Vous avez donc regardé tous les tutoriels. Vous comprenez maintenant comment fonctionne un réseau de neurones. Vous avez construit un classificateur pour chats et chiens. Vous vous êtes essayé à un RNN au niveau du personnage à moitié décent. Tu es juste un pip install tensorflow loin de construire le terminateur, non? Tort.

Une partie très importante de l'apprentissage en profondeur consiste à trouver les bons hyperparamètres. Ce sont des nombres que le modèle ne peut pas apprendre.
Dans cet article, je vais vous expliquer certains des hyperparamètres les plus courants (et les plus importants) que vous rencontrerez sur votre route vers la première place des classements Kaggle. De plus, je vais également vous montrer quelques algorithmes puissants qui peuvent vous aider à choisir judicieusement vos hyperparamètres.
Hyperparamètres dans le Deep Learning
Les hyperparamètres peuvent être considérés comme les boutons de réglage de votre modèle.
Un système home cinéma Dolby Atmos 7.1 sophistiqué avec un subwoofer qui produit des basses au-delà de la portée audible de l'oreille humaine est inutile si vous réglez votre récepteur AV sur stéréo.

De même, un inception_v3 avec un billion de paramètres ne vous fera même pas dépasser MNIST si vos hyperparamètres sont désactivés.
Alors maintenant, jetons un coup d'œil aux boutons à régler avant d'entrer dans la façon de composer les bons réglages.
Taux d'apprentissage
Sans doute l'hyperparamètre le plus important, le taux d'apprentissage, en gros, contrôle la vitesse à laquelle votre réseau neuronal «apprend».
Alors pourquoi ne pas simplement amplifier cela et vivre la vie sur la voie rapide?

Pas si simple. Rappelez-vous, dans l'apprentissage en profondeur, notre objectif est de minimiser une fonction de perte. Si le taux d'apprentissage est trop élevé, notre perte commencera à bondir partout et ne convergera jamais.

Et si le taux d'apprentissage est trop faible, le modèle mettra beaucoup trop de temps à converger, comme illustré ci-dessus.
Élan
Étant donné que cet article se concentre sur l'optimisation des hyperparamètres, je ne vais pas expliquer tout le concept de élan. Mais en bref, la constante d'élan peut être considérée comme la masse d'une balle qui roule sur la surface de la fonction de perte.
Plus la balle est lourde, plus elle tombe rapidement. Mais s'il est trop lourd, il peut rester coincé ou dépasser la cible.

marginal
Si vous ressentez un thème ici, je vais maintenant vous diriger vers Amar Budhirâjaarticle sur le décrochage.

Mais comme rappel rapide, le décrochage est une technique de régularisation proposée par Geoff Hinton qui définit aléatoirement les activations dans un réseau de neurones à 0 avec une probabilité de (p). Cela permet d'éviter que les réseaux neuronaux ne surappliquent (mémorisent) les données au lieu de les apprendre.
(p) est un hyperparamètre.
Architecture - Nombre de couches, neurones par couche, etc.
Une autre idée (assez récente) est de faire de l'architecture du réseau neuronal lui-même un hyperparamètre.
Bien que nous ne fassions généralement pas en sorte que les machines comprennent l'architecture de nos modèles (sinon les chercheurs en IA perdraient leur emploi), certaines nouvelles techniques comme Recherche d'architecture neuronale ont été mis en œuvre cette idée avec divers degrés de succès.
Si vous en avez entendu parler AutoML, voici comment Google procède: faites de tout un hyperparamètre puis jetez un milliard de TPU sur le problème et laissez-le se résoudre.
Mais pour la grande majorité d'entre nous qui voulons simplement classer les chats et les chiens avec une machine à budget bricolée après une vente du Black Friday, il est grand temps que nous trouvions comment faire fonctionner ces modèles d'apprentissage en profondeur.
Algorithmes d'optimisation des hyperparamètres
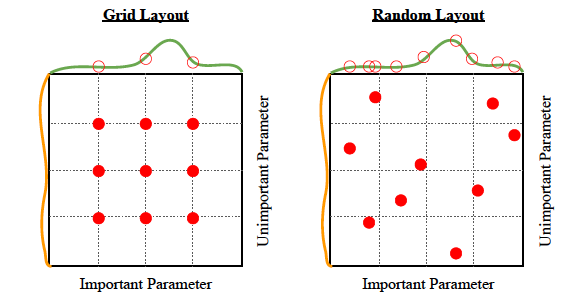
Recherche de grille
C'est le moyen le plus simple d'obtenir de bons hyperparamètres. C'est littéralement juste de la force brute.
L'algorithme: Essayez un ensemble d'hyperparamètres à partir d'un ensemble donné d'hyperparamètres et voyez ce qui fonctionne le mieux.
Les pros: C'est assez facile pour un élève de cinquième à mettre en œuvre. Peut être facilement parallélisé.
Les inconvénients: Comme vous l'avez probablement deviné, il est incroyablement coûteux en calcul (comme toutes les méthodes de force brute le sont).
Dois-je l'utiliser: Probablement pas. La recherche de grille est terriblement inefficace. Même si vous voulez rester simple, il vaut mieux utiliser la recherche aléatoire.
Recherche aléatoire
Tout est dans le nom - recherches de recherche aléatoires. Au hasard.
L'algorithme: Essayez un tas d'hyperparamètres aléatoires à partir d'une distribution uniforme sur un espace d'hyperparamètres et voyez ce qui fonctionne le mieux.
Les pros: Peut être facilement parallélisé. Tout aussi simple que la recherche de grille, mais un peu une meilleure performance, comme illustré ci-dessous:

Les inconvénients: Bien qu'elle offre de meilleures performances que la recherche de grille, elle est toujours aussi intensive en calcul.
Dois-je l'utiliser: Si la parallélisation et la simplicité triviales sont de la plus haute importance, allez-y. Mais si vous pouvez épargner du temps et des efforts, vous serez récompensé beaucoup de temps en utilisant l'optimisation bayésienne.
Optimisation bayésienne
Contrairement aux autres méthodes que nous avons vues jusqu'à présent, l'optimisation bayésienne utilise la connaissance des itérations précédentes de l'algorithme. Avec la recherche par grille et la recherche aléatoire, chaque hypothèse d'hyperparamètre est indépendante. Mais avec les méthodes bayésiennes, chaque fois que nous sélectionnons et essayons différents hyperparamètres, les pouces vers la perfection.

Les idées derrière le réglage des hyperparamètres bayésiens sont longues et riches en détails. Alors pour éviter trop de terriers de lapin, je vais vous donner l'essentiel ici. Mais assurez-vous de lire sur Processus gaussiens et les Optimisation bayésienne en général, si c'est le genre de chose qui vous intéresse.
N'oubliez pas que la raison pour laquelle nous utilisons ces algorithmes de réglage d'hyperparamètres est qu'il est impossible d'évaluer individuellement plusieurs choix d'hyperparamètres. Par exemple, disons que nous voulions trouver un bon taux d'apprentissage manuellement. Cela impliquerait de définir un taux d'apprentissage, de former votre modèle, de l'évaluer, de sélectionner un taux d'apprentissage différent, de former à nouveau votre modèle à partir de zéro, de le réévaluer et le cycle se poursuit.
Le problème est que «la formation de votre modèle» peut prendre jusqu'à plusieurs jours (selon la complexité du problème) pour se terminer. Ainsi, vous ne pourrez essayer que quelques taux d'apprentissage avant la date limite de soumission des articles pour la conférence. Et que savez-vous, vous n'avez même pas commencé à jouer avec l'élan. Oops.

L'algorithme: Les méthodes bayésiennes tentent de construire une fonction (plus précisément, une distribution de probabilité sur une fonction possible) qui estime la qualité de votre modèle pourrait être pour un certain choix d'hyperparamètres. En utilisant cette fonction approximative (appelée fonction de substitution dans la littérature), vous n'avez pas à parcourir la boucle ensemble, train, évaluation trop de fois, car vous pouvez simplement optimiser les hyperparamètres vers la fonction de substitution.
À titre d'exemple, disons que nous voulons minimiser cette fonction (pensez-y comme un proxy pour la fonction de perte de votre modèle):

La fonction de substitution provient de ce qu'on appelle un processus gaussien (note: il existe d'autres façons de modéliser la fonction de substitution, mais j'utiliserai un processus gaussien). Comme, je l'ai mentionné, je ne ferai pas de dérivations lourdes en mathématiques, mais voici ce que tout ce que l'on dit sur les Bayésiens et les Gaussiens se résume à:
$$ mathbb {P} (F_n (X) | X_n) = frac {e ^ {- frac12 F_n ^ T Sigma_n ^ {- 1} F_n}} {sqrt {(2pi) ^ n | Sigma_n |}} $$
Ce qui, certes, est une bouchée. Mais essayons de le décomposer.
Le côté gauche vous indique qu'une distribution de probabilité est impliquée (étant donné la présence de l'aspect sophistiqué (mathbb {P})). En regardant à l'intérieur des crochets, nous pouvons voir qu'il s'agit d'une distribution de probabilité de (F_n (X)), qui est une fonction arbitraire. Pourquoi? Parce que rappelez-vous, nous définissons une distribution de probabilité sur toutes les fonctions possibles, pas seulement une en particulier. Essentiellement, le côté gauche indique que la probabilité que la vraie fonction qui mappe les hyperparamètres aux métriques du modèle (comme la précision de validation, la vraisemblance du journal, le taux d'erreur de test, etc.) est (F_n (X)), compte tenu de quelques exemples de données (X_n) est égal à ce qui se trouve sur le côté droit.
Maintenant que nous avons la fonction d'optimiser, nous l'optimisons.
Voici à quoi ressemblera le processus gaussien avant de commencer le processus d'optimisation:

Utilisez votre optimiseur préféré (les avantages comme maximiser l'amélioration attendue), mais d'une manière ou d'une autre, suivez simplement les signes (ou les gradients) et avant de vous en rendre compte, vous vous retrouverez à vos minima locaux.
Après quelques itérations, le processus gaussien s'améliore pour se rapprocher de la fonction cible:

Quelle que soit la méthode que vous avez utilisée, vous avez maintenant trouvé le fichier `argmin` de la fonction de substitution. Et surprise, surprise, ces arguments qui minimisent la fonction de substitution sont (une estimation de) les hyperparamètres optimaux! Yay.
Le résultat final devrait ressembler à ceci:

Utilisez ces hyperparamètres «optimaux» pour effectuer un entraînement sur votre réseau neuronal, et vous devriez voir une amélioration. Mais vous pouvez également utiliser ces nouvelles informations pour refaire tout le processus d'optimisation bayésienne, encore et encore, et encore. N'hésitez pas à exécuter la boucle bayésienne autant de fois que vous le souhaitez, mais méfiez-vous. Vous êtes en train de calculer des trucs. Ces crédits AWS ne sont pas gratuits, vous savez. Ou est-ce qu'ils…
Les pros: L'optimisation bayésienne donne de meilleurs résultats que la recherche par grille et la recherche aléatoire.
Les inconvénients: Ce n'est pas aussi facile de paralléliser.
Dois-je l'utiliser: Dans la plupart des cas, oui! Les seules exceptions seraient si
- Vous êtes un expert en apprentissage profond et vous n'avez pas besoin de l'aide d'un algorithme d'approximation misérable.
- Vous avez accès à de vastes ressources de calcul et pouvez massivement paralléliser la recherche de grille et la recherche aléatoire.
- Si vous êtes un nerd fréquentiste / anti-bayésien des statistiques.
Une approche alternative pour trouver un bon taux d'apprentissage
Dans toutes les méthodes que nous avons vues jusqu'à présent, il y a un thème sous-jacent: automatiser le travail de l'ingénieur en apprentissage automatique. Ce qui est génial et tout; jusqu'à ce que votre patron en ait vent et décide de vous remplacer par 4 cartes RTX Titan. Hein. Je suppose que vous auriez dû vous en tenir à la recherche manuelle.

Mais ne désespérez pas, il existe une recherche active visant à faire en sorte que les chercheurs en fassent moins et soient simultanément mieux payés. Et l'une des idées qui a extrêmement bien fonctionné est le test de plage de taux d'apprentissage, qui, à ma connaissance, est apparu pour la première fois dans un article de Leslie Smith.
Le document traite en fait d'une méthode pour planifier (modifier) le taux d'apprentissage au fil du temps. Le test de la plage LR (taux d'apprentissage) était une pépite d'or que l'auteur a simplement laissée tomber sur le côté.
Lorsque vous utilisez un barème de taux d'apprentissage qui fait varier le taux d'apprentissage d'une valeur minimale à une valeur maximale, telle que taux d'apprentissage cyclique or descente en gradient stochastique avec redémarrages à chaud, l'auteur suggère d'augmenter linéairement le taux d'apprentissage après chaque itération d'une petite à une grande valeur (disons, 1e-7 à 1e-1), évaluez la perte à chaque itération et tracez la perte (ou erreur de test ou précision) par rapport au taux d'apprentissage sur une échelle logarithmique. Votre intrigue devrait ressembler à ceci:

Comme indiqué sur l'intrigue, vous utiliseriez ensuite définir votre calendrier de taux d'apprentissage pour rebondir entre les taux d'apprentissage minimum et maximum, qui sont trouvés en regardant l'intrigue et en essayant de regarder la région avec le gradient le plus raide.
Voici un exemple de tracé de test de plage LR (DenseNet formé sur CIFAR10) de notre Colab cahier:

En règle générale, si vous ne faites pas de trucs sophistiqués de calendrier de taux d'apprentissage, réglez simplement votre taux d'apprentissage constant à un ordre de grandeur inférieur à la valeur minimale du graphique. Dans ce cas, ce serait à peu près 1e-2.
La partie la plus intéressante de cette méthode, à part qu'elle fonctionne très bien et vous évite le temps, l'effort mental et les calculs nécessaires pour trouver de bons hyperparamètres avec d'autres algorithmes, c'est qu'elle ne coûte pratiquement aucun calcul supplémentaire.
Alors que les autres algorithmes, à savoir la recherche de grille, la recherche aléatoire et Optimisation bayésienne, vous oblige à exécuter un projet entier de manière tangentielle à votre objectif de formation d'un bon réseau neuronal, le test de portée LR exécute simplement une boucle d'apprentissage simple et régulière et garde la trace de quelques variables en cours de route.
Voici le type de vitesse de convergence auquel vous pouvez vous attendre lorsque vous utilisez un taux d'apprentissage optimal (de l'exemple du cahier):

Le test de la gamme LR a été mis en œuvre par l'équipe à rapide.ai, et vous devriez certainement jeter un œil à leur bibliothèque pour implémenter le test de plage LR (ils l'appellent le chercheur de taux d'apprentissage) ainsi que de nombreux autres algorithmes avec facilité.
Pour le praticien du Deep Learning plus sophistiqué
Si vous êtes intéressé, il y a aussi un cahier écrit en pur pytorch qui met en œuvre ce qui précède. Cela pourrait vous donner une meilleure compréhension du processus de formation en coulisse. Vérifiez-le ici.
Épargnez-vous l'effort

Bien sûr, tous ces algorithmes, aussi bons soient-ils, ne fonctionnent pas toujours dans la pratique. Il y a beaucoup plus de facteurs à prendre en compte lors de la formation des réseaux neuronaux, tels que la façon dont vous allez prétraiter vos données, définir votre modèle et obtenir un ordinateur suffisamment puissant pour exécuter ce sacré truc.
nanonets fournit des API faciles à utiliser pour former et déployer un apprentissage en profondeur personnalisé des modèles. Il s'occupe de tous les gros travaux, y compris l'augmentation des données, l'apprentissage par transfert et oui, l'optimisation des hyperparamètres!
nanonets utilise la recherche bayésienne sur leurs vastes clusters de GPU pour trouver le bon ensemble d'hyperparamètres sans que vous ayez à vous soucier de dépenser de l'argent sur la dernière carte graphique et out of bounds for axis 0.
Une fois qu'il trouve le meilleur modèle, nanonets le sert sur leur cloud pour vous permettre de tester le modèle à l'aide de leur interface web ou de l'intégrer dans votre programme en utilisant 2 lignes de code.
Dites adieu aux modèles moins que parfaits.
Conclusion
Dans cet article, nous avons parlé des hyperparamètres et de quelques méthodes pour les optimiser. Mais qu'est-ce que tout cela veut dire?
Alors que nous essayons de plus en plus de démocratiser la technologie de l'IA, le réglage automatisé des hyperparamètres est probablement un pas dans la bonne direction. Cela permet aux gens ordinaires comme vous et moi de créer des applications d'apprentissage en profondeur incroyables sans doctorat en mathématiques.
Bien que l'on puisse affirmer que rendre le modèle avide de puissance de calcul laisse les meilleurs modèles entre les mains de ceux qui peuvent se permettre cette puissance de calcul, les services cloud comme AWS et Nanonets aident à démocratiser l'accès à des machines puissantes, rendant l'apprentissage en profondeur beaucoup plus accessible.
Mais plus fondamentalement, ce que nous sommes actually faire ici en utilisant les mathématiques pour résoudre plus de mathématiques. Ce qui est intéressant non seulement en raison de la façon dont cela sonne méta, mais aussi en raison de la facilité avec laquelle il peut être mal interprété.

Nous avons certainement parcouru un long chemin depuis l'ère des cartes perforées et des tables de trace jusqu'à une époque où nous optimisons les fonctions qui optimisent les fonctions qui optimisent les fonctions. Mais nous sommes loin de construire des machines capables de «penser» par elles-mêmes.
Et ce n'est pas du tout décourageant, car si l'humanité peut faire tant de choses avec si peu, imaginez ce que l'avenir nous réserve, quand nos visions deviennent quelque chose que nous pouvons réellement voir.
Et donc nous nous asseyons, sur une chaise en maille rembourrée, regardant un écran de terminal vide, chaque frappe nous donnant un sudo superpuissance qui peut nettoyer le disque.
Et donc nous nous asseyons, nous restons assis là toute la journée, parce que la prochaine grande percée pourrait être juste une pip install
Paresseux pour coder? Vous ne voulez pas dépenser en ressources de calcul? Dirigez-vous vers nanonets et les Commencer à créer un modèle dès maintenant ! Réservez votre place aujourd'hui!
Vous pourriez être intéressé par nos derniers articles sur:
Source : https://nanonets.com/blog/hyperparameter-optimization/
- 7
- 9
- accès
- infection
- AI
- algorithme
- algorithmes
- Tous
- amp
- Apis
- applications
- architecture
- arguments
- article
- Audible
- Automatisation
- AV
- AWS
- LES MEILLEURS
- Milliards
- Bit
- Noir
- Black Friday
- construire
- Développement
- Bouquet
- Appelez-nous
- les soins
- cas
- Argent liquide
- Chats
- le cloud
- services de cloud computing
- code
- Commun
- calcul
- informatique
- Puissance de calcul
- Congrès
- continue
- Costs
- Crédits
- données
- journée
- l'apprentissage en profondeur
- Chiens
- chuté
- ingénieur
- estimations
- etc
- RAPIDE
- Figure
- trouve
- Prénom
- s'adapter
- suivre
- gratuitement ici
- Vendredi
- FS
- fonction
- avenir
- gif
- GitHub
- Don
- Or
- Bien
- GPU
- l'
- Grille
- front
- ici
- Haute
- Accueil
- Comment
- How To
- HTTPS
- Avide
- idée
- pouces
- Y compris
- d'information
- impliqué
- IT
- Emploi
- Emplois
- en gardant
- spécialisées
- gros
- Nouveautés
- APPRENTISSAGE
- apprentissage
- Bibliothèque
- littérature
- locales
- logo
- Location
- machine learning
- Les machines
- Majorité
- Fabrication
- Map
- math
- Médias
- moyenne
- mème
- Meta
- Métrique
- modèle
- Élan
- à savoir
- net
- réseau et
- Neural
- Réseau neuronal
- numéros
- de commander
- Autre
- Papier
- performant
- Poteaux
- power
- Programme
- Projet
- procuration
- gamme
- Tarifs
- RE
- un article
- Resources
- Résultats
- Courir
- SOLDE
- Escaliers intérieurs
- pour écran
- Rechercher
- Services
- set
- mise
- Shorts
- Signes
- étapes
- petit
- So
- RÉSOUDRE
- Space
- vitesse
- passer
- Spot
- Commencer
- j'ai commencé
- statistiques
- succès
- Surface
- surprise
- combustion propre
- Target
- Technologie
- tester
- El futuro
- théâtre
- thème
- fiable
- suivre
- Formation
- tutoriels
- Unsplash
- us
- utilitaire
- Plus-value
- Montres
- web
- WHO
- Vent
- activités principales
- vos contrats
- X







{kind=link}
{kind=link}
{kind=link}