संपादक द्वारा छवि
चाबी छीन लेना
- टी-टेस्ट एक सांख्यिकीय परीक्षण है जिसका उपयोग यह निर्धारित करने के लिए किया जा सकता है कि डेटा के दो स्वतंत्र नमूनों के साधनों के बीच कोई महत्वपूर्ण अंतर है या नहीं।
- हम बताते हैं कि आईरिस डेटासेट और पायथन की स्किपी लाइब्रेरी का उपयोग करके टी-टेस्ट कैसे लागू किया जा सकता है।
टी-टेस्ट एक सांख्यिकीय परीक्षण है जिसका उपयोग यह निर्धारित करने के लिए किया जा सकता है कि डेटा के दो स्वतंत्र नमूनों के साधनों के बीच कोई महत्वपूर्ण अंतर है या नहीं। इस ट्यूटोरियल में, हम टी-टेस्ट के सबसे बुनियादी संस्करण का वर्णन करते हैं, जिसके लिए हम मानेंगे कि दो नमूनों में समान प्रसरण हैं। टी-टेस्ट के अन्य उन्नत संस्करणों में वेल्च का टी-टेस्ट शामिल है, जो टी-टेस्ट का एक अनुकूलन है, और अधिक विश्वसनीय है जब दो नमूनों में असमान प्रसरण और संभवतः असमान नमूना आकार होते हैं।
टी आँकड़ा या टी-मान की गणना निम्नानुसार की जाती है:
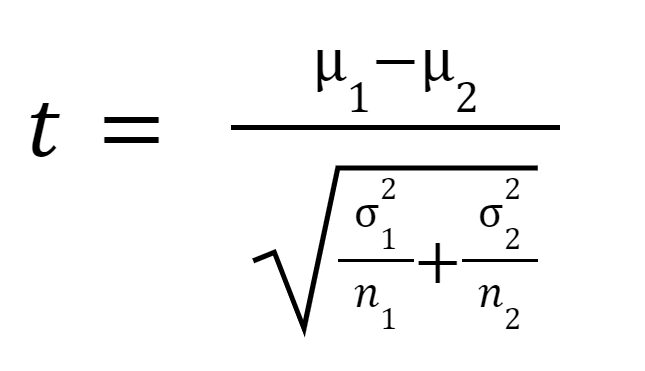
जहां
नमूना 1 का मतलब है,
नमूना 2 का मतलब है,
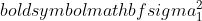 नमूना 1 का विचरण है,
नमूना 1 का विचरण है, 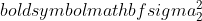 नमूना 2 का विचरण है,
नमूना 2 का विचरण है, 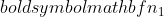 नमूना 1 का नमूना आकार है, और
नमूना 1 का नमूना आकार है, और 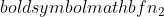 नमूना 2 का नमूना आकार है।
नमूना 2 का नमूना आकार है।
टी-टेस्ट के उपयोग को स्पष्ट करने के लिए, हम आइरिस डेटासेट का उपयोग करके एक सरल उदाहरण दिखाएंगे। मान लीजिए कि हम दो स्वतंत्र नमूनों का निरीक्षण करते हैं, उदाहरण के लिए फूल बाह्यदल की लंबाई, और हम विचार कर रहे हैं कि क्या दो नमूने एक ही आबादी से लिए गए थे (उदाहरण के लिए फूल की एक ही प्रजाति या समान बाह्य विशेषताओं वाली दो प्रजातियां) या दो अलग-अलग आबादी।
टी-परीक्षण दो नमूनों के अंकगणितीय माध्यों के बीच अंतर की मात्रा निर्धारित करता है। पी-मान शून्य परिकल्पना (कि नमूने समान जनसंख्या साधनों के साथ आबादी से लिए गए हैं) को सच मानते हुए, देखे गए परिणामों को प्राप्त करने की संभावना को निर्धारित करता है। एक चुने हुए थ्रेशोल्ड (जैसे 5% या 0.05) से बड़ा पी-वैल्यू इंगित करता है कि हमारा अवलोकन संयोग से होने की संभावना नहीं है। इसलिए, हम समान जनसंख्या साधनों की शून्य परिकल्पना को स्वीकार करते हैं। यदि पी-वैल्यू हमारी दहलीज से छोटा है, तो हमारे पास बराबर जनसंख्या के शून्य परिकल्पना के खिलाफ सबूत हैं।
टी-टेस्ट इनपुट
टी-टेस्ट करने के लिए आवश्यक इनपुट या पैरामीटर हैं:
- दो सरणियाँ a और b नमूना 1 और नमूना 2 के लिए डेटा युक्त
टी-टेस्ट आउटपुट
टी-टेस्ट निम्नलिखित देता है:
- परिकलित टी-सांख्यिकी
- पी-मूल्य
आवश्यक पुस्तकालय आयात करें
import numpy as np
from scipy import stats import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
आईरिस डेटासेट लोड करें
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
नमूना माध्य और नमूना प्रसरण की गणना करें
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
टी-टेस्ट लागू करें
stats.ttest_ind(a_1, b_1, equal_var = False)
उत्पादन
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
उत्पादन
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
उत्पादन
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)टिप्पणियों
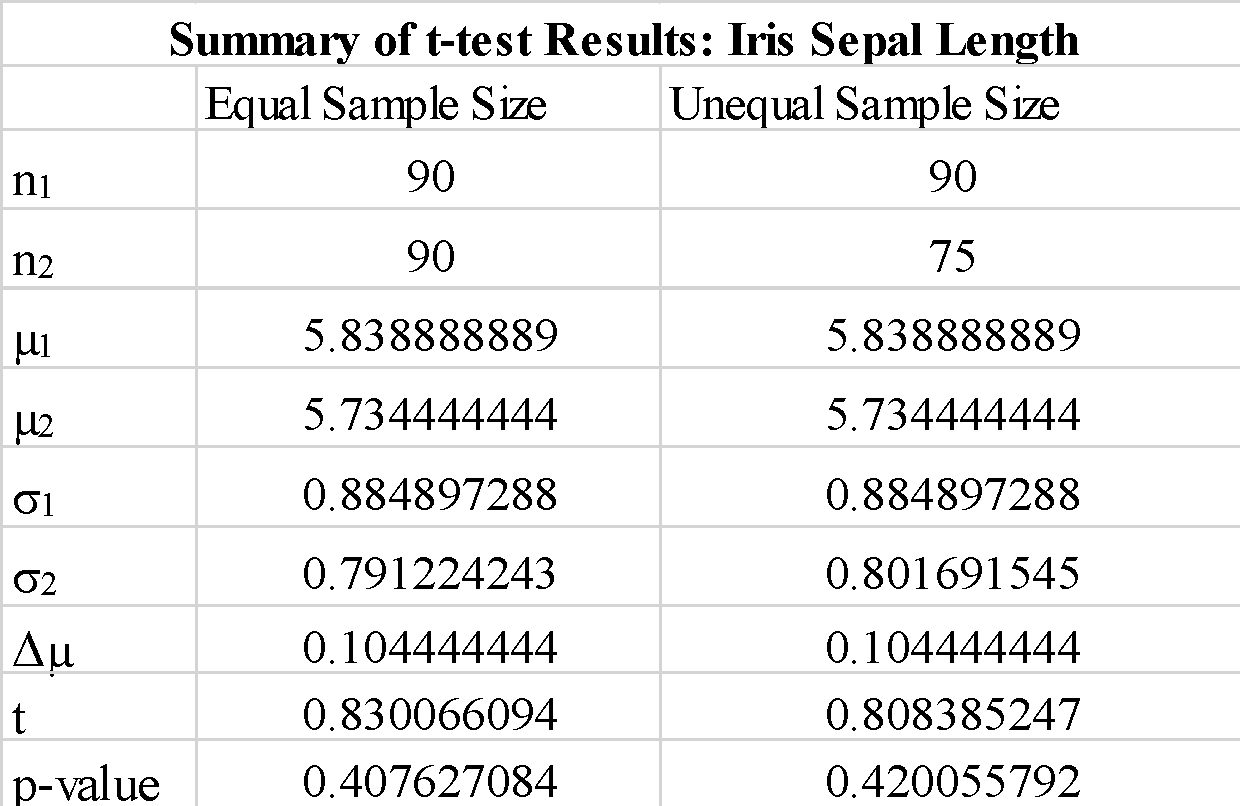
हम देखते हैं कि "समान-वार" पैरामीटर के लिए "सत्य" या "गलत" का उपयोग करने से टी-टेस्ट के परिणाम बहुत अधिक नहीं बदलते हैं। हम यह भी देखते हैं कि नमूना सरणियों के क्रम को बदलने से a_1 और b_1 एक नकारात्मक t-परीक्षण मान प्राप्त होता है, लेकिन अपेक्षा के अनुसार t-परीक्षण मान के परिमाण में परिवर्तन नहीं होता है। चूंकि परिकलित पी-मान 0.05 की दहलीज मान से काफी बड़ा है, इसलिए हम शून्य परिकल्पना को अस्वीकार कर सकते हैं कि नमूना 1 और नमूना 2 के साधनों के बीच का अंतर महत्वपूर्ण है। इससे पता चलता है कि नमूना 1 और नमूना 2 के लिए बाह्यदल की लंबाई समान जनसंख्या डेटा से ली गई थी।
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
नमूना माध्य और नमूना प्रसरण की गणना करें
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
टी-टेस्ट लागू करें
stats.ttest_ind(a_1, b_1, equal_var = False)
उत्पादन
stats.ttest_ind(a_1, b_1, equal_var = False)टिप्पणियों
हम देखते हैं कि असमान आकार वाले नमूनों का उपयोग करने से टी-सांख्यिकी और पी-मान महत्वपूर्ण रूप से नहीं बदलते हैं।
सारांश में, हमने दिखाया है कि कैसे एक साधारण टी-टेस्ट को पायथन में स्किपी लाइब्रेरी का उपयोग करके लागू किया जा सकता है।
बेंजामिन ओ टायो एक भौतिक विज्ञानी, डेटा विज्ञान शिक्षक और लेखक होने के साथ-साथ DataScienceHub के मालिक भी हैं। इससे पहले, बेंजामिन सेंट्रल ओक्लाहोमा के यू., ग्रैंड कैन्यन यू. और पिट्सबर्ग स्टेट यू में इंजीनियरिंग और भौतिकी पढ़ा रहे थे।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/2023/01/performing-ttest-python.html?utm_source=rss&utm_medium=rss&utm_campaign=performing-a-t-test-in-python
- 1
- 7
- 9
- a
- स्वीकार करें
- उन्नत
- के खिलाफ
- और
- लागू
- बुनियादी
- बेंजामिन
- के बीच
- परिकलित
- केंद्रीय
- संयोग
- परिवर्तन
- विशेषताएँ
- करने के लिए चुना
- पर विचार
- सका
- तिथि
- डेटा विज्ञान
- डेटासेट
- निर्धारित करना
- अंतर
- विभिन्न
- तैयार
- अभियांत्रिकी
- सबूत
- उदाहरण
- अपेक्षित
- फूल
- निम्नलिखित
- इस प्रकार है
- से
- कैसे
- HTTPS
- कार्यान्वित
- आयात
- in
- शामिल
- स्वतंत्र
- इंगित करता है
- केडनगेट्स
- बड़ा
- पुस्तकालय
- लिंक्डइन
- matplotlib
- साधन
- अधिक
- अधिकांश
- आवश्यक
- नकारात्मक
- numpy
- निरीक्षण
- प्राप्त करने के
- हुआ
- ओक्लाहोमा
- आदेश
- अन्य
- मालिक
- प्राचल
- पैरामीटर
- प्रदर्शन
- भौतिक विज्ञान
- पिट्सबर्ग
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- आबादी
- आबादी
- पहले से
- संभावना
- अजगर
- विश्वसनीय
- परिणाम
- रिटर्न
- वही
- विज्ञान
- दिखाना
- दिखाया
- दिखाता है
- महत्वपूर्ण
- काफी
- समान
- सरल
- के बाद से
- आकार
- आकार
- छोटे
- So
- राज्य
- सांख्यिकीय
- आँकड़े
- सारांश
- शिक्षण
- परीक्षण
- RSI
- इसलिये
- द्वार
- सेवा मेरे
- <strong>उद्देश्य</strong>
- ट्यूटोरियल
- उपयोग
- मूल्य
- संस्करण
- या
- कौन कौन से
- मर्जी
- लेखक
- पैदावार
- जेफिरनेट





