Les grands modèles de langage (LLM) deviennent de plus en plus populaires et de nouveaux cas d'utilisation sont constamment explorés. En général, vous pouvez créer des applications alimentées par des LLM en incorporant une ingénierie rapide dans votre code. Cependant, il existe des cas où l'incitation à un LLM existant ne suffit pas. C’est là que l’ajustement du modèle peut s’avérer utile. L'ingénierie des invites consiste à guider la sortie du modèle en créant des invites de saisie, tandis que le réglage fin consiste à entraîner le modèle sur des ensembles de données personnalisés pour le rendre mieux adapté à des tâches ou des domaines spécifiques.
Avant de pouvoir affiner un modèle, vous devez rechercher un ensemble de données spécifique à une tâche. Un ensemble de données couramment utilisé est le Ensemble de données d'exploration commune. Le corpus Common Crawl contient des pétaoctets de données, régulièrement collectées depuis 2008, et contient des données brutes de pages Web, des extraits de métadonnées et des extraits de texte. En plus de déterminer quel ensemble de données doit être utilisé, il est nécessaire de nettoyer et de traiter les données selon les besoins spécifiques du réglage fin.
Nous avons récemment travaillé avec un client qui souhaitait prétraiter un sous-ensemble du dernier ensemble de données Common Crawl, puis affiner son LLM avec des données nettoyées. Le client cherchait comment y parvenir de la manière la plus rentable possible sur AWS. Après avoir discuté des exigences, nous avons recommandé d'utiliser Amazon EMR sans serveur comme plate-forme de prétraitement des données. EMR Serverless est bien adapté au traitement de données à grande échelle et élimine le besoin de maintenance de l'infrastructure. En termes de coût, il facture uniquement en fonction des ressources et de la durée utilisées pour chaque tâche. Le client a pu prétraiter des centaines de To de données en une semaine grâce à EMR Serverless. Après avoir prétraité les données, ils ont utilisé Amazon Sage Maker pour peaufiner le LLM.
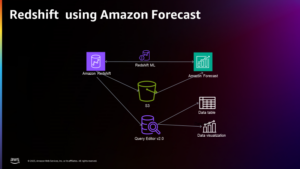
Dans cet article, nous vous présentons le cas d'utilisation du client et l'architecture utilisée.
Dans les sections suivantes, nous présentons d'abord l'ensemble de données Common Crawl et comment explorer et filtrer les données dont nous avons besoin. Amazone Athéna ne facture que la taille des données analysées et est utilisé pour explorer et filtrer les données rapidement, tout en étant rentable. EMR Serverless fournit une option rentable et sans maintenance pour le traitement des données Spark et est utilisé pour traiter les données filtrées. Ensuite, nous utilisons Amazon SageMaker JumpStart pour affiner le Modèle Lama 2 avec l’ensemble de données prétraité. SageMaker JumpStart fournit un ensemble de solutions pour les cas d'utilisation les plus courants qui peuvent être déployées en quelques clics. Vous n'avez pas besoin d'écrire de code pour affiner un LLM tel que Llama 2. Enfin, nous déployons le modèle affiné en utilisant Amazon Sage Maker et comparez les différences de sortie de texte pour la même question entre les modèles Llama 2 originaux et affinés.
Le schéma suivant illustre l'architecture de cette solution.
Avant de plonger dans les détails de la solution, effectuez les étapes préalables suivantes :
Common Crawl est un ensemble de données de corpus ouvert obtenu en explorant plus de 50 milliards de pages Web. Il comprend des quantités massives de données non structurées dans plusieurs langues, à partir de 2008 et atteignant le niveau du pétaoctet. Il est continuellement mis à jour.
Dans la formation de GPT-3, l'ensemble de données Common Crawl représente 60 % de ses données de formation, comme le montre le schéma suivant (source : Les modèles de langage sont des apprenants peu expérimentés).
Un autre ensemble de données important qui mérite d'être mentionné est le Jeu de données C4. C4, abréviation de Colossal Clean Crawled Corpus, est un ensemble de données dérivé du post-traitement de l'ensemble de données Common Crawl. Dans l'article LLaMA de Meta, ils ont décrit les ensembles de données utilisés, Common Crawl représentant 67 % (utilisant 3.3 To de données) et C4 15 % (utilisant 783 Go de données). Le document souligne l'importance d'incorporer des données prétraitées différemment pour améliorer les performances du modèle. Bien que les données C4 originales fassent partie de Common Crawl, Meta a opté pour la version retraitée de ces données.
Dans cette section, nous abordons les méthodes courantes d'interaction, de filtrage et de traitement de l'ensemble de données Common Crawl.
L'ensemble de données brutes Common Crawl comprend trois types de fichiers de données : les données brutes de pages Web (WARC), les métadonnées (WAT) et l'extraction de texte (WET).
Les données collectées après 2013 sont stockées au format WARC et comprennent les métadonnées correspondantes (WAT) et les données d'extraction de texte (WET). L'ensemble de données se trouve dans Amazon S3, mis à jour mensuellement et est accessible directement via Marketplace AWS .
$ aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2023-23/
PRE segments/
2023-06-21 00:34:08 2164 cc-index-table.paths.gz
2023-06-21 00:34:08 637 cc-index.paths.gz
2023-06-21 05:52:05 2724 index.html
2023-06-21 00:34:09 161064 non200responses.paths.gz
2023-06-21 00:34:10 160888 robotstxt.paths.gz
2023-06-21 00:34:10 480 segment.paths.gz
2023-06-21 00:34:11 161082 warc.paths.gz
2023-06-21 00:34:12 160895 wat.paths.gz
2023-06-21 00:34:12 160898 wet.paths.gzL'ensemble de données Common Crawl fournit également une table d'index pour filtrer les données, appelée cc-index-table.
Le cc-index-table est un index des données existantes, fournissant un index basé sur une table des fichiers WARC. Il permet de rechercher facilement des informations, telles que le fichier WARC correspondant à une URL spécifique.
Par exemple, vous pouvez créer une table Athena pour mapper les données cc-index avec le code suivant :
Les instructions SQL précédentes montrent comment créer une table Athena, ajouter des partitions et exécuter une requête.
Filtrer les données de l'ensemble de données Common Crawl
Comme vous pouvez le voir dans l'instruction SQL de création de table, plusieurs champs peuvent aider à filtrer les données. Par exemple, si vous souhaitez obtenir le nombre de documents chinois pendant une période spécifique, l'instruction SQL pourrait être la suivante :
Si vous souhaitez effectuer un traitement ultérieur, vous pouvez enregistrer les résultats dans un autre compartiment S3.
Analyser les données filtrées
Les Dépôt GitHub Common Crawl fournit plusieurs exemples PySpark pour traiter les données brutes.
Regardons un exemple d'exécution server_count.py (exemple de script fourni par le repo Common Crawl GitHub) sur les données situées dans s3://commoncrawl/crawl-data/CC-MAIN-2023-23/segments/1685224643388.45/warc/.
Tout d’abord, vous avez besoin d’un environnement Spark, tel qu’EMR Spark. Par exemple, vous pouvez lancer un cluster Amazon EMR sur EC2 dans us-east-1 (parce que l'ensemble de données est en us-east-1). L'utilisation d'un cluster EMR sur EC2 peut vous aider à effectuer des tests avant de soumettre des tâches à l'environnement de production.
Après avoir lancé un cluster EMR sur EC2, vous devez vous connecter SSH au nœud principal du cluster. Ensuite, emballez l'environnement Python et soumettez le script (reportez-vous au Documentation Conda pour installer Miniconda) :
Le traitement de toutes les références dans warc.path peut prendre du temps. À des fins de démonstration, vous pouvez améliorer le temps de traitement avec les stratégies suivantes :
- Télécharger le fichier
s3://commoncrawl/crawl-data/CC-MAIN-2023-23/warc.paths.gzsur votre ordinateur local, décompressez-le, puis téléchargez-le sur HDFS ou Amazon S3. En effet, le fichier .gzip n'est pas divisible. Vous devez le décompresser pour traiter ce fichier en parallèle. - Modifier la
warc.pathfichier, supprimez la plupart de ses lignes et ne conservez que deux lignes pour que le travail s'exécute beaucoup plus rapidement.
Une fois le travail terminé, vous pouvez voir le résultat dans s3://xxxx-common-crawl/output/, au format Parquet.
Implémenter une logique de possession personnalisée
Le dépôt Common Crawl GitHub fournit une approche commune pour traiter les fichiers WARC. Généralement, vous pouvez prolonger la CCSparkJob pour remplacer une seule méthode (process_record), ce qui est suffisant dans de nombreux cas.
Regardons un exemple pour obtenir les critiques IMDB de films récents. Tout d'abord, vous devez filtrer les fichiers sur le site IMDB :
Vous pouvez ensuite obtenir des listes de fichiers WARC contenant des données de révision IMDB et enregistrer les noms de fichiers WARC sous forme de liste dans un fichier texte.
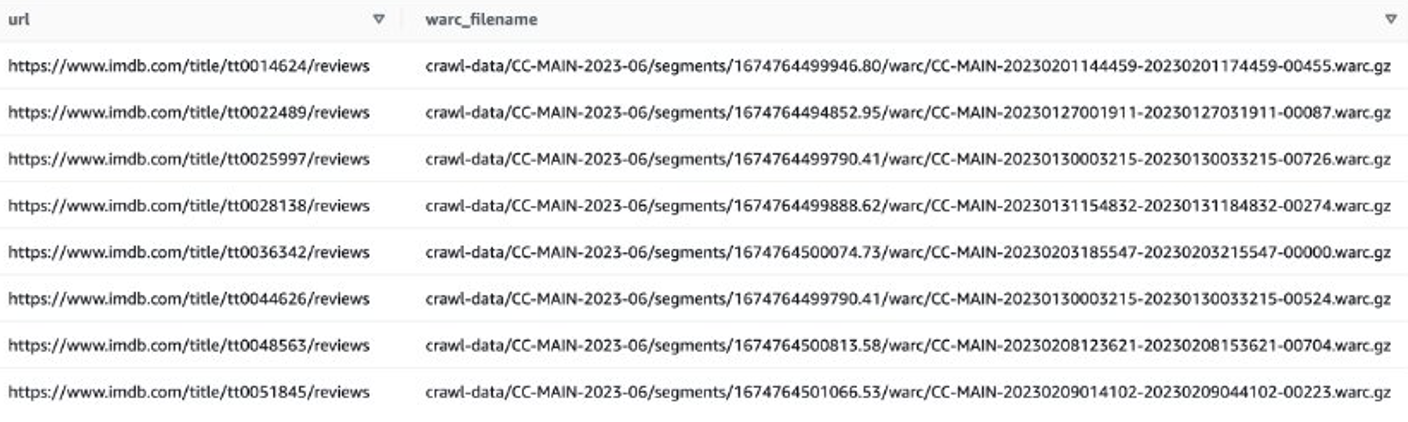
Vous pouvez également utiliser EMR Spark pour obtenir la liste des fichiers WARC et la stocker dans Amazon S3. Par exemple:
Le fichier de sortie devrait ressembler à s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt.
L'étape suivante consiste à extraire les avis des utilisateurs de ces fichiers WARC. Vous pouvez prolonger le CCSparkJob pour outrepasser le process_record() méthode:
Vous pouvez enregistrer le script précédent sous imdb_extractor.py, que vous utiliserez dans les étapes suivantes. Après avoir préparé les données et les scripts, vous pouvez utiliser EMR Serverless pour traiter les données filtrées.
EMR sans serveur
EMR Serverless est une option de déploiement sans serveur permettant d'exécuter des applications d'analyse Big Data à l'aide de frameworks open source comme Apache Spark et Hive sans configurer, gérer et mettre à l'échelle des clusters ou des serveurs.
Avec EMR Serverless, vous pouvez exécuter des charges de travail d'analyse à n'importe quelle échelle grâce à une mise à l'échelle automatique qui redimensionne les ressources en quelques secondes pour répondre à l'évolution des volumes de données et des exigences de traitement. EMR Serverless augmente et diminue automatiquement les ressources pour fournir la capacité appropriée à votre application, et vous ne payez que pour ce que vous utilisez.
Le traitement de l'ensemble de données Common Crawl est généralement une tâche de traitement unique, ce qui le rend adapté aux charges de travail EMR sans serveur.
Créer une application sans serveur EMR
Vous pouvez créer une application EMR Serverless sur la console EMR Studio. Effectuez les étapes suivantes :
- Sur la console EMR Studio, choisissez Applications sous Sans serveur dans le volet de navigation.
- Selectionnez Créer une application.

- Fournissez un nom pour l'application et choisissez une version Amazon EMR.

- Si l'accès aux ressources VPC est requis, ajoutez un paramètre réseau personnalisé.

- Selectionnez Créer une application.
Votre environnement sans serveur Spark sera alors prêt.
Avant de pouvoir soumettre une tâche à EMR Spark Serverless, vous devez toujours créer un rôle d'exécution. Faire référence à Premiers pas avec Amazon EMR sans serveur pour plus de détails.
Traiter les données Common Crawl avec EMR Serverless
Une fois votre application EMR Spark Serverless prête, procédez comme suit pour traiter les données :
- Préparez un environnement Conda et téléchargez-le sur Amazon S3, qui sera utilisé comme environnement dans EMR Spark Serverless.
- Téléchargez les scripts à exécuter dans un compartiment S3. Dans l'exemple suivant, il existe deux scripts :
- imbd_extractor.py – Logique personnalisée pour extraire le contenu de l’ensemble de données. Le contenu peut être trouvé plus tôt dans cet article.
- cc-pyspark/sparkcc.py – L’exemple de framework PySpark du Dépôt GitHub d'exploration commune, qu'il est nécessaire d'inclure.
- Soumettez la tâche PySpark à EMR Serverless Spark. Définissez les paramètres suivants pour exécuter cet exemple dans votre environnement :
- ID d'application – L’ID d’application de votre application EMR Serverless.
- exécution-rôle-arn – Votre rôle d’exécution EMR Serverless. Pour le créer, reportez-vous à Créer un rôle d'exécution de tâche.
- Emplacement du fichier WARC – L’emplacement de vos fichiers WARC.
s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txtcontient la liste de fichiers WARC filtrée, que vous avez obtenue plus tôt dans cet article. - spark.sql.warehouse.dir – L'emplacement de l'entrepôt par défaut (utilisez votre répertoire S3).
- spark.archives – L’emplacement S3 de l’environnement Conda préparé.
- spark.submit.pyFiles – Le script PySpark préparé sparkcc.py.
Voir le code suivant:
Une fois le travail terminé, les avis extraits sont stockés dans Amazon S3. Pour vérifier le contenu, vous pouvez utiliser Amazon S3 Select, comme indiqué dans la capture d'écran suivante.
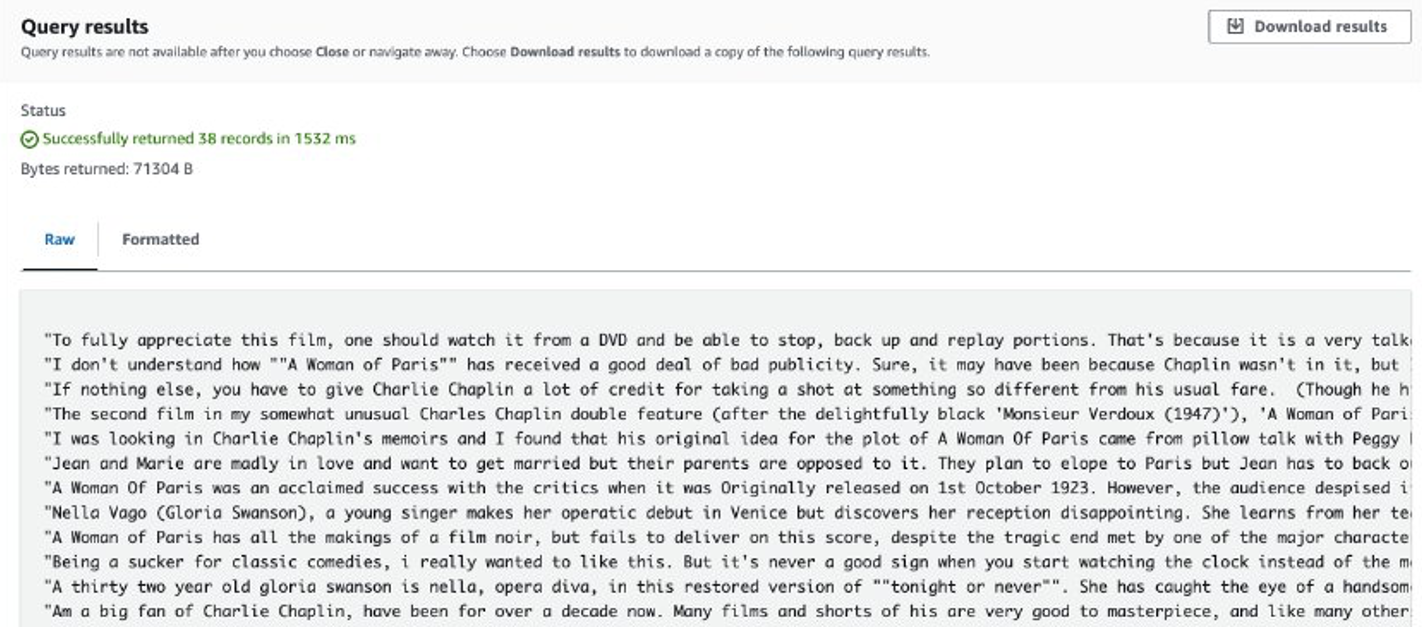
Considérations
Voici les points à prendre en compte lorsque vous traitez des quantités massives de données avec un code personnalisé :
- Certaines bibliothèques Python tierces peuvent ne pas être disponibles dans Conda. Dans de tels cas, vous pouvez passer à un environnement virtuel Python pour créer l'environnement d'exécution PySpark.
- S'il y a une énorme quantité de données à traiter, essayez de créer et d'utiliser plusieurs applications EMR Serverless Spark pour les paralléliser. Chaque application traite un sous-ensemble de listes de fichiers.
- Vous pouvez rencontrer un problème de ralentissement avec Amazon S3 lors du filtrage ou du traitement des données Common Crawl. En effet, le compartiment S3 stockant les données est accessible au public et d'autres utilisateurs peuvent accéder aux données en même temps. Pour atténuer ce problème, vous pouvez ajouter un mécanisme de nouvelle tentative ou synchroniser des données spécifiques du compartiment Common Crawl S3 vers votre propre compartiment.
Affiner Llama 2 avec SageMaker
Une fois les données préparées, vous pouvez affiner un modèle Llama 2 avec. Vous pouvez le faire en utilisant SageMaker JumpStart, sans écrire de code. Pour plus d'informations, reportez-vous à Affinez Llama 2 pour la génération de texte sur Amazon SageMaker JumpStart.
Dans ce scénario, vous effectuez un réglage fin de l'adaptation du domaine. Avec cet ensemble de données, l'entrée consiste en un fichier CSV, JSON ou TXT. Vous devez mettre toutes les données d'évaluation dans un fichier TXT. Pour ce faire, vous pouvez soumettre une tâche Spark simple à EMR Spark Serverless. Consultez l’exemple d’extrait de code suivant :
Après avoir préparé les données d'entraînement, entrez l'emplacement des données pour Ensemble de données d'entraînement, Puis choisissez Train.
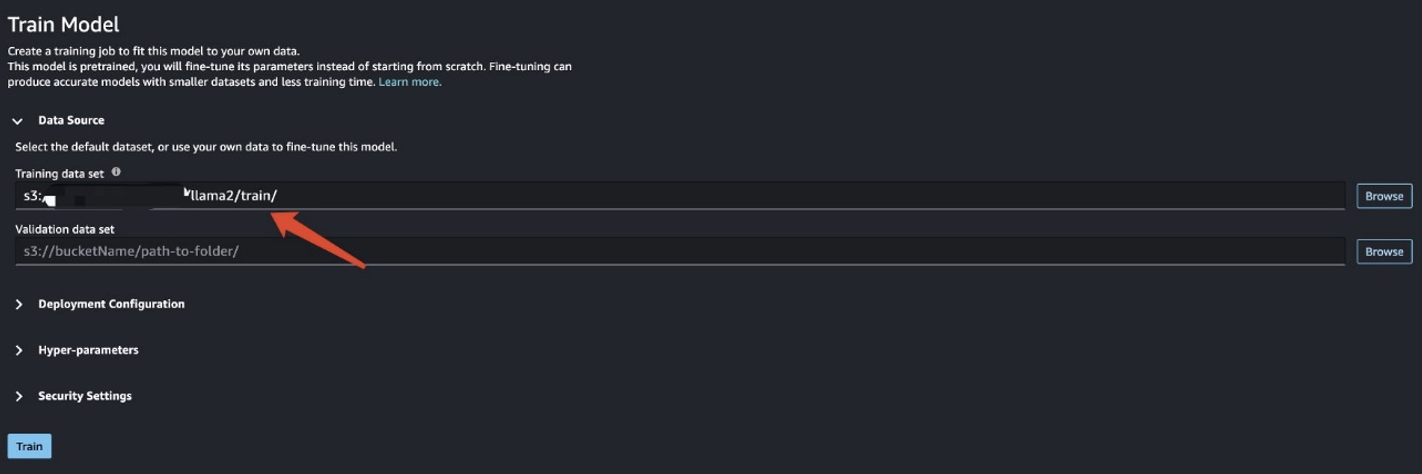
Vous pouvez suivre l'état du travail de formation.
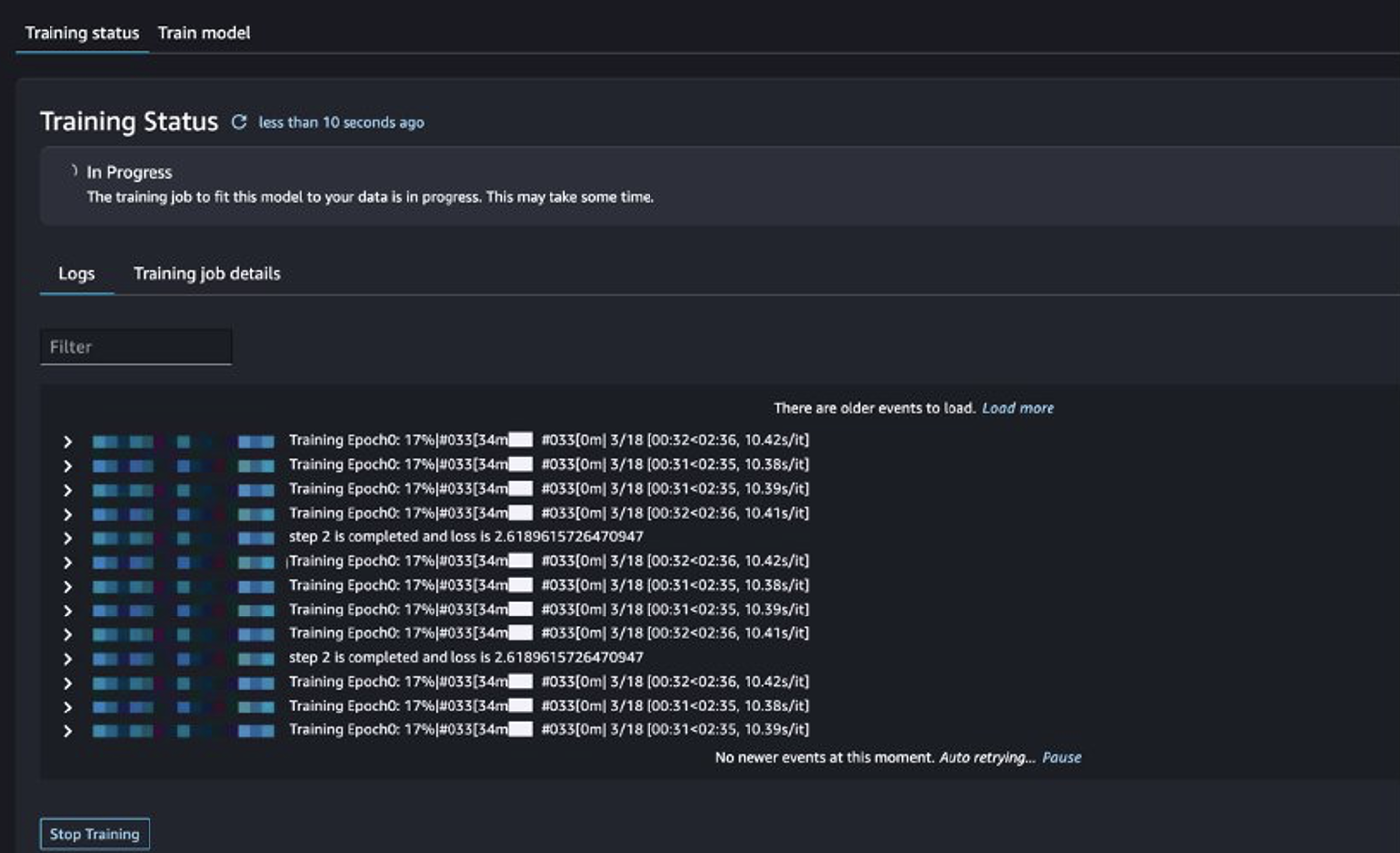
Évaluer le modèle affiné
Une fois la formation terminée, choisissez Déployer dans SageMaker JumpStart pour déployer votre modèle affiné.

Une fois le modèle déployé avec succès, choisissez Cahier ouvert, qui vous redirige vers un notebook Jupyter préparé dans lequel vous pouvez exécuter votre code Python.

Vous pouvez utiliser l'image Data Science 2.0 et le noyau Python 3 pour le notebook.
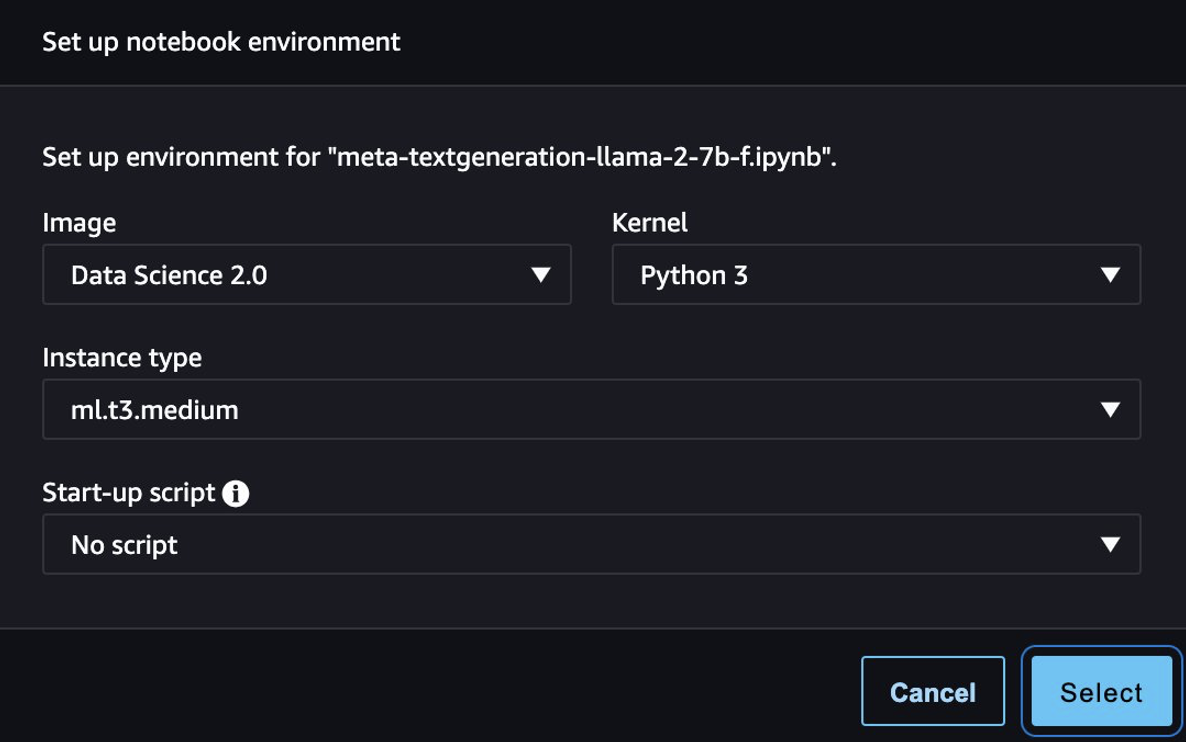
Ensuite, vous pouvez évaluer le modèle affiné et le modèle original dans ce cahier.
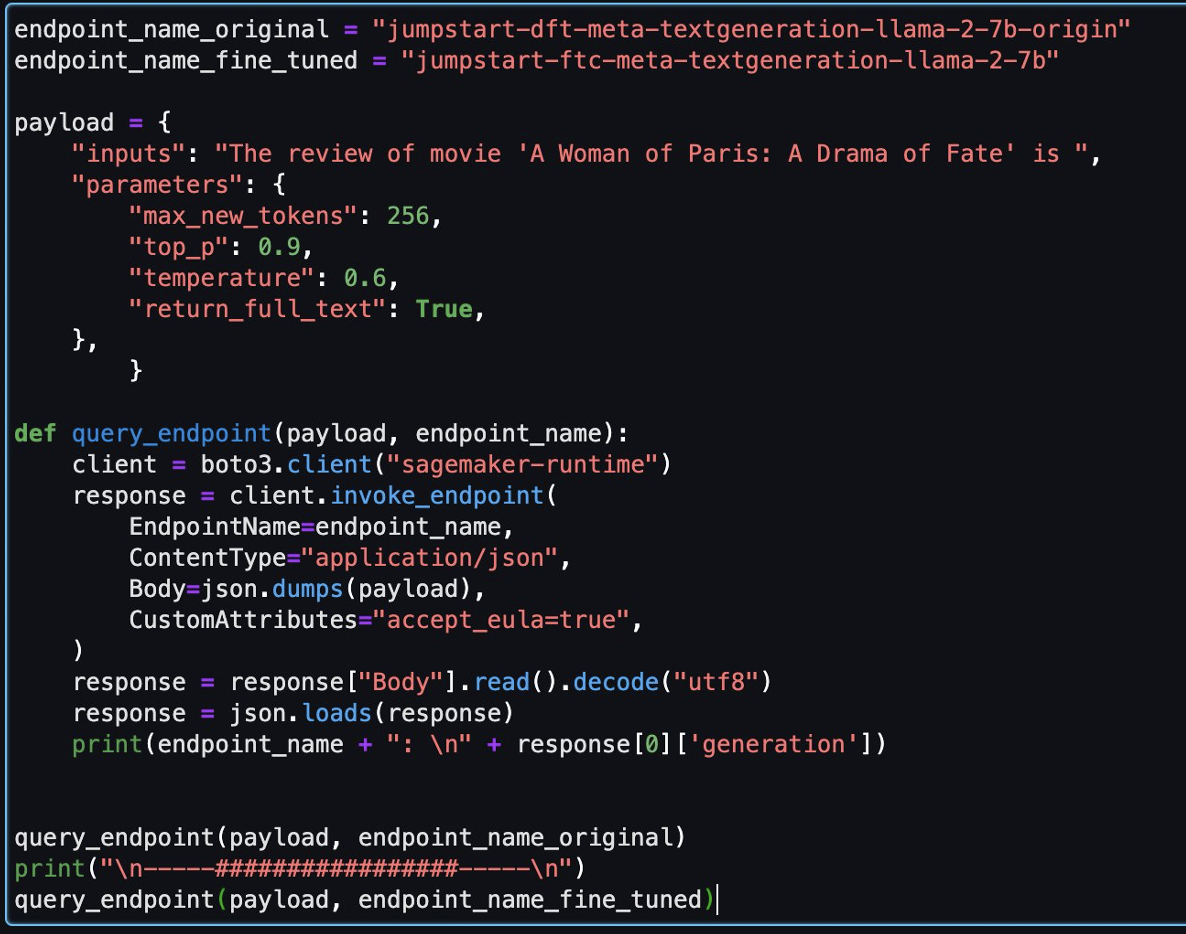
Voici deux réponses renvoyées par le modèle original et le modèle affiné pour la même question.

Nous avons fourni aux deux modèles la même phrase : « La critique du film « Une femme de Paris : un drame du destin » est » et les avons laissés compléter la phrase.
Le modèle original génère des phrases dénuées de sens :
"The review of movie 'A woman of Paris: A Drama of Fate' is 3.0/5.
A Woman of Paris: A Drama of Fate(1923)
A Woman of Paris: A Drama of Fate movie released on 17 October, 1992. The movie is directed by. A Woman of Paris: A Drama of Fate featured Jeanne Eagles, William Haines, Burr McIntosh and Jack Rollens in lead rols.
..."
En revanche, les résultats du modèle affiné ressemblent davantage à une critique de film :
" The review of movie 'A Woman of Paris: A Drama of Fate' is 6.3/10. I liked the story, the plot, the character, the background. The performances are amazing. Rory (Judy Davis) is an Australian photographer who travels to Africa to photograph the people, wildlife, and scenery. She meets Peter (Donald Sutherland), a zoologist, and they begin a relationship..."
De toute évidence, le modèle affiné fonctionne mieux dans ce scénario spécifique.
Nettoyer
Une fois cet exercice terminé, effectuez les étapes suivantes pour nettoyer vos ressources :
- Supprimer le compartiment S3 qui stocke l'ensemble de données nettoyé.
- Arrêtez l'environnement EMR sans serveur.
- Supprimer le point de terminaison SageMaker qui héberge le modèle LLM.
- Supprimer le domaine SageMaker qui exécute vos cahiers.
L'application que vous avez créée devrait s'arrêter automatiquement après 15 minutes d'inactivité par défaut.
En règle générale, vous n'avez pas besoin de nettoyer l'environnement Athena car il n'y a aucun frais lorsque vous ne l'utilisez pas.
Conclusion
Dans cet article, nous avons présenté l'ensemble de données Common Crawl et comment utiliser EMR Serverless pour traiter les données pour le réglage fin du LLM. Nous avons ensuite montré comment utiliser SageMaker JumpStart pour affiner le LLM et le déployer sans aucun code. Pour plus de cas d'utilisation d'EMR Serverless, reportez-vous à Amazon EMR sans serveur. Pour plus d'informations sur l'hébergement et le réglage précis des modèles sur Amazon SageMaker JumpStart, consultez le Documentation Sagemaker JumpStart.
À propos des auteurs
 Tang Shijian est un architecte de solutions spécialisé en analyse chez Amazon Web Services.
Tang Shijian est un architecte de solutions spécialisé en analyse chez Amazon Web Services.
 Matthieu Liem est responsable principal de l'architecture de solutions chez Amazon Web Services.
Matthieu Liem est responsable principal de l'architecture de solutions chez Amazon Web Services.
 Dalei Xu est un architecte de solutions spécialisé en analyse chez Amazon Web Services.
Dalei Xu est un architecte de solutions spécialisé en analyse chez Amazon Web Services.
 Yuan Jun Xiao est architecte de solutions senior chez Amazon Web Services.
Yuan Jun Xiao est architecte de solutions senior chez Amazon Web Services.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/preprocess-and-fine-tune-llms-quickly-and-cost-effectively-using-amazon-emr-serverless-and-amazon-sagemaker/
- :est
- :ne pas
- :où
- $UP
- 08
- 09
- 1
- 10
- 100
- 11
- 12
- 14
- 15%
- 17
- 2008
- 2013
- 23
- 258
- 40
- 50
- 52
- 7
- 9
- a
- Capable
- Qui sommes-nous
- accès
- accédé
- accessible
- Comptabilité
- hybrides
- atteindre
- activer
- ajouter
- ajout
- Afrique
- Après
- Tous
- permet
- aussi
- incroyable
- Amazon
- Amazon DME
- Amazon Sage Maker
- Amazon SageMaker JumpStart
- Amazon Web Services
- montant
- quantités
- an
- analytique
- ainsi que les
- Une autre
- tous
- Apache
- Apache Spark
- Application
- applications
- une approche
- architecture
- SONT
- AS
- At
- Australien
- Automatique
- automatiquement
- disponibles
- AWS
- fond
- basé
- base
- BE
- pour créer les plus
- car
- devenir
- before
- commencer
- va
- Améliorée
- jusqu'à XNUMX fois
- Big
- Big Data
- Milliards
- corps
- tous les deux
- construire
- by
- appelé
- CAN
- Peut obtenir
- Compétences
- porter
- maisons
- cas
- en changeant
- caractère
- des charges
- vérifier
- chinois
- Selectionnez
- classe
- espace extérieur plus propre,
- client
- Grappe
- code
- COM
- Commun
- communément
- comparer
- complet
- Configurer
- Considérer
- consiste
- Console
- constamment
- contiennent
- contient
- contenu
- continuellement
- contraste
- Correspondant
- correspond
- Prix
- rentable
- pourriez
- compter
- couverture
- engendrent
- créée
- Customiser
- des clients
- sont adaptées
- données
- Analyse de Donnée
- informatique
- science des données
- ensembles de données
- Davis
- traitement
- Offres
- profond
- Réglage par défaut
- Vous permet de définir
- Démo
- démontrer
- démontré
- déployer
- déployé
- déploiement
- Dérivé
- Malgré
- détails
- détermination
- diagramme
- différences
- différemment
- dirigé
- directement
- discuter
- plongeon
- do
- INSTITUTIONNELS
- domaine
- domaines
- donald
- Ne pas
- down
- Films dramatique
- driver
- durée
- pendant
- chacun
- Plus tôt
- Easy
- élimine
- souligne
- rencontre
- ENGINEERING
- améliorer
- Entrer
- Environment
- Ether (ETH)
- évaluer
- exemple
- exemples
- exécution
- Exercises
- existant
- existe
- explorez
- Exploré
- étendre
- externe
- extrait
- extraction
- Extraits
- Chutes
- non
- plus rapide
- sort
- en vedette
- few
- Des champs
- Déposez votre dernière attestation
- Fichiers
- une fonction filtre
- filtration
- finalement
- Trouvez
- finition
- Prénom
- Abonnement
- suit
- Pour
- le format
- trouvé
- Framework
- cadres
- de
- plus
- Général
- généralement
- générateur
- génération
- obtenez
- Git
- GitHub
- guidage
- Vous avez
- vous aider
- Ruche
- hébergement
- hôtes
- Comment
- How To
- Cependant
- HTML
- HTTPS
- Des centaines
- i
- IAM
- ID
- if
- illustre
- image
- importer
- important
- améliorer
- in
- inclus
- inclut
- incorporation
- croissant
- indice
- d'information
- Infrastructure
- contribution
- entrées
- installer
- interagir
- développement
- introduire
- introduit
- aide
- IT
- SES
- jack
- Emploi
- Emplois
- json
- Jupyter Notebook
- juste
- XNUMX éléments à
- ACTIVITES
- langue
- Langues
- grande échelle
- Nouveautés
- lancer
- lancement
- conduire
- laisser
- Niveau
- bibliothèques
- comme
- LIMIT
- lignes
- Liste
- Liste
- Flamme
- llm
- locales
- situé
- emplacement
- logique
- vous connecter
- Style
- recherchez-
- rechercher
- click
- facile
- a prendre une
- Fabrication
- manager
- les gérer
- de nombreuses
- Localisation
- massif
- Mai..
- mécanisme
- Découvrez
- Se rencontre
- mentionnant
- Meta
- Métadonnées
- méthode
- minutes
- Réduire les
- modèle
- numériques jumeaux (digital twin models)
- mensuel
- PLUS
- (en fait, presque toutes)
- film
- Films
- beaucoup
- plusieurs
- prénom
- noms
- Navigation
- nécessaire
- Besoin
- réseau et
- Nouveauté
- next
- aucune
- nœud
- cahier
- ordinateurs portables
- obtenu
- octobre
- of
- on
- ONE
- uniquement
- ouvert
- open source
- Option
- or
- original
- Autre
- ande
- décrit
- sortie
- sorties
- plus de
- Commande
- propre
- PACK
- paquet
- pain
- Papier
- Parallèle
- paramètres
- Paris
- partie
- chemin
- chemins
- Payer
- Personnes
- performant
- performances
- effectue
- période
- pétaoctet
- Peter
- photographe
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- parcelle
- des notes bonus
- Populaire
- Post
- alimenté
- pré
- précédant
- Préparer
- préparé
- primaire
- processus
- traité
- traitement
- Vidéo
- instructions
- fournir
- à condition de
- fournit
- aportando
- publiquement
- des fins
- mettre
- Python
- question
- question
- vite.
- raw
- les données brutes
- atteindre
- Lire
- solutions
- récent
- récemment
- recommandé
- record
- reportez-vous
- régulièrement
- relation amoureuse
- libéré
- réparation
- remplacer
- demandes
- conditions
- Exigences
- Resources
- réponse
- réponses
- résultat
- Résultats
- Avis
- Avis
- bon
- Rôle
- Rory
- Courir
- pour le running
- fonctionne
- sagemaker
- même
- Épargnez
- Escaliers intérieurs
- Balance
- mise à l'échelle
- analyse
- scénario
- Sciences
- scénario
- scripts
- secondes
- Section
- les sections
- sur le lien
- clignotant
- Sélectionner
- AUTO
- supérieur
- phrase
- Sans serveur
- serveurs
- Services
- set
- mise
- plusieurs
- elle
- Shorts
- devrait
- montré
- importance
- similaires
- depuis
- unique
- site
- Taille
- Ralentissez
- Fragment
- So
- sur mesure
- Solutions
- soupe
- Identifier
- Spark
- spécialiste
- groupe de neurones
- SQL
- ssh
- j'ai commencé
- Commencez
- Déclaration
- déclarations
- Statut
- étapes
- Étapes
- Encore
- Arrêter
- Boutique
- stockée
- STORES
- Histoire
- simple
- les stratégies
- Chaîne
- studio
- soumettre
- soumission
- Avec succès
- tel
- suffisant
- convient
- Interrupteur
- synchroniser.
- table
- Prenez
- Target
- Tâche
- tâches
- tensorflow
- conditions
- tests
- texte
- génération de texte
- qui
- Les
- leur
- Les
- puis
- Là.
- Ces
- l'ont
- des tiers.
- this
- trois
- Avec
- fiable
- horodatage
- à
- suivre
- Formation
- voyage
- oui
- Essai
- deux
- types
- sous
- déstructuré
- a actualisé
- URL
- utilisé
- cas d'utilisation
- d'utiliser
- Utilisateur
- Critiques d'utilisateurs
- utilisateurs
- en utilisant
- Utilisant
- version
- Salle de conférence virtuelle
- volumes
- marcher
- souhaitez
- voulu
- Entrepots
- était
- Façon..
- façons
- we
- web
- services Web
- semaine
- WELL
- Quoi
- quand
- Les
- qui
- tout en
- WHO
- Faune
- sera
- william
- comprenant
- dans les
- sans
- femme
- travaillé
- vaut
- écrire
- écriture
- Rendement
- you
- Votre
- zéphyrnet