Les organisations du monde entier, qu'elles soient à but lucratif ou non, cherchent à tirer parti de l'analyse des données pour améliorer leurs performances commerciales. Les conclusions d'un Enquête McKinsey indiquent que les organisations basées sur les données ont 23 fois plus de chances d'acquérir des clients, six fois plus de chances de les fidéliser et 19 fois plus rentables [1]. Recherche du MIT ont constaté que les entreprises matures sur le plan numérique sont 26 % plus rentables que leurs pairs [2]. Mais de nombreuses entreprises, bien que riches en données, ont du mal à mettre en œuvre des analyses de données en raison de priorités contradictoires entre les besoins commerciaux, les capacités disponibles et les ressources. Recherche de Gartner ont constaté que plus de 85 % des projets de données et d'analyse échouent [3] et un rapport conjoint d'IBM et Carnegie Melon montre que 90 % des données d'une organisation ne sont jamais utilisées avec succès à des fins stratégiques [4].
Dans ce contexte, nous introduisons le concept de « structure d'analyse de données (DAF) », en tant qu'écosystème ou structure qui permet à l'analyse de données de fonctionner efficacement en fonction de (a) les besoins ou objectifs de l'entreprise, (b) les capacités disponibles telles que les personnes/compétences. , les processus, la culture, les technologies, les connaissances, les compétences décisionnelles, etc., et (c) les ressources (c'est-à-dire les composants dont une entreprise a besoin pour fonctionner).
Notre objectif principal en introduisant le tissu d'analyse des données est de répondre à cette question fondamentale : « Que faut-il pour construire efficacement un système décisionnel à partir de Sciences des données des algorithmes pour mesurer et améliorer les performances des entreprises ? Le tissu analytique des données et ses cinq manifestations clés sont présentés et discutés ci-dessous.
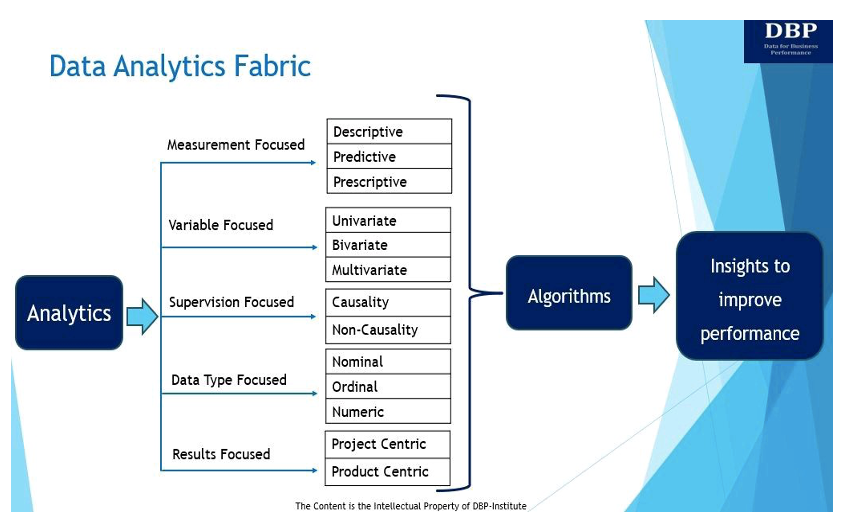
1. Axé sur la mesure
À la base, l’analyse consiste à utiliser des données pour obtenir des informations, mesurer et améliorer les performances de l’entreprise [5]. Il existe trois principaux types d'analyses pour mesurer et améliorer les performances de l'entreprise :
- Analyse descriptive pose la question : « Que s'est-il passé ? » L'analyse descriptive est utilisée pour analyser les données historiques afin d'identifier des modèles, des tendances et des relations à l'aide de techniques d'analyse de données exploratoires, associatives et inférentielles. Les techniques d’analyse exploratoire des données analysent et résument les ensembles de données. L'analyse descriptive associative explique la relation entre les variables. L'analyse descriptive inférentielle des données est utilisée pour déduire ou conclure des tendances concernant une population plus large sur la base de l'ensemble de données échantillon.
- Analyses prédictives cherche à répondre à la question « Que va-t-il se passer ? » Fondamentalement, l'analyse prédictive est le processus d'utilisation des données pour prévoir les tendances et les événements futurs. L'analyse prédictive peut être effectuée manuellement (communément appelée analyse prédictive pilotée par les analystes) ou à l'aide de algorithmes d'apprentissage automatique (également connue sous le nom d'analyse prédictive basée sur les données). Quoi qu’il en soit, les données historiques sont utilisées pour faire des prédictions futures.
- Analyse prescriptive aide à répondre à la question « Comment pouvons-nous y parvenir ? » Fondamentalement, l'analyse prescriptive recommande le meilleur plan d'action pour avancer en utilisant des techniques d'optimisation et de simulation. En règle générale, l'analyse prédictive et l'analyse prescriptive vont de pair, car l'analyse prédictive aide à trouver des résultats potentiels, tandis que l'analyse prescriptive examine ces résultats et trouve davantage d'options.
2. Axé sur les variables
Les données peuvent également être analysées en fonction du nombre de variables disponibles. À cet égard, en fonction du nombre de variables, les techniques d'analyse des données peuvent être univariées, bivariées ou multivariées.
- Analyse univariée: L'analyse univariée consiste à analyser le modèle présent dans une variable unique à l'aide de mesures de centralité (moyenne, médiane, mode, etc.) et de variation (écart type, erreur type, variance, etc.).
- Analyse bivariée : Il existe deux variables dans lesquelles l'analyse est liée à la cause et à la relation entre les deux variables. Ces deux variables peuvent être dépendantes ou indépendantes l'une de l'autre. La technique de corrélation est la technique d'analyse bivariée la plus utilisée.
- Analyse multivariée : Cette technique est utilisée pour analyser plus de deux variables. Dans un environnement multivarié, nous opérons généralement dans le domaine de l'analyse prédictive et la plupart des algorithmes d'apprentissage automatique (ML) bien connus tels que la régression linéaire, la régression logistique, les arbres de régression, les machines à vecteurs de support et les réseaux de neurones sont généralement appliqués à un environnement multivarié. paramètre.
3. Axé sur la supervision
Le troisième type de tissu d'analyse de données concerne la formation des données d'entrée ou des données de variables indépendantes qui ont été étiquetées pour une sortie particulière (c'est-à-dire la variable dépendante). Fondamentalement, la variable indépendante est celle contrôlée par l’expérimentateur. La variable dépendante est la variable qui change en réponse à la variable indépendante. Le DAF axé sur la supervision pourrait être de deux types.
- Causalité: Les données étiquetées, qu'elles soient générées automatiquement ou manuellement, sont essentielles à l'apprentissage supervisé. Les données étiquetées permettent de définir clairement une variable dépendante, puis il appartient à l'algorithme d'analyse prédictive de créer un outil d'IA/ML qui établirait une relation entre l'étiquette (variable dépendante) et l'ensemble de variables indépendantes. Du fait qu’il existe une démarcation nette entre la notion de variable dépendante et celle d’un ensemble de variables indépendantes, nous nous permettons d’introduire le terme de « causalité » pour mieux expliquer la relation.
- Non-causalité : Lorsque nous indiquons « axé sur la supervision » comme notre dimension, nous entendons également « l’absence de supervision », ce qui amène les modèles non causals à la discussion. Les modèles non causals méritent d’être mentionnés car ils ne nécessitent pas de données étiquetées. La technique de base ici est le clustering, et les méthodes les plus populaires sont les k-Means et le clustering hiérarchique.
4. Axé sur le type de données
Cette dimension ou manifestation du tissu d'analyse de données se concentre sur les trois différents types de variables de données liées aux variables indépendantes et dépendantes qui sont utilisées dans les techniques d'analyse de données pour obtenir des informations.
- Données nominales est utilisé pour étiqueter ou catégoriser les données. Il n'implique pas de valeur numérique et aucun calcul statistique n'est donc possible avec des données nominales. Des exemples de données nominales sont le sexe, la description du produit, l'adresse du client, etc.
- Données ordinales ou classées C'est l'ordre des valeurs, mais les différences entre chacune ne sont pas vraiment connues. Des exemples courants ici sont le classement des entreprises en fonction de leur capitalisation boursière, des conditions de paiement des fournisseurs, des scores de satisfaction des clients, de la priorité de livraison, etc.
- Données numériques n’a pas besoin d’être présenté et a une valeur numérique. Ces variables constituent les types de données les plus fondamentaux pouvant être utilisés pour modéliser tous les types d’algorithmes.
5. Axé sur les résultats
Ce type de structure d'analyse de données examine la manière dont la valeur commerciale peut être générée à partir des informations dérivées de l'analyse. Il existe deux manières de générer de la valeur commerciale grâce à l'analyse : par le biais de produits ou de projets. Même si les produits doivent peut-être aborder des ramifications supplémentaires concernant l'expérience utilisateur et l'ingénierie logicielle, l'exercice de modélisation effectué pour dériver le modèle sera similaire dans le projet et dans le produit.
- A produit d'analyse de données est un actif de données réutilisable pour répondre aux besoins à long terme de l'entreprise. Il collecte des données à partir de sources de données pertinentes, garantit la qualité des données, les traite et les rend accessibles à toute personne qui en a besoin. Les produits sont généralement conçus pour des personnages et comportent plusieurs étapes ou itérations du cycle de vie au cours desquelles la valeur du produit est réalisée.
- A projet d'analyse de données est conçu pour répondre à un besoin commercial particulier ou unique et a une base d’utilisateurs ou un objectif défini ou restreint. Fondamentalement, un projet est une entreprise temporaire destinée à fournir la solution pour une portée définie, dans les limites du budget et des délais.
L'économie mondiale va se transformer radicalement dans les années à venir, car les organisations utiliseront de plus en plus de données et d'analyses pour obtenir des informations et prendre des décisions afin de mesurer et d'améliorer leurs performances commerciales. McKinsey ont constaté que les entreprises axées sur la connaissance déclarent que l'EBITDA (bénéfice avant intérêts, impôts, dépréciation et amortissement) augmente jusqu'à 25 % [5]. Cependant, de nombreuses organisations ne parviennent pas à exploiter les données et les analyses pour améliorer leurs résultats commerciaux. Mais il n’existe pas de méthode ou d’approche standard pour fournir des analyses de données. Le déploiement ou la mise en œuvre de solutions d'analyse de données dépend des objectifs, des capacités et des ressources de l'entreprise. Le DAF et ses cinq manifestations décrites ici peuvent permettre un déploiement efficace des analyses en fonction des besoins de l'entreprise, des capacités disponibles et des ressources.
Bibliographie
- mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/five-facts-how-customer-analytics-boosts-corporate-performance
- ide.mit.edu/insights/digitally-mature-firms-are-26-more-profitable-than-their-peers/
- gartner.com/en/newsroom/press-releases/2018-02-13-gartner-dit que près de la moitié des cios envisagent de déployer l'intelligence artificielle
- forbes.com/sites/forbestechcouncil/2023/04/04/three-key-misconceptions-of-data-quality/?sh=58570fc66f98
- Southekal, Prashanth, « Meilleures pratiques analytiques », Technics, 2020
- mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/insights-to-impact-creating-and-sustaining-data-driven-commercial-growth
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Automobile / VE, Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- GraphiquePrime. Élevez votre jeu de trading avec ChartPrime. Accéder ici.
- Décalages de bloc. Modernisation de la propriété des compensations environnementales. Accéder ici.
- La source: https://www.dataversity.net/introducing-the-data-analytics-fabric-concept/
- :possède
- :est
- :ne pas
- $UP
- 1
- 19
- 23
- a
- A Propos
- accessible
- acquérir
- Action
- Supplémentaire
- propos
- AI / ML
- algorithme
- algorithmes
- Tous
- permettre
- permet
- aussi
- amortissement
- an
- selon une analyse de l’Université de Princeton
- analytique
- il analyse
- analysé
- l'analyse
- ainsi que
- répondre
- tous
- chacun.e
- appliqué
- une approche
- SONT
- Arena
- autour
- AS
- atout
- At
- automatiquement
- disponibles
- b
- toile de fond
- base
- basé
- Essentiel
- En gros
- BE
- car
- était
- before
- va
- ci-dessous
- LES MEILLEURS
- jusqu'à XNUMX fois
- tous les deux
- Apportez le
- budget
- construire
- la performance des entreprises
- performance de l'entreprise
- mais
- by
- CAN
- capacités
- capitalisation
- catégoriser
- Causes
- Centralité
- Modifications
- clairement
- regroupement
- recueille
- COM
- Venir
- Commun
- communément
- Sociétés
- composants électriques
- concept
- conclut
- menée
- Contradictoire
- contrôles
- Core
- Corrélation
- pourriez
- cours
- Culture
- des clients
- Satisfaction client
- Clients
- données
- l'analyse des données
- Analyse de Donnée
- qualité des données
- ensemble de données
- ensembles de données
- data-driven
- DATAVERSITÉ
- Offres
- La prise de décision
- décisions
- Vous permet de définir
- défini
- livrer
- livré
- page de livraison.
- dépendant
- dépend
- déployé
- déploiement
- dépréciation
- Dérivé
- la description
- mériter
- un
- Malgré
- déviation
- différences
- différent
- numériquement
- Dimension
- discuté
- spirituelle
- distinct
- do
- fait
- Dramatiquement
- entraîné
- deux
- e
- chacun
- Mes Revenus
- EBITDA
- économie
- risque numérique
- de manière efficace
- non plus
- permettre
- permet
- s'efforcer
- ENGINEERING
- Assure
- erreur
- essential
- événements
- exemples
- Exercises
- d'experience
- Expliquer
- Explique
- L'analyse exploratoire des données
- .
- fait
- FAIL
- Trouvez
- résultats
- trouve
- entreprises
- cinq
- se concentre
- Pour
- Forbes
- Prévision
- Avant
- trouvé
- De
- fonction
- fondamental
- avenir
- Gartner
- Genre
- généré
- Go
- objectif
- arriver
- arrivé
- Vous avez
- aide
- d'où
- ici
- historique
- Cependant
- HTTPS
- i
- IBM
- identifier
- Mettre en oeuvre
- la mise en oeuvre
- améliorer
- amélioré
- l'amélioration de
- in
- Augmente
- de plus en plus
- indépendant
- indiquer
- contribution
- idées.
- prévu
- intérêt
- introduire
- Découvrez le tout nouveau
- Introduction
- impliquer
- implique
- IT
- itérations
- SES
- ACTIVITES
- connu
- Libellé
- l'étiquetage
- plus importantes
- apprentissage
- en tirant parti
- vos produits
- comme
- Probable
- long-term
- recherchez-
- LOOKS
- click
- machine learning
- Les machines
- Entrée
- a prendre une
- FAIT DU
- manuellement
- de nombreuses
- Marché
- Capitalisation boursière
- Matière
- mature
- largeur maximale
- Mai..
- McKinsey
- signifier
- mesurer
- les mesures
- mentionner
- méthodes
- MIT
- ML
- Mode
- modèle
- modélisation statistique
- numériques jumeaux (digital twin models)
- PLUS
- (en fait, presque toutes)
- Le Plus Populaire
- en mouvement
- plusieurs
- Besoin
- Besoins
- réseaux
- Neural
- les réseaux de neurones
- n'allons jamais
- aucune
- À but non lucratif
- Notion
- nombre
- objectifs
- of
- on
- ONE
- fonctionner
- à mettre en œuvre pour gérer une entreprise rentable. Ce guide est basé sur trois décennies d'expérience
- Options
- or
- de commander
- organisation
- organisations
- Autre
- nos
- nous-mêmes
- les résultats
- sortie
- plus de
- particulier
- Patron de Couture
- motifs
- Paiement
- performant
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Populaire
- population
- possible
- défaillances
- Prédictions
- prédictive
- Analyse prédictive
- Analyses prédictives
- représentent
- primaire
- priorité
- processus
- les process
- Produit
- Produits
- Profit
- rentable
- Projet
- projets
- but
- qualité
- question
- ramifications
- classé
- Classement
- réalisé
- vraiment
- recommande
- Considérer
- régression
- en relation
- relation amoureuse
- Les relations
- pertinent
- rapport
- exigent
- conditions
- Resources
- réponse
- conserver
- réutilisable
- client
- portée
- scores
- besoin
- set
- Sets
- mise
- montré
- Spectacles
- similaires
- simulation
- unique
- SIX
- So
- Logiciels
- génie logiciel
- sur mesure
- Solutions
- Identifier
- Sources
- étapes
- Standard
- statistique
- Stratégique
- structure
- Lutter
- réussi
- Avec succès
- tel
- résumé
- enseignement supervisé
- surveillance
- Support
- combustion propre
- Taxes
- techniques
- Les technologies
- temporaire
- terme
- conditions
- que
- qui
- La
- le monde
- leur
- puis
- Là.
- Ces
- l'ont
- Troisièmement
- this
- ceux
- trois
- Avec
- fiable
- fois
- à
- ensemble
- outil
- Formation
- Transformer
- Arbres
- Trends
- deux
- type
- types
- typiquement
- expérience unique et authentique
- utilisé
- d'utiliser
- Utilisateur
- Expérience utilisateur
- en utilisant
- Plus-value
- Valeurs
- variable
- vendeur
- Façon..
- façons
- we
- bien connu
- quand
- que
- qui
- tout en
- WHO
- sera
- comprenant
- dans les
- world
- monde
- pourra
- années
- zéphyrnet











