By David Wendt ainsi que les Grégory Kimball
Le traitement efficace des données de chaîne est vital pour de nombreuses applications de science des données. Pour extraire des informations précieuses à partir de données de chaîne, RAPIDS libcudf fournit des outils puissants pour accélérer les transformations de données de chaîne. libcudf est une bibliothèque C++ GPU DataFrame utilisée pour charger, joindre, agréger et filtrer des données.
En science des données, les données de chaîne représentent la parole, le texte, les séquences génétiques, la journalisation et de nombreux autres types d'informations. Lorsque vous travaillez avec des données de chaîne pour l'apprentissage automatique et l'ingénierie des fonctionnalités, les données doivent souvent être normalisées et transformées avant de pouvoir être appliquées à des cas d'utilisation spécifiques. libcudf fournit à la fois des API à usage général ainsi que des utilitaires côté périphérique pour permettre une large gamme d'opérations de chaînes personnalisées.
Cet article montre comment transformer habilement des colonnes de chaînes avec l'API à usage général libcudf. Vous acquerrez de nouvelles connaissances sur la façon de débloquer des performances optimales à l'aide de noyaux personnalisés et d'utilitaires côté périphérique libcudf. Cet article vous explique également comment gérer au mieux la mémoire GPU et construire efficacement des colonnes libcudf pour accélérer vos transformations de chaînes.
libcudf stocke les données de chaîne dans la mémoire de l'appareil en utilisant Format flèche, qui représente les colonnes de chaînes sous la forme de deux colonnes enfants : chars and offsets (Figure 1).
Les chars La colonne contient les données de chaîne sous forme d'octets de caractères encodés en UTF-8 qui sont stockés de manière contiguë dans la mémoire.
Les offsets colonne contient une séquence croissante d'entiers qui sont des positions d'octets identifiant le début de chaque chaîne individuelle dans le tableau de données chars. L'élément de décalage final est le nombre total d'octets dans la colonne chars. Cela signifie la taille d'une chaîne individuelle à la ligne i est défini comme (offsets[i+1]-offsets[i]).
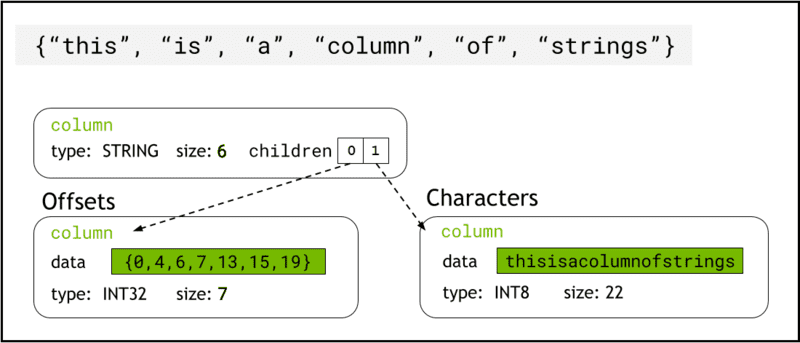 Figure 1. Schéma montrant comment le format Arrow représente les colonnes de chaînes avec
Figure 1. Schéma montrant comment le format Arrow représente les colonnes de chaînes avec chars ainsi que les offsets colonnes enfants
Pour illustrer un exemple de transformation de chaîne, considérons une fonction qui reçoit deux colonnes de chaînes d'entrée et produit une colonne de chaînes de sortie expurgées.
Les données d'entrée ont la forme suivante : une colonne « noms » contenant les noms et prénoms séparés par un espace et une colonne « visibilités » contenant le statut « public » ou « privé ».
Nous proposons la fonction « expurger » qui opère sur les données d'entrée pour produire des données de sortie composées de la première initiale du nom de famille suivie d'un espace et du prénom entier. Cependant, si la colonne de visibilité correspondante est "privée", la chaîne de sortie doit être entièrement expurgée en "X X".
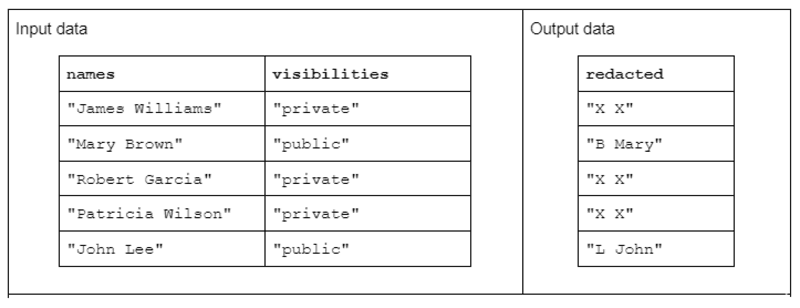 Tableau 1. Exemple d'une transformation de chaîne « expurgée » qui reçoit des noms et des colonnes de chaînes de visibilité en entrée et des données partiellement ou entièrement expurgées en sortie
Tableau 1. Exemple d'une transformation de chaîne « expurgée » qui reçoit des noms et des colonnes de chaînes de visibilité en entrée et des données partiellement ou entièrement expurgées en sortie
Tout d'abord, la transformation de chaîne peut être accomplie en utilisant le API de chaînes libcudf. L'API à usage général est un excellent point de départ et une bonne référence pour comparer les performances.
Les fonctions de l'API fonctionnent sur une colonne entière de chaînes, lançant au moins un noyau par fonction et affectant un thread par chaîne. Chaque thread gère une seule ligne de données en parallèle sur le GPU et génère une seule ligne dans le cadre d'une nouvelle colonne de sortie.
Pour terminer l'exemple de fonction de rédaction à l'aide de l'API à usage général, procédez comme suit :
- Convertissez la colonne de chaînes "visibilités" en une colonne booléenne à l'aide de
contains - Créez une nouvelle colonne de chaînes à partir de la colonne des noms en copiant "XX" chaque fois que l'entrée de ligne correspondante dans la colonne booléenne est "faux"
- Divisez la colonne "caviardée" en colonnes de prénom et de nom de famille
- Tranchez le premier caractère des noms de famille comme les initiales du nom de famille
- Construisez la colonne de sortie en concaténant la colonne des dernières initiales et la colonne des prénoms avec un séparateur espace ("").
// convert the visibility label into a boolean
auto const visible = cudf::string_scalar(std::string("public"));
auto const allowed = cudf::strings::contains(visibilities, visible); // redact names auto const redaction = cudf::string_scalar(std::string("X X"));
auto const redacted = cudf::copy_if_else(names, redaction, allowed->view()); // split the first name and last initial into two columns
auto const sv = cudf::strings_column_view(redacted->view())
auto const first_last = cudf::strings::split(sv);
auto const first = first_last->view().column(0);
auto const last = first_last->view().column(1);
auto const last_initial = cudf::strings::slice_strings(last, 0, 1); // assemble a result column
auto const tv = cudf::table_view({last_initial->view(), first});
auto result = cudf::strings::concatenate(tv, std::string(" "));
Cette approche prend environ 3.5 ms sur un A6000 avec 600 XNUMX lignes de données. Cet exemple utilise contains, copy_if_else, split, slice_strings ainsi que les concatenate pour accomplir une transformation de chaîne personnalisée. Une analyse de profil avec Systèmes de vision montre que la split fonction prend le plus de temps, suivi de slice_strings ainsi que les concatenate.
La figure 2 montre les données de profilage de Nsight Systems de l'exemple expurgé, montrant le traitement de chaînes de bout en bout jusqu'à environ 600 millions d'éléments par seconde. Les régions correspondent aux plages NVTX associées à chaque fonction. Les plages bleu clair correspondent aux périodes d'exécution des noyaux CUDA.
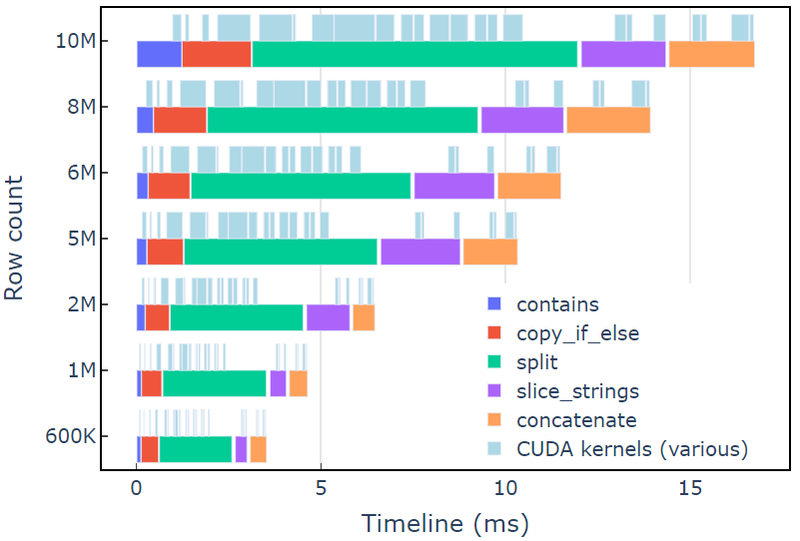 Figure 2. Données de profilage de Nsight Systems de l'exemple de rédaction
Figure 2. Données de profilage de Nsight Systems de l'exemple de rédaction
L'API libcudf strings est une boîte à outils rapide et efficace pour transformer les chaînes, mais parfois les fonctions critiques pour les performances doivent s'exécuter encore plus rapidement. Une source clé de travail supplémentaire dans l'API de chaînes libcudf est la création d'au moins une nouvelle colonne de chaînes dans la mémoire globale de l'appareil pour chaque appel d'API, ouvrant la possibilité de combiner plusieurs appels d'API dans un noyau personnalisé.
Limitations de performances dans les appels malloc du noyau
Tout d'abord, nous allons créer un noyau personnalisé pour implémenter la transformation d'exemple de rédaction. Lors de la conception de ce noyau, nous devons garder à l'esprit que les colonnes de chaînes libcudf sont immuables.
Les colonnes de chaînes ne peuvent pas être modifiées sur place car les octets de caractères sont stockés de manière contiguë et toute modification de la longueur d'une chaîne invaliderait les données de décalage. Par conséquent, la redact_kernel le noyau personnalisé génère une nouvelle colonne de chaînes en utilisant une fabrique de colonnes libcudf pour créer les deux offsets ainsi que les chars colonnes enfants.
Dans cette première approche, la chaîne de sortie pour chaque ligne est créée dans mémoire dynamique de l'appareil en utilisant un appel malloc à l'intérieur du noyau. La sortie personnalisée du noyau est un vecteur de pointeurs de périphérique vers chaque sortie de ligne, et ce vecteur sert d'entrée à une fabrique de colonnes de chaînes.
Le noyau personnalisé accepte un cudf::column_device_view pour accéder aux données de la colonne de chaînes et utilise le element méthode pour retourner un cudf::string_view représentant les données de chaîne à l'index de ligne spécifié. La sortie du noyau est un vecteur de type cudf::string_view qui contient des pointeurs vers la mémoire de l'appareil contenant la chaîne de sortie et la taille de cette chaîne en octets.
Les cudf::string_view est similaire à la classe std::string_view mais est implémentée spécifiquement pour libcudf et encapsule une longueur fixe de données de caractères dans la mémoire de l'appareil encodée en UTF-8. Il a plusieurs des mêmes caractéristiques (find ainsi que les substr fonctions, par exemple) et limitations (pas de terminateur nul) comme le std homologue. UN cudf::string_view représente une séquence de caractères stockée dans la mémoire de l'appareil et nous pouvons donc l'utiliser ici pour enregistrer la mémoire malloc'd pour un vecteur de sortie.
Noyau malloc
// note the column_device_view inputs to the kernel __global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, cudf::string_view* d_output)
{ // get index for this thread auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; char* output_ptr = static_cast(malloc(output_size)); // build output string d_output[index] = cudf::string_view{output_ptr, output_size}; memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
} __global__ void free_kernel(cudf::string_view redaction, cudf::string_view* d_output, int count)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= count) return; auto ptr = const_cast(d_output[index].data()); if (ptr != redaction.data()) free(ptr); // free everything that does match the redaction string
}
Cela peut sembler une approche raisonnable, jusqu'à ce que les performances du noyau soient mesurées. Cette approche prend environ 108 ms sur un A6000 avec 600 30 lignes de données, soit plus de XNUMX fois plus lentement que la solution fournie ci-dessus à l'aide de l'API de chaînes libcudf.
redact_kernel 60.3ms
free_kernel 45.5ms
make_strings_column 0.5ms
Le principal goulot d'étranglement est le malloc/free appels à l'intérieur des deux noyaux ici. La mémoire de l'appareil dynamique CUDA nécessite malloc/free appels dans un noyau à synchroniser, provoquant la dégénérescence de l'exécution parallèle en exécution séquentielle.
Pré-allocation de la mémoire de travail pour éliminer les goulots d'étranglement
Éliminer le malloc/free goulot d'étranglement en remplaçant le malloc/free appels dans le noyau avec de la mémoire de travail pré-allouée avant de lancer le noyau.
Pour l'exemple de rédaction, la taille de sortie de chaque chaîne de cet exemple ne doit pas être supérieure à la chaîne d'entrée elle-même, car la logique ne supprime que des caractères. Par conséquent, un seul tampon de mémoire de périphérique peut être utilisé avec la même taille que le tampon d'entrée. Utilisez les décalages d'entrée pour localiser chaque position de ligne.
L'accès aux décalages de la colonne de chaînes implique d'envelopper le cudf::column_view avec une cudf::strings_column_view et en appelant son offsets_begin méthode. La taille du chars la colonne enfant est également accessible à l'aide de la chars_size méthode. Puis un rmm::device_uvector est pré-alloué avant d'appeler le noyau pour stocker les données de sortie des caractères.
auto const scv = cudf::strings_column_view(names);
auto const offsets = scv.offsets_begin();
auto working_memory = rmm::device_uvector(scv.chars_size(), stream);Noyau pré-alloué
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, char* working_memory, cudf::offset_type const* d_offsets, cudf::string_view* d_output)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // resolve output string location char* output_ptr = working_memory + d_offsets[index]; d_output[index] = cudf::string_view{output_ptr, output_size}; // build output string into output_ptr memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
}
Le noyau génère un vecteur de cudf::string_view objets qui sont passés au cudf::make_strings_column fonction d'usine. Le deuxième paramètre de cette fonction est utilisé pour identifier les entrées nulles dans la colonne de sortie. Les exemples de cet article n'ont pas d'entrées nulles, donc un espace réservé nullptr cudf::string_view{nullptr,0} est utilisé.
auto str_ptrs = rmm::device_uvector(names.size(), stream); redact_kernel>>(*d_names, *d_visibilities, d_redaction.value(), working_memory.data(), offsets, str_ptrs.data()); auto result = cudf::make_strings_column(str_ptrs, cudf::string_view{nullptr,0}, stream);
Cette approche prend environ 1.1 ms sur un A6000 avec 600 2 lignes de données et bat donc la ligne de base de plus de XNUMX fois. La répartition approximative est indiquée ci-dessous :
redact_kernel 66us make_strings_column 400us
Le temps restant est consacré à cudaMalloc, cudaFree, cudaMemcpy, ce qui est typique des frais généraux liés à la gestion des instances temporaires de rmm::device_uvector. Cette méthode fonctionne bien s'il est garanti que toutes les chaînes de sortie ont la même taille ou une taille inférieure à celle des chaînes d'entrée.
Dans l'ensemble, le passage à une allocation de mémoire de travail en bloc avec RAPIDS RMM est une amélioration significative et une bonne solution pour une fonction de chaînes personnalisées.
Optimisation de la création de colonnes pour des temps de calcul plus rapides
Existe-t-il un moyen d'améliorer encore cela? Le goulot d'étranglement est maintenant le cudf::make_strings_column fonction d'usine qui construit les deux composants de colonne de chaînes, offsets ainsi que les chars, à partir du vecteur de cudf::string_view objets.
Dans libcudf, de nombreuses fonctions d'usine sont incluses pour la construction de colonnes de chaînes. La fonction factory utilisée dans les exemples précédents prend une cudf::device_span of cudf::string_view objets, puis construit la colonne en effectuant une gather sur les données de caractères sous-jacentes pour créer les décalages et les colonnes enfants de caractères. UN rmm::device_uvector est automatiquement convertible en un cudf::device_span sans copier aucune donnée.
Cependant, si le vecteur de caractères et le vecteur de décalages sont construits directement, une fonction de fabrique différente peut être utilisée, qui crée simplement la colonne de chaînes sans nécessiter de collecte pour copier les données.
Les sizes_kernel effectue une première passe sur les données d'entrée pour calculer la taille de sortie exacte de chaque ligne de sortie :
Noyau optimisé : partie 1
__global__ void sizes_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type* d_sizes)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); cudf::size_type result = redaction.size_bytes(); // init to redaction size if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); result = first.size_bytes() + last_initial.size_bytes() + 1; } d_sizes[index] = result;
}
Les tailles de sortie sont ensuite converties en décalages en effectuant une analyse sur place exclusive_scan. Notez que le offsets vecteur a été créé avec names.size()+1 éléments. La dernière entrée sera le nombre total d'octets (toutes les tailles additionnées) tandis que la première entrée sera 0. Ceux-ci sont tous deux gérés par le exclusive_scan appel. La taille du chars colonne est récupérée à partir de la dernière entrée de la offsets colonne pour construire le vecteur chars.
// create offsets vector
auto offsets = rmm::device_uvector(names.size() + 1, stream); // compute output sizes
sizes_kernel>>( *d_names, *d_visibilities, offsets.data()); thrust::exclusive_scan(rmm::exec_policy(stream), offsets.begin(), offsets.end(), offsets.begin());
Les redact_kernel la logique est toujours sensiblement la même sauf qu'elle accepte la sortie d_offsets vecteur pour résoudre l'emplacement de sortie de chaque ligne :
Noyau optimisé : partie 2
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type const* d_offsets, char* d_chars)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); // resolve output_ptr using the offsets vector char* output_ptr = d_chars + d_offsets[index]; auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // build output string memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { memcpy(output_ptr, redaction.data(), redaction.size_bytes()); }
}
La taille de la sortie d_chars colonne est récupérée à partir de la dernière entrée de la d_offsets colonne pour allouer le vecteur chars. Le noyau se lance avec le vecteur de décalages pré-calculé et renvoie le vecteur de caractères peuplé. Enfin, la fabrique de colonnes de chaînes libcudf crée les colonnes de chaînes de sortie.
Ce cudf::make_strings_column La fonction d'usine construit la colonne de chaînes sans faire de copie des données. Les offsets données et chars les données sont déjà au format correct et attendu et cette usine déplace simplement les données de chaque vecteur et crée la structure de colonne autour de celui-ci. Une fois terminé, le rmm::device_uvectors en offsets ainsi que les chars sont vides, leurs données ayant été déplacées dans la colonne de sortie.
cudf::size_type output_size = offsets.back_element(stream);
auto chars = rmm::device_uvector(output_size, stream); redact_kernel>>( *d_names, *d_visibilities, offsets.data(), chars.data()); // from pre-assembled offsets and character buffers
auto result = cudf::make_strings_column(names.size(), std::move(offsets), std::move(chars));
Cette approche prend environ 300 us (0.3 ms) sur un A6000 avec 600 2 lignes de données et s'améliore de plus de XNUMX fois par rapport à l'approche précédente. Vous remarquerez peut-être que sizes_kernel ainsi que les redact_kernel partagent une grande partie de la même logique : une fois pour mesurer la taille de la sortie, puis à nouveau pour remplir la sortie.
Du point de vue de la qualité du code, il est avantageux de refactoriser la transformation en tant que fonction de périphérique appelée à la fois par les tailles et les noyaux de rédaction. Du point de vue des performances, vous pourriez être surpris de voir le coût de calcul de la transformation payé deux fois.
Les avantages pour la gestion de la mémoire et une création de colonne plus efficace l'emportent souvent sur le coût de calcul de l'exécution de la transformation deux fois.
Le tableau 2 montre le temps de calcul, le nombre de noyaux et les octets traités pour les quatre solutions décrites dans cet article. Le « nombre total de lancements de noyaux » reflète le nombre total de noyaux lancés, y compris les noyaux de calcul et d'assistance. Le « total d'octets traités » est le débit cumulé de lecture et d'écriture de la DRAM et le « octets minimum traités » est une moyenne de 37.9 octets par ligne pour nos entrées et sorties de test. Le cas idéal de "bande passante mémoire limitée" suppose une bande passante de 768 Go/s, le débit de pointe théorique de l'A6000.
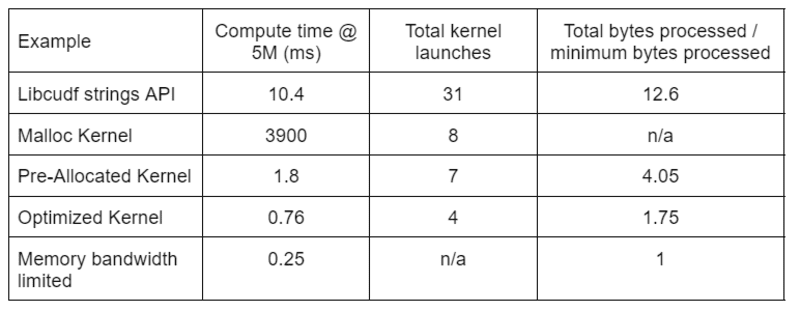 Tableau 2. Temps de calcul, nombre de noyaux et octets traités pour les quatre solutions décrites dans cet article
Tableau 2. Temps de calcul, nombre de noyaux et octets traités pour les quatre solutions décrites dans cet article
"Optimized Kernel" fournit le débit le plus élevé en raison du nombre réduit de lancements de noyau et du nombre total d'octets traités. Avec des noyaux personnalisés efficaces, le nombre total de lancements de noyau passe de 31 à 4 et le nombre total d'octets traités de 12.6x à 1.75x de l'entrée plus la taille de sortie.
En conséquence, le noyau personnalisé atteint un débit > 10 fois plus élevé que l'API de chaînes à usage général pour la transformation de rédaction.
La ressource mémoire du pool dans Gestionnaire de mémoire RAPIDS (RMM) est un autre outil que vous pouvez utiliser pour augmenter les performances. Les exemples ci-dessus utilisent la "ressource de mémoire CUDA" par défaut pour allouer et libérer la mémoire globale de l'appareil. Cependant, le temps nécessaire pour allouer la mémoire de travail ajoute une latence importante entre les étapes des transformations de chaîne. La « ressource de mémoire de pool » dans RMM réduit la latence en allouant un grand pool de mémoire à l'avance et en attribuant des sous-allocations selon les besoins pendant le traitement.
Avec la ressource de mémoire CUDA, "Optimized Kernel" affiche une accélération de 10x à 15x qui commence à chuter à des nombres de lignes plus élevés en raison de l'augmentation de la taille d'allocation (Figure 3). L'utilisation de la ressource de mémoire de pool atténue cet effet et maintient des accélérations de 15x à 25x par rapport à l'approche de l'API de chaînes libcudf.
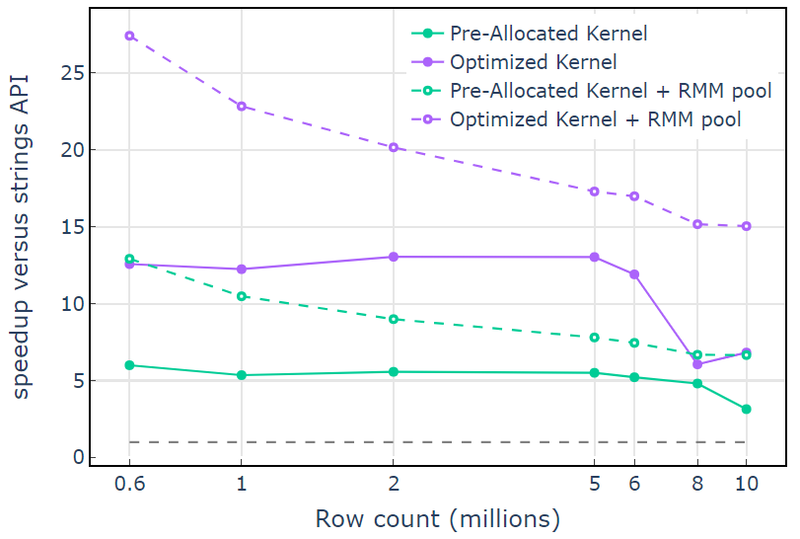 Figure 3. Accélération à partir des noyaux personnalisés « Noyau pré-alloué » et « Noyau optimisé » avec la ressource de mémoire CUDA par défaut (solide) et la ressource de mémoire de pool (en pointillés), par rapport à l'API de chaîne libcudf utilisant la ressource de mémoire CUDA par défaut
Figure 3. Accélération à partir des noyaux personnalisés « Noyau pré-alloué » et « Noyau optimisé » avec la ressource de mémoire CUDA par défaut (solide) et la ressource de mémoire de pool (en pointillés), par rapport à l'API de chaîne libcudf utilisant la ressource de mémoire CUDA par défaut
Avec la ressource de mémoire de pool, un débit de mémoire de bout en bout approchant la limite théorique pour un algorithme à deux passes est démontré. Le « noyau optimisé » atteint un débit de 320 à 340 Go/s, mesuré à l'aide de la taille des entrées plus la taille des sorties et le temps de calcul (Figure 4).
L'approche en deux passes mesure d'abord les tailles des éléments de sortie, alloue de la mémoire, puis définit la mémoire avec les sorties. Étant donné un algorithme de traitement en deux passes, l'implémentation dans "Optimized Kernel" fonctionne près de la limite de bande passante mémoire. Le "débit de mémoire de bout en bout" est défini comme la taille d'entrée plus la taille de sortie en Go divisée par le temps de calcul. *Bande passante mémoire RTX A6000 (768 Go/s).
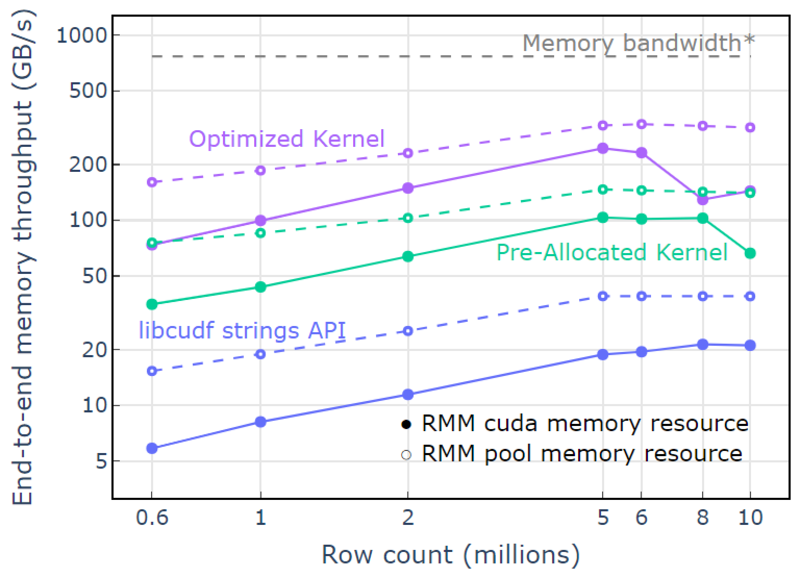 Figure 4. Débit mémoire pour « Optimized Kernel », « Pre-Allocated Kernel » et « libcudf strings API » en fonction du nombre de lignes d'entrée/sortie
Figure 4. Débit mémoire pour « Optimized Kernel », « Pre-Allocated Kernel » et « libcudf strings API » en fonction du nombre de lignes d'entrée/sortie
Cet article présente deux approches pour écrire des transformations de données de chaîne efficaces dans libcudf. L'API à usage général libcudf est rapide et simple pour les développeurs, et offre de bonnes performances. libcudf fournit également des utilitaires côté périphérique conçus pour être utilisés avec des noyaux personnalisés, dans cet exemple déverrouillant des performances > 10 fois plus rapides.
Appliquez vos connaissances
Pour démarrer avec RAPIDS cuDF, visitez le rapidsai/cudf Dépôt GitHub. Si vous n'avez pas encore essayé cuDF et libcudf pour vos charges de travail de traitement de chaînes, nous vous encourageons à tester la dernière version. Conteneurs Docker sont fournis pour les versions ainsi que pour les versions nocturnes. Forfaits Conda sont également disponibles pour faciliter les tests et le déploiement. Si vous utilisez déjà cuDF, nous vous encourageons à exécuter le nouvel exemple de transformation de chaînes en visitant rapidsai/cudf/tree/HEAD/cpp/examples/strings sur GitHub.
David Wendt est un ingénieur logiciel système senior chez NVIDIA qui développe du code C++/CUDA pour RAPIDS. David est titulaire d'une maîtrise en génie électrique de l'Université Johns Hopkins.
Grégory Kimball est responsable de l'ingénierie logicielle chez NVIDIA et travaille dans l'équipe RAPIDS. Gregory dirige le développement de libcudf, la bibliothèque CUDA/C++ pour le traitement de données en colonnes qui alimente RAPIDS cuDF. Gregory est titulaire d'un doctorat en physique appliquée du California Institute of Technology.
ORIGINALE. Republié avec permission.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://www.kdnuggets.com/2023/01/mastering-string-transformations-rapids-libcudf.html?utm_source=rss&utm_medium=rss&utm_campaign=mastering-string-transformations-in-rapids-libcudf
- 1
- 7
- 9
- a
- Qui sommes-nous
- au dessus de
- accélérer
- Accepte
- accès
- accédé
- accompli
- à travers
- ajoutée
- Ajoute
- algorithme
- Tous
- alloue
- allocation
- déjà
- montant
- selon une analyse de l’Université de Princeton
- ainsi que les
- Une autre
- Apache
- api
- Apis
- applications
- appliqué
- une approche
- approches
- approchant
- autour
- tableau
- associé
- auto
- automatiquement
- disponibles
- moyen
- Bande passante
- Baseline
- car
- before
- va
- ci-dessous
- avantageux
- avantages.
- LES MEILLEURS
- jusqu'à XNUMX fois
- Bleu
- Breakdown
- tampon
- construire
- Développement
- construit
- construit
- C + +
- Californie
- Appelez-nous
- appelé
- appel
- Appels
- ne peut pas
- maisons
- cas
- causer
- Modifications
- caractère
- caractères
- enfant
- classe
- Fermer
- code
- Colonne
- Colonnes
- combiner
- comparant
- complet
- Complété
- composants électriques
- calcul
- calcul
- Considérer
- Qui consiste
- construire
- contient
- convertir
- converti
- copier
- Correspondant
- Prix
- engendrent
- créée
- crée des
- création
- Customiser
- données
- informatique
- science des données
- David
- Réglage par défaut
- Degré
- offre
- démontré
- déploiement
- un
- conception
- mobiles
- développement
- Développement
- dispositif
- différent
- directement
- discuté
- divisé
- Docker
- Goutte
- pendant
- Dynamic
- chacun
- plus facilement
- effet
- efficace
- efficacement
- ingénierie électrique
- éléments
- éliminé
- permettre
- encourager
- end-to-end
- ingénieur
- ENGINEERING
- Tout
- entrée
- Ether (ETH)
- Pourtant, la
- peut
- exemple
- exemples
- excellent
- Sauf
- exécution
- attendu
- externe
- supplémentaire
- extrait
- PERSONNEL
- RAPIDE
- plus rapide
- Fonctionnalité
- Fonctionnalités:
- Figure
- filtration
- finale
- finalement
- Prénom
- fixé
- suivre
- suivi
- Abonnement
- formulaire
- le format
- Gratuit
- fréquemment
- de
- avant
- d’étiquettes électroniques entièrement
- fonction
- fonctions
- plus
- Gain
- Général
- génère
- obtenez
- GitHub
- donné
- Global
- Bien
- GPU
- garantie
- Poignées
- ayant
- ici
- augmentation
- le plus élevé
- détient
- Comment
- How To
- Cependant
- HTML
- HTTPS
- idéal
- identifier
- immuable
- Mettre en oeuvre
- la mise en oeuvre
- mis en œuvre
- améliorer
- amélioration
- améliore
- in
- inclus
- Y compris
- Améliore
- croissant
- indice
- individuel
- d'information
- initiale
- contribution
- Institut
- interne
- IT
- lui-même
- Johns Hopkins
- Johns Hopkins University
- joindre
- KDnuggetsGenericName
- XNUMX éléments à
- ACTIVITES
- spécialisées
- Libellé
- gros
- plus importantes
- Nom de famille
- Latence
- Nouveautés
- dernière version
- lancé
- lance
- lancement
- Conduit
- apprentissage
- Longueur
- Bibliothèque
- lumière
- LIMIT
- limites
- chargement
- emplacement
- click
- machine learning
- Entrée
- maintient
- a prendre une
- FAIT DU
- Fabrication
- gérer
- gestion
- manager
- les gérer
- de nombreuses
- maître
- mastering
- Match
- veux dire
- mesurer
- les mesures
- Mémoire
- méthode
- pourrait
- million
- l'esprit
- PLUS
- plus efficace
- se déplace
- MS
- plusieurs
- prénom
- noms
- Besoin
- nécessaire
- Nouveauté
- nombre
- Nvidia
- objets
- compenser
- ONE
- ouverture
- fonctionner
- exploite
- Opérations
- Opportunités
- Autre
- payé
- Parallèle
- paramètre
- partie
- passé
- Courant
- performant
- effectuer
- effectue
- périodes
- autorisation
- objectifs
- Physique
- Place
- Platon
- Intelligence des données Platon
- PlatonDonnées
- plus
- Point
- pool
- peuplé
- position
- positions
- Post
- solide
- pouvoirs
- précédent
- traitement
- produire
- profilage
- proposer
- à condition de
- fournit
- public
- but
- qualité
- gamme
- atteint
- Lire
- raisonnable
- reçoit
- record
- Prix Réduit
- réduit
- Refactoriser
- reflète
- régions
- libérer
- de Presse
- restant
- représentation
- représente
- ressource
- résultat
- retourner
- Retours
- RANGÉE
- Courir
- pour le running
- même
- Sciences
- Deuxièmement
- supérieur
- Séquence
- sert
- Sets
- Partager
- devrait
- montré
- Spectacles
- significative
- similaires
- simplement
- depuis
- unique
- Taille
- tailles
- faibles
- So
- Logiciels
- Software Engineer
- génie logiciel
- solide
- sur mesure
- Solutions
- Identifier
- Space
- groupe de neurones
- spécifiquement
- spécifié
- discours
- vitesse
- dépensé
- scission
- Commencer
- j'ai commencé
- Commencez
- Statut
- Étapes
- Encore
- Boutique
- stockée
- STORES
- simple
- courant
- structure
- surpris
- Système
- prend
- équipe
- Technologie
- temporaire
- tester
- Essais
- Les
- leur
- théorique
- donc
- Avec
- débit
- fiable
- à
- ensemble
- outil
- Boîte à outils
- les outils
- Total
- Transformer
- De La Carrosserie
- transformations
- transformé
- transformer
- tv
- types
- débutante
- sous-jacent
- université
- ouvrir
- déverrouillage
- us
- utilisé
- les services publics
- Précieux
- Des informations précieuses
- Versus
- définition
- visible
- vital
- qui
- tout en
- large
- Large gamme
- sera
- dans les
- sans
- activités principales
- de travail
- vos contrats
- pourra
- écrire
- écriture
- X
- Votre
- zéphyrnet










