Alors qu'OpenAI ChatGPT aspire tout l'oxygène du cycle de nouvelles de 24 heures, Google a discrètement dévoilé un nouveau modèle d'IA qui peut générer des vidéos lorsqu'on lui donne des entrées de vidéo, d'image et de texte. Le nouvel éditeur vidéo Google Dreamix AI rapproche désormais la vidéo générée de la réalité.
Selon la recherche publiée sur GitHub, Dreamix édite la vidéo en se basant sur une vidéo et une invite de texte. La vidéo résultante conserve sa fidélité à la couleur, à la posture, à la taille de l'objet et à la pose de la caméra, ce qui donne une vidéo cohérente dans le temps. Pour le moment, Dreamix ne peut pas générer de vidéos à partir d'une simple invite, cependant, il peut prendre du matériel existant et modifier la vidéo à l'aide d'invites de texte.
Google utilise des modèles de diffusion vidéo pour Dreamix, une approche qui a été appliquée avec succès pour la plupart des montages d'images vidéo que nous voyons dans les IA d'image telles que DALL-E2 ou la diffusion stable open source.
L'approche consiste à réduire considérablement la vidéo d'entrée, à ajouter du bruit artificiel, puis à la traiter dans un modèle de diffusion vidéo, qui utilise ensuite une invite de texte pour générer une nouvelle vidéo à partir de celle-ci qui conserve certaines propriétés de la vidéo d'origine et en restitue d'autres selon à la saisie de texte.
Le modèle de diffusion vidéo offre un avenir prometteur qui pourrait inaugurer une nouvelle ère pour travailler avec des vidéos.

Par exemple, dans la vidéo ci-dessous, Dreamix transforme le singe mangeur (à gauche) en un ours dansant (à droite) à l'invite "Un ours dansant et sautant sur une musique entraînante, bougeant tout son corps".
Dans un autre exemple ci-dessous, Dreamix utilise une seule photo comme modèle (comme dans image-to-video) et un objet est ensuite animé à partir de celle-ci dans une vidéo via une invite. Les mouvements de caméra sont également possibles dans la nouvelle scène ou un enregistrement time-lapse ultérieur.
Dans un autre exemple, Dreamix transforme l'orang-outan dans un bassin d'eau (à gauche) en un orang-outan aux cheveux orange se baignant dans une belle salle de bain.
« Alors que les modèles de diffusion ont été appliqués avec succès pour le montage d'images, très peu de travaux l'ont fait pour le montage vidéo. Nous présentons la première méthode basée sur la diffusion capable d'effectuer une édition de mouvement et d'apparence basée sur du texte de vidéos générales.
Selon le document de recherche de Google, Dreamix utilise un modèle de diffusion vidéo pour combiner, au moment de l'inférence, les informations spatio-temporelles basse résolution de la vidéo d'origine avec de nouvelles informations haute résolution qu'il a synthétisées pour s'aligner sur l'invite de texte d'orientation.
Google a déclaré avoir adopté cette approche car "l'obtention d'une haute fidélité à la vidéo d'origine nécessite de conserver certaines de ses informations haute résolution, nous ajoutons une étape préliminaire de réglage fin du modèle sur la vidéo d'origine, augmentant considérablement la fidélité".
Vous trouverez ci-dessous un aperçu vidéo du fonctionnement de Dreamix.
[Contenu intégré]
Comment fonctionnent les modèles de diffusion vidéo Dreamix
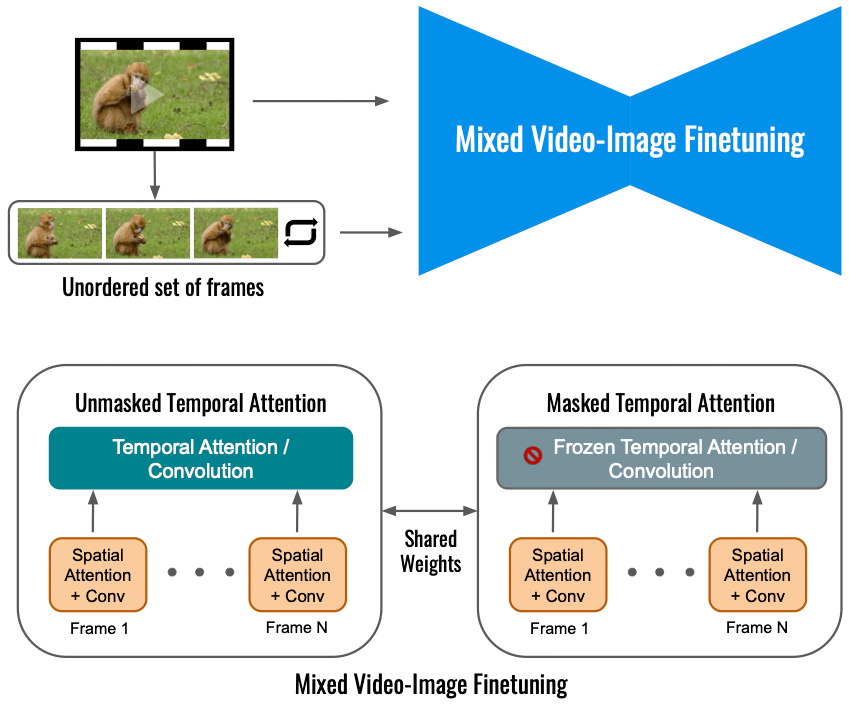
Selon Google, le réglage fin du modèle de diffusion vidéo pour Dreamix sur la seule vidéo d'entrée limite l'ampleur du changement de mouvement. Au lieu de cela, nous utilisons un objectif mixte qui, outre l'objectif d'origine (en bas à gauche), s'ajuste également sur l'ensemble non ordonné d'images. Cela se fait en utilisant «l'attention temporelle masquée», empêchant l'attention temporelle et la convolution d'être affinées (en bas à droite). Cela permet d'ajouter du mouvement à une vidéo statique.
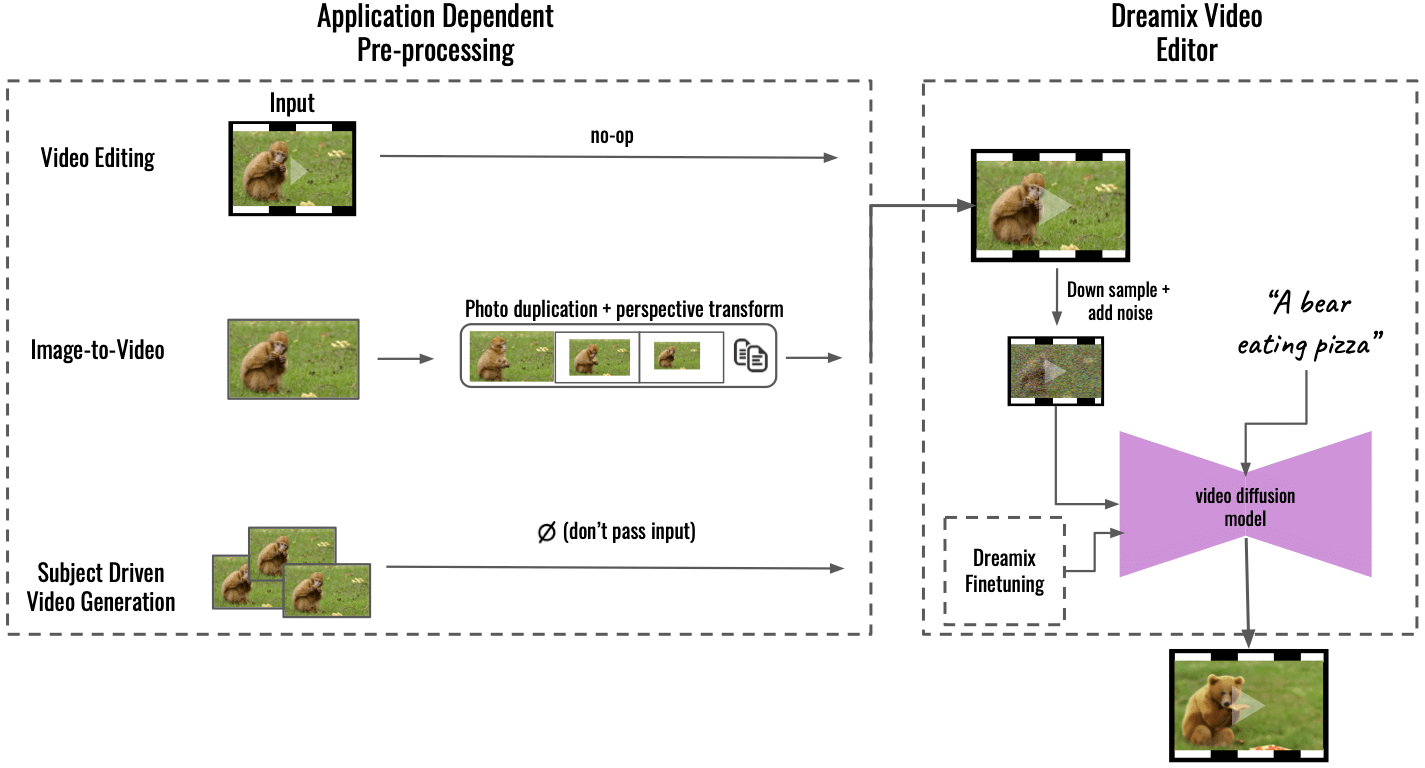
« Notre méthode prend en charge plusieurs applications grâce à un prétraitement dépendant de l'application (à gauche), convertissant le contenu d'entrée en un format vidéo uniforme. Pour l'image en vidéo, l'image d'entrée est dupliquée et transformée à l'aide de transformations de perspective, synthétisant une vidéo grossière avec un certain mouvement de caméra. Pour la génération vidéo axée sur le sujet, l'entrée est omise - le réglage fin seul prend en charge la fidélité. Cette vidéo grossière est ensuite éditée à l'aide de notre "Dreamix Video Editor" général (à droite) : nous corrompons d'abord la vidéo en sous-échantillonnant puis en ajoutant du bruit. Nous appliquons ensuite le modèle de diffusion vidéo guidé par texte affiné, qui améliore la vidéo à la résolution spatio-temporelle finale », a écrit Dream sur GitHub.
Vous pouvez lire le document de recherche ci-dessous.
Google Dreamix- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://techstartups.com/2023/02/10/google-launches-ai-powered-video-editor-dreamix-to-create-edit-videos-and-animate-images/
- a
- Capable
- Selon
- AI
- vidéo ai
- Alimenté par l'IA
- Tous
- permet
- seul
- ainsi que
- Une autre
- applications
- appliqué
- Appliquer
- une approche
- artificiel
- précaution
- basé
- Gardez
- pour créer les plus
- car
- va
- ci-dessous
- corps
- stimuler
- Bas et Leggings
- Apporte
- appareil photo
- ne peut pas
- les soins
- Change
- ChatGPT
- plus
- Couleur
- combiner
- cohérent
- contenu
- La création
- cycle
- Danse
- La diffusion
- rêve
- éditeur
- intégré
- Ère
- exemple
- existant
- few
- fidélité
- finale
- Prénom
- suivi
- le format
- de
- avenir
- Général
- générer
- généré
- génération
- gif
- GitHub
- donné
- Implants
- fortement
- haute résolution
- Comment
- Cependant
- HTTPS
- image
- satellite
- in
- d'information
- contribution
- plutôt ;
- IT
- lance
- limites
- maintient
- Matériel
- max
- méthode
- mixte
- modèle
- numériques jumeaux (digital twin models)
- modifier
- moment
- (en fait, presque toutes)
- mouvement
- mouvements
- en mouvement
- plusieurs
- Musique
- Nouveauté
- nouvelles
- Bruit
- objet
- objectif
- Offres Speciales
- open source
- OpenAI
- Orange
- original
- Autres
- vue d'ensemble
- Oxygène
- Papier
- effectuer
- objectifs
- Platon
- Intelligence des données Platon
- PlatonDonnées
- pool
- possible
- représentent
- prévention
- traitement
- prometteur
- propriétés
- publié
- tranquillement
- Lire
- Réalité
- l'enregistrement
- réduire
- a besoin
- un article
- Résolution
- résultant
- retenue
- Saïd
- scène
- set
- de façon significative
- unique
- Taille
- So
- quelques
- stable
- Étape
- ultérieur
- Avec succès
- tel
- Les soutiens
- Prenez
- modèle
- La
- fiable
- à
- transformations
- transformé
- dévoilé
- utilisé
- via
- Vidéo
- Vidéos
- Eau
- qui
- de travail
- vos contrats
- Youtube
- zéphyrnet











