकरण और उत्पादकों और उपभोक्ताओं से जुड़े व्यावहारिक अनुप्रयोग शामिल हैं।
मॉड्यूल काफ्का कॉन्फ़िगरेशन और स्ट्रीम को भी कवर करता है, स्ट्रीम जॉइन, परीक्षण, विंडोिंग और काफ्का ksqldb और कनेक्ट के उपयोग जैसे विषयों को संबोधित करता है। इसके अतिरिक्त, यह अपना ध्यान पायथन और जेवीएम वातावरण पर केंद्रित करता है, जिसमें पायथन स्ट्रीम प्रोसेसिंग के लिए फॉस्ट, पाइस्पार्क - स्ट्रक्चर्ड स्ट्रीमिंग और काफ्का स्ट्रीम के लिए स्काला उदाहरण शामिल हैं।
कार्यशाला 2: एसक्यूएल के साथ स्ट्रीम प्रोसेसिंग
आप राइजिंगवेव के साथ स्ट्रीमिंग डेटा को संसाधित और प्रबंधित करना सीखेंगे, जो आपके स्ट्रीम प्रोसेसिंग अनुप्रयोगों को सशक्त बनाने के लिए पोस्टग्रेएसक्यूएल-शैली अनुभव के साथ एक लागत प्रभावी समाधान प्रदान करता है।
परियोजना: वास्तविक-विश्व डेटा इंजीनियरिंग अनुप्रयोग
इस परियोजना का उद्देश्य एंड-टू-एंड डेटा पाइपलाइन का निर्माण करने के लिए इस पाठ्यक्रम में सीखी गई सभी अवधारणाओं को लागू करना है। आप एक डेटासेट का चयन करके दो टाइलों से युक्त एक डैशबोर्ड बनाएंगे, डेटा को संसाधित करने और इसे डेटा लेक में संग्रहीत करने के लिए एक पाइपलाइन का निर्माण करेंगे, संसाधित डेटा को डेटा लेक से डेटा वेयरहाउस में स्थानांतरित करने के लिए एक पाइपलाइन का निर्माण करेंगे, परिवर्तन करेंगे। डेटा वेयरहाउस में डेटा और उसे डैशबोर्ड के लिए तैयार करना, और अंत में डेटा को दृश्य रूप से प्रस्तुत करने के लिए एक डैशबोर्ड बनाना।
2024 समूह विवरण
- पंजीकरण: अब दाखिला ले
- आरंभ तिथि: 15 जनवरी 2024, 17:00 सीईटी पर
- निर्देशित समर्थन के साथ स्व-गति से सीखना
- समूह फ़ोल्डर होमवर्क और समय सीमा के साथ
- इंटरैक्टिव सुस्त समुदाय सहकर्मी सीखने के लिए
.. पूर्वापेक्षाएँ
- बुनियादी कोडिंग और कमांड लाइन कौशल
- एसक्यूएल में फाउंडेशन
- पायथन: लाभदायक लेकिन अनिवार्य नहीं
आपकी यात्रा का नेतृत्व करने वाले विशेषज्ञ प्रशिक्षक
- अंकुश खन्ना
- विक्टोरिया पेरेज़ मोला
- एलेक्सी ग्रिगोरेव
- मैट पामर
- लुइस ओलिवेरा
- माइकल शूमेकर
हमारे 2024 समूह में शामिल हों और एक अद्भुत डेटा इंजीनियरिंग समुदाय के साथ सीखना शुरू करें। विशेषज्ञ के नेतृत्व वाले प्रशिक्षण, व्यावहारिक अनुभव और उद्योग की जरूरतों के अनुरूप पाठ्यक्रम के साथ, यह बूटकैंप न केवल आपको आवश्यक कौशल से लैस करता है बल्कि आपको एक आकर्षक और मांग वाले करियर पथ में सबसे आगे रखता है। आज ही नामांकन करें और अपनी आकांक्षाओं को वास्तविकता में बदलें!
आबिद अली अवनी (@1अबिदलियावान) एक प्रमाणित डेटा वैज्ञानिक पेशेवर है जो मशीन लर्निंग मॉडल बनाना पसंद करता है। वर्तमान में, वह सामग्री निर्माण और मशीन लर्निंग और डेटा विज्ञान प्रौद्योगिकियों पर तकनीकी ब्लॉग लिखने पर ध्यान केंद्रित कर रहा है। आबिद के पास प्रौद्योगिकी प्रबंधन में मास्टर डिग्री और दूरसंचार इंजीनियरिंग में स्नातक की डिग्री है। उनका दृष्टिकोण मानसिक बीमारी से जूझ रहे छात्रों के लिए ग्राफ न्यूरल नेटवर्क का उपयोग करके एआई उत्पाद बनाना है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 000
- 1
- 15% तक
- 17
- 2024
- a
- योग्य
- About
- सक्रिय रूप से
- इसके अतिरिक्त
- को संबोधित
- उन्नत
- आगे बढ़ने
- बाद
- AI
- सब
- साथ में
- भी
- अद्भुत
- an
- विश्लेषण
- विश्लेषणात्मक
- विश्लेषिकी
- और
- और बुनियादी ढांचे
- अपाचे
- अपाचे स्पार्क
- एपीआई
- एपीआई
- अनुप्रयोगों
- आर्किटेक्ट
- हैं
- कला
- AS
- At
- उपलब्ध
- मूल बातें
- BE
- बन
- बनने
- शुरुआती
- लाभदायक
- BEST
- सर्वोत्तम प्रथाओं
- bigquery
- मिश्रण
- ब्लॉग
- के छात्रों
- निर्माण
- इमारत
- लेकिन
- by
- कैरियर
- कॅरिअर
- प्रमाणित
- बादल
- बादल का भंडारण
- गुच्छन
- कोड
- कोडन
- जत्था
- समुदाय
- कंपनियों
- पूरा
- व्यापक
- अवधारणाओं
- निष्कर्ष निकाला है
- विन्यास
- मिला हुआ
- जुडिये
- माना
- मिलकर
- निर्माण
- उपभोक्ताओं
- शामिल हैं
- सामग्री
- सामग्री निर्माण
- पाठ्यक्रम
- पाठ्यक्रमों
- शामिल किया गया
- बनाना
- बनाना
- निर्माण
- महत्वपूर्ण
- वर्तमान में
- पाठ्यचर्या
- डैशबोर्ड
- तिथि
- डेटा इंजीनियर
- डेटा लेक
- डेटा विज्ञान
- आँकड़े वाला वैज्ञानिक
- डेटा भंडारण
- डाटा गोदाम
- तारीख
- डिग्री
- तैनाती
- बनाया गया
- डिज़ाइन बनाना
- विस्तृत
- मुश्किल
- डाक में काम करनेवाला मज़दूर
- से प्रत्येक
- प्रभावी रूप से
- कुशल
- भी
- सशक्त
- सक्षम
- समाप्त
- शुरू से अंत तक
- इंजीनियर
- अभियांत्रिकी
- इंजीनियर्स
- नामांकन के
- सुनिश्चित
- वातावरण
- वातावरण
- आवश्यक
- ईथर (ईटीएच)
- सब कुछ
- उदाहरण
- उत्तेजक
- मौजूदा
- अनुभव
- विशेषज्ञों
- अन्वेषण
- तलाश
- फैली
- Feature
- विशेषताएं
- की विशेषता
- कुछ
- खेत
- फ़ाइलें
- अंत में
- प्रथम
- फोकस
- केंद्रित
- ध्यान केंद्रित
- पीछा किया
- के लिए
- सबसे आगे
- मूलभूत
- ढांचा
- मुक्त
- से
- समारोह
- आधार
- अन्तर
- जीसीपी
- दी
- गूगल
- Google मेघ
- ग्राफ
- ग्राफ तंत्रिका नेटवर्क
- निर्देशित
- हाथों पर
- है
- he
- पर प्रकाश डाला
- उसके
- रखती है
- समग्र
- होमवर्क
- कांटों
- तथापि
- HTTPS
- संकर
- हाइपरपरमेटर ट्यूनिंग
- बीमारी
- लागू करने के
- in
- में गहराई
- शामिल
- सहित
- वृद्धिशील
- उद्योग
- इंफ्रास्ट्रक्चर
- अभिनव
- स्थापना
- निर्देश
- घालमेल
- एकीकरण
- में
- शुरू की
- द्वारा प्रस्तुत
- शुरू करने
- परिचय
- परिचय
- शामिल
- IT
- आईटी इस
- जनवरी
- जुड़ती
- काफ्का
- केडनगेट्स
- कुंजी
- झील
- प्रमुख
- जानें
- सीखा
- शिक्षार्थियों
- सीख रहा हूँ
- पसंद
- लाइन
- लिंक्डइन
- लिनक्स
- लोड हो रहा है
- स्थानीय
- देख
- प्यार करता है
- निम्न
- लाभप्रद
- मशीन
- यंत्र अधिगम
- MacOS
- प्रबंधन
- प्रबंध
- अनिवार्य
- बहुत
- मास्टर
- माहिर
- सामग्री
- मानसिक
- मानसिक बीमारी
- ML
- आदर्श
- मोडलिंग
- मॉडल
- आधुनिक
- मॉड्यूल
- मॉड्यूल
- अधिक
- विभिन्न
- आवश्यक
- आवश्यकता
- जरूरत
- की जरूरत है
- नेटवर्क
- शुद्ध कार्यशील
- तंत्रिका
- तंत्रिका नेटवर्क
- उद्देश्य
- of
- की पेशकश
- ऑफर
- on
- केवल
- खुला स्रोत
- संचालन
- or
- आर्केस्ट्रा
- अन्य
- हमारी
- पामर
- विशेष रूप से
- पथ
- वेतन
- सहकर्मी
- प्रदर्शन
- पाइपलाइन
- प्लेटफार्म
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- प्ले
- पदों
- PostgreSQL
- व्यावहारिक
- व्यावहारिक अनुप्रयोगों
- अभ्यास
- प्रथाओं
- तैयारी
- वर्तमान
- प्रक्रिया
- संसाधित
- प्रसंस्करण
- प्रोड्यूसर्स
- एस्ट्रो मॉल
- पेशेवर
- पेशेवरों
- प्रगति
- परियोजना
- परियोजनाओं
- प्रदान करता है
- प्रदान कर
- अजगर
- प्रशन
- उठाता
- पढ़ना
- असली दुनिया
- वास्तविकता
- उपयुक्त संसाधन चुनें
- भूमिका
- भूमिकाओं
- दौड़ना
- s
- वेतन
- स्काला
- विज्ञान
- वैज्ञानिक
- वैज्ञानिकों
- मांग
- का चयन
- वरिष्ठ
- की स्थापना
- व्यवस्था
- कौशल
- ढीला
- समाधान
- कुछ
- कभी कभी
- परिष्कृत
- स्पार्क
- विशेष
- एसक्यूएल
- प्रारंभ
- शुरुआत में
- भंडारण
- धारा
- स्ट्रीमिंग
- नदियों
- संरचित
- संघर्ष
- छात्र
- स्टूडियो
- पर्याप्त
- ऐसा
- समर्थन
- स्विच
- सिस्टम
- अनुरूप
- प्रतिभा
- कार्य
- तकनीक
- तकनीकी
- तकनीक
- टेक्नोलॉजीज
- टेक्नोलॉजी
- दूरसंचार
- terraform
- परीक्षण
- कि
- RSI
- मूल बातें
- फिर
- इसका
- यहाँ
- सेवा मेरे
- आज
- साधन
- उपकरण
- विषय
- प्रशिक्षण
- स्थानांतरित कर रहा है
- बदालना
- परिवर्तन
- परिवर्तनकारी
- तब्दील
- बदलने
- ट्यूटोरियल
- दो
- समझ
- यूएसडी
- उपयोग
- उपयोगकर्ताओं
- का उपयोग
- Ve
- बहुत
- के माध्यम से
- वीडियो
- दृष्टि
- नेत्रहीन
- vs
- गोदाम
- भण्डारण
- we
- क्या
- कौन कौन से
- कौन
- मर्जी
- खिड़कियां
- साथ में
- वर्कफ़्लो
- workflows
- कार्यशाला
- कार्यशालाओं
- लिख रहे हैं
- इसलिए आप
- आपका
- जेफिरनेट