De nombreuses organisations, petites et grandes, s'efforcent de migrer et de moderniser leurs charges de travail d'analyse sur Amazon Web Services (AWS). Il existe de nombreuses raisons pour lesquelles les clients migrent vers AWS, mais l'une des principales raisons est la possibilité d'utiliser des services entièrement gérés plutôt que de consacrer du temps à la maintenance de l'infrastructure, aux correctifs, à la surveillance, aux sauvegardes, etc. Les équipes de direction et de développement peuvent consacrer plus de temps à optimiser les solutions actuelles et même à expérimenter de nouveaux cas d'utilisation, plutôt qu'à maintenir l'infrastructure actuelle.
Avec la possibilité d'évoluer rapidement sur AWS, vous devez également être responsable des données que vous recevez et traitez à mesure que vous continuez à évoluer. Ces responsabilités incluent le respect des lois et réglementations sur la confidentialité des données et le fait de ne pas stocker ou exposer des données sensibles telles que des informations personnellement identifiables (PII) ou des informations de santé protégées (PHI) provenant de sources en amont.
Dans cet article, nous passons en revue une architecture de haut niveau et un cas d'utilisation spécifique qui démontrent comment vous pouvez continuer à faire évoluer la plate-forme de données de votre organisation sans avoir à consacrer beaucoup de temps de développement pour répondre aux problèmes de confidentialité des données. Nous utilisons Colle AWS pour détecter, masquer et supprimer les données PII avant de les charger dans Service Amazon OpenSearch.
Vue d'ensemble de la solution
Le diagramme suivant illustre l'architecture de la solution de haut niveau. Nous avons défini toutes les couches et composants de notre conception conformément aux Lentille d'analyse de données AWS Well-Architected Framework.
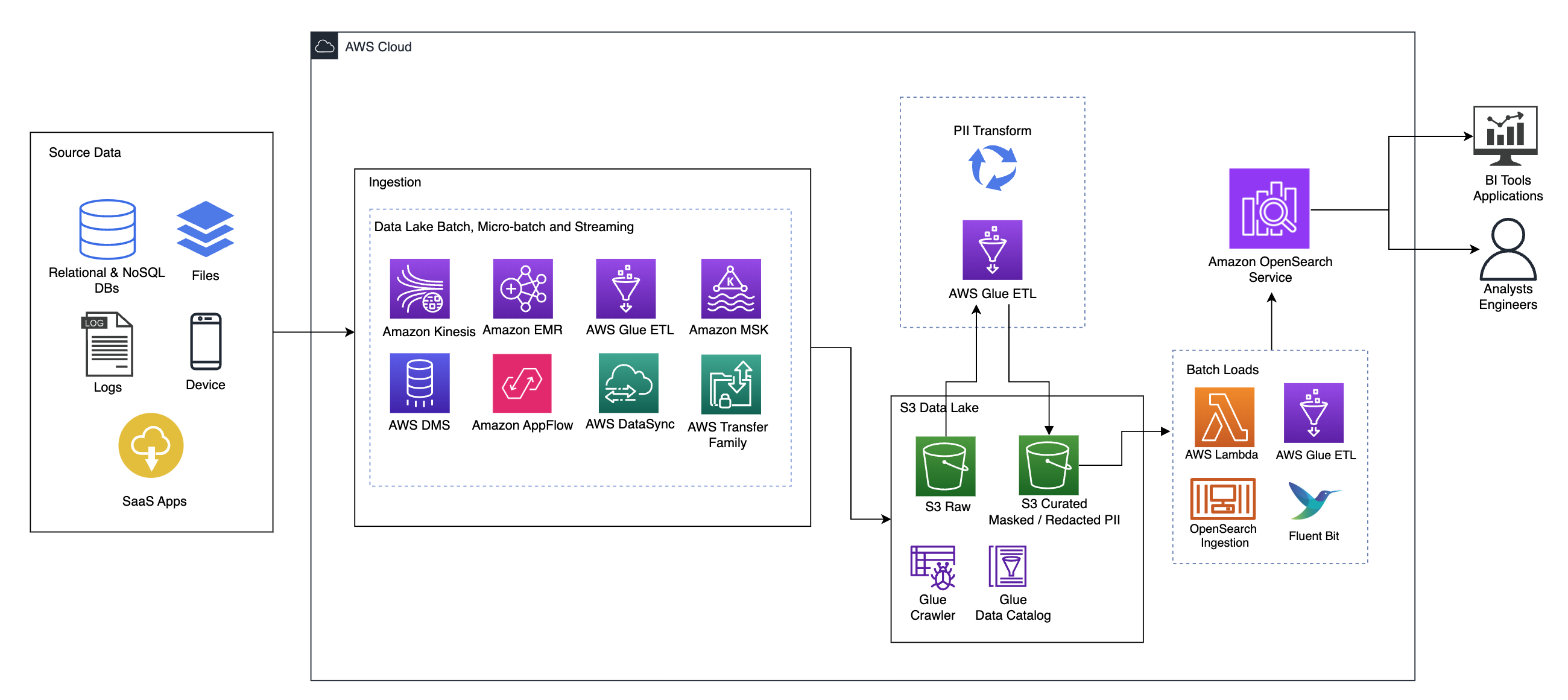
L'architecture est composée de plusieurs composants :
Source de données
Les données peuvent provenir de plusieurs dizaines, voire centaines de sources, notamment des bases de données, des transferts de fichiers, des journaux, des applications SaaS (Software as a Service), etc. Les organisations n’ont pas toujours le contrôle sur les données qui transitent par ces canaux et dans leurs applications et stockages en aval.
Ingestion : Data Lake batch, micro-batch et streaming
De nombreuses organisations transfèrent leurs données sources dans leur lac de données de diverses manières, notamment par des tâches par lots, par micro-lots et par streaming. Par exemple, Amazon DME, Colle AWSet la Service de migration de base de données AWS (AWS DMS) peuvent tous être utilisés pour effectuer des opérations par lots et/ou en streaming qui sont transférées vers un lac de données sur Service de stockage simple Amazon (Amazon S3). Flux d'application Amazon peut être utilisé pour transférer des données de différentes applications SaaS vers un lac de données. Synchronisation de données AWS ainsi que les Famille de transfert AWS peut aider à déplacer des fichiers vers et depuis un lac de données via un certain nombre de protocoles différents. Amazon Kinésis et Amazon MSK ont également la capacité de diffuser des données directement vers un lac de données sur Amazon S3.
Lac de données S3
L'utilisation d'Amazon S3 pour votre lac de données est conforme à la stratégie de données moderne. Il fournit un stockage à faible coût sans sacrifier les performances, la fiabilité ou la disponibilité. Avec cette approche, vous pouvez apporter le calcul à vos données selon vos besoins et ne payer que pour la capacité dont elles ont besoin pour fonctionner.
Dans cette architecture, les données brutes peuvent provenir de diverses sources (internes et externes), pouvant contenir des données sensibles.
À l'aide des robots d'exploration AWS Glue, nous pouvons découvrir et cataloguer les données, ce qui permettra de créer les schémas de table pour nous et, en fin de compte, de simplifier l'utilisation d'AWS Glue ETL avec la transformation PII pour détecter et masquer ou supprimer toutes les données sensibles qui pourraient avoir atterri. dans le lac de données.
Contexte commercial et ensembles de données
Pour démontrer la valeur de notre approche, imaginons que vous faites partie d’une équipe d’ingénierie de données pour une organisation de services financiers. Vos exigences sont de détecter et de masquer les données sensibles lorsqu’elles sont ingérées dans l’environnement cloud de votre organisation. Les données seront consommées par les processus analytiques en aval. À l’avenir, vos utilisateurs pourront rechercher en toute sécurité l’historique des transactions de paiement sur la base des flux de données collectés auprès des systèmes bancaires internes. Les résultats de recherche des équipes opérationnelles, des clients et des applications d'interface doivent être masqués dans des champs sensibles.
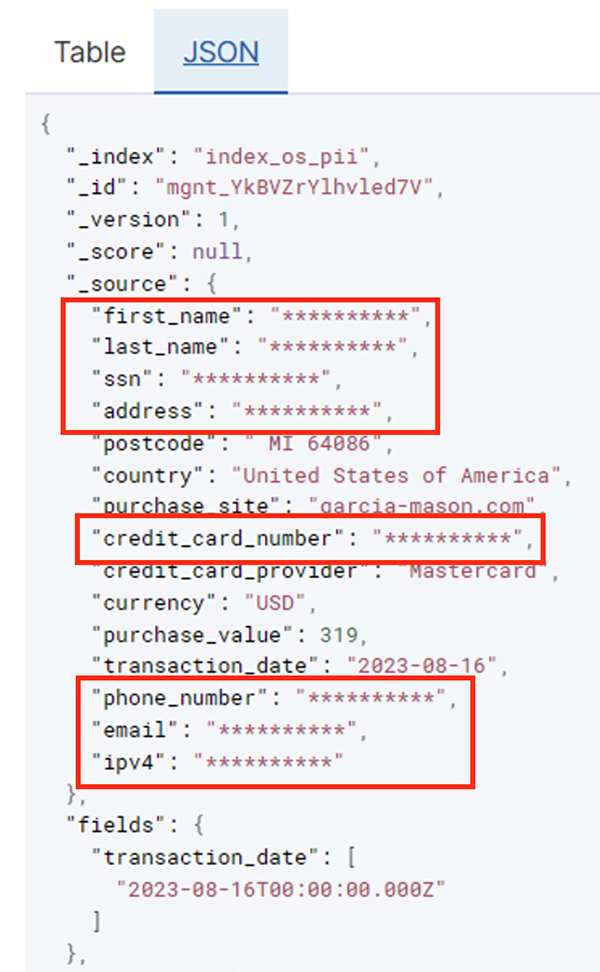
Le tableau suivant montre la structure de données utilisée pour la solution. Pour plus de clarté, nous avons mappé les noms de colonnes bruts aux noms de colonnes organisés. Vous remarquerez que plusieurs champs de ce schéma sont considérés comme des données sensibles, telles que le prénom, le nom, le numéro de sécurité sociale (SSN), l'adresse, le numéro de carte de crédit, le numéro de téléphone, l'e-mail et l'adresse IPv4.
| Nom de colonne brut | Nom de la colonne organisée | Type |
| c0 | Prénom | un magnifique |
| c1 | nom de famille | un magnifique |
| c2 | ssn | un magnifique |
| c3 | propos | un magnifique |
| c4 | code postal | un magnifique |
| c5 | Pays | un magnifique |
| c6 | site_achat | un magnifique |
| c7 | Numéro de Carte de Crédit | un magnifique |
| c8 | credit_card_provider | un magnifique |
| c9 | monnaie | un magnifique |
| c10 | valeur d'achat | entier |
| c11 | Date de la transaction | données |
| c12 | numéro de téléphone | un magnifique |
| c13 | un magnifique | |
| c14 | ipv4 | un magnifique |
Cas d'utilisation : Détection par lots de PII avant le chargement sur OpenSearch Service
Les clients qui mettent en œuvre l'architecture suivante ont construit leur lac de données sur Amazon S3 pour exécuter différents types d'analyses à grande échelle. Cette solution convient aux clients qui n'ont pas besoin d'une ingestion en temps réel d'OpenSearch Service et qui prévoient d'utiliser des outils d'intégration de données qui s'exécutent selon un calendrier ou sont déclenchés par des événements.
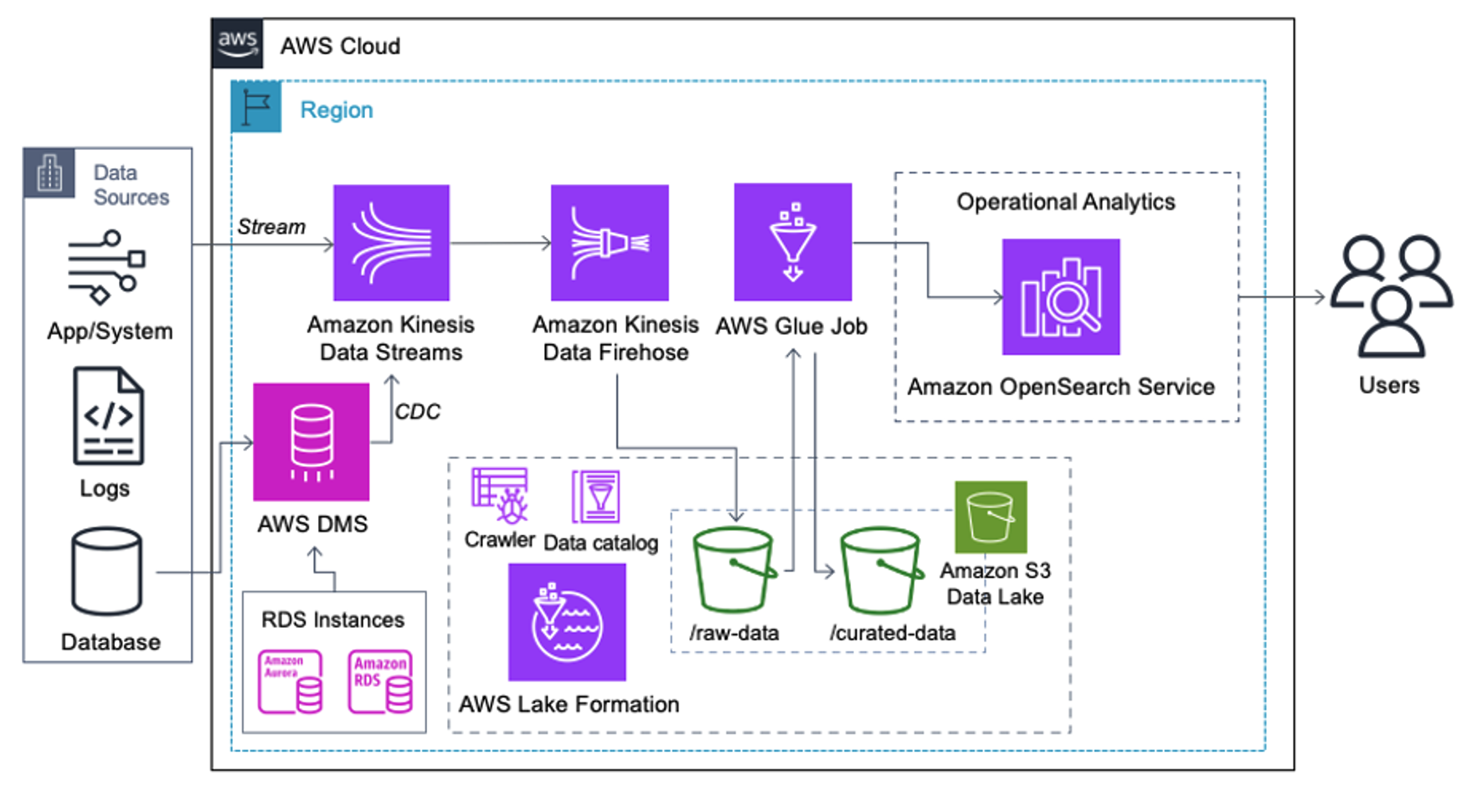
Avant que les enregistrements de données n'arrivent sur Amazon S3, nous implémentons une couche d'ingestion pour amener tous les flux de données de manière fiable et sécurisée vers le lac de données. Kinesis Data Streams est déployé en tant que couche d'ingestion pour accélérer l'acquisition de flux de données structurés et semi-structurés. Des exemples en sont les modifications de bases de données relationnelles, les applications, les journaux système ou les flux de clics. Pour les cas d'utilisation de la capture de données modifiées (CDC), vous pouvez utiliser Kinesis Data Streams comme cible pour AWS DMS. Les applications ou systèmes générant des flux contenant des données sensibles sont envoyés au flux de données Kinesis via l'une des trois méthodes prises en charge : l'agent Amazon Kinesis, le kit AWS SDK pour Java ou la bibliothèque Kinesis Producer. Comme dernière étape, Firehose de données Amazon Kinesis nous aide à charger de manière fiable des lots de données en temps quasi réel dans notre destination de lac de données S3.
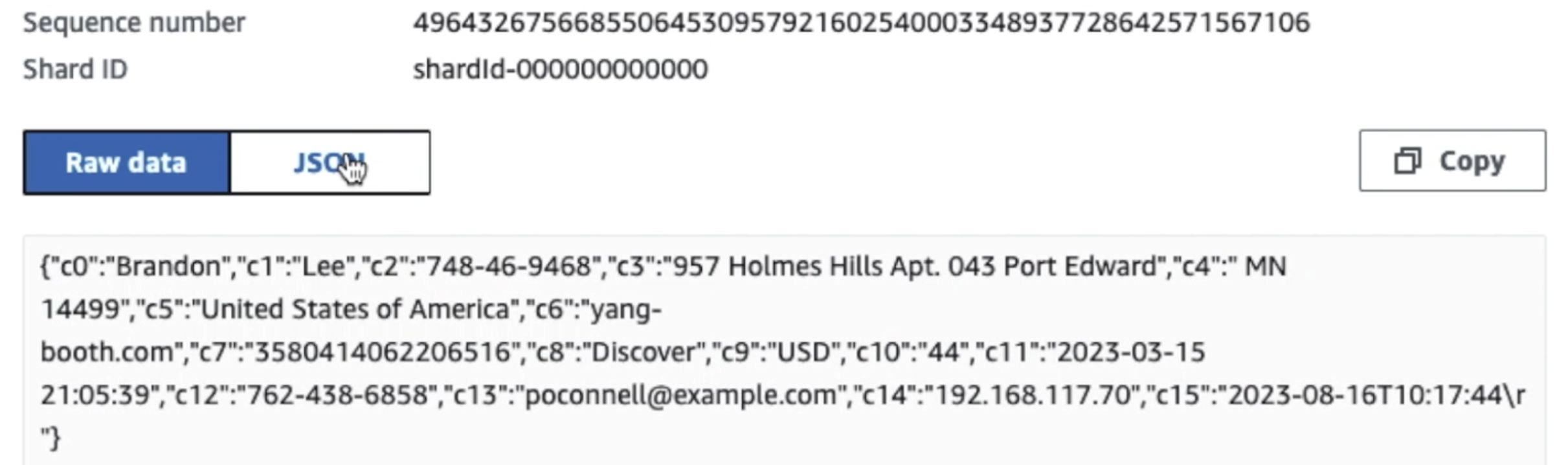
La capture d'écran suivante montre comment les données circulent via Kinesis Data Streams via le Visionneuse de données et récupère des exemples de données qui atterrissent sur le préfixe S3 brut. Pour cette architecture, nous avons suivi le cycle de vie des données pour les préfixes S3 comme recommandé dans Fondation du lac de données.
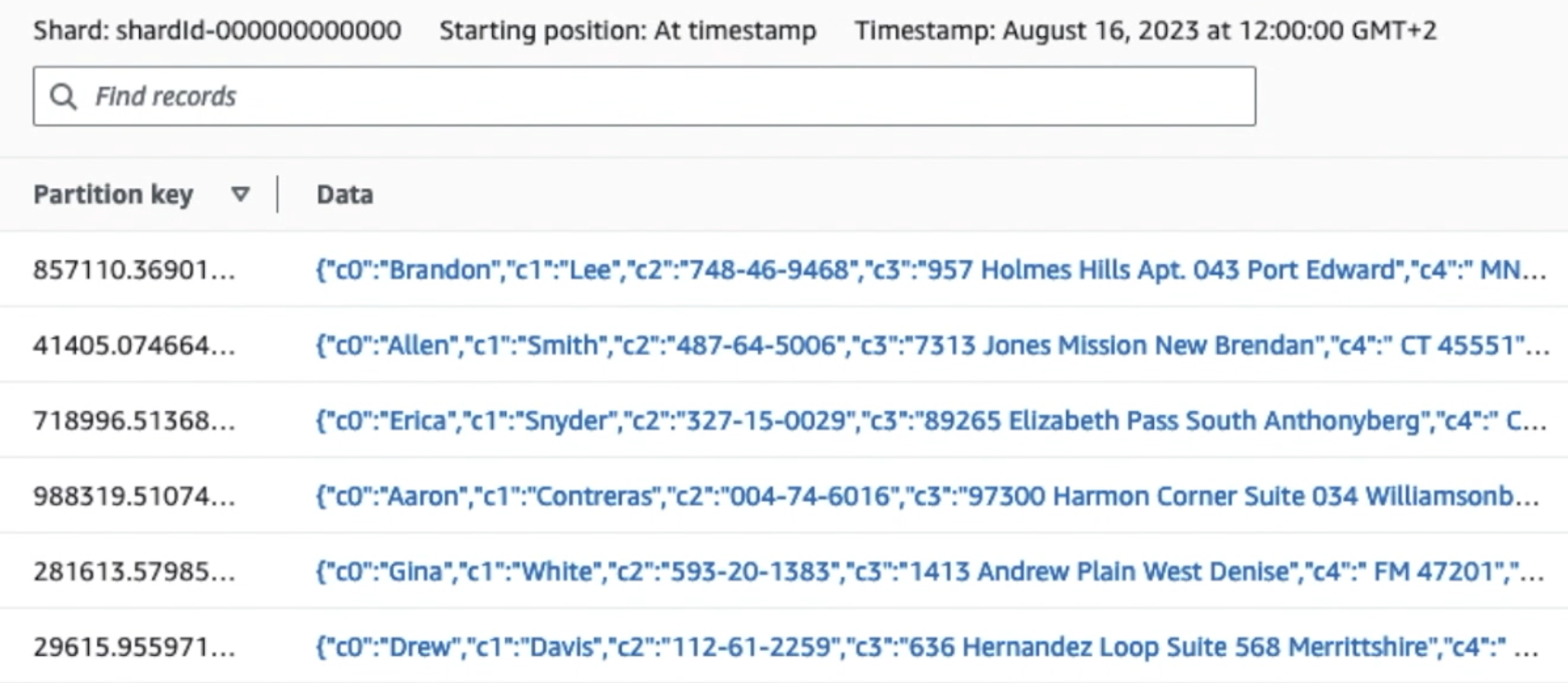
Comme vous pouvez le voir à partir des détails du premier enregistrement dans la capture d'écran suivante, la charge utile JSON suit le même schéma que dans la section précédente. Vous pouvez voir les données non expurgées circuler dans le flux de données Kinesis, qui seront masquées ultérieurement au cours des étapes suivantes.
Une fois les données collectées et ingérées dans Kinesis Data Streams et transmises au compartiment S3 à l'aide de Kinesis Data Firehose, la couche de traitement de l'architecture prend le relais. Nous utilisons la transformation AWS Glue PII pour automatiser la détection et le masquage des données sensibles dans notre pipeline. Comme le montre le diagramme de flux de travail suivant, nous avons adopté une approche ETL visuelle sans code pour mettre en œuvre notre tâche de transformation dans AWS Glue Studio.
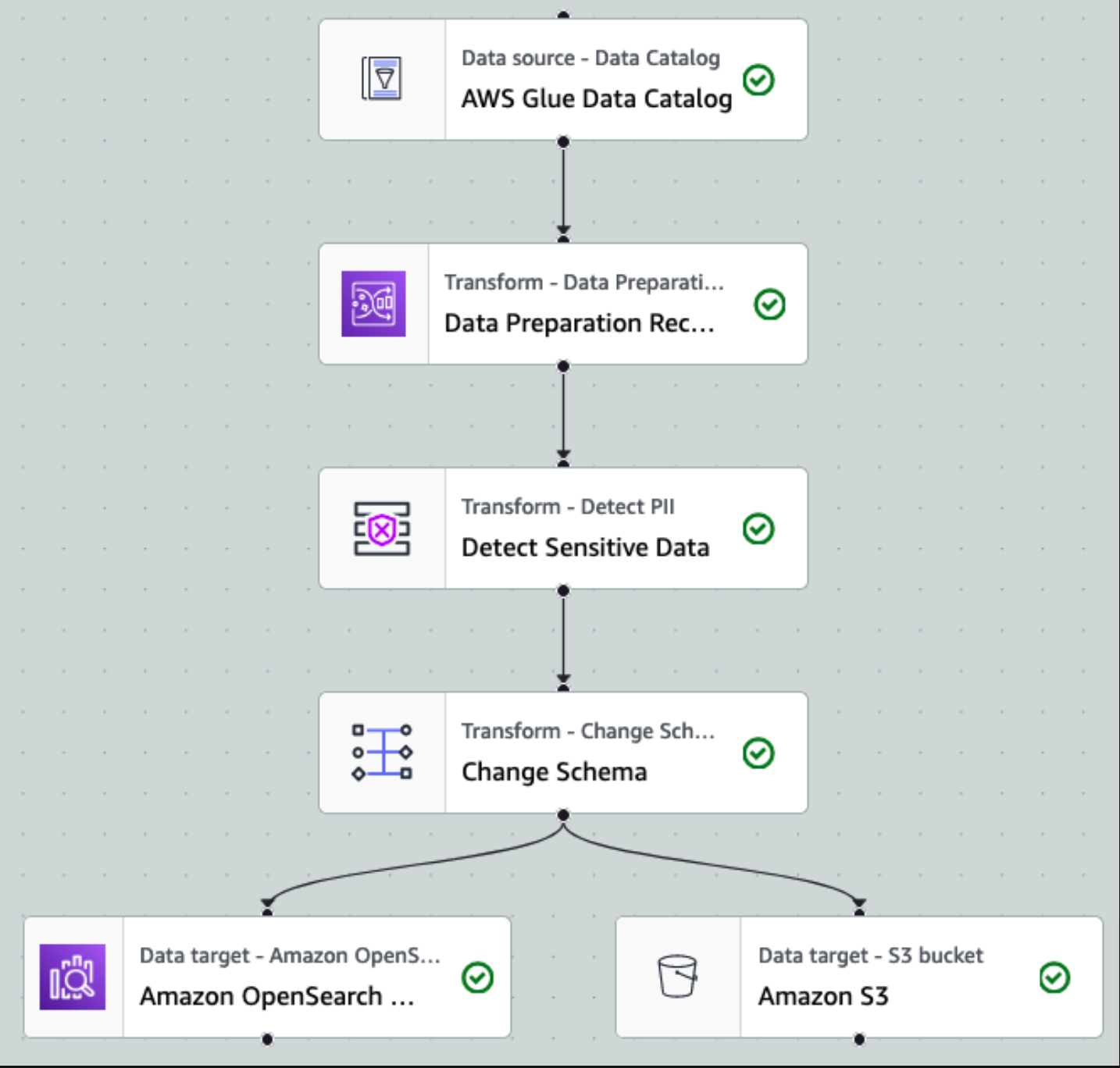
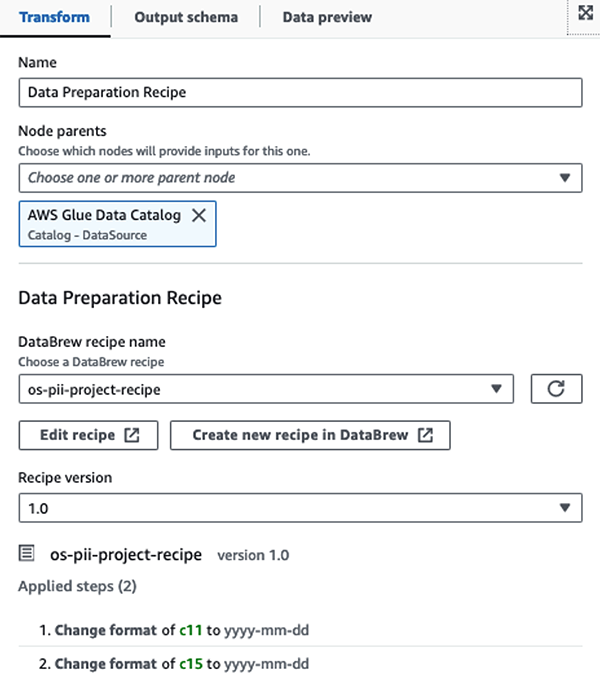
Tout d’abord, nous accédons à la table source du catalogue de données brute à partir du pii_data_db base de données. Le tableau présente la structure du schéma présentée dans la section précédente. Pour garder une trace des données brutes traitées, nous avons utilisé signets de travail.

Nous utilisons les Recettes AWS Glue DataBrew dans la tâche ETL visuelle AWS Glue Studio transformer deux attributs de date pour être compatible avec OpenSearch attendu formats. Cela nous permet d’avoir une expérience complète sans code.
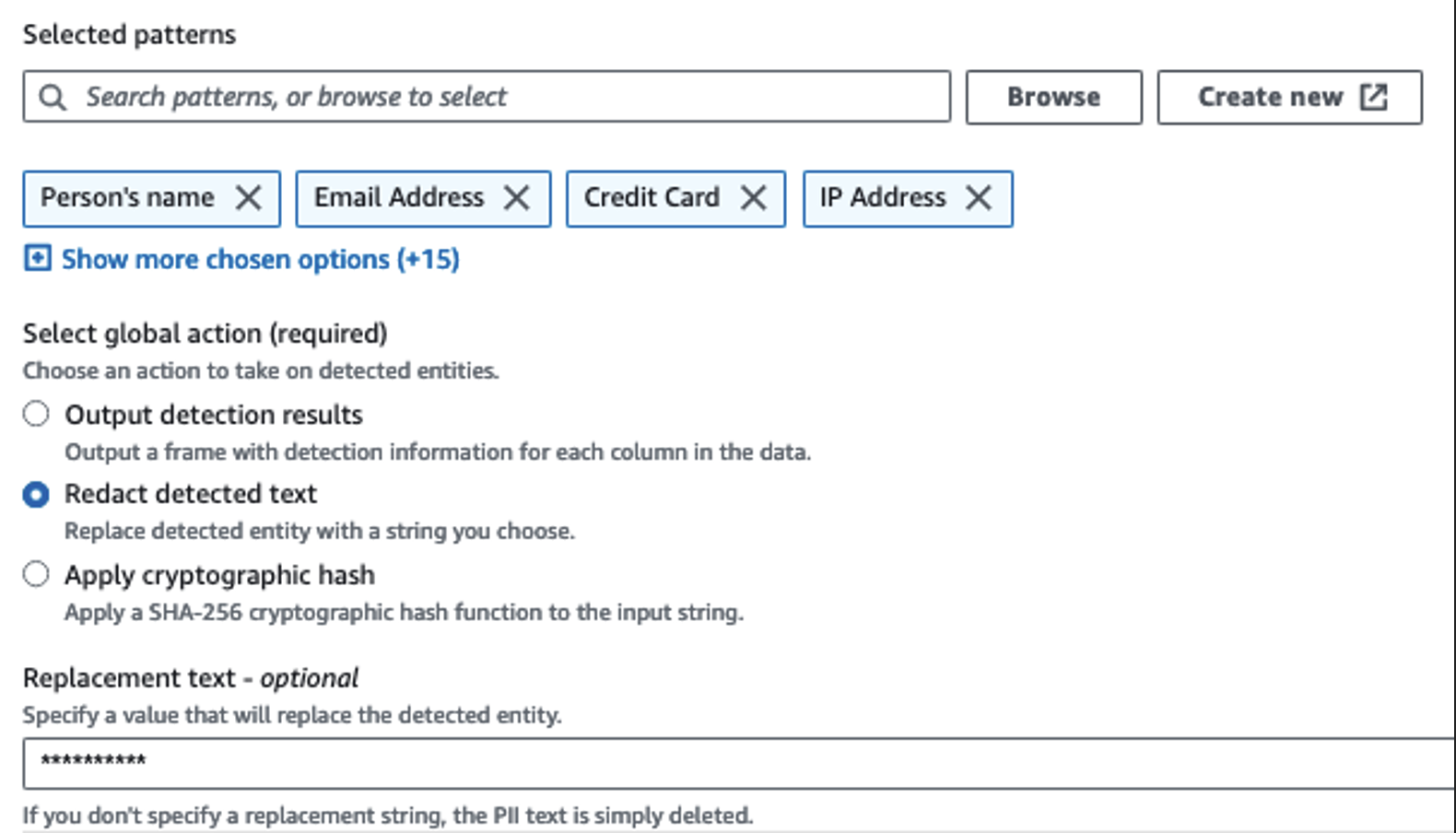
Nous utilisons l'action Détecter les informations personnelles pour identifier les colonnes sensibles. Nous laissons AWS Glue déterminer cela en fonction des modèles sélectionnés, du seuil de détection et d'un échantillon de lignes de l'ensemble de données. Dans notre exemple, nous avons utilisé des modèles qui s'appliquent spécifiquement aux États-Unis (tels que les SSN) et peuvent ne pas détecter les données sensibles provenant d'autres pays. Vous pouvez rechercher les catégories et emplacements disponibles applicables à votre cas d'utilisation ou utiliser des expressions régulières (regex) dans AWS Glue pour créer des entités de détection pour les données sensibles provenant d'autres pays.
Il est important de sélectionner la bonne méthode d'échantillonnage proposée par AWS Glue. Dans cet exemple, on sait que les données provenant du flux contiennent des données sensibles dans chaque ligne, il n'est donc pas nécessaire d'échantillonner 100 % des lignes de l'ensemble de données. Si vous avez une exigence selon laquelle aucune donnée sensible n'est autorisée vers les sources en aval, envisagez d'échantillonner 100 % des données pour les modèles que vous avez choisis, ou analysez l'intégralité de l'ensemble de données et agissez sur chaque cellule individuelle pour vous assurer que toutes les données sensibles sont détectées. L’avantage que vous tirez de l’échantillonnage est une réduction des coûts car vous n’avez pas besoin d’analyser autant de données.

L'action Détecter les informations personnelles vous permet de sélectionner une chaîne par défaut lors du masquage des données sensibles. Dans notre exemple, nous utilisons la chaîne **********.
Nous utilisons l'opération de mappage d'application pour renommer et supprimer les colonnes inutiles telles que ingestion_year, ingestion_monthet la
ingestion_day. Cette étape nous permet également de changer le type de données d'une des colonnes (purchase_value) de la chaîne à l'entier.

À partir de ce moment, la tâche est divisée en deux destinations de sortie : OpenSearch Service et Amazon S3.
Notre cluster OpenSearch Service provisionné est connecté via le Connecteur intégré OpenSearch pour Glue. Nous spécifions l'index OpenSearch dans lequel nous souhaitons écrire et le connecteur gère les informations d'identification, le domaine et le port. Dans la capture d'écran ci-dessous, nous écrivons dans l'index spécifié index_os_pii.
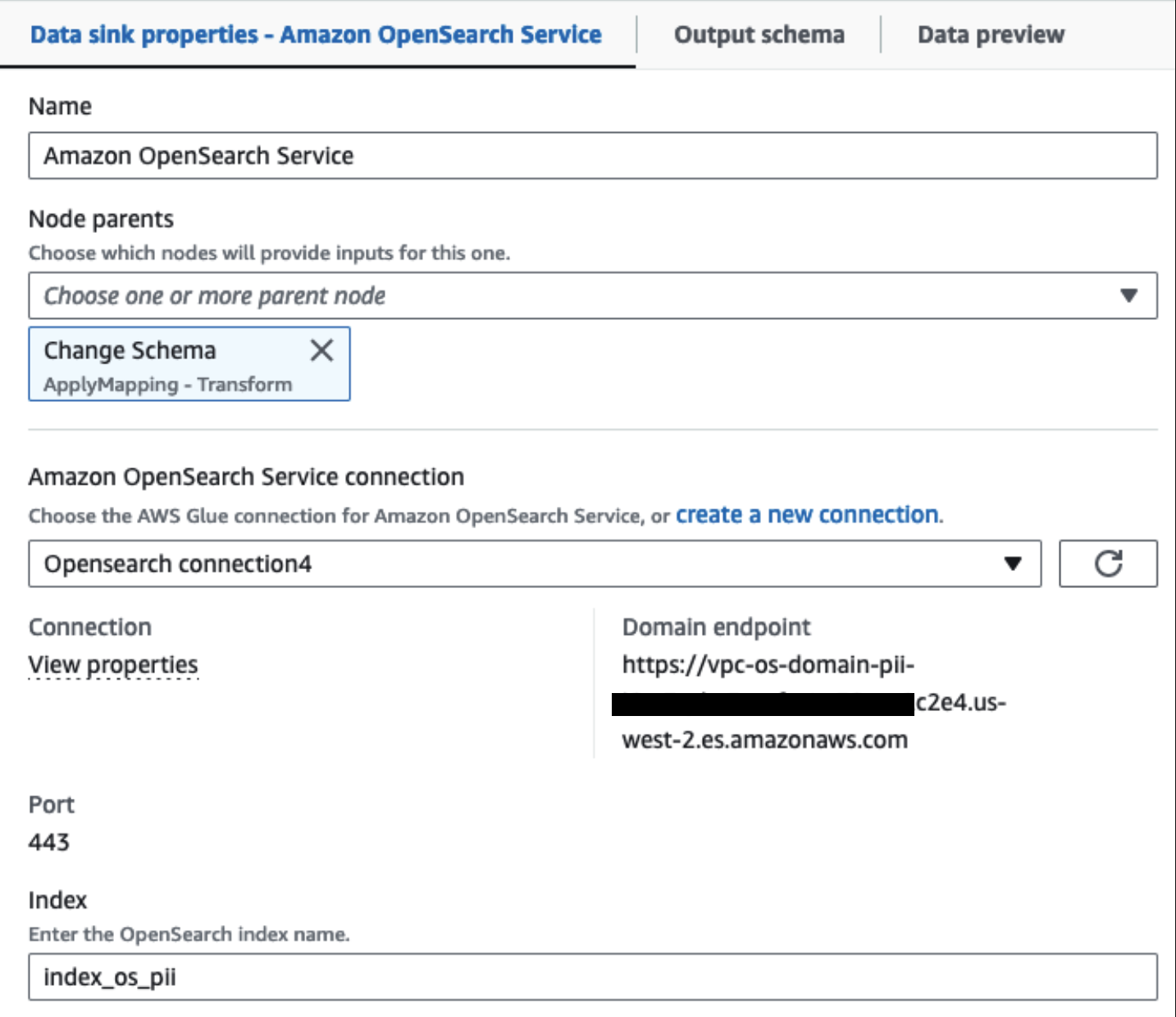
Nous stockons l'ensemble de données masqué dans le préfixe S3 organisé. Nous y disposons de données normalisées en fonction d'un cas d'utilisation spécifique et d'une consommation sûre par des data scientists ou pour des besoins de reporting ponctuels.
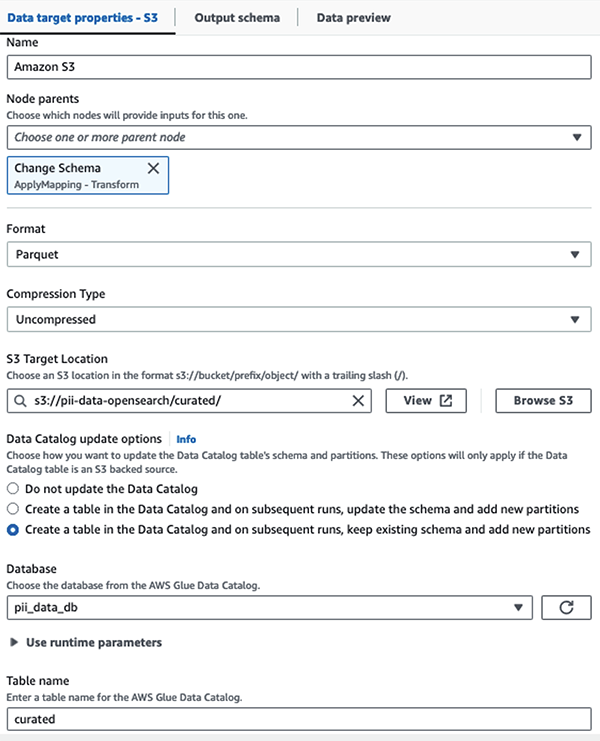
Pour une gouvernance unifiée, un contrôle d'accès et des pistes d'audit de tous les ensembles de données et tables Data Catalog, vous pouvez utiliser Formation AWS Lake. Cela vous aide à restreindre l'accès aux tables AWS Glue Data Catalog et aux données sous-jacentes aux seuls utilisateurs et rôles disposant des autorisations nécessaires pour ce faire.
Une fois le travail par lots exécuté avec succès, vous pouvez utiliser OpenSearch Service pour exécuter des requêtes de recherche ou des rapports. Comme le montre la capture d'écran suivante, le pipeline a masqué automatiquement les champs sensibles sans aucun effort de développement de code.

Vous pouvez identifier des tendances à partir des données opérationnelles, telles que le nombre de transactions par jour filtrées par fournisseur de carte de crédit, comme indiqué dans la capture d'écran précédente. Vous pouvez également déterminer les emplacements et les domaines sur lesquels les utilisateurs effectuent des achats. Le transaction_date L'attribut nous aide à voir ces tendances au fil du temps. La capture d'écran suivante montre un enregistrement avec toutes les informations de la transaction expurgées de manière appropriée.
Pour d'autres méthodes sur la façon de charger des données dans Amazon OpenSearch, reportez-vous à Chargement de données en streaming dans Amazon OpenSearch Service.
De plus, les données sensibles peuvent également être découvertes et masquées à l'aide d'autres solutions AWS. Par exemple, vous pourriez utiliser Amazone Macie pour détecter les données sensibles dans un compartiment S3, puis utiliser Amazon comprendre pour expurger les données sensibles détectées. Pour plus d'informations, reportez-vous à Techniques courantes pour détecter les données PHI et PII à l'aide des services AWS.
Conclusion
Cet article traite de l'importance de gérer les données sensibles au sein de votre environnement et des diverses méthodes et architectures pour rester conforme tout en permettant à votre organisation d'évoluer rapidement. Vous devriez maintenant bien comprendre comment détecter, masquer ou expurger et charger vos données dans Amazon OpenSearch Service.
À propos des auteurs
 Michael Hamilton est un architecte de solutions analytiques senior dont l'objectif est d'aider les entreprises clientes à moderniser et à simplifier leurs charges de travail d'analyse sur AWS. Il aime faire du VTT et passer du temps avec sa femme et ses trois enfants lorsqu'il ne travaille pas.
Michael Hamilton est un architecte de solutions analytiques senior dont l'objectif est d'aider les entreprises clientes à moderniser et à simplifier leurs charges de travail d'analyse sur AWS. Il aime faire du VTT et passer du temps avec sa femme et ses trois enfants lorsqu'il ne travaille pas.
 Daniel Rozo est un architecte de solutions senior chez AWS qui prend en charge les clients aux Pays-Bas. Sa passion est de concevoir des solutions simples de données et d'analyse et d'aider les clients à migrer vers des architectures de données modernes. En dehors du travail, il aime jouer au tennis et faire du vélo.
Daniel Rozo est un architecte de solutions senior chez AWS qui prend en charge les clients aux Pays-Bas. Sa passion est de concevoir des solutions simples de données et d'analyse et d'aider les clients à migrer vers des architectures de données modernes. En dehors du travail, il aime jouer au tennis et faire du vélo.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/
- :possède
- :est
- :ne pas
- :où
- 07
- 100
- 28
- 300
- 31
- 32
- 39
- 40
- 46
- 50
- 51
- 600
- 90
- 970
- a
- capacité
- Capable
- accéléré
- accès
- Agis
- Action
- Ad
- propos
- Agent
- Tous
- permis
- Permettre
- permet
- aussi
- toujours
- Amazon
- Amazon Kinésis
- Amazon Web Services
- Amazon Web Services (AWS)
- montant
- quantités
- an
- Analytique
- analytique
- ainsi que les
- tous
- en vigueur
- applications
- Appliquer
- une approche
- de manière appropriée
- architecture
- SONT
- AS
- At
- attributs
- audit
- automatiser
- automatiquement
- disponibilité
- disponibles
- AWS
- Colle AWS
- sauvegardes
- Services bancaires
- Systèmes bancaires
- basé
- BE
- car
- était
- before
- va
- ci-dessous
- profiter
- apporter
- construire
- construit
- intégré
- mais
- by
- CAN
- capacités
- Compétences
- capturer
- carte
- maisons
- cas
- catalogue
- catégories
- CDC
- cellule
- Change
- Modifications
- Voies
- Enfants
- choisir
- clarté
- le cloud
- Grappe
- code
- Colonne
- Colonnes
- comment
- vient
- Venir
- compatible
- composants électriques
- Composé
- calcul
- Préoccupations
- connecté
- Considérer
- considéré
- consommées
- consommation
- contiennent
- contexte
- continuer
- des bactéries
- correct
- Costs
- pourriez
- d'exportation
- engendrent
- Lettres de créance
- crédit
- carte de crédit
- organisée
- Courant
- Clients
- données
- Analyse de Donnée
- intégration de données
- Lac de données
- Plateforme de données
- confidentialité des données
- stratégie de données
- Base de données
- bases de données
- ensembles de données
- Date
- journée
- Réglage par défaut
- défini
- livré
- démontrer
- démontre
- déployé
- Conception
- destination
- destinations
- détails
- détecter
- détecté
- Détection
- Déterminer
- Développement
- équipes de développement
- différent
- directement
- découvrez
- découvert
- discuté
- do
- domaine
- domaines
- Ne pas
- chacun
- efforts
- ENGINEERING
- assurer
- Entreprise
- clients entreprise
- Tout
- entités
- Environment
- Ether (ETH)
- Pourtant, la
- événements
- Chaque
- exemple
- exemples
- attendu
- d'experience
- expressions
- externe
- RAPIDE
- Des champs
- Déposez votre dernière attestation
- Fichiers
- la traduction de documents financiers
- services financiers
- Prénom
- Écoulement
- Flux
- mettant l'accent
- suivi
- Abonnement
- suit
- Pour
- Framework
- de
- plein
- d’étiquettes électroniques entièrement
- avenir
- générateur
- obtenez
- Bien
- gouvernance
- accordée
- Poignées
- Maniabilité
- Vous avez
- he
- Santé
- information sur la santé
- vous aider
- aider
- aide
- de haut niveau
- sa
- historique
- Comment
- How To
- HTML
- http
- HTTPS
- Des centaines
- identifier
- if
- illustre
- image
- Mettre en oeuvre
- importance
- important
- in
- comprendre
- Y compris
- indice
- individuel
- d'information
- Infrastructure
- à l'intérieur
- l'intégration
- interne
- développement
- IT
- Java
- Emploi
- Emplois
- jpg
- json
- XNUMX éléments à
- Firehose de données Kinesis
- Flux de données Kinesis
- connu
- lac
- Transport routier
- terres
- gros
- Nom de famille
- plus tard
- Lois
- Lois et règlements
- couche
- poules pondeuses
- Leadership
- laisser
- Bibliothèque
- vos produits
- comme
- Gamme
- charge
- chargement
- emplacements
- Style
- low cost
- Entrée
- le maintien
- a prendre une
- gérés
- de nombreuses
- cartographie
- masque
- Mai..
- méthode
- méthodes
- émigrer
- migration
- Villas Modernes
- moderniser
- Stack monitoring
- PLUS
- Montagne
- Bougez
- en mouvement
- beaucoup
- plusieurs
- must
- prénom
- noms
- nécessaire
- Besoin
- nécessaire
- besoin
- Besoins
- Netherlands
- Nouveauté
- aucune
- nœuds
- Remarquer..
- maintenant
- nombre
- of
- Offres Speciales
- on
- ONE
- uniquement
- opération
- opérationnel
- Opérations
- l'optimisation
- Options
- or
- organisation
- organisations
- Autre
- nos
- sortie
- au contrôle
- plus de
- partie
- passion
- patcher
- motifs
- Payer
- Paiement
- /
- effectuer
- performant
- autorisations
- Personnellement
- Téléphone
- pii
- pipeline
- plan
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- jouer
- Point
- partieInvestir dans des appareils économes en énergie et passer à l'éclairage
- Post
- précédant
- présenté
- précédent
- la confidentialité
- lois sur la vie privée
- traité
- les process
- traitement
- producteur
- protégé
- protocoles
- de voiture.
- fournit
- achats
- requêtes
- vite.
- plutôt
- raw
- les données brutes
- en temps réel
- Les raisons
- recevoir
- Recettes
- recommandé
- record
- Articles
- Prix Réduit
- reportez-vous
- Standard
- règlements
- fiabilité
- rester
- supprimez
- Rapports
- Rapports
- exigent
- exigence
- Exigences
- responsabilités
- responsables
- restreindre
- Résultats
- rôle
- RANGÉE
- Courir
- fonctionne
- SaaS.
- sacrifier
- des
- en toute sécurité
- même
- Escaliers intérieurs
- balayage
- calendrier
- scientifiques
- pour écran
- Sdk
- Rechercher
- Section
- en toute sécurité
- sécurité
- sur le lien
- Sélectionner
- choisi
- supérieur
- sensible
- envoyé
- service
- Services
- coup
- devrait
- montré
- Spectacles
- étapes
- simplifier
- petit
- So
- Réseaux sociaux
- Logiciels
- logiciel en tant que service
- sur mesure
- Solutions
- Identifier
- Sources
- groupe de neurones
- spécifiquement
- spécifié
- passer
- Dépenses
- splits
- étapes
- États
- étapes
- storage
- Boutique
- simple
- de Marketing
- courant
- streaming
- flux
- Chaîne
- structure
- structuré
- studio
- ultérieur
- Avec succès
- tel
- convient
- Appareils
- Appuyer
- combustion propre
- Système
- table
- prend
- Target
- équipe
- équipes
- techniques
- tennis
- dizaines
- que
- qui
- Les
- El futuro
- Pays-Bas
- La Source
- leur
- puis
- Là.
- Ces
- this
- ceux
- trois
- порог
- Avec
- fiable
- à
- a
- les outils
- suivre
- Transactions
- transférer
- transferts
- Transformer
- De La Carrosserie
- Trends
- déclenché
- deux
- type
- types
- En fin de compte
- sous-jacent
- compréhension
- unifiée
- Uni
- États-Unis
- us
- utilisé
- cas d'utilisation
- d'utiliser
- utilisateurs
- en utilisant
- Plus-value
- variété
- divers
- via
- visuel
- marcher
- était
- façons
- we
- web
- services Web
- Quoi
- quand
- qui
- tout en
- WHO
- femme
- sera
- comprenant
- dans les
- sans
- activités principales
- workflow
- de travail
- écrire
- you
- Votre
- zéphyrnet