Service Amazon OpenSearch est un service géré qui facilite la sécurisation, le déploiement et l'exploitation des clusters OpenSearch et Elasticsearch hérités à grande échelle dans le cloud AWS. Amazon OpenSearch Service provisionne toutes les ressources de votre cluster, le lance et détecte et remplace automatiquement les nœuds défaillants, réduisant ainsi la surcharge des infrastructures autogérées. Le service vous permet d'effectuer facilement des analyses de journaux interactives, une surveillance des applications en temps réel, des recherches de sites Web, etc. en offrant les dernières versions d'OpenSearch, la prise en charge de 19 versions d'Elasticsearch (versions 1.5 à 7.10) et des capacités de visualisation optimisées par Tableaux de bord OpenSearch et Kibana (versions 1.5 à 7.10).
Dans la dernière version du logiciel de service, nous avons mis à jour la logique d'allocation des fragments pour qu'elle soit sensible à la charge afin que, lorsque les fragments sont redistribués en cas de défaillance d'un nœud, le service empêche les nœuds survivants d'être surchargés par des fragments précédemment hébergés sur le nœud défaillant. Ceci est particulièrement important pour les domaines multi-AZ afin de fournir des performances de cluster cohérentes et prévisibles.
Si vous souhaitez plus d'informations sur la logique d'allocation des fragments en général, veuillez consulter Démystifier l'allocation des fragments Elasticsearch.
Le défi
Un domaine Amazon OpenSearch Service est dit « équilibré » lorsque le nombre de nœuds est réparti de manière égale sur les zones de disponibilité configurées et que le nombre total de fragments est réparti de manière égale sur tous les nœuds disponibles sans concentration de fragments d'un index sur un quelconque. nœud. En outre, OpenSearch possède une propriété appelée "Zone Awareness" qui, lorsqu'elle est activée, garantit que le fragment principal et son réplica correspondant sont alloués dans différentes zones de disponibilité. Si vous disposez de plusieurs copies de données, le fait d'avoir plusieurs zones de disponibilité offre une meilleure tolérance aux pannes et une meilleure disponibilité. Dans le cas où le domaine est mis à l'échelle ou réduit ou lors de la défaillance d'un ou plusieurs nœuds, OpenSearch redistribue automatiquement les fragments entre les nœuds disponibles tout en respectant les règles d'allocation basées sur la prise en compte de la zone.
Alors que le processus d'équilibrage des fragments garantit que les fragments sont répartis uniformément entre les zones de disponibilité, dans certains cas, en cas de défaillance inattendue dans une seule zone, les fragments seront réaffectés aux nœuds survivants. Cela peut entraîner une surcharge des nœuds survivants, ce qui a un impact sur la stabilité du cluster.
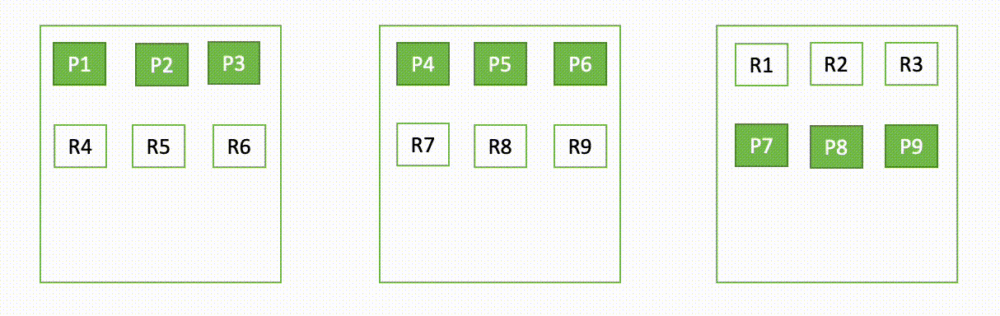
Par exemple, si un nœud d'un cluster à trois nœuds tombe en panne, OpenSearch redistribue les fragments non attribués, comme illustré dans le diagramme suivant. Ici, « P » représente une copie de fragment principal, tandis que « R » représente une copie de fragment de réplique.

Ce comportement du domaine peut être expliqué en deux parties : lors de la panne et lors de la récupération.
Pendant l'échec
Un domaine déployé sur plusieurs zones de disponibilité peut rencontrer plusieurs types de pannes au cours de son cycle de vie.
Défaillance complète de la zone
Un cluster peut perdre une seule zone de disponibilité pour diverses raisons, ainsi que tous les nœuds de cette zone. Aujourd'hui, le service tente de placer les nœuds perdus dans les zones de disponibilité saines restantes. Le service essaie également de recréer les fragments perdus dans les nœuds restants tout en suivant les règles d'allocation. Cela peut entraîner des conséquences inattendues.
- Lorsque les partitions de la zone impactée sont réaffectées à des zones saines, elles déclenchent des récupérations de partition qui peuvent augmenter les latences car elles consomment des cycles CPU et de la bande passante réseau supplémentaires.
- Pour une configuration n-AZ, n-copies, (n>1), les zones de disponibilité n-1 survivantes sont allouées avec la nième copie de partition, ce qui peut être indésirable car cela peut entraîner une asymétrie dans la distribution des partitions, ce qui peut également entraîner trafic déséquilibré entre les nœuds. Ces nœuds peuvent être surchargés, entraînant de nouvelles pannes.
Panne de zone partielle
En cas de défaillance partielle d'une zone ou lorsque le domaine ne perd que certains des nœuds d'une zone de disponibilité, Amazon OpenSearch Service essaie de remplacer les nœuds défaillants aussi rapidement que possible. Cependant, si le remplacement des nœuds prend trop de temps, OpenSearch essaie d'allouer les fragments non attribués de cette zone aux nœuds survivants de la zone de disponibilité. Si le service ne peut pas remplacer les nœuds dans la zone de disponibilité concernée, il peut les allouer dans l'autre zone de disponibilité configurée, ce qui peut encore fausser la distribution des fragments à la fois à travers et dans la zone. Cela a à nouveau des conséquences imprévues.
- Si les nœuds du domaine ne disposent pas de suffisamment d'espace de stockage pour accueillir les fragments supplémentaires, le domaine peut être bloqué en écriture, ce qui a un impact sur l'opération d'indexation.
- En raison de la répartition asymétrique des fragments, le domaine peut également subir un trafic asymétrique sur les nœuds, ce qui peut encore augmenter les latences ou les délais d'attente pour les opérations de lecture et d'écriture.
Récupération
Aujourd'hui, afin de maintenir le nombre de nœuds souhaité du domaine, Amazon OpenSearch Service lance des nœuds de données dans les zones de disponibilité saines restantes, similaires aux scénarios décrits dans la section d'échec ci-dessus. Afin d'assurer une distribution correcte des nœuds dans toutes les zones de disponibilité après un tel incident, une intervention manuelle était nécessaire par AWS.
Ce qui change
Pour améliorer la gestion globale des pannes et minimiser l'impact des pannes sur la santé et les performances du domaine, Amazon OpenSearch Service effectue les modifications suivantes :
- Détection de zone forcée: OpenSearch a une configuration d'équilibrage de partition préexistante appelée reconnaissance forcée qui est utilisée pour définir les zones de disponibilité auxquelles les partitions doivent être allouées. Par exemple, si vous avez un attribut de sensibilisation appelé zone et que vous configurez des nœuds dans
zone1ainsi quezone2, vous pouvez utiliser la reconnaissance forcée pour empêcher OpenSearch d'allouer des répliques si une seule zone est disponible :
Avec cet exemple de configuration, si vous démarrez deux nœuds avec node.attr.zone ajuster à zone1 et créez un index avec cinq partitions et une réplique, OpenSearch crée l'index et alloue les cinq partitions principales mais pas de répliques. Les répliques ne sont allouées qu'une seule fois aux nœuds avec node.attr.zone ajuster à zone2 sont disponibles.
Amazon OpenSearch Service utilisera la configuration de détection forcée sur les domaines multi-AZ pour s'assurer que les fragments ne sont alloués qu'en fonction des règles de détection de zone. Cela empêcherait l'augmentation soudaine de la charge sur les nœuds des zones de disponibilité saines.
- Allocation de partition sensible à la charge: Amazon OpenSearch Service prendra en considération des facteurs tels que la capacité allouée, la capacité réelle et le nombre total de copies de partitions pour calculer si un nœud est surchargé avec plus de partitions en fonction des partitions moyennes attendues par nœud. Cela empêcherait l'attribution de partition lorsqu'un nœud a alloué un nombre de partitions qui dépasse cette limite.
Notes que tout non attribué primaire copie serait toujours autorisée sur le nœud surchargé pour empêcher le cluster de toute perte de données imminente.
De même, pour résoudre le problème de récupération manuelle (comme décrit dans la section Récupération ci-dessus), Amazon OpenSearch Service apporte également des modifications à son composant de mise à l'échelle interne. Avec les modifications les plus récentes en place, Amazon OpenSearch Service ne lancera pas de nœuds dans les zones de disponibilité restantes, même lorsqu'il passe par le scénario d'échec décrit précédemment.
Visualisation du comportement actuel et nouveau
Par exemple, un domaine Amazon OpenSearch Service est configuré avec 3-AZ, 6 nœuds de données, 12 fragments principaux et 24 fragments de réplique. Le domaine est provisionné sur AZ-1, AZ-2 et AZ-3, avec deux nœuds dans chacune des zones.
Allocation de partition actuelle :
Nombre total de fragments : 12 primaires + 24 répliques = 36 fragments
Nombre de zones de disponibilité : 3
Nombre de partitions par zone (la détection de zone est vraie) : 36/3 = 12
Nombre de nœuds par zone de disponibilité : 2
Nombre de fragments par nœud : 12/2 = 6
Le diagramme suivant fournit une représentation visuelle de la configuration du domaine. Les cercles indiquent le nombre de fragments alloués au nœud. Amazon OpenSearch Service allouera six partitions par nœud.

Lors d'une panne de zone partielle, lorsqu'un nœud dans AZ-3 tombe en panne, le nœud défaillant est affecté à la zone restante et les fragments de la zone sont redistribués en fonction des nœuds disponibles. Après les modifications décrites ci-dessus, le cluster ne créera pas de nouveau nœud ni ne redistribuera les fragments après la défaillance du nœud.

Dans le diagramme ci-dessus, avec la perte d'un nœud dans AZ-3, Amazon OpenSearch Service essaierait de lancer la capacité de remplacement dans la même zone. Cependant, en raison d'une panne, la zone pourrait être altérée et ne parviendrait pas à lancer le remplacement. Dans un tel cas, le service tente de lancer une capacité déficitaire dans une autre zone saine, ce qui peut entraîner un déséquilibre entre les zones de disponibilité. Les fragments de la zone impactée sont stockés sur le nœud survivant de la même zone. Cependant, avec le nouveau comportement, le service essaierait de lancer de la capacité dans la même zone mais éviterait de lancer une capacité déficitaire dans d'autres zones pour éviter un déséquilibre. L'allocateur de fragments garantirait également que les nœuds survivants ne soient pas surchargés.

De même, si tous les nœuds de AZ-3 sont perdus ou si AZ-3 est endommagé, Amazon OpenSearch Service affiche les nœuds perdus dans la zone de disponibilité restante et redistribue également les fragments sur les nœuds. Cependant, après les nouvelles modifications, Amazon OpenSearch Service n'allouera pas de nœuds à la zone restante ou tentera de réallouer les fragments perdus à la zone restante. Amazon OpenSearch Service attendra que la récupération se produise et que le domaine revienne à la configuration d'origine après la récupération.
Si votre domaine n'est pas provisionné avec une capacité suffisante pour résister à la perte d'une zone de disponibilité, vous pouvez rencontrer une baisse de débit pour votre domaine. Il est donc fortement recommandé de suivre les meilleures pratiques lors du dimensionnement de votre domaine, ce qui signifie disposer de suffisamment de ressources provisionnées pour résister à la perte d'une seule défaillance de la zone de disponibilité.

Actuellement, une fois le domaine récupéré, le service nécessite une intervention manuelle pour équilibrer la capacité entre les zones de disponibilité, ce qui implique également des mouvements de partition. Cependant, avec le nouveau comportement, aucune intervention n'est nécessaire pendant le processus de récupération car la capacité revient dans la zone impactée et les fragments sont également automatiquement alloués aux nœuds récupérés. Cela garantit qu'il n'y a pas de priorités concurrentes sur les ressources restantes.
Ce que vous pouvez vous attendre
Après avoir mis à jour votre domaine Amazon OpenSearch Service vers la dernière version du logiciel de service, les domaines qui ont été configuré avec les meilleures pratiques aura des performances plus prévisibles même après avoir perdu un ou plusieurs nœuds de données dans une zone de disponibilité. Il y aura moins de cas de surallocation de fragments dans un nœud. Il est recommandé de fournir une capacité suffisante pour pouvoir tolérer une défaillance d'une seule zone
Vous pouvez parfois voir un domaine devenir jaune lors de tels échecs inattendus, car nous n'attribuerons pas de fragments de réplique aux nœuds surchargés. Cependant, cela ne signifie pas qu'il y aura une perte de données dans un domaine bien configuré. Nous veillerons toujours à ce que toutes les primaires soient affectées pendant les pannes. Une récupération automatisée est en place, qui se chargera d'équilibrer les nœuds dans le domaine et de s'assurer que les répliques sont attribuées une fois la panne récupérée.
Mettez à jour le logiciel de service de votre domaine Amazon OpenSearch Service pour que ces nouvelles modifications soient appliquées à votre domaine. Plus de détails sur le processus de mise à jour du logiciel de service sont dans le Documentation du service Amazon OpenSearch.
Conclusion
Dans cet article, nous avons vu comment Amazon OpenSearch Service a récemment amélioré la logique de distribution des nœuds et des fragments dans les zones de disponibilité lors des pannes zonales.
Cette modification aidera le service à garantir des performances plus cohérentes et prévisibles lors des pannes de nœud ou de zone. Les domaines ne verront pas de latences accrues ni de blocs d'écriture pendant le traitement des écritures et des lectures, qui apparaissaient parfois plus tôt en raison de la surallocation des fragments sur les nœuds.
À propos des auteurs
 Boukhtawar Khan est un ingénieur logiciel senior travaillant sur Amazon OpenSearch Service. Il s'intéresse aux systèmes distribués et autonomes. Il est un contributeur actif à OpenSearch.
Boukhtawar Khan est un ingénieur logiciel senior travaillant sur Amazon OpenSearch Service. Il s'intéresse aux systèmes distribués et autonomes. Il est un contributeur actif à OpenSearch.
 Anshu Agarwal est un ingénieur logiciel senior travaillant sur AWS OpenSearch chez Amazon Web Services. Elle est passionnée par la résolution de problèmes liés à la construction de systèmes évolutifs et hautement fiables.
Anshu Agarwal est un ingénieur logiciel senior travaillant sur AWS OpenSearch chez Amazon Web Services. Elle est passionnée par la résolution de problèmes liés à la construction de systèmes évolutifs et hautement fiables.
 Shourya Dutta Biswas est un ingénieur logiciel travaillant sur AWS OpenSearch chez Amazon Web Services. Il est passionné par la construction de systèmes distribués hautement résilients.
Shourya Dutta Biswas est un ingénieur logiciel travaillant sur AWS OpenSearch chez Amazon Web Services. Il est passionné par la construction de systèmes distribués hautement résilients.
 Rishab Nahata est un ingénieur logiciel travaillant sur OpenSearch chez Amazon Web Services. Il est fasciné par la résolution de problèmes dans les systèmes distribués. Il est un contributeur actif à OpenSearch.
Rishab Nahata est un ingénieur logiciel travaillant sur OpenSearch chez Amazon Web Services. Il est fasciné par la résolution de problèmes dans les systèmes distribués. Il est un contributeur actif à OpenSearch.
 Ranjith Ramachandra est un responsable de l'ingénierie travaillant sur Amazon OpenSearch Service chez Amazon Web Services.
Ranjith Ramachandra est un responsable de l'ingénierie travaillant sur Amazon OpenSearch Service chez Amazon Web Services.
 Jon Gestionnaire est un architecte principal principal de solutions, spécialisé dans les technologies de recherche AWS - Amazon CloudSearch et Amazon OpenSearch Service. Basé à Palo Alto, il aide un large éventail de clients à déployer correctement et à bien fonctionner leurs charges de travail de recherche et d'analyse de journaux.
Jon Gestionnaire est un architecte principal principal de solutions, spécialisé dans les technologies de recherche AWS - Amazon CloudSearch et Amazon OpenSearch Service. Basé à Palo Alto, il aide un large éventail de clients à déployer correctement et à bien fonctionner leurs charges de travail de recherche et d'analyse de journaux.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/impact-of-infrastructure-failures-on-shard-in-amazon-opensearch-service/
- 1
- 10
- 100
- 7
- 9
- a
- Capable
- A Propos
- au dessus de
- accommoder
- Selon
- à travers
- infection
- Supplémentaire
- propos
- Après
- Tous
- consacrée
- alloue
- allocation
- Amazon
- Amazon Web Services
- analytique
- ainsi que
- Une autre
- Application
- appliqué
- attribué
- attributs
- Automatisation
- automatiquement
- autonome
- disponibilité
- disponibles
- moyen
- AWS
- fond
- Balance
- Bande passante
- basé
- car
- devient
- LES MEILLEURS
- les meilleures pratiques
- Améliorée
- jusqu'à XNUMX fois
- Au-delà
- Blocs
- Apportez le
- vaste
- Développement
- appelé
- Peut obtenir
- ne peut pas
- capacités
- Compétences
- les soins
- maisons
- cas
- Causes
- Change
- Modifications
- cercles
- le cloud
- Grappe
- compétition
- composant
- concentration
- configuration
- Conséquences
- considération
- cohérent
- contributeur
- Correspondant
- engendrent
- crée des
- Courant
- Clients
- cycles
- données
- La perte de données
- DÉFICIT
- déployer
- déployé
- décrit
- détails
- différent
- distribuer
- distribué
- systèmes distribués
- distribution
- domaine
- domaines
- Ne pas
- down
- Goutte
- pendant
- chacun
- Plus tôt
- ingénieur
- ENGINEERING
- assez
- assurer
- Assure
- assurer
- également
- notamment
- Ether (ETH)
- Pourtant, la
- événement
- exemple
- attendu
- d'experience
- expliqué
- facteurs
- FAIL
- Échoué
- échoue
- Échec
- suivre
- Abonnement
- Force
- De
- fonctionnement
- plus
- Général
- obtenez
- obtention
- gif
- Goes
- Bien
- Maniabilité
- arriver
- ayant
- Santé
- la santé
- vous aider
- aide
- ici
- très
- organisé
- Comment
- Cependant
- HTML
- HTTPS
- déséquilibre
- Impact
- impact
- important
- améliorer
- amélioré
- in
- Dans d'autres
- incident
- Améliore
- increased
- indice
- Infrastructure
- infrastructures
- instance
- Interactif
- intéressé
- interne
- intervention
- aide
- IT
- Nouveautés
- lancer
- lance
- lancement
- conduire
- conduisant
- Legacy
- LIMIT
- charge
- Location
- perdre
- Perd
- pas à perdre
- perte
- maintenir
- a prendre une
- FAIT DU
- Fabrication
- gérés
- manager
- Manuel
- de nombreuses
- veux dire
- pourrait
- réduisant au minimum
- Stack monitoring
- PLUS
- mouvements
- plusieurs
- Besoin
- Ni
- réseau et
- Nouveauté
- nœud
- Répartition des nœuds
- nœuds
- nombre
- offrant
- ONE
- fonctionner
- opération
- Opérations
- de commander
- original
- Autre
- coupure de courant
- Les pannes
- global
- accablé
- Palo Alto
- les pièces
- passionné
- effectuer
- performant
- effectuer
- Place
- Platon
- Intelligence des données Platon
- PlatonDonnées
- veuillez cliquer
- possible
- Post
- alimenté
- pratique
- pratiques
- Prévisible
- empêcher
- précédemment
- primaire
- Directeur
- d'ouvrabilité
- processus
- traitement
- correct
- propriété
- fournir
- fournit
- disposition
- vite.
- gamme
- Lire
- en temps réel
- Les raisons
- récemment
- recommandé
- Récupère
- récupération
- Prix Réduit
- réduire
- en relation
- libérer
- fiable
- restant
- remplacer
- répondre
- représentation
- représente
- a besoin
- résilient
- Resources
- résultat
- retourner
- Retours
- Saïd
- même
- évolutive
- Escaliers intérieurs
- mise à l'échelle
- scénarios
- Rechercher
- Section
- sécurisé
- service
- Services
- set
- installation
- montré
- similaires
- depuis
- unique
- SIX
- biais
- So
- Logiciels
- Software Engineer
- Solutions
- Résoudre
- quelques
- Space
- spécialisation
- Stabilité
- Commencer
- Encore
- storage
- fortement
- tel
- soudain
- suffisant
- Support
- Surface
- Système
- Prenez
- prend
- Les technologies
- La
- leur
- donc
- Avec
- débit
- fois
- à
- aujourd'hui
- tolérance
- trop
- Total
- circulation
- déclencher
- oui
- Tournant
- types
- Inattendu
- Mises à jour
- a actualisé
- utilisé
- Valeurs
- variété
- visualisation
- attendez
- web
- services Web
- Site Web
- qui
- tout en
- sera
- dans les
- sans
- de travail
- pourra
- écrire
- Votre
- zéphyrnet
- zones