Image Freepik
L'IA conversationnelle fait référence aux agents virtuels et aux chatbots qui imitent les interactions humaines et peuvent engager des conversations avec des êtres humains. Utiliser l’IA conversationnelle est en passe de devenir un mode de vie – depuis demander à Alexa de «trouver le restaurant le plus proche » à demander à Siri de "créer un rappel, " les assistants virtuels et les chatbots sont souvent utilisés pour répondre aux questions des consommateurs, résoudre les plaintes, effectuer des réservations et bien plus encore.
Développer ces assistants virtuels nécessite des efforts considérables. Cependant, comprendre et relever les principaux défis peut rationaliser le processus de développement. J'ai utilisé mon expérience directe dans la création d'un chatbot mature pour une plateforme de recrutement comme point de référence pour expliquer les principaux défis et les solutions correspondantes.
Pour créer un chatbot IA conversationnel, les développeurs peuvent utiliser des frameworks tels que RASA, Lex d'Amazon ou Dialogflow de Google pour créer des chatbots. La plupart préfèrent RASA lorsqu'ils planifient des modifications personnalisées ou que le bot est au stade de maturité car il s'agit d'un framework open source. D'autres frameworks conviennent également comme point de départ.
Les défis peuvent être classés en trois composants majeurs d'un chatbot.
Compréhension du langage naturel (NLU) est la capacité d'un bot à comprendre le dialogue humain. Il effectue la classification des intentions, l'extraction des entités et la récupération des réponses.
Gestionnaire de dialogues est responsable d'un ensemble d'actions à effectuer en fonction de l'ensemble actuel et précédent d'entrées utilisateur. Il prend l'intention et les entités en entrée (dans le cadre de la conversation précédente) et identifie la réponse suivante.
Génération du langage naturel (NLG) est le processus de génération de phrases écrites ou orales à partir de données données. Il encadre la réponse, qui est ensuite présentée à l'utilisateur.
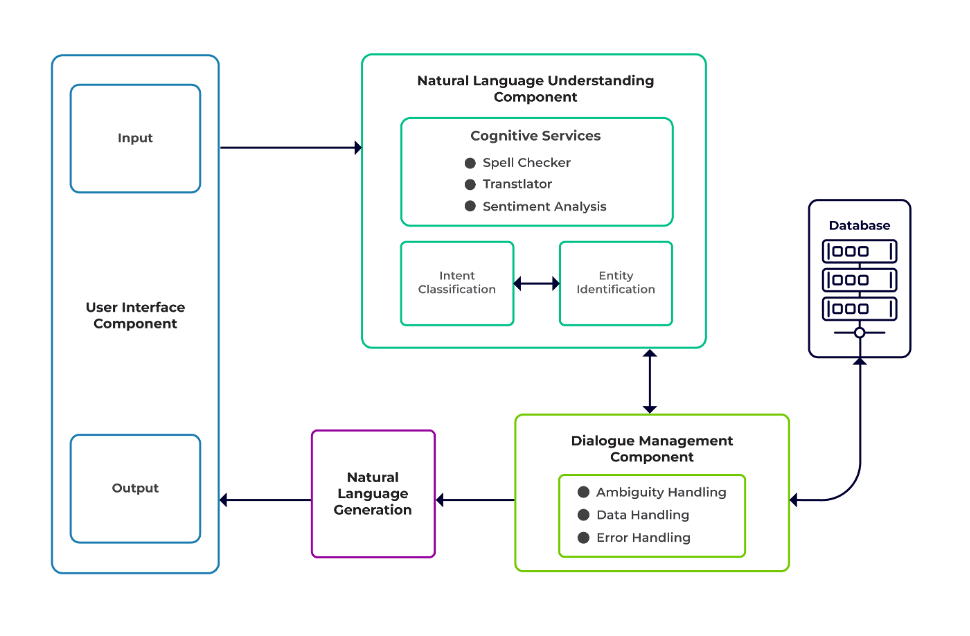
Image du logiciel Talentica
Données insuffisantes
Lorsque les développeurs remplacent les FAQ ou autres systèmes d'assistance par un chatbot, ils obtiennent une quantité décente de données de formation. Mais la même chose ne se produit pas lorsqu’ils créent le bot à partir de zéro. Dans de tels cas, les développeurs génèrent des données de formation de manière synthétique.
Que faire?
Un générateur de données basé sur un modèle peut générer une quantité décente de requêtes d'utilisateurs pour la formation. Une fois le chatbot prêt, les porteurs de projet peuvent l'exposer à un nombre limité d'utilisateurs pour améliorer les données de formation et les mettre à niveau sur une période donnée.
Sélection de modèle inappropriée
Une sélection de modèle et des données de formation appropriées sont essentielles pour obtenir les meilleurs résultats d’extraction d’intention et d’entité. Les développeurs forment généralement les chatbots dans une langue et un domaine spécifiques, et la plupart des modèles pré-entraînés disponibles sont souvent spécifiques à un domaine et formés dans une seule langue.
Il peut également y avoir des cas de langues mixtes où les gens sont polyglottes. Ils peuvent saisir des requêtes dans une langue mixte. Par exemple, dans une région à prédominance française, les gens peuvent utiliser un type d'anglais qui est un mélange de français et d'anglais.
Que faire?
L’utilisation de modèles formés dans plusieurs langues pourrait réduire le problème. Un modèle pré-entraîné comme LaBSE (intégration de phrases de Bert indépendante du langage) peut être utile dans de tels cas. Le LaBSE est formé dans plus de 109 langues sur une tâche de similarité de phrases. Le modèle connaît déjà des mots similaires dans une autre langue. Dans notre projet, cela a très bien fonctionné.
Extraction d'entité incorrecte
Les chatbots exigent que les entités identifient le type de données recherchées par l'utilisateur. Ces entités incluent l'heure, le lieu, la personne, l'élément, la date, etc. Cependant, les robots peuvent ne pas parvenir à identifier une entité à partir du langage naturel :
Même contexte mais entités différentes. Par exemple, les robots peuvent confondre un lieu avec une entité lorsqu'un utilisateur tape « Nom des étudiants de l'IIT Delhi » puis « Nom des étudiants de Bengaluru ».
Scénarios dans lesquels les entités sont mal prédites avec un faible niveau de confiance. Par exemple, un robot peut identifier IIT Delhi comme une ville avec un faible niveau de confiance.
Extraction partielle d'entités par modèle d'apprentissage automatique. Si un utilisateur saisit « étudiants de l'IIT Delhi », le modèle ne peut identifier « IIT » que comme une entité au lieu de « IIT Delhi ».
Les entrées d'un seul mot sans contexte peuvent confondre les modèles d'apprentissage automatique. Par exemple, un mot comme « Rishikesh » peut signifier à la fois le nom d’une personne et celui d’une ville.
Que faire?
L'ajout de davantage d'exemples de formation pourrait être une solution. Mais il y a une limite au-delà de laquelle en ajouter davantage ne servirait à rien. De plus, c'est un processus sans fin. Une autre solution pourrait consister à définir des modèles d'expression régulière à l'aide de mots prédéfinis pour aider à extraire des entités avec un ensemble connu de valeurs possibles, comme une ville, un pays, etc.
Les modèles partagent une confiance plus faible lorsqu'ils ne sont pas sûrs de la prédiction de l'entité. Les développeurs peuvent l'utiliser comme déclencheur pour appeler un composant personnalisé capable de rectifier l'entité peu fiable. Considérons l'exemple ci-dessus. Si IIT Delhi est prédite comme une ville avec un faible niveau de confiance, alors l'utilisateur peut toujours la rechercher dans la base de données. Après avoir échoué à trouver l'entité prédite dans le Ville table, le modèle passerait à d'autres tables et, éventuellement, le trouverait dans la Institut table, entraînant une correction d’entité.
Classification des intentions erronées
Chaque message utilisateur est associé à une intention. Étant donné que les intentions déterminent le prochain cours d'actions d'un bot, il est crucial de classer correctement les requêtes des utilisateurs avec intention. Cependant, les développeurs doivent identifier les intentions avec un minimum de confusion entre les intentions. Sinon, il peut y avoir des cas de bugs dus à la confusion. Par exemple, "Montre-moi les postes vacants » contre. "Montrez-moi les candidats aux postes vacants ».
Que faire?
Il existe deux manières de différencier les requêtes déroutantes. Premièrement, un développeur peut introduire une sous-intention. Deuxièmement, les modèles peuvent gérer des requêtes basées sur les entités identifiées.
Un chatbot spécifique à un domaine doit être un système fermé dans lequel il doit clairement identifier ce dont il est capable et ce dont il ne l'est pas. Les développeurs doivent effectuer le développement par phases tout en planifiant des chatbots spécifiques à un domaine. À chaque phase, ils peuvent identifier les fonctionnalités non prises en charge du chatbot (via une intention non prise en charge).
Ils peuvent également identifier ce que le chatbot ne peut pas gérer dans une intention « hors de portée ». Mais il peut y avoir des cas où le bot est confondu avec une intention non prise en charge et hors de portée. Pour de tels scénarios, un mécanisme de secours doit être mis en place : si le niveau de confiance de l'intention est inférieur à un seuil, le modèle peut fonctionner correctement avec une intention de secours pour gérer les cas de confusion.
Une fois que le robot a identifié l'intention du message d'un utilisateur, il doit renvoyer une réponse. Le robot décide de la réponse en fonction d'un certain ensemble de règles et d'histoires définies. Par exemple, une règle peut être aussi simple que stricte "Bonjour" lorsque l'utilisateur salue "Salut". Cependant, le plus souvent, les conversations avec les chatbots comprennent une interaction de suivi et leurs réponses dépendent du contexte global de la conversation.
Que faire?
Pour gérer cela, les chatbots sont alimentés par des exemples de conversations réelles appelés Stories. Cependant, les utilisateurs n’interagissent pas toujours comme prévu. Un chatbot mature doit gérer tous ces écarts avec élégance. Les concepteurs et les développeurs peuvent garantir cela s'ils ne se concentrent pas uniquement sur un chemin heureux lorsqu'ils écrivent des histoires, mais travaillent également sur des chemins malheureux.
L'engagement des utilisateurs avec les chatbots dépend fortement des réponses des chatbots. Les utilisateurs pourraient perdre tout intérêt si les réponses sont trop robotiques ou trop familières. Par exemple, un utilisateur peut ne pas aimer une réponse telle que « Vous avez tapé une mauvaise requête » pour une mauvaise saisie, même si la réponse est correcte. La réponse ici ne correspond pas à la personnalité d'un assistant.
Que faire?
Le chatbot sert d’assistant et doit posséder une personnalité et un ton de voix spécifiques. Ils doivent être accueillants et humbles, et les développeurs doivent concevoir les conversations et les déclarations en conséquence. Les réponses ne doivent pas paraître robotiques ou mécaniques. Par exemple, le robot pourrait dire : «Désolé, il semble que je n'ai aucun détail. Pourriez-vous s'il vous plaît retaper votre requête ? » pour corriger une mauvaise entrée.
Les chatbots basés sur LLM (Large Language Model) comme ChatGPT et Bard sont des innovations révolutionnaires et ont amélioré les capacités des IA conversationnelles. Ils sont non seulement doués pour engager des conversations ouvertes de type humain, mais peuvent également effectuer différentes tâches telles que le résumé de texte, la rédaction de paragraphes, etc., qui ne pouvaient être réalisées auparavant que par des modèles spécifiques.
L'un des défis des systèmes de chatbot traditionnels est de catégoriser chaque phrase en intentions et de décider de la réponse en conséquence. Cette approche n'est pas pratique. Les réponses telles que « Désolé, je n'ai pas pu vous joindre » sont souvent irritantes. Les systèmes de chatbots intentifs sont la voie à suivre, et les LLM peuvent en faire une réalité.
Les LLM peuvent facilement obtenir des résultats de pointe en matière de reconnaissance générale d'entités nommées, à l'exception de certaines reconnaissances d'entités spécifiques à un domaine. Une approche mixte de l'utilisation des LLM avec n'importe quel framework de chatbot peut inspirer un système de chatbot plus mature et plus robuste.
Avec les dernières avancées et la recherche continue en matière d’IA conversationnelle, les chatbots s’améliorent chaque jour. Des domaines tels que la gestion de tâches complexes aux intentions multiples, telles que « Réserver un vol pour Mumbai et organiser un taxi pour Dadar », retiennent beaucoup l'attention.
Bientôt, des conversations personnalisées auront lieu en fonction des caractéristiques de l'utilisateur pour maintenir l'engagement de l'utilisateur. Par exemple, si un robot constate que l’utilisateur n’est pas satisfait, il redirige la conversation vers un véritable agent. De plus, avec des données de chatbot toujours croissantes, les techniques d'apprentissage en profondeur telles que ChatGPT peuvent générer automatiquement des réponses aux requêtes à l'aide d'une base de connaissances.
Souman Saurav est Data Scientist chez Talentica Software, une société de développement de produits logiciels. Il est un ancien élève de NIT Agartala avec plus de 8 ans d'expérience dans la conception et la mise en œuvre de solutions d'IA révolutionnaires utilisant la PNL, l'IA conversationnelle et l'IA générative.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them
- :possède
- :est
- :ne pas
- :où
- 8
- a
- capacité
- A Propos
- au dessus de
- en conséquence
- atteindre
- atteint
- à travers
- actes
- ajoutant
- En outre
- propos
- adresser
- progrès
- Après
- Agent
- agents
- AI
- AI chatbot
- Alexa
- Tous
- déjà
- aussi
- ancien élève
- toujours
- montant
- an
- ainsi que
- Une autre
- répondre
- tous
- une approche
- SONT
- domaines
- AS
- demandant
- Assistante gérante
- assistants
- associé
- At
- précaution
- automatiquement
- disponibles
- éviter
- RETOUR
- base
- basé
- BE
- devenir
- êtres
- ci-dessous
- LES MEILLEURS
- Améliorée
- Bot
- tous les deux
- les robots
- construire
- mais
- by
- Appelez-nous
- appelé
- CAN
- ne peut pas
- capacités
- capable
- cas
- catégoriser
- certaines
- globaux
- Modifications
- caractéristiques
- Chatbot
- Chatbots
- ChatGPT
- Ville
- classification
- classifié
- clairement
- fonds à capital fermé
- Société
- plaintes
- complexe
- composant
- composants électriques
- comprendre
- confiance
- confus
- confusion
- confusion
- Considérer
- contexte
- continu
- Conversation
- de la conversation
- IA conversationnel
- conversations
- correct
- correctement
- Correspondant
- pourriez
- Pays
- cours
- engendrent
- La création
- crucial
- Courant
- Customiser
- données
- Data Scientist
- Base de données
- Date
- journée
- décent
- Décider
- profond
- l'apprentissage en profondeur
- Vous permet de définir
- défini
- Delhi
- dépendre
- dériver
- Conception
- designers
- conception
- détails
- Développeur
- mobiles
- Développement
- boîte de dialogue
- Dialogue
- différent
- différencier
- do
- Ne fait pas
- domaine
- Ne pas
- chacun
- Plus tôt
- même
- effort
- enrobage
- Endless
- s'engager
- engagé
- participation
- Anglais
- de renforcer
- Entrer
- entités
- entité
- etc
- Pourtant, la
- faire une éventuelle
- de plus en plus
- Chaque
- tous les jours
- exemple
- exemples
- d'experience
- Expliquer
- extrait
- extraction
- FAIL
- défaut
- familier
- RAPIDE
- Fonctionnalités:
- Fed
- Trouvez
- trouve
- vol
- Focus
- Pour
- Avant
- Framework
- cadres
- Français
- De
- Général
- générer
- générateur
- génération
- génératif
- IA générative
- générateur
- obtenez
- obtention
- donné
- Bien
- guarantir
- manipuler
- Maniabilité
- arriver
- heureux vous
- Vous avez
- ayant
- he
- fortement
- vous aider
- utile
- ici
- Comment
- How To
- Cependant
- HTTPS
- humain
- humble
- i
- identifié
- identifie
- identifier
- if
- la mise en œuvre
- amélioré
- in
- comprendre
- innovations
- contribution
- entrées
- inspirer
- instance
- plutôt ;
- prévu
- intention
- interagir
- l'interaction
- interactions
- intérêt
- développement
- introduire
- IT
- jpg
- juste
- KDnuggetsGenericName
- XNUMX éléments à
- ACTIVITES
- Genre
- spécialisées
- connu
- sait
- langue
- Langues
- gros
- Nouveautés
- apprentissage
- VIE
- comme
- LIMIT
- limité
- perdre
- Faible
- baisser
- click
- machine learning
- majeur
- a prendre une
- Fabrication
- Match
- mature
- Mai..
- me
- signifier
- mécanique
- mécanisme
- message
- pourrait
- minimal
- mélanger
- mixte
- modèle
- numériques jumeaux (digital twin models)
- PLUS
- Par ailleurs
- (en fait, presque toutes)
- beaucoup
- plusieurs
- Mumbai
- must
- my
- prénom
- Nommé
- Nature
- Langage naturel
- next
- NLG
- nlp
- nlu
- aucune
- nombre
- of
- souvent
- on
- une fois
- uniquement
- ouvert
- open source
- or
- Autre
- autrement
- nos
- plus de
- global
- propriétaires
- partie
- chemin
- chemins
- motifs
- Personnes
- effectuer
- effectué
- effectue
- période
- personne
- Personnalisé
- phase
- phases
- Place
- plan
- et la planification de votre patrimoine
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- veuillez cliquer
- Point
- position
- posséder
- possible
- Méthode
- prédit
- prédiction
- préfère
- présenté
- précédent
- Problème
- procéder
- processus
- Produit
- le développement de produits
- Projet
- requêtes
- fréquemment posées
- R
- rasa
- solutions
- réal
- Réalité
- vraiment
- reconnaissance
- recrutement
- réduire
- référence
- se réfère
- région
- compter
- rappel
- remplacer
- exigent
- a besoin
- un article
- résoudre
- réponse
- réponses
- responsables
- résultant
- Résultats
- révolutionnaire
- robuste
- Règle
- même
- dire
- scénarios
- Scientifique
- gratter
- Rechercher
- recherche
- semble
- sélection
- envoyer
- phrase
- sert
- set
- Partager
- devrait
- similaires
- étapes
- depuis
- unique
- siri
- Logiciels
- sur mesure
- Solutions
- quelques
- Son
- groupe de neurones
- parlé
- Étape
- Commencez
- state-of-the-art
- Stories
- rationaliser
- Étudiante
- Ces
- tel
- convient
- Support
- Systèmes de support
- sûr
- synthétiquement
- combustion propre
- Système
- T
- table
- Prenez
- prend
- Tâche
- tâches
- techniques
- texte
- que
- qui
- La
- leur
- Les
- puis
- Là.
- Ces
- l'ont
- this
- bien que?
- trois
- порог
- fiable
- à
- TON
- Ton de la voix
- trop
- traditionnel
- Train
- qualifié
- Formation
- déclencher
- deux
- type
- types
- compréhension
- améliorer
- utilisé
- d'utiliser
- Utilisateur
- utilisateurs
- en utilisant
- d'habitude
- Valeurs
- via
- Salle de conférence virtuelle
- Voix
- vs
- W
- Façon..
- façons
- Cela peut créer
- WELL
- Quoi
- quand
- chaque fois que
- qui
- tout en
- sera
- comprenant
- Word
- des mots
- activités principales
- travaillé
- pourra
- écriture
- code écrit
- faux
- années
- you
- Votre
- zéphyrnet