Les organisations de tous les secteurs ont des exigences complexes en matière de traitement des données pour leurs cas d'utilisation analytique dans différents systèmes d'analyse, tels que lacs de données sur AWS, entrepôts de données (Redshift d'Amazon), recherche (Service Amazon OpenSearch), NoSQL (Amazon DynamoDB), l'apprentissage automatique (Amazon Sage Maker), et plus. Les professionnels de l'analyse sont chargés de tirer de la valeur des données stockées dans ces systèmes distribués afin de créer des expériences meilleures, sécurisées et optimisées en termes de coûts pour leurs clients. Par exemple, les entreprises de médias numériques cherchent à combiner et à traiter des ensembles de données dans des bases de données internes et externes pour créer des vues unifiées de leurs profils clients, stimuler des idées de fonctionnalités innovantes et accroître l'engagement de la plateforme.
Dans ces scénarios, les clients à la recherche d'une offre d'intégration de données sans serveur utilisent Colle AWS en tant que composant central pour le traitement et le catalogage des données. AWS Glue est bien intégré aux services AWS et aux produits partenaires, et fournit des options d'extraction, de transformation et de chargement (ETL) low-code/no-code pour activer les workflows d'analyse, d'apprentissage automatique (ML) ou de développement d'applications. Les tâches ETL AWS Glue peuvent être un composant d'un pipeline plus complexe. Orchestrer l'exécution et gérer les dépendances entre ces composants est une capacité clé dans une stratégie de données. Flux de travail gérés par Amazon pour Apache Airflows (Amazon MWAA) orchestre les pipelines de données à l'aide de technologies distribuées, notamment des ressources sur site, des services AWS et des composants tiers.
Dans cet article, nous montrons comment simplifier la surveillance d'une tâche AWS Glue orchestrée par Airflow à l'aide des dernières fonctionnalités d'Amazon MWAA.
Présentation de la solution
Ce message traite des éléments suivants :
- Comment mettre à niveau un environnement Amazon MWAA vers la version 2.4.3.
- Comment orchestrer une tâche AWS Glue à partir d'un Airflow Graphique acyclique dirigé (DAG).
- Améliorations de l'observabilité du package du fournisseur Airflow Amazon dans Amazon MWAA. Vous pouvez désormais consolider les journaux d'exécution des tâches AWS Glue sur la console Airflow pour simplifier le dépannage des pipelines de données. La console Amazon MWAA devient une référence unique pour surveiller et analyser les exécutions de tâches AWS Glue. Auparavant, les équipes d'assistance devaient accéder au Console de gestion AWS et prendre des mesures manuelles pour cette visibilité. Cette fonctionnalité est disponible par défaut à partir de la version 2.4.3 d'Amazon MWAA.
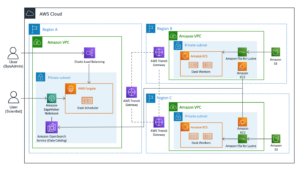
Le diagramme suivant illustre notre architecture de solution.
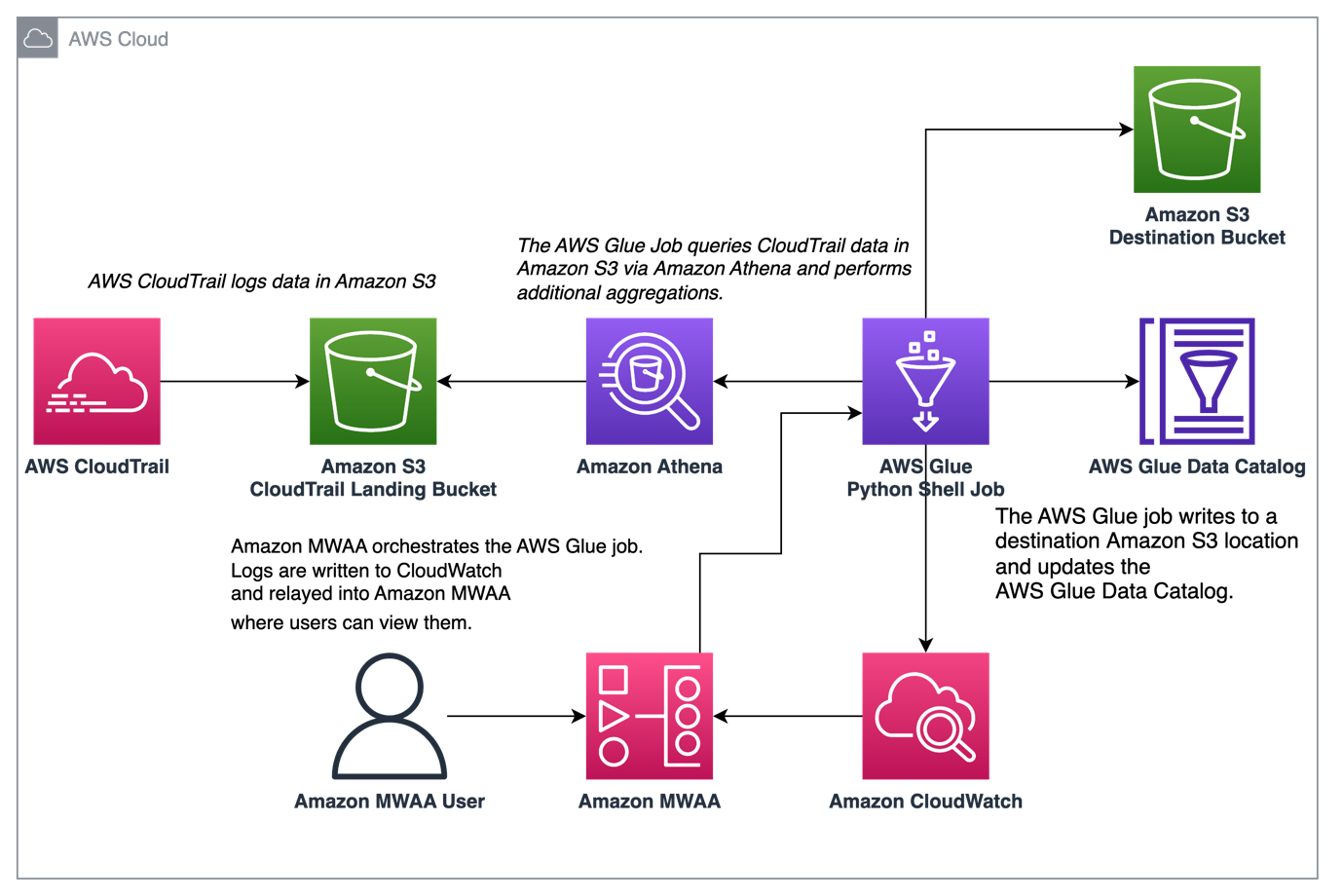
Pré-requis
Vous avez besoin des prérequis suivants :
Configurer l'environnement Amazon MWAA
Pour obtenir des instructions sur la création de votre environnement, reportez-vous à Créer un environnement Amazon MWAA. Pour les utilisateurs existants, nous recommandons de passer à la version 2.4.3 pour profiter des améliorations d'observabilité présentées dans cet article.
Les étapes de mise à niveau d'Amazon MWAA vers la version 2.4.3 diffèrent selon que la version actuelle est 1.10.12 ou 2.2.2. Nous discutons des deux options dans cet article.
Prérequis pour la configuration d'un environnement Amazon MWAA
Vous devez remplir les prérequis suivants :
Mise à niveau de la version 1.10.12 vers la 2.4.3
Si vous utilisez la version Amazon MWAA 1.10.12, faire référence à Migration vers un nouvel environnement Amazon MWAA pour passer à la version 2.4.3.
Mise à niveau de la version 2.0.2 ou 2.2.2 vers la 2.4.3
Si vous utilisez l'environnement Amazon MWAA version 2.2.2 ou antérieure, procédez comme suit :
- Créer un requirements.txt pour toutes les dépendances personnalisées avec les versions spécifiques requises pour vos DAG.
- Télécharger le fichier sur Amazon S3 à l'emplacement approprié où l'environnement Amazon MWAA pointe vers requirements.txt pour l'installation des dépendances.
- Suivez les étapes de Migration vers un nouvel environnement Amazon MWAA et sélectionnez la version 2.4.3.
Mettez à jour vos DAG
Les clients qui ont effectué une mise à niveau à partir d'un ancien environnement Amazon MWAA peuvent avoir besoin de mettre à jour les DAG existants. Dans Airflow version 2.4.3, l'environnement Airflow utilisera par défaut le package de fournisseur Amazon version 6.0.0. Ce package peut inclure des modifications potentiellement importantes, telles que des modifications des noms d'opérateurs. Par exemple, le AWSGlueJobOperatorAWSGlueJobOperatorAWSGlueJobOperatorAWSGlueJobOperator a été déprécié et remplacé par le Opérateur GlueJob. Pour maintenir la compatibilité, mettez à jour vos DAG Airflow en remplaçant tous les opérateurs obsolètes ou non pris en charge des versions précédentes par les nouveaux. Effectuez les étapes suivantes :
- Accédez à Opérateurs Amazon AWS.
- Sélectionnez la version appropriée installée dans votre instance Amazon MWAA (6.0.0. par défaut) pour trouver une liste des opérateurs Airflow pris en charge.
- Apportez les modifications nécessaires au code DAG existant et chargez les fichiers modifiés à l'emplacement DAG dans Amazon S3.
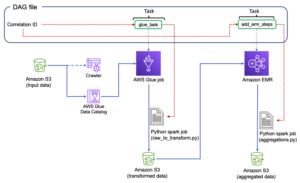
Orchestrez la tâche AWS Glue à partir d'Airflow
Cette section couvre les détails de l'orchestration d'une tâche AWS Glue dans les DAG Airflow. Airflow facilite le développement de pipelines de données avec des dépendances entre des systèmes hétérogènes tels que des processus sur site, des dépendances externes, d'autres services AWS, etc.
Orchestrez l'agrégation de journaux CloudTrail avec AWS Glue et Amazon MWAA
Dans cet exemple, nous passons en revue un cas d'utilisation d'utilisation d'Amazon MWAA pour orchestrer une tâche AWS Glue Python Shell qui conserve des métriques agrégées basées sur les journaux CloudTrail.
CloudTrail permet une visibilité sur les appels d'API AWS qui sont effectués dans votre compte AWS. Un cas d'utilisation courant avec ces données serait de collecter des métriques d'utilisation sur les principaux agissant sur les ressources de votre compte pour des besoins d'audit et de réglementation.
Au fur et à mesure que les événements CloudTrail sont consignés, ils sont livrés sous forme de fichiers JSON dans Amazon S3, ce qui n'est pas idéal pour les requêtes analytiques. Nous voulons agréger ces données et les conserver en tant que fichiers Parquet pour permettre des performances de requête optimales. Dans un premier temps, nous pouvons utiliser Athena pour effectuer l'interrogation initiale des données avant de procéder à des agrégations supplémentaires dans notre tâche AWS Glue. Pour plus d'informations sur la création d'une table de catalogue de données AWS Glue, consultez Création de la table pour les journaux CloudTrail dans Athena à l'aide de la projection de partition données. Une fois que nous avons exploré les données via Athena et décidé quelles métriques nous souhaitons conserver dans les tableaux agrégés, nous pouvons créer une tâche AWS Glue.
Créer une table CloudTrail dans Athena
Tout d'abord, nous devons créer une table dans notre catalogue de données qui permet d'interroger les données CloudTrail via Athena. L'exemple de requête suivant crée une table avec deux partitions sur la région et la date (appelée snapshot_date). Assurez-vous de remplacer les espaces réservés pour votre compartiment CloudTrail, l'ID de compte AWS et le nom de la table CloudTrail :
create external table if not exists `<<<CLOUDTRAIL_TABLE_NAME>>>`( `eventversion` string comment 'from deserializer', `useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>> comment 'from deserializer', `eventtime` string comment 'from deserializer', `eventsource` string comment 'from deserializer', `eventname` string comment 'from deserializer', `awsregion` string comment 'from deserializer', `sourceipaddress` string comment 'from deserializer', `useragent` string comment 'from deserializer', `errorcode` string comment 'from deserializer', `errormessage` string comment 'from deserializer', `requestparameters` string comment 'from deserializer', `responseelements` string comment 'from deserializer', `additionaleventdata` string comment 'from deserializer', `requestid` string comment 'from deserializer', `eventid` string comment 'from deserializer', `resources` array<struct<arn:string,accountid:string,type:string>> comment 'from deserializer', `eventtype` string comment 'from deserializer', `apiversion` string comment 'from deserializer', `readonly` string comment 'from deserializer', `recipientaccountid` string comment 'from deserializer', `serviceeventdetails` string comment 'from deserializer', `sharedeventid` string comment 'from deserializer', `vpcendpointid` string comment 'from deserializer')
PARTITIONED BY ( `region` string, `snapshot_date` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/'
TBLPROPERTIES ( 'projection.enabled'='true', 'projection.region.type'='enum', 'projection.region.values'='us-east-2,us-east-1,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-3,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1', 'projection.snapshot_date.format'='yyyy/mm/dd', 'projection.snapshot_date.interval'='1', 'projection.snapshot_date.interval.unit'='days', 'projection.snapshot_date.range'='2020/10/01,now', 'projection.snapshot_date.type'='date', 'storage.location.template'='s3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/${region}/${snapshot_date}')Exécutez la requête précédente sur la console Athena et notez le nom de la table et la base de données AWS Glue Data Catalog dans laquelle elle a été créée. Nous utilisons ces valeurs plus tard dans le code Airflow DAG.
Exemple de code de travail AWS Glue
Le code suivant est un exemple Tâche AWS Glue Python Shell qui fait ce qui suit :
- Prend des arguments (que nous transmettons depuis notre Amazon MWAA DAG) sur les données du jour à traiter
- Utilise le Kit de développement logiciel AWS pour Pandas pour exécuter une requête Athena pour effectuer le filtrage initial des données CloudTrail JSON en dehors d'AWS Glue
- Utilise Pandas pour faire des agrégations simples sur les données filtrées
- Génère les données agrégées dans le catalogue de données AWS Glue dans une table
- Utilise la journalisation pendant le traitement, qui sera visible dans Amazon MWAA
import awswrangler as wr
import pandas as pd
import sys
import logging
from awsglue.utils import getResolvedOptions
from datetime import datetime, timedelta # Logging setup, redirects all logs to stdout
LOGGER = logging.getLogger()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s')
streamHandler = logging.StreamHandler(sys.stdout)
streamHandler.setFormatter(formatter)
LOGGER.addHandler(streamHandler)
LOGGER.setLevel(logging.INFO) LOGGER.info(f"Passed Args :: {sys.argv}") sql_query_template = """
select
region,
useridentity.arn,
eventsource,
eventname,
useragent from "{cloudtrail_glue_db}"."{cloudtrail_table}"
where snapshot_date='{process_date}'
and region in ('us-east-1','us-east-2') """ required_args = ['CLOUDTRAIL_GLUE_DB', 'CLOUDTRAIL_TABLE', 'TARGET_BUCKET', 'TARGET_DB', 'TARGET_TABLE', 'ACCOUNT_ID']
arg_keys = [*required_args, 'PROCESS_DATE'] if '--PROCESS_DATE' in sys.argv else required_args
JOB_ARGS = getResolvedOptions ( sys.argv, arg_keys) LOGGER.info(f"Parsed Args :: {JOB_ARGS}") # if process date was not passed as an argument, process yesterday's data
process_date = ( JOB_ARGS['PROCESS_DATE'] if JOB_ARGS.get('PROCESS_DATE','NONE') != "NONE" else (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d") ) LOGGER.info(f"Taking snapshot for :: {process_date}") RAW_CLOUDTRAIL_DB = JOB_ARGS['CLOUDTRAIL_GLUE_DB']
RAW_CLOUDTRAIL_TABLE = JOB_ARGS['CLOUDTRAIL_TABLE']
TARGET_BUCKET = JOB_ARGS['TARGET_BUCKET']
TARGET_DB = JOB_ARGS['TARGET_DB']
TARGET_TABLE = JOB_ARGS['TARGET_TABLE']
ACCOUNT_ID = JOB_ARGS['ACCOUNT_ID'] final_query = sql_query_template.format( process_date=process_date.replace("-","/"), cloudtrail_glue_db=RAW_CLOUDTRAIL_DB, cloudtrail_table=RAW_CLOUDTRAIL_TABLE
) LOGGER.info(f"Running Query :: {final_query}") raw_cloudtrail_df = wr.athena.read_sql_query( sql=final_query, database=RAW_CLOUDTRAIL_DB, ctas_approach=False, s3_output=f"s3://{TARGET_BUCKET}/athena-results",
) raw_cloudtrail_df['ct']=1 agg_df = raw_cloudtrail_df.groupby(['arn','region','eventsource','eventname','useragent'],as_index=False).agg({'ct':'sum'})
agg_df['snapshot_date']=process_date LOGGER.info(agg_df.info(verbose=True)) upload_path = f"s3://{TARGET_BUCKET}/{TARGET_DB}/{TARGET_TABLE}" if not agg_df.empty: LOGGER.info(f"Upload to {upload_path}") try: response = wr.s3.to_parquet( df=agg_df, path=upload_path, dataset=True, database=TARGET_DB, table=TARGET_TABLE, mode="overwrite_partitions", schema_evolution=True, partition_cols=["snapshot_date"], compression="snappy", index=False ) LOGGER.info(response) except Exception as exc: LOGGER.error("Uploading to S3 failed") LOGGER.exception(exc) raise exc
else: LOGGER.info(f"Dataframe was empty, nothing to upload to {upload_path}")
Voici quelques avantages clés de cette tâche AWS Glue :
- Nous utilisons une requête Athena pour nous assurer que le filtrage initial est effectué en dehors de notre tâche AWS Glue. Ainsi, une tâche Python Shell avec un calcul minimal est toujours suffisante pour agréger un grand ensemble de données CloudTrail.
- Nous assurons la option d'ensemble de bibliothèque d'analyse est activé lors de la création de notre tâche AWS Glue pour utiliser la bibliothèque AWS SDK for Pandas.
Créer une tâche AWS Glue
Effectuez les étapes suivantes pour créer votre tâche AWS Glue :
- Copiez le script de la section précédente et enregistrez-le dans un fichier local. Pour ce post, le fichier s'appelle
script.py. - Sur la console AWS Glue, choisissez Emplois ETL dans le volet de navigation.
- Créez une nouvelle tâche et sélectionnez Éditeur de scripts Python Shell.
- Sélectionnez Télécharger et modifier un script existant et téléchargez le fichier que vous avez enregistré localement.
- Selectionnez Création.

- Sur le Détails du poste , saisissez un nom pour votre tâche AWS Glue.
- Pour Rôle IAM, choisissez un rôle existant ou créez un nouveau rôle disposant des autorisations requises pour Amazon S3, AWS Glue et Athena. Le rôle doit interroger la table CloudTrail que vous avez créée précédemment et écrire dans un emplacement de sortie.
Vous pouvez utiliser l'exemple de code de stratégie suivant. Remplacez les espaces réservés par votre compartiment de journaux CloudTrail, le nom de la table de sortie, la base de données AWS Glue de sortie, le compartiment S3 de sortie, le nom de la table CloudTrail, la base de données AWS Glue contenant la table CloudTrail et votre ID de compte AWS.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:List*", "s3:Get*" ], "Resource": [ "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>/*", "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>*" ], "Effect": "Allow", "Sid": "GetS3CloudtrailData" }, { "Action": [ "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>/<<<CLOUDTRAIL_TABLE>>>*" ], "Effect": "Allow", "Sid": "GetGlueCatalogCloudtrailData" }, { "Action": [ "s3:PutObject*", "s3:Abort*", "s3:DeleteObject*", "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:Head*" ], "Resource": [ "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>", "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>/*" ], "Effect": "Allow", "Sid": "WriteOutputToS3" }, { "Action": [ "glue:CreateTable", "glue:CreatePartition", "glue:UpdatePartition", "glue:UpdateTable", "glue:DeleteTable", "glue:DeletePartition", "glue:BatchCreatePartition", "glue:BatchDeletePartition", "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<OUTPUT_GLUE_DB>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>*" ], "Effect": "Allow", "Sid": "AllowOutputToGlue" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:/aws-glue/*", "Effect": "Allow", "Sid": "LogsAccess" }, { "Action": [ "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:DeleteObject*", "s3:PutObject", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3:PutObjectTagging", "s3:PutObjectVersionTagging", "s3:Abort*" ], "Resource": [ "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>", "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>/*" ], "Effect": "Allow", "Sid": "AccessToAthenaResults" }, { "Action": [ "athena:StartQueryExecution", "athena:StopQueryExecution", "athena:GetDataCatalog", "athena:GetQueryResults", "athena:GetQueryExecution" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:datacatalog/AwsDataCatalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:workgroup/primary" ], "Effect": "Allow", "Sid": "AllowAthenaQuerying" } ]
}
Pour Version Python, choisissez Python 3.9.
- Sélectionnez Charger des bibliothèques d'analyse communes.
- Pour Unités de traitement de données, choisissez 1 UPD.
- Laissez les autres options par défaut ou ajustez-les si nécessaire.

- Selectionnez Épargnez pour enregistrer la configuration de votre tâche.
Configurer un DAG Amazon MWAA pour orchestrer la tâche AWS Glue
Le code suivant est destiné à un DAG qui peut orchestrer la tâche AWS Glue que nous avons créée. Nous profitons des fonctionnalités clés suivantes dans ce DAG :
"""Sample DAG"""
import airflow.utils
from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
from airflow import DAG
from datetime import timedelta
import airflow.utils # allow backfills via DAG run parameters
process_date = '{{ dag_run.conf.get("process_date") if dag_run.conf.get("process_date") else "NONE" }}' dag = DAG( dag_id = "CLOUDTRAIL_LOGS_PROCESSING", default_args = { 'depends_on_past':False, 'start_date':airflow.utils.dates.days_ago(0), 'retries':1, 'retry_delay':timedelta(minutes=5), 'catchup': False }, schedule_interval = None, # None for unscheduled or a cron expression - E.G. "00 12 * * 2" - at 12noon Tuesday dagrun_timeout = timedelta(minutes=30), max_active_runs = 1, max_active_tasks = 1 # since there is only one task in our DAG
) ## Log ingest. Assumes Glue Job is already created
glue_ingestion_job = GlueJobOperator( task_id="<<<some-task-id>>>", job_name="<<<GLUE_JOB_NAME>>>", script_args={ "--ACCOUNT_ID":"<<<YOUR_AWS_ACCT_ID>>>", "--CLOUDTRAIL_GLUE_DB":"<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "--CLOUDTRAIL_TABLE":"<<<CLOUDTRAIL_TABLE>>>", "--TARGET_BUCKET": "<<<OUTPUT_S3_BUCKET>>>", "--TARGET_DB": "<<<OUTPUT_GLUE_DB>>>", # should already exist "--TARGET_TABLE": "<<<OUTPUT_TABLE_NAME>>>", "--PROCESS_DATE": process_date }, region_name="us-east-1", dag=dag, verbose=True
) glue_ingestion_job
Augmenter l'observabilité des tâches AWS Glue dans Amazon MWAA
Les tâches AWS Glue écrivent des journaux sur Amazon Cloud Watch. Avec les récentes améliorations d'observabilité apportées au package de fournisseur Amazon d'Airflow, ces journaux sont désormais intégrés aux journaux de tâches d'Airflow. Cette consolidation offre aux utilisateurs d'Airflow une visibilité de bout en bout directement dans l'interface utilisateur d'Airflow, éliminant ainsi le besoin de rechercher dans CloudWatch ou la console AWS Glue.
Pour utiliser cette fonctionnalité, assurez-vous que le rôle IAM attaché à l'environnement Amazon MWAA dispose des autorisations suivantes pour récupérer et écrire les journaux nécessaires :
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:GetLogEvents", "logs:GetLogRecord", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogGroupFields", "logs:GetQueryResults", ], "Resource": [ "arn:aws:logs:*:*:log-group:airflow-243-<<<Your environment name>>>-*"--Your Amazon MWAA Log Stream Name ] } ]
}Si verbose=true, les journaux d'exécution de tâche AWS Glue s'affichent dans les journaux de tâche Airflow. Le défaut est faux. Pour plus d'informations, reportez-vous à Paramètres.
Lorsqu'ils sont activés, les DAG lisent à partir du flux de journaux CloudWatch de la tâche AWS Glue et les relaient vers les journaux d'étape de la tâche Airflow DAG AWS Glue. Cela fournit des informations détaillées sur l'exécution d'une tâche AWS Glue en temps réel via les journaux DAG. Notez que les tâches AWS Glue génèrent un groupe de journaux CloudWatch de sortie et d'erreur en fonction respectivement de STDOUT et STDERR de la tâche. Tous les journaux du groupe de journaux de sortie et les journaux d'exceptions ou d'erreurs du groupe de journaux d'erreurs sont relayés dans Amazon MWAA.
Les administrateurs AWS peuvent désormais limiter l'accès d'une équipe d'assistance à Airflow uniquement, faisant d'Amazon MWAA le volet unique de l'orchestration des tâches et de la gestion de la santé des tâches. Auparavant, les utilisateurs devaient vérifier l'état d'exécution de la tâche AWS Glue dans les étapes du DAG Airflow et récupérer l'identifiant d'exécution de la tâche. Ils devaient ensuite accéder à la console AWS Glue pour trouver l'historique d'exécution des tâches, rechercher la tâche qui les intéressait à l'aide de l'identifiant et enfin accéder aux journaux CloudWatch de la tâche pour résoudre les problèmes.
Créer le DAG
Pour créer le DAG, procédez comme suit :
- Enregistrez le code DAG précédent dans un fichier .py local, en remplaçant les espaces réservés indiqués.
Les valeurs de votre ID de compte AWS, du nom de la tâche AWS Glue, de la base de données AWS Glue avec la table CloudTrail et du nom de la table CloudTrail doivent déjà être connues. Vous pouvez ajuster le compartiment S3 de sortie, la base de données AWS Glue de sortie et le nom de la table de sortie selon vos besoins, mais assurez-vous que le rôle IAM de la tâche AWS Glue que vous avez utilisé précédemment est configuré en conséquence.
- Sur la console Amazon MWAA, accédez à votre environnement pour voir où le code DAG est stocké.
Le dossier DAGs est le préfixe dans le compartiment S3 où votre fichier DAG doit être placé.
- Téléchargez votre fichier modifié ici.

- Ouvrez la console Amazon MWAA pour confirmer que le DAG apparaît dans le tableau.

Exécutez le DAG
Pour exécuter le DAG, procédez comme suit :
- Choisissez parmi les options suivantes:
- Déclencher DAG – Cela entraîne l'utilisation des données d'hier comme données à traiter
- Déclencher DAG avec configuration – Avec cette option, vous pouvez passer une date différente, éventuellement pour les remblais, qui est récupérée à l'aide de
dag_run.confdans le code DAG puis transmis dans la tâche AWS Glue en tant que paramètre

La capture d'écran suivante montre les options de configuration supplémentaires si vous choisissez Déclencher DAG avec configuration.

- Surveillez le DAG pendant son exécution.
- Lorsque le DAG est terminé, ouvrez les détails de l'exécution.
Dans le volet de droite, vous pouvez afficher les journaux ou choisir Détails de l'instance de tâche pour une vue complète.

- Affichez les journaux de sortie des tâches AWS Glue dans Amazon MWAA sans utiliser la console AWS Glue grâce à la
GlueJobOperatordrapeau verbeux.

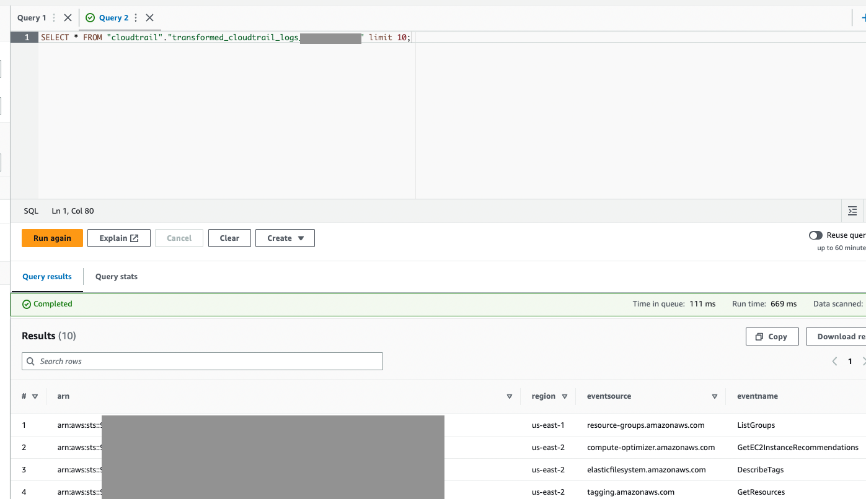
La tâche AWS Glue aura écrit les résultats dans la table de sortie que vous avez spécifiée.
- Interrogez cette table via Athena pour confirmer que l'opération a réussi.
Résumé
Amazon MWAA fournit désormais un emplacement unique pour suivre l'état des tâches AWS Glue et vous permet d'utiliser la console Airflow comme panneau unique pour l'orchestration des tâches et la gestion de l'intégrité. Dans cet article, nous avons parcouru les étapes pour orchestrer les tâches AWS Glue via Airflow à l'aide GlueJobOperator. Grâce aux nouvelles améliorations d'observabilité, vous pouvez facilement dépanner les tâches AWS Glue dans une expérience unifiée. Nous avons également montré comment mettre à niveau votre environnement Amazon MWAA vers une version compatible, mettre à jour les dépendances et modifier la stratégie de rôle IAM en conséquence.
Pour plus d'informations sur les étapes de dépannage courantes, reportez-vous à Dépannage : création et mise à jour d'un environnement Amazon MWAA. Pour plus de détails sur la migration vers un environnement Amazon MWAA, consultez Mise à niveau de 1.10 vers 2. Pour en savoir plus sur les modifications apportées au code open source pour une observabilité accrue des tâches AWS Glue dans le package du fournisseur Airflow Amazon, consultez le relayer les journaux des tâches AWS Glue.
Enfin, nous vous recommandons de visiter le Blog AWS Big Data pour d'autres documents sur l'analyse, le ML et la gouvernance des données sur AWS.
À propos des auteurs
 Roushabh Lokhande est un ingénieur Data & ML avec la pratique AWS Professional Services Analytics. Il aide les clients à mettre en œuvre des solutions de Big Data, d'apprentissage automatique et d'analyse. En dehors du travail, il aime passer du temps avec sa famille, lire, courir et jouer au golf.
Roushabh Lokhande est un ingénieur Data & ML avec la pratique AWS Professional Services Analytics. Il aide les clients à mettre en œuvre des solutions de Big Data, d'apprentissage automatique et d'analyse. En dehors du travail, il aime passer du temps avec sa famille, lire, courir et jouer au golf.
 Ryan Gomes est un ingénieur Data & ML avec la pratique AWS Professional Services Analytics. Il se passionne pour aider les clients à obtenir de meilleurs résultats grâce à des solutions d'analyse et d'apprentissage automatique dans le cloud. En dehors du travail, il aime faire du fitness, cuisiner et passer du temps de qualité avec ses amis et sa famille.
Ryan Gomes est un ingénieur Data & ML avec la pratique AWS Professional Services Analytics. Il se passionne pour aider les clients à obtenir de meilleurs résultats grâce à des solutions d'analyse et d'apprentissage automatique dans le cloud. En dehors du travail, il aime faire du fitness, cuisiner et passer du temps de qualité avec ses amis et sa famille.
 Vishwa Gupta est architecte de données senior au sein de la pratique AWS Professional Services Analytics. Il aide les clients à mettre en œuvre des solutions de Big Data et d'analyse. En dehors du travail, il aime passer du temps avec sa famille, voyager et essayer de nouveaux plats.
Vishwa Gupta est architecte de données senior au sein de la pratique AWS Professional Services Analytics. Il aide les clients à mettre en œuvre des solutions de Big Data et d'analyse. En dehors du travail, il aime passer du temps avec sa famille, voyager et essayer de nouveaux plats.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoAiStream. Intelligence des données Web3. Connaissance Amplifiée. Accéder ici.
- Frapper l'avenir avec Adryenn Ashley. Accéder ici.
- Achetez et vendez des actions de sociétés PRE-IPO avec PREIPO®. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/simplify-aws-glue-job-orchestration-and-monitoring-with-amazon-mwaa/
- :possède
- :est
- :ne pas
- :où
- $UP
- 1
- 10
- 100
- 12
- 8
- a
- A Propos
- accès
- en conséquence
- Compte
- atteindre
- à travers
- Action
- acyclique
- Supplémentaire
- Avantage
- avantages
- Après
- agrégation
- Tous
- permettre
- permet
- déjà
- aussi
- Amazon
- Amazon Web Services
- an
- Analytique
- analytique
- il analyse
- ainsi que
- tous
- Apache
- api
- Application
- Le développement d'applications
- approprié
- architecture
- SONT
- argument
- arguments
- AS
- At
- attributs
- audit
- disponibles
- AWS
- Colle AWS
- Services professionnels AWS
- basé
- BE
- devient
- était
- before
- va
- Améliorée
- jusqu'à XNUMX fois
- Big
- Big Data
- tous les deux
- Rupture
- construire
- mais
- by
- appelé
- Appels
- CAN
- maisons
- cas
- catalogue
- les causes
- Change
- Modifications
- vérifier
- Selectionnez
- le cloud
- code
- COM
- combiner
- commentaire
- Commun
- Sociétés
- compatibilité
- compatible
- complet
- complexe
- composant
- composants électriques
- calcul
- configuration
- Confirmer
- Console
- consolider
- consolidation
- cuisine
- Core
- couvre
- engendrent
- créée
- crée des
- La création
- Courant
- Customiser
- des clients
- Clients
- JOUR
- données
- intégration de données
- informatique
- stratégie de données
- entrepôts de données
- Base de données
- bases de données
- ensembles de données
- Date
- Dates
- datetime
- jours
- décidé
- Réglage par défaut
- livré
- démontré
- Selon
- obsolète
- détaillé
- détails
- Développement
- différer
- différent
- numérique
- Médias numériques
- directement
- discuter
- distribué
- systèmes distribués
- do
- faire
- fait
- pendant
- e
- Plus tôt
- Facilite
- effet
- l'élimination
- d'autre
- permettre
- activé
- permet
- end-to-end
- participation
- ingénieur
- améliorations
- assurer
- Entrer
- Environment
- erreur
- Ether (ETH)
- événements
- exemple
- Sauf
- exception
- exister
- existant
- existe
- d'experience
- Expériences
- Exploré
- expression
- externe
- extrait
- Échoué
- non
- famille
- Fonctionnalité
- en vedette
- Fonctionnalités:
- Déposez votre dernière attestation
- Fichiers
- filtration
- finalement
- Trouvez
- de l'aptitude
- Abonnement
- nourriture
- Pour
- le format
- amis
- De
- plein
- recueillir
- générer
- en verre.
- Go
- golf
- gouvernance
- Réservation de groupe
- Hadoop
- Vous avez
- he
- Santé
- aider
- aide
- Histoire
- Ruche
- Comment
- How To
- HTML
- http
- HTTPS
- IAM
- ID
- idéal
- et idées cadeaux
- identifiant
- if
- illustre
- Mettre en oeuvre
- importer
- in
- en profondeur
- comprendre
- Y compris
- Améliore
- increased
- indiqué
- secteurs
- info
- d'information
- initiale
- technologie innovante
- idées.
- installer
- instance
- Des instructions
- des services
- l'intégration
- intérêt
- interne
- développement
- IT
- Emploi
- Emplois
- jpg
- json
- ACTIVITES
- connu
- gros
- plus tard
- Nouveautés
- APPRENTISSAGE
- apprentissage
- Bibliothèque
- LIMIT
- Liste
- charge
- locales
- localement
- emplacement
- enregistrer
- Connecté
- enregistrement
- recherchez-
- click
- machine learning
- LES PLANTES
- maintenir
- a prendre une
- Fabrication
- gérés
- gestion
- les gérer
- Manuel
- Matériel
- Mai..
- Médias
- Découvrez
- message
- Métrique
- migrer
- minimal
- ML
- modifié
- module
- Surveiller
- Stack monitoring
- PLUS
- must
- prénom
- noms
- NAVIGUER
- Navigation
- nécessaire
- Besoin
- nécessaire
- Besoins
- Nouveauté
- rien
- maintenant
- of
- offrant
- on
- ONE
- et, finalement,
- uniquement
- ouvert
- open source
- code open-source
- opérateur
- opérateurs
- optimaux
- Option
- Options
- or
- orchestrée
- orchestration
- Autre
- nos
- les résultats
- sortie
- au contrôle
- paquet
- pandas
- pain
- paramètres
- les partenaires
- pass
- passé
- passionné
- performant
- autorisations
- persiste
- pipeline
- Place
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- des notes bonus
- politique
- Post
- l'éventualité
- pratique
- conditions préalables
- précédent
- précédemment
- processus
- les process
- traitement
- Produits
- professionels
- ,une équipe de professionnels qualifiés
- Profils
- Projection
- de voiture.
- fournisseurs
- fournit
- Python
- qualité
- requêtes
- augmenter
- gamme
- Lire
- en cours
- réal
- en temps réel
- récent
- recommander
- région
- régulateurs
- Relais
- remplacer
- remplacé
- conditions
- Exigences
- ressource
- Resources
- respectivement
- réponse
- Résultats
- conserver
- bon
- Rôle
- RANGÉE
- Courir
- pour le running
- s
- Épargnez
- scénarios
- Sdk
- de façon transparente
- Rechercher
- Section
- sécurisé
- sur le lien
- Chercher
- supérieur
- Sans serveur
- Services
- mise
- installation
- coquillage
- devrait
- montrer
- Spectacles
- étapes
- simplifier
- depuis
- unique
- Instantané
- sur mesure
- Solutions
- quelques
- groupe de neurones
- spécifié
- Dépenses
- Déclaration
- Statut
- étapes
- Étapes
- Encore
- storage
- stockée
- de Marketing
- courant
- Chaîne
- réussi
- tel
- suffisant
- Support
- Appareils
- Système
- table
- Prenez
- prise
- Tâche
- équipes
- Les technologies
- modèle
- à
- qui
- La
- leur
- Les
- puis
- Là.
- Ces
- l'ont
- des tiers.
- this
- Avec
- fiable
- à
- suivre
- Transformer
- Voyages
- oui
- Essai
- Mardi
- Tourné
- deux
- type
- ui
- unifiée
- unité
- Mises à jour
- Actualités
- la mise à jour
- améliorer
- mis à jour
- Téléchargement
- Utilisation
- utilisé
- cas d'utilisation
- d'utiliser
- utilisateurs
- en utilisant
- Plus-value
- Valeurs
- version
- via
- Voir
- vues
- définition
- visible
- marcha
- souhaitez
- était
- we
- web
- services Web
- WELL
- Quoi
- quand
- que
- qui
- WHO
- sera
- comprenant
- dans les
- sans
- activités principales
- workflows
- pourra
- écrire
- code écrit
- you
- Votre
- zéphyrnet