Image par l'éditeur
Faits marquants
- Le test t est un test statistique qui peut être utilisé pour déterminer s'il existe une différence significative entre les moyennes de deux échantillons de données indépendants.
- Nous illustrons comment un test t peut être appliqué à l'aide de l'ensemble de données iris et de la bibliothèque Scipy de Python.
Le test t est un test statistique qui peut être utilisé pour déterminer s'il existe une différence significative entre les moyennes de deux échantillons de données indépendants. Dans ce didacticiel, nous illustrons la version la plus basique du test t, pour laquelle nous supposerons que les deux échantillons ont des variances égales. D'autres versions avancées du test t incluent le test t de Welch, qui est une adaptation du test t, et est plus fiable lorsque les deux échantillons ont des variances inégales et éventuellement des tailles d'échantillon inégales.
La statistique t ou la valeur t est calculée comme suit :
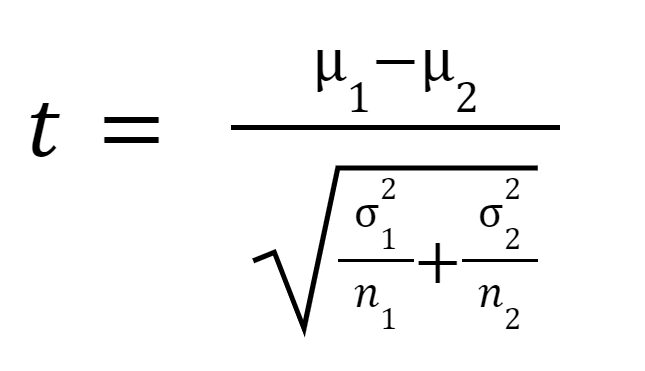
De
est la moyenne de l'échantillon 1,
est la moyenne de l'échantillon 2,
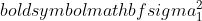 est la variance de l'échantillon 1,
est la variance de l'échantillon 1, 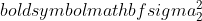 est la variance de l'échantillon 2,
est la variance de l'échantillon 2, 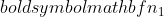 est la taille de l'échantillon de l'échantillon 1, et
est la taille de l'échantillon de l'échantillon 1, et 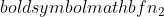 est la taille de l'échantillon de l'échantillon 2.
est la taille de l'échantillon de l'échantillon 2.
Pour illustrer l'utilisation du test t, nous allons montrer un exemple simple utilisant l'ensemble de données de l'iris. Supposons que nous observions deux échantillons indépendants, par exemple des longueurs de sépales floraux, et que nous examinions si les deux échantillons provenaient de la même population (par exemple la même espèce de fleur ou deux espèces avec des caractéristiques de sépales similaires) ou de deux populations différentes.
Le test t quantifie la différence entre les moyennes arithmétiques des deux échantillons. La valeur de p quantifie la probabilité d'obtenir les résultats observés, en supposant que l'hypothèse nulle (que les échantillons sont tirés de populations ayant les mêmes moyennes de population) est vraie. Une valeur de p supérieure à un seuil choisi (par exemple 5 % ou 0.05) indique qu'il est peu probable que notre observation se soit produite par hasard. Par conséquent, nous acceptons l'hypothèse nulle de moyennes de population égales. Si la valeur de p est inférieure à notre seuil, alors nous avons des preuves contre l'hypothèse nulle de moyennes de population égales.
Entrée de test T
Les entrées ou paramètres nécessaires pour effectuer un test t sont :
- Deux tableaux a ainsi que b contenant les données de l'échantillon 1 et de l'échantillon 2
Sorties de test T
Le test t renvoie les éléments suivants :
- Les statistiques t calculées
- La valeur p
Importer les bibliothèques nécessaires
import numpy as np
from scipy import stats import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
Charger l'ensemble de données Iris
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
Calculer les moyennes d'échantillon et les variances d'échantillon
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Mettre en œuvre le test t
stats.ttest_ind(a_1, b_1, equal_var = False)
Sortie
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
Sortie
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
Sortie
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)Observations
Nous observons que l'utilisation de "true" ou "false" pour le paramètre "equal-var" ne change pas beaucoup les résultats du test t. Nous observons également que l'échange de l'ordre des tableaux d'échantillons a_1 et b_1 donne une valeur de test t négative, mais ne change pas l'amplitude de la valeur de test t, comme prévu. Étant donné que la valeur de p calculée est bien supérieure à la valeur seuil de 0.05, nous pouvons rejeter l'hypothèse nulle selon laquelle la différence entre les moyennes de l'échantillon 1 et de l'échantillon 2 est significative. Cela montre que les longueurs des sépales pour l'échantillon 1 et l'échantillon 2 ont été tirées des mêmes données de population.
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
Calculer les moyennes d'échantillon et les variances d'échantillon
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Mettre en œuvre le test t
stats.ttest_ind(a_1, b_1, equal_var = False)
Sortie
stats.ttest_ind(a_1, b_1, equal_var = False)Observations
Nous observons que l'utilisation d'échantillons de taille inégale ne modifie pas significativement la statistique t et la valeur p.
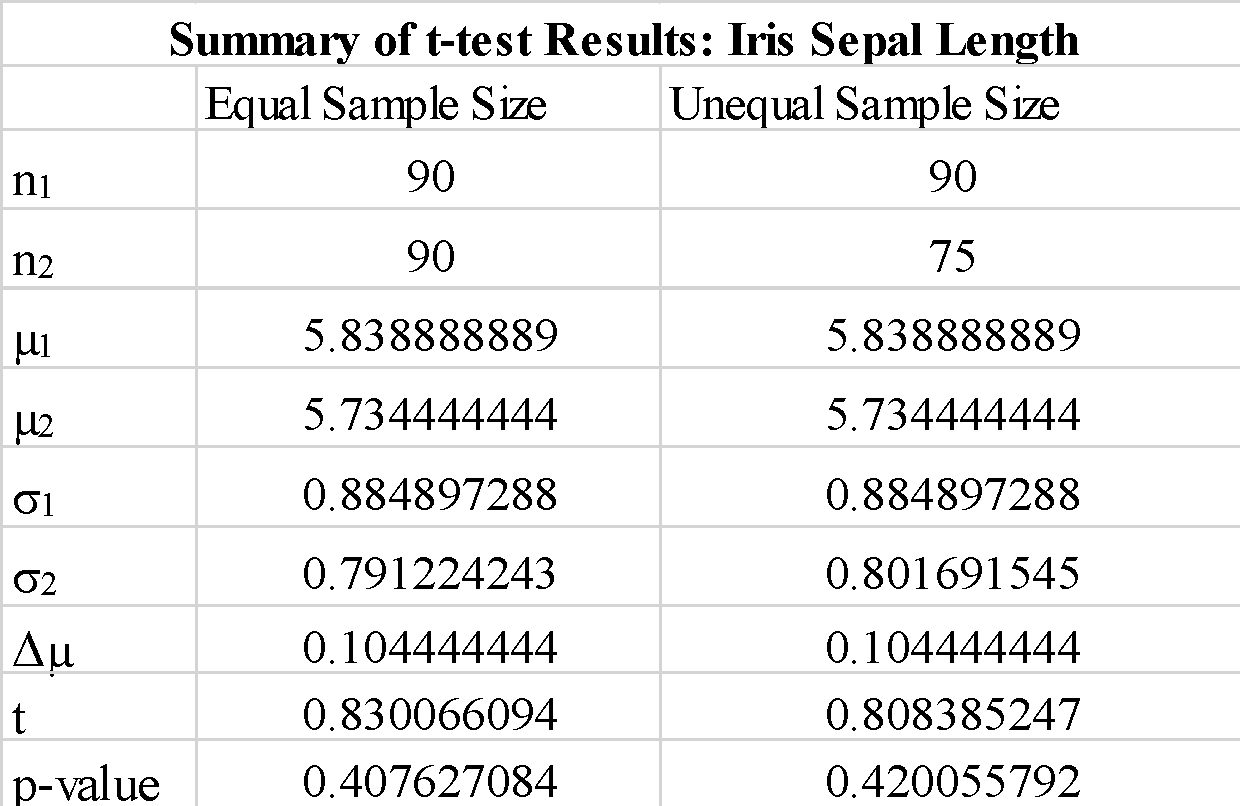
En résumé, nous avons montré comment un simple test t pouvait être implémenté à l'aide de la bibliothèque scipy en python.
Benjamin O.Tayo est un physicien, un éducateur en science des données et un écrivain, ainsi que le propriétaire de DataScienceHub. Auparavant, Benjamin enseignait l'ingénierie et la physique à l'Université de Central Oklahoma, à l'Université du Grand Canyon et à l'Université de l'État de Pittsburgh.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://www.kdnuggets.com/2023/01/performing-ttest-python.html?utm_source=rss&utm_medium=rss&utm_campaign=performing-a-t-test-in-python
- 1
- 7
- 9
- a
- Accepter
- Avancée
- à opposer à
- ainsi que
- appliqué
- Essentiel
- Benjamin
- jusqu'à XNUMX fois
- calculé
- central
- Chance
- Change
- caractéristiques
- choisi
- considérant
- pourriez
- données
- science des données
- ensembles de données
- Déterminer
- différence
- différent
- tiré
- ENGINEERING
- preuve
- exemple
- attendu
- fleur
- Abonnement
- suit
- De
- Comment
- HTTPS
- mis en œuvre
- importer
- in
- comprendre
- indépendant
- indique
- KDnuggetsGenericName
- plus importantes
- Bibliothèque
- matplotlib
- veux dire
- PLUS
- (en fait, presque toutes)
- nécessaire
- négatif
- numpy
- observer
- obtention
- a eu lieu
- Oklahoma
- de commander
- Autre
- propriétaire
- paramètre
- paramètres
- effectuer
- Physique
- Pittsburgh
- Platon
- Intelligence des données Platon
- PlatonDonnées
- population
- populations
- précédemment
- probabilité
- Python
- fiable
- Résultats
- Retours
- même
- Sciences
- montrer
- montré
- Spectacles
- significative
- de façon significative
- similaires
- étapes
- depuis
- Taille
- tailles
- faibles
- So
- Région
- statistique
- stats
- RÉSUMÉ
- Enseignement
- tester
- La
- donc
- порог
- à
- oui
- tutoriel
- utilisé
- Plus-value
- version
- que
- qui
- sera
- écrivain
- rendements
- zéphyrnet





