Kuva tekijältä
Monet kehittyneet koneoppimismallit, kuten satunnaiset metsät tai gradienttitehostusalgoritmit, kuten XGBoost, CatBoost tai LightGBM (ja jopa autokooderit!) luottaa keskeiseen yhteiseen ainesosaan: päätöspuu!
Ilman päätöspuiden ymmärtämistä on mahdotonta ymmärtää myöskään mitään edellä mainituista edistyneistä pussitus- tai gradienttia lisäävistä algoritmeista, mikä on häpeällistä datatieteilijälle! Selvitetään siis päätöspuun sisäinen toiminta toteuttamalla sellainen Pythonissa.
Tässä artikkelissa opit
- miksi ja miten päätöspuu jakaa tietoja,
- tiedon saaminen ja
- kuinka toteuttaa päätöspuut Pythonissa NumPyn avulla.
Löydät koodin osoitteesta minun Github.
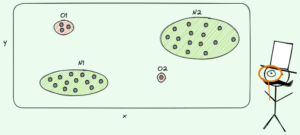
Ennusteiden tekemiseksi päätöspuut luottavat siihen halkaisu tietojoukon pienempiin osiin rekursiivisesti.

Kuva tekijältä
Yllä olevassa kuvassa näet yhden esimerkin jakamisesta – alkuperäinen tietojoukko jaetaan kahteen osaan. Seuraavassa vaiheessa molemmat osat jaetaan uudelleen ja niin edelleen. Tämä jatkuu, kunnes jonkinlainen pysäytyskriteeri täyttyy, esim.
- jos jakaminen johtaa siihen, että osa on tyhjä
- jos saavutettiin tietty rekursio- syvyys
- jos (aiempien jakojen jälkeen) tietojoukko koostuu vain muutamasta elementistä, mikä tekee lisäjakoista tarpeettomia.
Miten löydämme nämä erot? Ja miksi me edes välitämme? Otetaan selvää.
Motivoiminen
Oletetaan, että haluamme ratkaista a binaarinen luokitteluongelma jonka luomme itsemme nyt:
import numpy as np
np.random.seed(0) X = np.random.randn(100, 2) # features
y = ((X[:, 0] > 0) * (X[:, 1] < 0)) # labels (0 and 1)Kaksiulotteiset tiedot näyttävät tältä:

Kuva tekijältä
Voimme nähdä, että on olemassa kaksi erilaista luokkaa - violetti noin 75 prosentissa ja keltainen noin 25 prosentissa tapauksista. Jos syötät nämä tiedot päätöspuuhun luokitella, tällä puulla on aluksi seuraavat ajatukset:
”On kaksi erilaista etikettiä, mikä on minulle liian sotkuista. Haluan siivota tämän sotkun jakamalla tiedot kahteen osaan – näiden osien pitäisi olla puhtaampia kuin koko data ennen." - tajuihinsa tullut puu
Ja niin puu tekee.

Kuva tekijältä
Puu päättää tehdä halkeaman suunnilleen pitkin x-akseli. Tämä vaikuttaa siihen, että tietojen yläosa on nyt täydellinen puhdas, tarkoittaa, että vain löydät yksi luokka (tässä tapauksessa violetti) siellä.
Alaosa on kuitenkin edelleen sotkuinen, tietyssä mielessä jopa sotkumpi kuin ennen. Luokkasuhde oli aiemmin noin 75:25 koko tietojoukossa, mutta tässä pienemmässä osassa se on noin 50:50, mikä on niin sekava kuin voi olla.
Huomautus: Tässä ei ole väliä, että violetti ja keltainen erottuvat kuvassa kauniisti. Vain se raaka määrä eri etiketeistä kahdessa osassa lasketaan.

Kuva tekijältä
Tämä on kuitenkin tarpeeksi hyvä ensimmäiseksi askeleeksi puulle, ja niin se jatkaa. Vaikka se ei loisi uutta jakoa yläosaan, puhdas osa enää, se voi luoda toisen halkeaman alaosaan sen puhdistamiseksi.

Kuva tekijältä
Et voilà, jokainen kolmesta erillisestä osasta on täysin puhdas, koska löydämme vain yhden värin (etiketin) per osa.
Ennusteiden tekeminen on nyt todella helppoa: Jos uusi tietopiste tulee, tarkista vain, mikä niistä kolme osaa se valehtelee ja antaa sille vastaavan värin. Tämä toimii niin hyvin nyt, koska jokainen osa on puhdas. Helppoa, eikö?

Kuva tekijältä
Selvä, me puhuimme puhdas ja sotkuinen tiedot, mutta toistaiseksi nämä sanat edustavat vain epämääräistä ideaa. Jotta voimme toteuttaa mitään, meidän on löydettävä tapa määritellä puhtaus.
Puhtaustoimenpiteet
Oletetaan, että meillä on esimerkiksi joitain tarroja
y_1 = [0, 0, 0, 0, 0, 0, 0, 0] y_2 = [1, 0, 0, 0, 0, 0, 1, 0]
y_3 = [1, 0, 1, 1, 0, 0, 1, 0]Intuitiivisesti, y₁ on puhtain tarrasarja, jota seuraa y₂ ja sitten y₃. Toistaiseksi kaikki on mennyt hyvin, mutta kuinka voimme arvioida tätä käyttäytymistä? Ehkä helpoin asia, joka tulee mieleen, on seuraava:
Laske vain nollien määrä ja ykkösten määrä. Laske niiden absoluuttinen ero. Jotta se olisi mukavampaa, normalisoi se jakamalla taulukoiden pituudella.
Esimerkiksi y₂ on yhteensä 8 merkintää — 6 nollaa ja 2 ykköstä. Siksi meidän räätälöityjä puhtauspisteet olisi |6 – 2| /8 = 0.5. Puhtauspisteet on helppo laskea y₁ ja y₃ ovat 1.0 ja 0.0. Tässä näemme yleisen kaavan:

Kuva tekijältä
Täällä n₀ ja nXNUMX ovat nollien ja ykkösten lukuja, vastaavasti, n = nXNUMX + nXNUMX on taulukon pituus ja pXNUMX = nl/n on 1-tunnisteiden osuus.
Tämän kaavan ongelma on, että se on räätälöity erityisesti kahden luokan tapaukseen, mutta usein olemme kiinnostuneita moniluokkaisesta luokituksesta. Yksi varsin hyvin toimiva kaava on Gini-epäpuhtausmitta:

Kuva tekijältä
tai yleinen tapaus:

Kuva tekijältä
Se toimii niin hyvin, että scikit-learn hyväksyi sen oletustoimenpiteenä ICT DecisionTreeClassifier luokka.

Kuva tekijältä
Huomautus: Gini mittaa sotkuisuus puhtauden sijasta. Esimerkki: jos lista sisältää vain yhden luokan (=erittäin puhdasta dataa!), niin kaikki summan termit ovat nollia, joten summa on nolla. Pahin tapaus on, jos kaikki luokat esiintyvät tarkan määrän kertoja, jolloin Gini on 1-1/C jossa C on luokkien lukumäärä.
Nyt kun meillä on puhtauden/sotkuisuuden mitta, katsotaan kuinka sitä voidaan käyttää hyvien halkeamien löytämiseen.
Splittien löytäminen
Valikoimastamme löytyy monia jakoja, mutta mikä on hyvä? Käytetään uudelleen alkuperäistä tietojoukkoamme yhdessä Gini-epäpuhtausmitan kanssa.

Kuva tekijältä
Emme nyt laske pisteitä, mutta oletetaan, että 75 % on violetteja ja 25 % keltaisia. Ginin määritelmää käyttäen koko tietojoukon epäpuhtaus on

Kuva tekijältä
Jos jaamme tietojoukon pitkin x-akseli, kuten aiemmin:

Kuva tekijältä
- yläosassa on Gini-epäpuhtaus 0.0 ja alaosa

Kuva tekijältä
Keskimäärin näissä kahdessa osassa on Gini-epäpuhtaus (0.0 + 0.5) / 2 = 0.25, mikä on parempi kuin koko tietojoukon 0.375 aikaisemmasta. Voimme ilmaista sen myös ns tiedon saaminen:
Tämän jaon informaatiohyöty on 0.375 – 0.25 = 0.125.
Helppoa niin. Mitä suurempi tiedon vahvistus (eli mitä pienempi Gini-epäpuhtaus), sitä parempi.
Huomautus: Toinen yhtä hyvä alkujako olisi y-akselia pitkin.
Tärkeä asia pitää mielessä, että siitä on hyötyä punnitse osien Gini-epäpuhtaudet osien koon mukaan. Oletetaan esimerkiksi niin
- osa 1 koostuu 50 tietopisteestä ja sen Gini-epäpuhtaudet ovat 0.0 ja
- osa 2 koostuu 450 tietopisteestä ja sen Gini-epäpuhtaus on 0.5,
silloin keskimääräisen Gini-epäpuhtauden ei pitäisi olla (0.0 + 0.5) / 2 = 0.25, vaan pikemminkin 50 / (50 + 450) * 0.0 + 450 / (50 + 450) * 0.5 = 0.45.
Okei, ja miten löydämme parhaan jaon? Yksinkertainen mutta järkyttävä vastaus on:
Kokeile vain kaikkia jakoja ja valitse se, jolla on eniten tietoa. Se on pohjimmiltaan raa'an voiman lähestymistapa.
Tarkemmin sanottuna käytetään tavallisia päätöspuita halkeaa koordinaattiakseleita pitkin, eli xᵢ = c jollekin ominaisuudelle i ja kynnys c. Tämä tarkoittaa sitä että
- yksi osa jaetuista tiedoista koostuu kaikista datapisteistä x with xᵢ cja
- toinen osa kaikista kohdista x with xᵢ ≥ c.
Nämä yksinkertaiset jakosäännöt ovat osoittautuneet riittävän hyviksi käytännössä, mutta voit tietysti myös laajentaa tätä logiikkaa luomaan muita jakoja (esim. xᵢ + 2xⱼ = 3, esimerkiksi).
Hienoa, nämä ovat kaikki ainekset, jotka meidän on nyt lähdettävä liikkeelle!
Otamme nyt päätöspuun käyttöön. Koska se koostuu solmuista, määritellään a Node luokka ensin.
from dataclasses import dataclass @dataclass
class Node: feature: int = None # feature for the split value: float = None # split threshold OR final prediction left: np.array = None # store one part of the data right: np.array = None # store the other part of the dataSolmu tuntee ominaisuuden, jota se käyttää jakamiseen (feature) sekä jakoarvo (value). value käytetään myös tallennusvälineenä päätöspuun lopulliselle ennusteelle. Koska rakennamme binääripuun, jokaisen solmun on tunnettava vasen ja oikea lapsensa sellaisina kuin ne on tallennettu left ja right .
Tehdään nyt varsinainen päätöspuun toteutus. Teen siitä scikit-learn-yhteensopivan, joten käytän joitain luokkia sklearn.base . Jos et ole perehtynyt asiaan, katso artikkelini aiheesta kuinka rakentaa scikit-learn-yhteensopivia malleja.
Toteutetaan!
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin class DecisionTreeClassifier(BaseEstimator, ClassifierMixin): def __init__(self): self.root = Node() @staticmethod def _gini(y): """Gini impurity.""" counts = np.bincount(y) p = counts / counts.sum() return (p * (1 - p)).sum() def _split(self, X, y): """Bruteforce search over all features and splitting points.""" best_information_gain = float("-inf") best_feature = None best_split = None for feature in range(X.shape[1]): split_candidates = np.unique(X[:, feature]) for split in split_candidates: left_mask = X[:, feature] split X_left, y_left = X[left_mask], y[left_mask] X_right, y_right = X[~left_mask], y[~left_mask] information_gain = self._gini(y) - ( len(X_left) / len(X) * self._gini(y_left) + len(X_right) / len(X) * self._gini(y_right) ) if information_gain > best_information_gain: best_information_gain = information_gain best_feature = feature best_split = split return best_feature, best_split def _build_tree(self, X, y): """The heavy lifting.""" feature, split = self._split(X, y) left_mask = X[:, feature] split X_left, y_left = X[left_mask], y[left_mask] X_right, y_right = X[~left_mask], y[~left_mask] if len(X_left) == 0 or len(X_right) == 0: return Node(value=np.argmax(np.bincount(y))) else: return Node( feature, split, self._build_tree(X_left, y_left), self._build_tree(X_right, y_right), ) def _find_path(self, x, node): """Given a data point x, walk from the root to the corresponding leaf node. Output its value.""" if node.feature == None: return node.value else: if x[node.feature] node.value: return self._find_path(x, node.left) else: return self._find_path(x, node.right) def fit(self, X, y): self.root = self._build_tree(X, y) return self def predict(self, X): return np.array([self._find_path(x, self.root) for x in X])Ja siinä se! Voit tehdä kaikki scikit-learnissä rakastamasi asiat nyt:
dt = DecisionTreeClassifier().fit(X, y)
print(dt.score(X, y)) # accuracy # Output
# 1.0Koska puu on epäsäännöllinen, se istuu liikaa, joten täydellinen junatulos. Tarkkuus olisi huonompi näkymättömissä tiedoissa. Voimme myös tarkistaa, miltä puu näyttää via
print(dt.root) # Output (prettified manually):
# Node(
# feature=1,
# value=-0.14963454032767076,
# left=Node(
# feature=0,
# value=0.04575851730144607,
# left=Node(
# feature=None,
# value=0,
# left=None,
# right=None
# ),
# right=Node(
# feature=None,
# value=1,
# left=None,
# right=None
# )
# ),
# right=Node(
# feature=None,
# value=0,
# left=None,
# right=None
# )
# )Kuvana se olisi tämä:

Kuva tekijältä
Tässä artikkelissa olemme nähneet, kuinka päätöspuut toimivat yksityiskohtaisesti. Aloitimme epämääräisillä, mutta intuitiivisilla ideoilla ja muutimme ne kaavoiksi ja algoritmeiksi. Lopulta pystyimme toteuttamaan päätöspuun tyhjästä.
Varoituksen sana kuitenkin: Päätöspuutamme ei voida vielä laillistaa. Yleensä haluamme määrittää parametreja, kuten
- max syvyys
- lehtien koko
- ja minimaalinen tiedonsaanti
monien muiden joukossa. Onneksi nämä asiat eivät ole niin vaikeita toteuttaa, mikä tekee tästä täydellisen kotitehtävän sinulle. Esimerkiksi jos määrität leaf_size=10 parametrina, yli 10 näytettä sisältäviä solmuja ei pitäisi enää jakaa. Myös tämä toteutus on ei tehokasta. Yleensä et halua tallentaa osia tietojoukoista solmuihin, vaan sen sijaan vain indeksit. Joten (mahdollisesti suuri) tietojoukkosi on muistissa vain kerran.
Hyvä asia on, että voit nyt tulla hulluksi tämän päätöspuumallin kanssa. Sinä pystyt:
- toteuttaa diagonaaliset jaot, esim xᵢ + 2xⱼ = 3 eikä vain xᵢ = 3,
- muuttaa lehtien sisällä tapahtuvaa logiikkaa, eli voit suorittaa logistisen regression jokaisen lehden sisällä pelkän enemmistöäänestyksen sijaan, mikä antaa sinulle lineaarinen puu
- muuta jakamismenettelyä, eli raa'an voiman käyttämisen sijaan kokeile satunnaisia yhdistelmiä ja valitse paras, joka antaa sinulle ylimääräinen puiden luokitin
- ja enemmän.
Tri Robert Kübler on tietotutkija Publicis Mediassa ja kirjoittaja Towards Data Science -palvelussa.
Alkuperäinen. Postitettu luvalla.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- Platoblockchain. Web3 Metaverse Intelligence. Tietoa laajennettu. Pääsy tästä.
- Lähde: https://www.kdnuggets.com/2023/02/understanding-implementing-decision-tree.html?utm_source=rss&utm_medium=rss&utm_campaign=understanding-by-implementing-decision-tree
- 1
- 10
- 100
- 11
- 28
- 7
- 9
- a
- pystyy
- Meistä
- edellä
- absoluuttinen
- tarkkuus
- kehittynyt
- Jälkeen
- algoritmit
- Kaikki
- määrä
- ja
- Toinen
- vastaus
- näyttää
- lähestymistapa
- suunnilleen
- noin
- Ryhmä
- artikkeli
- kirjoittaja
- keskimäärin
- pohja
- Pohjimmiltaan
- koska
- ennen
- ovat
- PARAS
- Paremmin
- lisäämällä
- pohja
- raaka voima
- rakentaa
- ei voi
- joka
- tapaus
- tapauksissa
- tietty
- tarkastaa
- Lapset
- Valita
- luokka
- luokat
- luokittelu
- koodi
- väri
- yhdistelmät
- Yhteinen
- yhteensopiva
- täydellinen
- täysin
- Laskea
- tajunta
- jatkuu
- koordinoida
- vastaava
- kurssi
- luoda
- ratkaiseva
- tiedot
- tietojenkäsittely
- tietojen tutkija
- aineistot
- päätös
- päätöspuu
- oletusarvo
- syvyys
- yksityiskohta
- ero
- eri
- vaikea
- ei
- tekee
- kukin
- Helpoin
- vaikutus
- elementtejä
- tarpeeksi
- Koko
- yhtä
- Eetteri (ETH)
- Jopa
- esimerkki
- ilmaista
- laajentaa
- tuttu
- Muoti
- Ominaisuus
- Ominaisuudet
- harvat
- lopullinen
- Löytää
- Etunimi
- kellua
- seurannut
- jälkeen
- voima
- kaava
- alkaen
- edelleen
- Saada
- general
- saada
- Gini
- Antaa
- tietty
- antaa
- Go
- menee
- hyvä
- tapahtuu
- tätä
- korkeampi
- suurin
- läksyt
- Miten
- HTML
- HTTPS
- ajatus
- ideoita
- toteuttaa
- täytäntöönpano
- täytäntöönpanosta
- tuoda
- tärkeä
- mahdoton
- in
- Indeksit
- tiedot
- ensimmäinen
- ensin
- sen sijaan
- kiinnostunut
- intuitiivinen
- IT
- KDnuggets
- Pitää
- laji
- Tietää
- Merkki
- tarrat
- suuri
- oppiminen
- Pituus
- nosto
- linjat
- Lista
- ulkonäkö
- Erä
- rakkaus
- kone
- koneoppiminen
- Enemmistö
- tehdä
- TEE
- Tekeminen
- käsin
- monet
- asia
- välineet
- mitata
- Media
- Muisti
- mielessä
- minimi
- sekoitettu
- mallit
- lisää
- Tarve
- tarpeet
- Uusi
- seuraava
- solmu
- solmut
- numero
- numerot
- numpy
- ONE
- tilata
- alkuperäinen
- Muut
- Muuta
- parametri
- parametrit
- osa
- osat
- täydellinen
- lupa
- poimia
- kuva
- Platon
- Platonin tietotieto
- PlatonData
- Kohta
- pistettä
- mahdollisesti
- harjoitusta.
- ennustus
- Ennusteet
- edellinen
- Ongelma
- todistettu
- laittaa
- Python
- satunnainen
- suhde
- saavutettu
- Rekursiivinen
- regressio
- edustaa
- vastaavasti
- tulokset
- palata
- ROBERT
- juuri
- säännöt
- ajaa
- tiede
- Tiedemies
- scikit opittava
- Haku
- SELF
- tunne
- erillinen
- setti
- Jaa:
- shouldnt
- Yksinkertainen
- koska
- single
- Koko
- pienempiä
- So
- niin kaukana
- SOLVE
- jonkin verran
- jakaa
- splits
- standardi
- alkoi
- Vaihe
- pysäyttäminen
- Levytila
- verkkokaupasta
- tallennettu
- niin
- Räätälöity
- puhuminen
- sapluuna
- ehdot
- -
- tiedot
- heidän
- asia
- asiat
- kolmella
- kynnys
- Kautta
- kertaa
- että
- yhdessä
- liian
- ylin
- Yhteensä
- kohti
- Juna
- Puut
- Sorvatut
- ymmärtää
- ymmärtäminen
- us
- käyttää
- yleensä
- arvo
- Äänestää
- joka
- vaikka
- tulee
- sisällä
- sana
- sanoja
- Referenssit
- louhos
- toimii
- pahin
- olisi
- X
- XGBoost
- Sinun
- zephyrnet
- nolla-