Image par auteur
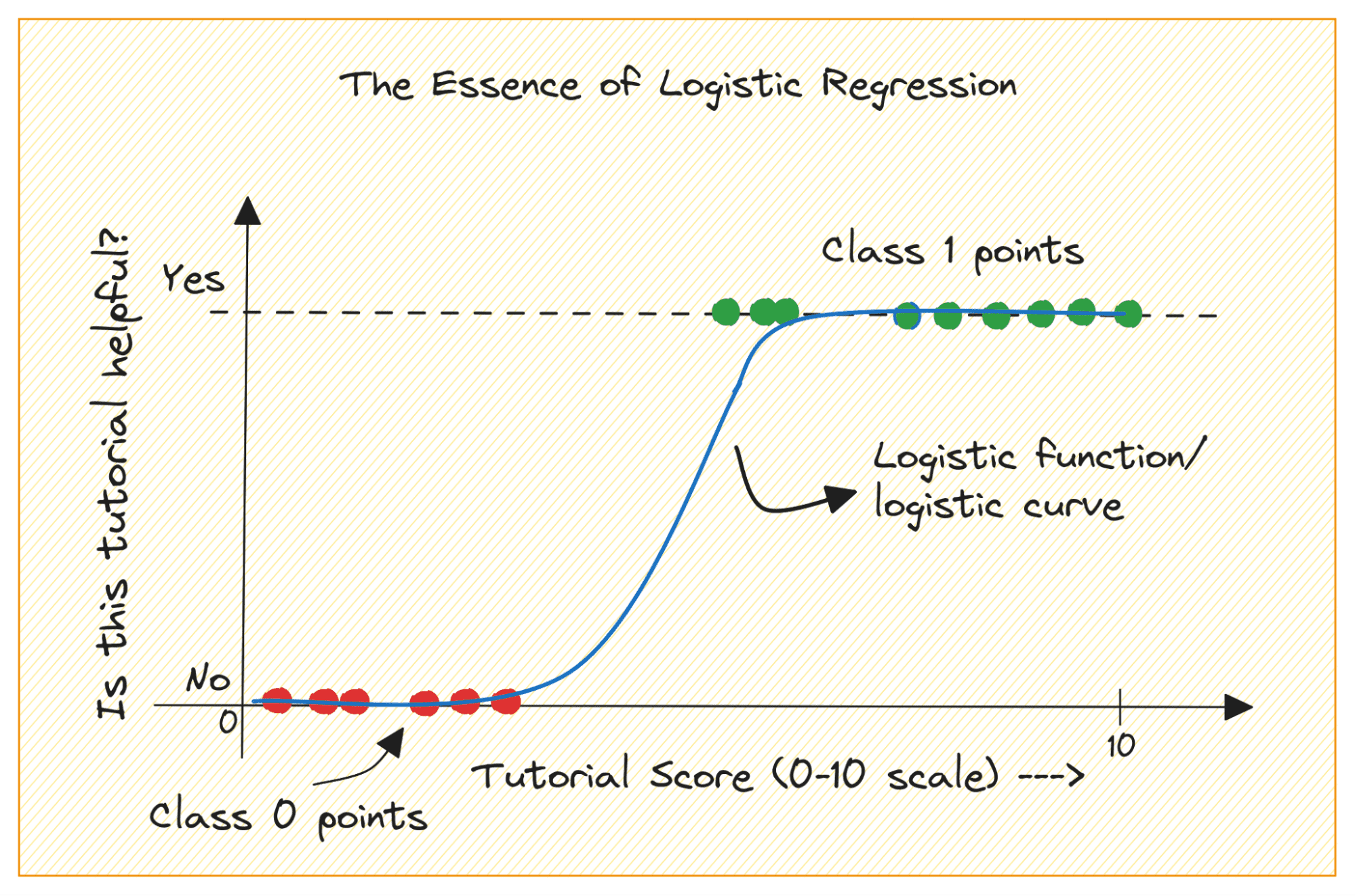
When you are getting started with machine learning, logistic regression is one of the first algorithms you’ll add to your toolbox. It’s a simple and robust algorithm, commonly used for binary classification tasks.
Considérons un problème de classification binaire avec les classes 0 et 1. La régression logistique adapte une fonction logistique ou sigmoïde aux données d'entrée et prédit la probabilité qu'un point de données de requête appartienne à la classe 1. Intéressant, non ?
Dans ce didacticiel, nous découvrirons la régression logistique de A à Z en couvrant :
- La fonction logistique (ou sigmoïde)
- Comment passer de la régression linéaire à la régression logistique
- Comment fonctionne la régression logistique
Enfin, nous construirons un modèle de régression logistique simple pour classer les retours RADAR de l'ionosphère.
Before we learn more about logistic regression, let’s review how the logistic function works. The logistic (or sigmoid function) is given by:

Lorsque vous tracez la fonction sigmoïde, cela ressemblera à ceci :
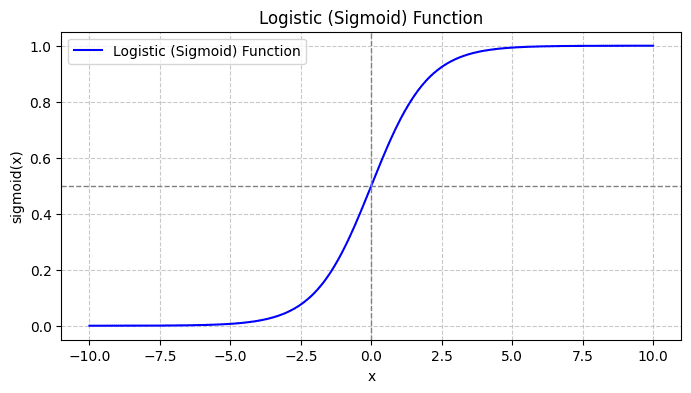
D'après le tracé, nous voyons que :
- Lorsque x = 0, σ(x) prend la valeur 0.5.
- Lorsque x tend vers +∞, σ(x) tend vers 1.
- Lorsque x tend vers -∞, σ(x) tend vers 0.
Ainsi, pour toutes les entrées réelles, la fonction sigmoïde les écrase pour prendre des valeurs comprises dans la plage [0, 1].
Let’s first discuss why we cannot use linear regression for a binary classification problem.
Dans un problème de classification binaire, le résultat est une étiquette catégorielle (0 ou 1). Étant donné que la régression linéaire prédit des résultats à valeur continue qui peuvent être inférieurs à 0 ou supérieurs à 1, cela n'a pas de sens pour le problème en question.
De plus, une ligne droite n’est peut-être pas la meilleure solution lorsque les étiquettes de sortie appartiennent à l’une des deux catégories.
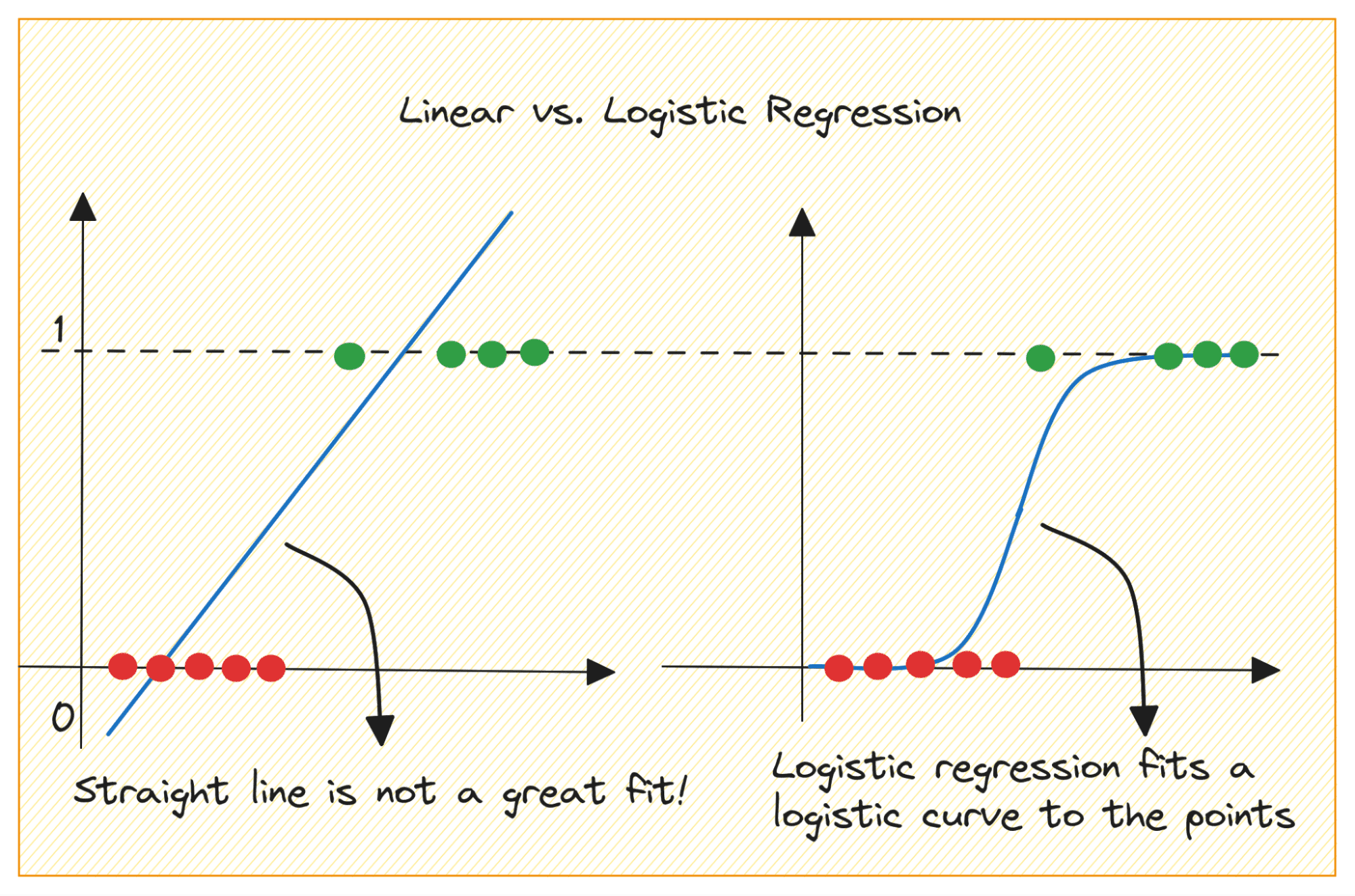
Image par auteur
Alors, comment passer de la régression linéaire à la régression logistique ? En régression linéaire, le résultat prédit est donné par :
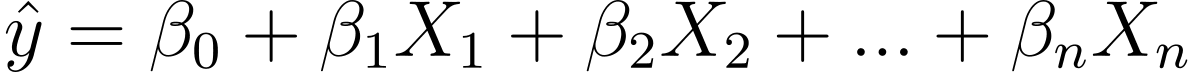
Où les βs sont les coefficients et X_is sont les prédicteurs (ou caractéristiques).
Sans perte de généralité, supposons X_0 = 1 :

On peut donc avoir une expression plus concise :
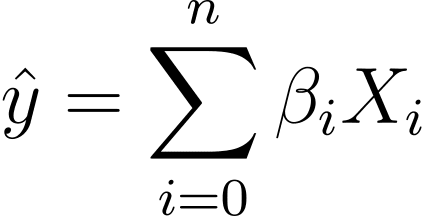
En régression logistique, nous avons besoin de la probabilité prédite p_i dans l'intervalle [0,1]. Nous savons que la fonction logistique écrase les entrées afin qu'elles prennent des valeurs dans l'intervalle [0,1].
En branchant donc cette expression dans la fonction logistique, nous avons la probabilité prédite comme suit :
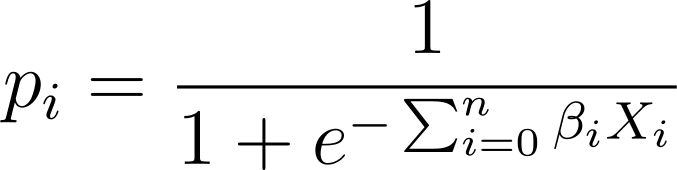
Alors, comment trouver la courbe logistique la mieux adaptée à l’ensemble de données donné ? Pour répondre à cette question, comprenons l’estimation du maximum de vraisemblance.
Estimation du maximum de vraisemblance (MLE) is used to estimate the parameters of the logistic regression model by maximizing the likelihood function. Let’s break down the process of MLE in logistic regression and how the cost function is formulated for optimization using gradient descent.
Décomposition de l'estimation du maximum de vraisemblance
Comme indiqué, nous modélisons la probabilité qu'un résultat binaire se produise en fonction d'une ou plusieurs variables prédictives (ou caractéristiques) :
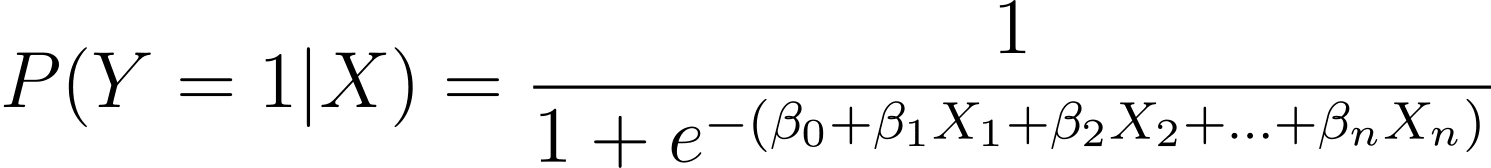
Here, the βs are the model parameters or coefficients. X_1, X_2,…, X_n are the predictor variables.
MLE vise à trouver les valeurs de β qui maximisent la probabilité des données observées. La fonction de vraisemblance, notée L(β), représente la probabilité d'observer les résultats donnés pour les valeurs prédictives données dans le cadre du modèle de régression logistique.
Formulation de la fonction log-vraisemblance
To simplify the optimization process, it’s common to work with the log-likelihood function. Because it transforms products of probabilities into sums of log probabilities.
La fonction log-vraisemblance pour la régression logistique est donnée par :
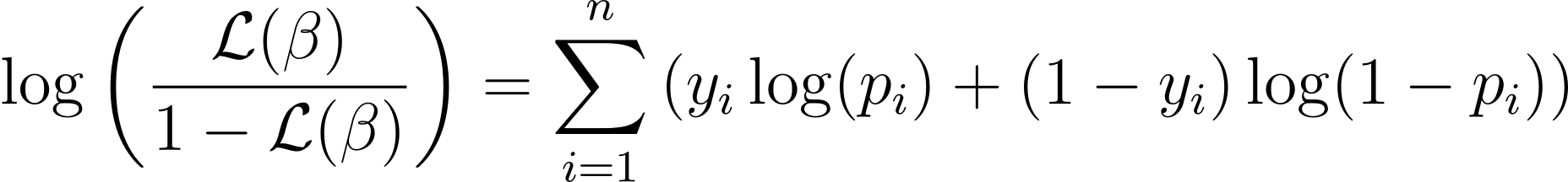
Now that we know the essence of log-likelihood, let’s proceed to formulate the cost function for logistic regression and subsequently gradient descent for finding the best model parameters
Fonction de coût pour la régression logistique
Pour optimiser le modèle de régression logistique, nous devons maximiser la log-vraisemblance. Nous pouvons donc utiliser la log-vraisemblance négative comme fonction de coût à minimiser pendant la formation. La log-vraisemblance négative, souvent appelée perte logistique, est définie comme :
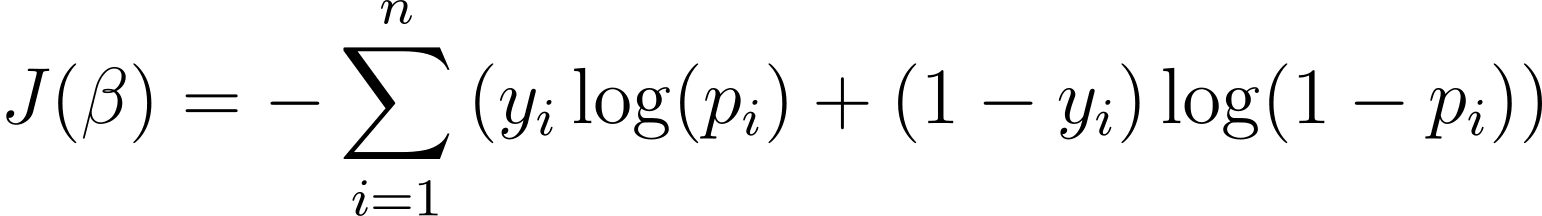
Le but de l’algorithme d’apprentissage est donc de trouver les valeurs de ? qui minimisent cette fonction de coût. La descente de gradient est un algorithme d'optimisation couramment utilisé pour trouver le minimum de cette fonction de coût.
Descente de gradient dans la régression logistique
Descente graduelle est un algorithme d'optimisation itératif qui met à jour les paramètres du modèle β dans le sens opposé du gradient de la fonction de coût par rapport à β. La règle de mise à jour à l'étape t+1 pour la régression logistique utilisant la descente de gradient est la suivante :
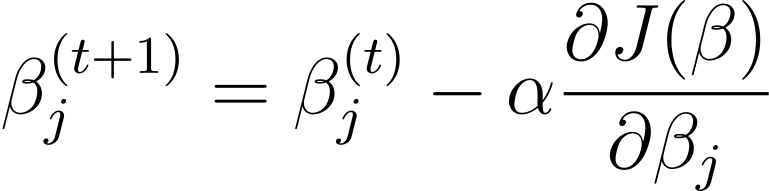
Où α est le taux d’apprentissage.
Les dérivées partielles peuvent être calculées à l'aide de la règle de la chaîne. La descente de gradient met à jour les paramètres de manière itérative, jusqu'à convergence, dans le but de minimiser la perte logistique. En convergeant, il trouve les valeurs optimales de β qui maximisent la vraisemblance des données observées.
Maintenant que vous savez comment fonctionne la régression logistique, créons un modèle prédictif à l'aide de la bibliothèque scikit-learn.
Nous utiliserons le Ensemble de données sur l'ionosphère du référentiel d'apprentissage automatique UCI pour ce tutoriel. L'ensemble de données comprend 34 caractéristiques numériques. La sortie est binaire, soit « bonne » ou « mauvaise » (notée « g » ou « b »). L'étiquette de sortie « bon » fait référence aux retours RADAR qui ont détecté une certaine structure dans l'ionosphère.
Étape 1 – Chargement de l'ensemble de données
Tout d’abord, téléchargez l’ensemble de données et lisez-le dans une trame de données pandas :
import pandas as pd
import urllib
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/iphere.data"
data = urllib.request.urlopen(url)
df = pd.read_csv(data, header=None)Étape 2 – Explorer l'ensemble de données
Let’s take a look at the first few rows of the dataframe:
# Display the first few rows of the DataFrame
df.head()
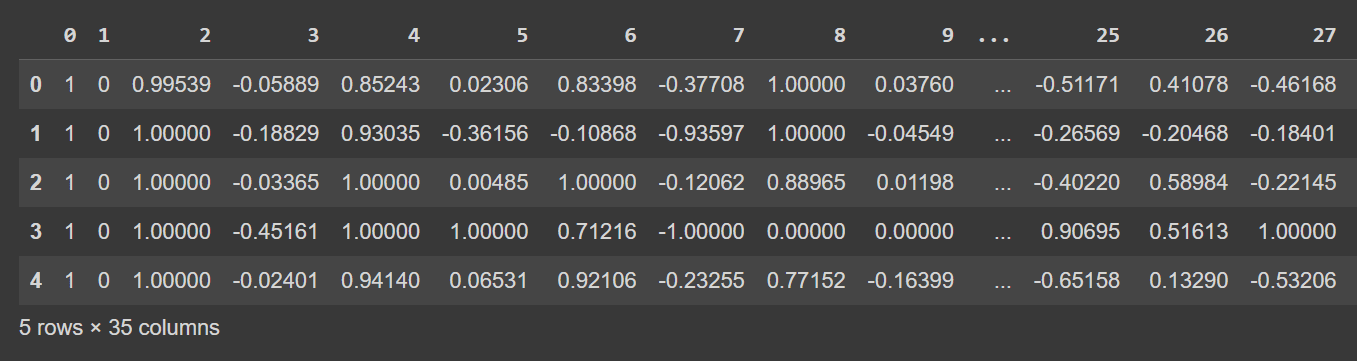
Sortie tronquée de df.head()
Let’s get some information about the dataset: the number of non-null values and the data types of each of the columns:
# Get information about the dataset
print(df.info())
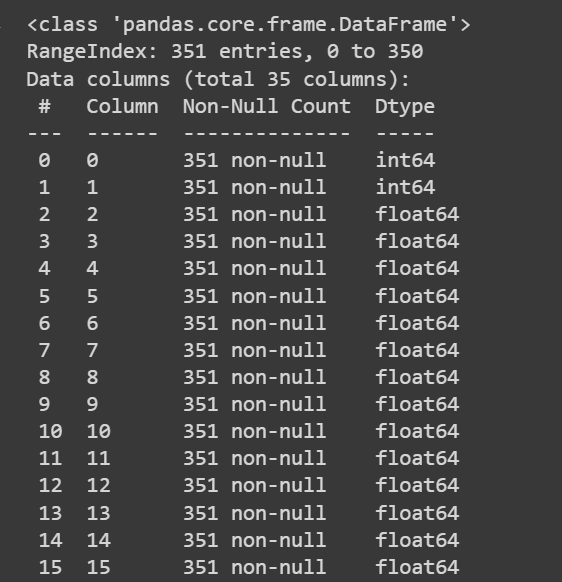 Sortie tronquée de df.info()
Sortie tronquée de df.info()
Parce que nous disposons de toutes les fonctionnalités numériques, nous pouvons également obtenir des statistiques descriptives en utilisant le describe() méthode sur la trame de données :
# Get descriptive statistics of the dataset
print(df.describe())
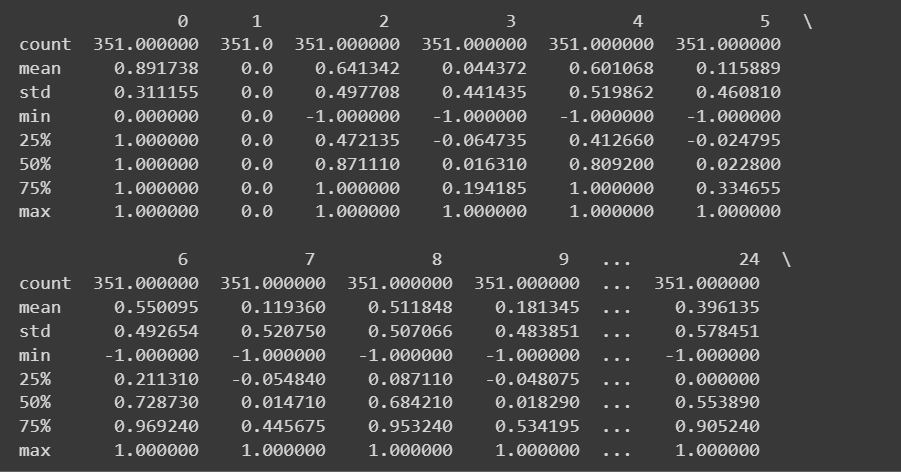
Sortie tronquée de df.describe()
Les noms de colonnes vont actuellement de 0 à 34, y compris l'étiquette. Étant donné que l'ensemble de données ne fournit pas de noms descriptifs pour les colonnes, il les fait simplement référence comme attribut_1 à attribut_34 si vous souhaitez renommer les colonnes du bloc de données comme indiqué :
column_names = [
"attribute_1", "attribute_2", "attribute_3", "attribute_4", "attribute_5",
"attribute_6", "attribute_7", "attribute_8", "attribute_9", "attribute_10",
"attribute_11", "attribute_12", "attribute_13", "attribute_14", "attribute_15",
"attribute_16", "attribute_17", "attribute_18", "attribute_19", "attribute_20",
"attribute_21", "attribute_22", "attribute_23", "attribute_24", "attribute_25",
"attribute_26", "attribute_27", "attribute_28", "attribute_29", "attribute_30",
"attribute_31", "attribute_32", "attribute_33", "attribute_34", "class_label"
]
df.columns = column_names
Remarque : Cette étape est purement facultative. Vous pouvez continuer avec les noms de colonnes par défaut si vous préférez.
# Display the first few rows of the DataFrame
df.head()
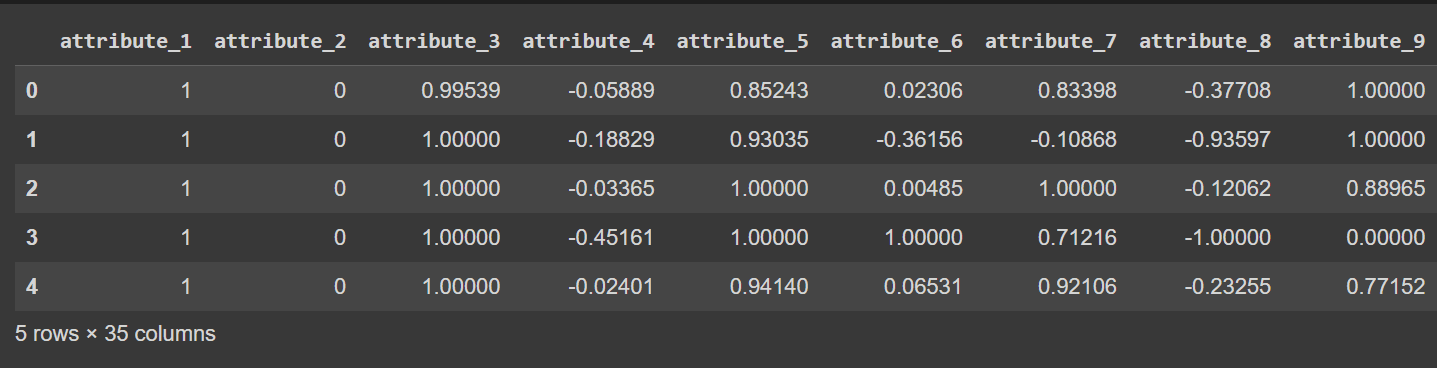
Sortie tronquée de df.head() [Après avoir renommé les colonnes]
Étape 3 – Renommer les étiquettes de classe et visualiser la distribution des classes
Étant donné que les étiquettes de classe de sortie sont « g » et « b », nous devons les mapper respectivement à 1 et 0 . Vous pouvez le faire en utilisant map() or replace():
# Convert the class labels from 'g' and 'b' to 1 and 0, respectively
df["class_label"] = df["class_label"].replace({'g': 1, 'b': 0})
Visualisons également la distribution des étiquettes de classe :
import matplotlib.pyplot as plt
# Count the number of data points in each class
class_counts = df['class_label'].value_counts()
# Create a bar plot to visualize the class distribution
plt.bar(class_counts.index, class_counts.values)
plt.xlabel('Class Label')
plt.ylabel('Count')
plt.xticks(class_counts.index)
plt.title('Class Distribution')
plt.show()
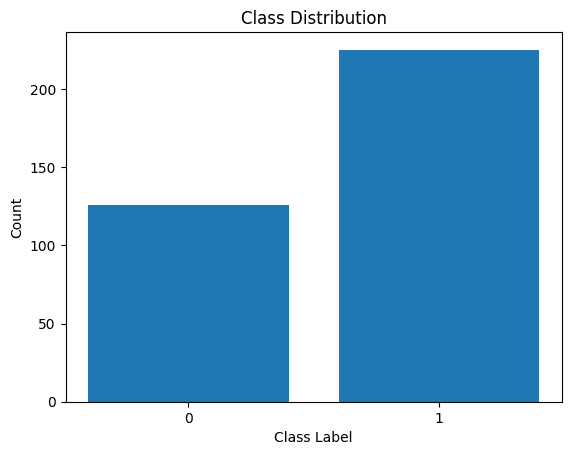
Distribution des étiquettes de classe
On voit qu'il y a un déséquilibre dans la répartition. Il y a plus d'enregistrements appartenant à la classe 1 qu'à la classe 0. Nous gérerons ce déséquilibre de classe lors de la construction du modèle de régression logistique.
Étape 5 – Prétraitement de l'ensemble de données
Rassemblons les fonctionnalités et les étiquettes de sortie comme ceci :
X = df.drop('class_label', axis=1) # Input features
y = df['class_label'] # Target variable
Après avoir divisé l'ensemble de données en ensembles d'entraînement et de test, nous devons prétraiter l'ensemble de données.
Lorsqu'il existe de nombreuses caractéristiques numériques, chacune à une échelle potentiellement différente, nous devons prétraiter les caractéristiques numériques. Une méthode courante consiste à les transformer de telle sorte qu’ils suivent une distribution avec une moyenne nulle et une variance unitaire.
La StandardScaler du module de prétraitement de scikit-learn nous aide à y parvenir.
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Get the indices of the numerical features
numerical_feature_indices = list(range(34)) # Assuming the numerical features are in columns 0 to 33
# Initialize the StandardScaler
scaler = StandardScaler()
# Normalize the numerical features in the training set
X_train.iloc[:, numerical_feature_indices] = scaler.fit_transform(X_train.iloc[:, numerical_feature_indices])
# Normalize the numerical features in the test set using the trained scaler from the training set
X_test.iloc[:, numerical_feature_indices] = scaler.transform(X_test.iloc[:, numerical_feature_indices])Étape 6 – Création d'un modèle de régression logistique
Nous pouvons maintenant instancier un classificateur de régression logistique. Le LogisticRegression La classe fait partie du module Linear_model de scikit-learn.
Notez que nous avons défini le class_weight paramètre sur « équilibré ». Cela nous aidera à expliquer le déséquilibre des classes. En attribuant des pondérations à chaque classe, inversement proportionnelles au nombre d'enregistrements dans les classes.
Après avoir instancié la classe, nous pouvons adapter le modèle à l'ensemble de données d'entraînement :
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)Étape 7 – Évaluation du modèle de régression logistique
Vous pouvez appeler le predict() méthode pour obtenir les prédictions du modèle.
En plus du score de précision, nous pouvons également obtenir un rapport de classification avec des mesures telles que la précision, le rappel et le score F1.
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
classification_rep = classification_report(y_test, y_pred)
print("Classification Report:n", classification_rep)
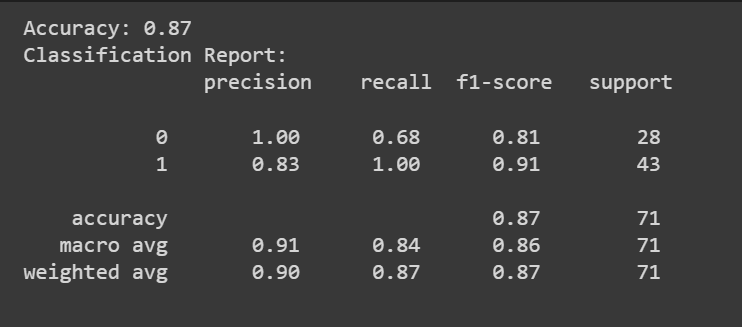
Félicitations, vous avez codé votre premier modèle de régression logistique !
Dans ce didacticiel, nous avons découvert la régression logistique en détail : de la théorie et des mathématiques au codage d'un classificateur de régression logistique.
Dans une prochaine étape, essayez de créer un modèle de régression logistique pour un ensemble de données approprié de votre choix.
L'ensemble de données Ionosphère est sous licence Creative Commons Attribution 4.0 Internationale (CC BY 4.0) licence :
Sigillito, V., Wing, S., Hutton, L. et Baker, K. (1989). Ionosphère. Référentiel d'apprentissage automatique UCI. https://doi.org/10.24432/C5W01B.
Bala Priya C est un développeur et rédacteur technique indien. Elle aime travailler à l'intersection des mathématiques, de la programmation, de la science des données et de la création de contenu. Ses domaines d'intérêt et d'expertise incluent DevOps, la science des données et le traitement du langage naturel. Elle aime lire, écrire, coder et prendre un café ! Actuellement, elle travaille à l'apprentissage et au partage de ses connaissances avec la communauté des développeurs en créant des didacticiels, des guides pratiques, des articles d'opinion, etc.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.kdnuggets.com/building-predictive-models-logistic-regression-in-python?utm_source=rss&utm_medium=rss&utm_campaign=building-predictive-models-logistic-regression-in-python
- :est
- :ne pas
- $UP
- 1
- 10
- 11
- 13
- 20
- 33
- 7
- 9
- a
- A Propos
- Compte
- précision
- atteindre
- ajouter
- ajout
- Après
- vise
- algorithme
- algorithmes
- Tous
- aussi
- an
- ainsi que
- répondre
- approches
- SONT
- domaines
- AS
- assumer
- At
- création
- b
- boulanger
- Équilibré
- barre
- BE
- car
- qui appartiennent
- LES MEILLEURS
- Pause
- construire
- Développement
- by
- Appelez-nous
- CAN
- ne peut pas
- catégories
- chaîne
- le choix
- classe
- les classes
- classification
- codé
- Codage
- recueillir
- Colonne
- Colonnes
- Commun
- communément
- Chambre des communes
- Communautés
- comprend
- concis
- contenu
- création de contenu
- convertir
- Prix
- couvrant
- engendrent
- création
- Lecture
- courbe
- données
- points de données
- science des données
- ensemble de données
- Réglage par défaut
- défini
- Dérivés
- détail
- détecté
- Développeur
- DevOps
- différent
- direction
- discuter
- discuté
- Commande
- distribution
- do
- down
- download
- pendant
- chacun
- essence
- estimation
- évaluer
- nous a permis de concevoir
- Explorer
- expression
- Fonctionnalités:
- few
- Trouvez
- trouver
- trouve
- Prénom
- s'adapter
- suivre
- suit
- Pour
- CADRE
- De
- fonction
- obtenez
- obtention
- donné
- Go
- objectif
- plus grand
- Sol
- Guides
- main
- manipuler
- Vous avez
- vous aider
- aide
- ici
- Comment
- HTTPS
- ICS
- if
- déséquilibre
- importer
- in
- comprendre
- indice
- Inde
- Indices
- d'information
- contribution
- entrées
- intérêt
- intéressant
- intersection
- développement
- IT
- juste
- KDnuggetsGenericName
- Savoir
- spécialisées
- Libellé
- Etiquettes
- langue
- APPRENTISSAGE
- savant
- apprentissage
- moins
- laisser
- Bibliothèque
- Licence
- Autorisé
- comme
- probabilité
- aime
- Gamme
- chargement
- enregistrer
- Style
- ressembler
- perte
- click
- machine learning
- a prendre une
- de nombreuses
- Localisation
- math
- matplotlib
- Maximisez
- maximisant
- maximales
- Mai..
- signifier
- méthode
- Métrique
- minimiser
- minimum
- modèle
- numériques jumeaux (digital twin models)
- module
- PLUS
- Bougez
- noms
- Nature
- Langage naturel
- Traitement du langage naturel
- Besoin
- négatif
- next
- nombre
- observée
- of
- souvent
- on
- ONE
- Opinion
- opposé
- optimaux
- à mettre en œuvre pour gérer une entreprise rentable. Ce guide est basé sur trois décennies d'expérience
- Optimiser
- or
- Résultat
- les résultats
- sortie
- sorties
- pandas
- paramètre
- paramètres
- partie
- pièces
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Point
- des notes bonus
- l'éventualité
- La précision
- prédit
- Prédictions
- prédictive
- Predictor
- Prévoit
- préfère
- probabilité
- Problème
- procéder
- processus
- traitement
- Produits
- Programmation
- fournir
- purement
- Python
- radar
- gamme
- Tarif
- Lire
- en cours
- réal
- Articles
- visée
- se réfère
- régression
- rapport
- dépôt
- représente
- nécessaire
- respect
- respectivement
- Retours
- Avis
- robuste
- Règle
- s
- Sciences
- scikit-apprendre
- But
- sur le lien
- sens
- set
- Sets
- partage
- elle
- montré
- étapes
- simplifier
- So
- quelques
- scission
- j'ai commencé
- statistiques
- étapes
- droit
- structure
- Par la suite
- tel
- convient
- des sommes
- Prenez
- prend
- Target
- tâches
- Technique
- tester
- Essais
- que
- qui
- La
- Les
- théorie
- Là.
- donc
- l'ont
- this
- Avec
- à
- Boîte à outils
- Train
- qualifié
- Formation
- Transformer
- se transforme
- Essai
- tutoriel
- tutoriels
- deux
- types
- sous
- comprendre
- unité
- Mises à jour
- Actualités
- URL
- us
- Compte américain
- utilisé
- d'utiliser
- en utilisant
- Plus-value
- Valeurs
- visualiser
- we
- quand
- qui
- why
- Wikipédia
- sera
- Aile
- comprenant
- activités principales
- de travail
- vos contrats
- pourra
- écrivain
- écriture
- X
- Oui
- you
- Votre
- zéphyrnet
- zéro