Avec Amazon DME 6.15hXNUMX, nous avons lancé Formation AWS Lake basés sur des contrôles d'accès précis (FGAC) sur des formats de table ouverts (OTF), notamment Apache Hudi, Apache Iceberg et Delta Lake. Cela vous permet de simplifier la sécurité et la gouvernance sur lacs de données transactionnels en fournissant des contrôles d'accès au niveau des autorisations au niveau des tables, des colonnes et des lignes avec vos tâches Apache Spark. De nombreuses grandes entreprises cherchent à utiliser leur lac de données transactionnelles pour obtenir des informations et améliorer la prise de décision. Vous pouvez créer une architecture de maison en lac à l'aide d'Amazon EMR intégré à Lake Formation pour FGAC. Cette combinaison de services vous permet d'effectuer des analyses de données sur votre lac de données transactionnel tout en garantissant un accès sécurisé et contrôlé.
Le composant du serveur d'enregistrements Amazon EMR prend en charge la fonctionnalité de filtrage des données au niveau des tables, des colonnes, des lignes, des cellules et des attributs imbriqués. Il étend la prise en charge des formats Hive, Apache Hudi, Apache Iceberg et Delta Lake pour les opérations de lecture (y compris le voyage dans le temps et les requêtes incrémentielles) et d'écriture (sur les instructions DML telles que INSERT). De plus, avec la version 6.15, Amazon EMR introduit une protection de contrôle d'accès pour son interface Web d'application, telle que Spark History Server sur le cluster, Yarn Timeline Server et l'interface utilisateur Yarn Resource Manager.
Dans cet article, nous montrons comment implémenter FGAC sur Apache Hudi tables utilisant Amazon EMR intégré à Lake Formation.
Cas d'utilisation du lac de données de transaction
Les clients Amazon EMR utilisent souvent les formats Open Table pour prendre en charge leurs besoins en matière de transactions ACID et de voyages dans le temps dans un lac de données. En préservant les versions historiques, le voyage dans le temps des lacs de données offre des avantages tels que l'audit et la conformité, la récupération et la restauration des données, l'analyse reproductible et l'exploration des données à différents moments.
Un autre cas d’utilisation populaire du lac de données de transaction est la requête incrémentielle. La requête incrémentielle fait référence à une stratégie de requête qui se concentre sur le traitement et l'analyse uniquement des données nouvelles ou mises à jour dans un lac de données depuis la dernière requête. L'idée clé derrière les requêtes incrémentielles est d'utiliser des métadonnées ou des mécanismes de suivi des modifications pour identifier les données nouvelles ou modifiées depuis la dernière requête. En identifiant ces changements, le moteur de requête peut optimiser la requête pour traiter uniquement les données pertinentes, réduisant ainsi considérablement le temps de traitement et les besoins en ressources.
Vue d'ensemble de la solution
Dans cet article, nous montrons comment implémenter FGAC sur les tables Apache Hudi à l'aide d'Amazon EMR sur Cloud de calcul élastique Amazon (Amazon EC2) intégré à Lake Formation. Apache Hudi est un framework de lac de données transactionnel open source qui simplifie grandement le traitement incrémentiel des données et le développement de pipelines de données. Cette nouvelle fonctionnalité FGAC prend en charge tous les OTF. En plus de démontrer avec Hudi ici, nous ferons un suivi avec d'autres tables OTF sur d'autres blogs. Nous utilisons ordinateurs portables in Amazon SageMakerStudio pour lire et écrire des données Hudi via différentes autorisations d'accès utilisateur via un cluster EMR. Cela reflète des scénarios d'accès aux données réels : par exemple, si un utilisateur technique a besoin d'un accès complet aux données pour résoudre des problèmes sur une plate-forme de données, alors que les analystes de données peuvent n'avoir besoin d'accéder qu'à un sous-ensemble de ces données qui ne contient pas d'informations personnellement identifiables (PII). ). Intégration à Lake Formation via le Rôle d'exécution Amazon EMR vous permet en outre d'améliorer votre posture de sécurité des données et simplifie la gestion du contrôle des données pour les charges de travail Amazon EMR. Cette solution garantit un environnement sécurisé et contrôlé pour l'accès aux données, répondant aux divers besoins et exigences de sécurité des différents utilisateurs et rôles dans une organisation.
Le diagramme suivant illustre l'architecture de la solution.
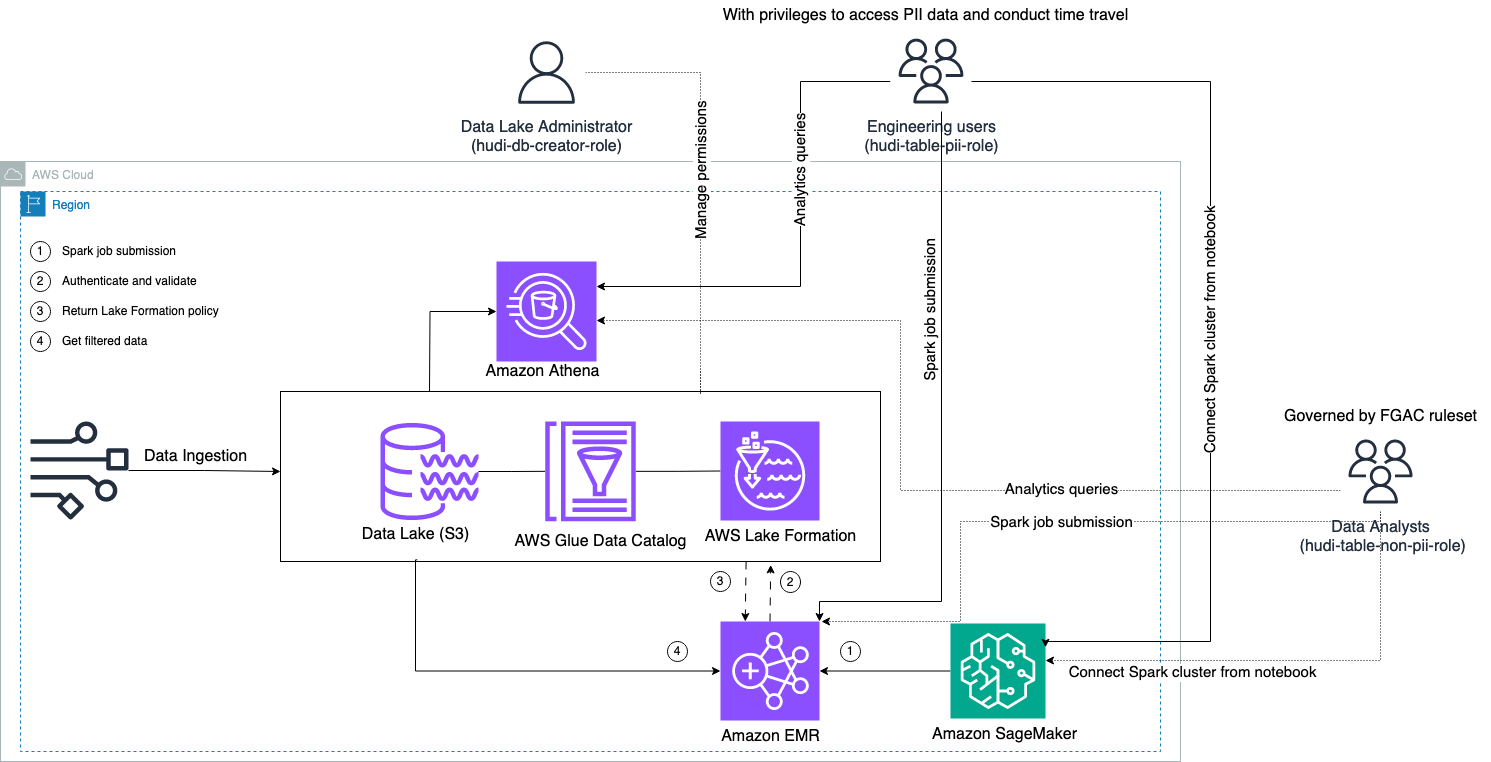
Nous effectuons un processus d'ingestion de données pour insérer (mettre à jour et insérer) un ensemble de données Hudi dans un Service de stockage simple Amazon (Amazon S3) et conserver ou mettre à jour le schéma de table dans le Colle AWS Catalogue de données. Sans aucun mouvement de données, nous pouvons interroger la table Hudi régie par Lake Formation via divers services AWS, tels que Amazone Athéna, Amazon EMR et Amazon Sage Maker.
Lorsque les utilisateurs soumettent une tâche Spark via n'importe quel point de terminaison du cluster EMR (EMR Steps, Livy, EMR Studio et SageMaker), Lake Formation valide leurs privilèges et demande au cluster EMR de filtrer les données sensibles telles que les données PII.
Cette solution propose trois types d'utilisateurs différents avec différents niveaux d'autorisations pour accéder aux données Hudi :
- hudi-db-créateur-rôle – Ceci est utilisé par l'administrateur du lac de données qui dispose de privilèges pour effectuer des opérations DDL telles que la création, la modification et la suppression d'objets de base de données. Ils peuvent définir des règles de filtrage des données sur Lake Formation pour le contrôle d'accès aux données au niveau des lignes et des colonnes. Ces règles FGAC garantissent que le lac de données est sécurisé et respecte les réglementations requises en matière de confidentialité des données.
- hudi-table-pii-rôle – Ceci est utilisé par les utilisateurs ingénieurs. Les utilisateurs ingénieurs sont capables d'effectuer des voyages dans le temps et des requêtes incrémentielles à la fois sur la copie sur écriture (CoW) et sur la fusion sur lecture (MoR). Ils ont également le privilège d’accéder aux données PII en fonction de n’importe quel horodatage.
- hudi-table-non-pii-role – Ceci est utilisé par les analystes de données. Les droits d’accès aux données des analystes de données sont régis par les règles autorisées du FGAC et contrôlées par les administrateurs de lacs de données. Ils n'ont pas de visibilité sur les colonnes contenant des données PII telles que les noms et les adresses. De plus, ils ne peuvent pas accéder aux lignes de données qui ne remplissent pas certaines conditions. Par exemple, les utilisateurs ne peuvent accéder qu'aux lignes de données appartenant à leur pays.
Pré-requis
Vous pouvez télécharger les trois cahiers utilisés dans cet article depuis le GitHub repo.
Avant de déployer la solution, assurez-vous de disposer des éléments suivants :
Suivez les étapes suivantes pour configurer vos autorisations :
- Connectez-vous à votre compte AWS avec votre utilisateur administrateur IAM.
Assurez-vous que vous êtes dans leus-east-1Région.
- Créez un compartiment S3 dans le
us-east-1Région (par exemple,emr-fgac-hudi-us-east-1-<ACCOUNT ID>).
Ensuite, nous activons Lake Formation en changer le modèle d'autorisation par défaut.
- Connectez-vous à la console Lake Formation en tant qu'utilisateur administrateur.
- Selectionnez Paramètres du catalogue de données sous Administration dans le volet de navigation.
- Sous Autorisations par défaut pour les bases de données et les tables nouvellement créées, désélectionner Utiliser uniquement le contrôle d'accès IAM pour les nouvelles bases de données ainsi que les Utiliser uniquement le contrôle d'accès IAM pour les nouvelles tables dans les nouvelles bases de données.
- Selectionnez Épargnez.
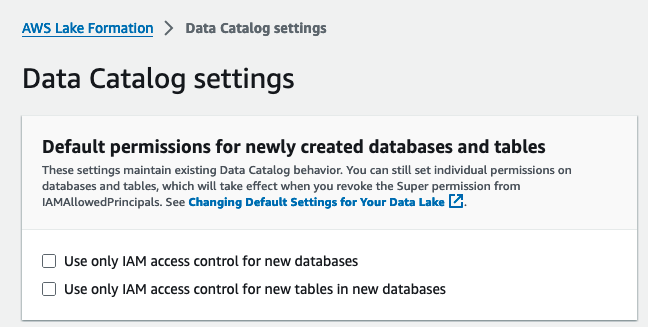
Vous devez également révoquer les IAMAllowedPrincipals sur les ressources (bases de données et tables) créées si vous avez démarré Lake Formation avec l'option par défaut.
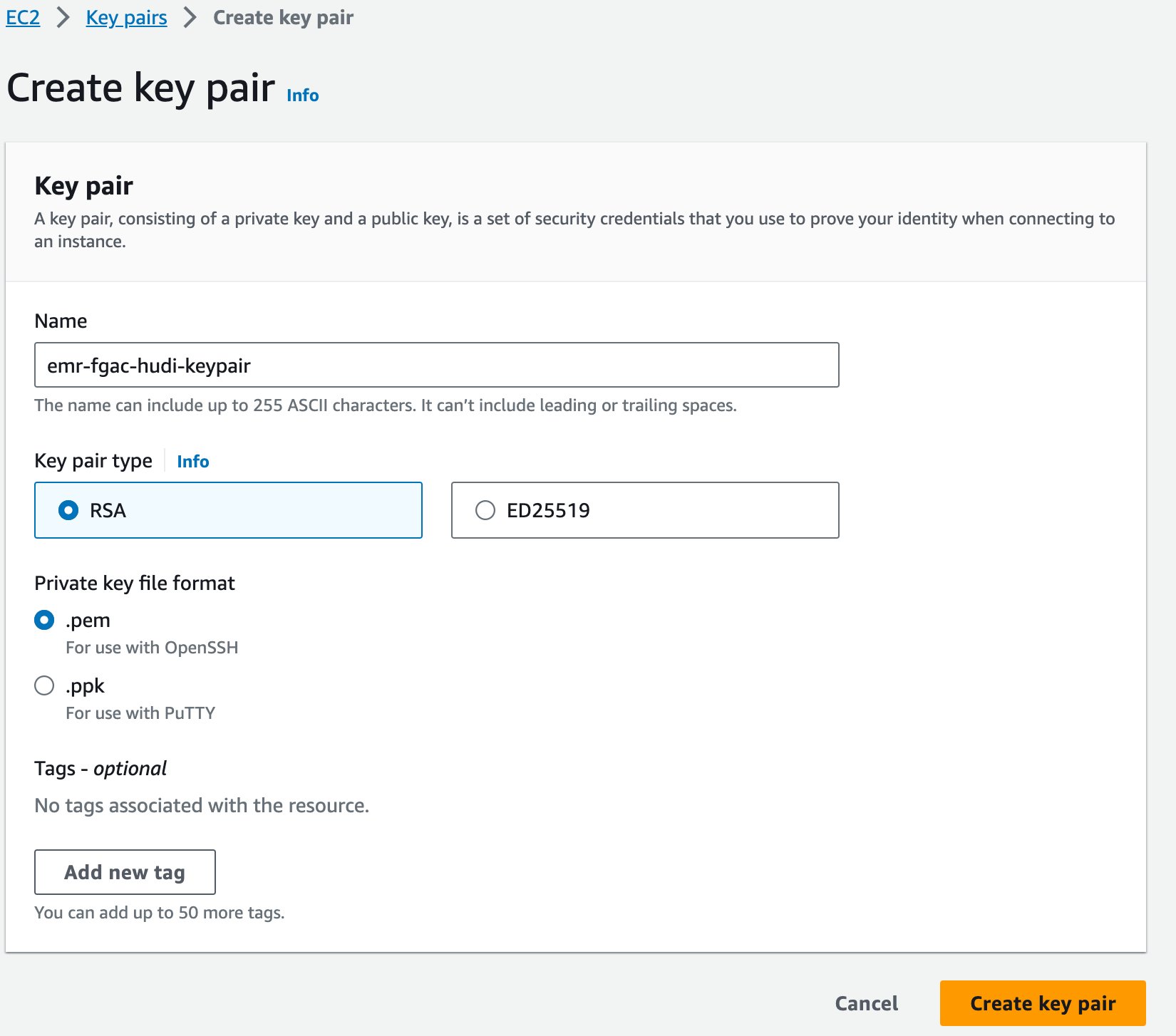
Enfin, nous créons une paire de clés pour Amazon EMR.
- Sur la console Amazon EC2, choisissez Paires de clés dans le volet de navigation.
- Selectionnez Créer une paire de clés.
- Pour Nom, saisissez un nom (par exemple
emr-fgac-hudi-keypair). - Selectionnez Créer une paire de clés.
La paire de clés générée (pour cet article, emr-fgac-hudi-keypair.pem) sera enregistré sur votre ordinateur local.
Ensuite, nous créons un AWSCloud9 environnement de développement interactif (IDE).
- Sur la console AWS Cloud9, choisissez Environnements dans le volet de navigation.
- Selectionnez Créer un environnement.
- Pour Nom¸ entrez un nom (par exemple,
emr-fgac-hudi-env). - Conservez les autres paramètres par défaut.
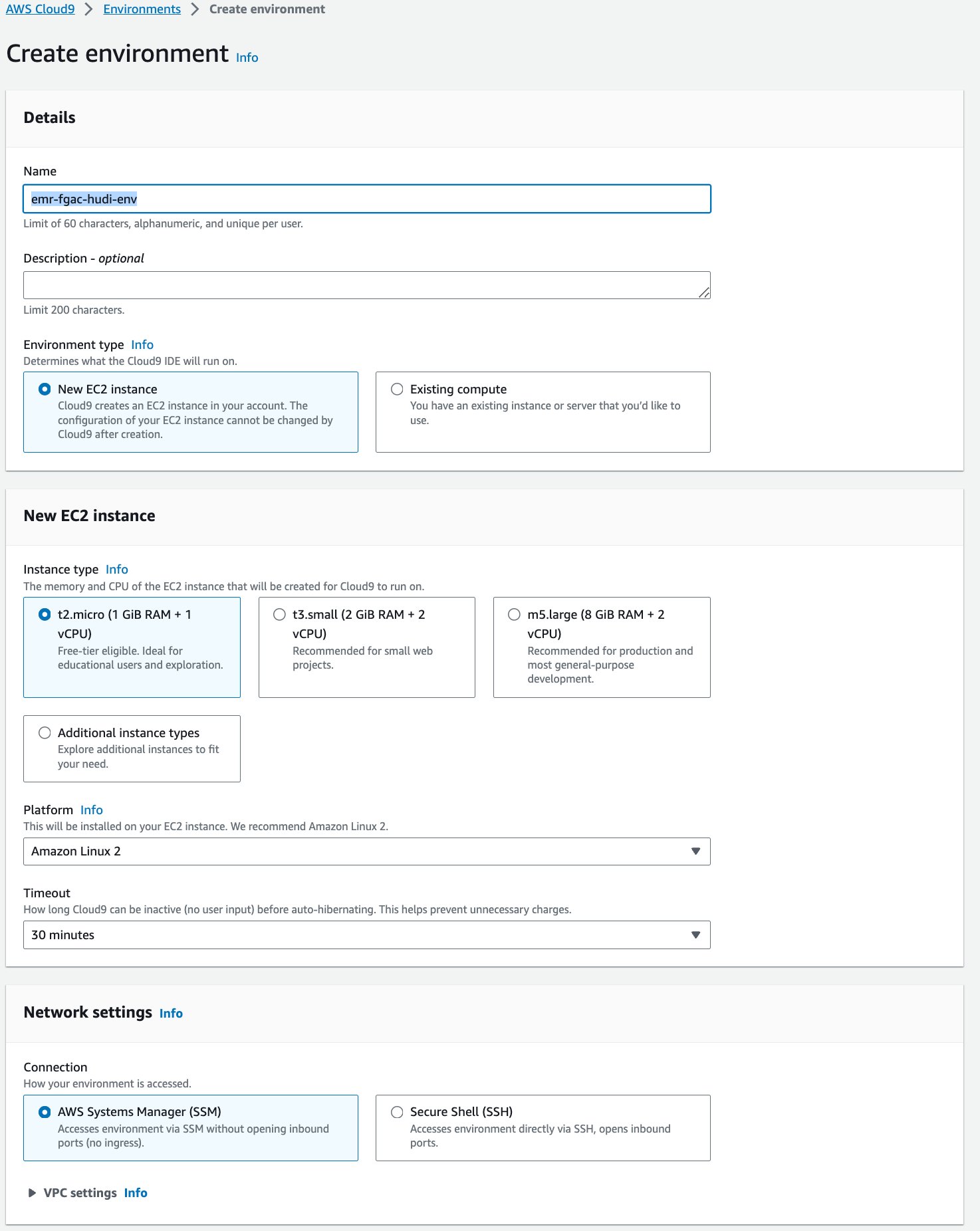
- Selectionnez Création.
- Lorsque l'EDI est prêt, choisissez Ouvert pour l'ouvrir.
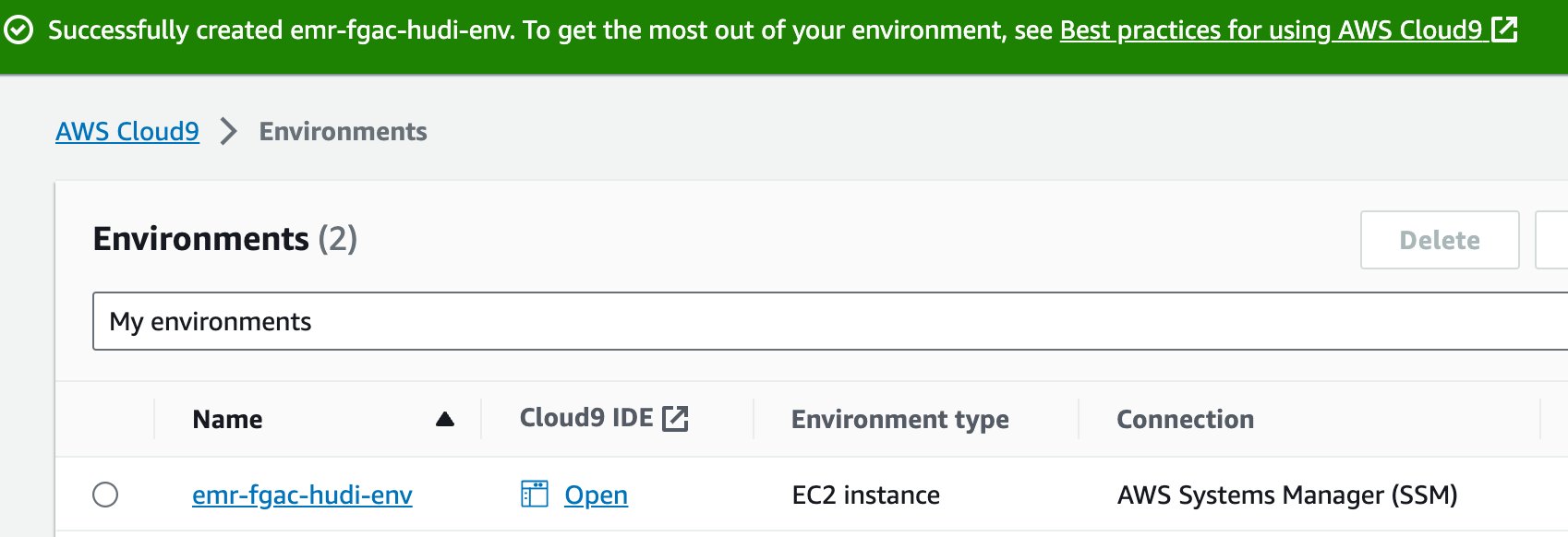
- Dans l'IDE AWS Cloud9, sur le Déposez votre dernière attestation menu, choisissez Télécharger des fichiers locaux.

- Téléchargez le fichier de paire de clés (
emr-fgac-hudi-keypair.pem). - Choisissez le signe plus et choisissez Nouveau terminal.
- Dans le terminal, saisissez les lignes de commande suivantes :
Notez que l'exemple de code est une preuve de concept à des fins de démonstration uniquement. Pour les systèmes de production, utilisez une autorité de certification (CA) de confiance pour émettre des certificats. Faire référence à Fournir des certificats pour chiffrer les données en transit avec le chiffrement Amazon EMR pour en savoir plus.
Déployer la solution via AWS CloudFormation
Nous fournissons un AWS CloudFormation modèle qui configure automatiquement les services et composants suivants :
- Un compartiment S3 pour le lac de données. Il contient l'exemple d'ensemble de données TPC-DS.
- Un cluster EMR avec configuration de sécurité et DNS public activés.
- Rôles IAM d'exécution EMR avec autorisations précises de Lake Formation :
- -hudi-db-creator-role – Ce rôle est utilisé pour créer la base de données et les tables Apache Hudi.
- -hudi-table-pii-role – Ce rôle donne l'autorisation d'interroger toutes les colonnes des tables Hudi, y compris les colonnes avec des informations personnelles.
- -hudi-table-non-pii-role – Ce rôle donne l'autorisation d'interroger les tables Hudi qui ont filtré les colonnes PII par Lake Formation.
- Rôles d'exécution de SageMaker Studio qui permettent aux utilisateurs d'assumer leurs rôles d'exécution EMR correspondants.
- Ressources réseau telles que VPC, sous-réseaux et groupes de sécurité.
Effectuez les étapes suivantes pour déployer les ressources :
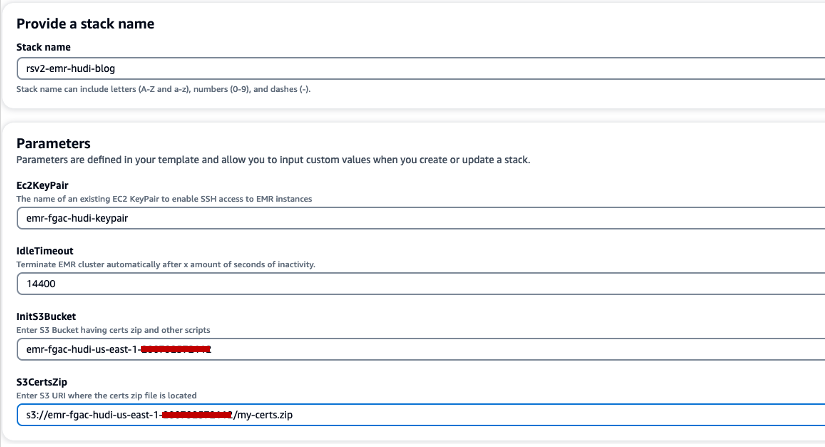
- Selectionnez Création rapide d'une pile pour lancer la pile CloudFormation.
- Pour Nom de la pile, saisissez un nom de pile (par exemple,
rsv2-emr-hudi-blog). - Pour Ec2KeyPaire, saisissez le nom de votre paire de clés.
- Pour Délai d'inactivité, saisissez un délai d'inactivité pour le cluster EMR afin d'éviter de payer pour le cluster lorsqu'il n'est pas utilisé.
- Pour InitS3Bucket, saisissez le nom du compartiment S3 que vous avez créé pour enregistrer le fichier .zip du certificat de chiffrement Amazon EMR.
- Pour S3CertsZip, saisissez l'URI S3 du fichier .zip du certificat de chiffrement Amazon EMR.
- Sélectionnez Je reconnais qu'AWS CloudFormation peut créer des ressources IAM avec des noms personnalisés.
- Selectionnez Créer une pile.
Le déploiement de la pile CloudFormation prend environ 10 minutes.
Configurer Lake Formation pour l'intégration d'Amazon EMR
Effectuez les étapes suivantes pour configurer Lake Formation :
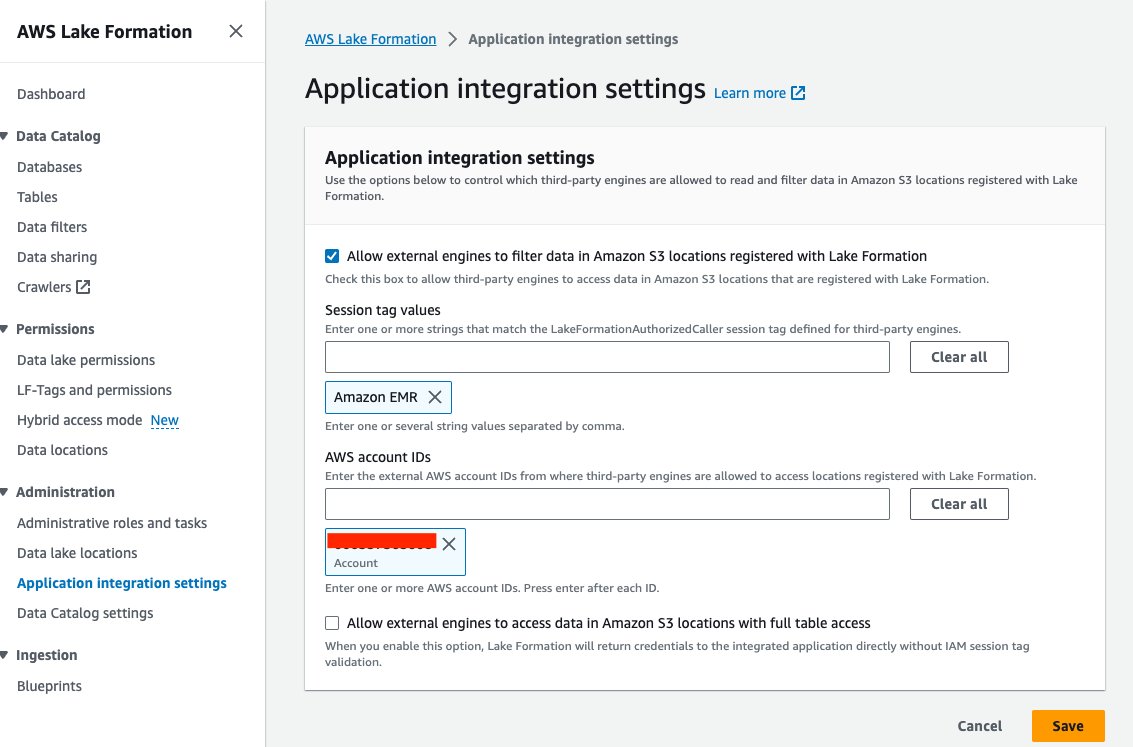
- Sur la console Lake Formation, choisissez Paramètres d'intégration d'applications sous Administration dans le volet de navigation.
- Sélectionnez Autoriser les moteurs externes à filtrer les données dans les emplacements Amazon S3 enregistrés auprès de Lake Formation.
- Selectionnez Amazon DME en Valeurs des balises de session.
- Entrez votre ID de compte AWS pour ID de compte AWS.
- Selectionnez Épargnez.
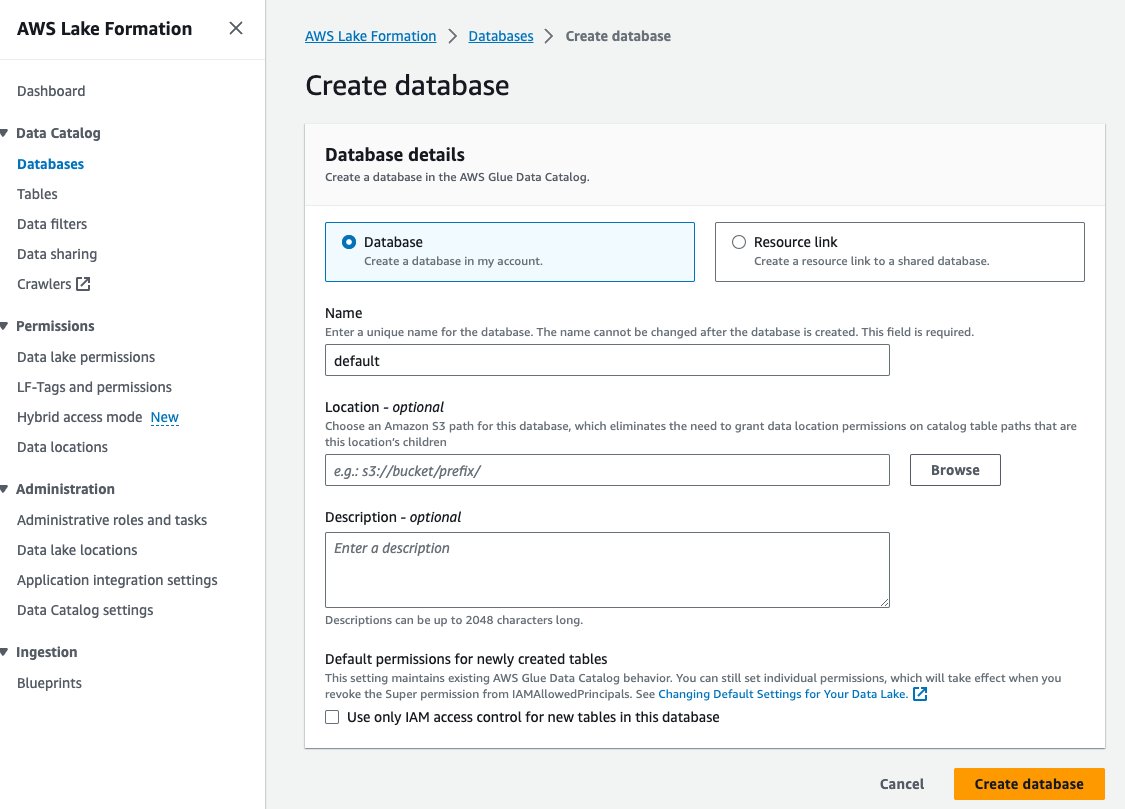
- Selectionnez Bases de données sous Catalogue de données dans le volet de navigation.
- Selectionnez Créer une base de données.
- Pour Nom, entrez la valeur par défaut.
- Selectionnez Créer une base de données.
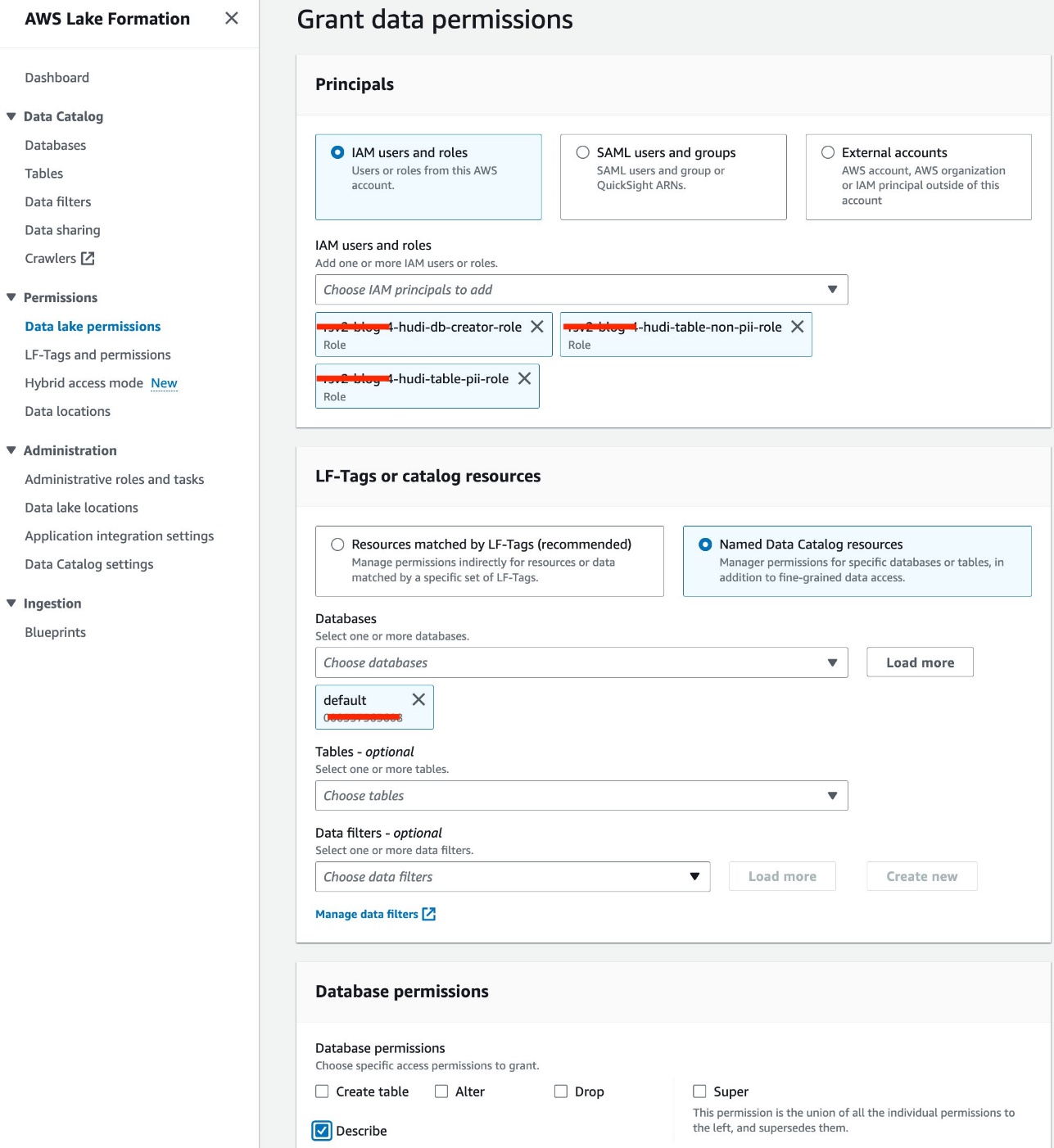
- Selectionnez Autorisations du lac de données sous Permissions dans le volet de navigation.
- Selectionnez Subvention.
- Sélectionnez Utilisateurs et rôles IAM.
- Choisissez vos rôles IAM.
- Pour Bases de données, choisissez par défaut.
- Pour Autorisations de base de données, sélectionnez Décrire.
- Selectionnez Subvention.
Copiez le fichier Hudi JAR sur Amazon EMR HDFS
À utiliser Hudi avec les notebooks Jupyter, vous devez effectuer les étapes suivantes pour le cluster EMR, qui incluent la copie d'un fichier JAR Hudi du répertoire local Amazon EMR vers son stockage HDFS, afin que vous puissiez configurer une session Spark pour utiliser Hudi :
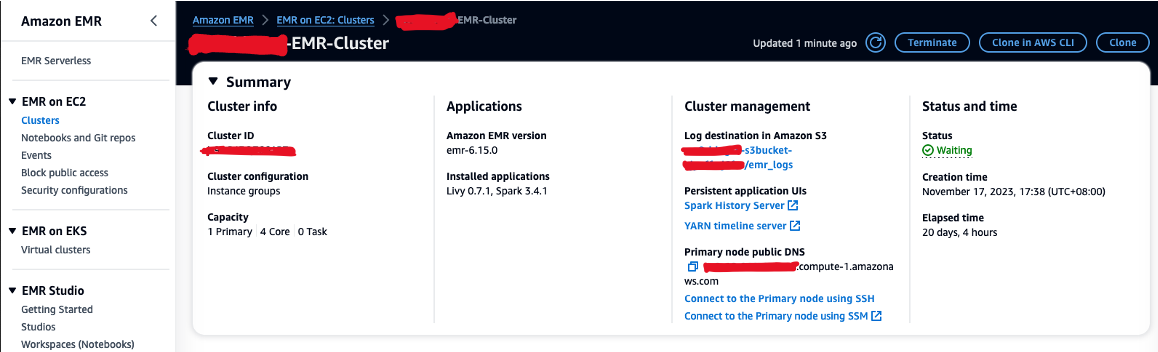
- Autoriser le trafic SSH entrant (port 22).
- Copiez la valeur de DNS public du nœud principal (par exemple, ec2-XXX-XXX-XXX-XXX.compute-1.amazonaws.com) du cluster EMR Résumé .
- Revenez au terminal AWS Cloud9 précédent que vous avez utilisé pour créer la paire de clés EC2.
- Exécutez la commande suivante en SSH sur le nœud principal EMR. Remplacez l'espace réservé par votre nom d'hôte DNS EMR :
- Exécutez la commande suivante pour copier le fichier Hudi JAR sur HDFS :
Créer la base de données et les tables Hudi dans Lake Formation
Nous sommes maintenant prêts à créer la base de données et les tables Hudi avec FGAC activé par le rôle d'exécution EMR. Le Rôle d'exécution EMR est un rôle IAM que vous pouvez spécifier lorsque vous soumettez une tâche ou une requête à un cluster EMR.
Accorder l'autorisation au créateur de la base de données
Tout d’abord, accordons au créateur de la base de données Lake Formation l’autorisation de<STACK-NAME>-hudi-db-creator-role:
- Connectez-vous à votre compte AWS en tant qu'administrateur.
- Sur la console Lake Formation, choisissez Rôles et tâches administratives sous Administration dans le volet de navigation.
- Confirmez que votre utilisateur de connexion AWS a été ajouté en tant qu'administrateur de lac de données.
- Dans le Créateur de base de données section, choisissez Subvention.
- Pour Utilisateurs et rôles IAM, choisissez
<STACK-NAME>-hudi-db-creator-role. - Pour Autorisations de catalogue, sélectionnez Créer une base de données.
- Selectionnez Subvention.
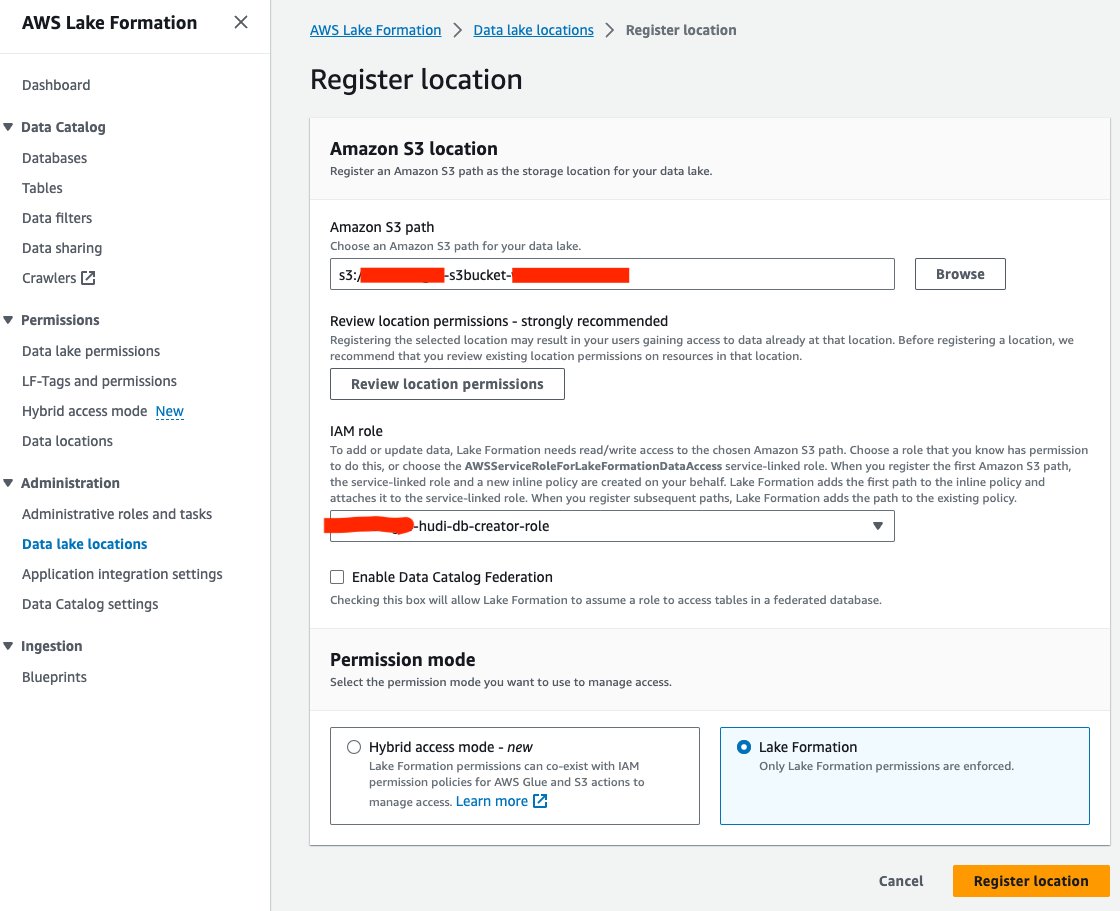
Enregistrer l'emplacement du lac de données
Ensuite, enregistrons l'emplacement du lac de données S3 dans Lake Formation :
- Sur la console Lake Formation, choisissez Emplacements des lacs de données sous Administration dans le volet de navigation.
- Selectionnez Enregistrer l'emplacement.
- Pour Chemin Amazon S3, Choisissez Explorer et choisissez le compartiment Data Lake S3. (
<STACK_NAME>s3bucket-XXXXXXX) créé à partir de la pile CloudFormation. - Pour Rôle IAM, choisissez
<STACK-NAME>-hudi-db-creator-role. - Pour Mode d'autorisation, sélectionnez Formation du lac.
- Selectionnez Enregistrer l'emplacement.
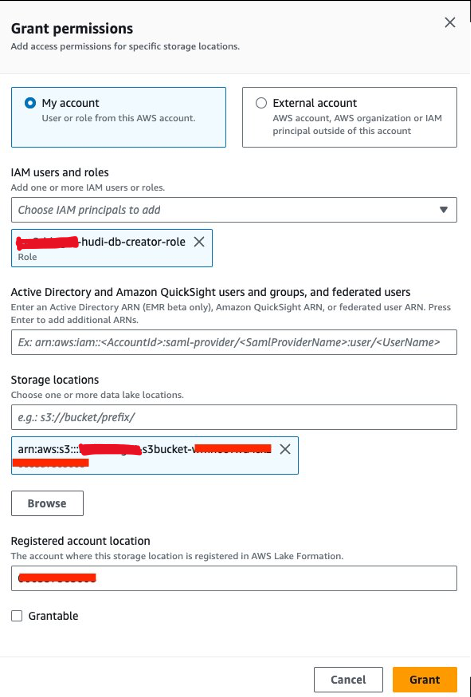
Accorder l'autorisation de localisation des données
Ensuite, nous devons accorder<STACK-NAME>-hudi-db-creator-rolel'autorisation de localisation des données :
- Sur la console Lake Formation, choisissez Emplacements des données sous Permissions dans le volet de navigation.
- Selectionnez Subvention.
- Pour Utilisateurs et rôles IAM, choisissez
<STACK-NAME>-hudi-db-creator-role. - Pour Emplacements de stockage, entrez le compartiment S3 (
<STACK_NAME>-s3bucket-XXXXXXX). - Selectionnez Subvention.
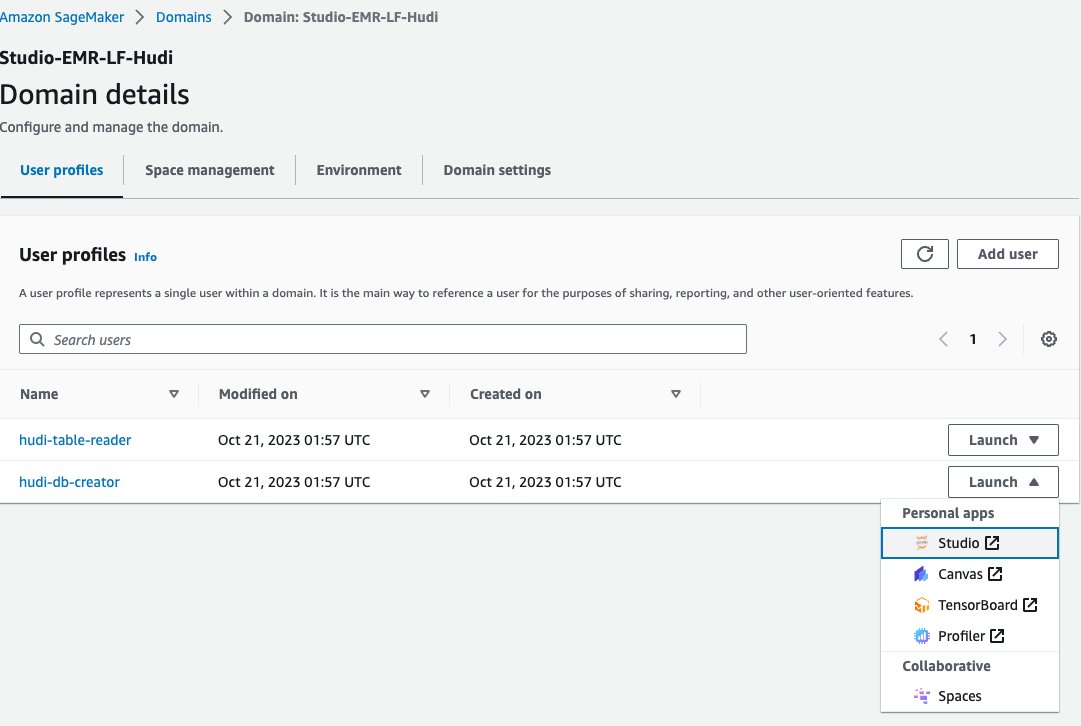
Connectez-vous au cluster EMR
Utilisons maintenant un notebook Jupyter dans SageMaker Studio pour nous connecter au cluster EMR avec le rôle d'exécution EMR du créateur de base de données :
- Sur la console SageMaker, choisissez Domaines dans le volet de navigation.
- Choisissez le domaine
<STACK-NAME>-Studio-EMR-LF-Hudi. - Sur le Lancement menu à côté du profil utilisateur
<STACK-NAME>-hudi-db-creator, choisissez Studio.
- Télécharger le cahier rsv2-hudi-db-creator-notebook.
- Choisissez l'icône de téléchargement.
- Choisissez le notebook Jupyter téléchargé et choisissez Ouvert.
- Ouvrez le bloc-notes téléchargé.
- Pour Image(s), choisissez SparkMagique.
- Pour Noyau, choisissez PySparkName.
- Laissez les autres configurations par défaut et choisissez Sélectionnez.
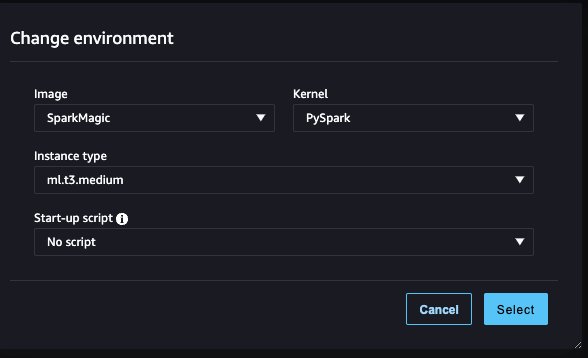
- Selectionnez Grappe pour vous connecter au cluster EMR.

- Choisissez le cluster EMR sur EC2 (
<STACK-NAME>-EMR-Cluster) créé avec la pile CloudFormation. - Selectionnez NOUS CONTACTER.
- Pour Rôle d'exécution du DME, choisissez
<STACK-NAME>-hudi-db-creator-role. - Selectionnez NOUS CONTACTER.
Créer une base de données et des tables
Vous pouvez maintenant suivre les étapes du bloc-notes pour créer la base de données et les tables Hudi. Les grandes étapes sont les suivantes :
- Lorsque vous démarrez le notebook, configurez
“spark.sql.catalog.spark_catalog.lf.managed":"true"pour informer Spark que spark_catalog est protégé par Lake Formation. - Créez des tables Hudi à l'aide du Spark SQL suivant.
- Insérez les données de la table source dans les tables Hudi.
- Insérez à nouveau les données dans les tables Hudi.
Interrogez les tables Hudi via Lake Formation avec FGAC
Après avoir créé la base de données et les tables Hudi, vous êtes prêt à interroger les tables à l'aide d'un contrôle d'accès précis avec Lake Formation. Nous avons créé deux types de tables Hudi : Copy-On-Write (COW) et Merge-On-Read (MOR). La table COW stocke les données sous forme de colonnes (Parquet) et chaque mise à jour crée une nouvelle version des fichiers lors d'une écriture. Cela signifie que pour chaque mise à jour, Hudi réécrit l'intégralité du fichier, ce qui peut nécessiter plus de ressources mais offre des performances de lecture plus rapides. MOR, en revanche, est introduit pour les cas où COW peut ne pas être optimal, en particulier pour les charges de travail lourdes en écriture ou en modification. Dans une table MOR, chaque fois qu'il y a une mise à jour, Hudi écrit uniquement la ligne de l'enregistrement modifié, ce qui réduit les coûts et permet des écritures à faible latence. Cependant, les performances de lecture peuvent être plus lentes que celles des tables COW.
Accorder l'autorisation d'accès à la table
Nous utilisons le rôle IAM<STACK-NAME>-hudi-table-pii-rolepour interroger Hudi COW et MOR contenant des colonnes PII. Nous accordons d'abord l'autorisation d'accès à la table via Lake Formation :
- Sur la console Lake Formation, choisissez Autorisations du lac de données sous Permissions dans le volet de navigation.
- Selectionnez Subvention.
- Selectionnez
<STACK-NAME>-hudi-table-pii-roleen Utilisateurs et rôles IAM. - Choisissez le
rsv2_blog_hudi_db_1base de données pour Bases de données. - Pour Tables, choisissez les quatre tables Hudi que vous avez créées dans le notebook Jupyter.
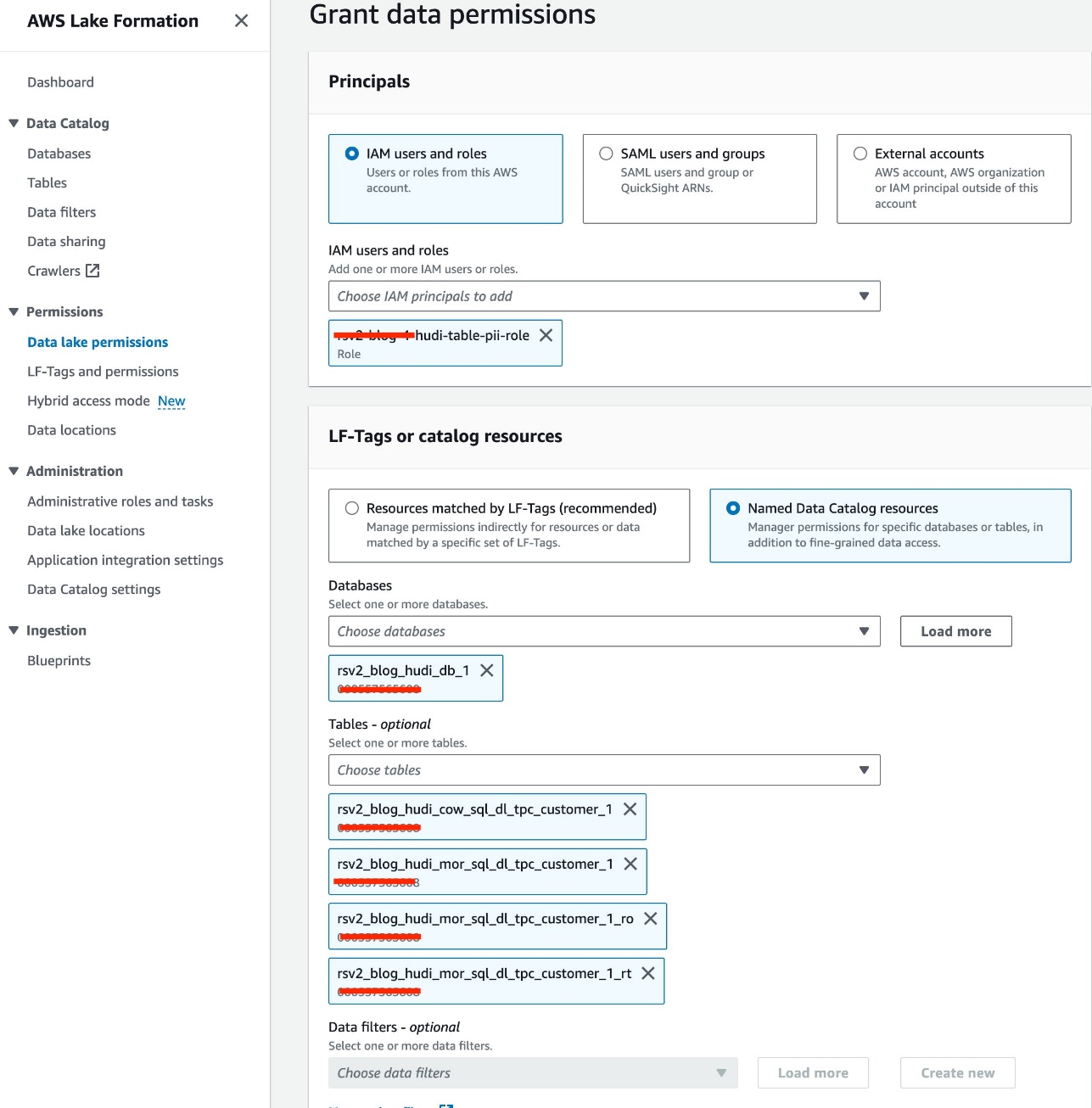
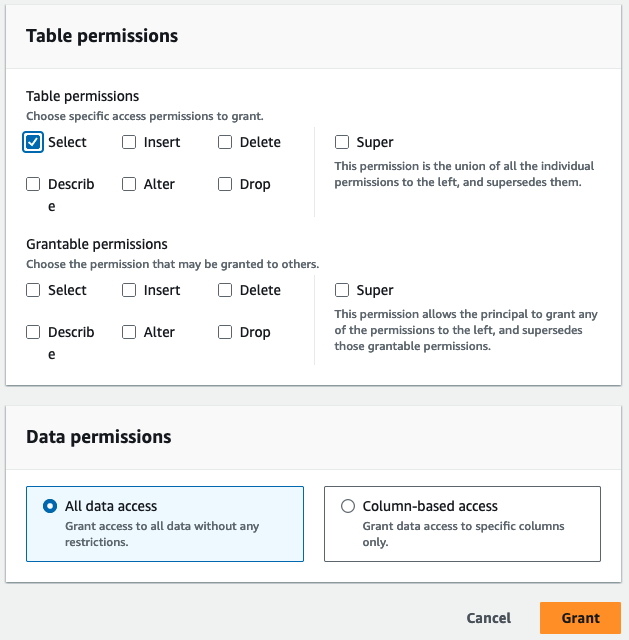
- Pour Droits de table, sélectionnez Sélectionnez.
- Selectionnez Subvention.
Interroger les colonnes PII
Vous êtes maintenant prêt à exécuter le notebook pour interroger les tables Hudi. Suivons des étapes similaires à celles de la section précédente pour exécuter le notebook dans SageMaker Studio :
- Sur la console SageMaker, accédez au
<STACK-NAME>-Studio-EMR-LF-Hudidomaine. - Sur le Lancement menu à côté du
<STACK-NAME>-hudi-table-readerprofil utilisateur, choisissez Studio. - Téléchargez le carnet téléchargé rsv2-hudi-table-pii-reader-notebook.
- Ouvrez le bloc-notes téléchargé.
- Répétez les étapes de configuration du notebook et connectez-vous au même cluster EMR, mais utilisez le rôle
<STACK-NAME>-hudi-table-pii-role.
Au stade actuel, le cluster EMR compatible FGAC doit interroger la colonne de temps de validation de Hudi pour effectuer des requêtes incrémentielles et des voyages dans le temps. Il ne prend pas en charge la syntaxe « horodatage à partir de » de Spark et Spark.read(). Nous travaillons activement à l'intégration de la prise en charge des deux actions dans les futures versions d'Amazon EMR avec FGAC activé.
Vous pouvez maintenant suivre les étapes du carnet. Voici quelques étapes mises en évidence :
- Exécutez une requête d'instantané.
- Exécutez une requête incrémentielle.
- Exécutez une requête de voyage dans le temps.
- Exécutez des requêtes de table MOR optimisées en lecture et en temps réel.
Interrogez les tables Hudi avec des filtres de données au niveau des colonnes et des lignes
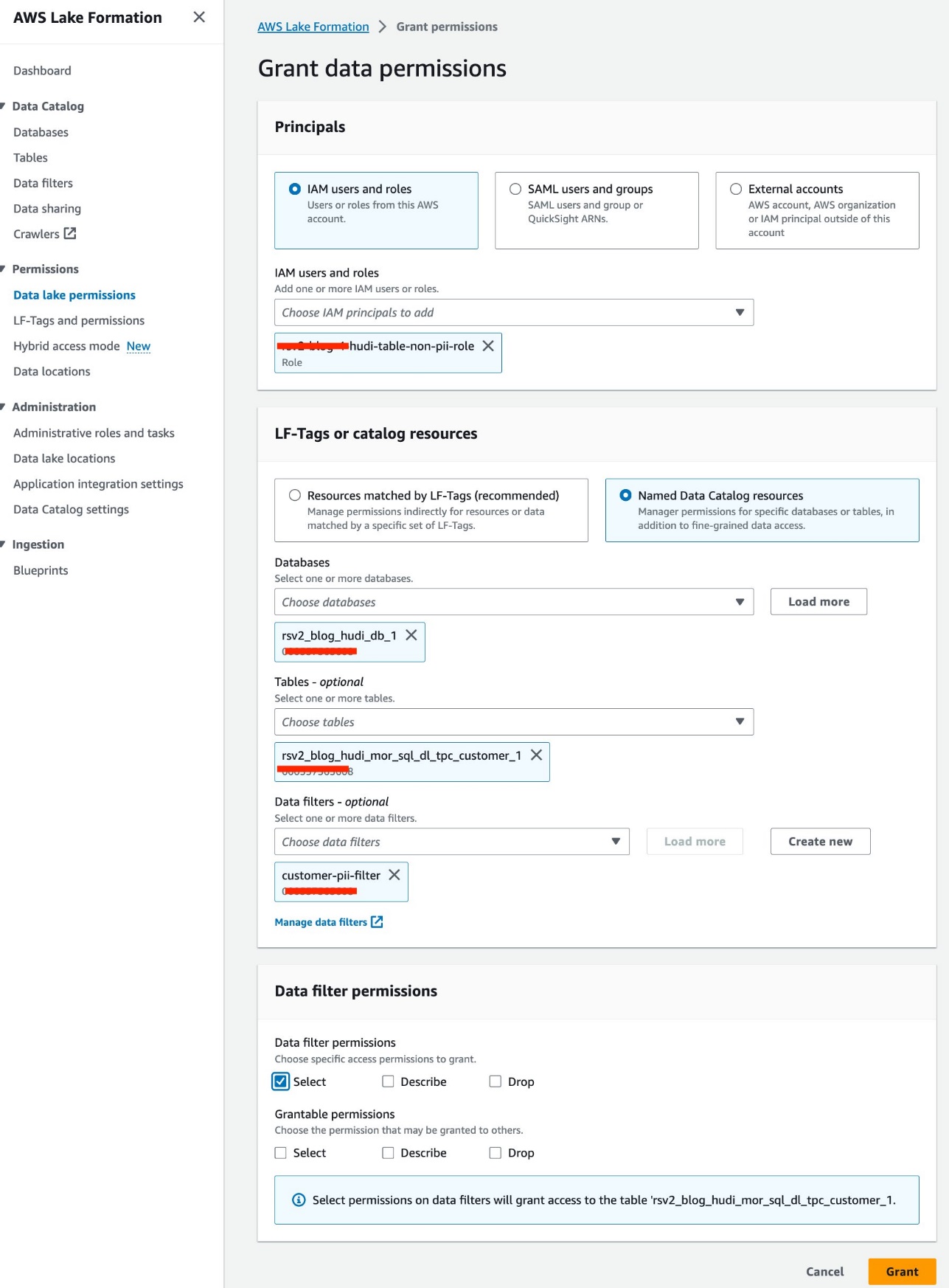
Nous utilisons le rôle IAM<STACK-NAME>-hudi-table-non-pii-rolepour interroger les tables Hudi. Ce rôle n'est pas autorisé à interroger les colonnes contenant des informations personnelles. Nous utilisons les filtres de données au niveau des colonnes et des lignes de Lake Formation pour implémenter un contrôle d'accès précis :
- Sur la console Lake Formation, choisissez Filtres de données sous Catalogue de données dans le volet de navigation.
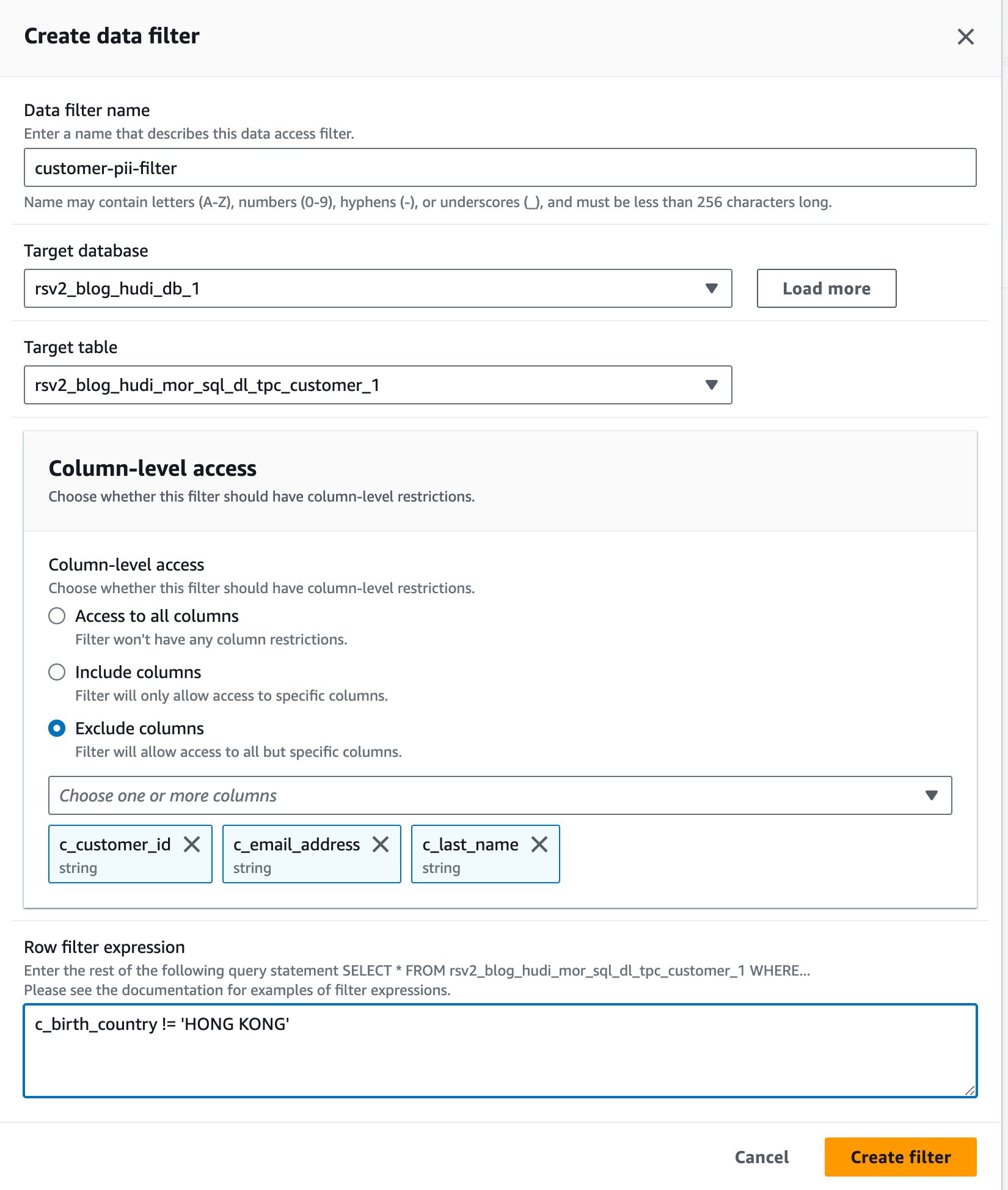
- Selectionnez Créer un nouveau filtre.
- Pour Nom du filtre de données, Entrer
customer-pii-filter. - Selectionnez
rsv2_blog_hudi_db_1en Base de données cible. - Selectionnez
rsv2_blog_hudi_mor_sql_dl_customer_1en Tableau cible. - Sélectionnez Exclure les colonnes Et choisissez le
c_customer_id,c_email_addresset lac_last_namecolonnes. - Entrer
c_birth_country != 'HONG KONG'en Expression de filtre de ligne. - Selectionnez Créer un filtre.
- Selectionnez Autorisations du lac de données sous Permissions dans le volet de navigation.
- Selectionnez Subvention.
- Selectionnez
<STACK-NAME>-hudi-table-non-pii-roleen Utilisateurs et rôles IAM. - Selectionnez
rsv2_blog_hudi_db_1en Bases de données. - Selectionnez
rsv2_blog_hudi_mor_sql_dl_tpc_customer_1en Tables. - Selectionnez
customer-pii-filteren Filtres de données. - Pour Autorisations de filtre de données, sélectionnez Sélectionnez.
- Selectionnez Subvention.
Suivons des étapes similaires pour exécuter le notebook dans SageMaker Studio :
- Sur la console SageMaker, accédez au domaine
Studio-EMR-LF-Hudi. - Sur le Lancement menu pour le
hudi-table-readerprofil utilisateur, choisissez Studio. - Téléchargez le carnet téléchargé rsv2-hudi-table-non-pii-reader-notebook et choisissez Ouvert.
- Répétez les étapes de configuration du notebook et connectez-vous au même cluster EMR, mais sélectionnez le rôle
<STACK-NAME>-hudi-table-non-pii-role.
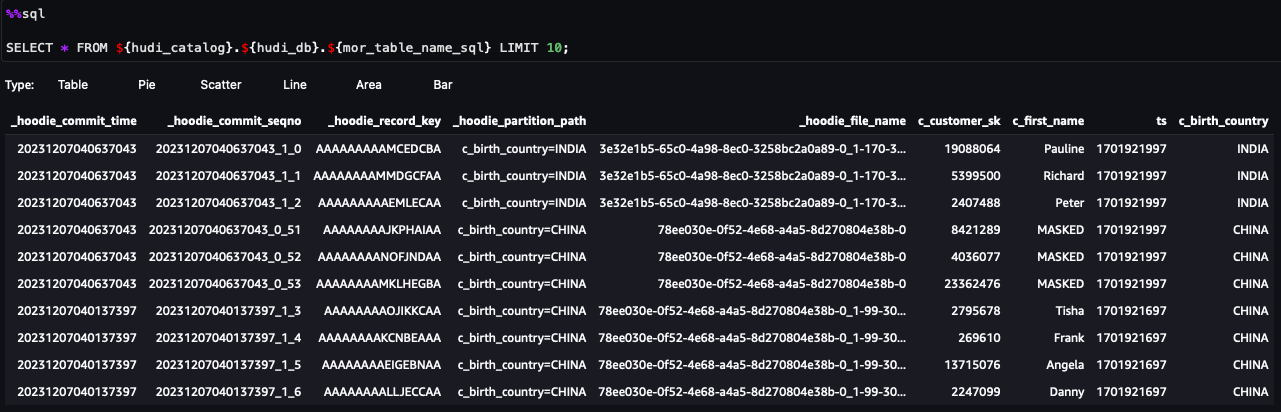
Vous pouvez maintenant suivre les étapes du carnet. À partir des résultats de la requête, vous pouvez voir que FGAC via le filtre de données Lake Formation a été appliqué. Le rôle ne peut pas voir les colonnes PIIc_customer_id,c_last_nameet la
c_email_address. De plus, les lignes deHONG KONGont été filtrés.
Nettoyer
Une fois que vous avez fini d’expérimenter la solution, nous vous recommandons de nettoyer les ressources en suivant les étapes suivantes pour éviter des coûts inattendus :
- Arrêtez les applications SageMaker Studio pour les profils utilisateurs.
Le cluster EMR sera automatiquement supprimé après la valeur du délai d'inactivité.
- Supprimer l' Système de fichiers Amazon Elastic (Amazon EFS) créé pour le domaine.
- Vider les compartiments S3 créé par la pile CloudFormation.
- Sur la console AWS CloudFormation, supprimez la pile.
Conclusion
Dans cet article, nous avons utilisé Apachi Hudi, un type de tables OTF, pour démontrer cette nouvelle fonctionnalité permettant d'appliquer un contrôle d'accès précis sur Amazon EMR. Vous pouvez définir des autorisations granulaires dans Lake Formation pour les tables OTF et les appliquer via des requêtes Spark SQL sur les clusters EMR. Vous pouvez également utiliser les fonctionnalités du lac de données transactionnelles telles que l'exécution de requêtes d'instantané, de requêtes incrémentielles, de voyages dans le temps et de requêtes DML. Veuillez noter que cette nouvelle fonctionnalité couvre toutes les tables OTF.
Cette fonctionnalité est lancée à partir de la version 6.15 d'Amazon EMR dans tous les cas. Régions où Amazon EMR est disponible. Grâce à l'intégration d'Amazon EMR avec Lake Formation, vous pouvez gérer et traiter le Big Data en toute confiance, en obtenant des informations et en facilitant une prise de décision éclairée tout en garantissant la sécurité et la gouvernance des données.
Pour en savoir plus, consultez Activer la formation de lacs avec Amazon EMR et n'hésitez pas à contacter vos architectes de solutions AWS, qui peuvent vous aider tout au long de votre parcours de données.
À propos de l’auteur
 Raymond Laï est un architecte de solutions senior spécialisé dans la satisfaction des besoins des grandes entreprises clientes. Son expertise consiste à aider les clients à migrer des systèmes et des bases de données d'entreprise complexes vers AWS, à créer des plates-formes d'entreposage de données d'entreprise et de lac de données. Raymond excelle dans l'identification et la conception de solutions pour les cas d'utilisation de l'IA/ML, et il se concentre particulièrement sur les solutions AWS Serverless et la conception d'architectures événementielles.
Raymond Laï est un architecte de solutions senior spécialisé dans la satisfaction des besoins des grandes entreprises clientes. Son expertise consiste à aider les clients à migrer des systèmes et des bases de données d'entreprise complexes vers AWS, à créer des plates-formes d'entreposage de données d'entreprise et de lac de données. Raymond excelle dans l'identification et la conception de solutions pour les cas d'utilisation de l'IA/ML, et il se concentre particulièrement sur les solutions AWS Serverless et la conception d'architectures événementielles.
 Ben Wang, PhD, est un architecte de solutions spécialisé en analyse senior chez AWS, bénéficiant de plus de 12 ans d'expérience dans l'industrie du ML, avec un accent particulier sur la publicité. Il possède une expertise dans le traitement du langage naturel (NLP), les systèmes de recommandation, divers algorithmes de ML et les opérations de ML. Il est profondément passionné par l’application des techniques ML/DL et Big Data pour résoudre des problèmes du monde réel.
Ben Wang, PhD, est un architecte de solutions spécialisé en analyse senior chez AWS, bénéficiant de plus de 12 ans d'expérience dans l'industrie du ML, avec un accent particulier sur la publicité. Il possède une expertise dans le traitement du langage naturel (NLP), les systèmes de recommandation, divers algorithmes de ML et les opérations de ML. Il est profondément passionné par l’application des techniques ML/DL et Big Data pour résoudre des problèmes du monde réel.
 Aditya Shah est ingénieur en développement logiciel chez AWS. Il s'intéresse aux moteurs de bases de données et d'entrepôts de données et a travaillé sur l'optimisation des performances, la conformité en matière de sécurité et la conformité ACID pour des moteurs comme Apache Hive et Apache Spark.
Aditya Shah est ingénieur en développement logiciel chez AWS. Il s'intéresse aux moteurs de bases de données et d'entrepôts de données et a travaillé sur l'optimisation des performances, la conformité en matière de sécurité et la conformité ACID pour des moteurs comme Apache Hive et Apache Spark.
 Mélodie Yang est architecte principal de solutions Big Data pour Amazon EMR chez AWS. Elle est une responsable analytique expérimentée travaillant avec les clients AWS pour fournir des conseils sur les meilleures pratiques et des conseils techniques afin de les aider à réussir dans la transformation des données. Ses domaines d'intérêt sont les frameworks open-source et l'automatisation, l'ingénierie des données et les DataOps.
Mélodie Yang est architecte principal de solutions Big Data pour Amazon EMR chez AWS. Elle est une responsable analytique expérimentée travaillant avec les clients AWS pour fournir des conseils sur les meilleures pratiques et des conseils techniques afin de les aider à réussir dans la transformation des données. Ses domaines d'intérêt sont les frameworks open-source et l'automatisation, l'ingénierie des données et les DataOps.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/enforce-fine-grained-access-control-on-open-table-formats-via-amazon-emr-integrated-with-aws-lake-formation/
- :possède
- :est
- :ne pas
- :où
- $UP
- 1
- 10
- 100
- 11
- 12
- 130
- 15%
- 16
- 17
- 20
- 22
- 400
- 7
- 8
- 9
- a
- Qui sommes-nous
- accès
- Compte
- reconnaître
- actes
- activement
- ajoutée
- En outre
- adresses
- admin
- administrateurs
- Numérique
- conseils
- Après
- encore
- AI / ML
- algorithmes
- Tous
- permettre
- permis
- permet
- aux côtés de
- aussi
- Amazon
- Amazon EC2
- Amazon DME
- Amazon Web Services
- an
- selon une analyse de l’Université de Princeton
- Analystes
- Analytique
- analytique
- l'analyse
- ainsi que les
- tous
- Apache
- Apache Spark
- Application
- appliqué
- Appliquer
- Application
- architectes
- architecture
- SONT
- domaines
- autour
- AS
- aider
- Assistance
- assistant
- assumer
- At
- audit
- autorité
- autorisé
- automatiquement
- Automation
- disponibles
- éviter
- AWS
- AWSCloud9
- AWS CloudFormation
- Formation AWS Lake
- RETOUR
- basé
- BE
- était
- derrière
- va
- avantages.
- outre
- LES MEILLEURS
- Big
- Big Data
- blogue
- se vanter
- tous les deux
- construire
- mais
- by
- CA
- CAN
- capable
- porter
- la réalisation
- maisons
- cas
- catalogue
- VIP gastronomie à bord,
- certaines
- certificat
- certificats
- Certifications
- Change
- modifié
- Modifications
- Chine
- Selectionnez
- Nettoyage
- Cloud9
- Grappe
- code
- Colonne
- Colonnes
- COM
- combinaison
- commettre
- Sociétés
- par rapport
- complet
- conformité
- composant
- composants électriques
- calcul
- ordinateur
- concept
- conditions
- Conduire
- avec confiance
- configuration
- NOUS CONTACTER
- Console
- la construction
- contact
- contiennent
- contient
- des bactéries
- contrôlée
- contrôles
- copier
- Correspondant
- Prix
- Costs
- Pays
- couvre
- engendrent
- créée
- crée des
- La création
- créateur
- Courant
- Customiser
- Clients
- données
- accès aux données
- l'analyse des données
- Lac de données
- Plateforme de données
- confidentialité des données
- informatique
- la sécurité des données
- entrepôt de données
- Base de données
- bases de données
- La prise de décision
- profondément
- Réglage par défaut
- Vous permet de définir
- Delta
- démontrer
- démontrer
- déployer
- déploiement
- Conception
- conception
- détails
- Développement
- différent
- distinct
- plusieurs
- dns
- do
- Ne fait pas
- domaine
- fait
- Ne pas
- down
- download
- entraîné
- pendant
- chacun
- d'autre
- permettre
- activé
- permet
- chiffrement
- fin
- critères
- imposer
- Moteur
- ingénieur
- ENGINEERING
- Moteurs
- assurer
- Assure
- assurer
- Entrer
- Entreprise
- clients entreprise
- Tout
- Environment
- Ether (ETH)
- événement
- Chaque
- exemple
- exécution
- existe
- d'experience
- expérimenté
- nous a permis de concevoir
- exploration
- S'étend
- externe
- faciliter
- plus rapide
- Fonctionnalité
- Fonctionnalités:
- ressentir
- Déposez votre dernière attestation
- Fichiers
- une fonction filtre
- filtration
- filtres
- Prénom
- Focus
- se concentre
- suivre
- Abonnement
- suit
- Pour
- le format
- formation
- quatre
- Framework
- cadres
- Gratuit
- de
- Remplir
- plein
- plus
- avenir
- Gain
- généré
- gouvernance
- régie
- subvention
- considérablement
- Réservation de groupe
- Groupes
- l'orientation
- main
- Vous avez
- he
- ici
- ici
- Surbrillance
- sa
- historique
- Histoire
- Ruche
- Hong
- Hong Kong
- Villa
- Comment
- How To
- Cependant
- HTML
- http
- HTTPS
- IAM
- ICON
- ID
- idée
- identifier
- identifier
- Idle
- if
- illustre
- Mettre en oeuvre
- améliorer
- in
- inclut
- Y compris
- incorporation
- incrémental
- Inde
- industrie
- informer
- d'information
- Actualités
- contribution
- idées.
- des services
- Intégration
- l'intégration
- Interactif
- intéressé
- intérêts
- Interfaces
- interne
- développement
- complexe
- introduit
- Introduit
- aide
- IT
- SES
- Emploi
- Emplois
- chemin
- jpg
- Jupyter Notebook
- ACTIVITES
- Kong
- lac
- langue
- gros
- Nom de famille
- lancer
- lancé
- leader
- APPRENTISSAGE
- niveaux
- se trouve
- comme
- LIMIT
- lignes
- locales
- emplacement
- emplacements
- vous connecter
- majeur
- a prendre une
- gérer
- gérés
- gestion
- manager
- de nombreuses
- Mai..
- veux dire
- mécanismes
- réunion
- Menu
- Métadonnées
- pourrait
- migrer
- minutes
- ML
- Algorithmes ML
- modifié
- PLUS
- mouvement
- prénom
- noms
- Nature
- Langage naturel
- Traitement du langage naturel
- NAVIGUER
- Navigation
- Besoin
- Besoins
- Nouveauté
- nouvelle fonctionnalité
- nouvellement
- next
- nlp
- nœud
- noter
- cahier
- ordinateurs portables
- maintenant
- objets
- of
- souvent
- on
- ONE
- uniquement
- ouvert
- open source
- openssl
- Opérations
- optimaux
- Optimiser
- Option
- Options
- or
- de commander
- organisation
- Autre
- ande
- plus de
- paire
- pain
- particulier
- particulièrement
- passionné
- payant
- performant
- effectuer
- autorisation
- autorisations
- Personnellement
- phd
- pii
- espace réservé
- plateforme
- Plateformes
- Platon
- Intelligence des données Platon
- PlatonDonnées
- veuillez cliquer
- plus
- des notes bonus
- Populaire
- possède
- Post
- pratique
- conservation
- précédent
- primaire
- la confidentialité
- privilège
- privilèges
- d'ouvrabilité
- processus
- traitement
- Vidéo
- Profil
- Profils
- preuve
- preuve de concept
- protégé
- protection
- fournir
- fournit
- aportando
- public
- des fins
- requêtes
- Lire
- en cours
- solutions
- monde réel
- en temps réel
- recommander
- record
- récupération
- réduit
- réduire
- reportez-vous
- se réfère
- reflète
- région
- vous inscrire
- inscrit
- règlements
- libérer
- de Presse
- pertinent
- remplacer
- conditions
- Exigences
- ressource
- gourmande en ressources
- Resources
- résultat
- Résultats
- droits
- Rôle
- rôle
- RANGÉE
- rsa
- Courir
- pour le running
- sagemaker
- même
- Épargnez
- Section
- sécurisé
- sécurisé
- sécurité
- sur le lien
- Chercher
- Sélectionner
- supérieur
- sensible
- serveur
- Sans serveur
- Services
- Session
- set
- Sets
- Paramétres
- installation
- elle
- signer
- de façon significative
- similaires
- étapes
- simplifie
- simplifier
- depuis
- Instantané
- So
- Logiciels
- développement de logiciels
- sur mesure
- Solutions
- RÉSOUDRE
- quelques
- Identifier
- Spark
- spécialiste
- spécialise
- SQL
- empiler
- Étape
- Commencer
- j'ai commencé
- Commencez
- déclarations
- Étapes
- storage
- STORES
- de Marketing
- Chaîne
- studio
- soumettre
- sous-réseaux
- succès
- tel
- RÉSUMÉ
- Support
- Les soutiens
- sûr
- syntaxe
- Système
- table
- TAG
- prend
- Technique
- techniques
- modèle
- terminal
- qui
- Les
- La Source
- leur
- Les
- puis
- Là.
- Ces
- l'ont
- this
- trois
- Avec
- fiable
- voyage dans le temps
- calendrier
- à
- Tracking
- transaction
- transactionnel
- De La Carrosserie
- transit
- Voyage
- oui
- confiance
- Ts
- deux
- type
- types
- ui
- sous
- Inattendu
- inconnu
- déverrouillage
- Mises à jour
- a actualisé
- maintien
- téléchargé
- URI
- utilisé
- cas d'utilisation
- d'utiliser
- Utilisateur
- utilisateurs
- en utilisant
- valide
- Plus-value
- divers
- version
- via
- définition
- le volume
- Entrepots
- Entreposage
- we
- web
- services Web
- quand
- Les
- qui
- tout en
- WHO
- sera
- comprenant
- dans les
- travaillé
- de travail
- écrire
- années
- you
- Votre
- zéphyrnet
- zéro
- Zip