Redshift d'Amazon est un service d'entreposage de données cloud qui fournit un traitement analytique haute performance basé sur une architecture de traitement massivement parallèle (MPP). La création et la maintenance de pipelines de données constituent un défi commun à toutes les entreprises. La gestion des fichiers SQL, l'intégration du travail inter-équipes, l'incorporation de tous les principes du génie logiciel et l'importation d'utilitaires externes peuvent être une tâche fastidieuse qui nécessite une conception complexe et beaucoup de préparation.
dbt (DataBuildTool) propose ce mécanisme en introduisant un cadre bien structuré pour l'analyse, la transformation et l'orchestration des données. Il applique également les principes généraux de l'ingénierie logicielle comme l'intégration avec les référentiels git, la configuration Séchoir code, ajout de cas de tests fonctionnels et inclusion de bibliothèques externes. Ce mécanisme permet aux développeurs de se concentrer sur la préparation des fichiers SQL selon la logique métier, et le reste est pris en charge par dbt.
Dans cet article, nous examinons un moyen optimal et rentable d'intégrer dbt dans Amazon Redshift. Nous utilisons Amazon Élastique Registre des conteneurs (Amazon ECR) pour stocker nos images Docker dbt et AWSFargate en tant que Service de conteneur élastique Amazon (Amazon ECS) pour exécuter la tâche.
Comment le framework dbt fonctionne-t-il avec Amazon Redshift ?
dbt dispose d'un module adaptateur Amazon Redshift nommé dbt-redshift cela lui permet de se connecter et de travailler avec Amazon Redshift. Tous les profils de connexion sont configurés dans le dbt profiles.yml déposer. Dans un environnement optimal, nous stockons les identifiants dans AWS Secrets Manager et récupérez-les.
Le code suivant montre le contenu de profile.yml :
Le diagramme suivant illustre les composants clés du framework dbt :
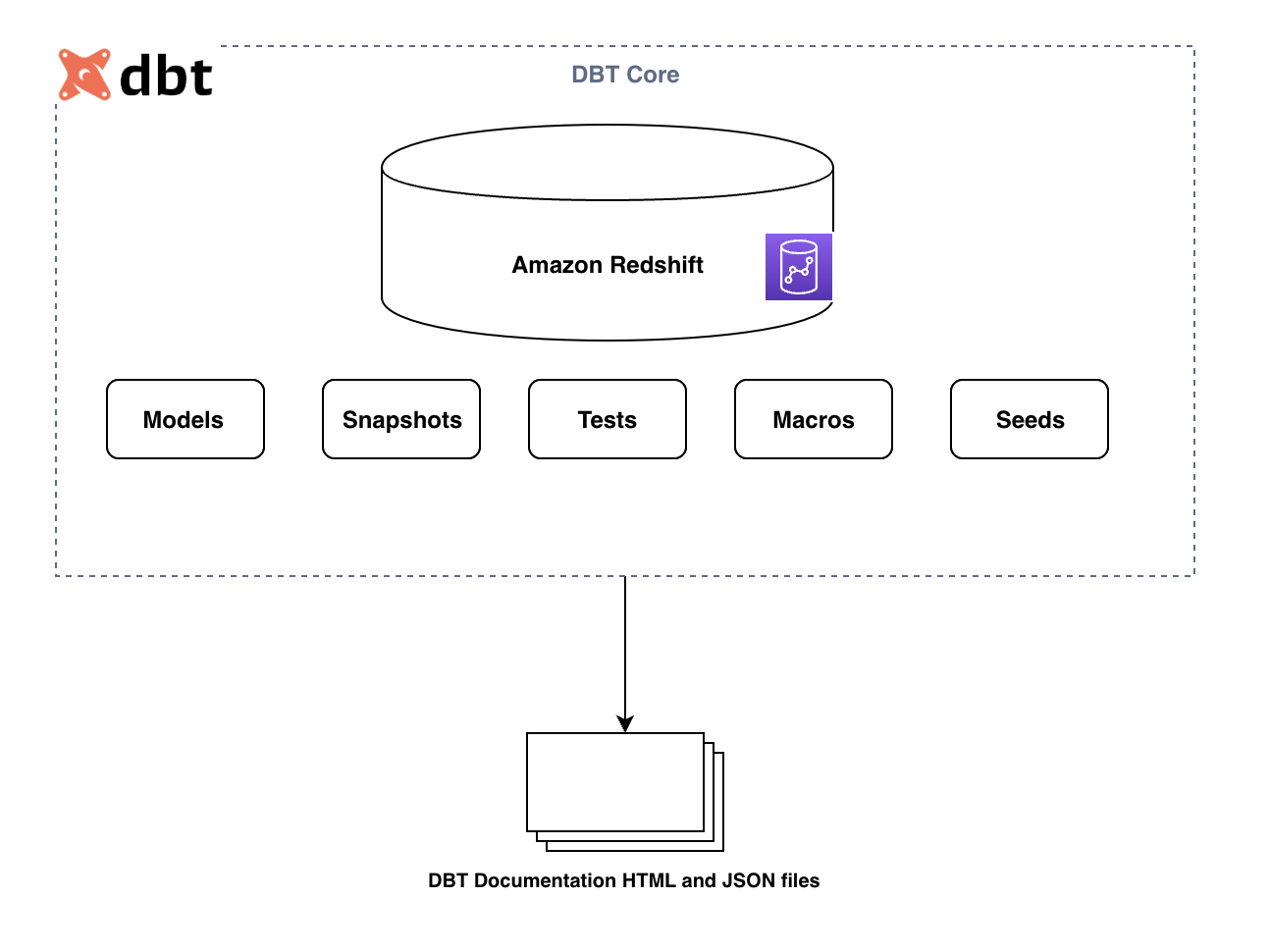
Les principaux composants sont les suivants :
- Des modèles photo – Ceux-ci sont écrits sous forme d’instruction SELECT et enregistrés sous forme de fichier .sql. Toutes les requêtes de transformation peuvent être écrites ici et peuvent être matérialisées sous forme de table ou de vue. L'actualisation de la table peut être complète ou incrémentielle en fonction de la configuration. Pour plus d’informations, consultez les modèles SQL.
- Instantanés – Ces outils type 2 changeant lentement les dimensions (SCD) sur des tables sources mutables. Ces SCD identifient la manière dont une ligne d'un tableau évolue au fil du temps.
- Graines – Ce sont des fichiers CSV dans votre projet dbt (généralement dans votre répertoire seed), que dbt peut charger dans votre entrepôt de données utilisant l'
dbt seedcommander. - Tests – Il s'agit d'affirmations que vous faites sur vos modèles et autres ressources dans votre projet dbt (telles que les sources, les graines et les instantanés). Quand tu cours
dbt test, dbt vous dira si chaque test de votre projet réussit ou échoue. - Macros – Ce sont des morceaux de code qui peuvent être réutilisés plusieurs fois. Elles sont analogues aux « fonctions » dans d’autres langages de programmation et sont extrêmement utiles si vous vous retrouvez à répéter du code sur plusieurs modèles.
Ces composants sont stockés sous forme de fichiers .sql et sont exécutés par Commandes CLI dbt. Pendant l'exécution, dbt crée un Graphique acyclique dirigé (DAG) basé sur la référence interne entre les composants dbt. Il utilise le DAG pour orchestrer la séquence d'exécution en conséquence.
Plusieurs profils peuvent être créés dans le fichier profiles.yml, que dbt peut utiliser pour cibler différents environnements Redshift lors de son exécution. Pour plus d'informations, reportez-vous à la configuration de Redshift.
Vue d'ensemble de la solution
Le diagramme suivant illustre notre architecture de solution.
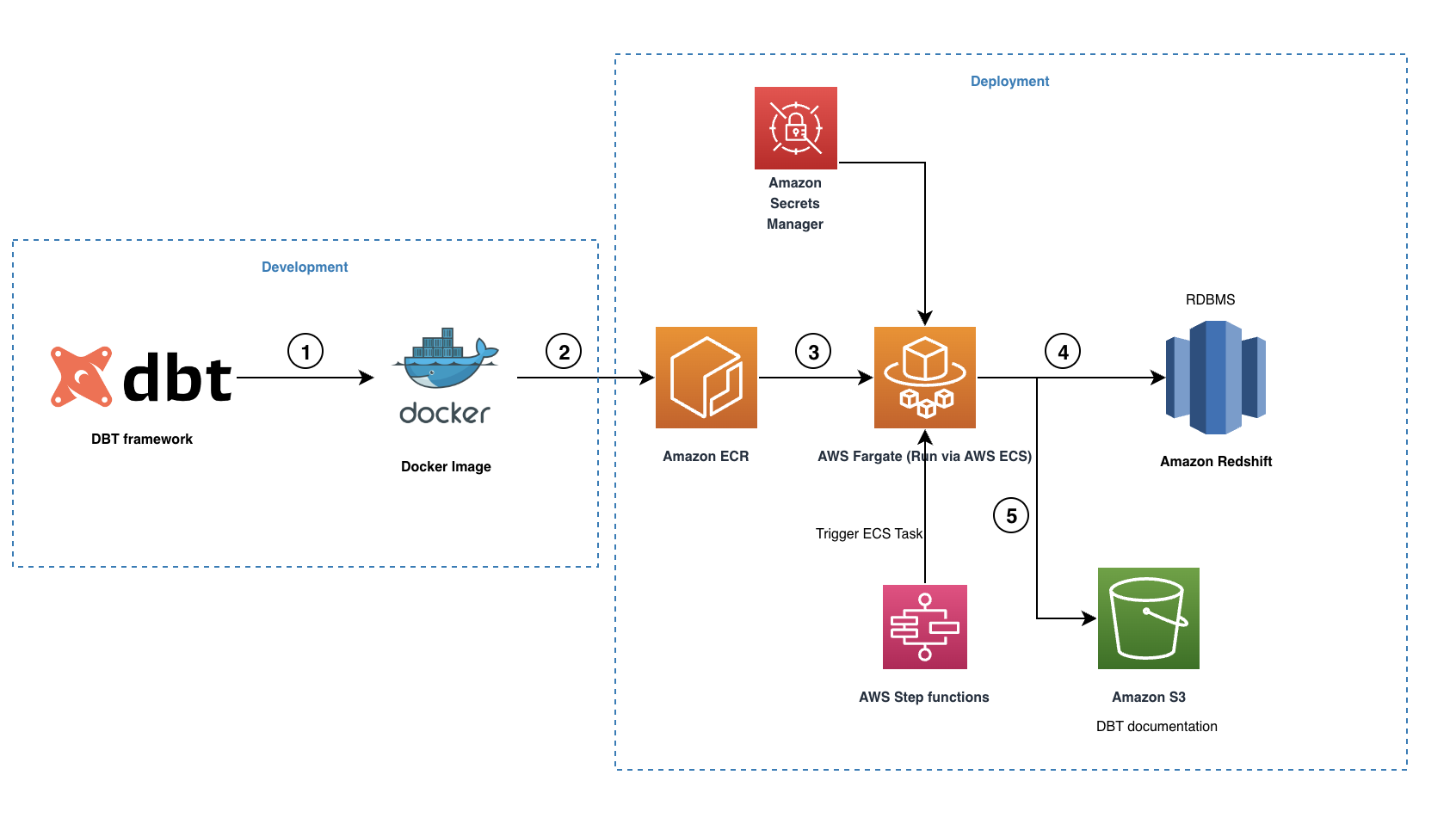
Le workflow contient les étapes suivantes:
- Le connecteur open source dbt-redshift est utilisé pour créer notre projet dbt comprenant tous les modèles, instantanés, tests, macros et profils nécessaires.
- Une image Docker est créée et transférée vers le référentiel ECR.
- L'image Docker est exécutée par Fargate en tant que tâche ECS déclenchée via Fonctions d'étape AWS. Toutes les informations d'identification Amazon Redshift sont stockées dans Secrets Manager, qui est ensuite utilisé par la tâche ECS pour se connecter à Amazon Redshift.
- Pendant l'exécution, dbt convertit tous les modèles, instantanés, tests et macros en instructions SQL conformes à Amazon Redshift et orchestre l'exécution en fonction des paramètres internes. graphique de lignage des données entretenu. Ces commandes SQL sont exécutées directement sur le cluster Redshift et la charge de travail est donc transmise directement à Amazon Redshift.
- Une fois l'exécution terminée, dbt créera un ensemble de fichiers HTML et JSON pour héberger le documentation de la dette, qui décrit le catalogue de données, les instructions SQL compilées, le graphique de lignage des données, etc.
Pré-requis
Vous devez avoir les prérequis suivants :
- Une bonne compréhension des principes de la dette et des étapes de mise en œuvre.
- Un compte AWS avec l'autorisation de rôle d'utilisateur pour accéder aux services AWS utilisés dans cette solution.
- Groupes de sécurité permettant à Fargate d'accéder au cluster Redshift et à Secrets Manager depuis Amazon ECS.
- Un cluster Redshift. Pour les instructions de création, reportez-vous à Créer un cluster.
- Un référentiel ECR: Pour obtenir des instructions, reportez-vous à Création d'un référentiel privé
- Un gestionnaire de secrets secret contenant toutes les informations d'identification pour se connecter à Amazon Redshift. Cela inclut l'hôte, le port, le nom de la base de données, le nom d'utilisateur et le mot de passe. Pour plus d'informations, reportez-vous à Créer un secret de base de données AWS Secrets Manager.
- An Stockage simple d'Amazon (Amazon S3) pour héberger les fichiers de documentation.
Créer un projet Dbt
Nous utilisons dbt CLI afin que toutes les commandes soient exécutées dans la ligne de commande. Par conséquent, installez pip s’il n’est pas déjà installé. Faire référence à installation pour plus d'information.
Pour créer un projet dbt, procédez comme suit :
- Installez les packages dbt dépendants :
pip install dbt-redshift - Initialisez un projet dbt à l'aide du
dbt init <project_name>commande, qui crée automatiquement tous les dossiers de modèles. - Ajoutez tous les artefacts DBT requis.
Reportez-vous à dbt-redshift-etlpattern repo qui comprend un projet dbt de référence. Pour plus d'informations sur les projets de construction, reportez-vous à À propos des projets DBT.
Dans le projet de référence, nous avons implémenté les fonctionnalités suivantes :
- SCD type 1 utilisant des modèles incrémentiels
- SCD type 2 utilisant des instantanés
- Fichiers de recherche de semences
- Macros pour ajouter du code réutilisable dans le projet
- Tests d'analyse des données entrantes
Le script Python est prêt à récupérer les informations d'identification requises auprès de Secrets Manager pour accéder à Amazon Redshift. Se référer au export_redshift_connection.py fichier.
- Préparer la
run_dbt.shscript pour exécuter le pipeline dbt de manière séquentielle. Ce script est placé dans le dossier racine du projet dbt, comme indiqué dans l'exemple de dépôt.
- Créez un fichier Docker dans le répertoire parent du dossier du projet dbt. Cette étape crée l'image du projet dbt à pousser vers le référentiel ECR.
Téléchargez l'image sur Amazon ECR et exécutez-la en tant que tâche ECS
Pour transférer l'image vers le référentiel ECR, procédez comme suit :
- Récupérez un jeton d'authentification et authentifiez votre client Docker auprès de votre registre :
- Créez votre image Docker à l'aide de la commande suivante :
- Une fois la construction terminée, marquez votre image afin de pouvoir la transférer vers le référentiel :
- Exécutez la commande suivante pour transférer l'image vers votre référentiel AWS nouvellement créé :
- Sur la console Amazon ECS, créez un cluster avec Fargate comme option d'infrastructure.
- Fournissez votre VPC et vos sous-réseaux selon les besoins.
- Après avoir créé le cluster, créez une tâche ECS et attribuez l'image dbt créée en tant que famille de définition de tâche.
- Dans la section Mise en réseau, choisissez votre VPC, vos sous-réseaux et votre groupe de sécurité pour vous connecter à Amazon Redshift, Amazon S3 et Secrets Manager.
Cette tâche déclenchera le run_dbt.sh script pipeline et exécutez toutes les commandes dbt de manière séquentielle. Une fois le script terminé, nous pouvons voir les résultats dans Amazon Redshift et les fichiers de documentation transférés vers Amazon S3.
- Vous pouvez héberger la documentation via l'hébergement de site Web statique Amazon S3. Pour plus d'informations, reportez-vous à Hébergement d'un site Web statique à l'aide d'Amazon S3.
- Enfin, vous pouvez exécuter cette tâche dans Step Functions en tant que tâche ECS pour planifier les tâches selon vos besoins. Pour plus d'informations, reportez-vous à Gérer les tâches Amazon ECS ou Fargate avec Step Functions.
Le dbt-redshift-etlpattern repo contient désormais tous les exemples de code requis.
Le coût d'exécution des tâches dbt dans AWS Fargate en tant que tâche Amazon ECS avec des exigences opérationnelles minimales prendrait environ 1.5 $ (coût_lien) par mois.
Nettoyer
Effectuez les étapes suivantes pour nettoyer vos ressources :
- Supprimer le cluster ECS vous avez créé.
- Supprimer le référentiel ECR que vous avez créé pour stocker les fichiers image.
- Supprimer le cluster Redshift vous avez créé.
- Supprimez les secrets de Redshift stockés dans Secrets Manager.
Conclusion
Cet article couvrait la mise en œuvre de base de l'utilisation de dbt avec Amazon Redshift de manière rentable en utilisant Fargate dans Amazon ECS. Nous avons décrit l'infrastructure clé et la configuration avec un exemple de projet. Cette architecture peut vous aider à profiter des avantages d'un framework dbt pour gérer votre plateforme d'entrepôt de données dans Amazon Redshift.
Pour plus d'informations sur les macros et les modèles dbt pour le fonctionnement et la maintenance internes d'Amazon Redshift, reportez-vous à ce qui suit. GitHub repo. Dans l'article suivant, nous explorerons les modèles traditionnels d'extraction, de transformation et de chargement (ETL) que vous pouvez implémenter à l'aide du framework dbt dans Amazon Redshift. Testez cette solution dans votre compte et faites part de vos retours ou suggestions dans les commentaires.
À propos des auteurs
 Seshadri Senthamaraikannan est un architecte de données au sein de l'équipe de services professionnels AWS basée à Londres, au Royaume-Uni. Il est expérimenté et spécialisé dans l'analyse de données et travaille avec des clients en se concentrant sur la création de solutions innovantes et évolutives dans AWS Cloud pour atteindre leurs objectifs commerciaux. Dans ses temps libres, il aime passer du temps avec sa famille et faire du sport.
Seshadri Senthamaraikannan est un architecte de données au sein de l'équipe de services professionnels AWS basée à Londres, au Royaume-Uni. Il est expérimenté et spécialisé dans l'analyse de données et travaille avec des clients en se concentrant sur la création de solutions innovantes et évolutives dans AWS Cloud pour atteindre leurs objectifs commerciaux. Dans ses temps libres, il aime passer du temps avec sa famille et faire du sport.
 Mohamed Hamdi est un architecte Big Data senior chez AWS Professional Services basé à Londres, au Royaume-Uni. Il possède plus de 15 ans d’expérience dans l’architecture, la direction et la création d’entrepôts de données et de plateformes Big Data. Il aide les clients à développer des solutions de Big Data et d'analyse pour accélérer leurs résultats commerciaux tout au long de leur parcours d'adoption du cloud. En dehors du travail, Mohamed aime voyager, courir, nager et jouer au squash.
Mohamed Hamdi est un architecte Big Data senior chez AWS Professional Services basé à Londres, au Royaume-Uni. Il possède plus de 15 ans d’expérience dans l’architecture, la direction et la création d’entrepôts de données et de plateformes Big Data. Il aide les clients à développer des solutions de Big Data et d'analyse pour accélérer leurs résultats commerciaux tout au long de leur parcours d'adoption du cloud. En dehors du travail, Mohamed aime voyager, courir, nager et jouer au squash.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/implement-data-warehousing-solution-using-dbt-on-amazon-redshift/
- :possède
- :est
- :ne pas
- $UP
- 1
- 10
- 11
- 15 ans
- 15%
- 7
- 8
- 90
- 970
- a
- A Propos
- accélérer
- accès
- accès
- Compte
- à travers
- ajouter
- ajoutant
- Adoption
- Avantage
- Tous
- permet
- déjà
- aussi
- Amazon
- Amazon Web Services
- an
- selon une analyse de l’Université de Princeton
- Analytique
- analytique
- l'analyse
- et les
- s'applique
- architecture
- SONT
- autour
- AS
- authentifier
- Authentification
- automatiquement
- AWS
- Services professionnels AWS
- basé
- Essentiel
- BE
- avantages.
- jusqu'à XNUMX fois
- Big
- Big Data
- construire
- Développement
- construit
- la performance des entreprises
- by
- CAN
- les soins
- cas
- catalogue
- challenge
- Modifications
- en changeant
- Selectionnez
- espace extérieur plus propre,
- client
- le cloud
- adoption du cloud
- Grappe
- code
- commentaires
- Commun
- compilé
- complet
- complexe
- composants électriques
- configuration
- configurée
- NOUS CONTACTER
- Connecter les
- connexion
- Console
- Contenant
- contient
- contenu
- rentable
- couvert
- engendrent
- créée
- crée des
- création
- Lettres de créance
- Customiser
- Clients
- JOUR
- données
- l'analyse des données
- Analyse de Donnée
- entrepôt de données
- entrepôts de données
- Base de données
- Réglage par défaut
- définition
- dépendant
- décrit
- Conception
- dev
- développer
- mobiles
- différent
- directement
- Docker
- Documentation
- pendant
- chacun
- permet
- ENGINEERING
- entreprises
- Environment
- environnements
- Ether (ETH)
- exécution
- d'experience
- expérimenté
- explorez
- externe
- extrait
- extrêmement
- échoue
- famille
- Fonctionnalités:
- Réactions
- Déposez votre dernière attestation
- Fichiers
- Trouvez
- Focus
- mettant l'accent
- Abonnement
- suit
- Pour
- Framework
- De
- plein
- fonctionnel
- fonctions
- Général
- générer
- Git
- Objectifs
- Bien
- graphique
- Réservation de groupe
- Groupes
- Vous avez
- ayant
- he
- vous aider
- aide
- ici
- haute performance
- sa
- hôte
- hébergement
- Comment
- HTML
- HTTPS
- identifier
- if
- illustre
- image
- satellite
- Mettre en oeuvre
- la mise en oeuvre
- mis en œuvre
- importer
- l'importation
- in
- Dans d'autres
- inclut
- Y compris
- incorporation
- incrémental
- d'information
- Infrastructure
- technologie innovante
- installer
- Des instructions
- Intégration
- interne
- développement
- Découvrez le tout nouveau
- IT
- Emploi
- Emplois
- chemin
- json
- ACTIVITES
- Langues
- Nouveautés
- conduisant
- bibliothèques
- comme
- aime
- Gamme
- charge
- logique
- vous connecter
- London
- Style
- beaucoup
- macros
- le maintien
- facile
- a prendre une
- gérer
- manager
- les gérer
- massivement
- mécanisme
- Découvrez
- minimal
- modèle
- numériques jumeaux (digital twin models)
- module
- Mohamed
- Mois
- PLUS
- plusieurs
- prénom
- Nommé
- nécessaire
- de mise en réseau
- nouvellement
- maintenant
- of
- Offres Speciales
- on
- ouvert
- open source
- opération
- opérationnel
- optimaux
- Option
- or
- orchestration
- Autre
- nos
- les résultats
- sorties
- au contrôle
- plus de
- vue d'ensemble
- Forfaits
- Parallèle
- passes
- Mot de Passe
- motifs
- /
- autorisation
- pièces
- pipeline
- mis
- plateforme
- Plateformes
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Jouez
- jouer
- Post
- préparation
- préparé
- en train de préparer
- conditions préalables
- primaire
- principes
- Privé
- traitement
- professionels
- Profil
- Profils
- Programmation
- langages de programmation
- Projet
- projets
- fournir
- fournit
- Push
- Poussé
- Python
- requêtes
- reportez-vous
- référence
- enregistrement
- dépôt
- exigent
- conditions
- Exigences
- a besoin
- Resources
- REST
- Résultats
- réutilisable
- Rôle
- racine
- RANGÉE
- Courir
- pour le running
- sauvé
- évolutive
- calendrier
- scénario
- secondes
- secrets
- Section
- sécurité
- sur le lien
- seed
- graines
- supérieur
- Séquence
- service
- Services
- set
- mise
- devrait
- montré
- Spectacles
- étapes
- Lentement
- Instantané
- So
- Logiciels
- génie logiciel
- sur mesure
- Solutions
- Identifier
- Sources
- spécialisé
- Dépenses
- Sports
- SQL
- Déclaration
- déclarations
- étapes
- Étapes
- Boutique
- stockée
- sous-réseaux
- ultérieur
- tel
- natation
- table
- TAG
- Prenez
- tâches
- Target
- Tâche
- tâches
- équipe
- dire
- modèle
- tester
- tests
- qui
- Le
- leur
- Les
- puis
- donc
- Ces
- l'ont
- this
- Avec
- fiable
- long
- fois
- à
- jeton
- traditionnel
- Transformer
- De La Carrosserie
- déclencher
- déclenché
- type
- typiquement
- Uk
- compréhension
- utilisé
- d'utiliser
- Utilisateur
- Usages
- en utilisant
- les services publics
- via
- Voir
- Entrepots
- Entreposage
- Façon..
- we
- web
- services Web
- Site Web
- WELL
- quand
- qui
- tout en
- Wikipédia
- sera
- comprenant
- dans les
- activités principales
- workflow
- vos contrats
- pourra
- code écrit
- années
- you
- Votre
- vous-même
- zéphyrnet