À mesure que Roblox s'est développé au cours des 16 dernières années, l'ampleur et la complexité de l'infrastructure technique qui prend en charge des millions de co-expériences 3D immersives ont également augmenté. Le nombre de machines que nous prenons en charge a plus que triplé au cours des deux dernières années, passant d'environ 36,000 30 au 2021 juin 145,000 à près de 1,000 XNUMX aujourd'hui. Soutenir ces expériences permanentes pour les personnes du monde entier nécessite plus de XNUMX XNUMX services internes. Pour nous aider à contrôler les coûts et la latence du réseau, nous déployons et gérons ces machines dans le cadre d'une infrastructure de cloud privé hybride et personnalisée qui s'exécute principalement sur site.
Notre infrastructure prend actuellement en charge plus de 70 millions d'utilisateurs actifs quotidiens dans le monde, y compris les créateurs qui s'appuient sur Roblox. économie pour leurs entreprises. Tous ces millions de personnes attendent un très haut niveau de fiabilité. Compte tenu de la nature immersive de nos expériences, la tolérance aux décalages ou à la latence est extrêmement faible, sans parler des pannes. Roblox est une plateforme de communication et de connexion, où les gens se réunissent dans des expériences 3D immersives. Lorsque les gens communiquent en tant qu'avatars dans un espace immersif, même des retards ou des problèmes mineurs sont plus visibles que dans un fil de discussion ou une conférence téléphonique.
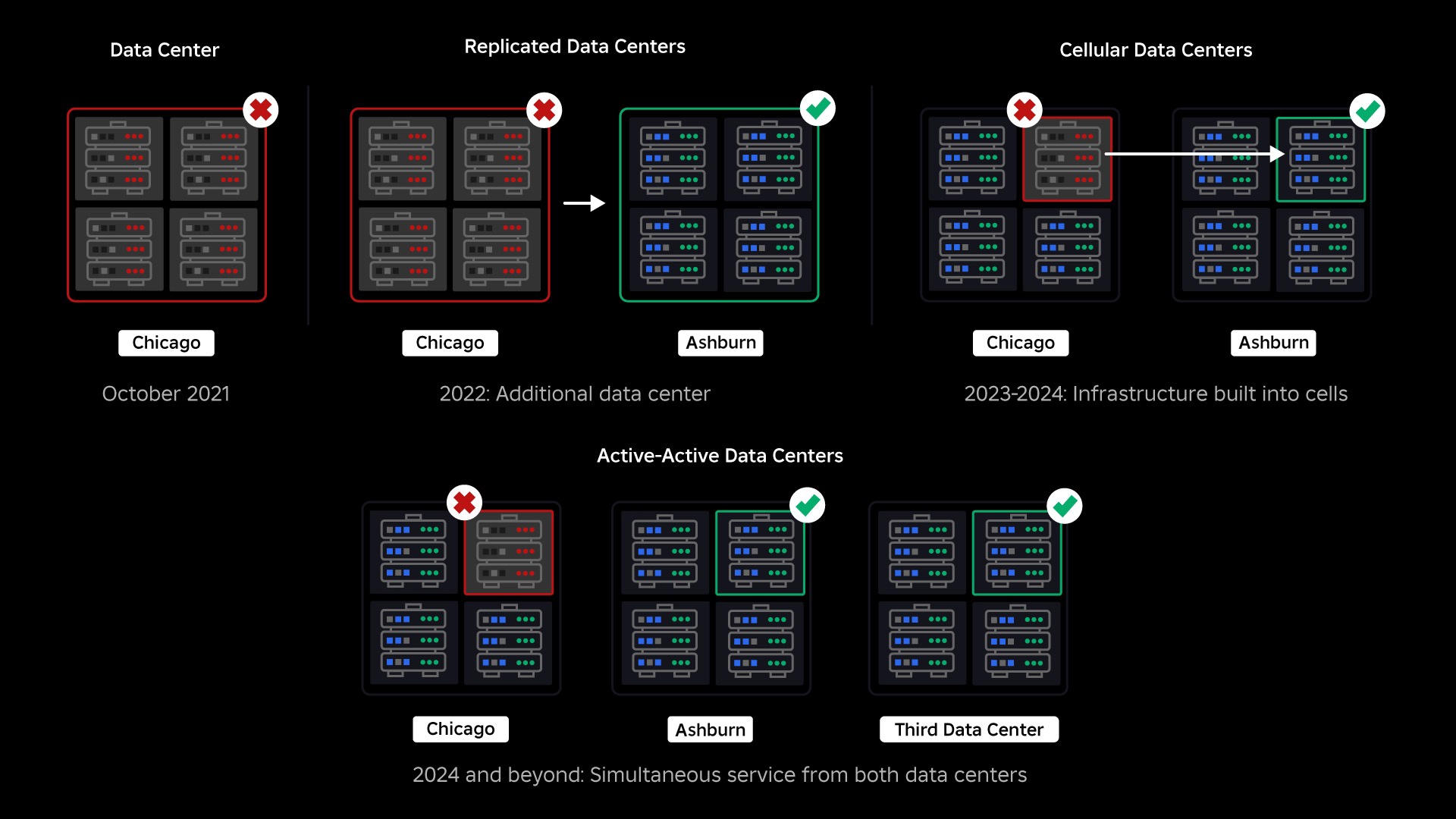
En octobre 2021, nous avons connu une panne à l'échelle du système. Tout a commencé modestement, avec un problème concernant un composant d’un centre de données. Mais cela s’est propagé rapidement au cours de notre enquête et a finalement entraîné une panne de 73 heures. A l'époque, nous partagions les deux des détails sur ce qui s'est passé et certains de nos premiers enseignements sur cette question. Depuis lors, nous étudions ces enseignements et travaillons à accroître la résilience de notre infrastructure aux types de pannes qui se produisent dans tous les systèmes à grande échelle en raison de facteurs tels que des pics de trafic extrêmes, la météo, une panne matérielle, des bogues logiciels ou simplement les humains font des erreurs. Lorsque ces pannes se produisent, comment pouvons-nous garantir qu’un problème affectant un seul composant ou un groupe de composants ne se propage pas à l’ensemble du système ? Cette question est au centre de nos préoccupations depuis deux ans et, même si les travaux se poursuivent, ce que nous avons fait jusqu'à présent porte déjà ses fruits. Par exemple, au premier semestre 2023, nous avons économisé 125 millions d'heures d'engagement par mois par rapport au premier semestre 2022. Aujourd'hui, nous partageons le travail que nous avons déjà effectué, ainsi que notre vision à long terme pour construire un système d’infrastructure plus résilient.
Construire un filet de sécurité
Au sein des systèmes d’infrastructure à grande échelle, des pannes à petite échelle se produisent plusieurs fois par jour. Si une machine rencontre un problème et doit être mise hors service, cela est gérable car la plupart des entreprises gèrent plusieurs instances de leurs services back-end. Ainsi, lorsqu’une seule instance échoue, d’autres reprennent la charge de travail. Pour résoudre ces échecs fréquents, les requêtes sont généralement configurées pour réessayer automatiquement si elles obtiennent une erreur.
Cela devient difficile lorsqu'un système ou une personne réessaye de manière trop agressive, ce qui peut permettre à ces pannes à petite échelle de se propager à travers l'infrastructure vers d'autres services et systèmes. Si le réseau ou un utilisateur réessaye de manière suffisamment persistante, il finira par surcharger chaque instance de ce service, et potentiellement d'autres systèmes, à l'échelle mondiale. Notre panne de 2021 était le résultat de quelque chose qui est assez courant dans les systèmes à grande échelle : une panne commence petit puis se propage dans tout le système, devenant si rapide qu'il est difficile de la résoudre avant que tout ne s'arrête.
Au moment de notre panne, nous avions un centre de données actif (avec des composants faisant office de sauvegarde). Nous avions besoin de pouvoir basculer manuellement vers un nouveau centre de données lorsqu'un problème entraînait la panne du centre de données existant. Notre première priorité était de garantir un déploiement de sauvegarde de Roblox, nous avons donc construit cette sauvegarde dans un nouveau centre de données, situé dans une région géographique différente. Cela a ajouté une protection contre le pire des cas : une panne se propageant à suffisamment de composants dans un centre de données pour qu'il devienne totalement inutilisable. Nous disposons désormais d'un centre de données gérant les charges de travail (actif) et d'un autre en veille, servant de sauvegarde (passif). Notre objectif à long terme est de passer de cette configuration actif-passif à une configuration actif-actif, dans laquelle les deux centres de données gèrent les charges de travail, avec un équilibreur de charge répartissant les requêtes entre eux en fonction de la latence, de la capacité et de l'état de santé. Une fois que cela sera en place, nous espérons avoir une fiabilité encore plus élevée pour l’ensemble de Roblox et être capable de basculer presque instantanément plutôt que sur plusieurs heures. 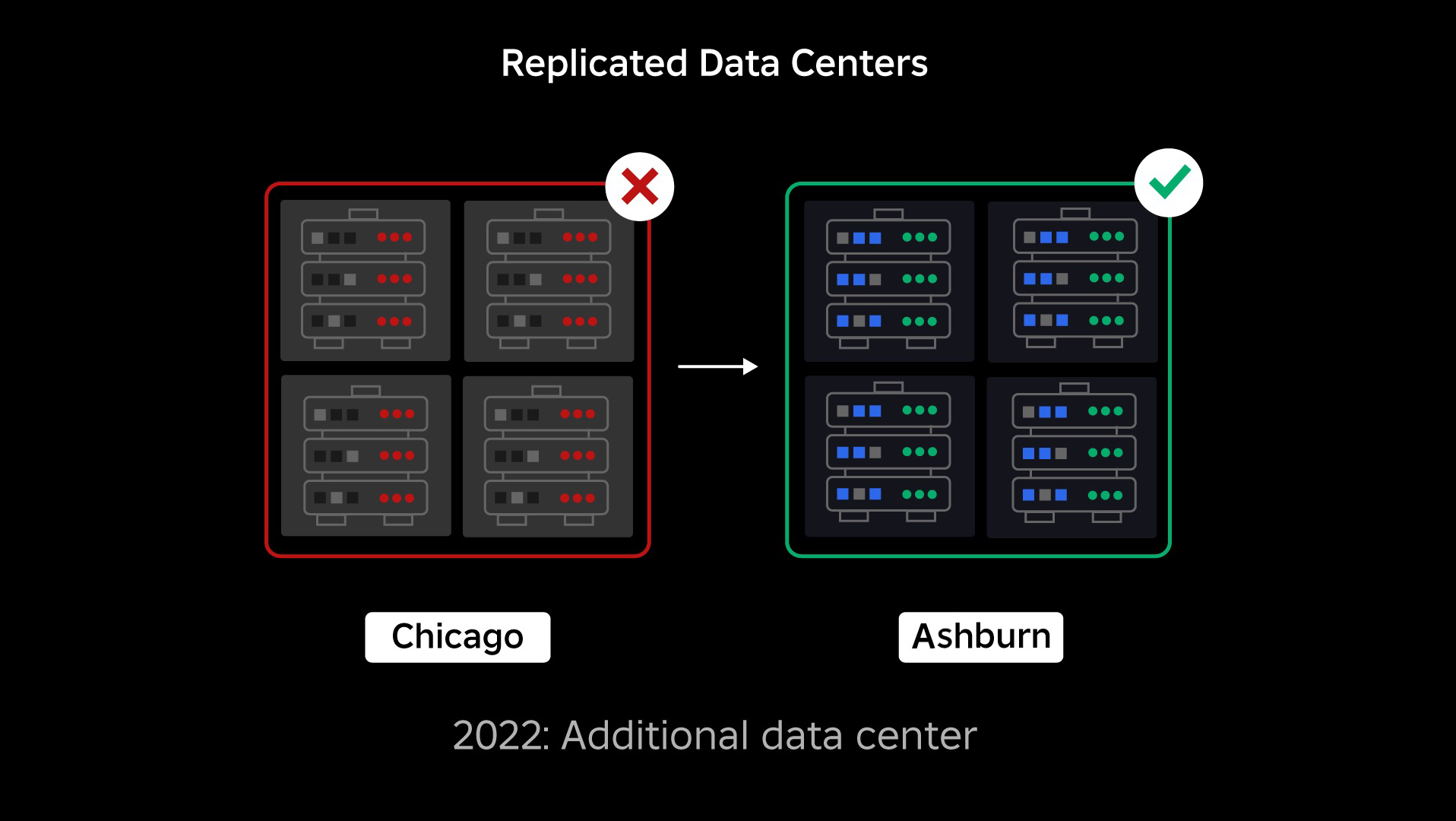
Passer à une infrastructure cellulaire
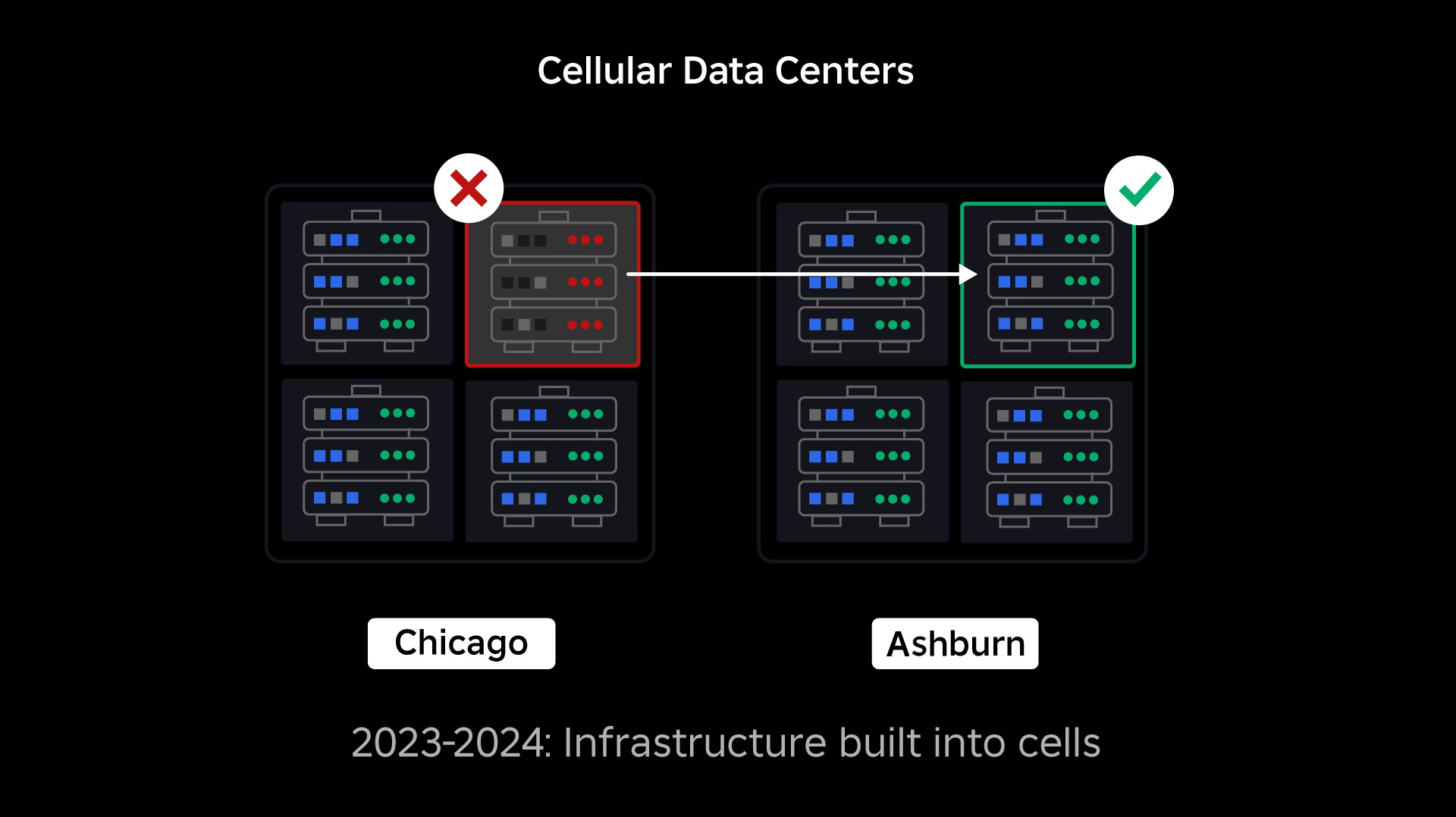
Notre prochaine priorité était de créer des murs anti-souffle solides à l'intérieur de chaque centre de données afin de réduire le risque de panne de l'ensemble d'un centre de données. Les cellules (certaines entreprises les appellent clusters) sont essentiellement un ensemble de machines et c'est grâce à elles que nous créons ces murs. Nous reproduisons les services à la fois au sein et entre les cellules pour une redondance accrue. En fin de compte, nous voulons que tous les services de Roblox fonctionnent dans des cellules afin qu'ils puissent bénéficier à la fois de murs anti-souffle solides et de redondance. Si une cellule n'est plus fonctionnelle, elle peut être désactivée en toute sécurité. La réplication entre les cellules permet au service de continuer à fonctionner pendant que la cellule est réparée. Dans certains cas, la réparation cellulaire peut signifier un réapprovisionnement complet de la cellule. Dans l’ensemble du secteur, l’effacement et le réapprovisionnement d’une machine individuelle ou d’un petit ensemble de machines sont assez courants, mais le fait de procéder ainsi pour une cellule entière, qui contient environ 1,400 XNUMX machines, ne l’est pas.
Pour que cela fonctionne, ces cellules doivent être largement uniformes, afin que nous puissions déplacer rapidement et efficacement les charges de travail d'une cellule à une autre. Nous avons défini certaines exigences auxquelles les services doivent répondre avant de s'exécuter dans une cellule. Par exemple, les services doivent être conteneurisés, ce qui les rend beaucoup plus portables et empêche quiconque d'apporter des modifications à la configuration au niveau du système d'exploitation. Nous avons adopté une philosophie d'infrastructure en tant que code pour les cellules : dans notre référentiel de code source, nous incluons la définition de tout ce qui se trouve dans une cellule afin de pouvoir la reconstruire rapidement à partir de zéro à l'aide d'outils automatisés.
Tous les services ne répondent pas actuellement à ces exigences. Nous nous sommes donc efforcés d'aider les propriétaires de services à les satisfaire dans la mesure du possible, et nous avons créé de nouveaux outils pour faciliter la migration des services vers les cellules lorsqu'ils sont prêts. Par exemple, notre nouvel outil de déploiement « répartit » automatiquement un déploiement de service sur plusieurs cellules, afin que les propriétaires de services n'aient pas à penser à la stratégie de réplication. Ce niveau de rigueur rend le processus de migration beaucoup plus difficile et plus long, mais le résultat à long terme sera un système dans lequel :
- Il est beaucoup plus facile de contenir une défaillance et de l'empêcher de se propager à d'autres cellules ;
- Nos ingénieurs en infrastructure peuvent être plus efficaces et agir plus rapidement ; et
- Les ingénieurs qui créent les services au niveau produit qui sont finalement déployés dans les cellules n'ont pas besoin de savoir ni de s'inquiéter des cellules dans lesquelles leurs services s'exécutent.
Résoudre des défis plus importants
De la même manière que les portes coupe-feu sont utilisées pour contenir les flammes, les cellules agissent comme de solides murs anti-souffle au sein de notre infrastructure pour aider à contenir tout problème qui déclenche une défaillance dans une seule cellule. À terme, tous les services qui composent Roblox seront déployés de manière redondante à l'intérieur et entre les cellules. Une fois ce travail terminé, les problèmes pourraient encore se propager suffisamment largement pour rendre une cellule entière inutilisable, mais il serait extrêmement difficile qu'un problème se propage au-delà de cette cellule. Et si nous parvenons à rendre les cellules interchangeables, la récupération sera nettement plus rapide car nous pourrons basculer vers une autre cellule et éviter que le problème n'affecte les utilisateurs finaux.
Là où cela devient délicat, c'est en séparant suffisamment ces cellules pour réduire le risque de propagation d'erreurs, tout en gardant les choses performantes et fonctionnelles. Dans un système d'infrastructure complexe, les services doivent communiquer entre eux pour partager des requêtes, des informations, des charges de travail, etc. Lorsque nous reproduisons ces services dans des cellules, nous devons réfléchir à la manière dont nous gérons la communication croisée. Dans un monde idéal, nous redirigeons le trafic d’une cellule malsaine vers d’autres cellules saines. Mais comment gérer une « question de mort » – une question qui causer une cellule est en mauvaise santé ? Si nous redirigeons cette requête vers une autre cellule, cela peut rendre cette cellule malsaine, exactement comme nous essayons d'éviter. Nous devons trouver des mécanismes pour déplacer le « bon » trafic des cellules malsaines tout en détectant et en supprimant le trafic qui rend les cellules malsaines.
À court terme, nous avons déployé des copies des services informatiques sur chaque cellule de calcul afin que la plupart des requêtes adressées au centre de données puissent être traitées par une seule cellule. Nous équilibrons également la charge du trafic entre les cellules. À plus long terme, nous avons commencé à construire un processus de découverte de services de nouvelle génération qui sera exploité par un maillage de services, que nous espérons achever en 2024. Cela nous permettra de mettre en œuvre des politiques sophistiquées qui permettront la communication entre cellules uniquement lorsque cela n'aura pas d'impact négatif sur les cellules de basculement. En 2024, une méthode permettant de diriger les requêtes dépendantes vers une version de service dans la même cellule sera également disponible, ce qui minimisera le trafic entre cellules et réduira ainsi le risque de propagation des pannes entre cellules.
Au pic, plus de 70 % du trafic de nos services back-end est servi à partir de cellules et nous avons beaucoup appris sur la façon de créer des cellules, mais nous prévoyons davantage de recherches et de tests à mesure que nous poursuivons la migration de nos services jusqu'en 2024 et au-delà. Au fur et à mesure que nous progressons, ces murs antisouffle deviendront de plus en plus solides.
Migrer une infrastructure toujours active
Roblox est une plate-forme mondiale prenant en charge les utilisateurs du monde entier, nous ne pouvons donc pas déplacer les services pendant les heures creuses ou les « temps d'arrêt », ce qui complique encore davantage le processus de migration de toutes nos machines vers des cellules et de nos services pour qu'ils s'exécutent dans ces cellules. . Nous disposons de millions d'expériences toujours actives qui doivent continuer à être prises en charge, même si nous déplaçons les machines sur lesquelles elles s'exécutent et les services qui les prennent en charge. Lorsque nous avons lancé ce processus, nous n'avions pas des dizaines de milliers de machines inutilisées et disponibles sur lesquelles migrer ces charges de travail.
Nous avions cependant un petit nombre de machines supplémentaires achetées en prévision de notre croissance future. Pour commencer, nous avons construit de nouvelles cellules à l’aide de ces machines, puis avons migré les charges de travail vers celles-ci. Nous valorisons l'efficacité ainsi que la fiabilité, donc plutôt que d'acheter plus de machines une fois que nous avons manqué de machines « de rechange », nous avons construit plus de cellules en effaçant et en réapprovisionnant les machines d'où nous avions migré. Nous avons ensuite migré les charges de travail vers ces machines réapprovisionnées et avons recommencé le processus. Ce processus est complexe : à mesure que les machines sont remplacées et libérées pour être intégrées dans des cellules, elles ne se libèrent pas de manière idéale et ordonnée. Ils sont physiquement fragmentés dans les data halls, ce qui nous oblige à les provisionner de manière fragmentaire, ce qui nécessite un processus de défragmentation au niveau matériel pour maintenir les emplacements matériels alignés avec les domaines de défaillance physique à grande échelle.
Une partie de notre équipe d'ingénierie d'infrastructure se concentre sur la migration des charges de travail existantes de notre environnement existant, ou « pré-cellule », vers les cellules. Ce travail se poursuivra jusqu'à ce que nous ayons migré des milliers de services d'infrastructure différents et des milliers de services back-end vers des cellules nouvellement construites. Nous prévoyons que cela prendra toute l’année prochaine et peut-être jusqu’en 2025, en raison de certains facteurs compliqués. Premièrement, ce travail nécessite la construction d’un outillage robuste. Par exemple, nous avons besoin d'outils pour rééquilibrer automatiquement un grand nombre de services lorsque nous déployons une nouvelle cellule, sans impact sur nos utilisateurs. Nous avons également vu des services construits avec des hypothèses concernant notre infrastructure. Nous devons réviser ces services afin qu'ils ne dépendent pas de choses qui pourraient changer à l'avenir à mesure que nous emménagerons dans les cellules. Nous avons également mis en œuvre un moyen de rechercher les modèles de conception connus qui ne fonctionneront pas bien avec l'architecture cellulaire, ainsi qu'un processus de test méthodique pour chaque service migré. Ces processus nous aident à éviter tout problème rencontré par les utilisateurs causé par l'incompatibilité d'un service avec les cellules.
Aujourd'hui, près de 30,000 99.99 machines sont gérées par des cellules. Cela ne représente qu’une fraction de notre flotte totale, mais la transition s’est déroulée en douceur jusqu’à présent, sans impact négatif sur les joueurs. Notre objectif ultime est que nos systèmes atteignent une disponibilité utilisateur de 0.01 % chaque mois, ce qui signifie que nous ne perturberions pas plus de XNUMX % des heures d'engagement. À l'échelle de l'industrie, les temps d'arrêt ne peuvent pas être complètement éliminés, mais notre objectif est de réduire les temps d'arrêt de Roblox à un point tel qu'ils deviennent presque imperceptibles.
Une pérennité à mesure que nous évoluons
Même si nos premiers efforts se révèlent fructueux, nos travaux sur les cellules sont loin d’être terminés. À mesure que Roblox continue d'évoluer, nous continuerons à travailler pour améliorer l'efficacité et la résilience de nos systèmes grâce à cette technologie et à d'autres. Au fur et à mesure, la plateforme deviendra de plus en plus résiliente aux problèmes, et tous les problèmes qui surviennent devraient devenir progressivement moins visibles et perturbateurs pour les utilisateurs de notre plateforme.
En résumé, à ce jour, nous avons :
- Construction d'un deuxième centre de données et obtention du statut actif/passif.
- Création de cellules dans nos centres de données actifs et passifs et migration réussie de plus de 70 % de notre trafic de services back-end vers ces cellules.
- Mettez en place les exigences et les meilleures pratiques que nous devrons suivre pour maintenir l'uniformité de toutes les cellules alors que nous continuons à migrer le reste de notre infrastructure.
- Lancement d’un processus continu de construction de « murs anti-souffle » plus solides entre les cellules.
À mesure que ces cellules deviennent plus interchangeables, il y aura moins de diaphonie entre les cellules. Cela nous ouvre des opportunités très intéressantes en termes d’automatisation croissante de la surveillance, du dépannage et même du transfert automatique des charges de travail.
En septembre, nous avons également commencé à mener des expériences actives/actives dans nos centres de données. Il s'agit d'un autre mécanisme que nous testons pour améliorer la fiabilité et minimiser les temps de basculement. Ces expériences ont permis d'identifier un certain nombre de modèles de conception de systèmes, en grande partie autour de l'accès aux données, que nous devons retravailler à mesure que nous nous efforçons de devenir pleinement actifs-actifs. Dans l’ensemble, l’expérience a été suffisamment réussie pour qu’elle puisse fonctionner avec le trafic d’un nombre limité de nos utilisateurs.
Nous sommes ravis de continuer à faire avancer ce travail pour apporter une plus grande efficacité et résilience à la plateforme. Ce travail sur les cellules et les infrastructures actives-actives, ainsi que nos autres efforts, nous permettront de devenir un service public fiable et performant pour des millions de personnes et de continuer à évoluer alors que nous travaillons à connecter un milliard de personnes en temps réel. temps.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://blog.roblox.com/2023/12/making-robloxs-infrastructure-efficient-resilient/
- :possède
- :est
- :ne pas
- :où
- $UP
- 000
- 01
- 1
- 125
- 2021
- 2022
- 2023
- 2024
- 2025
- 30
- 36
- 3d
- 400
- 70
- a
- capacité
- Capable
- Qui sommes-nous
- accès
- atteindre
- atteint
- à travers
- Agis
- intérim
- infection
- ajoutée
- Supplémentaire
- propos
- adopté
- encore
- agressivement
- aligné
- Tous
- permettre
- seul
- le long de
- déjà
- aussi
- an
- ainsi que le
- Une autre
- anticiper
- anticipation
- tous
- chacun.e
- d'environ
- architecture
- SONT
- autour
- AS
- hypothèses
- At
- Automatisation
- automatiquement
- Automation
- disponibles
- Avatars
- éviter
- Back-end
- sauvegarde
- balancier
- équilibrage
- basé
- BE
- car
- devenez
- devient
- devenir
- était
- before
- commencé
- va
- profiter
- LES MEILLEURS
- les meilleures pratiques
- jusqu'à XNUMX fois
- Au-delà
- Big
- plus gros
- Milliards
- Blog
- tous les deux
- apporter
- Apporté
- bogues
- construire
- Développement
- construit
- entreprises
- mais
- Achat
- by
- Appelez-nous
- CAN
- ne peut pas
- Compétences
- cas
- Causes
- causé
- causer
- cellule
- Cellules
- cellulaire
- Canaux centraux
- Centres
- certaines
- difficile
- Change
- Modifications
- Fermer
- le cloud
- infrastructure de cloud
- code
- comment
- Venir
- Commun
- communiquer
- communicant
- Communication
- Sociétés
- par rapport
- complet
- complètement
- complexe
- complexité
- composant
- composants électriques
- calcul
- informatique
- Congrès
- configuration
- NOUS CONTACTER
- connexion
- contiennent
- contient
- continuer
- continue
- continu
- des bactéries
- copies
- Costs
- pourriez
- engendrent
- La création
- créateurs
- Lecture
- Construit sur mesure
- Tous les jours
- données
- accès aux données
- Centre de données
- les centres de données
- Date
- journée
- définition
- Degré
- retards
- dépendre
- dépendant
- déployer
- déployé
- déploiement
- Conception
- modèles de conception
- DID
- différent
- difficile
- direction
- découverte
- Perturber
- perturbateur
- distribuer
- do
- faire
- domaines
- fait
- Ne pas
- portes
- down
- les temps d'arrêt
- conduite
- deux
- pendant
- chacun
- "Early Bird"
- plus facilement
- Easy
- efficace
- efficace
- efficacement
- efforts
- éliminée
- permet
- fin
- participation
- ENGINEERING
- Les ingénieurs
- assez
- assurer
- Tout
- entièrement
- Environment
- erreur
- Erreurs
- essentiellement
- etc
- Pourtant, la
- faire une éventuelle
- Chaque
- peut
- exemple
- excité
- existant
- attendre
- expérimenté
- Expériences
- expérience
- expériences
- extrême
- extrêmement
- facteurs
- FAIL
- défaut
- échoue
- Échec
- échecs
- équitablement
- loin
- Mode
- plus rapide
- Trouvez
- Incendie
- Prénom
- FLOTTE
- Focus
- concentré
- suivre
- Pour
- Avant
- fraction
- fragmenté
- Gratuit
- fréquent
- De
- plein
- d’étiquettes électroniques entièrement
- fonctionnel
- plus
- avenir
- croissance future
- généralement
- géographique
- obtenez
- obtention
- donné
- Global
- À l'échelle mondiale
- Go
- objectif
- Goes
- aller
- plus grand
- Réservation de groupe
- Croître
- cultivé
- Croissance
- ait eu
- Half
- manipuler
- Maniabilité
- arriver
- Dur
- Matériel
- Vous avez
- front
- Santé
- la santé
- vous aider
- a aidé
- Haute
- augmentation
- d'espérance
- HEURES
- Comment
- How To
- Cependant
- HTTPS
- Les êtres humains
- Hybride
- idéal
- identifier
- if
- immersive
- Impact
- impactant
- Mettre en oeuvre
- mis en œuvre
- améliorer
- in
- comprendre
- Y compris
- incompatible
- Améliore
- croissant
- de plus en plus
- individuel
- industrie
- d'information
- Infrastructure
- à l'intérieur
- instance
- cas
- instantanément
- intéressant
- interne
- développement
- aide
- vous aider à faire face aux problèmes qui vous perturbent
- IT
- juin
- juste
- XNUMX éléments à
- en gardant
- Savoir
- connu
- gros
- grande échelle
- principalement
- Latence
- savant
- Laisser
- départ
- Legacy
- moins
- laisser
- Niveau
- à effet de levier
- comme
- limité
- charge
- situé
- emplacements
- long-term
- plus long
- recherchez-
- Lot
- Faible
- click
- Les machines
- maintenir
- a prendre une
- FAIT DU
- Fabrication
- gérer
- gérés
- manuellement
- de nombreuses
- largeur maximale
- signifier
- sens
- mécanisme
- mécanismes
- Découvrez
- engrener
- méthode
- méthodique
- pourrait
- émigrer
- migré
- migrer
- migration
- million
- des millions
- minimiser
- mineur
- erreurs
- Stack monitoring
- Mois
- PLUS
- plus efficace
- (en fait, presque toutes)
- Bougez
- beaucoup
- plusieurs
- must
- Nature
- presque
- Besoin
- nécessaire
- négatif
- négativement
- réseau et
- Nouveauté
- nouvellement
- next
- La prochaine génération
- aucune
- maintenant
- nombre
- numéros
- se produire
- octobre
- of
- de rabais
- on
- une fois
- ONE
- en cours
- uniquement
- Opportunités
- Opportunités
- or
- OS
- Autre
- Autres
- nos
- ande
- coupure de courant
- Les pannes
- plus de
- global
- propriétaires
- partie
- passif
- passé
- motifs
- payant
- Courant
- Personnes
- /
- pour cent
- effectuer
- constamment
- personne
- philosophie
- Physique
- Physiquement
- en particulier pendant la préparation
- Place
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- joueur
- politiques
- portable
- partieInvestir dans des appareils économes en énergie et passer à l'éclairage
- possibilité
- possible
- peut-être
- l'éventualité
- pratiques
- empêcher
- empêche
- qui se déroulent
- priorité
- Privé
- processus
- les process
- Progrès
- progressivement
- propagation
- protection
- Prouver
- disposition
- acheté
- Push
- requêtes
- question
- vite.
- plutôt
- solutions
- réal
- en temps réel
- rééquilibrer
- récupération
- réorienter
- réduire
- région
- fiabilité
- fiable
- compter
- réparation
- remplacé
- réplication
- dépôt
- demandes
- Exigences
- a besoin
- un article
- la résilience
- résilient
- résoudre
- REST
- résultat
- résulté
- réviser
- Analyse
- Roblox
- robuste
- Courir
- pour le running
- fonctionne
- en toute sécurité
- même
- sauvé
- Escaliers intérieurs
- scénario
- gratter
- Rechercher
- Deuxièmement
- vu
- séparation
- Septembre
- servi
- service
- Services
- service
- set
- plusieurs
- Partager
- commun
- partage
- décalage
- DÉPLACEMENT
- Shorts
- devrait
- de façon significative
- depuis
- unique
- Séance
- petit
- lisse
- So
- jusqu'à présent
- Logiciels
- quelques
- quelque chose
- sophistiqué
- Identifier
- code source
- Space
- pointes
- propagation
- Diffusion
- Commencer
- j'ai commencé
- départs
- Statut
- Encore
- de Marketing
- STRONG
- plus efficacement
- Étudier
- réussir
- réussi
- Avec succès
- RÉSUMÉ
- Support
- Appareils
- Appuyer
- Les soutiens
- combustion propre
- Système
- Prenez
- tâches
- équipe
- Technique
- Les technologies
- dizaines
- terme
- conditions
- Essais
- texte
- que
- qui
- Les
- El futuro
- le monde
- leur
- Les
- puis
- Là.
- ainsi
- Ces
- l'ont
- des choses
- penser
- this
- ceux
- milliers
- Avec
- tout au long de
- fiable
- fois
- à
- aujourd'hui
- ensemble
- tolérance
- trop
- outil
- les outils
- Total
- vers
- circulation
- transition
- déclenchement
- essayer
- deux
- types
- ultime
- En fin de compte
- déverrouille
- jusqu'à
- inutilisé
- sur
- Stabilité
- us
- d'utiliser
- Utilisateur
- utilisateurs
- en utilisant
- utilitaire
- Plus-value
- version
- très
- visible
- vision
- souhaitez
- était
- Façon..
- we
- Météo
- WELL
- ont été
- Quoi
- quelle que soit
- quand
- qui
- tout en
- WHO
- large
- sera
- essuyage
- comprenant
- dans les
- activités principales
- travaillé
- de travail
- world
- s'inquiéter
- pourra
- an
- années
- zéphyrnet