Aujourd'hui, nous mettons à disposition une nouvelle fonctionnalité de Colle AWS Catalogue de données qui permet de générer des statistiques au niveau des colonnes pour les tables AWS Glue. Ces statistiques sont désormais intégrées aux optimiseurs basés sur les coûts (CBO) de Amazone Athéna et Amazon Spectre de décalage vers le rouge, ce qui entraîne une amélioration des performances des requêtes et des économies potentielles.
Les lacs de données sont conçus pour stocker de grandes quantités de données brutes, non structurées ou semi-structurées à faible coût, et les organisations partagent ces ensembles de données entre plusieurs départements et équipes. Les requêtes sur ces grands ensembles de données lisent de grandes quantités de données et peuvent effectuer des opérations de jointure complexes sur plusieurs ensembles de données. En discutant avec nos clients, nous avons appris que l'un des défis des performances des lacs de données est de savoir comment optimiser ces requêtes analytiques pour qu'elles s'exécutent plus rapidement.
L'optimisation des performances du lac de données est particulièrement importante pour les requêtes comportant plusieurs jointures et c'est là que les optimiseurs basés sur les coûts sont le plus utiles. Pour que le CBO fonctionne, les statistiques des colonnes doivent être collectées et mises à jour en fonction des modifications apportées aux données. Nous lançons la possibilité de générer des statistiques au niveau des colonnes telles que le nombre de distincts, le nombre de valeurs nulles, le maximum et le minimum sur des fichiers tels que Parquet, ORC, JSON, Amazon ION, CSV, XML sur les tables AWS Glue. Avec ce lancement, les clients bénéficient désormais d'une expérience intégrée de bout en bout où les statistiques sur les tables Glue sont collectées et stockées dans le catalogue AWS Glue, et mises à la disposition des services d'analyse pour une planification et une exécution améliorées des requêtes.
Grâce à ces statistiques, les optimiseurs basés sur les coûts améliorent les plans d'exécution des requêtes et augmentent les performances des requêtes exécutées dans Amazon Athena et Amazon Redshift Spectrum. Par exemple, CBO peut utiliser des statistiques de colonnes telles que le nombre de valeurs distinctes et le nombre de valeurs nulles pour améliorer la prédiction des lignes. La prédiction de lignes est le nombre de lignes d'une table qui seront renvoyées à une certaine étape lors de la phase de planification de la requête. Plus les prédictions de lignes sont précises, plus les étapes d'exécution des requêtes sont efficaces. Cela conduit à une exécution plus rapide des requêtes et à une réduction potentielle des coûts. Certaines des optimisations spécifiques que CBO peut utiliser incluent la réorganisation des jointures et la suppression des agrégations en fonction des statistiques disponibles pour chaque table et colonne.
Pour les clients utilisant maillage de données comprenant Formation AWS Lake autorisations, les tables de différents producteurs de données sont cataloguées dans les comptes de gouvernance centralisés. À mesure qu'ils génèrent des statistiques sur les tables du catalogue centralisé et partagent ces tables avec les consommateurs, les requêtes sur ces tables dans les comptes consommateurs verront automatiquement des améliorations des performances des requêtes. Dans cet article, nous démontrerons la capacité d'AWS Glue Data Catalog à générer des statistiques de colonnes pour nos exemples de tables.
Vue d'ensemble de la solution
Pour démontrer l'efficacité de cette fonctionnalité, nous utilisons l'ensemble de données TPC-DS standard de 3 To stocké dans un Amazon Simple Storage Service (Amazon S3) compartiment public. Nous comparerons les performances des requêtes avant et après la génération des statistiques de colonnes pour les tables, en exécutant des requêtes dans Amazon Athena et Amazon Redshift Spectrum. Nous fournissons les requêtes que nous avons utilisées dans cet article et nous vous encourageons à essayer vos propres requêtes en suivant le flux de travail, comme illustré dans les détails suivants.
Le flux de travail comprend les étapes de haut niveau suivantes :
- Catalogage du compartiment Amazon S3 : Utilisez AWS Glue Crawler pour explorer le compartiment Amazon S3 désigné, extraire les métadonnées et les stocker de manière transparente dans le catalogue de données AWS Glue. Nous interrogerons ces tables à l'aide d'Amazon Athena et d'Amazon Redshift Spectrum.
- Génération de statistiques de colonnes : Utilisez les capacités améliorées d'AWS Glue Data Catalog pour générer des statistiques de colonnes complètes pour les données analysées, fournissant ainsi des informations précieuses sur l'ensemble de données.
- Interrogation avec Amazon Athena et Amazon Redshift Spectrum : Évaluez l'impact des statistiques de colonnes sur les performances des requêtes en utilisant Amazon Athena et Amazon Redshift Spectrum pour exécuter des requêtes sur l'ensemble de données.
Le diagramme suivant illustre l'architecture de la solution.
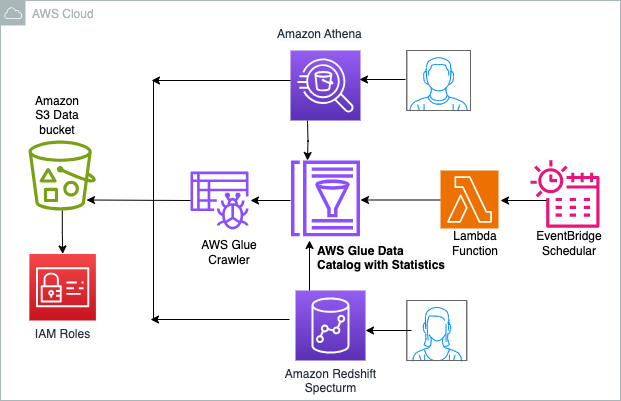
Procédure pas à pas
Pour mettre en œuvre la solution, nous effectuons les étapes suivantes :
- Configurer des ressources avec AWS CloudFormation.
- Exécutez AWS Glue Crawler sur le compartiment public Amazon S3 pour répertorier l'ensemble de données TPC-DS de 3 To.
- Exécutez des requêtes sur Amazon Athena et Amazon Redshift et notez la durée des requêtes
- Générer des statistiques pour les tables AWS Glue Data Catalog
- Exécutez des requêtes sur Amazon Athena et Amazon Redshift et comparez la durée de la requête avec l'exécution précédente
- Facultatif : Planifiez des tâches de statistiques de colonne AWS Glue à l'aide d'AWS Lambda et du planificateur Amazon EventBridge.
Configurer des ressources avec AWS CloudFormation
Ce poste comprend un AWS CloudFormation modèle pour une configuration rapide. Vous pouvez le consulter et le personnaliser en fonction de vos besoins. Le modèle génère les ressources suivantes :
- Un cloud privé virtuel Amazon (VPC Amazon), sous-réseau public, sous-réseaux privés et tables de routage.
- Un groupe de travail et un espace de noms Amazon Redshift Serverless.
- Un robot d'exploration AWS Glue pour analyser le compartiment public Amazon S3 et créer une table pour l'ensemble de données Glue Data Catalog pour TPC-DS
- Bases de données et tables du catalogue AWS Glue
- Un compartiment Amazon S3 pour stocker le résultat Athena.
- Gestion des identités et des accès AWS (AWS IAM) et les stratégies.
- Planificateur AWS Lambda et Amazon Event Bridge pour planifier les statistiques de la colonne AWS Glue
Pour lancer la pile AWS CloudFormation, procédez comme suit :
Notes: Les tables du catalogue de données AWS Glue sont générées à l'aide du compartiment public s3://blogpost-sparkoneks-us-east-1/blog/BLOG_TPCDS-TEST-3T-partitioned/, hébergé dans le us-east-1 région. Si vous avez l'intention de déployer ce modèle AWS CloudFormation dans une autre région, il est nécessaire soit de copier les données dans la région correspondante, soit de partager les données au sein de votre région déployée pour qu'elles soient accessibles depuis Amazon Redshift.
- Connectez-vous au Console de gestion AWS comme AWS Identity and Access Management (AWS IAM) administrateur.
- Choisissez Launch Stack pour déployer un modèle AWS CloudFormation.

- Selectionnez Suivant.
- Sur la page suivante, conservez toutes les options par défaut ou apportez les modifications appropriées en fonction de vos besoins, choisissez Suivant.
- Passez en revue les détails sur la dernière page et sélectionnez Je reconnais qu'AWS CloudFormation peut créer des ressources IAM.
- Selectionnez Création.
Cette pile peut prendre environ 10 minutes, après quoi vous pouvez afficher la pile déployée sur la console AWS CloudFormation.
Exécutez les AWS Glue Crawlers créés par la pile AWS CloudFormation
Pour exécuter vos robots d'exploration, procédez comme suit :
- Sur la console AWS Glue pour Console de colle AWS, choisissez Crawlers sous Data Catalog dans le volet de navigation.
- Localisez et exécutez deux robots d'exploration
tpcdsdb-without-statset lestpcdsdb-with-stats. Cela peut prendre quelques minutes.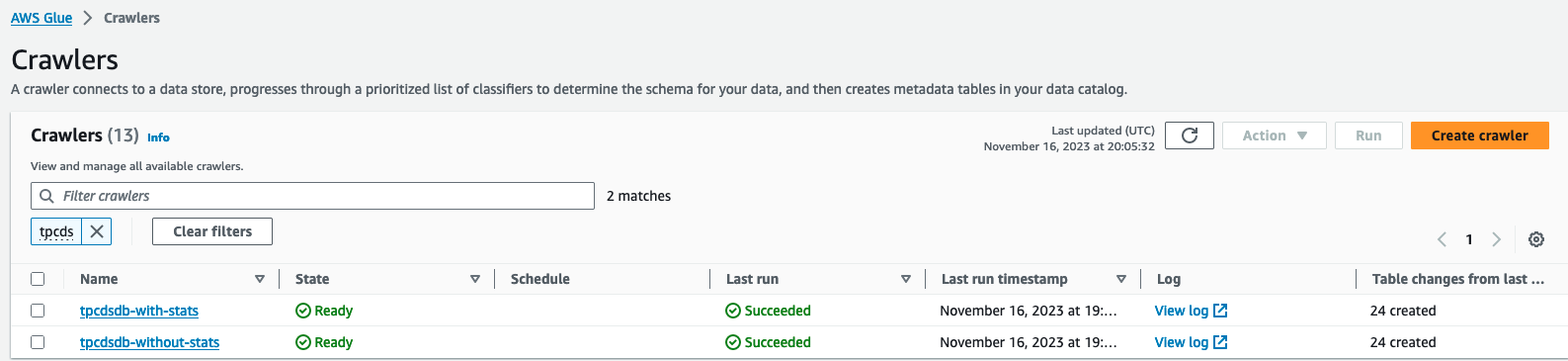
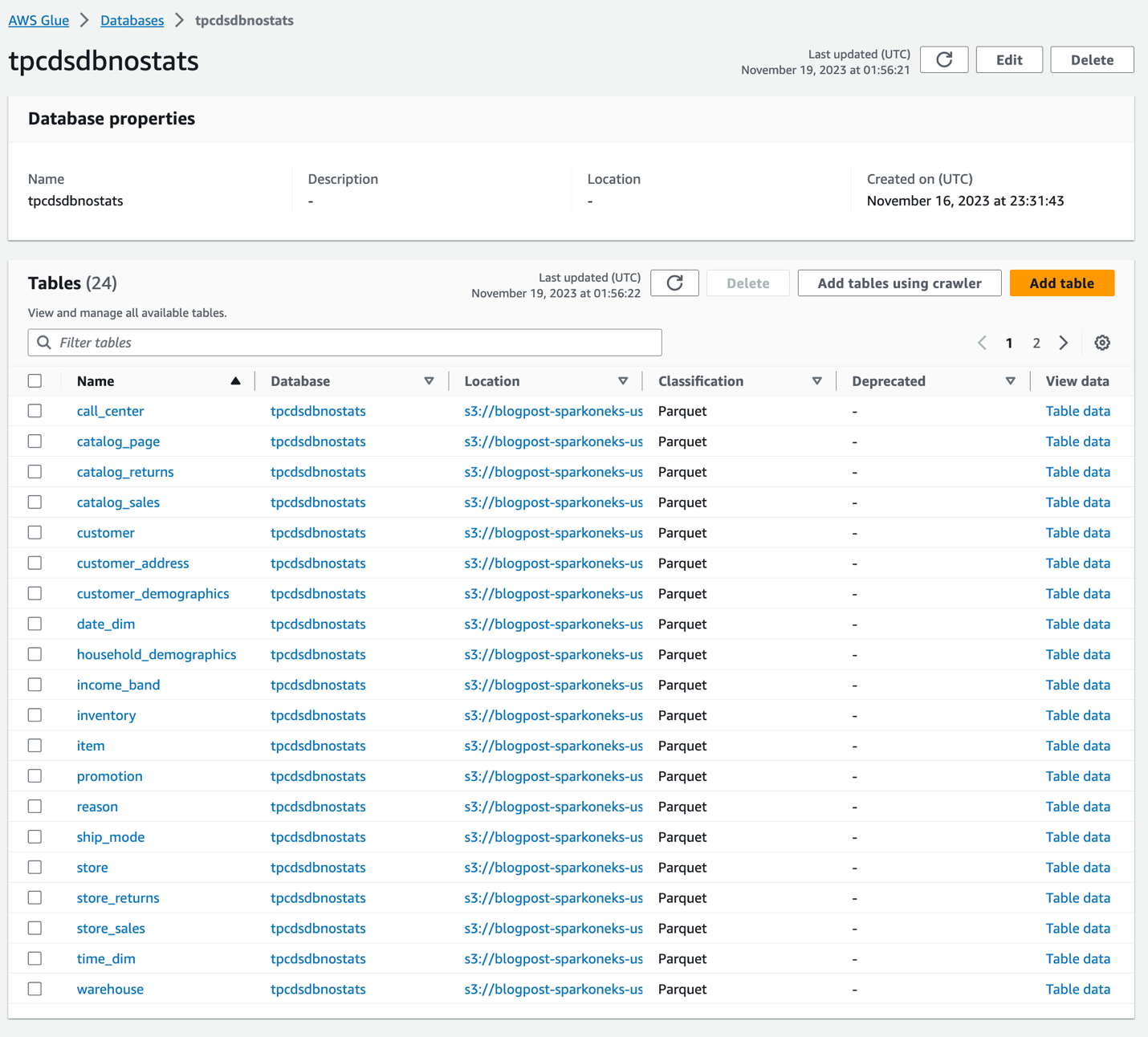
Une fois le robot terminé, il créera deux bases de données identiques. tpcdsdbnostats et les tpcdsdbwithstats. Les tableaux dans tpcdsdbnostats n'aura aucune statistique et nous les utiliserons comme référence. Nous générons des statistiques sur les tableaux dans tpcdsdbwithstats. Veuillez vérifier que vous disposez de ces deux bases de données et tables sous-jacentes à partir de la console AWS Glue. La base de données tpcdsdbnostats ressemblera à ci-dessous. À l’heure actuelle, aucune statistique n’est générée sur ces tableaux.
Exécuter la requête fournie à l'aide d'Amazon Athena sur des tables sans statistiques
Pour exécuter votre requête dans Amazon Athena sur des tables sans statistiques, procédez comme suit :
- Téléchargez les requêtes Athena depuis ici.
- Sur l'Amazonie Console Athéna, choisissez la requête fournie une par une pour les tables de la base de données
tpcdsdbnostats. - Exécutez la requête et notez le le temps d'exécution pour chaque requête.

Exécuter la requête fournie à l'aide d'Amazon Redshift Spectrum sur des tables sans statistiques
Pour exécuter votre requête dans Amazon Redshift, procédez comme suit :
- Téléchargez les requêtes Amazon Redshift depuis ici.
- Sur le Éditeur de requête Redshift v2, exécutez le Requête Redshift pour les tables sans statistiques section de la requête téléchargée.
- Exécutez la requête et notez l’exécution de chaque requête.
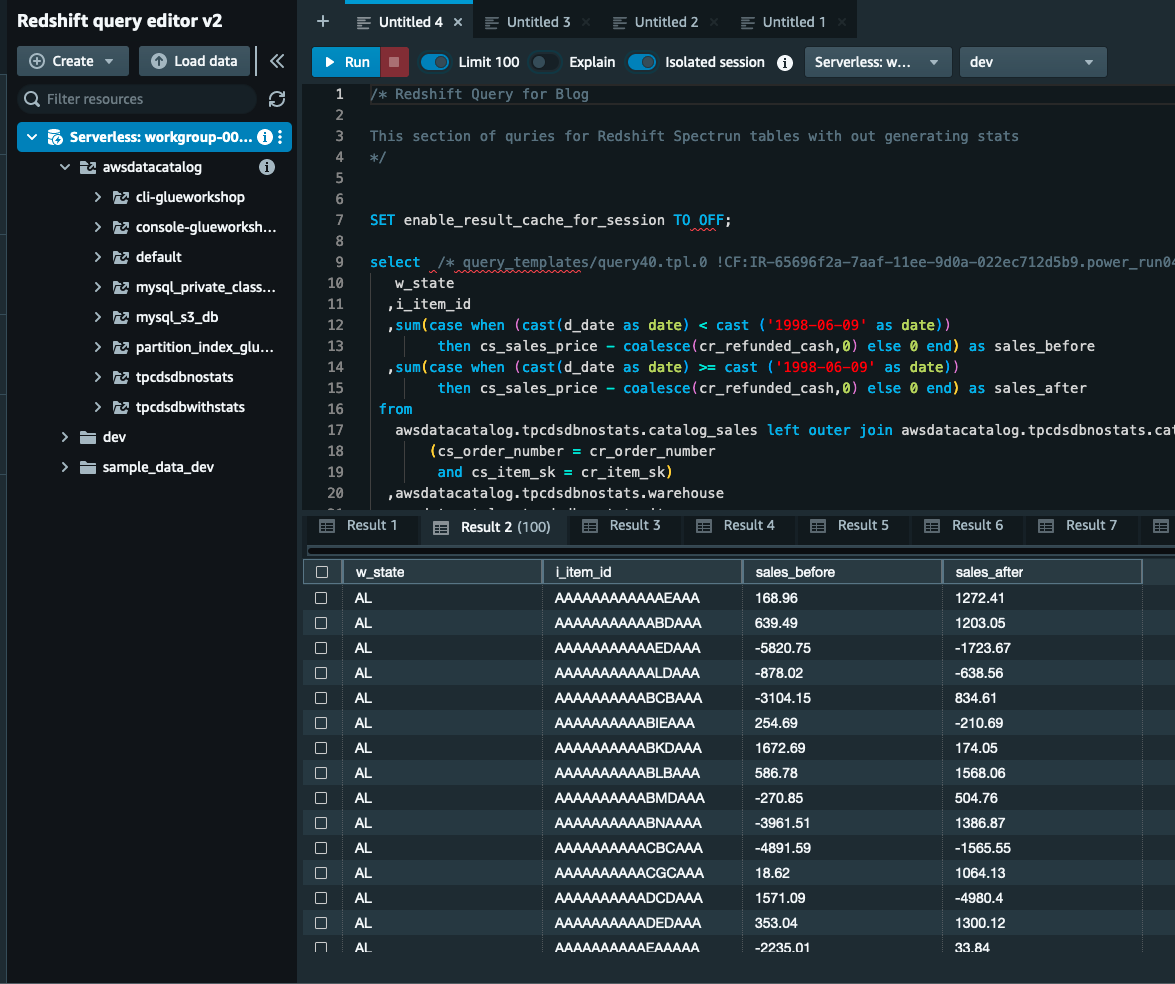
Générer des statistiques sur les tables du catalogue AWS Glue
Pour générer des statistiques sur les tables AWS Glue Catalog, procédez comme suit :
- Accédez à la Console de colle AWS et choisissez les bases de données sous Catalogue de données.
- Cliquez sur
tpcdsdbwithstatsbase de données et il listera toutes les tables disponibles. - Sélectionnez l'une de ces tables (par exemple,
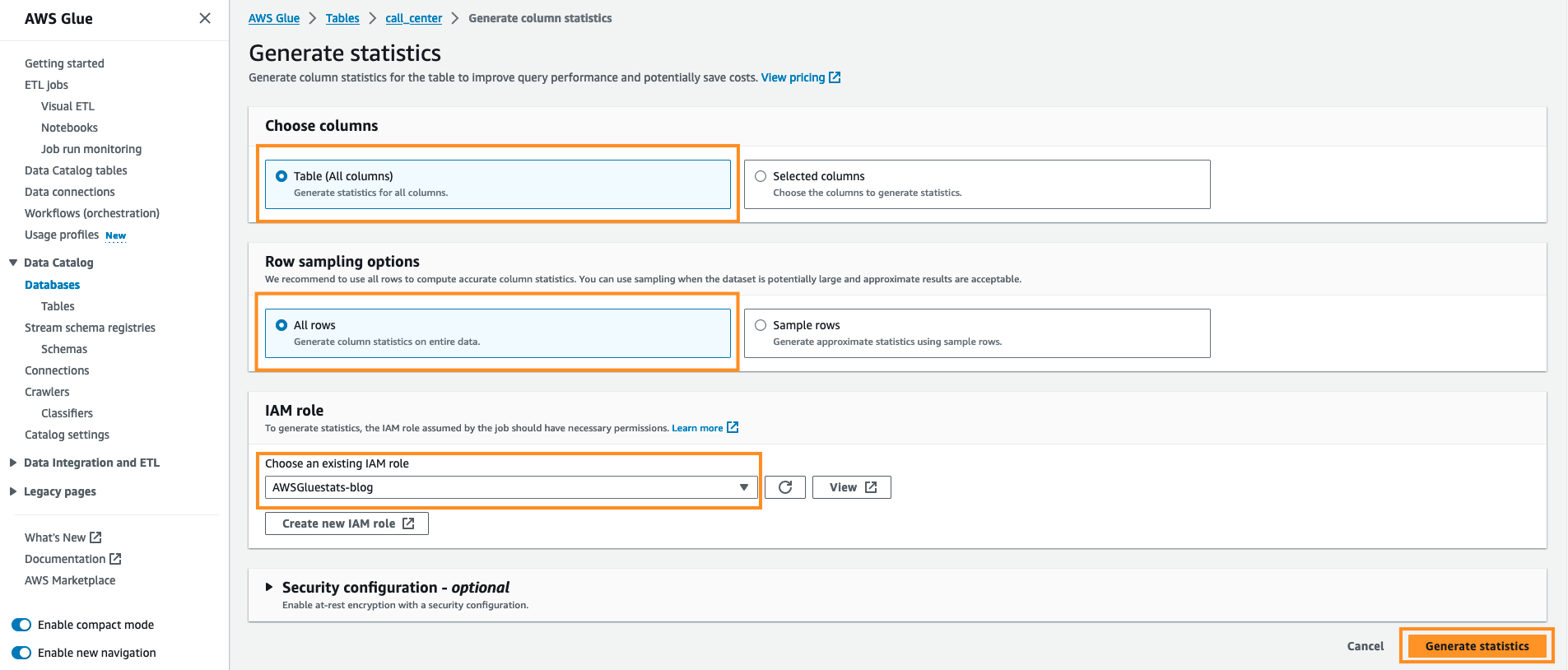
call_center). - Cliquez sur Statistiques de colonnes – nouveau onglet et choisissez Générez des statistiques.
- Conservez l'option par défaut. Sous Choisir des colonnes garder Tableau (toutes les colonnes) et sous Options d'échantillonnage de lignes XNUMX éléments à Toutes les lignes, En dessous de IAM rôle choisir Blog AWSGluestats et sélectionnez Générez des statistiques.
Vous pourrez voir l'état de l'exécution de la génération de statistiques, comme indiqué dans l'illustration suivante :

Après avoir généré des statistiques sur les tables AWS Glue Catalog, vous devriez pouvoir voir les statistiques détaillées des colonnes pour cette table :
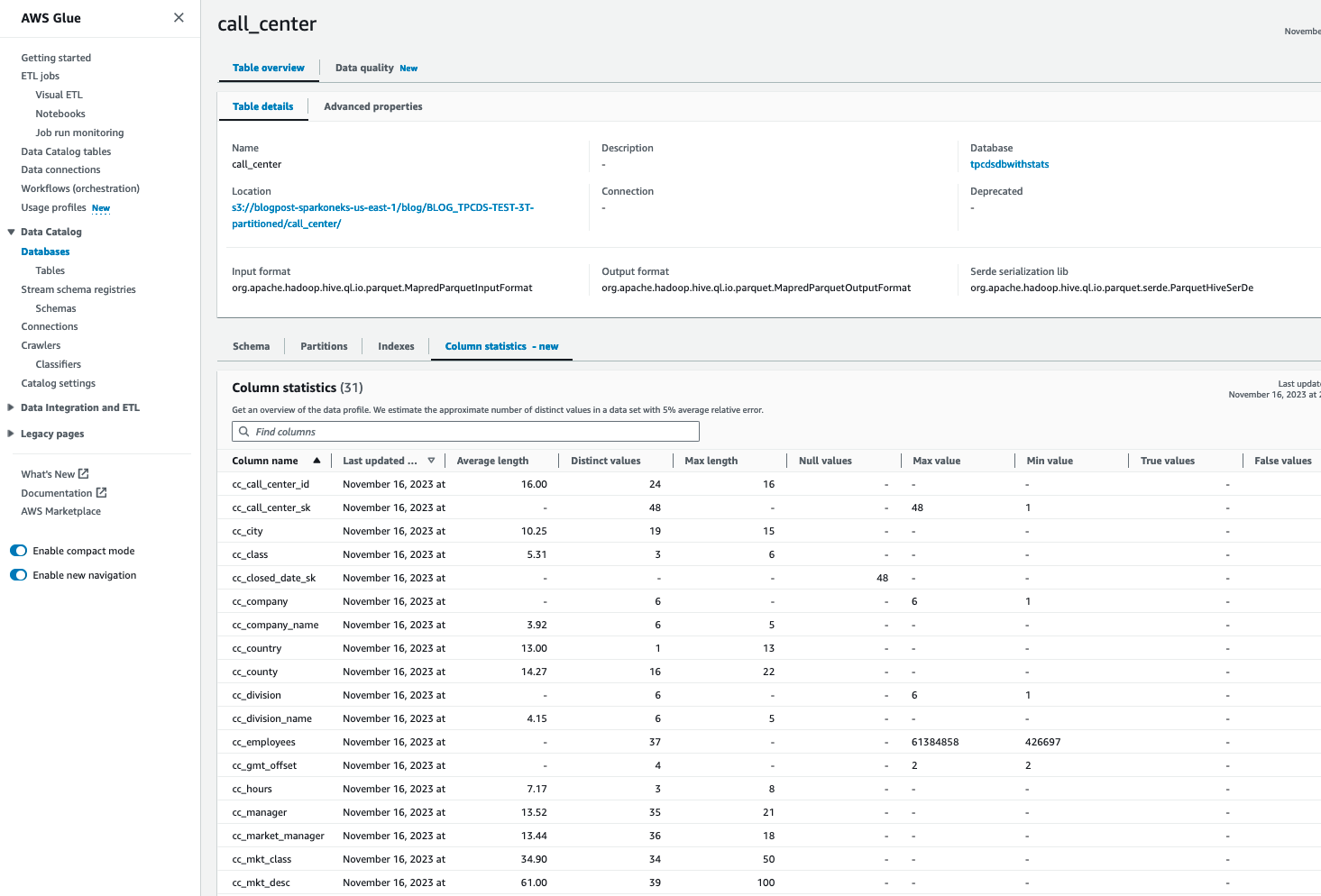
Répétez les étapes 2 à 5 pour générer des statistiques pour toutes les tables nécessaires, telles que catalog_sales, catalog_returns, warehouse, item, date_dim, store_sales, customer, customer_address, web_sales, time_dim, ship_mode, web_site, web_returns. Alternativement, vous pouvez suivre le «Planifier les exécutions de statistiques AWS Glue» vers la fin de ce blog pour générer des statistiques pour toutes les tables. Une fois cela fait, évaluez les performances des requêtes pour chaque requête.
Exécuter la requête fournie à l'aide de la console Athena sur les tables de statistiques
- Sur l'Amazonie Console Athéna, exécutez le Athena Query pour les tables avec des statistiques section de la requête téléchargée.
- Exécutez et notez l’exécution de chaque requête.
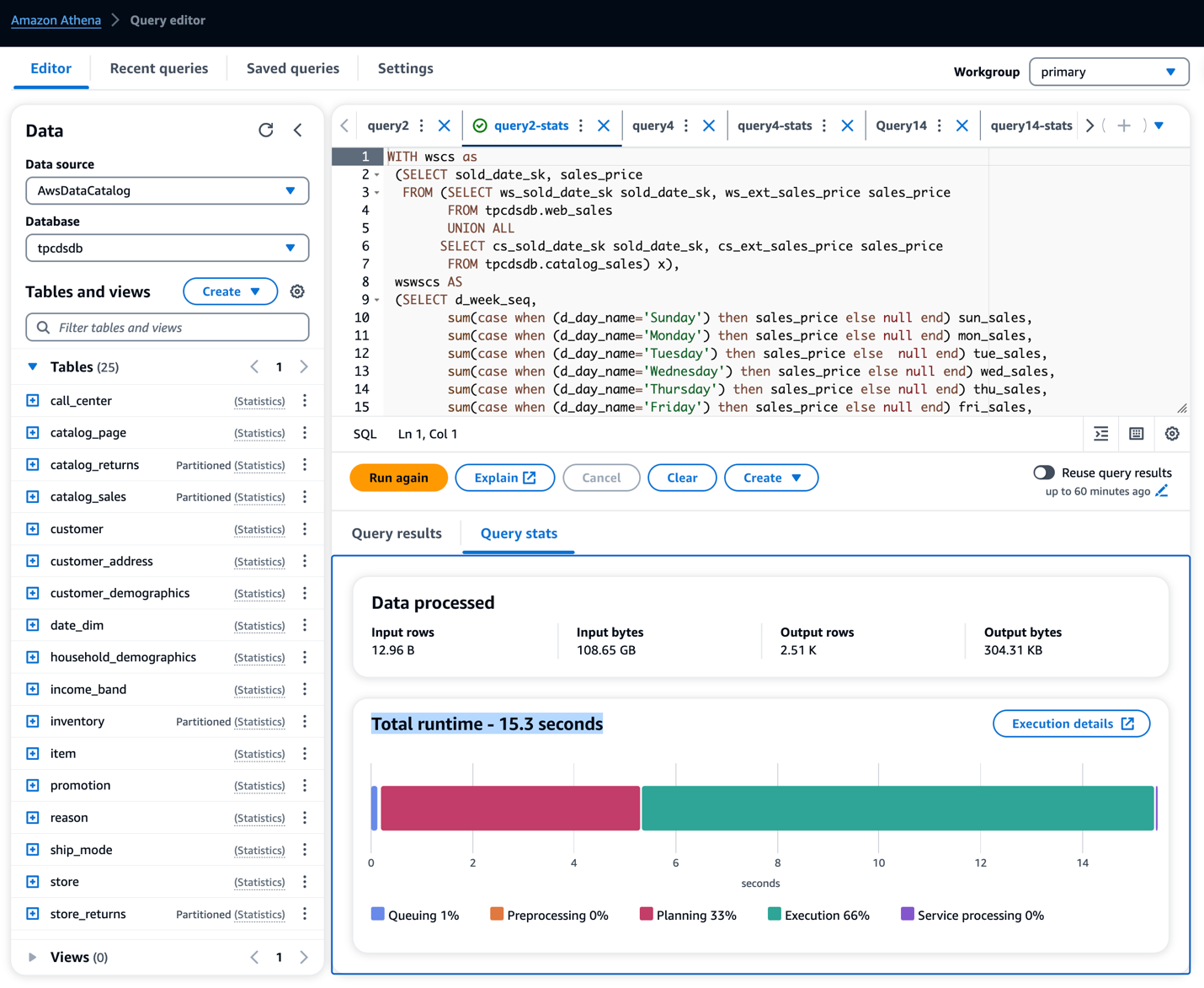
Dans notre exemple d'exécution de requêtes sur les tables, nous avons observé le temps d'exécution des requêtes selon le tableau ci-dessous. Nous avons constaté une nette amélioration des performances des requêtes, allant de 13 à 55 %.
Amélioration du temps de requête Athena
| Requêtes TPC-DS 3T | sans statistiques de colle (sec) | avec des statistiques de colle (sec) | amélioration des performances (%) |
| Requête 2 | 33.62 | 15.17 | 55% |
| Requête 4 | 132.11 | 72.94 | 45% |
| Requête 14 | 134.77 | 91.48 | 32% |
| Requête 28 | 55.99 | 39.36 | 30% |
| Requête 38 | 29.32 | 25.58 | 13% |
Exécutez la requête fournie à l'aide d'Amazon Redshift Spectrum sur les tables de statistiques
- Sur l'Amazonie Éditeur de requête Redshift v2, exécutez le Requête Redshift pour les tables avec des statistiques section de la requête téléchargée.
- Exécutez la requête et notez l’exécution de chaque requête.
Dans notre exemple d'exécution de requêtes sur les tables, nous avons observé le temps d'exécution des requêtes selon le tableau ci-dessous. Nous avons constaté une nette amélioration des performances des requêtes, allant de 13 à 89 %.
Amélioration du temps de requête Amazon Redshift Spectrum
| Requêtes TPC-DS 3T | sans statistiques de colle (sec) | avec des statistiques de colle (sec) | amélioration des performances (%) |
| Requête 40 | 124.156 | 13.12 | 89% |
| Requête 60 | 29.52 | 16.97 | 42% |
| Requête 66 | 18.914 | 16.39 | 13% |
| Requête 95 | 308.806 | 200 | 35% |
| Requête 99 | 20.064 | 16 | 20% |
Planifier les exécutions de statistiques AWS Glue
Dans ce segment de l'article, nous vous guiderons à travers les étapes de planification des exécutions de statistiques de colonne AWS Glue à l'aide de AWS Lambda et les terres parsemées de Amazon Event Bridge Planificateur. Pour rationaliser ce processus, une fonction AWS Lambda et un planificateur Amazon EventBridge ont été créés dans le cadre du déploiement de la pile CloudFormation.
- Configuration de la fonction AWS Lambda :
Pour commencer, nous utilisons une fonction AWS Lambda pour déclencher l'exécution de la tâche de statistiques de colonne AWS Glue. La fonction AWS Lambda appelle le start_column_statistics_task_run API via la bibliothèque boto3 (AWS SDK pour Python). Cela pose les bases de l’automatisation de la mise à jour des statistiques des colonnes.
Explorons la fonction AWS Lambda :
-
- Allez à Console AWS Glue Lambda.
- Sélectionnez Les fonctions et localiser le
GlueTableStatisticsFunctionv1. - Pour une meilleure compréhension de la fonction AWS Lambda, nous vous recommandons de consulter le code dans le Code section et en examinant les variables d'environnement sous configuration.
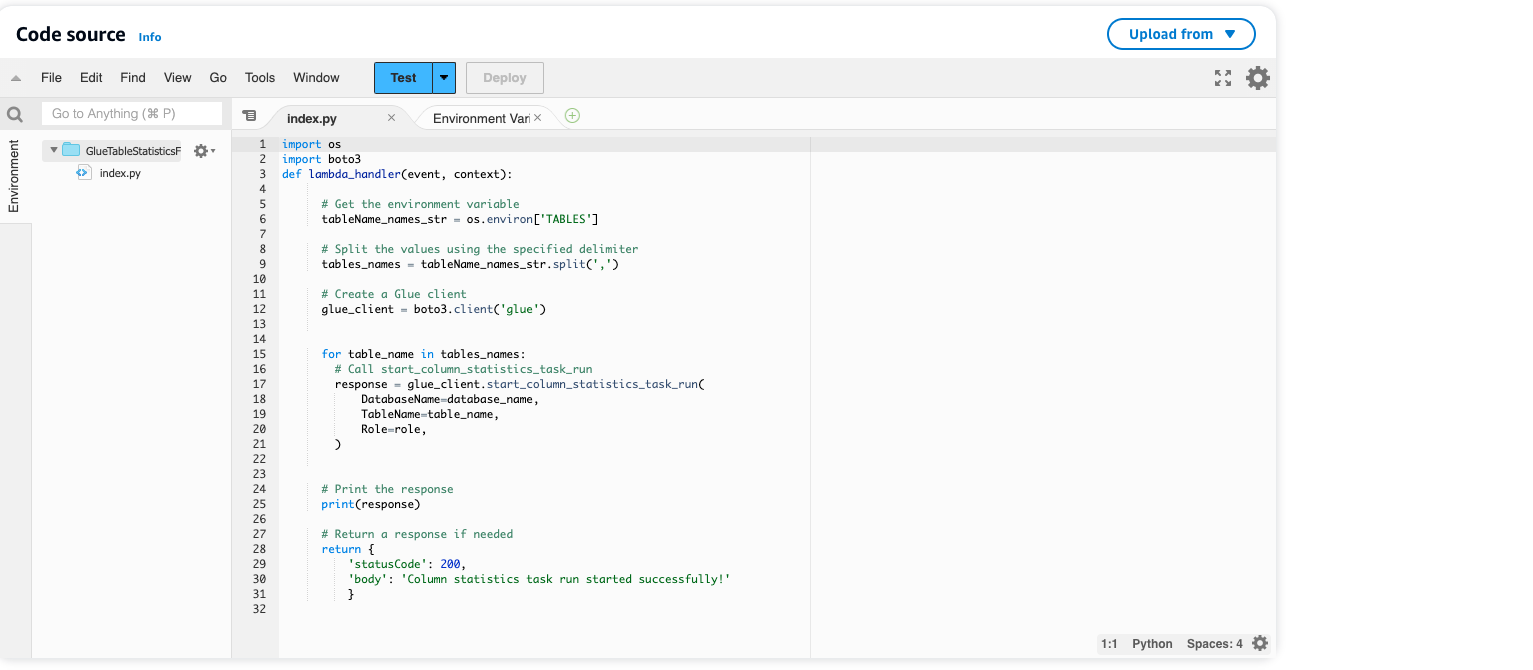
- Configuration du planificateur Amazon EventBridge
L'étape suivante consiste à planifier l'appel de la fonction AWS Lambda à l'aide d'Amazon. Planificateur EventBridge. Le planificateur est configuré pour déclencher la fonction AWS Lambda quotidiennement à une heure précise – dans ce cas, 08h00. Cela garantit que la tâche de statistiques de colonne AWS Glue s'exécute de manière régulière et prévisible.
Voyons maintenant comment mettre à jour le planning :
Nettoyer
Pour éviter des frais indésirables sur votre compte AWS, supprimez les ressources AWS :
- Connectez-vous à la console AWS CloudFormation en tant qu'administrateur AWS IAM utilisé pour créer la pile AWS CloudFormation.
- Supprimez la pile AWS CloudFormation que vous avez créée.
Conclusion
Dans cet article, nous vous avons montré comment utiliser Catalogue de données AWS Glue pour générer des statistiques au niveau des colonnes pour Colle AWS les tables. Ces statistiques sont désormais intégrées à l'optimiseur basé sur les coûts de Amazone Athéna et Amazon Spectre de décalage vers le rouge, ce qui entraîne une amélioration des performances des requêtes et des économies potentielles. Faire référence à Docs pour la prise en charge des statistiques du catalogue Glue dans divers services analytiques AWS.
Si vous avez des questions ou des suggestions, soumettez-les dans la section des commentaires.
À propos des auteurs
 Sandeep Adwankar est chef de produit technique senior chez AWS. Basé dans la région de la baie de Californie, il travaille avec des clients du monde entier pour traduire les exigences commerciales et techniques en produits qui permettent aux clients d'améliorer la façon dont ils gèrent, sécurisent et accèdent aux données.
Sandeep Adwankar est chef de produit technique senior chez AWS. Basé dans la région de la baie de Californie, il travaille avec des clients du monde entier pour traduire les exigences commerciales et techniques en produits qui permettent aux clients d'améliorer la façon dont ils gèrent, sécurisent et accèdent aux données.
 Navnit Shukla sert d'architecte de solutions spécialisé AWS avec un accent sur l'analyse. Il possède un grand enthousiasme pour aider les clients à découvrir des informations précieuses à partir de leurs données. Grâce à son expertise, il construit des solutions innovantes qui permettent aux entreprises de prendre des décisions éclairées et fondées sur les données. Notamment, Navnit Shukla est l'auteur accompli du livre intitulé Data Wrangling on AWS. Il est joignable via LinkedIn.
Navnit Shukla sert d'architecte de solutions spécialisé AWS avec un accent sur l'analyse. Il possède un grand enthousiasme pour aider les clients à découvrir des informations précieuses à partir de leurs données. Grâce à son expertise, il construit des solutions innovantes qui permettent aux entreprises de prendre des décisions éclairées et fondées sur les données. Notamment, Navnit Shukla est l'auteur accompli du livre intitulé Data Wrangling on AWS. Il est joignable via LinkedIn.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/enhance-query-performance-using-aws-glue-data-catalog-column-level-statistics/
- :est
- :où
- $UP
- 08
- 1
- 10
- 100
- 13
- 264
- 30
- a
- Capable
- accès
- Gestion des accès
- accessible
- accompli
- Compte
- hybrides
- Avec cette connaissance vient le pouvoir de prendre
- reconnaître
- à travers
- Après
- Tous
- permet
- Amazon
- Amazone Athéna
- Amazon Web Services
- quantités
- an
- Analytique
- analytique
- et les
- tous
- api
- approprié
- architecture
- SONT
- Réservé
- autour
- AS
- d'aspect
- Evaluer
- assistant
- At
- auteur
- automatiquement
- automatiser
- disponibles
- éviter
- AWS
- AWS CloudFormation
- Colle AWS
- AWS Lambda
- basé
- base
- baie
- BE
- before
- commencer
- ci-dessous
- Blog
- livre
- l'attrait
- PONT
- la performance des entreprises
- entreprises
- by
- Californie
- CAN
- capacités
- aptitude
- maisons
- catalogue
- centralisée
- certaines
- difficile
- Modifications
- des charges
- choix
- Selectionnez
- clair
- plus clair
- CLIENTS
- le cloud
- code
- Colonne
- Colonnes
- commentaires
- comparer
- complet
- finalise
- complexe
- complet
- configurée
- consiste
- Console
- consommateur
- Les consommateurs
- Correspondant
- Prix
- les économies de coûts
- Costs
- chenilles
- engendrent
- créée
- La création
- Clients
- personnaliser
- Tous les jours
- données
- Lac de données
- data-driven
- Base de données
- bases de données
- ensembles de données
- Réglage par défaut
- démontrer
- départements
- déployer
- déployé
- déploiement
- désigné
- un
- détaillé
- détails
- différent
- découverte
- distinct
- fait
- down
- durée
- pendant
- e
- chacun
- éditeur
- efficacité
- efficace
- non plus
- vous accompagner
- permettre
- encourager
- fin
- end-to-end
- de renforcer
- améliorée
- Assure
- à leurs besoins.
- Environment
- notamment
- Ether (ETH)
- évaluer
- événement
- Examiner
- exemple
- exécuter
- exécution
- d'experience
- nous a permis de concevoir
- explorez
- plus rapide
- few
- Fichiers
- finale
- Focus
- suivre
- Abonnement
- Pour
- De
- fonction
- générer
- généré
- génère
- générateur
- génération
- globe
- gouvernance
- fond
- guide
- Vous avez
- he
- aide
- Haute
- sa
- organisé
- Comment
- How To
- HTML
- http
- HTTPS
- IAM
- identique
- Identite
- gestion des identités et des accès
- if
- illustre
- Impact
- Mettre en oeuvre
- important
- améliorer
- amélioré
- amélioration
- améliorations
- améliore
- in
- comprendre
- inclut
- Actualités
- technologie innovante
- idées.
- des services
- l'intention
- développement
- invoque
- implique
- IT
- Emploi
- Emplois
- rejoindre
- Joint
- jpg
- json
- XNUMX éléments à
- lac
- des lacs
- gros
- lancer
- lancement
- Conduit
- savant
- Niveau
- Bibliothèque
- comme
- Liste
- Style
- ressembler
- Faible
- LES PLANTES
- a prendre une
- Fabrication
- gérer
- gestion
- manager
- max
- Mai..
- Métadonnées
- pourrait
- m.
- minutes
- PLUS
- plus efficace
- (en fait, presque toutes)
- plusieurs
- Navigation
- Près
- nécessaire
- Besoin
- Besoins
- Nouveauté
- next
- aucune
- notamment
- noter
- maintenant
- nombre
- observée
- of
- on
- une fois
- ONE
- Opérations
- à mettre en œuvre pour gérer une entreprise rentable. Ce guide est basé sur trois décennies d'expérience
- Optimiser
- Option
- or
- de commander
- organisations
- nos
- ande
- propre
- page
- pain
- partie
- /
- effectuer
- performant
- autorisations
- et la planification de votre patrimoine
- plans
- Platon
- Intelligence des données Platon
- PlatonDonnées
- veuillez cliquer
- pm
- politiques
- possède
- Post
- défaillances
- l'éventualité
- Prévisible
- prédiction
- Prédictions
- précédent
- Privé
- processus
- Nos producteurs
- Produit
- chef de produit
- Produits
- à condition de
- aportando
- public
- Python
- requêtes
- fréquemment posées
- Rapide
- allant
- raw
- atteint
- Lire
- recommander
- Prix Réduit
- reportez-vous
- référence
- région
- Standard
- exigence
- Exigences
- Resources
- résultat
- résultant
- Avis
- examen
- Rôle
- Itinéraire
- RANGÉE
- Courir
- pour le running
- fonctionne
- Épargnes
- scie
- calendrier
- ordonnancement
- Sdk
- de façon transparente
- SEC
- Section
- sécurisé
- sur le lien
- clignotant
- Sélectionner
- supérieur
- Sans serveur
- sert
- service
- Services
- Sets
- installation
- Partager
- devrait
- montré
- montré
- étapes
- sur mesure
- Solutions
- quelques
- spécialiste
- groupe de neurones
- Spectre
- SQL
- empiler
- Étape
- statistiques
- stats
- Statut
- étapes
- Étapes
- storage
- Boutique
- stockée
- rationaliser
- STRONG
- soumettre
- sous-réseau
- sous-réseaux
- Avec succès
- tel
- Combinaison
- Support
- table
- Prenez
- parlant
- équipes
- Technique
- modèle
- qui
- Le
- leur
- Les
- Là.
- ainsi
- Ces
- l'ont
- this
- ceux
- Avec
- fiable
- titré
- à
- traduire
- déclencher
- Essai
- deux
- sous
- sous-jacent
- compréhension
- indésirable
- Mises à jour
- a actualisé
- utilisé
- d'utiliser
- utilisateurs
- en utilisant
- utiliser
- Utilisant
- Précieux
- Valeurs
- divers
- Vaste
- vérifier
- Voir
- Salle de conférence virtuelle
- we
- web
- services Web
- ont été
- quand
- qui
- sera
- comprenant
- dans les
- sans
- activités principales
- workflow
- Groupe De Travail
- vos contrats
- pourra
- XML
- yaml
- you
- Votre
- zéphyrnet