Les clients des services financiers utilisent des données provenant de différentes sources et provenant de différentes fréquences, notamment des ensembles de données en temps réel, par lots et archivés. De plus, ils ont besoin d’architectures de streaming pour gérer les volumes d’échanges croissants, la volatilité des marchés et les exigences réglementaires. Voici quelques-uns des principaux cas d’utilisation commerciale qui mettent en évidence ce besoin :
- Rapports commerciaux – Depuis la crise financière mondiale de 2007-2008, les régulateurs ont accru leurs exigences et leur contrôle sur les rapports réglementaires. Les régulateurs ont mis davantage l'accent sur la protection du consommateur grâce à la déclaration des transactions (généralement T+1, c'est-à-dire 1 jour ouvrable après la date de la transaction) et sur l'augmentation de la transparence des marchés via des exigences de déclaration des transactions en temps quasi réel.
- La gestion des risques – À mesure que les marchés de capitaux deviennent plus complexes et que les régulateurs lancent de nouveaux cadres de risque, tels que Revue fondamentale du portefeuille de négociation (FRTB) et Bâle III, les institutions financières cherchent à augmenter la fréquence des calculs du risque global de marché, du risque de liquidité, du risque de contrepartie et d'autres mesures de risque, et souhaitent se rapprocher le plus possible des calculs en temps réel.
- Qualité et optimisation des échanges – Afin de surveiller et d'optimiser la qualité des transactions, vous devez évaluer en permanence les caractéristiques du marché telles que le volume, la direction, la profondeur du marché, le taux de remplissage et d'autres critères liés à la réalisation des transactions. La qualité des échanges n'est pas seulement liée à la performance du courtier, mais constitue également une exigence des régulateurs, à commencer par MIFID II.
Le défi est de trouver une solution capable de gérer ces sources disparates, ces fréquences variées et ces exigences de consommation à faible latence. La solution doit être évolutive, rentable et simple à adopter et à exploiter. Redshift d'Amazon des fonctionnalités telles que l'ingestion de streaming, Amazon Aurora intégration zéro ETL, et partage de données avec Échange de données AWS permettre un traitement en temps quasi réel pour les rapports commerciaux, la gestion des risques et l'optimisation des transactions.
Dans cet article, nous proposons une architecture de solution qui décrit comment vous pouvez traiter des données provenant de trois types différents de sources (données de streaming, transactionnelles et de référence tierces) et les regrouper dans Amazon Redshift pour les rapports de business intelligence (BI).
Vue d'ensemble de la solution
Cette architecture de solution est créée en privilégiant une approche low-code/no-code avec les principes directeurs suivants :
- Facilité d’utilisation – Il devrait être moins complexe à mettre en œuvre et à exploiter avec des interfaces utilisateur intuitives
- Evolutif – Vous devriez pouvoir augmenter et diminuer de manière transparente la capacité à la demande
- Intégration native – Les composants doivent s’intégrer sans connecteurs ni logiciels supplémentaires
- Rentable – Il doit offrir un rapport prix/performance équilibré
- Peu d'entretien – Cela devrait nécessiter moins de frais de gestion et de fonctionnement
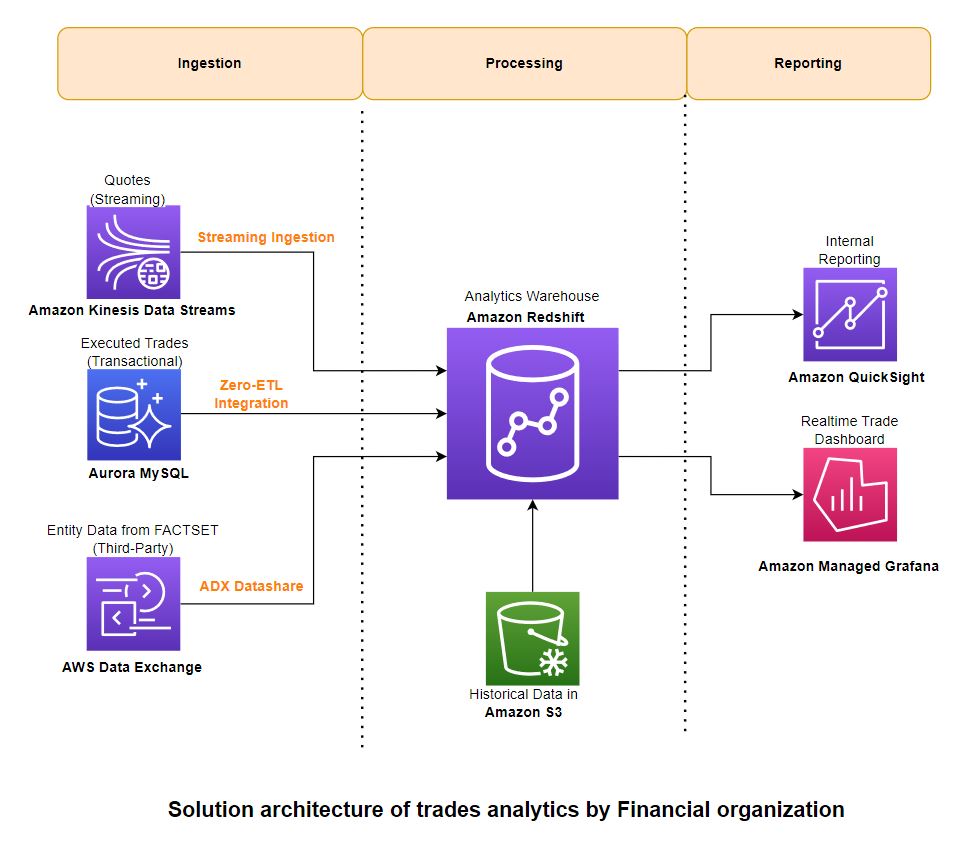
Le diagramme suivant illustre l'architecture de la solution et la manière dont ces principes directeurs ont été appliqués aux composants d'ingestion, d'agrégation et de reporting.
![]()
Déployez la solution
Vous pouvez utiliser ce qui suit AWS CloudFormation modèle pour déployer la solution.
![]()
Cette pile crée les ressources suivantes et les autorisations nécessaires pour intégrer les services :
Ingestion
Pour ingérer des données, vous utilisez Ingestion de flux Amazon Redshift pour charger des données en streaming à partir du flux de données Kinesis. Pour les données transactionnelles, vous utilisez le Intégration Redshift zéro-ETL avec Amazon Aurora MySQL. Pour les données de référence tierces, vous bénéficiez de Partages de données AWS Data Exchange. Ces fonctionnalités vous permettent de créer rapidement des pipelines de données évolutifs, car vous pouvez augmenter la capacité des partitions Kinesis Data Streams, calculer pour les sources et cibles zéro ETL et calculer Redshift pour les partages de données lorsque vos données augmentent. L'ingestion de streaming Redshift et l'intégration zéro ETL sont des solutions low-code/no-code que vous pouvez créer avec des SQL simples sans investir beaucoup de temps et d'argent dans le développement de code personnalisé complexe.
Pour les données utilisées pour créer cette solution, nous nous sommes associés à FactSet, l'un des principaux fournisseurs de données financières, d'analyses et de technologies ouvertes. FactSet a plusieurs ensembles de données disponible sur le marché AWS Data Exchange, que nous avons utilisé comme données de référence. Nous avons également utilisé FactSet solutions de données de marché pour les cotations et les transactions historiques et en streaming.
En cours
Les données sont traitées dans Amazon Redshift selon une méthodologie d'extraction, de chargement et de transformation (ELT). Avec une évolutivité pratiquement illimitée et une isolation des charges de travail, ELT est plus adapté aux solutions d'entrepôt de données cloud.
Vous utilisez l'ingestion de streaming Redshift pour l'ingestion en temps réel de cotations de streaming (offre/demande) du flux de données Kinesis directement dans une vue matérialisée de streaming et traitez les données à l'étape suivante à l'aide de PartiQL pour analyser les entrées du flux de données. Notez que les vues matérialisées en streaming diffèrent des vues matérialisées classiques en termes de fonctionnement de l'actualisation automatique et de commandes SQL de gestion des données utilisées. Faire référence à Considérations sur l’ingestion de streaming pour en savoir plus.
Vous utilisez l'intégration zéro ETL Aurora pour ingérer des données transactionnelles (trades) à partir de sources OLTP. Faire référence à Travailler avec des intégrations zéro ETL pour les sources actuellement prises en charge. Vous pouvez combiner les données de toutes ces sources à l'aide de vues et utiliser des procédures stockées pour mettre en œuvre des règles de transformation commerciale telles que le calcul de moyennes pondérées entre les secteurs et les bourses.
Les volumes de données historiques sur les échanges et les cotations sont énormes et ne sont souvent pas interrogés fréquemment. Vous pouvez utiliser Spectre Amazon Redshift pour accéder à ces données sur place sans les charger dans Amazon Redshift. Vous créez des tables externes pointant vers des données dans Service de stockage simple Amazon (Amazon S3) et interrogez de la même manière que vous interrogez n'importe quelle autre table locale dans Amazon Redshift. Plusieurs entrepôts de données Redshift peuvent interroger simultanément les mêmes ensembles de données dans Amazon S3 sans qu'il soit nécessaire de faire des copies des données pour chaque entrepôt de données. Cette fonctionnalité simplifie l'accès aux données externes sans écrire de processus ETL complexes et améliore la facilité d'utilisation de la solution globale.
Passons en revue quelques exemples de requêtes utilisées pour analyser les cotations et les transactions. Nous utilisons les tables suivantes dans les exemples de requêtes :
- dt_hist_quote – Données de cotations historiques contenant le prix acheteur et le volume, le prix vendeur et le volume, ainsi que les bourses et les secteurs. Vous devez utiliser des ensembles de données pertinents dans votre organisation qui contiennent ces attributs de données.
- dt_hist_trades – Données historiques sur les transactions contenant les prix négociés, le volume, le secteur et les détails de l’échange. Vous devez utiliser des ensembles de données pertinents dans votre organisation qui contiennent ces attributs de données.
- faitset_sector_map – Cartographie entre secteurs et échanges. Vous pouvez l'obtenir auprès du Ensemble de données ADX FactSet Fundamentals.
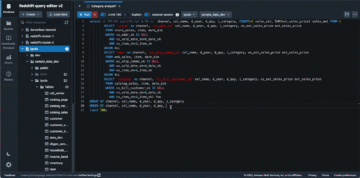
Exemple de requête pour analyser les cotations historiques
Vous pouvez utiliser la requête suivante pour rechercher les spreads moyens pondérés sur les cotations :
Exemple de requête pour analyser les transactions historiques
Vous pouvez utiliser la requête suivante pour trouver $-volume sur les transactions par bourse détaillée, par secteur et par bourse majeure (NYSE et Nasdaq) :
Rapports
Vous pouvez utiliser Amazon QuickSight ainsi que le Grafana géré par Amazon respectivement pour la BI et le reporting en temps réel. Ces services s'intègrent nativement à Amazon Redshift sans qu'il soit nécessaire d'utiliser des connecteurs ou des logiciels supplémentaires entre les deux.
Vous pouvez exécuter une requête directe à partir de QuickSight pour les rapports et tableaux de bord BI. Avec QuickSight, vous pouvez également stocker localement des données dans le cache SPICE avec actualisation automatique pour une faible latence. Faire référence à Autorisation des connexions d'Amazon QuickSight aux clusters Amazon Redshift pour plus de détails sur la façon d'intégrer QuickSight à Amazon Redshift.
Vous pouvez utiliser Amazon Managed Grafana pour obtenir des tableaux de bord commerciaux en temps quasi réel qui sont actualisés toutes les quelques secondes. Les tableaux de bord en temps réel pour surveiller les latences d'ingestion des échanges sont créés à l'aide de Grafana et les données proviennent de vues système dans Amazon Redshift. Faire référence à Utilisation de la source de données Amazon Redshift pour savoir comment configurer Amazon Redshift comme source de données pour Grafana.
Les utilisateurs qui interagissent avec les systèmes de reporting réglementaire comprennent des analystes, des gestionnaires de risques, des opérateurs et d'autres personnes prenant en charge les opérations commerciales et technologiques. En plus de générer des rapports réglementaires, ces équipes ont besoin d'une visibilité sur la santé des systèmes de reporting.
Analyse des cotations historiques
Dans cette section, nous explorons quelques exemples d'analyse de citations historiques du Amazon QuickSight tableau de bord.
Spread moyen pondéré par secteurs
Le graphique suivant montre l'agrégation quotidienne par secteur des spreads acheteur-vendeur moyens pondérés de toutes les transactions individuelles sur le NASDAQ et le NYSE sur 3 mois. Pour calculer le spread quotidien moyen, chaque spread est pondéré par la somme du volume acheteur et du volume vendeur en dollars. La requête pour générer ce graphique traite 103 milliards de points de données au total, relie chaque transaction à la table de référence sectorielle et s'exécute en moins de 10 secondes.
![]()
Spread moyen pondéré par bourses
Le graphique suivant montre l'agrégation quotidienne des spreads acheteur-vendeur moyens pondérés de toutes les transactions individuelles sur le NASDAQ et le NYSE sur 3 mois. La méthodologie de calcul et les mesures de performances des requêtes sont similaires à celles du graphique précédent.
![]()
Analyse historique des transactions
Dans cette section, nous explorons quelques exemples d'analyses historiques des métiers du Amazon QuickSight tableau de bord.
Volumes d'échanges par secteur
Le graphique suivant montre l'agrégation quotidienne par secteur de toutes les transactions individuelles sur le NASDAQ et le NYSE sur 3 mois. La requête permettant de générer ce graphique traite 3.6 milliards de transactions au total, relie chaque transaction à la table de référence sectorielle et s'exécute en moins de 5 secondes.
![]()
Volumes d’échanges pour les principales bourses
Le graphique suivant montre l'agrégation quotidienne par groupe de bourse de toutes les transactions individuelles sur 3 mois. La requête permettant de générer ce graphique présente des mesures de performances similaires à celles du graphique précédent.
![]()
Tableaux de bord en temps réel
La surveillance et l'observabilité sont une exigence importante pour toute application commerciale critique telle que les systèmes de reporting commercial, de gestion des risques et de gestion commerciale. Outre les mesures au niveau du système, il est également important de surveiller les indicateurs de performance clés en temps réel afin que les opérateurs puissent être alertés et réagir le plus rapidement possible aux événements ayant un impact sur l'activité. Pour cette démonstration, nous avons créé des tableaux de bord dans Grafana qui surveillent respectivement le retard des données de cotation et de négociation du flux de données Kinesis et Aurora.
Le tableau de bord du délai d'ingestion des devis indique le temps nécessaire pour que chaque enregistrement de devis soit ingéré à partir du flux de données et soit disponible pour une interrogation dans Amazon Redshift.
![]()
Le tableau de bord du délai d'ingestion des échanges indique le temps nécessaire pour qu'une transaction dans Aurora soit disponible dans Amazon Redshift pour interrogation.
![]()
Nettoyer
Pour nettoyer vos ressources, supprimez la pile que vous avez déployée à l'aide d'AWS CloudFormation. Pour obtenir des instructions, reportez-vous à Suppression d'une pile sur la console AWS CloudFormation.
Conclusion
Des volumes croissants d'activités de négociation, une gestion des risques plus complexe et des exigences réglementaires renforcées conduisent les sociétés de marchés de capitaux à adopter le traitement des données en temps réel et quasi-réel, même sur les plateformes de mid-office et de back-office où le traitement en fin de journée et pendant la nuit était la norme. Dans cet article, nous avons montré comment vous pouvez utiliser les fonctionnalités d'Amazon Redshift pour une utilisation facile, une maintenance réduite et une rentabilité. Nous avons également discuté des intégrations interservices pour ingérer des données de marché en streaming, traiter les mises à jour des bases de données OLTP et utiliser des données de référence tierces sans avoir à effectuer un traitement ETL ou ELT complexe et coûteux avant de rendre les données disponibles à des fins d'analyse et de reporting.
Veuillez nous contacter si vous avez besoin de conseils pour mettre en œuvre cette solution. Faire référence à Analyses en temps réel avec l'ingestion de streaming Amazon Redshift, Guide de démarrage pour l'analyse opérationnelle en temps quasi réel à l'aide de l'intégration Amazon Aurora zéro ETL avec Amazon Redshift ainsi que Travailler avec les partages de données AWS Data Exchange en tant que producteur pour plus d'information.
À propos des auteurs
![]() Satesh Sonti est un architecte de solutions spécialisé en analytique basé à Atlanta, spécialisé dans la création de plates-formes de données d'entreprise, d'entreposage de données et de solutions d'analyse. Il a plus de 18 ans d'expérience dans la création d'actifs de données et dans la direction de programmes de plateformes de données complexes pour des clients bancaires et d'assurance à travers le monde.
Satesh Sonti est un architecte de solutions spécialisé en analytique basé à Atlanta, spécialisé dans la création de plates-formes de données d'entreprise, d'entreposage de données et de solutions d'analyse. Il a plus de 18 ans d'expérience dans la création d'actifs de données et dans la direction de programmes de plateformes de données complexes pour des clients bancaires et d'assurance à travers le monde.
![]() Alket Memushaj travaille en tant qu'architecte principal au sein de l'équipe de développement du marché des services financiers chez AWS. Alket est responsable de la stratégie technique pour les marchés de capitaux, travaillant avec des partenaires et des clients pour déployer des applications tout au long du cycle de vie des transactions sur le cloud AWS, y compris la connectivité du marché, les systèmes de négociation et les plateformes d'analyse et de recherche pré- et post-négociation.
Alket Memushaj travaille en tant qu'architecte principal au sein de l'équipe de développement du marché des services financiers chez AWS. Alket est responsable de la stratégie technique pour les marchés de capitaux, travaillant avec des partenaires et des clients pour déployer des applications tout au long du cycle de vie des transactions sur le cloud AWS, y compris la connectivité du marché, les systèmes de négociation et les plateformes d'analyse et de recherche pré- et post-négociation.
![]() Rubén Falk est un spécialiste des marchés financiers axé sur l'IA, les données et l'analyse. Ruben consulte les acteurs des marchés de capitaux sur l'architecture de données moderne et les processus d'investissement systématiques. Il a rejoint AWS après avoir travaillé chez S&P Global Market Intelligence où il était responsable mondial des solutions de gestion des investissements.
Rubén Falk est un spécialiste des marchés financiers axé sur l'IA, les données et l'analyse. Ruben consulte les acteurs des marchés de capitaux sur l'architecture de données moderne et les processus d'investissement systématiques. Il a rejoint AWS après avoir travaillé chez S&P Global Market Intelligence où il était responsable mondial des solutions de gestion des investissements.
![]() Jeff Wilson est un spécialiste mondial du marketing de marché avec 15 ans d'expérience dans le domaine des plateformes analytiques. Son objectif actuel est de partager les avantages de l'utilisation d'Amazon Redshift, l'entrepôt de données cloud natif d'Amazon. Jeff est basé en Floride et travaille chez AWS depuis 2019.
Jeff Wilson est un spécialiste mondial du marketing de marché avec 15 ans d'expérience dans le domaine des plateformes analytiques. Son objectif actuel est de partager les avantages de l'utilisation d'Amazon Redshift, l'entrepôt de données cloud natif d'Amazon. Jeff est basé en Floride et travaille chez AWS depuis 2019.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/combine-transactional-streaming-and-third-party-data-on-amazon-redshift-for-financial-services/
- :possède
- :est
- :ne pas
- :où
- ][p
- $UP
- 1
- 10
- 100
- 130
- 15 ans
- 15%
- 150
- 16
- 20
- 2019
- 27
- 30
- a
- Capable
- Qui sommes-nous
- accès
- accès
- à travers
- activité
- Supplémentaire
- En outre
- adhérant
- adopter
- Avantage
- adx
- Après
- agrégat
- agrégation
- AI
- Tous
- permettre
- aussi
- Amazon
- Grafana géré par Amazon
- Amazon QuickSight
- Amazon Web Services
- montant
- an
- selon une analyse de l’Université de Princeton
- Analystes
- Analytique
- analytique
- l'analyse
- ainsi que le
- tous
- A PART
- Application
- applications
- appliqué
- une approche
- architecture
- architectures
- SONT
- AS
- demander
- Outils
- At
- Atlanta
- attributs
- Aurora
- auto
- disponibles
- moyen
- AWS
- AWS CloudFormation
- b
- Équilibré
- Services bancaires
- basé
- BE
- car
- devenez
- était
- before
- repères
- avantages.
- jusqu'à XNUMX fois
- offre
- Milliards
- à
- tous les deux
- courtier
- construire
- Développement
- construit
- la performance des entreprises
- l'intelligence d'entreprise
- Transformation de l'entreprise
- mais
- by
- cachette
- calculer
- le calcul
- calcul
- CAN
- capacités
- Compétences
- capital
- Marchés de capitaux
- maisons
- cas
- Cboe
- challenge
- caractéristiques
- Graphique
- espace extérieur plus propre,
- CLIENTS
- Fermer
- le cloud
- code
- combiner
- comment
- achèvement
- complexe
- composants électriques
- complet
- calcul
- Connexions
- Connectivité
- consommateur
- consommation
- contiennent
- continuellement
- copies
- engendrent
- créée
- crée des
- crise
- critique
- Courant
- Lecture
- Customiser
- Clients
- Tous les jours
- tableau de bord
- tableaux de bord
- données
- D'échange de données
- gestion des données
- Plateforme de données
- points de données
- informatique
- partage de données
- entrepôt de données
- entrepôts de données
- bases de données
- ensembles de données
- Date
- journée
- diminuer
- retarder
- livrer
- demandes
- démontré
- déployer
- déployé
- profondeur
- décrit
- détaillé
- détails
- développement
- Développement
- équipe de développement
- diagramme
- différent
- direction
- directement
- discuté
- disparate
- Dollar
- chacun
- facilité
- facilité d'utilisation
- embrasser
- permettre
- fin
- améliorée
- Améliore
- Entreprise
- Ether (ETH)
- évaluer
- Pourtant, la
- événements
- Chaque
- exemples
- échange
- Échanges
- cher
- Découvrez
- explorez
- externe
- extrait
- Fonctionnalité
- Fonctionnalités:
- few
- remplir
- la traduction de documents financiers
- crise financière
- données financières
- Institutions financières
- services financiers
- Trouvez
- entreprises
- Floride
- Focus
- concentré
- Abonnement
- Pour
- cadres
- La fréquence
- fréquemment
- de
- Notions de base
- générer
- générateur
- obtenez
- Global
- financière mondiale
- Crise financière mondiale
- marché global
- globe
- Aller au marché
- Réservation de groupe
- Croissance
- Pousse
- l'orientation
- guide
- guidage
- manipuler
- Vous avez
- ayant
- he
- front
- Santé
- Souligner
- sa
- historique
- Comment
- How To
- HTML
- http
- HTTPS
- majeur
- if
- illustre
- Mettre en oeuvre
- la mise en œuvre
- important
- in
- comprendre
- inclut
- Y compris
- Améliore
- increased
- Indicateurs
- individuel
- d'information
- entrées
- les établissements privés
- Des instructions
- Assurance
- intégrer
- l'intégration
- intégrations
- Intelligence
- interagir
- développement
- intuitif
- sueñortiendo
- un investissement
- seul
- IT
- rejoindre
- rejoint
- Joint
- jpg
- ACTIVITES
- Flux de données Kinesis
- Latence
- lancer
- conduisant
- APPRENTISSAGE
- moins
- vos produits
- comme
- Liquidité
- charge
- chargement
- locales
- localement
- recherchez-
- Faible
- facile
- majeur
- a prendre une
- Fabrication
- gérés
- gestion
- Gestionnaires
- cartographie
- Marché
- Données du marché
- Volatilité du marché
- marché
- Marchés
- sens
- des mesures
- Méthodologie
- Métrique
- Villas Modernes
- de l'argent
- Surveiller
- Stack monitoring
- mois
- PLUS
- plusieurs
- MySQL
- Nasdaq
- indigène
- nativement
- nécessaire
- Besoin
- Nouveauté
- New York
- New York Stock Exchange
- next
- noter
- NYSE
- obtenir
- of
- souvent
- on
- uniquement
- ouvert
- fonctionner
- opérationnel
- Opérations
- opérateurs
- à mettre en œuvre pour gérer une entreprise rentable. Ce guide est basé sur trois décennies d'expérience
- Optimiser
- or
- de commander
- organisation
- Autre
- ande
- plus de
- global
- du jour au lendemain
- participants
- en partenariat
- partenaires,
- effectuer
- performant
- autorisations
- Place
- mis
- plateforme
- Plateformes
- Platon
- Intelligence des données Platon
- PlatonDonnées
- des notes bonus
- possible
- Post
- post-transaction
- précédant
- prix
- Directeur
- principes
- priorisation
- procédures
- processus
- traité
- les process
- traitement
- Programmes
- protéger
- fournir
- de voiture.
- qualité
- requêtes
- question
- vite.
- Devis
- citations
- Tarif
- nous joindre
- réal
- en temps réel
- record
- reportez-vous
- référence
- Standard
- Régulateurs
- régulateurs
- en relation
- pertinent
- Rapports
- Rapports
- exigent
- exigence
- Exigences
- un article
- Resources
- respectivement
- Réagir
- responsables
- Avis
- Analyse
- la gestion des risques
- Courir
- fonctionne
- S & P
- S&P Global
- même
- évolutive
- Escaliers intérieurs
- examen minutieux
- de façon transparente
- secondes
- Section
- secteur
- Secteurs
- Sélectionner
- Services
- plusieurs
- Partages
- partage
- devrait
- Spectacles
- significative
- similaires
- De même
- étapes
- simplifie
- depuis
- So
- Logiciels
- sur mesure
- Solutions
- quelques
- disponible
- Identifier
- source
- Sources
- spécialiste
- spécialisé
- épice
- propagation
- les pâtes à tartiner
- SQL
- empiler
- Standard
- j'ai commencé
- Commencez
- étapes
- stock
- Bourse des valeurs
- storage
- Boutique
- stockée
- simple
- de Marketing
- courant
- streaming
- flux
- tel
- somme
- Support
- Appareils
- combustion propre
- Système
- table
- Prenez
- prend
- objectifs
- équipe
- équipes
- Technique
- Technologie
- modèle
- conditions
- que
- qui
- Les
- leur
- Les
- puis
- Ces
- l'ont
- des tiers.
- données de tiers
- this
- ceux
- trois
- Avec
- fiable
- à
- Total
- commerce
- échangés
- métiers
- Commerce
- transaction
- transactionnel
- Transformer
- De La Carrosserie
- Transparence
- types
- typiquement
- sous
- illimité
- Actualités
- us
- utilisé
- d'utiliser
- Utilisateur
- utilisateurs
- en utilisant
- via
- Voir
- vues
- pratiquement
- définition
- Volatilité
- le volume
- volumes
- souhaitez
- Entrepots
- Entreposage
- était
- we
- web
- services Web
- poids
- ont été
- quand
- qui
- WHO
- comprenant
- sans
- de travail
- vos contrats
- écriture
- yaml
- années
- york
- you
- Votre
- zéphyrnet